
When selecting the best combination of feature and value as the splitting point, two criteria such as Gini Impurity and Information Gain can be used to measure the quality of separation.
Gini Impurity, as its name implies, measures the impurity rate of the class distribution of data points, or the class mixture rate. For a dataset with K classes, suppose data from class  take up a fraction
take up a fraction  of the entire dataset, the Gini Impurity of this dataset is written as follows:
of the entire dataset, the Gini Impurity of this dataset is written as follows:

Lower Gini Impurity indicates a purer dataset. For example, when the dataset contains only one class, say the fraction of this class is 1 and that of others is 0, its Gini Impurity becomes  . In another example, a dataset records a large number of coin flips, and heads and tails each take up half of the samples. The Gini Impurity is
. In another example, a dataset records a large number of coin flips, and heads and tails each take up half of the samples. The Gini Impurity is  . In binary cases, Gini Impurity under different values of the positive class' fraction can be visualized by the following code blocks:
. In binary cases, Gini Impurity under different values of the positive class' fraction can be visualized by the following code blocks:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
The fraction of the positive class varies from 0 to 1:
>>> pos_fraction = np.linspace(0.00, 1.00, 1000)
Gini Impurity is calculated accordingly, followed by the plot of Gini Impurity versus Positive fraction:
>>> gini = 1 – pos_fraction**2 – (1-pos_fraction)**2
>>> plt.plot(pos_fraction, gini)
>>> plt.ylim(0, 1)
>>> plt.xlabel(‘Positive fraction')
>>> plt.ylabel(‘Gini Impurity')
>>> plt.show()
Refer to the following screenshot for the end result:

Given the labels of a dataset, we can implement the Gini Impurity calculation function as follows:
>>> def gini_impurity(labels):
... # When the set is empty, it is also pure
... if not labels:
... return 0
... # Count the occurrences of each label
... counts = np.unique(labels, return_counts=True)[1]
... fractions = counts / float(len(labels))
... return 1 - np.sum(fractions ** 2)
Test it out with some examples:
>>> print('{0:.4f}'.format(gini_impurity([1, 1, 0, 1, 0])))
0.4800
>>> print('{0:.4f}'.format(gini_impurity([1, 1, 0, 1, 0, 0])))
0.5000
>>> print('{0:.4f}'.format(gini_impurity([1, 1, 1, 1])))
0.0000
In order to evaluate the quality of a split, we simply add up the Gini Impurity of all resulting subgroups, combining the proportions of each subgroup as corresponding weight factors. And again, the smaller the weighted sum of Gini Impurity, the better the split.
Take a look at the following self-driving car ad example, where we split the data based on user's gender and interest in technology respectively:

The weighted Gini Impurity of the first split can be calculated as follows:

The second split is as follows:

Thus, splitting based on the user's interest in technology is a better strategy than gender.
Another metric, Information Gain, measures the improvement of purity after splitting, or in other words, the reduction of uncertainty due to a split. Higher Information Gain implies better splitting. We obtain the Information Gain of a split by comparing the entropy before and after the split.
Entropy is the probabilistic measure of uncertainty. Given a K-class dataset, and  denoted as the fraction of data from class
denoted as the fraction of data from class  , the entropy of the dataset is defined as follows:
, the entropy of the dataset is defined as follows:
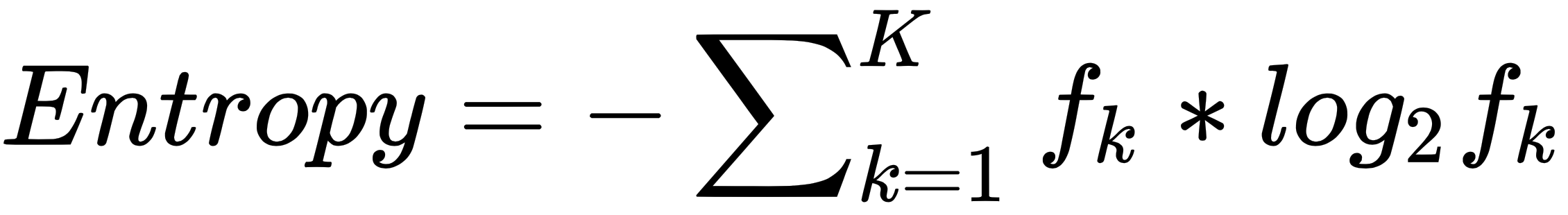
Lower entropy implies a purer dataset with less ambiguity. In a perfect case where the dataset contains only one class, the entropy is  . In the coin flip example, the entropy becomes
. In the coin flip example, the entropy becomes  .
.
Similarly, we can visualize how entropy changes with different values of the positive class's fraction in binary cases using the following lines of codes:
>>> pos_fraction = np.linspace(0.00, 1.00, 1000)
>>> ent = - (pos_fraction * np.log2(pos_fraction) +
(1 - pos_fraction) * np.log2(1 - pos_fraction))
>>> plt.plot(pos_fraction, ent)
>>> plt.xlabel('Positive fraction')
>>> plt.ylabel('Entropy')
>>> plt.ylim(0, 1)
>>> plt.show()
This will give us the following output:

Given the labels of a dataset, the entropy calculation function can be implemented as follows:
>>> def entropy(labels):
... if not labels:
... return 0
... counts = np.unique(labels, return_counts=True)[1]
... fractions = counts / float(len(labels))
... return - np.sum(fractions * np.log2(fractions))
Test it out with some examples:
>>> print('{0:.4f}'.format(entropy([1, 1, 0, 1, 0])))
0.9710
>>> print('{0:.4f}'.format(entropy([1, 1, 0, 1, 0, 0])))
1.0000
>>> print('{0:.4f}'.format(entropy([1, 1, 1, 1])))
-0.0000
Now that we have fully understood entropy, we can look into how Information Gain measures how much uncertainty was reduced after splitting, which is defined as the difference in entropy before a split (parent) and after the split (children):

Entropy after a split is calculated as the weighted sum of the entropy of each child, similarly to the weighted Gini Impurity.
During the process of constructing a node at a tree, our goal is to search for the splitting point where the maximum Information Gain is obtained. As the entropy of the parent node is unchanged, we just need to measure the entropy of the resulting children due to a split. The best split is the one with the lowest entropy of its resulting children.
To understand it better, let's look at the self-driving car ad example again.
For the first option, the entropy after the split can be calculated as follows:

The second way of splitting is as follows:

For exploration, we can also calculate their Information Gain by:

According to the Information Gain = entropy-based evaluation, the second split is preferable, which is the conclusion of the Gini Impurity criterion.
In general, the choice of two metrics, Gini Impurity and Information Gain, has little effect on the performance of the trained decision tree. They both measure the weighted impurity of the children after a split. We can combine them into one function to calculate the weighted impurity:
>>> criterion_function = {'gini': gini_impurity,
'entropy': entropy}
>>> def weighted_impurity(groups, criterion='gini'):
... """
... Calculate weighted impurity of children after a split
... @param groups: list of children, and a child consists a
list of class labels
... @param criterion: metric to measure the quality of a split,
'gini' for Gini Impurity or 'entropy' for Information Gain
... @return: float, weighted impurity
... """
... total = sum(len(group) for group in groups)
... weighted_sum = 0.0
... for group in groups:
... weighted_sum += len(group) / float(total) *
criterion_function[criterion](group)
... return weighted_sum
Test it with the example we just hand-calculated, as follows:
>>> children_1 = [[1, 0, 1], [0, 1]]
>>> children_2 = [[1, 1], [0, 0, 1]]
>>> print('Entropy of #1 split:
{0:.4f}'.format(weighted_impurity(children_1, 'entropy')))
Entropy of #1 split: 0.9510
>>> print('Entropy of #2 split:
{0:.4f}'.format(weighted_impurity(children_2, 'entropy')))
Entropy of #2 split: 0.5510