
SVM and many other classifiers can be applied to cases with more than two classes. There are two typical approaches we can take, one-vs-rest (also called one-versus-all), and one-vs-one.
In the one-vs-rest setting, for a K-class problem, it constructs K different binary SVM classifiers. For the kth classifier, it treats the kth class as the positive case and the remaining K-1 classes as the negative case as a whole; the hyperplane denoted as  is trained to separate these two cases. To predict the class of a new sample, x', it compares the resulting predictions
is trained to separate these two cases. To predict the class of a new sample, x', it compares the resulting predictions  from K individual classifiers from 1 to k. As we discussed in the previous section, the larger value of
from K individual classifiers from 1 to k. As we discussed in the previous section, the larger value of  means higher confidence that x' belongs to the positive case. Therefore, it assigns x' to the class i where
means higher confidence that x' belongs to the positive case. Therefore, it assigns x' to the class i where  has the largest value among all prediction results:
has the largest value among all prediction results:

The following diagram presents how the one-vs-rest strategy works in a three-class case:

For instance, if we have the following (r, b, and g denote the red, blue, and green classes respectively):

We can say x' belongs to the red class since 0.78 > 0.35 > -0.64. If we have the following:

Then, we can determine that x' belongs to the blue class regardless of the sign since -0.35 > -0.64 > -0.78.
In the one-vs-one strategy, it conducts pairwise comparison by building a set of SVM classifiers distinguishing data points from each pair of classes. This will result in 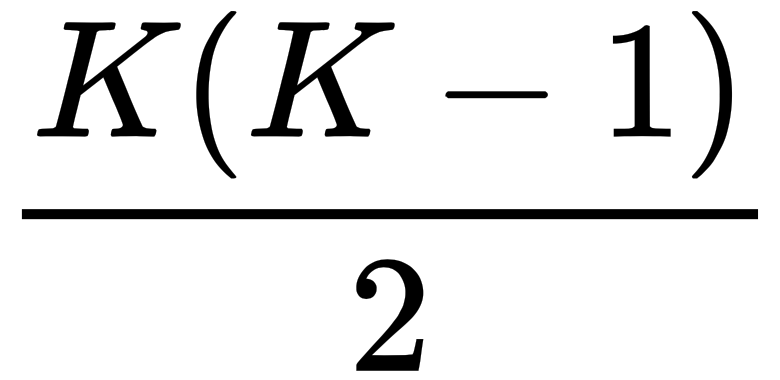 different classifiers.
different classifiers.
For a classifier associated with classes i and j, the hyperplane denoted as  is trained only on the basis of observations from i (can be viewed as a positive case) and j (can be viewed as a negative case); it then assigns the class, either i or j, to a new sample, x', based on the sign of
is trained only on the basis of observations from i (can be viewed as a positive case) and j (can be viewed as a negative case); it then assigns the class, either i or j, to a new sample, x', based on the sign of  . Finally, the class with the highest number of assignments is considered the predicting result of x'. The winner is the one that gets the most votes.
. Finally, the class with the highest number of assignments is considered the predicting result of x'. The winner is the one that gets the most votes.
The following diagram presents how the one-vs-one strategy works in a three-class case:
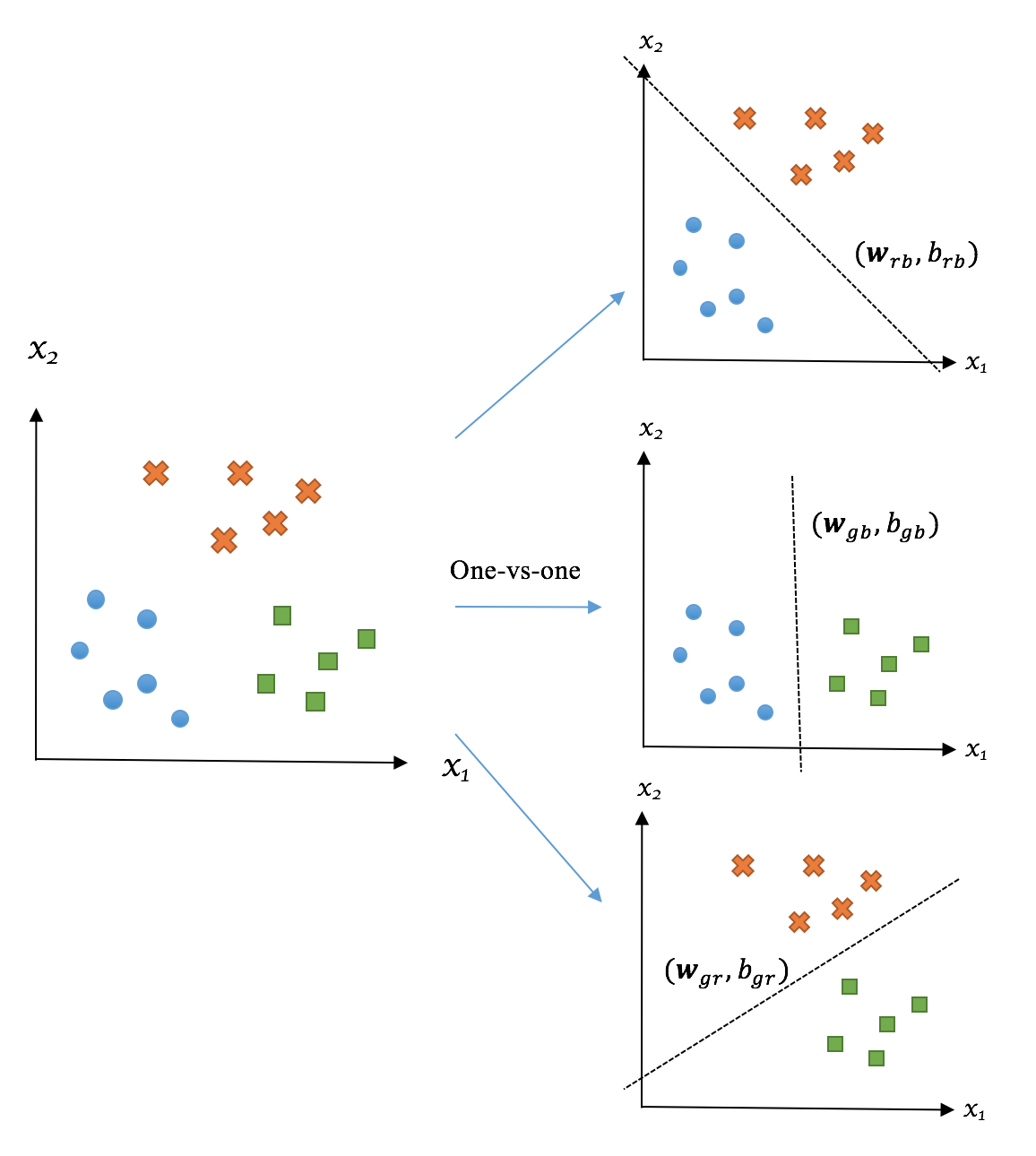
In general, an SVM classifier with one-vs-rest and with one-vs-one setting perform comparably in terms of accuracy. The choice between these two strategies is largely computational. Although one-vs-one requires more classifiers  than one-vs-rest (K), each pairwise classifier only needs to learn on a small subset of data, as opposed to the entire set in the one-vs-rest setting. As a result, training an SVM model in the one-vs-one setting is generally more memory-efficient and less computationally expensive, and hence more preferable for practical use, as argued in Chih-Wei Hsu and Chih-Jen Lin's A comparison of methods for multiclass support vector machines (IEEE Transactions on Neural Networks, March 2002, Volume 13, pp. 415-425).
than one-vs-rest (K), each pairwise classifier only needs to learn on a small subset of data, as opposed to the entire set in the one-vs-rest setting. As a result, training an SVM model in the one-vs-one setting is generally more memory-efficient and less computationally expensive, and hence more preferable for practical use, as argued in Chih-Wei Hsu and Chih-Jen Lin's A comparison of methods for multiclass support vector machines (IEEE Transactions on Neural Networks, March 2002, Volume 13, pp. 415-425).
In scikit-learn, classifiers handle multiclass cases internally, and we do not need to explicitly write any additional codes to enable it. We can see how simple it is in the following example of classifying five topics - comp.graphics, sci.space, alt.atheism, talk.religion.misc, and rec.sport.hockey:
>>> categories = [
... 'alt.atheism',
... 'talk.religion.misc',
... 'comp.graphics',
... 'sci.space',
... 'rec.sport.hockey'
... ]
>>> data_train = fetch_20newsgroups(subset='train',
categories=categories, random_state=42)
>>> data_test = fetch_20newsgroups(subset='test',
categories=categories, random_state=42)
>>> cleaned_train = clean_text(data_train.data)
>>> label_train = data_train.target
>>> cleaned_test = clean_text(data_test.data)
>>> label_test = data_test.target
>>> term_docs_train = tfidf_vectorizer.fit_transform(cleaned_train)
>>> term_docs_test = tfidf_vectorizer.transform(cleaned_test)
In an SVC model, multiclass support is implicitly handled according to the one-vs-one scheme:
>>> svm = SVC(kernel='linear', C=1.0, random_state=42)
>>> svm.fit(term_docs_train, label_train)
>>> accuracy = svm.score(term_docs_test, label_test)
>>> print('The accuracy of 5-class classification is:
{0:.1f}%'.format(accuracy*100))
The accuracy on testing set is: 88.6%
We also check how it performs for individual classes:
>>> from sklearn.metrics import classification_report
>>> prediction = svm.predict(term_docs_test)
>>> report = classification_report(label_test, prediction)
>>> print(report)
precision recall f1-score support
0 0.79 0.77 0.78 319
1 0.92 0.96 0.94 389
2 0.98 0.96 0.97 399
3 0.93 0.94 0.93 394
4 0.74 0.73 0.73 251
micro avg 0.89 0.89 0.89 1752
macro avg 0.87 0.87 0.87 1752
weighted avg 0.89 0.89 0.89 1752
Not bad! Also, we could further tweak the values of the hyperparameters kernel and C. As discussed, the factor C controls the strictness of separation, and it can be tuned to achieve the best trade-off between bias and variance. How about the kernel? What does it mean and what are the alternatives to a linear kernel?