
The sum of the product of the features and weights is given to the sigmoid or activation function. This is called the hypothesis. We begin with theories on what the output will look like, and then see how wrong we are when the results turn out to be different to what we actually require.
To realize how inaccurate our theories are, we require a loss, or cost, function:

The loss or cost function is the difference between the hypothesis and the real value that we know from the data. We need to add the sum function to make sure that the model accounts for all the examples and not only 1. The reason we square the value is so that we can maintain a positive value and exaggerate the difference between the true data and the error, such that the neural network will work harder to maintain as low an error rate as possible.
The plot for the cost function is as follows:
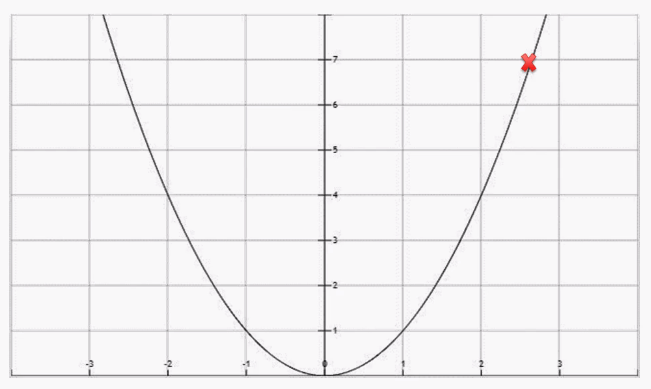
The first hypothesis is marked on the plot. We want the hypothesis that produces a cost value at the zero point because we want the hypothesis to be equal to reality, and they are equal, as we can see from the previous equation. This means that the difference is zero. But, as we saw at the beginning, we start really far away from this value.
Now we need to act on the cost function value to check the accuracy and performance of the hypothesis. In order to understand the direction in which we need to move, we need to calculate the derivative of the cost function by each of the weights. Graphically, that is interpreted as the plot on the following graph, which is tagged with the current cost value:

We subtract the derivation value from the actual weights. This is mathematically given as follows:
 ,
,
 ,
,
 ,
,
And so on...
We keep subtracting these values, iteration by iteration, just doing forward and backward passes, and keep moving closer to the zero point:

Notice the alpha here, or the learning rate. The learning rate actually defines how big the step is. If we have smaller values then the step is really small and it takes longer to get the desired value, which slows down the neural network learning, while having bigger values may actually cause our model to never get to the desired point. The alpha learning rate has to be just right.
As a sanity check, we can monitor the cost function so that it will increase iteration by iteration, and it should decrease in the long term.