
Chapter 2: Business Use Cases for Machine Learning
As a machine learning (ML) practitioner, I often need to develop a deep understanding of different businesses to have effective conversations with the business and technology leaders. This should not come as a surprise since the ultimate goal for any machine learning solution architecture (ML solution architecture) is to solve practical business problems with science and technology solutions. As such, one of the main ML solution architecture focus areas is to develop a broad understanding of different business domains, business workflows, and relevant data. Without this understanding, it would be challenging to make sense of the data and design and develop practical ML solutions for business problems.
In this chapter, you will learn about some real-world ML use cases across several industry verticals. You will develop an understanding of key business workflows and challenges in industries such as financial services and retail, and where ML technologies can help solve these challenges. The learning goal is not for you to become an expert in an industry or its ML use case and techniques, but to make you aware of real-world ML use cases in the context of business requirements and workflows. After reading this chapter, you will be able to apply similar thinking in your line of business and be able to identify ML solutions.
In this chapter, we will cover the following topics:
- ML use cases in financial services
- ML use cases in media and entertainment
- ML use cases in healthcare and life sciences
- ML use cases in manufacturing
- ML use cases in retail
- ML use case identification exercis
ML use cases in financial services
The Financial Services Industry (FSI), one of the most technologically savvy industries, is a front-runner in ML investment and adoption. Over the last several years, I have seen a wide range of ML solutions being adopted across different business functions within financial services. In capital markets, ML is being used in front, middle, and back offices to support investment decisions, trade optimization, risk management, and transaction settlement processing. In insurance, carriers are using ML to streamline underwriting, prevent fraud, and automate claim management. And banks are using ML to improve customer experience, combat fraud, and make loan approval decisions. Next, we will discuss several core business areas within financial services and how ML can be used to solve some of these business challenges.
Capital markets front office
In finance, the front office is the business area that directly generates revenue and mainly consists of customer-facing roles such as sales, traders, investment bankers, and financial advisors. Front office departments engage their customers with products and services such as Merger and Acquisition (M&A) and IPO advisory, wealth management, and the trading of financial assets such as equity (for example, stocks), fixed income (for example, bonds), commodities (for example, oil), and currency products. Now, let's look at some specific business functions in the front office area.
Sales trading and research
In sales trading, a firm's sales staff monitors investment news such as earnings reports or M&A activities and looks for investment opportunities to pitch to their institutional clients. The trading staff then execute the trades for their clients, also known as agency trading. Trading staff can also execute trades for the firm they work for, also known as prop trading. Trading staff often need to trade large quantities of securities. So, it is crucial to optimize the trading strategy to acquire the shares at favorable prices without driving up prices. Sales and trading staff are supported by research teams who focus on researching and analyzing equities and fixed income assets and provide their recommendations to sales and trading staff.
Another type of trading is algorithmic trading, where a computer is used for trading securities automatically based on predefined logic and market conditions. Some of the core challenges in sales trading and research are as follows:
- A tight timeline is faced by research analysts to deliver a research report.
- Gathering a large amount of market information to collect and analyze to develop trading strategies and make an informed trading decision.
- The markets need to be constantly monitored to adjust the trading strategy.
- Achieving the optimal trading at the preferred price without driving the market up or down. The following diagram shows the business flow of a sales trading desk and how different players interact to complete a trading activity:

Figure 2.1 – Sales, trading, and research
There are many opportunities for ML in sales trading and research. Natural language processing (NLP) models can automatically extract key entities such as people, events, organizations, and places from data sources such as SEC filing, news announcements, and earnings call transcripts. NLP can also discover relationships among discovered entities and help understand market sentiments toward a company and its stock by analyzing large amounts of news, research reports, and earning calls to inform trading decisions.
Natural language generation (NLG) can assist with narrative writing and report generation. Computer vision has been used to help identify market signals from alternative data sources such as satellite images to understand business patterns such as retail traffic. In trading, ML models can sift through large amounts of data to discover patterns such as stock similarity using data points such as company fundamentals, trading patterns, and technical indicators to inform trading strategies such as pair trading. And in trade execution, ML models can help estimate trading cost and identify optimal trading execution strategies to minimize costs and optimize profits. There is a massive amount of time series data in financial services, such as prices of different financial instruments, that can be used to discover market signals and estimate market trends. ML has been adopted for use cases such as financial time series classification and forecasting financial instruments and economic indicators.
Investment banking
When corporations, governments, and institutions need access to capital to fund business operations and growth, they engage investment bankers for capital raising (selling of stocks or bonds) services. The following diagram shows the relationship between investment bankers and investors. In addition to capital raising, the investment banking department also engages in M&A advisory to assist their clients in negotiating and structuring merger and acquisition deals from start to finish. Investment banking staff take on many activities such as financial modeling, business valuation, pitch book generation, and transaction document preparation to complete and execute an investment banking deal. They are also responsible for general relationship management and business development management activities.
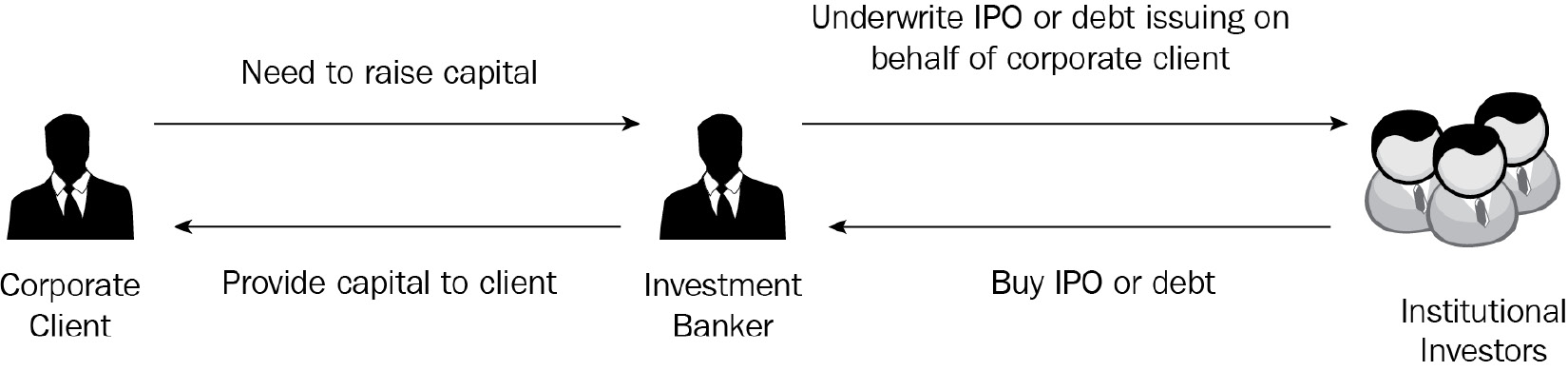
Figure 2.2 – Investment banking workflow
One of the main challenges in an investment banking workflow is searching for and analyzing large amounts of structured (financial statements) and unstructured data (annual reports, filing, news, and internal documents). Typical junior bankers spend many hours searching for documents that might contain useful information and manually extract information from the documents to prepare pitch books or perform financial modeling. Investment banks have been experimenting and adopting ML to help with this labor-intensive process. They are using NLP to extract structured tabular data automatically from large amounts of PDF documents. Specifically, named entity recognition (NER) techniques can help with automatic entity extraction from documents. ML-based reading comprehension technology can assist bankers in finding relevant information from large volumes of text quickly and accurately using natural human questions instead of simple text string matching. Documents can also be automatically tagged with metadata and classified using the ML technique to improve document management and information retrievals. Other common challenges in the investment banking workflow that can be solved with ML include linking company identifiers from different data sources and the name resolution of different variations of company names.
Wealth management
In the wealth management (WM) business, WM firms advise their clients with wealth planning and structuring services to grow and preserve their clients' wealth. These institutions differentiate themselves from more investment advisory-focused brokerage firms in that WM firms bring together tax planning, wealth preserving, and estate planning to meet their client's more complex financial planning goals. WM firms engage clients to understand their life goals and spending patterns and design customized financial planning solutions for their clients. Some of the challenges that are faced by WM firms are as follows:
- WM clients are demanding more holistic and personalized financial planning strategies for their WM needs.
- WM clients are becoming increasingly tech-savvy, and many are demanding new channels of engagement in addition to direct client-advisor interactions.
- WM advisors need to cover increasingly more clients while maintaining the same personalized services and planning.
To offer more personalized services, WM firms are adopting ML-based solutions to understand client behaviors and needs. For example, WM firms use their clients' transaction history, portfolio details, conversation logs, investment preferences, and life goals to build ML models that can make personalized recommendations on investment products and services. These models recommend the next best action by combining both the clients' propensity to take an offer and other business metrics such as the expected medium- or long-term value of the action.
The following diagram shows the concept of the Next Best Action method:

Figure 2.3 – Next Best Action recommendation
To improve client engagement and experience, WM firms build virtual assistants that can provide personalized answers to clients' inquiries without human intervention and automatically fulfill client demands. WM firms are equipping Financial Advisors (FAs) with AI-based solutions that can automate tasks such as transcribing audio conversations to text for text analysis. ML models are also being used to help assess clients' sentiment and alert FAs of potential customer churn.
Capital markets back office operations
The back office is the part of financial services companies that handles non-client facing and support activities. Their main functions include trade settlement and clearance, record keeping, regulatory compliance, accounting, and technology services. It is one of the areas for early ML adoption due to the financial benefits and cost-saving it could bring from ML-based automation and its improved ability to meet regulatory (for example, anti-money laundering) and internal controls requirements (for example, trade surveillance). Next, let's take a look at some back office business processes and where ML can be applied.
Net Asset Value review
Financial services companies that offer Mutual Funds and ETFs need to accurately reflect the values of the funds for trading and reporting purposes. They use a Net Asset Value (NAV) calculation, which is the value of an entity's assets minus its liability, to represent the value of the fund. NAV is the price at which an investor can buy and sell the fund. Every day, after the market closes, fund administrators must calculate the NAV price with 100% accuracy, and the process consists of five core steps:
- Stock reconciliation
- Reflection of any corporate actions
- Pricing the instrument
- Booking, calculating, and reconciling fees and interest accruals, as well as cash reconciliation
- NAV/price validation
The following diagram shows the core steps in the NAV review process:

Figure 2.4 – Net Asset Value review process
Step 5 is the most vital because if it is done incorrectly, the fund administrator could be liable, which can result in monetary compensations to investors. Traditional methods use fixed thresholds to flag exceptions, such as incorrectly valued stock or corporation actions not being correctly processed for analysts for review, which could result in large volumes of false positives and wasted time. Large volumes of data need to be used for investigation and reviews such as the prices of the instruments, fees and interest, assets (for example, equities, bonds, and futures), cash positions, and corporate actions data.
The main objective of the NAV validation step is to identify pricing exceptions, which can be treated as an anomaly detection problem. ML-based anomaly detection solutions have been adopted to identify potential pricing irregularities and flag these irregularities for further human investigation. The ML approach has proven to significantly reduce false positives and save significant amounts of time for human reviewers.
Post-trade settlement failure prediction
After the front office executes a trade, several post-trade processes are involved to complete the trade, such as settlement and clearance. Post-trade settlement is the process where buyers and sellers compare trade details, approve the transaction, change records of ownership and arrange for securities and cash to be transferred. Trade settlements are handled automatically using straight-through processing. However, some trade settlements fail due to various reasons, such as sellers failing to deliver securities, and brokers will need to use their reserves to complete the transaction. To ensure the stockpile is set at the correct level so that valuable capital can be used elsewhere, predicting settlement failure is critical.
The following diagram shows the workflow for the trade where buyers and sellers buy and sell their securities at exchange through their respective brokerage firms:
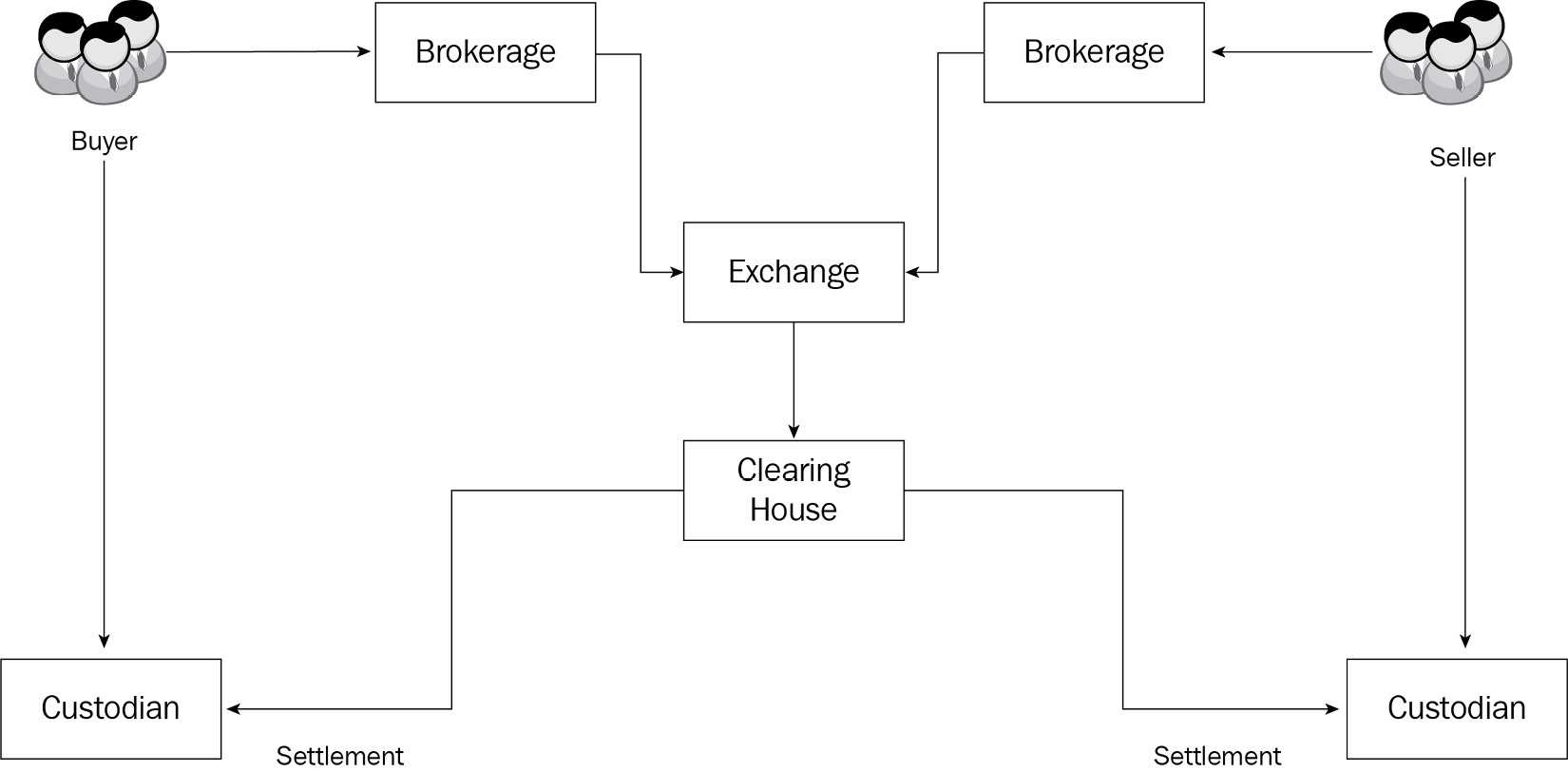
Figure 2.5 – Trading workflow
After the trade is executed, a clearing house such as DTCC would handle the clearance and settlement of the trades with the respective custodians for the buyer and sellers.
To ensure the right amount of stockpile reserve is maintained to reduce capital expenditure cost and optimize the buyer and sellers' transaction rates, brokerage houses have been using ML models to predict trade failure early in the process. This allows the broker to take preventive or corrective actions.
Risk management and fraud
Risk management and fraud are part of the back office operations of financial services firms, including investment banks and commercial banks, and they are one of the top areas for ML adoption in financial services due to their large financial and regulatory impact.
There are many kinds of fraud and risk management use cases for ML, such as anti-money laundering, trade surveillance, credit card transaction fraud, and insurance claim fraud. Let's take a look at a few of them.
Anti-money laundering
Anti-money laundering (AML) is a set of laws and regulations that have been established to prevent criminals from legitimizing illegally obtained funds legally through complex financial transactions. Under these laws and regulations, financial institutions are required to help detect activities that aid illegal money laundering. Financial services companies devote substantial amounts of financial, technical, and people resources to combat AML activities. Traditionally, companies have been using rule-based systems to detect AML activities. However, rule-based systems usually have a limited view as it is challenging to include a large number of features to be evaluated in a rule-based system. Also, it is hard to keep the rules up to date with new changes; a rule-based solution can only detect well-known frauds that have happened in the past.
Machine learning-based solutions have been used in multiple areas of AML, such as the following:
- Network link analysis to reveal the complex social and business relationships among different entities and jurisdictions.
- Clustering analysis to find similar and dissimilar entities to spot trends in criminal activity patterns.
- Deep learning-based predictive analytics to identify criminal activity.
- NLP to gather as much information as possible for the vast number of entities from unstructured data sources.
The following diagram shows the data flow for AML analysis, the reporting requirements for regulators, and internal risk management and audit functions:
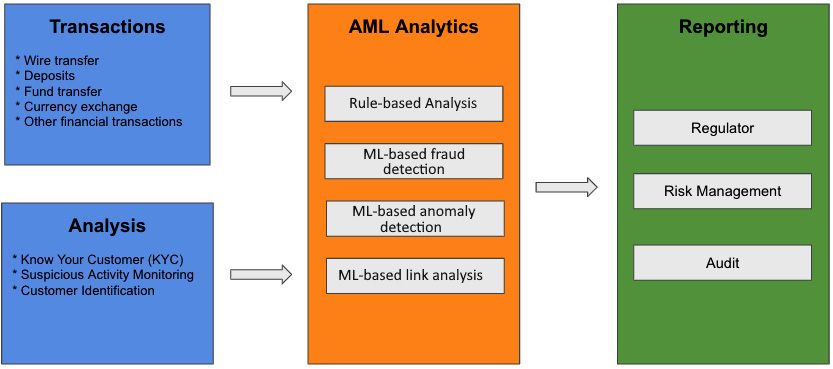
Figure 2.6 – Anti-money laundering detection flow
An AML platform takes data from many different sources, including transactions data and internal analysis data such as Know Your Customer (KYC) and Suspicious Activity data. This data is processed and fed into different rule and ML-based analytics engines to monitor fraudulent activities. The findings can be sent to internal risk management and auditing, as well as regulators.
Trade surveillance
Traders at financial firms are intermediaries who buy and sell securities and other financial instruments on behalf of their clients. They execute orders and advise clients on entering and existing financial positions. Trade surveillance is the process of identifying and investigating potential market abuse by traders or financial organizations. Examples of market abuse include market manipulation, such as the dissemination of false and misleading information, manipulating trading volumes through large amounts of wash trading, and insider trading through the disclosure of non-public information. Financial institutions are required to comply with market abuse regulations such as Market Abuse Regulation (MAR), Markets in Financial Instruments Directive II (MiFID II), and internal compliance to protect themselves, such as damage to their reputations and financial performance. The challenges in enforcing trade surveillance include the lack of a proactive approach to abuse detection such as large noise/signal ratios resulting in many false positives, which increases the cost of case processing and investigations. One typical approach to abuse detection is to build complex rule-based systems with different fixed thresholds for decision making.
There are multiple ways to frame trade surveillance problems as ML problems, including the following:
- Framing the abuse detection of activities as a classification problem to replace rule-based systems
- Framing data extraction information such as entities (for example, restricted stocks) from unstructured data sources (for example, emails and chats) as NLP entity extraction problems
- Transforming entity relationship analysis (for example, trader-trader collaborations in market abuse) as machine learning-based network analysis problems
- Treating abusive behaviors as anomalies and using unsupervised ML techniques for anomaly detection
Many different datasets can be useful for building ML models for trade surveillance such as P and L information, positions, order book details, e-communications, linkage information among traders and their trades, market data, trading history, and details such as counterparty details, trade price, order type, and exchanges.
The following diagram shows the typical data flow and business workflow for trade surveillance management within a financial services company:
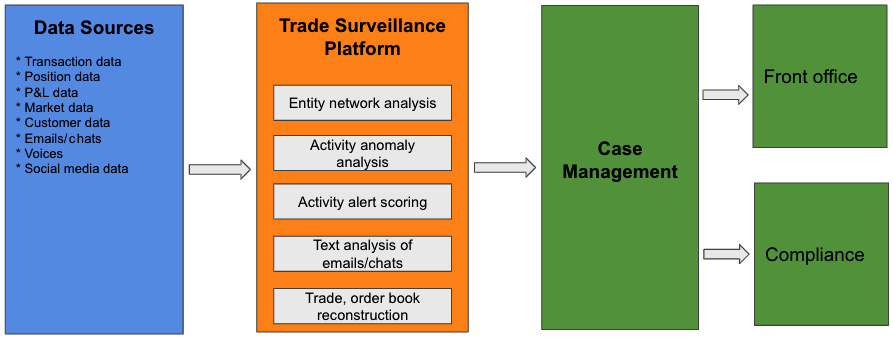
Figure 2.7 – Trade surveillance workflow
A trade surveillance system monitors many different data sources, and it feeds its findings to both the front office and compliance department for further investigation and enforcement.
Credit risk
When banks issue loans to businesses and individuals, there is the potential risk that the borrower might not be able to pay the required payment. As a result, banks suffer financial loss in both principal and interest from financial activities such as making loans for mortgages and credit cards. To minimize this default risk, banks go through credit risk modeling to assess the risk of making a loan by focusing on two main aspects:
- The probability that the borrower will default on the loan
- The impact on the lender's financial situation
Traditional human-based reviews of loan applications are slow and error-prone, resulting in high loan processing costs and lost opportunities due to incorrect and slow loan approval processing.
The following diagram shows a typical business workflow for credit risk assessment and its various decision points within the process:

Figure 2.8 – Credit risk approval workflow
To reduce credit risk associated with loans, many banks have widely adopted ML techniques to predict loan default and associated risk scores more accurately and quickly. The credit risk management modeling process requires the collection of financial information from borrowers, such as income, cash flow, debt, assets and collaterals, the utilization of credits, and other information such as loan type and loan payment behaviors. Since this process involves large amounts of information being extracted from unstructured data sources (financial statements) and then analyzed, machine learning-based solutions such as Optical Character Recognition (OCR) and NLP information extraction and understanding have been widely adopted for automated intelligence document processing.
Insurance
The insurance industry consists of several sub-sectors based on the insurance product types offered by the different insurance companies, such as accident and health insurance, property and casualty insurance, and life insurance. In addition to the insurance companies that provide coverage through insurance policies, insurance technology providers are also key players in the insurance industry.
There are two main business processes in most insurance companies: the insurance underwriting process and the insurance claim management process.
Insurance underwriting
Insurance underwriting is the process of assessing the risk of providing insurance coverage for people and assets. Through this process, an insurance company establishes the insurance premium for the risks that it is willing to take on. Insurance companies normally use insurance software and actuarial data to assess the magnitude of the risk. The underwriting processes vary, depending on the insurance products. For example, the steps for property insurance are normally as follows:
- The customer files an insurance application through an agent or insurance company directly.
- The underwriter at the insurance company assesses the application by considering different factors such as the applicant's loss and insurance history, actuarial factors to determine whether the insurance company should take on the risk, and what the price and premium should be for the risk. Then, they make an additional adjustment to the policy, such as coverage amount and deductibles.
- If the application is accepted, then an insurance policy is issued.
During the underwriting process, an underwriter has to collect and review a large amount of data, estimate the risk of a claim based on the data and underwriter's personal experience, and come up with a premium that can be justified. Human underwriters would only be able to review a subset of data and could introduce personal bias into the decision-making process. ML models would be able to act on a lot more data to make more accurate data-driven decisions on risk factors such as the probability of claims and the claim's outcome, and it would make decisions much faster than what a human underwriter can do. To come up with the premium for the policy, an underwriter would spend a lot of time assessing the different risk factors. ML models can help generate recommended premiums by using large amounts of historical data and risk factors.
Insurance claim management
Insurance claim management is the process where an insurance company assesses the insured's claims and reimburses the person who's insured for the damage and loss that they incurred according to the agreement in the policy. The claim processes for the different insurances are different. The steps for a property insurance claim are normally as follows:
- The person who is insured files a claim and supplies evidence for the claim, such as pictures of the damage and a police report for automobiles.
- The insurance company assigns an adjuster to assess the damage.
- The adjuster determines the damage, performs fraud assessment, and sends the claim for payment approval.
Some of the main challenges that are faced in the insurance claim management process are as follows:
- Time-consuming manual effort is needed for the damaged/lost item inventory process and data entry.
- The need for speedy claim damage assessment and adjustment.
- Insurance fraud.
Insurance companies collect a lot of data during the insurance claim process, such as property details, items damage data and photos, the insurance policy, the claims history, and historical fraud data.

Figure 2.9 – Insurance claim management workflow
ML can automate manual processes such as extracting data from documents and identifying insured objects from pictures to reduce manual effort in data collection. In damage assessment, ML can help assess different damages and the estimated cost for repair and replacement to speed up claim processing. In the fight for insurance fraud, ML can help detect exceptions in insurance claims and predict potential fraud for further investigation.
ML use cases in media and entertainment
The media and entertainment (M&E) industry consists of businesses that engage in the production and distribution of films, television, streaming content, music, games, and publishing. The current M&E landscape has been shaped by the increasing adoption of streaming and over-the-top (OTT) content delivery versus traditional broadcasting. M&E customers, faced with ever-increasing media content choices, are shifting their consumption habits and demanding more personalized and enhanced experiences across different devices, anytime, anywhere. M&E companies are also faced with fierce competition in the industry, and to stay competitive, M&E companies need to identify new monetization channels, improve user experience, and improve operational efficiency. The following diagram shows the main steps in the media production and distribution workflow:

Figure 2.10 – Media production and distribution workflow
Over the last several years, I have seen M&E companies increasingly adopting ML in the different stages of the media life cycle, such as content generation and content distribution, to improve efficiency and spur business growth. For example, ML has been used to enable better content management and search, new content development, monetization optimization, and compliance and quality control.
Content development and production
In the early planning phase of the film production life cycle, content producers need to make decisions on the next content based on factors such as estimated performance, revenue, and profitability. Filmmakers adopt ML-based predictive analytics models to help predict the popularity and profitability of new ideas by analyzing factors such as casts, scripts, the past performance of different films, and target audience. This allows producers to quickly eliminate ideas with small market potential to focus their effort on developing more promising and profitable ideas.
To support personalized content viewing needs, content producers often segment long video content into smaller micro-segments around certain events, scenes, or actors, so that they can be distributed individually or repackaged into something more personalized to individual preferences. This ML-based approach can be used for creating video clips by detecting elements such as scenes, actors, and events for the different target audiences with different tastes and preferences.
Content management and discovery
M&E companies with large digital content assets need to curate their content to create new content for new monetization opportunities. To do that, these companies need rich metadata for the digital assets to enable different content to be searched and discovered. Consumers also need to search for content easily and accurately for different usages, such as for personal entertainment or research. Without metadata tagging or the ability to understand the content, it is quite challenging to discover relevant content. Many companies hire humans to review and tag this content with meaningful metadata for discovery as part of the digital asset management workflow. Since manual tagging is very costly and time-consuming, most content is not tagged with sufficient metadata to support effective content management and discovery.
Computer vision models can automatically tag image and video content for items such as objects, genres, people, places, or themes. ML models can also interpret the meaning of textual content such as topics, sentiment, entities, and sometimes video. Audio content also needs to be transcribed into text for additional text analysis, such as summarization. Machine learning-based text summarization can help you summarize long text as part of the content metadata generation. The following diagram shows where ML-based analysis solutions fit into the media asset management flow:

Figure 2.11 – ML-based media analysis workflow
Machine learning-based content processing is being increasingly adopted by M&E companies to streamline media asset management workflows, and it has resulted in meaningful cost savings and enhanced content discovery.
Content distribution and customer engagement
Nowadays, media content such as films and music are increasingly being distributed through digital video on demand (VOD) and live streaming on different devices, bypassing traditional media such as DVDs and broadcasting. Consumers nowadays have a lot of options when it comes to media provider choices. Customer acquisition and retention are also a challenge for many media providers. M&E companies are increasingly focusing on customer needs and preferences to improve user experience and increase retention. They have turned to highly personalized product features and content to keep users engaged and stay on the platform. One effective way for highly personalized engagement is the content recommendation engine, and this has become the primary method to get consumers to consume content and keep them engaged. Content delivery platform providers use viewing and engagement behavior data and other profile data to train highly personalized recommendation ML models. And they use these recommendation models to target individuals based on their preference and viewing pattern, along with a combination of diverse media content, including videos, music, and games.
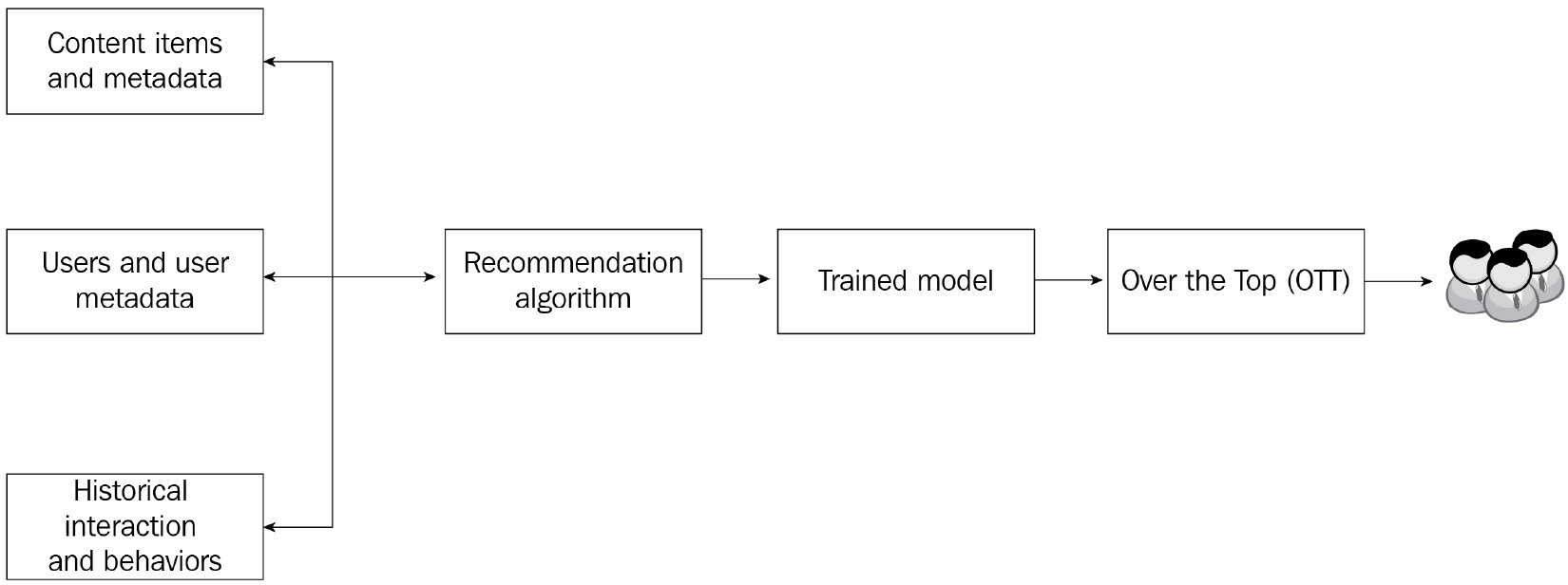
Figure 2.12 – Recommendation ML model training
Recommendation technologies have been around for many years and have improved greatly over the years. Nowadays, recommendation engines can learn patterns using multiple data inputs, such as those historical interactions users have with content and watching behaviors, different sequential patterns of the interactions, and the metadata associated with the users and content. Modern recommendation engines can also learn from the user's real-time behaviors/decisions and make dynamic recommendation decisions based on real-time user behaviors.
ML use cases in healthcare and life sciences
Healthcare and life science is one of the largest and most complex industries. Within this industry, there are several sectors, including the following:
- Drugs: These are the drug manufacturers, such as biotechnology firms, pharmaceutical firms, and the makers of genetics drugs.
- Medical equipment: These are the companies that manufacture both standard products as well as hi-tech equipment.
- Managed healthcare: These are the companies that provide health insurance policies.
- Health facilities: These are the hospitals, clinics, and labs.
- Government agencies such as CDC and FDA.
The industry has adopted ML for a wide range of use cases, such as medical diagnosis and imaging, drug discovery, medical data analysis and management, and disease prediction and treatment.
Medical imaging analysis
Medical imaging is the process and technique of creating a visual representation of the human body for medical analysis. Medical professionals, such as radiologists and pathologists, use medical imaging to assist with medical condition assessments and prescribe medical treatments. However, the industry is facing a shortage of qualified medical professionals, and sometimes, these professionals have to spend a lot of time reviewing a large number of medical images to determine whether a patient has a medical condition.
One ML-based solution is to treat medical imaging analysis as a computer vision object detection problem. In the case of cancer cell detection, cancerous tissues can be identified and labeled in the existing medical images as training data for computer vision algorithms. Once the model has been trained, and its accuracy has been validated to be acceptable, it can be used to automate the screening of a large number of X-ray images to highlight the ones that are important for the pathologists to review. The following diagram shows the process of training a computer vision model using labeled image data:
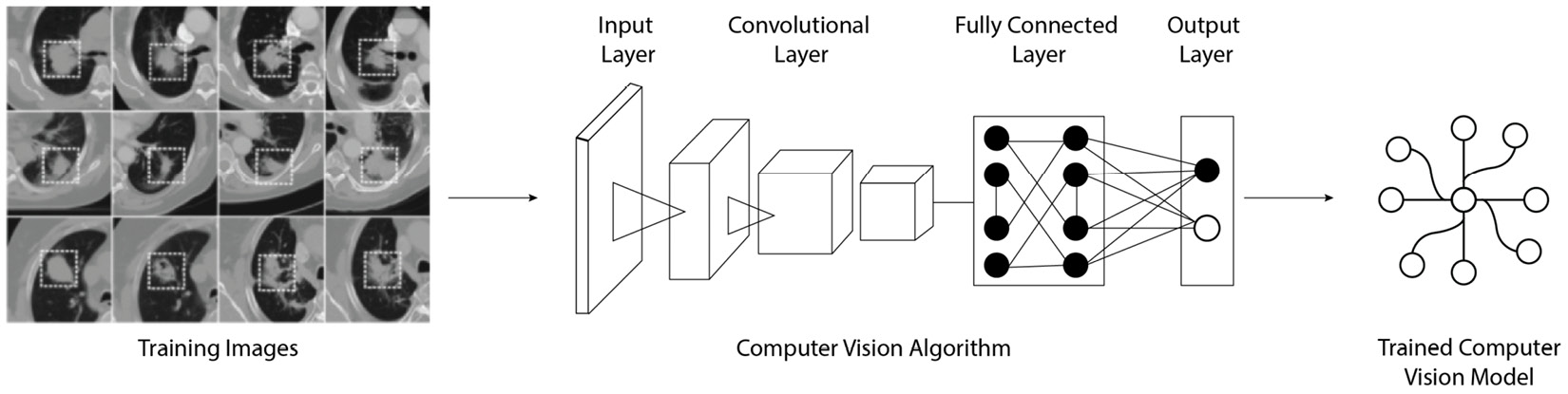
Figure 2.13 – Using computer vision for cancer detection
To enable more accurate prediction, image data can be combined with non-image data, such as clinical diagnosis data, to train a joint model to make the prediction.
Drug discovery
Drug discovery and development is a long, complex, and costly process. It consists of key stages such as the following:
- Discovery and development, where the goal is to find a lead compound targeting a particular protein or gene as a drug candidate through basic research
- Preclinical research, where the goal is to determine the efficacy and safety of the drug
- Clinical development, which involves clinical trials and volunteer studies to fine-tune the drug
- FDA review, where the drug is reviewed holistically to either approve or reject it
- Post-market monitoring, to ensure the safety of the drug
During the drug discovery phase, the main goal is to develop a molecule compound that can have a positive biological effect on a protein target to treat a disease without negative effects such as toxicity issues. One area that ML can help with is the process of compound design, where we can model the molecule compound as a sequence vector and use the advancements in natural language processing to learn about these patterns. We can do this using the existing molecule compounds with a variety of molecular structures. Once the model has been trained, it can be used to generate new compound suggestions for discovery purposes instead of having these molecules be created by humans manually to save time. The suggested compounds can be tested and validated with a target protein for interaction. The following diagram shows the flow of converting molecule compounds into SMILES representations and training a model that generates new compound sequences:

Figure 2.14 – Molecule compound generation
In addition to compound design, ML-based approaches have also been adopted in other stages of the drug discovery life cycle, such as identifying cohorts for clinical trials.
Healthcare data management
Large amounts of patient healthcare data is collected and generated in the healthcare industry every day. It comes in various formats, such as insurance claim data, doctor's handwritten notes, recorded medical conversations, and images such as X-rays. Medical companies need to extract useful information from these data sources to develop comprehensive views about patients or to support medical coding for medical billing processes. A significant amount of manual processing, often by people with health domain expertise, goes into organizing this data and extracting information from these data sources. This process is both expensive and error-prone. As a result, large amounts of patient healthcare data remain in its original form and is not comprehensively utilized.
In recent years, deep learning-based solutions have been adopted to help with health data management, especially with medical information extraction from unstructured data such as doctor's notes, recorded medical conversations, and medical images. These deep learning solutions can not only extract text from handwritten notes, images, and audio files, but they can also identify medical terms and conditions, drug names, prescription instructions, and the relationship among those different entities and terms. The following diagram shows the flow of extracting information from unstructured data sources using ML and using the results for different tasks, such as medical coding and clinical decision support:

Figure 2.15 – Medical data management
Almost 80% of healthcare data is unstructured data, and advances in ML are helping to unlock useful insights that are otherwise hidden in text and images.
ML use cases in manufacturing
Manufacturing is an industry sector that produces tangible finished products. It includes many sub-sectors such as consumer goods, electronics goods, industrial equipment, automobiles, furniture, building materials, sporting goods, clothing, and toys. There are multiple stages in a typical product manufacturing life cycle, including product design, prototyping, manufacturing and assembling, and post-manufacturing service and support. The following diagram shows the typical business functions and flow in the manufacturing sector:
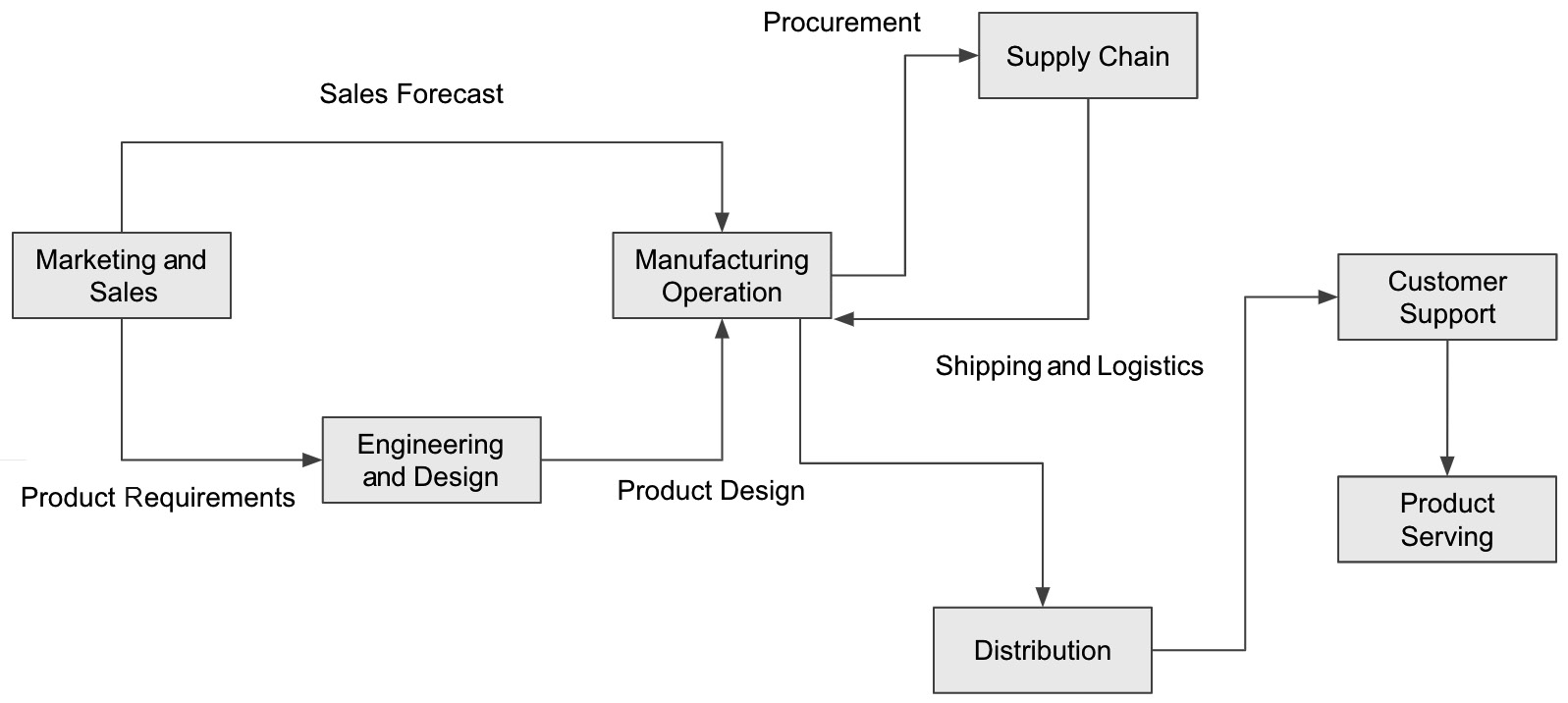
Figure 2.16 – Manufacturing business process flow
AI and ML have played an essential role in the manufacturing process, such as sales forecasting, predictive machine maintenance, quality control and robotic automation for manufacturing quality and yield, and process and supply chain optimization to improve overall operational efficiency.
Engineering and product design
Product design is the process where a product designer combines their creative power, the practical needs of market/consumers, and constraints to develop a product that will be successful once it has been launched. Designers often need to create many different variations of a new product concept during the design phase that will meet different needs and constraints. For example, in the apparel industry, fashion designers would analyze the needs and preferences of customers, such as color, texture, and styles, and develop these designs and generate the graphics for the apparel.
The manufacturing industry has been leveraging generative design ML technology to assist with new product concept design. For example, ML techniques such as Generative Adversarial Networks (GANs) have been used to generate new graphics for logo design and 3D industrial components such as machinery gears. The following diagram shows the basic concept of a GAN, where a generator model is trained to create fake images that can fool a discriminator. After the generator becomes good enough to fool the discriminator, it can be used to generate new images for items such as clothing.

Figure 2.17 – GAN concept for generating realistic fake images
In addition to generative design, ML techniques have also been used to analyze market requirements and estimate new products' market potentials.
Manufacturing operations – product quality and yield
Quality control is an important step in the manufacturing process to ensure a product's quality before it is shipped. Many manufactures rely on humans to inspect the manufactured products, which is highly time-consuming and costly. For example, factory workers would visually inspect the products for surface scratches, missing parts, color differences, and deformations.
Computer vision-based technology has been used to automate many aspects of the manufacturing lines' quality control process. For example, a computer object detection model can be trained using labeled image data to help identify the objects to be inspected from the captured images, and then a computer vision-based defective model can be trained using images labeled with good parts and bad parts to help inspect detected objects and classify them as either defective or not defective.
Manufacturing operations – machine maintenance
Industrial manufacturing equipment and machinery need regular maintenance to ensure smooth operations. Any unplanned outages due to equipment failures would not only result in high repair or replacement costs, but they would also disrupt production schedules, impacting delivering schedules to downstream tasks or customers. While following a regular maintenance schedule would alleviate this problem to a certain extent, having the ability to forecast potential problems in advance would further reduce the risk of any unforeseen failures.
Machine learning-based predictive maintenance analytics help reduce the risk of potential failures by predicting whether a piece of equipment will likely fail within a time window using a variety of data, such as telemetry data collected by Internet of Things (IoT) sensors. The maintenance crew can use the prediction results and take proactive maintenance actions to prevent disruptive failure.
ML use cases in retail
Retail businesses sell consumer products directly to customers through retail stores or e-commerce channels. They get supplies through wholesale distributors or from manufacturers directly. The industry has been going through some significant transformations. While e-commerce is growing much faster than traditional retail business, traditional brick-and-mortar stores are also transforming in-store shopping experiences to stay competitive. Retailers are looking for new ways to improve the overall shopping experience through both online and physical channels. New trends such as social commerce, augmented reality, virtual assistant shopping, smart stores, and 1:1 personalization are becoming some of the key differentiators among retail businesses.
AI and ML are a key driving force behind the retail industry's transformation, from inventory optimization and demand forecasting to highly personalized and immersive shopping experiences such as personalized product recommendations, virtual reality shopping, and cashier-less store shopping. In addition, AI and ML are also helping retailers fight crimes such as fraud and shoplifting.
Product search and discovery
When consumers shop online and need to search for a particular product, they rely on search engines to find the product on various e-commerce websites. This greatly simplifies the shopping experience when you know the name or certain attributes of the products to search for. However, sometimes, you only have a picture of the product and do not know what correct terms to search for.
Deep learning-powered visual search is a technology that can help you quickly identify and return similar-looking products from a picture of an item. Visual search technology works by creating a digital representation (also known as encoding/embedding) of the item's pictures and stores them in a high-performance item index. When a shopper needs to find a similar-looking item using a picture, the new picture is encoded into a digital representation, and the digital representation is searched against the item index using efficient distance-based comparison. The items that are the closest to the target items are returned. The following diagram shows an architecture for building an ML-based image search capability:

Figure 2.18 – Image search architecture
Visual search-based recommendations have been adopted by many large e-commerce sites such as Amazon.com to enhance the shopping experience.
Target marketing
Retailers use different marketing campaigns and advertising techniques, such as direct marketing email or digital advertisements, to target prospective shoppers with incentives or discounts based on the shopper's segments. These campaigns' effectiveness heavily depends on the right customer targeting to achieve a high conversion rate, all while reducing the campaign's cost or advertising and generating less end user disturbance.
Segmentation is one traditional way to understand the different customer segments to help improve marketing campaigns' effectiveness. There are different ways to do segmentations with machine learning, such as unsupervised clustering of customers based on data such as basic demographic data. This allows you to group customers into several segments and create unique marketing campaigns for each segment.
A more effective target marketing approach is to use highly personalized user-centric marketing campaigns. They work by creating accurate individual profiles using large amounts of individual behavior data such as historical transaction data, responses data to historical campaigns, and alternative textual data such as social media data. Highly personalized campaigns with customized marketing messages can be generated using these personal profiles for a higher conversion rate. The ML approach to user-centric target marketing predicts the conversion rate, such as the click-through rate (CTR), for different users and sends ads to users with a high conversion rate. This can be a classification or regression problem by learning the relationship between the user features and the probability of conversion.
Contextual advertising is another way to reach the target audience by placing advertisements such as display ads or video ads on web pages that match the advertisement's content. An example of contextual advertising is to place cooking product advertisements on cooking recipe sites. Because the ads are highly relevant to the content, they will likely resonate with the websites' readers and result in a much higher click-through rate. ML can help with detecting ads from a context so that the ads are placed correctly. For example, computer vision models can detect objects, people, and themes in video ads to extract contextual information and match them to the website's content.
Sentiment analysis
Retail businesses often need to understand the perception of their brand from their consumers' point of view. Positive and negative sentiments toward a retailer could greatly improve or damage a retail business. As more online platforms are becoming available, it is easier than ever for consumers to voice their feelings toward a product or business from their real-life experiences. Retail businesses are adopting different techniques to assess their customer's feelings and emotions toward their product and brand by analyzing feedback solicited from their shoppers or monitoring and analyzing their social media channels. Effective sentiment analysis can help identify areas for improvement, such as operational and product improvement, as well as for gathering intelligence in relation to potentially malicious brand reputation attacks.
Sentiment analysis is mainly a text classification problem that uses labeled text data (for example, a product review is labeled either positive or negative). Many different ML classifier algorithms, including deep learning-based algorithms, can be used to train a model to detect sentiment in a piece of text.
Product demand forecasting
Retail businesses need to do inventory planning and demand forecasting to optimize retail revenue and manage inventory costs. This helps them avoid out-of-stock situations while reducing the cost of stocking inventory. Traditionally, retailers have been using different demand forecasting techniques such as buyer surveys, collective opinions from multiple inputs, projections based on past demands, or expert opinions.
Statistical and ML techniques such as regression analysis and deep learning-based approaches can help produce more accurate and data-driven demand forecasting. In addition to using historical demand and sales data to model future forecasts, deep learning-based algorithms can also incorporate other related data such as price, holidays, special events, and product attributes to train an ML model that's capable of producing more accurate forecasts. The following diagram shows the concept of building a deep learning model using multiple data sources to generate forecasting models:

Figure 2.19 – Deep learning-based forecasting model
ML-based forecasting models can generate point forecasts (a number) of probabilistic forecasts (a forecast with a confidence score). Many retail businesses use ML to generate baseline forecasts, and professional forecasters review them and make adjustments based on human expertise and other factors.
ML use case identification exercise
In this exercise, you are going to apply what you have learned in this chapter to your line of business. The goal is to go through a thinking process to business problems that can potentially be solved with machine learning:
- Think about a business operation in your line of business. Create a workflow of the operation and identify any known issues, such as a lack of automation, human errors, and long processing cycles in the workflow.
- List the business impact of these issues in terms of lost revenue, increased cost, poor customer and employee satisfaction, and potential regulatory and compliance risk exposure. Try to quantify the business impact as much as possible.
- Pick one or two problems with the most significant impact if the problems can be solved. Think about ML approaches (supervised machine learning, unsupervised machine learning, or reinforcement machine learning) to solve the problem.
- List the data that could be helpful for building ML solutions.
- Write a proposal for your idea that includes the problem statement, identified opportunities and business value, data availability, and implementation and adoption challenges.
- List the business and technology stakeholders that you will need to work with to bring your idea to life.
Summary
In this chapter, we covered several ML use cases across multiple industries. You now should have a basic understanding of some top industries and some of the core business workflows in those industries. You have learned about some of the relevant use cases, the business impact that those use cases have, and the ML approaches for solving them.
The next chapter will cover how machines learn and some of the most commonly used ML algorithms.