
One last thing worth noting is how logistic regression algorithms deal with multiclass classification. Although we interact with the scikit-learn classifiers in multiclass cases the same way as in binary cases, it is encouraging to understand how logistic regression works in multiclass classification.
Logistic regression for more than two classes is also called multinomial logistic regression, or better known latterly as softmax regression. As we have seen in the binary case, the model is represented by one weight vector w, the probability of the target being 1 or the positive class is written as follows:

In the K class case, the model is represented by K weight vectors, w1, w2, …, wK, and the probability of the target being class k is written as follows:

Note that the term  normalizes probabilities
normalizes probabilities  (k from 1 to K) so that they total 1. The cost function in the binary case is expressed as follows:
(k from 1 to K) so that they total 1. The cost function in the binary case is expressed as follows:

Similarly, the cost function in the multiclass case becomes the following:

Here, function 1{y(i)=j} is 1 only if y(i)=j is true, otherwise 0.
With the cost function defined, we obtain the step ∆wj, for the j weight vector in the same way we derived the step ∆w in the binary case:

In a similar manner, all K weight vectors are updated in each iteration. After sufficient iterations, the learned weight vectors w1, w2, …, wK are then used to classify a new sample x' by means of the following equation:
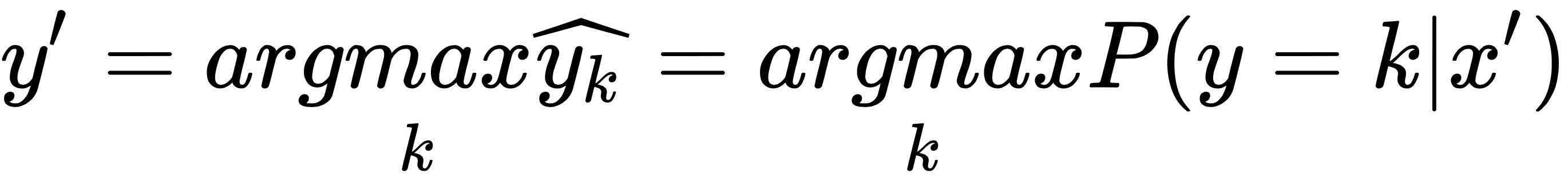
To have a better sense, we experiment on it with a classic dataset, the handwritten digits for classification:
>>> from sklearn import datasets
>>> digits = datasets.load_digits()
>>> n_samples = len(digits.images)
As the image data is stored in 8*8 matrices, we need to flatten them, as follows:
>>> X = digits.images.reshape((n_samples, -1))
>>> Y = digits.target
We then split the data as follows:
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, Y_train, Y_test = train_test_split(X, Y,
test_size=0.2, random_state=42)
We then combine grid search and cross-validation to find the optimal multiclass logistic regression model as follows:
>>> from sklearn.model_selection import GridSearchCV
>>> parameters = {'penalty': ['l2', None],
... 'alpha': [1e-07, 1e-06, 1e-05, 1e-04],
... 'eta0': [0.01, 0.1, 1, 10]}
>>> sgd_lr = SGDClassifier(loss='log', learning_rate='constant',
eta0=0.01, fit_intercept=True, n_iter=10)
>>> grid_search = GridSearchCV(sgd_lr, parameters,
n_jobs=-1, cv=3)
>>> grid_search.fit(term_docs_train, label_train)
>>> print(grid_search.best_params_)
{'alpha': 1e-07, 'eta0': 0.1, 'penalty': None}
To predict using the optimal model, we apply the following:
>>> sgd_lr_best = grid_search.best_estimator_
>>> accuracy = sgd_lr_best.score(term_docs_test, label_test)
>>> print('The accuracy on testing set is:
{0:.1f}%'.format(accuracy*100))
The accuracy on testing set is: 94.2%
It doesn't look much different from the previous example, since SGDClassifier handles multiclass internally.