
Chapter 2. Getting started with web services
This chapter covers
- XML, SOAP and WSDL basics
- Web services with Apache Axis
- Choices in service design
Chapter 1 described why and how SOA security is different from traditional application security. In this chapter, we are going to learn some of the foundational technical details of SOA, namely web services and SOAP.
Web services provide the most popular approach for implementing SOA. SOAP is the most-supported protocol in web services. It should be no surprise then that security solutions are more widely researched, developed, and implemented for SOAP-based web services. The principles behind the techniques for SOAP security hold good for wider SOA security as well, and the first two parts of this book will almost exclusively assume SOAP-based web services. Therefore, you need to have a good understanding of SOAP and other basic technologies that SOAP relies on to follow this book.
In this chapter, we will introduce the required technology, along with the tools and environment assumed in the sample code included with this book. We will get going by describing how you can set up the tools and environment required by our first example. The example consists of a sample SOAP-based web service and its clients, all developed using Apache Axis, an open-source web services toolkit. After showing you how to run the example, we will dig into the basics needed to understand the example—XML, SOAP, and WSDL. Once you understand the basics, we will return to the example and explain the code. We will then demonstrate interoperability between different web services platforms by showing how you can invoke the sample service (running on Apache Axis) from a client running on a different web services platform (.NET WSE). We will conclude the chapter with a discussion of the choices and challenges frequently faced by architects, designers, and developers when doing real-life SOA implementations.
This chapter is mostly about getting started with SOAP. It does not address any of the security issues in SOA. Readers with hands-on experience in creating and consuming SOAP-based web services can skim through this chapter merely to gain familiarity with the tools.
2.1. Setting up tools and environment
What do we need to create and use a basic web service?
To begin, we need to understand the technologies that make web services possible. XML and SOAP provide the basic technical foundation for web services. Next, we need to choose a programming platform and a toolkit for creating/consuming web services. In this section we will focus on the latter, so that we can illustrate technology basics of web services through hands-on examples in subsequent sections.
2.1.1. Choosing a platform and a toolkit
The programming platform you choose for web services depends on a number of factors such as the following:
- Previous experience with the platform
- Availability of toolkits for web services on the platform
- Availability of trained developers at affordable rates
- Synergy with other choices made for the project
The choice of a programming platform for web services is not as critical as in traditional application development, since no matter what choice we make, we expect our services/clients to interoperate well with those written on other platforms. After all, that is the promise of open standards-based web services.
In fact, you may even decide to use multiple platforms and toolkits in your implementations. For example, you may decide to use .NET for your clients and J2EE for your service implementations.
The current mainstream choices for the programming platform are .NET and J2EE. For the purposes of this book, we are interested in choosing open-source tools that allow you, the reader, to try out all the examples by yourself. That restricts our choice to the J2EE platform.
Apache Software Foundation (ASF) provides many of the popular open-source tools needed for implementing and consuming web services in Java. Apache Axis is at the center of those offerings. Axis implements SOAP and makes it possible to plug in support for protocols built on SOAP. All the examples in this book will assume Axis as the SOAP engine. There are of course other J2EE-based implementations that support SOAP. Most J2EE application servers come with one. For example, BEA WebLogic and IBM WebSphere come with their own SOAP engines.
The Java Community Process (JCP) is working to standardize on vendor-neutral Java APIs for web services. Most of these standards, except for the basic ones such as Java API for XML-based RPC (JAX-RPC), Java API for XML Messaging (JAXM), and SOAP with Attachments API for Java (SAAJ), are still on the drawing board. We will use Java vendor-neutral APIs in our examples as much as possible, but when we cannot, we will rely on particular open-source implementations. For example, instead of using Axis native APIs, we will stick to the standard JAX-RPC API when illustrating RPC with SOAP.
Even if you are not using the J2EE platform or Apache Axis, the examples in this book should still be useful to you as guidance in creating similar solutions. First, let’s get started with Axis.
2.1.2. Getting started with Apache Axis
In this section we provide you with the information needed to quickly set up Apache Axis and run an example web service. All it takes is a few steps. First, we will install the prerequisites. Next, we will install Apache Axis. Finally, we will show how to run the example. We will explain the inner workings of the example in the subsequent sections. For the present, we will only concentrate on getting the example running.
Installing the prerequisites
Apache Axis needs JDK and Tomcat. In addition to these, our example needs JUnit and Ant. Table 2.1 shows the details required to download and install the correct version of all these.
Table 2.1. Prerequisites for running examples in this book
|
Tool |
Version |
URL to download from |
Notes |
|---|---|---|---|
| Java SE Development Kit (JDK) | 5.x (also referred to as 1.5.x) | For Windows/Linux /Solaris: http://java.sun.com/j2se/1.5.0/download.jsp For Mac OS X: http://developer.apple.com/java/download/ | JDK 1.4.x would work as well; axis configuration just becomes more complex. |
| Tomcat | 5.5.x | http://tomcat.apache.org/ | You have the option of downloading the .exe (for Windows) or .zip for all the platforms, including Windows. These instructions assume that you downloaded a zip and extracted it to a directory of your preference. 1. Open a command prompt and change directory to apache-tomcat-* 2. To start Tomcat, run bin/startup.bat if you are on Windows. On other platforms, run bin/startup.sh instead. 3. You can verify that tomcat is running by visiting http://127.0.0.1:8080/ as tomcat listens on port 8080 by default. |
| Ant | 1.6.x | http://ant.apache.org/ | Download a zip archive containing Ant’s binary distribution and extract files to a location of your preference. Then: 1. Complete the installation using instructions found in docs/manual/install.html. 2. Test Ant by running the command ant –help |
| JUnit | 3.8.x | http://sourceforge.net/projects/junit | Extract JUnit zip archive into a directory of your preference. Copy junit.jar to the lib folder under Ant. |
Once the prerequisites are set up, the next step is to install Axis.
Installing Axis
Table 2.2 provides the instructions for setting up Axis.
Table 2.2. Instructions for installing Axis
|
Step |
Action |
How to |
|---|---|---|
| 1 | Set up the prerequisites | See table 2.1 for instructions |
| 2 | Download Axis 1.x | Download a binary distribution of Axis as a zip file from http://ws.apache.org/axis/. Extract the archive to a location of your preference. |
| 3 | Add Axis as a web application in Tomcat | 1. Copy or move the webapps/axis folder found under your Axis location as a subfolder of webapps under your Tomcat location. 2. Restart Tomcat by running shutdown and startup scripts (.bat files if you are using Windows and .sh files if you are on Linux/Soaris/OS X) found in the bin directory of Tomcat. |
| 4 | Validate Axis installation | 1. Open http://127.0.0.1:8080/axis/happyaxis.jsp in your web browser. This web page will tell you if you are missing any of the required or optional jars. 2. Axis provides a link for downloading a jar whenever a required or optional jar is found to be missing. Download the missing (required) jars and add them to webapps/axis/WEB-INF/lib/ under your Tomcat location. 3. Restart Tomcat and check again to make sure that the installation is successful. |
Now that Axis is installed, the next step is to set up the examples.
Setting up the examples
All the examples in this book come packaged with an Ant script. Use the instructions in table 2.3 to set up the examples.
Table 2.3. Instructions for setting up examples
|
Action |
How to |
|
|---|---|---|
| 1 | Download examples archive | Download the examples archive from http://www.manning.com/kanneganti/. Extract it to a location of your choice. |
| 2 | Configure build script | Edit the build.properties file in the top level directory and customize as necessary. The questions that precede each property assignment and the sample values will guide you in choosing the right values. |
| 3 | Deploy examples in Axis | Run the command ant deploy. |
| 4 | Restart Tomcat | Run shutdown and startup scripts (.bat files if you are using Windows and .sh files if you are on Linux/Solaris/OS X) found in the bin directory of Tomcat. |
Let’s now see how you can run the first example.
Running the first example
We now have Axis up and running with all the examples deployed. Table 2.4 shows how we can invoke our first sample web service.
Table 2.4. Instructions for running example 1
|
Step |
Action |
How to |
|---|---|---|
| 1 | Set up a monitoring mechanism to record and display all the network traffic to and from Tomcat. | 1. Run the command ant tcpmon. It will run a proxy on port 8000 that relays requests and response messages to their respective destinations after displaying them in a GUI. 2. In tcpmon window, check the box marked “XML format” since we are going to be looking at the XML traffic. |
| 2 | Invoke example web service | Run the command ant demo –Dexample.id=1. This results in the invocation of an example web service via the proxy we set up in the step 1. |
If all went well, you should see the message BUILD SUCCESSFUL along with some recorded network traffic in the tcpmon window. Look at the recorded network traffic to figure out what exactly happened. If this is the first time you are looking at SOAP, you will get a general feel for how SOAP over HTTP looks.
Figure 2.1 shows a screenshot of tcpmon after you are done with the example.
Figure 2.1. Screenshot of tcpmon showing the SOAP request and response messages captured in example 1. tcpmon is a tool available with Apache Axis to inspect messages received and sent by a service. It acts like a proxy, relaying requests and responses to their respective destinations after displaying them in the GUI.
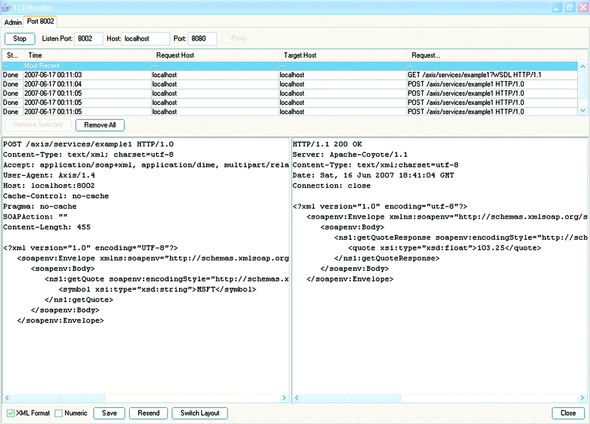
The rest of this chapter will take advantage of this example to dig more into basic XML and SOAP concepts.
2.2. XML basics
Given that you are reading a book on SOA security, you may already be familiar with XML. XML is everywhere we look in modern integration practice. XML is quite often introduced and seen as a document format—as a generalization of HTML or as a variant of SGML (a standard format for encoding electronic texts). But that is not the most interesting way to look at XML for SOA practitioners.
For us, XML is the common denominator format for data exchange between applications. Mismatch of data models and data formats is one of the biggest challenges of integration. Different applications will have different models of data. For example, an HR application may have a different data model for employee information than an e-learning application. Any attempt to unify the models may impose an unnecessary burden on both the applications. Furthermore, when exchanging data between applications, each application needs data in a format of its own liking. For example, the format in which your CRM application exports customer records may be different from the format your logistics application accepts for import.
When we integrate different applications, we may need to translate data from one model and format into another. If the data formats are arbitrary, we will be forced to write parsers for each data format, which requires good programming skills. So, what we need is a standard format that has two properties:
- The format should be expressive enough to serve multiple applications. That is, the data structures that the format can express (lists, trees, graphs, maps, and so on) should be sufficient for any application.
- The format should allow generic and reusable libraries for parsing and transformation.
XML is a format that solves both these problems to a large extent. It supports standard data structures such as lists, trees, and graphs. It allows generic and reusable libraries for parsing and transformation. Almost every programming language in use for business applications supports at least two varieties of XML parsers and one standard mechanism for transforming XML. We will elaborate on these parsing and transforming mechanisms in the later section.
In this section, we will introduce all aspects of XML that are required for understanding the material in the rest of the book. We’re going to cover quite a bit in this section, so if you are new to XML, get ready for a whirlwind tour. We’ll discuss:
- Use of XML to represent arbitrary data structures
- How to avoid naming conflicts using XML namespaces
- XML Schema Definition (XSD)
- XML processing with DOM API
- XPath expressions to query XML content
We will begin our tour with a description of how XML can be used to format arbitrary data structures.
2.2.1. XML data format
Listing 2.1. A sample XML document

It is easy to see that this XML document in listing 2.1 resembles a tree, as shown in figure 2.2. All the items that make up an XML document can be thought of as nodes in a tree. This includes elements, attributes, text values within the elements, and whatever else you find in XML documents. For example, comments too are nodes in the tree.
Figure 2.2. Visual representation of the sample XML document shown in listing 2.1. A well-formed XML document can always be represented as a tree. Text literals in the elements become leaf nodes. So do attributes. An attribute node, such as the Type node shown here, holds a name and a value. All other items permitted in an XML document become nodes as well. For example, comments become leaf nodes too.
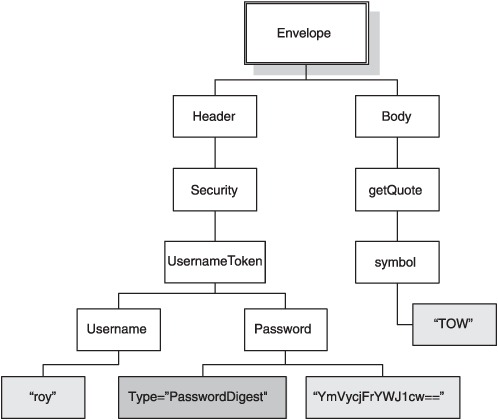
The two constraints that a well-formed XML document must satisfy are completely analogous to the two constraints a tree must satisfy. A tree should have:
- One and only one root node.
- One and only one path from the root to every node in the tree.
A well-formed XML document should have the following properties:
- It should have only one root element.
- If an element’s start tag lies within the content of another element, its end tag must also lie within that element.
We can see that the second rule of well-formedness, also known as the containment rule, is equivalent to the second rule that a tree should satisfy. Note the second rule of well-formedness can be reworded as “every non-root element lies completely within the content of one and only one element.” That is, every non-root element is a child of one and only parent. There can be one and only one path from the root element to any other element with the XML document.
But is a tree good enough to express more complex data structures such as graphs? For example, can XML be used to represent a dictionary in which terms can be hyperlinked to their meanings every time they appear? The answer is yes—let’s see how.

An XML document only looks like a tree syntactically; it may however be capturing semantically more complex structures. A common trick to achieve this is the use of identifier (ID) and identifier reference (IDREF) attributes. In the preceding example, the ref attribute of termref is an IDREF pointing to an entry element by its id. So, it is possible to represent using XML data structures more complex than a tree.
2.2.2. XML namespaces
When we use XML as data format, especially for multiple applications, one issue we face is conflicts in names. For example, two data formats might use the <account-number> tag to mark up different items. One application may use the tag to mark up a person’s bank account number, whereas another may use the same tag to mark up the person’s brokerage account number. When we are integrating these data formats into a unified format, we need to disambiguate our usage of such tags. XML namespace provides such a facility.
What is a namespace? Think of it as a clearly identifiable partition of a set of names. Two names, coming from different namespaces, are distinct even if the names are literally the same. This is made possible in XML by letting us prefix every tag name with a namespace identifier. For example, we can distinguish between the bank and brokerage account numbers if the tags that mark them up are prefixed appropriately as in <bank:account-number> and <brokerage:account-number>.
How can we ensure that two different namespaces aren’t identified by the same prefix? For example, more than one banking firm may employ the bank prefix to identify its tags. To make sure that the prefix itself is not ambiguous, we bind each namespace prefix to a Uniform Resource Identifier (URI). URIs, by definition, are guaranteed to be globally unique identifiers. For example, in the following XML, the soapenv prefix is bound to an URI containing a registered domain name to make sure that the namespace identification is unambiguous.

Namespace prefixes are bound to URIs using attributes prefixed with xmlns. Think of a URI as an opaque string that’s unlikely to be chosen by someone else to define their namespaces as well—a globally unique id. Often, people use strings that look like Uniform Resource Locators (URLs). This is primarily because registered domain names are a good way to generate readable globally unique IDs. However, there’s no requirement that a URI should look like a URL.
Namespace prefixes can qualify more than just element tags. Attribute names can be qualified as well, as shown for the encodingStyle attribute in the next example.

Note that the binding for a prefix is scoped. A binding is only valid within the element on which the binding is shown and its descendants. So, the ns1 prefix in the previous example is only bound to the shown URI within the getQuote element.
It is perfectly acceptable to rebind a previously bound prefix to a new URI. The rebinding will only be effective within the child element on which the binding is shown and its descendants. This scenario occurs when you combine different XML documents into a single document.
A default namespace can be defined as well. A default namespace within an element is defined by setting the xmlns attribute. Let us see how this works using an example.

2.2.3. XML schema
Before we move on, let’s back up and remember how we got here. We now have two of the conceptual underpinnings needed to make XML suitable as a common-denominator data format in integration.
- The concept of “well-formed” XML helps us define the constraints that every XML document from every domain should always satisfy. These constraints help us create tools such as parsers that can deal with all XML documents uniformly.
- If we think of a collection of all the element and attribute names within an application as its XML vocabulary, the concept of namespaces helps us distinguish terms of one XML vocabulary from another. Namespaces help eliminate confusion when XML is exchanged between applications.
Two additional constructs are clearly needed to ensure applications can indeed integrate via XML exchange.
- We need a way to clearly specify the contract that an application demands (or provides) when consuming (or producing) XML. Without such a contract, we cannot know if a particular XML document is fit for consumption by an application. Obviously, an application cannot make sense out of arbitrary XML.
- We need a way to transform (or map) the XML produced by one application to make it fit for consumption by another. Such mapping should support semantic translation from one format to another format.
The first requirement is easy; XSD language and other XML schema languages such as DTD and RELAX NG meet this requirement substantially. XSD, described in detail later, provides a language for specifying the contract an application demands from its XML providers. It answers questions such as what elements can appear, in what hierarchy, and with what content. XSD cannot explicitly spell out the semantics, of course. It cannot express all the constraints on the content either. However, it provides a starting point for assessing the validity of an XML document.
The second requirement, namely mapping, is a difficult issue. It involves lot more than simple inferences based on element and attribute names. To map one XML vocabulary into another, we need to know not only the terms but also the semantics of each element and attribute.
Obviously, mapping wouldn’t be needed if both applications used the same XML vocabulary and semantics. That usually happens to be the case if both applications are from the same vendor or if adequate standardization of XML vocabularies and semantics has happened within a particular domain. You can see such a standardization with SOAP, which pins down the vocabulary and semantics for use in SOAP servers and clients.
Listing 2.2 shows an extract from an XML schema describing a SOAP 1.1 envelope. We will be discussing SOAP later in this chapter.
Listing 2.2. Extract from the XML schema [1] describing a SOAP 1.1 envelope
1 This schema is sourced from http://schemas.xmlsoap.org/soap/envelope/ and is copyrighted by Martin Gudgin.


Here is how you should read this listing.
The targetNamespace attribute ![]() on the schema element declares the namespace to which types and elements defined by this schema belong. The other two attributes on the
schema element are simply namespace prefix bindings, as described in the previous section.
on the schema element declares the namespace to which types and elements defined by this schema belong. The other two attributes on the
schema element are simply namespace prefix bindings, as described in the previous section.
The contents of the schema element are either element declarations or data type definitions. In ![]() , the Envelope element is declared as an instance of the Envelope data type. The Envelope data type is itself defined in
, the Envelope element is declared as an instance of the Envelope data type. The Envelope data type is itself defined in ![]() . According to the definition shown in
. According to the definition shown in ![]() , an instance of the Envelope data type (such as the Envelope element declared in
, an instance of the Envelope data type (such as the Envelope element declared in ![]() ) can have a optional Header element before a Body element that must always be present in an envelope. (Note that minOccurs and maxOccurs attributes on an xs:element default to 1.) In addition, any attribute from a namespace other than the targetNamespace of this schema is allowed on an instance of the Envelope data type.
) can have a optional Header element before a Body element that must always be present in an envelope. (Note that minOccurs and maxOccurs attributes on an xs:element default to 1.) In addition, any attribute from a namespace other than the targetNamespace of this schema is allowed on an instance of the Envelope data type.
Subsequent to ![]() , we see the same pattern repeating. The Header and Body elements are declared to be of types Header and Body, respectively. The definitions for the Header and Body types describe the attributes and the content instances of these data types can/must have.
, we see the same pattern repeating. The Header and Body elements are declared to be of types Header and Body, respectively. The definitions for the Header and Body types describe the attributes and the content instances of these data types can/must have.
We also see that XSD allows in-line annotations that can be used to describe the contents of a schema.
As you can see, XSD specifies the syntactic structure of an XML document only. For example, the preceding specification does not tell us what goes in the body and what goes in the header. It is good enough for several purposes—notably for specifying abstract types in WSDL, which we will be using later for describing web services.
2.2.4. Processing XML
A common denominator data format such as XML should be easy to create, parse, and modify. In this section, we will very briefly mention some of the options available to application developers for processing XML. We will also show an example using W3C DOM, an API almost all the examples in this book rely on for XML processing. The material in this section is too brief to be sufficient if you have no prior experience in processing XML. The “Suggestions for further reading” section at the end of this chapter lists books and online resources you can use to learn more about XML processing.
Different applications will have different needs when processing XML. Performance may be critical for some applications, whereas ease or speed of development may be more important for others. Given this, multiple XML processing libraries are available from which application developers can pick the one that best fits their needs.
Broadly, XML processing libraries can be classified into two categories.
- Those that create or load the entirety of data in an XML document into memory. Document Object Model (DOM) APIs standardized by W3C (across multiple languages including Java) are most popular for libraries that create or load the entirety of the XML document in memory.
- Those that produce/consume the documents incrementally. These are commonly referred to as stream-based or streaming processors. Simple API for XML (SAX) and Streaming API for XML (StAX) are two different standard APIs for libraries that allow incremental parsing of documents.
DOM-based processors are obviously heavy on memory usage and not particularly suitable for server-side applications that need to concurrently process a large number of XML documents. However, they are still used in a large number of server-side applications, because processing logic in most applications is too complex to be implemented using a pure stream-based processor. For example, Apache Axis 1.x, the SOAP toolkit we introduced in section 2.1, uses DOM processing. Axis 2.x (which is still in the works at the time of writing this chapter) moves away from DOM to provide better performance.
Because most example code in this book relies on DOM APIs, we provide a very brief overview of DOM APIs here. This introduction is limited to the bare minimum required to understand the sample code in this book. You should refer to other books and online resources for a more comprehensive introduction to DOM APIs.
Basic DOM classes and interfaces can be found in the org.w3c.dom package. DOM looks upon an XML document as a tree of Node instances. Everything in a document tree is a Node—be it an element, attribute, text, comment, or the document itself. To be more precise, Node is a Java interface implemented by classes such as Element, Attr (attribute), Text, Comment, and Document.
The root element of the tree can be accessed using the getDocumentElement() method of a Document instance. You can traverse from any node in the tree to every other node using methods such as getParentNode(), getChildNodes(), getPreviousSibling(), and getNextSibling().
Attributes are not considered to be child nodes of the element they belong to. To get the attributes defined for an element, use the getAttributes() method to get a NamedNodeMap. To find the element node an attribute node belongs to, use the getOwnerElement() method.
Namespace URI and local name of an element or an attribute can be queried using getNamespaceURI() and getLocalName(). The getNodeValue() method returns the character data in text or comment nodes, and attribute value in the case of Attr nodes. To get the text content in an element, one needs to iterate through the child nodes and concatenate the text content under each of them unless they happen to be comments or processing instructions. The type of a node can always be determined using getNodeType().
Here is some sample code to give you a taste of DOM-based XML processing. The method in listing 2.3 locates a child element given its parent and name.
Listing 2.3. Locating a named child element under a given DOM element

In this example, we are defining a helper method named locateChildDOMElement to locate a child element with the given name (that is, with the given namespace URI and given local name) under the given parent.
We first get the list of child nodes using the getChildNodes() method ![]() . This method returns a NodeList whose length can be determined using getLength(). We then iterate over each of the child nodes
. This method returns a NodeList whose length can be determined using getLength(). We then iterate over each of the child nodes ![]() to find the desired child element.
to find the desired child element.
As we are looking only for a child element, we need to skip over child nodes (such as comments) that are not elements ![]() . We retrieve the i-th item in the children NodeList using item(i) and check its type using getNodeType().
. We retrieve the i-th item in the children NodeList using item(i) and check its type using getNodeType().
For each child element, we compare its namespace URI and the local name against the desired values. getNamespaceURI() and getLocalName() retrieve the namespace URI and local name of a node ![]() . If a matching element is found, it is returned. If we exhaust all the child elements without finding a match, we return
null.
. If a matching element is found, it is returned. If we exhaust all the child elements without finding a match, we return
null.
As you can see, the DOM API is quite simple to use. However, it is quite verbose, not to mention tedious to work with, especially when all you want to do is identify and extract a specific item from an XML document. XPath, an expression language for identifying specific parts of an XML document, can remove some of this tedium. We will introduce XPath next.
2.2.5. XPath
When developing XML applications, one often encounters the need to clearly identify specific portions of an XML document. For example, when we selectively encrypt or sign parts of a SOAP message, there is a need to declare exactly which parts of the message have been encrypted/signed. The same need arises when transforming an XML document or selectively validating a portion of it. When transforming, we need to identify which portions of the source document need to be mapped into the destination document. When selectively validating portions of an XML document, we need the ability to point out exactly which fragment or set of fragments needs to be validated.
XPath provides a standard mechanism for identifying parts of an XML document. It takes advantage of the fact that XML documents resemble trees structurally. A node in a document can be identified using the path to that node from the root or any other previously identified node. If the path is from the root node, it is known as an absolute path. Otherwise, a path is said to be relative to the current context. Let us look at a few easy examples.
- /soapenv:Envelope/soapenv:Header is an absolute path because it provides the path from the root (represented by the leading /) to the Header.
- If soapenv:Body is the current context, ns1:getQuote/@soapenv:encodingStyle refers to the encodingStyle attribute on the Quote element. The symbol @ is used to refer to attributes.
As you can see, a path is made up of a series of steps. In both examples, the steps are away from the tree’s root toward the leaves. As trees in programming books are always drawn with the root at the top and leaves at the bottom, we can say that each step in these examples is down the tree. Can we go up as well? Of course!
- To go one step up, to the parent of the current node, use .. (two dots).
- To get to any ancestor, prefix the step with ancestor::. For example, to reach the Body node from anywhere beneath it, you can say ancestor:: soapenv:Body. Prefixes such as this that allow you to specify the direction of traversal are referred to as axis specifiers.
- Similarly, you can go sideways using the axis specifiers sibling::, following::, and preceding::.
Notice that the axis specifiers not only allow you to traverse the tree in directions other than down, but also to travel more than one node at a time. When we search for the Body element from anywhere beneath it using ancestor::soapenv:Body, we may be traveling over multiple nodes to reach the Body node. Can we gallop the same way down the tree?
- We can travel one or more levels down the tree using two slashes instead of one. For example, //ns1:getQuote searches the getQuote element anywhere below the root.
- Just as in the case of other axes, we can use the descendant:: axis specifier. For example, /descendant::ns1:getQuote is equivalent to //ns1:getQuote.
We now have the machinery to move around the tree and identify elements and attributes by their names. What if we want to select a particular element when there is more than one element with the same name in the current context? For example, how do we choose a particular Security element in the following Header?
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:wsse="http://schemas.xmlsoap.org/ws/2002/04/secext">
<soapenv:Header >
<wsse:Security>
...
</wsse:Security>
<wsse:Security
soapenv:actor="http://schemas.xmlsoap.org/soap/actor/next">
...
</wsse:Security>
<wsse:Security
soapenv:actor="http://manning.com/xmlns/samples/soasecimpl/hub">
...
</wsse:Security>
</soapenv:Header>
<soapenv:Body>
...
</soapenv:Body>
</soapenv:Envelope>
We can pick a Security element by its position. For example, if /soapenv:Envelope/soapenv:Header is the current context, use wsse:Security[1] to pick the first Security element.
But the selection criteria we need to express are often much more complicated. XPath provides a detailed expression syntax that can be used to specify predicates. For example, to select a Security element whose actor attribute has a particular value, we can use the XPath:
wsse:Security[ @soapenv:actor="http://manning.com/xmlns/samples/soasecimpl/hub" ]
We can use Boolean algebra as well. To select all Security elements whose actor attribute has one of two values, we can use the XPath:
wsse:Security[ @soapenv:actor="http://manning.com/xmlns/samples/soasecimpl/hub" or @soapenv:actor="http://schemas.xmlsoap.org/soap/actor/next" ]
XPath also defines a few functions to help in creating more complex expressions. To select Security elements that do not have an actor attribute, we can use wsse:Security[count(@soapenv:actor)=0], or more succinctly, wsse:Security [not(@soapenv:actor)].
A more exhaustive description of XPath is outside the scope of this book. The description found here should, however, be sufficient for understanding its use in the rest of the book.
This concludes our discussion of XML basics. XML seems simple at first glance, yet is surprisingly rich and complex. In spite of this complexity, XML has gained popularity, as a number of libraries and tools are available in almost every programming language to help tackle the complexity in XML.
The near-universal acceptance of XML as a common denominator data format led to the development of XML-based integration technologies. The B2Bi[2] community was the first one to adopt XML in a big way for integration. Several B2Bi protocols such as RosettaNet and ebXML use XML messaging for integration between trading partners. Their success caught the attention of the distributed computing[3] community as well. This led to the development of XML-based distributed computing protocols such as XML-RPC and SOAP. With the backing of industry heavyweights such as Microsoft and IBM, SOAP gained a lot of momentum. Over time, SOAP became independent of its roots in distributed computing and is currently used for distributed computing as well as message-based integration. SOAP inspired the idea of web services, which in turn inspired the idea of SOA. As you can see, XML played a very influential role in the evolution of SOA.
2 B2Bi stands for Business-to-Business integration. B2Bi involves integration of the applications in an enterprise with the applications of its supply chain partners—be they suppliers, distributors, or other businesses that are customers. B2Bi is almost always implemented through exchange of messages (commonly referred to as “documents” in B2Bi) over transports such as FTP and HTTP. Popular B2Bi protocols are EDI, AS2, RosettaNet, and ebXML.
3 Distributed computing technologies strive to make code in one application usable by code in another application running on a remote machine. Examples of distributed computing technologies include DCOM (Distributed Component Object Model) and CORBA (Common Object Request Broker Architecture).
Some of the material you have seen in this section, such as XML namespaces, is essential for anyone trying to understand SOAP and related technologies such as WSDL. The rest of the material we have covered in this section will be helpful for you to follow the code listings in this and later chapters. Now that we have covered XML basics, we can turn our attention to understanding the basics of SOAP.
2.3. SOAP basics
SOAP is the core protocol that underlies most web services implementations. In this section, we’ll cover basic SOAP concepts. In particular, we will describe:
- SOAP message exchange model
- Anatomy of a SOAP message
- RPC with SOAP[4]
4 RPC is one of the first technologies that simplified distributed computing. It provides a way to invoke a function on the remote machine, as though it were available in the same process. Toolkits generate the code that does the heavy work: argument marshaling, sending over the wire, getting the response, and returning to the function. Since XML did not exist at that time, the protocol between RPC server and RPC client is implementation-specific.
- Use of SOAP for document exchange between applications
- Error (fault) handling in SOAP
Let’s start with the first of these—the SOAP message exchange model.
2.3.1. SOAP message exchange model
SOAP provides a standard model for exchange of messages between applications. Key elements of this model are:
- A SOAP message is a transmission from one endpoint to another. Two tranxxsmissions can be combined synchronously or asynchronously to make a request/response. Similarly, multiple transmissions can be combined to make a conversation.
- A SOAP message is created by wrapping any application message with a standard XML-based envelope structure. The envelope structure enables applications to express semantics such as what is in the message and how it is encoded.
- All error handling is carried out using a standard SOAP Fault mechanism.
- When making RPC calls and responses, application messages are structured using the conventions defined by SOAP.
- Data within the application message may be serialized using a standard SOAP-defined encoding. Other encodings may be declared and used as well.
As you can see, SOAP is a higher-level protocol than application-layer transport protocols such as Hypertext Transfer Protocol (HTTP). A SOAP message can hence be carried as a payload of any application transport. For example, applications can exchange SOAP messages using Java Messaging Service (JMS) or even File Transport Protocol (FTP).
The current version of the SOAP specification is 1.2. WS-I, an organization working to enhance interoperability among web services implementations, is basing its work on SOAP 1.1. They are tightening the specifications of basic web services standards under the name Basic Profile. Given that more than 170 organizations including Microsoft and IBM are driving WS-I, it is quite likely that the focus will remain on SOAP 1.1 for a while to come. For good reason, the examples shown here are all based on 1.1. We will point out any major changes from 1.1 to 1.2 as we discuss the details.
2.3.2. Anatomy of a SOAP message
SOAP messages are XML documents with the following structure:

The root element of a SOAP message must always be an Envelope ![]() element that is defined in a namespace whose URI
element that is defined in a namespace whose URI ![]() is defined by the SOAP specification. The Envelope element consists of an optional Header element
is defined by the SOAP specification. The Envelope element consists of an optional Header element ![]() followed by a mandatory Body element
followed by a mandatory Body element ![]() .
.
The Header element ![]() may contain one or more entries that can be used to extend SOAP and/or express additional application semantics. For example,
user credentials and security assertions may be carried using header entries to extend SOAP for security. Similarly, a correlation
identifier may be carried within a Header element to provide request/response semantics. We’ll discuss the use of Header entries extensively in the next chapter.
may contain one or more entries that can be used to extend SOAP and/or express additional application semantics. For example,
user credentials and security assertions may be carried using header entries to extend SOAP for security. Similarly, a correlation
identifier may be carried within a Header element to provide request/response semantics. We’ll discuss the use of Header entries extensively in the next chapter.
The Body element ![]() is where the application messages are carried. The only constraint on the content of a Body element cannot carry free text by itself. It should have only XML elements as its content. It is also possible to have no
text at all. In other words, the Body element cannot carry free text by itself; at least, the text to be carried should be encapsulated in an XML element.
is where the application messages are carried. The only constraint on the content of a Body element cannot carry free text by itself. It should have only XML elements as its content. It is also possible to have no
text at all. In other words, the Body element cannot carry free text by itself; at least, the text to be carried should be encapsulated in an XML element.
How to interpret the content of a SOAP message Body is up to the receiving application. In the next two sections, we will describe two popular ways of interpreting SOAP Body content.
2.3.3. RPC with SOAP
As we discussed in chapter 1, SOA makes distributed computing possible with services that can be invoked anywhere. Traditionally, such distribution happened with RPC. In this section, we will see how SOAP can be used for RPC. In the next section, we will see how SOAP can be used for message-based integration.
In SOA, applications make it possible for their capabilities to be integrated with those of others by exposing their capabilities as services. For the sake of simplicity, let’s say that an application wants to expose one of its functions as a service that other applications can invoke. What should it do so that other applications can invoke such a function?
- It must specify a function name.
- It must specify the signature of the function. The signature specifies the types of the arguments and the return value.
- It must specify the application instance. Remember that there can be many instances of the same application providing the service.
Obviously, the service and clients need to agree on a consistent way of representing or encoding this information. Let us see how this works with an example.
Consider the following request/response transmissions:

What these messages do is self-evident. The first message is a remote call to get the quote for the symbol MSFT, and the second message is the result of that call.
The target instance in which a function is to be invoked is identified by a URI. The SOAP message itself does not carry the URI. The underlying application transport is relied upon to carry the URI instead. For example, if we use HTTP to carry these messages, the URI may be carried using the target URL of the request and/or an additional header named SOAPAction, as shown in listing 2.4
Listing 2.4. A SOAP RPC request sent over HTTP

The function call is represented as a single structure. The function name becomes the name of the structure, and each of the function’s input and in/out parameters become top-level members of the structure. For example, in listing 2.4, getQuote is the function name, symbol is an input parameter, and there are no in/out parameters.
Similarly, the function’s response is modeled as a single structure. The return value along with the function’s out and in/out parameters, if any, become top-level members of the response structure. The names, types, and order of parameters in the function’s signature are preserved within the call/response structures. The return value is always the first top-level member of the response structure.
SOAP encoding
When using SOAP for RPC, the function call and response structures can be encoded using any scheme understood by the service and its clients. The scheme used for encoding data within any element of the SOAP message may be indicated by adding the SOAP-defined encodingStyle attribute to that element. The value of this attribute should be a list of one or more URIs that indicate the encoding schemes used within the element. When decoding, the receiver should try each of the schemes listed in the same order as they appear.
Just like XML namespace prefix bindings, an encoding style holds good for all content within the element unless it is specifically overridden by a different or empty encodingStyle attribute on a subelement. No encoding is assumed by default.
SOAP defines one possible RPC encoding. It is identified by the URI: http://schemas.xmlsoap.org/soap/encoding/ and is referred to as SOAP encoding. For example, the RPC request and response payloads shown in the beginning of this section use SOAP encoding.
SOAP encoding defines rules for serializing[5] simple and compound values. Compound values are formed by combining simple values that can be addressed by index (as in arrays) or by name. Serialization of complex object graphs is made possible by what are known as multiRefs. The easiest way to understand multiRef is by looking at an example, such as the one in listing 2.5
5 Serialization (or marshaling) is the process of converting a data structure into a sequence of bytes or characters.
Listing 2.5. Example illustrating the use of multiRef in SOAP encoding

In this example, note the use of the id attribute ![]() to assign an identifier to a multiRef and href attribute to refer to it elsewhere
to assign an identifier to a multiRef and href attribute to refer to it elsewhere ![]() . The soapenc:root attribute is used
. The soapenc:root attribute is used ![]() to distinguish true roots of the encoded object graph from others. That is, when it is 0, the node is assumed to not be the
root of the object.
to distinguish true roots of the encoded object graph from others. That is, when it is 0, the node is assumed to not be the
root of the object.
As you might already have observed, use of multiRefs clearly makes SOAP messages hard to read and understand by simple inspection. However, if we allow the serialization of complex data types commonly found in real-world applications, we find a need for multiRefs. Obviously, the use of tools is a must for managing encoding and decoding data structures in RPC calls. Still, tools cannot solve all problems. Data structures created in one programming language may not have good equivalents in other programming languages. In such cases, RPC is clearly not the best way to integrate two applications via SOAP. In the next section, we present an alternative technique to RPC.
2.3.4. Document exchange with SOAP
As we discussed earlier, message-based integration is as popular as RPC, if not moreso, for application integration. SOAP accommodates both approaches to integration under one model. The body of a SOAP message can carry any XML-based content as the payload. For example, a RosettaNet document can be embedded as the body of a SOAP message.
Let us rewrite the SOAP Body from the RPC example in the previous section (see listing 2.5) to use document exchange instead. The document we are submitting is called MarketOrderSubmission, which specifies what stock to buy or sell and in what quantity. It might appear similar to the RPC example—however, the model of programming is different. In RPC, applications invoke functions on endpoints, whereas here, the document is sent to the endpoint. As such, a data-centric model of processing would use document exchange.
<soapenv:Body>
<ns2:MarketOrderSubmission>
<ns2:symbol>GOOG</ns2:symbol>
<ns2:buyOrSell>buy</ns2:buyOrSell>
<ns2:quantity>200</ns2:quantity>
</ns2: MarketOrderSubmission>
</soapenv:Body>
Request-response is possible too. For example, here is how the SOAP Body may look in response to the MarketOrderSubmission document.
<soapenv:Body>
<ns2:MarketOrderReceipt>
<ns2:orderId>72379</ns2:orderId>
</ns2:MarketOrderReceipt>
</soapenv:Body>
How should an application respond to a SOAP message if it encounters an error while processing it? You’ll find out next.
2.3.5. SOAP Fault
SOAP defines a standard SOAP Fault mechanism to communicate error information back to a caller. The mechanism can be used in RPC as well in messaging. Let us start with an example.
<soapenv:Envelope ...>
<soapenv:Body>
<soapenv:Fault>
<faultcode>soapenv:Server</faultcode>
<faultstring>Internal Server Error</faultstring>
<detail>
<e:exception
xmlns:e=
"http://manning.com/xmlns/samples/soasecimpl/exception">
<class>java.sql.SQLException</class>
<message>Database connection lost</message>
</e:exception>
</detail>
</soapenv:Fault>
</soapenv:Body>
</soapenv:Envelope>
As you can see, a Fault element is returned within the Body to indicate that an error has occurred. Contents of the Fault element provide more information about the error.
The faultcode element is a machine-readable indication of what went wrong. A namespace-qualified name is what SOAP 1.1 mandates as the value. Table 2.5 shows the four faultcode values predefined in the SOAP 1.1 envelope namespace.
Table 2.5. The four faultCode values predefined by SOAP 1.1 specification
|
Description |
|
|---|---|
| soapenv:VersionMisMatch | The SOAP envelope element is not in the expected namespace. This might happen if the sender is assuming a different version of the SOAP spec. |
| soapenv:MustUnderstand | A Header entry that was marked as mustUnderstand is not understood by the receiver. We will revisit this more in depth when we discuss headers in the chapter 3. |
| soapenv:Client | The client made a mistake in composing the message. For example, the client may have provided no value for a mandatory parameter in a RPC method call. |
| soapenv:Server | The server encountered an internal error. For example, a database connection needed to provide the service might be temporarily down. |
SOAP 1.1 allows for a hierarchy of faultcode values. To specify an error subclass along with a more generic faultcode, SOAP 1.1 recommends the ns:generic-FC.specificFC convention. Interoperability experts will discourage you from attempting to extend the four predefined faultcode values because two applications can easily use the same subclass to express two semantically different errors. Hierarchical faultcode values are however encouraged for faultcode values defined in custom namespaces. Listing 2.6 is an example.
Listing 2.6. Example of a SOAP 1.1 Fault

The faultstring element ![]() is a description of the error. It is mandatory. An optional faultactor element (not shown in the listing, as we have yet to define the concept of an actor; chapter 3 will discuss this concept) takes a URI value to indicate the source of the error. The detail element
is a description of the error. It is mandatory. An optional faultactor element (not shown in the listing, as we have yet to define the concept of an actor; chapter 3 will discuss this concept) takes a URI value to indicate the source of the error. The detail element ![]() is reserved and mandatory for errors related to Body content.
is reserved and mandatory for errors related to Body content.
The SOAP fault mechanism has seen substantial refinement from SOAP 1.1 to SOAP 1.2. Listing 2.7 shows how it looks in SOAP 1.2.
Listing 2.7. Example of a SOAP 1.2 Fault


Notice the change in namespace URI ![]() between listings 2.6 and 2.7 to indicate that the latter is a SOAP 1.2-compliant envelope. SOAP 1.1 faultcode gives way to a more elaborate Code element
between listings 2.6 and 2.7 to indicate that the latter is a SOAP 1.2-compliant envelope. SOAP 1.1 faultcode gives way to a more elaborate Code element ![]() in SOAP 1.2.
in SOAP 1.2.
SOAP 1.1 faultstring ![]() gives way to a more elaborate Reason element that allows for multilingual error messages through the use of the xml:lang attribute.
gives way to a more elaborate Reason element that allows for multilingual error messages through the use of the xml:lang attribute.
The Code element is a machine-readable indication of what went wrong. The SOAP 1.2 spec adds one more value, soapenv:DataEncodingUnknown, to the four predefined faultcode values in SOAP 1.1. This code is used if one of the data encodings, declared with URIs as shown previously, is not understood by the application that needs to process the encoded data. In addition, SOAP 1.2 renamed the soapenv:Client and soapenv:Server values as soapenv:Sender and soapenv:Receiver, respectively.
Hierarchical error codes are supported by one or more nested Subcode elements. There are a few other changes from SOAP 1.1 to SOAP 1.2, some of which can be observed from the previous example. For example, the soapactor element is replaced with Node and Role elements. We’ll talk more about them in chapter 8.
So far we have seen how SOAP can be used to communicate between two applications. How does an application know what kind of message to send? In our getQuote example, how does the client know that it is supposed to send a stock symbol as a string? We need a way of specifying what the server expects—a contract that the server publishes for the client to use. WSDL serves that purpose for SOAP, and it is the subject for the next section.
2.4. WSDL basics
Formally describing a service helps establish a clear contract between the service and its clients. To describe a service, we need a declarative language. It is common practice in programming systems to generate required procedural code from a single declarative description. Interface Definition Language (IDL) did this job for CORBA and WSDL does it for the web services world. WSDL has a role in SOA security as well, by providing a possible vehicle to carry the security (and other) policies for a service.
WSDL builds upon several other abstractions such as endpoints, ports, and services. All these abstractions support a generic way of specifying the protocols and data formats. To make it easy to understand, we will provide a top-down example-driven explanation for WSDL. Specifically, we’ll cover:
- How to declare a service
- The concepts of port type and port
- The concept of a binding
Although WSDL can be used to describe services offered using any protocol and data format (see the callout at the end of this section), we will only focus on the use of WSDL with SOAP as the protocol.
2.4.1. Describing a service with WSDL
The example we use here is available in the examples archive under code/wsdl/example1.wsdl. The first point to note from this example is that WSDL uses <wsdl:definitions> as the root element. Coming from the bottom of the file, here is the last element:

This element is declaring a service named BrokerageService ![]() . It contains details about a port
. It contains details about a port ![]() , and an address
, and an address ![]() . WSDL defines a service as collection of related ports.
. WSDL defines a service as collection of related ports.
2.4.2. Understanding ports and port types
Think of a port as a specific implementation of an interface (port type), available at a particular address using a particular protocol and a particular data format.
What are related ports? A service may offer the same interface over different protocols. It may even offer a set of complementary interfaces over one or more protocols. Any logical grouping of ports qualifies as a service as long as they are not interdependent.
In the example BrokerageService, we can see the address at which a port named example1 is available ![]() , but where’s the rest of the information, such as interface (port type) name and protocol used? The binding attribute on the <wsdl:port> element refers to a previously declared binding element that provides this information.
, but where’s the rest of the information, such as interface (port type) name and protocol used? The binding attribute on the <wsdl:port> element refers to a previously declared binding element that provides this information.
2.4.3. Understanding bindings
A binding defines the protocol and data format details for all the methods (operations) defined in an interface (port type).
Listing 2.8. WSDL binding in action

In listing 2.8, we see how a binding is defined ![]() . The example defines a binding named example1SoapBinding for the impl:Brokerage interface (port type). The binding specifies that it uses SOAP RPC over HTTP
. The example defines a binding named example1SoapBinding for the impl:Brokerage interface (port type). The binding specifies that it uses SOAP RPC over HTTP ![]() as the transport protocol for operations defined by the interface.
as the transport protocol for operations defined by the interface.
In addition, this binding defines per-operation details such as SOAPAction ![]() and input/output data formats. SOAPAction is an HTTP header that may be used to succinctly convey the intent of a SOAP message. It is useful for HTTP infrastructure
elements such as load balancers and routers to act on an HTTP request without having to look into the SOAP message itself.
and input/output data formats. SOAPAction is an HTTP header that may be used to succinctly convey the intent of a SOAP message. It is useful for HTTP infrastructure
elements such as load balancers and routers to act on an HTTP request without having to look into the SOAP message itself.
Although it is obvious from this binding as to what operations constitute the impl:Brokerage interface, it is helpful to define the interface separately. This helps in detecting erroneous bindings, especially if there are multiple bindings for the same interface that can contradict each other as to what operations make up the interface. WSDL refers to an interface and its methods as port type and operations, respectively. Listing 2.9 shows how a port type is declared.
Listing 2.9. Declaring a port type

In this example, we are defining the operations provided by the Brokerage port type ![]() . For each operation
. For each operation ![]() , we are identifying the input and output message types by reference, indicating that these are request-response operations.
We would have omitted the output definition if any of the operations were one-way. For request-response operations, we can
add a fault message type as well.
, we are identifying the input and output message types by reference, indicating that these are request-response operations.
We would have omitted the output definition if any of the operations were one-way. For request-response operations, we can
add a fault message type as well.
A message defines a named collection of typed parts.
<wsdl:message name="createLimitOrderRequest"> <wsdl:part name="symbol" type="xsd:string"/> <wsdl:part name="buy" type="xsd:boolean"/> <wsdl:part name="quantity" type="xsd:int"/> <wsdl:part name="priceLimit" type="xsd:float"/> </wsdl:message>
In this example, we are defining the names and types of parts that constitute a createLimitOrderRequest message. All the parts in this message use basic types defined in the XSD specification. User-defined types can be used as well, provided they are declared within WSDL by embedding an XSD schema under a <wsdl:types> element.
<wsdl:types>
<xsd:schema>
...
</xsd:schema>
</wsdl:types>
Now that you understand how WSDL is written, in the next section we are going to show you how to use WSDL to generate skeletal code for web service implementations and invocations.
Note: WSDL is not just for SOAP-based services
WSDL can be used to describe services bound to any protocol and data format, not just SOAP. For example, WSDL can be used to describe the services offered by an Enterprise JavaBean (EJB). WSDL makes this possible by explicitly allowing extensions to describe protocol and data format bindings. Anyone can extend WSDL to describe services provided by existing applications using native protocols and data formats.
2.5. Web services in action with Apache Axis
Now that we understand the basics of XML, SOAP, and WSDL, let’s revisit the example in figure 2.1 (hereafter referred to as example 1). The goal is not only to better understand what happened in example 1, but also to see how we went about creating it. In this section, we will walk you through the process of creating and consuming a web service with Apache Axis.
2.5.1. Creating a web service
Example 1 illustrates RPC with SOAP. It illustrates the services a stock brokerage may offer to its customers. We will describe all the steps in creating web services:
- Defining the Java interface for brokerage services
- Converting the service interface into WSDL
- Implementing the service
- Deploying the service
We will also show you, as required, snippets of code for each of these steps.
Defining the service interface
The first step in the process is to identify the interfaces for services we want to offer. In other words, we want to create the WSDL for brokerage services. We can hand-code WSDL, but often, it is more convenient to generate WSDL using a tool. This is especially the case if we have pre-existing applications whose interfaces we wish to make available via SOAP.
Axis provides a Java2WSDL tool to generate WSDL from Java interfaces. So, let’s first create a Java interface describing the services we want to offer as a brokerage, as shown in listing 2.10.
Listing 2.10. Sample brokerage service

In this interface, we are describing three methods: getQuote ![]() , createLimitOrder
, createLimitOrder ![]() , and createMarketOrder
, and createMarketOrder ![]() . Some methods
. Some methods ![]() ,
, ![]() need additional information such as the person placing the order, which is assumed to be available from MessageContext. Because we want to use this interface as the basis for a JAX-RPC service, we follow the JAX-RPC rules by making the interface
extend java.rmi.Remote and by declaring that all of the interface methods can potentially throw a java.rmi. RemoteException.
need additional information such as the person placing the order, which is assumed to be available from MessageContext. Because we want to use this interface as the basis for a JAX-RPC service, we follow the JAX-RPC rules by making the interface
extend java.rmi.Remote and by declaring that all of the interface methods can potentially throw a java.rmi. RemoteException.
Note: Interfaces involving complex data types
Note that all of the methods in the interface defined by listing 2.10 use simple data types such as String and int for input and output. A more realistic implementation would:
- Involve objects such as Quote, Order, and OrderInstruction.
- Provide a lot more methods such as getOrderStatus(orderId) and modifyOrder(orderInstruction).
The use of complex objects as opposed to simple types certainly complicates the process of invoking them via SOAP. In some cases, custom serializers and extractors may have to be written to help Axis determine how to marshal and unmarshal such data types. But as this is simply a brief introduction and not an exhaustive reference on how to do RPC with SOAP using Axis, we will keep it simple.
Now that we have the Brokerage interface defined in Java, let’s convert it into WSDL.
Converting the interface to WSDL
The Ant script available in the examples archive provides a java2wsdl target. Run it with the command ant java2wsdl. You should now be able to find the produced example1.wsdl under the build/generated folder.
The Java2WSDL functionality in Axis comes with a minor limitation. As Axis relies on Java reflection to determine the methods declared in the interface, it does not have access to the parameter names in each method. All it can figure out using reflection are the method parameter types and order. So, Axis-produced WSDL uses manufactured names such as in0 and in1 for the parameters. If we want to restore the appropriate parameter names so as to make the resulting WSDL more human-readable, we will need to hand-edit the generated WSDL and fix the parameter names. You can observe this by comparing the generated build/generated/example1.wsdl with wsdl/example1.wsdl found in the examples archive.
Implementing the service
Now that we have declared what the service provides through its interface definition, it is time to implement it. Axis provides a WSDL2Java tool to assist in implementing the service and testing it. The Ant script available in the examples archive provides a wsdl2java target to use this tool. Run it using the command ant wsdl2java. This will produce:
- Server-side artifacts we can use to implement the service
- A deployment descriptor needed to deploy the service on Axis
- Client-side stubs we can use in the next section to consume the service
- A template for JUnit test cases that exercise the service
The folder build/generated/com/manning/samples/soasecimpl/example1/ contains the generated files. To implement the service, we edit the generated service implementation template, Example1SoapBindingImpl.java.
See java/com/manning/samples/soasecimpl/example1/ in the examples archive for a sample implementation. The implementation class can implement the javax.xml.rpc.server.ServiceLifecycle interface if nontrivial initialization and cleanup are needed. For example, the service may need a database connection pool to be initialized before any requests can be served.
Note that the service implementation is completely independent of native Axis APIs; the code is portable to other JAX-RPC-compliant SOAP engines. The deployment descriptors and client-side stubs generated by WSDL2Java are, however, Axis specific. This is not a problem, as:
- Every SOAP toolkit will provide tools similar to WSDL2Java to generate the deployment descriptors and client-side stubs.
- The base interface provided by the generated stubs to the client applications will be the same between all JAX-RPC compliant engines.
The service implementation as well as the client application code can be moved from one JAX-RPC-compliant SOAP toolkit to another simply by regenerating the deployment descriptors and client-side stubs.
Deploying the service
To deploy the service, you will need to make the server-side classes, libraries, and deployment descriptors available to Axis as follows:
- Start Tomcat in case it not already running.
- Run the command ant deploy. The Ant script packages the classes needed as a jar file that is then copied to the webapps/axis/WEB-INF/lib/ folder of Tomcat. In addition, the script transmits a deployment descriptor generated by wsdl2java to the AdminService of Axis.
- Restart Tomcat.
Now that we have deployed the web service, let’s see next how we can invoke it. In fact, we will see how we can invoke it from .NET as well to show the interoperability of SOAP and WSDL standards.
2.5.2. Consuming a web service
What we have done so far is to make the service available to a client. The client application can be anything: it can be a desktop application running on the desk of the traders, a web application available to the end users, or it can be invoked by other applications. Different application developers may wish to use the service in different ways. The way they invoke the service depends on the amount of knowledge they have about the service at design time.
There are three different mechanisms to make use of the service:
- Via the client stubs In this mechanism, the client application developers have access to WSDL. Using this information, integrated development environments (IDES) can provide design-time checks to make sure that the clients are invoking the service with appropriate arguments. In addition, the IDE can use the WSDL at design time to hide the details of invocation of the service.
- Via dynamic proxy If the client application developers have only access to the server-side interface when developing, it can still use it to provide client-side validation. That is, the IDE can help, at design time, to validate the arguments. However, since WSDL is only available at runtime, the code has to resolve the service details such as where it can be invoked at runtime only, via dynamic proxy.
- Via Dynamic Invocation Interface (DII) If an application does not know the interface or WSDL at design time, it can still invoke the service by getting the WSDL at runtime. In that case, the IDE cannot help in validating the arguments. The client application needs to take care of the details of getting the service information and signature of the operation and invoking the service.
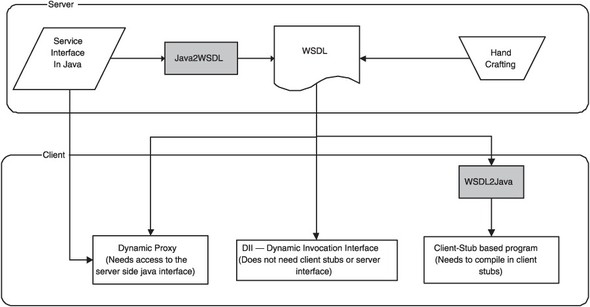
Figure 2.3 provides an overview of the three mechanisms.
Figure 2.3. Three different ways of consuming web services using JAX-RPC: (from right to left) via stubs pregenerated from WSDL by a tool, via Dynamic Invocation Interface (DII), and via a Dynamic Proxy of the service interface
Pregenerated client stubs
Can we hide from a client application the fact that a service implementation may be remote? If we can, the client application can use the same code to access a remote service implementation as it would to access a local one. This is partially made possible by tools such as WSDL2Java.
Tools such as WSDL2Java generate a class that implements all the service interface methods to simply forward each method call to the real service implementation using SOAP RPC. Such generated classes are known as client stubs. Client applications need to do just a little more work invoking remote services than they need to invoke a local implementation if they use stubs. They need to locate a stub instance first. But once they do that, they can use the stub as if it were a local instance of the service implementation class. Listing 2.11 is an example.
Listing 2.11. Service invocation using pregenerated stubs
Example1SoapBindingStub stub = (Example1SoapBindingStub) new BrokerageServiceLocator().getexample1(); float quote = stub.getQuote();
JAX-RPC mandates that stubs should also implement the javax.xml.rpc.Stub interface. This additional interface allows the client application to dynamically configure the stub instance with properties such as username, password, and service endpoint address.
Dynamic proxy
Can we avoid pregenerating stubs so as to make a client application completely portable between different JAX-RPC compliant SOAP toolkits? The answer is yes if the following two requirements can be met.
- The toolkits need to generate at runtime an object that implements a given service interface.
- The generated object should of course forward each method call to the real service implementation using SOAP RPC.
Listing 2.12 shows an example of the use of a dynamic proxy to avoid the pregeneration of toolkit-specific client-side stubs.
Listing 2.12. Service invocation using dynamic proxy

A client wishing to invoke a service using the dynamic proxy technique can identify the service to invoke by specifying ![]() the WSDL location and the namespace-qualified name of the service as declared in WSDL. The client application can then ask
the WSDL location and the namespace-qualified name of the service as declared in WSDL. The client application can then ask
![]() the JAX-RPC implementation to generate a dynamic proxy that implements the Brokerage interface (shown in listing 2.10). Once the client application gets a dynamic proxy instance, it can use it just as it would use a pre-generated stub. Invoking
a service operation
the JAX-RPC implementation to generate a dynamic proxy that implements the Brokerage interface (shown in listing 2.10). Once the client application gets a dynamic proxy instance, it can use it just as it would use a pre-generated stub. Invoking
a service operation ![]() is as simple as calling a method on the dynamic proxy.
is as simple as calling a method on the dynamic proxy.
Dynamic invocation interface
Let’s say we’re creating a generic trading client that can be configured for use with any brokerage service. As the client does not have access to a Java interface describing the service, it cannot use a dynamic proxy. A DII comes in handy in such a situation. A Call object can be used to fill in the in and in/out parameters and retrieve the out and in/out parameters after invocation. Listing 2.13 is an example.
Listing 2.13. Service invocation using DII

When using dynamic proxy (see listing 2.11), we identified the service to invoke using the WSDL location and service name. We then created a dynamic proxy implementing
the service interface so that we can invoke a specific operation using a mere method call. But here, in the case of DII (listing 2.12), as we do not have access to the service interface definition in Java, we will have to identify the operation to invoke
in a different way. Just as WSDL locations and service names identify a service ![]() , port and operation names identify a particular operation in a service. We make use of this idea in
, port and operation names identify a particular operation in a service. We make use of this idea in ![]() to create a Call object that can then be used in
to create a Call object that can then be used in ![]() to invoke the operation. Observe how in
to invoke the operation. Observe how in ![]() we are passing the arguments required by the operation as an array of objects.
we are passing the arguments required by the operation as an array of objects.
We have seen three different ways to invoke the service from Java. Can we invoke the service from other platforms? Indeed, we can use .NET to invoke the service. Even though we do not want to go into details of usage of .NET for that purpose, in the next section, we will demonstrate that a service developed in Axis can be used from .NET, fulfilling the interoperability promise of web services.
2.5.3. Using a web service from .NET
In this section, we will consume the web service developed in Axis from .NET. Thus, we check the interoperability of the brokerage service we created in the previous section. Since desktop applications are often written on Microsoft platforms using Microsoft technologies, these kinds of clients are useful for that purpose. In .NET, you can use different mechanisms to invoke a service, depending on the language. In C#, you can use all three of the mechanisms used in Java. Since our focus is to demonstrate the interoperability, we will show the easiest mechanism: using pregenerated stubs. You will need Microsoft Visual Studio .NET 2003 installed with the Visual C#.NET option to run the example described here.
Table 2.6 describes the high-level steps involved in creating a .NET-based consumer for our brokerage service.
Table 2.6. Instructions for consuming the brokerage service with a .NET-based client
|
Step |
Action |
How to |
|---|---|---|
| 1 | Start Tomcat if it is not already running. | Run shutdown and startup scripts found in the bin directory of Tomcat. |
| 2 | If the TCP monitor is not already running, start it. | Use the command ant tcpmon. |
| 3 | Open a Microsoft Visual Studio .NET 2003 command prompt. | Use the shortcut available under Start → Programs → Microsoft Visual Studio .NET 2003 → Visual Studio .NET Tools. |
| 4 | Generate the C# client stub for our brokerage service. | See the “Generating a C# client stub” section. |
| 5 | Create a simple C# client, BrokerageClient.cs, using the generated stub to retrieve a stock quote. | See the “Using a generated stub” section. |
| 6 | Compile BrokerageClient.cs and the generated stub (Brokerage-Service.cs) to produce an executable. | csc /target:exe /out:BrokerageClient.exe BrokerageClient.cs BrokerageService.cs |
| 7 | Run the generated executable to see if the interoperability indeed succeeds. |
The following two subsections show you the commands and code required for steps 4 and 5 listed in table 2.6.
Generating a C# client stub
Assuming Tomcat is listening on localhost:8080 and tcpmon is listening on port 8000, the command shown in listing 2.14 can be used to generate the C# client stub for our brokerage service.
Listing 2.14. Command for generating a C# client stub
wsdl /namespace:com.manning.samples.soasecimpl.example1 /out:BrokerageService.cs http://localhost:8000/axis/services/example1?WSDL
There are other methods of generating the stubs for .NET. You can get the IDE to generate the stubs without explicitly having to use the tools like we showed. However, the principle remains the same.
Using a generated stub
The generated C# client stub can be utilized as part of a client application, as shown in listing 2.15
Listing 2.15. Sample C# client, BrokerageClient.cs, using the generated stub to retrieve a stock quote
namespace com.manning.samples.soasecimpl.example1 {
public class BrokerageClient {
public static void Main(string[] args) {
BrokerageService service = new BrokerageService();
System.Console.WriteLine(service.getQuote("MSFT"));
}
}
}
So far we have shown how to develop, deploy, and use a service. As a developer, you must also understand what kind of services you should develop. Since there are several choices of transports and formats, as mentioned earlier, you should understand the role of standards in using services. The next section describes the choices that developers and architects face in implementing services.
2.6. Choices in service design
What we have not discussed in as much detail—so far—is service design. In this section, we will provide guidance on how you can make the right set of choices when designing services.
2.6.1. Wrap existing interfaces or design from scratch?
Several application servers and tools offer a quick way to wrap existing interfaces as services. For example, you can expose your EJBs as services. Although this allows you to quickly create “services,” this may not be the right way to go about creating services.
Considerations that go into the design of a service interface are quite different from those that go into the design of APIs. As we discussed in chapter 1, a service ideally needs to possess certain characteristics in order to be consistent with the vision of SOA. In particular, a service should represent a business capability that the service provider is offering to meet the needs of service consumers. Existing APIs may or may not fit this definition of a service; there may be a mismatch in granularity. As APIs often reflect the way a system is modularized, existing APIs are likely to be defined at a finer level of granularity than the level at which you see your business capabilities. It is important that you do not look at the job of creating service definitions as merely a technical one that can be automated by tools. Doing so will mean you are simply putting old wine in new bottles and the mileage you get out of SOA will be limited.
For these reasons, it is preferable to develop services that match the needs of the applications from a business perspective.
2.6.2. To use SOAP or not?
SOAP-based services may not always be a viable option due to reasons beyond your control. For example, your budget may not allow the cost of hardware and/or software development needed to wrap all of your legacy applications with SOAP-based interfaces. In such cases, you can still obtain most of the benefits of SOA by reorganizing all of your applications and infrastructure with services as the fundamental elements, albeit with native protocols and data formats. You can still describe the services you offer using WSDL with appropriate extension elements describing the protocol and data format bindings. Clients of your services may benefit not only because your view of your offerings now coincides with theirs, but also because they may be able to invoke your services in the same way as they would invoke SOAP-based services, thanks to frameworks such as Apache WSIF.
Note: Apache WSIF
The Apache Web Services Invocation Framework (WSIF) provides a common API to invoke any web service described using WSDL, no matter what the protocol and data format bindings are. WSIF requires a “provider” plug-in to support each type of binding. WSIF itself supplies providers needed to support invocation of web services bound to local Java classes, EJB, JMS-based applications, and Enterprise Information Systems (EIS) with J2EE Connector Architecture (JCA)-compliant adapters.
However, there are significant downsides to not using SOAP in your web services. A lot of effort has gone into the engineering of SOAP-based web services by the SOA community at large. You will not be able to take advantage of some of that work. For example, SOA security solutions are more widely developed for SOAP-based web services than for other web service implementation choices. The cost of re-engineering and adapting infrastructure developed for SOAP to your specific implementation needs to be taken into account before you can make the right choice on whether to use SOAP or not.
2.6.3. Start with WSDL or generate it?
The examples in this chapter clearly show the central role played by WSDL in the consumption of web services. Given that every toolkit comes with a tool to generate WSDL from interfaces specified in languages such as Java and C#, it is common to simply generate WSDL for each of the application interfaces. This leads to finely grained interfaces that are not optimal for providing services, as we discussed in section 2.6.1.
For example, a traditional brokerage application would probably have involved multiple steps before a market order is created.
Order marketOrder = new MarketOrder();
marketOrder.setSymbol("MSFT");
marketOrder.setBuy(true);
marketOrder.setQuantity(100);
brokerage.create(marketOrder);
If we had translated each of these method calls into a service invocation, a client would have been forced to make multiple round-trips to the server to create an order. Instead, our brokerage service offers a single method, createMarketOrder (String symbol, boolean buy, int quantity), to do the same.
You don’t necessarily have to write WSDL by hand. You can still generate it from the code for a coarsely grained interface. However, given that WSDL is the prime contract you are signing with your service’s consumers, take a look at the generated WSDL and make sure that it indeed presents the right interface. For example, when creating the brokerage service, we hand-edited WSDL generated by Axis to provide meaningful names for message parts.
2.6.4. Should security context be part of the interface?
Why don’t our createMarketOrder and createLimitOrder methods take user ID as one of their arguments? Every order that’s created should of course have an owner. However, user ID is not one of the arguments for these methods because the service should obtain it from the security context of an invocation. It is up to the security infrastructure of the service to compute and provide the security context of an invocation to the web service.
Similarly, other higher-level contexts such as a transaction context should not be a direct part of the service interface. We will discuss how these higher-level contexts can be established and used in the next chapter when we discuss SOAP extensibility via headers.
2.6.5. RPC or document exchange?
Choosing between RPC and document exchange requires an understanding of the usage patterns. Marshaling (encoding) schemes are the main source of incompatibility in SOAP implementations. As document exchange avoids the need for marshaling altogether, document exchange provides a higher degree of interoperability than RPC.
However, programming effort is higher for document exchange-based services than for RPC. Almost all SOAP engines support RPC with additional tools. The task of parsing the SOAP request payload and serializing the response pay-load is taken care of by the toolkits in case of RPC. This burden shifts to the service if it uses document exchange.
If you need to maximize interoperability, document exchange is the right choice unless the equivalent RPC interface only involves simple data types. On the other hand, if you are creating a service that is not expected to be widely exposed and if your enterprise predominantly uses a particular SOAP toolkit, RPC will make your job easier.
2.7. Related technologies: UDDI
In this chapter, we have seen how we can describe our web services, create them, and consume them. But how do we publicize them? How can others discover our services?
UDDI is a web services standard that seeks to answer these questions. UDDI provides standards for registries of businesses and services. Registries can be public, private, or shared between trusted partners. For example, some of the leading UDDI proponents host a Universal Business Registry (UBR) in which any business can register itself and its services.
UBR hasn’t really taken off, but that is because most enterprises offer web services for use within intranets and extranets only. Private and shared registries are hence currently more useful than UBR.
Registries can even interact with each other and group together in various ways. For example, registries can work together as a hierarchical group.
What is the connection between UDDI and the other standards we have discussed in this chapter? Businesses can register in UDDI registries the WSDL for each web service they offer in UDDI registries. UDDI registries categorize and classify the registered services into searchable taxonomies. Thus, they help interested consumers locate the services they need. Once a service is discovered, its WSDL can then be retrieved from a registry. Of course, once we have the WSDL, we know very well by now how to make use of it in creating a client application.
Java APIs for XML Registries (JAXR) provides a vendor-neutral API for working with UDDI registries. JAXR is to UDDI what JAX-RPC is to SOAP RPC.
2.8. Summary
By now, you are familiar with the basic technologies that make up the foundation for web services: XML, SOAP, and WSDL. This chapter is not meant as an exhaustive resource on these technologies. We provided just enough background material on these topics for you to understand the rest of the book. If you are familiar with web services, you understand these technologies already. If you are not, we recommend that you refer to other XML and web services books that are dedicated solely to these topics for a more comprehensive introduction.
By now, you also have set up the environment required to run the examples in this book. In case you have not already done so, we strongly encourage you to download and execute the example we described in this chapter. This will help you in getting the most out of examples in subsequent chapters as well. The code can be found at http://www.manning.com/kanneganti.
You are also now familiar with the considerations that go into choosing the right service interface. You understand that security context should not be a direct part of the service interface. But then, how does SOAP take care of security? From what you have seen in this chapter, SOAP doesn’t seem to be taking care of security at all. In the next chapter, you will see that SOAP doesn’t take care of security by itself. Instead, it provides extension mechanisms to build in support for additional concerns. Security is of course one big concern and a standard extension named WS-Security addresses it. In case you are wondering if we have already shown you a hook that can be leveraged to extend SOAP, recall that we have promised to dwell a lot more on SOAP Header in the next chapter. Let us go there next.
Suggestions for further reading
- The Java Community Process (JCP) website is located at http://jcp.org/en/home/index.
- JAX-RPC Specifications are available at http://java.sun.com/xml/downloads/jaxrpc.html.
- JAX-RPC 1.x is evolving into JAX-WS 2.0 as described at http://weblogs.java.net/blog/kohlert/archive/2005/05/jaxrpc_20_renam.html. You can find all about JAX-WS 2.0 at https://jax-ws.dev.java.net/.
- The XML 1.1 specification, a W3C Recommendation, is available at http://www.w3.org/TR/xml11. Grammar for Document Type Definition (DTD) is also laid down by this spec.
- “Namespaces in XML,” a W3C Recommendation, is available at http://www.w3.org/TR/REC-xml-names.
- The XML Schema specifications, W3C Recommendations, are available at http://www.w3.org/XML/Schema#dev.
- RELAX NG, another schema language for XML, is described at http://www.relaxng.org/.
- W3C DOM specifications are available at http://www.w3.org/DOM/DOMTR.
- The SAX website is https://sax.sourceforge.net/.
- Processing XML with Java, by Elliotte Rusty Harold and published by Addison-Wesley Professional in November 2002, is a good resource for learning DOM and SAX APIs. An online version is available at the author’s website, http://cafeconleche.org/books/xmljava/. The book is not new, and important developments in the last few years such as StAX are not covered. Seminar notes by the same author on StAX are available at http://www.cafeconleche.org/slides/sd2004west/stax/index.html.
- The XPath 1.0 specification, a W3C Recommendation, is available at http://www.w3.org/TR/xpath. XPath 2.0 specification is a Candidate W3C Recommendation at the time of writing this book. It is available at http://www.w3.org/TR/xpath20/.
- The SOAP 1.1 specification, a W3C Note, is available at http://www.w3.org/TR/2000/NOTE-SOAP-20000508/. The SOAP 1.2 specification, a Candidate W3C Recommendation at the time of writing this book, is available at http://www.w3.org/TR/soap/.
- All deliverables published in draft/final forms by Web Services Interoperability Organization (WS-I) are available at http://www.ws-i.org/deliverables/index.aspx. In particular, “Basic Profile” 1.1 is available at http://www.ws-i.org/Profiles/BasicProfile-1.1.html and “Simple SOAP Binding Profile” 1.0 is at http://www.ws-i.org/Profiles/SimpleSoapBindingProfile-1.0.html.
- The WSDL 1.1 specification, a W3C Note, is available at http://www.w3.org/TR/wsdl. WSDL 2.0, a Candidate W3C Recommendation at the time of writing this book, is available at http://www.w3.org/TR/wsdl20.
- The Apache Web Services Invocation Framework (WSIF) website is http://ws.apache.org/wsif/.
- Apache has recently released a rewrite of Axis named Axis2. Axis2 is based on StAX to eke out the best performance possible. Axis2 1.0 does not support JAX-RPC (or JAX-WS). Axis2 is homed at http://ws.apache.org/axis2/.
- XFire is another open-source StAX-based web services engine that is rising in popularity. XFire 1.1 does not support JAX-RPC. Support for JAX-WS is in the works. XFire is homed at http://xfire.codehaus.org/.
- The UDDI 3.0 specification, an OASIS standard, is available at http://uddi.org/pubs/uddi_v3.htm.
- The JAXR specification is available at http://java.sun.com/xml/downloads/jaxr.html.