
Conceptually, MapReduce jobs are relatively simple. In the map phase, each input record has a function applied to it, resulting in one or more key-value pairs. The reduce phase receives a group of the key-value pairs and performs some function over that group. Testing mappers and reducers should be as easy as testing any other function. A given input will result in an expected output. The complexities arise due to the distributed nature of Hadoop. Hadoop is a large framework with many moving parts. Prior to the release of MRUnit by Cloudera, even the simplest tests running in local mode would have to read from the disk and take several seconds each to set up and run.
MRUnit removes as much of the Hadoop framework as possible while developing and testing. The focus is narrowed to the map and reduce code, their inputs, and expected outputs. With MRUnit, developing and testing MapReduce code can be done entirely in the IDE, and these tests take fractions of a second to run.
This recipe will demonstrate how MRUnit uses the IdentityMapper provided by the MapReduce framework in the lib folder. The IdentityMapper takes a key-value pair as input and emits the same key-value pair, unchanged.
Start with the following steps:
- Download the latest version of MRUnit from http://mrunit.apache.org/general/downloads.html
- Create a new Java project
- Add the
mrunit-X.Y.Z-incubating-hadoop1.jarfile and other Hadoop JAR files to the build path of the Java project - Create a new class named
IdentityMapperTest - For the full source, review the
IdentityMapperTest.javafile in the source code folder of this chapter
Follow these steps to test a mapper with MRUnit:
- Have the
IdentityMapperTestclass extend theTestCaseclass:public class IdentityMapperTest extends TestCase
- Create two private members of mapper and driver:
private Mapper identityMapper; private MapDriver mapDriver;
- Add a
setup()method with aBeforeannotation:@Before public void setup() { identityMapper = new IdentityMapper(); mapDriver = new MapDriver(identityMapper); } - Add a
testIdentityMapper1()method with aTestannotation:@Test public void testIdentityMapper1() { mapDriver.withInput(new Text("key"), new Text("value")) mapDriver.withOutput(new Text("key"), new Text("value")) .runTest(); } - Run the application.
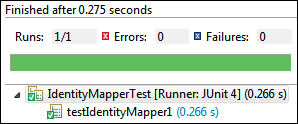
- Add a
testIdentityMapper2()method that would fail:@Test public void testIdentityMapper2() { mapDriver.withInput(new Text("key"), new Text("value")) mapDriver.withOutput(new Text("key2"), new Text("value2")) mapDriver.runTest(); } - Run the application again.
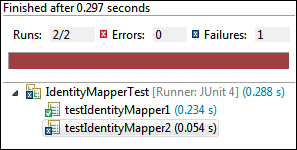
MRUnit is built on top of the popular JUnit testing framework. It uses the object-mocking library, Mockito, to mock most of the essential Hadoop objects so the user only needs to focus on the map and reduce logic. The
MapDriver class runs the test. It is instantiated with a Mapper class. The
withInput() method is called to provide input to the Mapper class that the MapDriver class was instantiated with. The withOutput() method is called to provide output to validate the results of the call to the Mapper class. The call to the
runTest() method actually calls the mapper, passing it the inputs and validating its outputs against the ones provided by the
withOutput() method.
This example only showed the testing of a mapper.
MRUnit also provides a ReduceDriver class that can be used in the same way as MapDriver for testing reducers.
- For more information on Mockito, visit http://code.google.com/p/mockito/
- The Developing and testing MapReduce jobs running in local mode recipe of this chapter