
Chapter 8: Harnessing Automation Opportunities
The cybersecurity skills gap is real, and it is growing. Based on demographics, it is likely to continue to get worse. Unless the near future holds a historical influx of new security professionals, automation will become increasingly necessary to meet the information security challenges we will face. Further, attackers have access to the same technology as us, and if they make better use of emerging technologies than we do, they will have an advantage. Capabilities such as machine learning and Artificial Intelligence (AI) are already in use by bad actors to evade countermeasures and learn how to emulate the behavior of legitimate users. However, most organizations rely solely upon human analysis to review and classify potential incidents. As a result, the mean time to detect threats is months to years on average in most organizations. Modern technology enables large-scale data transfers in seconds and minutes. If there is this gap between the ability to move large volumes of data and the ability for our teams to respond, data breaches involving large quantities of data will remain common.
Human beings are not machines. They cannot work around the clock, and they generally need time to perform their functions. Machines are not humans. They lack the ability to understand the nuances of human emotions and behaviors and rely upon patterns to make decisions. However, combining the response time of a machine with the emotional context of a human offers an opportunity to build programs that are both responsive and nuanced. We will not automate the whole of the information security field in the foreseeable future, but machine-augmented teams are likely to become the standard for security programs around the world.
To meet current challenges in the short term, most organizations will need to either automate significant portions of their operations or turn to a Managed Security Services Provider (MSSP), who is likely leveraging automation to maximize efficiency and profitability. In either case, security programs that do not leverage automation effectively have little chance of protecting their organizations from modern and evolving threats. This is due to both the shortcomings of currently available technologies in the AI space and the shortages of qualified security practitioners in the talent marketplace.
In this chapter, we will talk about the role of automation in security programs today, and opportunities to leverage automation technology in new ways as we approach the future. We will discuss the role of automation using the following sections:
- Defining automation opportunities
- Gathering data and applying context
- Testing the systems
- How attackers leverage automation
Defining automation opportunities
Automation offers the potential to lower operational costs while limiting human error and improving response times. However, not everything can be automated, and many organizations lack the processes necessary to identify automation opportunities. Too often, teams focus on solving large, complex problems rather than automating the mundane, repetitive tasks that are not only easier to automate, but also the most taxing on skilled resources. Human beings are very good at understanding context and behaviors. We are not good at consistently performing repetitive tasks with minimal errors and maximum efficiency. Machines are very good at recognizing patterns and performing repetitive tasks with minimal errors. Not everything a human being does is easily automated, but there are tasks that machines are better at than humans. These are ideal automation opportunities. The challenge with automation is finding the right problems to solve with the technology.
Example Case Study: Public Sector Automation
The public sector is rarely held up as a model of cost efficiency. However, when it comes to the average cost of a data breach, according to the 2020 Ponemon Cost of a Data Breach study, the public sector had the lowest costs compared to other industries at $1.08 million per breach. That is compared to an average across all industries of $3.86 million, and the highest average cost belonging to the healthcare industry at nearly $10 million per breach. Why is the public sector able to control costs so much better than the private sector? Many factors could contribute but it is widely believed that automation plays a significant role.
According to recent research, the public sector is adopting automation faster than any other industry and is using automation and orchestration to help correlate data points across multiple systems and agencies. Automation is not being used to lower the number of staff, but to allow existing staff to focus on other priorities and vulnerabilities. This means that not only are agencies able to respond more quickly to attacks but they are also able to build countermeasures across a larger percentage of their attack surface.
Finding tasks that can be automated and focusing resources on tasks that cannot are key to building an effective security practice in the modern world. There simply aren't enough people and resources to continue to throw people alone at the problem.
Building an automation program is like building other types of information security programs. First, the program must define what it intends to accomplish and what problem it intends to solve. Then, it needs to define who is responsible for solving the problem and what role each individual or group will play. Finally, it must clearly define the processes necessary to achieve success. In the case of finding automation opportunities, this requires the discipline to identify automation opportunities and the resources to act on those opportunities (Ponemon Institute, 2020), (Kanowitz, 2020).
There is a long-term opportunity for automation to perform very complex tasks that humans are unable to perform efficiently or effectively. However, there is also an immediate-term opportunity to replace low-skilled human labor with technology that exists today.
Before we do so, we should have a brief discussion about financial concepts as they relate to automation.
A brief introduction to finance
It is my opinion that a basic education in business concepts is critical to success in information security. One of the most important disciplines is finance. While it is not necessary for information security professionals and leaders to be accountants or have finance degrees, it is important that they understand some basic concepts in order to make sound investment decisions, such as the decision of whether to automate a process or not.
It is important to understand that simply because a task can be automated does not mean it should be automated. In order to determine whether it should, we need to consider factors such as the cost of capital, the time value of money, and the difference between operational expenses and capital expenses.
Operational expenses are expenses that continue every month. Capital expenses are expenses that are paid upfront in one go, but whose benefits extend over a period of time. A common example is buying a software license and deploying it in your data centers, which is a capital-intensive strategy. Subscribing to a cloud service is an operational-intensive strategy. The primary difference is capital strategies require more money upfront and less over time, and operational expenses require little capital investment upfront, but more money to be spent on an ongoing basis. So which strategy is better? That depends primarily on the cost of capital and the time horizon.
When evaluating an operational strategy against a capital strategy, there will always be a break-even point. That is the point in time where the total investment of the operational strategy and the capital strategy cross, and the capital-intensive strategy becomes less expensive than the operational-intensive strategy. Because a capital-intensive strategy has higher upfront costs and lower ongoing costs, the lines plotting the total investment will always cross, the question is when. The amount of time it takes for the lines to cross is known as the payback period for the capital investment, which is a key determining factor for decision-makers when evaluating an investment.
You could calculate the payback period in nominal dollar terms, but that is only part of the story. Money has a time value. The time value of money is equal to the return of that money if it were to be invested elsewhere. Money now is worth more than money in the future because of the time value.
Another consideration is the cost of capital. In some cases, the capital investment may make sense, but you do not have the capital available. In those cases, the cost of acquiring capital, in terms of interest on debt or the value of equity that must be sold to fund a project must be considered.
It is infeasible to cover these concepts in detail in this book. However, if you don't understand these concepts, a finance course would be helpful to help you evaluate investment decisions, including the decision of whether or not to automate specific tasks.
Now that we understand some basic finance concepts, we can continue to identify automation opportunities. The first step is to map out tasks by cost basis.
Mapping a task by its cost basis
The discipline of mapping tasks by cost basis is not limited to cybersecurity but is a best practice for identifying and evaluating all automation opportunities. The first step is to define each cost basis available to you from the lowest to the highest cost basis. The lowest cost basis for the purpose of this exercise should be automation.
Automation is often a project with fixed capital expenses and limited operational expenses. Human labor has little capital expense and is mostly an ongoing operational expense. Therefore, automation is a way an organization can increase its operating leverage, which means it gains efficiency as it takes on more tasks. When someone says an operation has an ability to scale, they are speaking about its degree of operating leverage. While this is a financial term, it is relevant to a security operation as well. When a security team takes on additional capabilities or the organization they are supporting grows, they need to grow their team's capacity. Teams using automation well may be able to add additional value at one third of the additional cost of a team that is using limited automation. Therefore, automation is often an upfront investment in scale and growth. While most of us don't think about contraction, operational leverage has the opposite effect on shrinking teams with shrinking budgets. This means shrinking teams with high degrees of operating leverage become less efficient as their team gets smaller and there are less tasks for them to perform.
When mapping cost basis categories, it is not uncommon to have a result that looks like the following diagram. Often, skill sets will diverge as the cost basis gets higher. This is natural as higher-cost resources are generally more specialized and lower-cost resources are often generalized. The same could be said for service providers. Hiring a generalist firm that does everything is likely to yield mediocre results across the board. When a specific outcome is needed, a specialist firm is more likely to be able to deliver a superior outcome. The output of mapping the skill sets available by cost basis should yield a diagram. The following diagram is a simple example of what a Security Operations Center may yield:
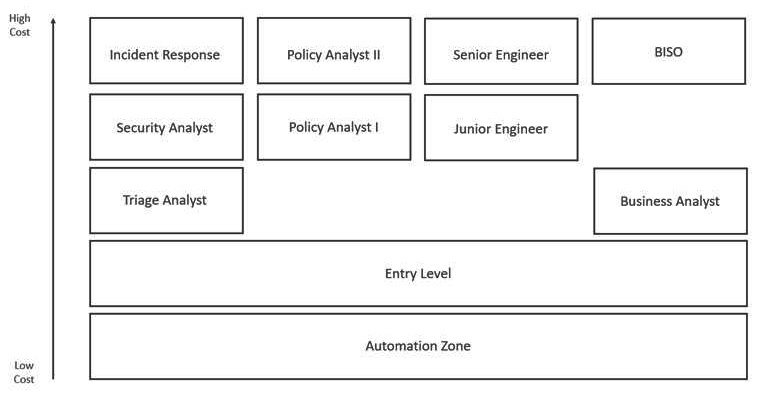
Figure 8.1 – Automation Opportunity Matrix – Stage 1
You may notice that there are gaps in this matrix. This is normal. There are often skill sets where even the most junior person is a relatively high-cost resource. The easiest tasks to automate are those that have a continuous path to the automation zone. However, it is possible to automate across gaps, it simply requires more planning and effort to automate those tasks.
Once the matrix is built, it is time to map tasks performed by each of those team members. In some organizations, the tasks each team member performs are well understood and documented. In others, this exercise may require a whiteboard session with cross-functional leadership. In either case, the output should be an understanding of the tasks each role performs. From my experience, even organizations that think they know the tasks each team member performs will gain valuable insight from the exercise of mapping it out with other stakeholders. Tasks that are taken for granted or are not well understood outside the team itself are often the best targets for automation.
The next step is to analyze the current costs of each of the tasks. To find the costs, you must understand the average hourly fully burdened cost for each skill set and the time spent per task in an average week. It is important to use fully burdened costs, which include not only the salary, but also benefits, paid time off, training, and bonuses. I see many organizations who use simple salary data to estimate costs or compare options and it is a skewed perspective. Often, the fully burdened cost of a resource is significantly more than their base salary. This discrepancy can be enough to change the outcome of an insourcing versus outsourcing decision, as well as the potential Return on Investment (ROI) of an automation opportunity. It is acceptable to estimate the time spent for operations that do not track time spent on tasks by role, but the more precise the data is, the better the team will be able to evaluate the ROI for automating the task.
The next step is to find the lowest logical cost basis for each task. There may be some tasks where automation is not appropriate. Others may be performed by higher cost resources due to necessity. Knowing the difference is valuable.
By the end of this exercise, you should be able to build a map of cost categories available, with a list of current tasks per cost basis in one color and a desired end cost basis in another color. The following diagram is a simplified version of what the end product will look like:
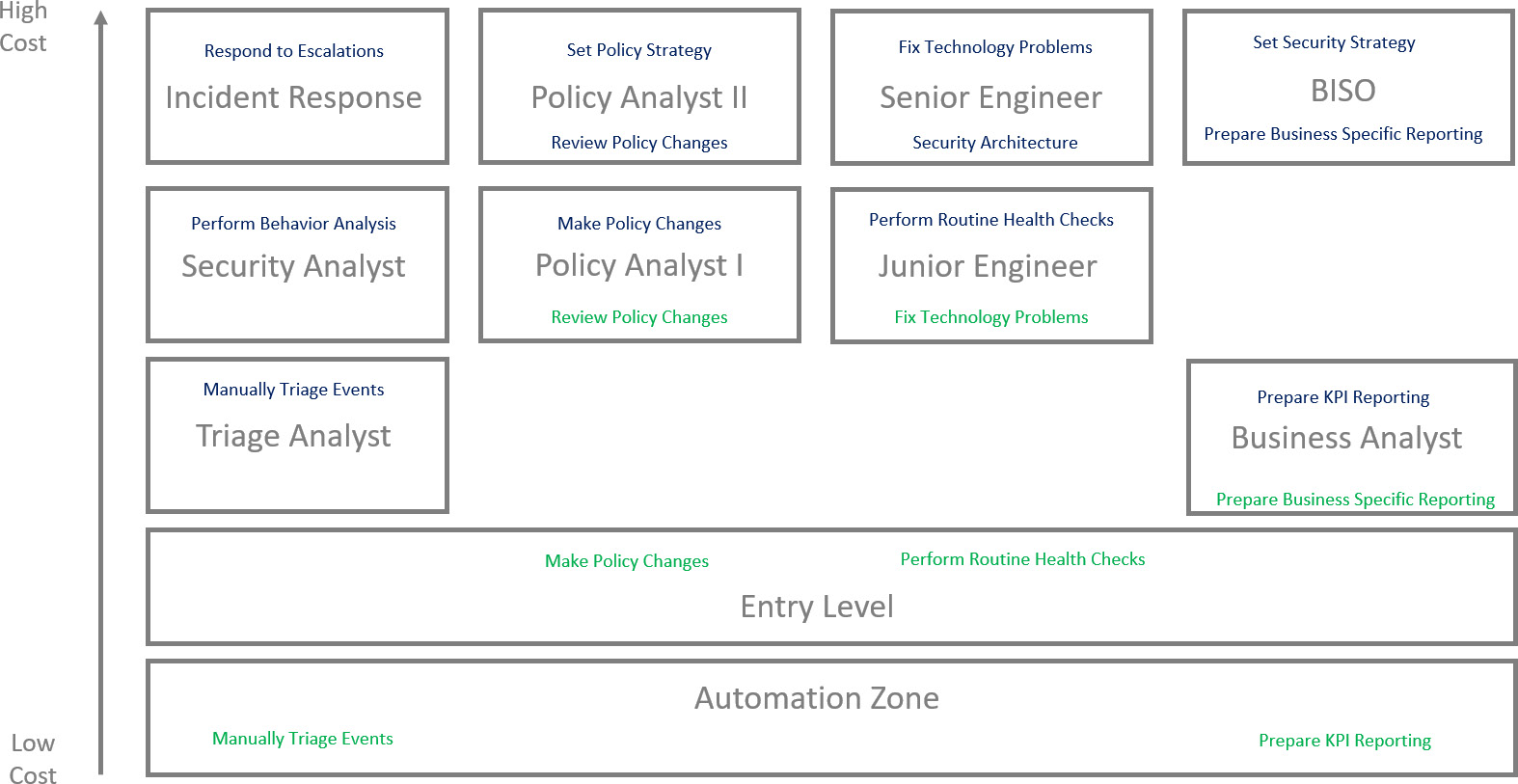
Figure 8.2 – Automation Opportunity Matrix – Stage 2
As you can see, not all tasks move down, and not all of those that do are candidates for automation. However, this matrix will highlight opportunities to drive tasks down to their lowest logical cost basis. The lowest possible cost basis is automation, and most tasks that can be taught to a true entry-level employee could be automated eventually. This is an important point. While cybersecurity is desperate for talent, there are few true entry-level jobs available. Addressing the talent shortage requires us to build entry-level opportunities for newly trained professionals. Assigning an entry-level person to test whether a process is ready for automation is a great learning opportunity for the employee, and an opportunity for the employer to save high-cost development resources who are trying to automate a process that is not yet well defined.
Once you have decided which tasks should be driven down the cost scale, you are ready for the next step in the process, which is documenting the processes in detail.
Documenting manual processes
Documenting a process allows you to consider whether the process could be accomplished on a lower cost basis. Some tasks are assigned to high-cost resources because they require certain skills and experience. Others are performed by high-cost resources because they are not well documented and require an unnecessary amount of judgment. Documenting those processes allows the organization to evaluate whether a lower cost resource is capable of performing the task. While not every task can be automated, most could be driven to a lower cost basis, which frees more senior resources to address more consequential problems for the organization. Also, the act of writing a process down often highlights gaps in the process or inefficiencies. Most processes in a security program are built by habit and few are intentionally designed. Intentionally designed processes are often more efficient and effective.
It should be highlighted that there are few automation techniques currently available that will allow a team to automate a process they don't understand. Techniques to allow AI to learn tasks that are not explicitly taught to it are rare. Therefore, if you hope to automate a process, the first step is to learn the task and document it to the point where a non-technical user could accomplish the task with consistent results. When the task can be reduced to a series of if-then statements in a decision matrix, the task is ready to be automated using commonly available techniques.
Once the process is well defined and documented, the next step is to automate the process.
Automating processes
Once the decision matrix has been built to the level that a person with no experience in the field could follow it to get the desired result, the task is ready to be automated. At that point, all that is necessary to automate the task is to code the decision matrix. This is a process that can be accomplished using coding languages, open source technology, and coding skills that are widely available. There are other possibilities for automation that require a deeper skill set and can solve a wider range of problems. However, most security operations can become more efficient without using advanced techniques.
In my experience, few information security teams have the necessary resources to perform complex automation operations. Complex automation techniques are likely to be the domain of security technology companies. When using automation through a security technology, understanding the Total Cost of Ownership (TCO) should take all costs into account including the cost of software, of hardware if applicable, and the fully burdened cost of the resources necessary to achieve the intended outcome. Comparing that TCO to the TCO of the current solution will allow for a cost comparison, which should be compared to a benefit comparison to do a proper cost-benefit analysis. One thing that should be clear by this point is that understanding business concepts is a critical skill for security leaders. Past generations of security leaders were often technical but not business savvy. Nowadays, the security leadership role is being redefined as a business role with an understanding of technology. This is the opposite of what was required from the role in the past, where security leaders were often security experts with a basic understanding of business. As security matures as a discipline, more business skills are required from the security team.
In my experience, when technology decisions go wrong, it is often due to underestimating the human resource costs. Technologies that are more expensive than their peers may have a favorable TCO if there are automation capabilities built into the product. Other companies offer services that may allow an organization to reduce the risks associated with underestimating their human resource costs.
Once the basic tasks have been identified and automated, it is time to build upon the automation foundation by gathering more data and applying context.
Gathering data and applying context
A general rule concerning machine learning specifically, and automation techniques generally, is that they require large amounts of data to be effective. More data will enable the machine to make better decisions and solve more complex problems. Part of the data that can be gathered will help the machines apply context to what they are seeing. Currently, algorithms struggle with qualitative analysis. Algorithms that can tell you what happened using a large dataset are commodities at this point. This is not to say these algorithms are not helpful, they are simply common. Some algorithms are also predictive. With enough historical data, some algorithms have become good at predicting what will happen next. This is largely based on pattern recognition and determining the next logical data point given the historical data. People should be very careful with predictive algorithms because incomplete datasets can lead to poor predictions. Also, machines have difficulty putting black swan events into perspective.
Black swan
A black swan is an event that cannot be predicted and changes everything. The COVID-19 pandemic which began in 2019, is not a true black swan event. It could be argued that a fast-spreading respiratory illness causing a global pandemic has been seen before and will likely occur again. However, assuming aspects of human life return to their patterns before the pandemic, most predictive algorithms would have difficulty making multi-year future predictions if data from 2020 and 2021 is in the dataset. True black swan events cause even more challenges.
What algorithms are currently most ineffective at is trying to determine why something happened. Why is an important question when dealing with security or law enforcement. Some machines attempt to answer why, but programming such algorithms leads to major ethical questions more often than yielding useful insights. Next, we will briefly introduce some of the ethical issues in AI.
Ethics in AI
AI offers exciting potential for a variety of applications. I am not an AI skeptic; in fact, I believe that we will need AI solutions to help us solve some of the problems we will face in the near future. However, there are some major issues with AI that we need to consider before the widespread use of AI in society can be ethical. It should be noted that this is not an exhaustive list. Ethics in AI is becoming a field in itself. This is simply an introduction to the top three ethics issues that I have seen arise when AI is used.
First, we will explore the challenges that arise when biased datasets are used, and their bias is built into automated systems.
Bias in datasets
AI systems need very large datasets to be effective. In many cases, those datasets go back for many years. The problem is that it is hard to find the necessary amount of unbiased data to create effective AI systems. As an example, I will use a hypothetical thought experiment. This is not a real example, but there have been enough examples of this thought experiment where it could be considered realistic, if not likely.
Let's imagine a city wants to deploy an AI algorithm to help predict crime rates in an area to help ensure police are close to where they are likely to be needed. The city has been struggling to staff its police force appropriately, which has led to rising crime rates and falling conviction rates. The city inputs all the historical data from the city from the previous 100 years into a large dataset. It then allows an AI algorithm to dispatch police cars based on the patterns it has observed. The system works. Police are now able to cut their response times to calls and their conviction rate increases significantly. Proponents of the system argue the high arrest rates in places where police were deployed versus other places they were not is evidence the system is working. Critics say the data is a self-fulfilling prophecy because police are making arrests where they happen to be.
Facing a wave of judge retirements, the city decides to extend the algorithm to make sentencing recommendations to the remaining judges within the statutory sentencing guidelines based on the likelihood that a person will re-offend. These suggestions help narrow sentencing guidelines and make the system more efficient. The system is expanded to parole boards to help make decisions on who should be released and reintegrated into society.
The American Civil Liberties Union (ACLU) is skeptical that the system is just. After an investigation, they find that minorities are more likely to be arrested. When arrested, they are more likely to be convicted and if they are convicted, they are more likely to receive a harsher sentence. Further, they are less likely to be released when they are eligible for parole. How could a seemingly unbiased algorithm create such inequity?
The answer is that there have been historical inequities in a variety of our institutions that have led to minorities being disproportionately impacted by the criminal justice system. With no way to understand that historical context, the algorithm incorrectly associated ethnicities and socio-economic factors to a higher propensity to commit a crime. Also, due to similar factors, the system determines minorities have a higher recidivism rate. These challenges are real, and we will see these debates expand in the coming decades as a decreasing labor force in many developed economies leads more organizations and jurisdictions to look for solutions in algorithms.
We are already seeing examples of bias in technology. There have been studies that show facial recognition technology is most effective for light-skinned faces and has diminishing accuracy rates when recognizing faces with a darker skin complexion. While it can be hurtful when Snapchat filters do not recognize a person's face, the consequences are more severe as facial recognition technology is used by police forces and customs and border patrol agents. A mistaken identity could lead a person to be wrongfully arrested. If juries are unduly confident in the technology and not aware of its imperfections, the bias could also lead to wrongful convictions.
Example Case Study: The Nijeer Parks Case
Challenges with bias in AI are concerning in the theoretical realm, but what many people don't realize is that immature AI algorithms are in use today. In some cases, like the case of Nijeer Parks, they are causing real-world negative consequences. In 2019, Woodbridge, New Jersey police arrested Mr. Parks for shoplifting candy and attempting to hit police officers with his car. He had been identified using facial recognition software. He was taken to jail and had to hire an attorney to defend himself before the case was eventually dismissed. The problem with the case? Mr. Parks was 30 miles away and the person in the surveillance video was not him, but another man with a similar complexion.
Facial recognition technology is seeing widespread use by law enforcement and conceptually it seems like a positive development. Over 200 cities in the United States use facial recognition technology to solve crimes. However, facial recognition software is prone to errors across the board, but the frequency of those errors increases for people with darker skin tones. When the tool is used appropriately to narrow a large list of potential suspects into a smaller list, it can make investigators' jobs less time-consuming, and the technology could be effective. However, too often the technology is being used as a basis to arrest people without meaningful human verification and mistakes are common.
This is a perfect example of a technology that should be used to aid humans rather than replace them. In fact, most automation technology will fall into that category for at least the next few decades as we continue to tune the models. However, the question of the proper use of technology is not the sole issue in this case.
There are civil rights implications associated with using technologies that have inherent bias when making decisions related to whether a person is arrested and charged with a crime. Many people have spent their lives fighting systemic injustices and to have those injustices written into algorithms that will form the basis of policing decisions in the future represents a major step backward for civil rights. It is important that we work to free our datasets and algorithms of bias, especially unconscious bias, or we risk transferring our worst historical impulses from ourselves to our machines (Hill, 2020).
Technology providers should not be expected to solve these problems themselves. It is expensive and time-consuming to collect large datasets. Inconsistent privacy regulations around the world make it more difficult than ever. I am an advocate for an open source data repository that can be used by anyone developing AI systems. The open source project could then gather large volumes of data and curate it in such a way where it had adequate representation from all ethnic groups and was free from inherent bias. This unbiased dataset would lead to higher-quality AI products that are less likely to have unintended negative consequences. Partnering with governments to create this dataset and make it available to companies in their country could help grow the tax base and thus their economies, giving them an incentive to cooperate. Making the data available to universities around the world will allow for deep tech research into better, fairer algorithms and will allow for the study of embedded biases and the improvement of the dataset overall. This dataset would be very important to fighting bias and improving the quality of AI.
Next, let's look at another ethical issue, which is privacy.
Protecting privacy
The Chinese government has hundreds of millions of cameras around the country using facial recognition technology to track citizens as they move. Based on where they go and what they do, an AI algorithm can match the movements to a personal profile. Based on surveillance of their communications, AI systems can gain an understanding of their thoughts and attitudes. In short, the Chinese government has created a system to predict who may become a problem so they can intervene before that happens.
During the COVID-19 pandemic, the government used this massive surveillance system coupled with an AI algorithm to assign risk to people before they boarded a train or entered a city. The system could just as easily be used to assess political risk. There is no doubt such a system could be helpful in reducing the spread of the coronavirus and may have other useful applications. However, it is also easy to imagine a scenario where such a system could be used in a way that is more controversial.
As we move into the future of technology, we need to think critically about what privacy means to us and how we should protect it. Regulations such as the European Union's GDPR are a good example of thoughtful legislation designed to get ahead of these problems. However, there have been countless other jurisdictions that have passed similar privacy legislation, and each one is slightly different. Since data does not respect terrestrial borders, it is very challenging to comply with this patchwork of legislation.
Example Case Study: Reading Between the Lines – The CCPA and Privacy in AI
On June 28, 2021, the California State Legislature passed the California Consumer Privacy Act (CCPA). At first glance, the CCPA is another piece of legislation loosely based on the European Union's GDPR that adds to the problematic global patchwork of privacy legislation. However, upon closer inspection, you can see a window into the challenges society will face as more companies leverage AI platforms around the world.
While much of the CCPA looks like GDPR, there are some important differences in the scope of what is considered personal information. California is home to Silicon Valley, one of the world's most robust technology innovation centers. The California State Legislature is foreseeing some of the problems that the rest of the world will face and trying to give its citizens some control over the data that may soon be used to make decisions about them without their consent.
The CCPA calls out personal information such as identification numbers, phone numbers, addresses, and other common forms of Personally Identifiable Information (PII). However, the CCPA also calls out things like a person's gait, or the way they walk, photos of a person, and other pieces of information often linked to visual media. Further, the CCPA covers inferences about a person going into an AI model and the derived data coming out of that AI model. This means that if an AI model uses information about you to derive some further piece of data, you own both the source data and the derived data as a data subject and you can exert your rights over the derived data as well as the source data. The CCPA also has a catch-all broad definition of personal data that allows the State of California to exert control over the use of new technologies, defining personal information as data that is capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer or household.
Is this approach going to solve problems with privacy and AI in California? It is difficult to predict, but the idea that we need to define who owns what information as we develop data-hungry technology capabilities is important. We need to consider what privacy means in the modern world, where governments can use technology to track our movements in the physical world and monitor everything we say in the digital world. There has never been a time in human history where surveillance was easier to conduct, nor a time where so much information about every individual exists. It is time for us to think critically about what the rules should be and how that data should be used (State of California, 2018).
It is easy to criticize the Chinese Communist Party for their use of surveillance and technology to create a police state. They are open about the fact that they do not believe in individual privacy rights. However, hundreds of cities in the United States are creating similar systems using facial recognition and AI to track citizens and their movements along with their online communications. Most cities are not notifying their citizens when they deploy these types of monitoring tools.
Some states have passed legislation similar to the California Consumer Privacy Act (CCPA). The CCPA protects an individual's right to privacy and defines personal information to include a person's likeness and their movements. The challenge is that privacy legislation is not consistent even within the United States, let alone globally. This leads to organizations scrambling to understand the requirements they must comply with to do business in each jurisdiction.
In my opinion, we need national legislation that supersedes the state-by-state approaches to privacy to create an environment where companies can respect privacy in an efficient way. Where countries agree on certain elements of privacy legislation, international treaties should be formed to simplify the regulatory landscape. Modern technology systems are not designed to respect terrestrial borders. The more inconsistent regulation is across jurisdictions, the less likely it is to be followed and its objectives met.
Next, we will talk about another ethical debate, behavior modification.
Behavior modification
The idea that companies would like to modify our behavior is nothing new. In fact, the field of advertising can be seen as the art and science of behavior modification through persuasion. However, companies using technology have become very good at behavior modification. Social media companies have been under fire recently for creating algorithms designed to push people toward their darkest impulses to increase their engagement with the platform, thereby amplifying advertising revenue for the company. The more extreme a person's views become, the more alienated from wider society they will be, and the more they will be driven toward online communities. This has been shown to have wide-ranging impacts, and it could be argued the impacts it has on children are most detrimental.
Example Case Study: How Social Media Divides Us
Social media was originally invented to help people who already knew each other stay connected. As it matured as a technology and a business model, social media companies realized that they could increase engagement by creating communities of like-minded people. As the algorithms continued to gather data about engagement, they determined that the more polarized the group, the more time they would spend on their online communities. Since the algorithms are designed to create maximum engagement, strategies that create division between groups of people continued to proliferate.
The challenge with social media was people who were members of these groups were not only holding alternative opinions from those in other groups, but they were also shown alternate realities. Since confirmation bias in people is so strong, over time, when presented with information that did not confirm their worldview, they rejected the information without considering it. The effect on society has been profound as people with minor disagreements on policy have turned into extremely polarized groups who have trouble communicating. This is because there is no basis of shared facts or shared reality, with each group inhabiting a world that is unrecognizable to the other.
Hyper-customization allows each of us to live in an online world of our own creation. Our preferences allow algorithms to feed us more of what we prefer while blocking what we don't. Over time, some people start to believe the things they don't prefer don't actually exist. This becomes a major challenge. While print media was doomed as soon as online media was developed, there are some merits in everyone reading the same sets of facts. Even if two people draw different conclusions from what they have read, at least there is a common basis for debate.
Similarly, online retailers have become very good at using technology to find the sets of stimuli necessary to maximize the number of products a person purchases on each visit. Where will we draw the line between acceptable commercial behavior and an unacceptable detriment to society? When does advertising and persuasion cross the line into infringing upon a person's basic right to self-determination? At what age, if ever, is a person's brain sufficiently developed to have a chance to resist these techniques? I do not intend to provide an answer to these questions, but I think it is important we continue to ask them, especially as technology improves and becomes more intertwined with our daily lives. We are rapidly approaching a place in our technological evolution in many spaces where the question shifts from What can we do? to What should we do?
Next, we will discuss what we should do once we have identified an automation opportunity and put a solution in place that we think will be effective – testing the system.
Testing the system
When you automate a task, sometimes you will have a more efficient and more effective method of achieving a necessary goal and it will be an overwhelming success. Other times you will have an outcome that is neither efficient nor effective, and it will be clear that you should return to the previous way of doing things and try again. Often, it will be somewhere in the middle. How do you test a system you have built? What is an acceptable error rate? How do you measure it?
First, we will talk about a framework for measuring test results known as the confusion matrix.
The confusion matrix
For each task, there are four possible outcomes. These four outcomes are collectively known as the confusion matrix. The following diagram is a visual representation of this simple concept:

Figure 8.3 – Confusion matrix
When testing systems, each outcome will fall into one of these categories. Here is a brief description of each:
- True positive: Something the algorithm should have flagged and did
- True negative: Something the algorithm should not have flagged and did not
- False positive: Something the system should not have flagged but did
- False negative: Something the system should have flagged but did not
When defining acceptable parameters, tolerance for both false positives and false negatives should be considered. In some cases, some false positives are acceptable, but there is low tolerance for false negatives. In other cases, the opposite may be true. In most cases, a simple accuracy rate is insufficient.
Once someone has defined their test criteria and the expected results, the system can be tested. Automation, like most types of innovation, is unlikely to be perfect the first time. As a result, we often see hybrid implementations as the technology is improved. Further, my opinion of the future is that humans and algorithms will work together to perform most tasks. Therefore, hybrid implementations are likely to be the way most tasks are accomplished for the foreseeable future.
Hybrid implementations
The term hybrid implementation refers to implementations of automation technology that work alongside a human, doing the same job. For example, you may have a self-driving car algorithm running silently in a car. You can then record the actions the algorithm would've taken in any given scenario and compare that data with the actions the human driver did take. Also, you could layer in the positive and negative outcomes. Over time, you can compare how effective the machine is at a given task, in this case driving, against the human. In the case of driving, the acceptable error rate for an algorithm is much lower than it is for human drivers. We accept a certain number of annual car accidents due to human error. Any time an automated system causes an accident, it is national news.
Other uses, such as those in most security applications, are more benign. When we were first building our event triage automation technology at InteliSecure, it started as a quality assurance mechanism. Once we felt we had an effective algorithm, we would run it alongside a human analyst. When the machine and the human agreed, nothing happened. When they disagreed, the event was escalated to a senior analyst who could review the event and determine whether the analyst or the algorithm was incorrect. In the beginning, analysts outperformed the algorithms. After some time, we were able to find tasks that the algorithm was better suited to and achieved a far lower error rate. As it turns out, those were the tasks least desirable and intellectually stimulating for the analysts. We were able to improve outcomes, efficiency, and job satisfaction through a hybrid implementation.
Sometimes a hybrid implementation is a means to an end. The solution is implemented in a hybrid fashion until the algorithm can be improved to the point it is more effective than the human, at which time the algorithm takes over. However, there are some tasks that will be hybrid implementations for the foreseeable future. In those cases, machines may be more adept at portions of an outcome and humans may be more adept at others. In these cases, the human and the machine will work together. For example, think of a research scientist. In the future, an algorithm could parse through a very large dataset, highlighting all the correlations in the data. The human could then analyze them and determine which correlations are likely coincidental and which may have causal factors. After listing the causal factors, the machine could then parse through the dataset again to confirm or deny the researcher's hypothesis. Using this method, research that once took months or years could be completed in days or weeks.
Many people see automation in the workforce as an all-or-nothing scenario. Hybrid implementations are likely to become more common as the technology improves. This will allow people to do what they're best at while being assisted by machines built specifically to do things humans find difficult or boring. If you listen to people talk long enough about AI, you generally get the sense that it will either be the best or worst thing that happened to humanity. It is likely to be somewhere in between.
Next, we will discuss the other side of the equation – how attackers can leverage automation.
How attackers can leverage automation
Of course, attackers have access to the same technological capabilities as defenders. Like security professionals, attackers have experts creating technology for them, helping them with consulting and expertise on demand, and generally making their jobs easier. It is similar with automation. If AI algorithms are good at pattern recognition, this provides an opportunity for attackers to use those capabilities for nefarious purposes.
For example, could it be possible to train a machine learning algorithm on a list of best practices for incident response and teach a piece of malicious code to evade commonly deployed countermeasures? I couldn't imagine why not. Could attackers build self-healing worms that use multi-stage attacks to defeat commonly deployed security technologies? I think those types of sophisticated attacks are already happening.
The key point is to raise awareness that at its heart, security is about people attacking people. Just as with any other conflict in human history, there is an ever-escalating arms race in terms of technology and tactics. That is one of the things that is fascinating about security, but also one of the things that makes it so challenging. You can never rest on your laurels or declare yourself secure. Every day we must be improving our defenses and preparing to defend ourselves because one day we will be attacked, and our response could be the difference between the success and failure of our entire organization.
While it is impossible to predict every way attackers will use automation, it is safe to assume they will use it, and they will innovate ways to use it to defeat the defense mechanisms we build. Each time we build an effective countermeasure, we are likely to see a new form of attack.
Summary
Automation is a necessary capability that will help us meet the staffing challenges of the modern world. While we can and should grow the cybersecurity workforce, that is a long-term solution. We will require effective solutions to meet challenges in the interim.
In this chapter, you have learned how to identify automation opportunities, along with a practical methodology to act upon those opportunities. You have learned about datasets and context and the ethical challenges posed by AI solutions. You have also learned how to test your solutions to ensure they are effective, and you have been given a brief idea of how attackers could leverage similar technologies against you to become more efficient and effective at what they do.
At this point in our journey, we have covered a wide range of topics relevant to protecting modern organizations. You now have the necessary understanding to look at the landscape and hopefully identify an area that appeals to you. For our final chapter, we will discuss what steps we can all take to keep our loved ones safe at home in an increasingly dangerous digital world.
Check your understanding
- What is the lowest cost basis for a cybersecurity task in any organization?
- What types of questions are AI solutions well positioned to answer, and which do they struggle with?
- What are some of the ethical challenges with AI systems?
- What are the quadrants of the confusion matrix?
- Which type of documentation of a manual process indicates that an automation opportunity is ready for coding?
Further reading
- Hill, K. (2020, December 29). Another Arrest, and Jail Time, Due to a Bad Facial Recognition Match. Retrieved from The New York Times: https://www.nytimes.com/2020/12/29/technology/facial-recognition-misidentify-jail.html.
- Kanowitz, S. (2020, February 12). Government revs up IT security automation. Retrieved from GCN: https://gcn.com/articles/2020/02/12/it-security-automation-public-sector.aspx.
- Ponemon Institute. (2020). 2020 Cost of a Data Breach Report. Ponemon Institute.
- State of California. (2018, June). California Consumer Privacy Act (CCPA). Retrieved from State of California Department of Justice: https://oag.ca.gov/privacy/ccpa.