
Now that we have a basic understanding of MAML, we will explore it in detail. Let's say we have a model f parameterized by θ—that is, fθ()—and we have a distribution over tasks, p(T). First, we initialize our parameter θ with some random values. Next, we sample some batch of tasks Ti from a distribution over tasks—that is, Ti ∼ p(T). Let's say we have sampled five tasks, T = {T1, T2, T3, T4, T5}, then, for each task Ti, we sample k data points and train the model. We do so by computing the loss  and we minimize the loss using gradient descent and find the optimal set of parameters that minimize the loss:
and we minimize the loss using gradient descent and find the optimal set of parameters that minimize the loss:

In the previous equation, the following applies:
 is the optimal parameter for a task Ti
is the optimal parameter for a task Ti- θ is the initial parameter
- α is the hyperparameter
 is the gradient of a task Ti
is the gradient of a task Ti
So, after the preceding gradient update, we will have optimal parameters for all five tasks that we have sampled:

Now, before sampling the next batch of tasks, we perform a meta update or meta optimization. That is, in the previous step, we found the optimal parameter  by training on each of the tasks, Ti. Now we calculate the gradient with respect to these optimal parameters
by training on each of the tasks, Ti. Now we calculate the gradient with respect to these optimal parameters  and update our randomly initialized parameter θ by training on a new set of tasks, Ti. This makes our randomly initialized parameter θ move to an optimal position where we don't have to take many gradient steps while training on the next batch of tasks. This step is called a meta step, meta update, meta optimization, or meta training. It can be expressed as follows:
and update our randomly initialized parameter θ by training on a new set of tasks, Ti. This makes our randomly initialized parameter θ move to an optimal position where we don't have to take many gradient steps while training on the next batch of tasks. This step is called a meta step, meta update, meta optimization, or meta training. It can be expressed as follows:

In the previous equation, the following applies:
- θ is our initial parameter
- β is the hyperparameter
 is the gradient for each of the new task Ti with respect to parameter
is the gradient for each of the new task Ti with respect to parameter 
If you look at our previous meta update equation closely, we can notice that we are updating our model parameter θ by merely taking an average of gradients of each new task Ti with the optimal parameter 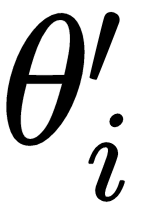 .
.
The overall algorithm of MAML is shown in the following diagram; our algorithm consists of two loops—an inner loop where we find the optimal parameter  for each of the task Ti and an outer loop where we update our randomly initialized model parameter θ by calculating gradients with respect to the optimal parameters
for each of the task Ti and an outer loop where we update our randomly initialized model parameter θ by calculating gradients with respect to the optimal parameters  in a new set of tasks Ti:
in a new set of tasks Ti:

 while updating the model parameter θ in the outer loop.
while updating the model parameter θ in the outer loop.So, in a nutshell, in MAML, we sample a batch of tasks and, for each task Ti in the batch, we minimize the loss using gradient descent and get the optimal parameter  . Then, before sampling another batch of tasks, we update our randomly initialized model parameter θ by calculating gradients with respect to the optimal parameters
. Then, before sampling another batch of tasks, we update our randomly initialized model parameter θ by calculating gradients with respect to the optimal parameters  in a new set of tasks Ti.
in a new set of tasks Ti.