
How can we deal with cases where it is unable to linearly segregate a set of observations containing outliers? We can actually allow misclassification of such outliers and try to minimize the error introduced. The misclassification error  (also called hinge loss) for a sample
(also called hinge loss) for a sample  can be expressed as follows:
can be expressed as follows:

Together with the ultimate term ‖w‖ to reduce, the final objective value we want to minimize becomes the following:

As regards a training set of m samples  ,
,  ,…
,…  …,
…, 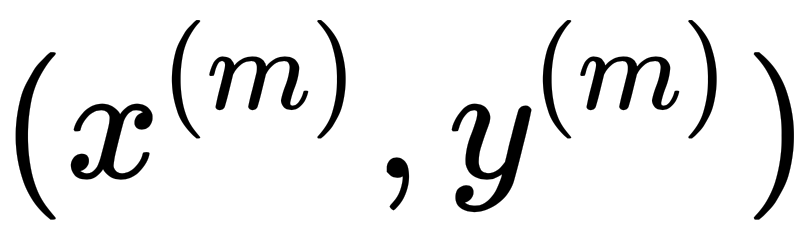 , where the hyperparameter C controls the trade-off between two terms:
, where the hyperparameter C controls the trade-off between two terms:
- If a large value of C is chosen, the penalty for misclassification becomes relatively high. It means the thumb rule of data segregation becomes stricter and the model might be prone to overfit, since few mistakes are allowed during training. An SVM model with a large C has a low bias, but it might suffer high variance.
- Conversely, if the value of C is sufficiently small, the influence of misclassification becomes fairly low. The model allows more misclassified data points than the model with large C does. Thus, data separation becomes less strict. Such a model has a low variance, but it might be compromised by a high bias.
A comparison between a large and small C is shown in the following diagram:

The parameter C determines the balance between bias and variance. It can be fine-tuned with cross-validation, which we will practice shortly.