
I wouldn’t like to build a tool that could only do what I had been able to imagine for it. | ||
| --Bjarne Stroustrup | ||
Closures are important. Very important. They’re arguably one of the most useful features of Groovy—but at the same time they can be a strange concept until you fully understand them. In order to get the best out of Groovy, or to understand anyone else’s Groovy code, you’re going to have to be comfortable with them. Not just “met them once at a wedding” comfortable, but “invite them over for a barbecue on the weekend” comfortable.
Now, we don’t want to scare you away. Closures aren’t hard—they’re just different than anything you might be used to. In a way, this is strange, because one of the chief tenets of object-orientation is that objects have behavior as well as data. Closures are objects whose main purpose in life is their behavior—that’s almost all there is to them.
In the past few chapters, you’ve seen a few uses of closures, so you might already have a good idea of what they’re about. Please forgive us if we seem to be going over the same ground again—it’s so important, we’d rather repeat ourselves than leave you without a good grasp of the basic principles.
In this chapter, we will introduce the fundamental concept of closures (again), explain their benefits, and then show how they can be declared and called. After this basic treatment, we will look in a bit more depth at other methods available on closures and the scope of a closure—that is, the data and members that can be accessed within it—as well as consider what it means to return from a closure. We end the chapter with a discussion of how closures can be used to implement many common design patterns and how they alleviate the need for some others by solving the problem in a different manner.
So, without further ado, let’s take a look at what closures really are in the first place.
Let’s start with a simple definition of closures, and then we’ll expand on it with an example. A closure is a piece of code wrapped up as an object. It acts like a method in that it can take parameters and it can return a value. It’s a normal object in that you can pass a reference to it around just as you can a reference to any other object. Don’t forget that the JVM has no idea you’re running Groovy code, so there’s nothing particularly odd that you could be doing with a closure object. It’s just an object. Groovy provides a very easy way of creating closure objects and enables some very smart behavior.
If it helps you to think in terms of real-world analogies, consider an envelope with a piece of paper in it. For other objects, the paper might have the values of variables on it: “x=5, y=10” and so on. For a closure, the paper would have a list of instructions. You can give that envelope to someone, and that person might decide to follow the instructions on the piece of paper, or they might give the envelope to someone else. They might decide to follow the instructions lots of times, with a different context each time. For instance, the piece of paper might say, “Send a letter to the person you’re thinking of,” and the person might flip through the pages of their address book thinking of every person listed in it, following the instructions over and over again, once for each contact in that address book.
The Groovy equivalent of that example would be something like this:
Closure envelope = { person -> new Letter(person).send() }
addressBook.each (envelope)That’s a fairly long-winded way of going about it, and not idiomatic Groovy, but it shows the distinction between the closure itself (in this case, the value of the envelope variable) and its use (as a parameter to the each method). Part of what makes closures hard to understand when coming to them for the first time is that they’re usually used in an abbreviated form. Groovy makes them very concise because they’re so frequently used—but that brevity can be detrimental to the learning process. Just for the comparison, here’s the previous code written using the shorthand Groovy provides. When you see this shorthand, it’s often worth mentally separating it out into the longer form:
addressBook.each { new Letter(it).send() }It’s still a method call passing a closure as the single parameter, but that’s all hidden—passing a closure to a method is sufficiently common in Groovy that there are special rules for it. Similarly, if the closure needs to take only a single parameter to work on, Groovy provides a default name—it—so that you don’t need to declare it specifically. That’s how our example ends up so short when we use all the Groovy shortcuts.
Now, we’re in danger of getting ahead of ourselves here, so we’ll pause and think about why we would want to have closures in the first place. Just keep remembering: They’re objects that are associated with some code, and Groovy provides neat syntax for them.
Java as a platform is great: portable, stable, scalable, and reasonably well-performing. Java as a language has a lot of advantages but unfortunately also some shortcomings.
Some of those deficiencies can be addressed in Groovy through the use of closures. We’ll look at two particular areas that benefit from closures: performing everyday tasks with collections, and using resources in a safe manner. In these two common situations, you need to be able to perform some logic that is the same for every case and execute arbitrary code to do the actual work. In the case of collections, that code is the body of the iterator; in the case of resource handling, it’s the use of the resource after it’s been acquired and before it’s been released. In general terms, such a mechanism uses a callback to execute the work. Closures are Groovy’s way of providing transparent callback targets as first-class citizens.
A typical construction in Java code is traversing a collection with an iterator:
// Java for (Iterator iter = collection.iterator(); iter.hasNext();){ ItemType item = (ItemType) iter.next(); // do something with item }
With a specific implementation of Collection, or an interface such as List, there may be options such as the following:
// Java for (int i=0; i < list.size(); i++){ ItemType item = (ItemType) list.get(i); // do something with item }
Java 5 improves the situation with two new features: generics and the enhanced for statement. Generics allow both to be written without casts; indeed, straightforward iteration can be written in a form that is very similar to the Groovy for loop, using : instead of in:
// Java 5
for (ItemType item : list) {
// do something with item
}The syntax may not be ideal[1]—the Java 5 designers were constrained in terms of adding keywords—but it gets the job done, right? Well, nearly. For one thing, it’s limited to Java 5—many developers still work with Java 1.4 or earlier and are forced to write a relatively large amount of code for what is such a common operation. It’s relatively simple to get this code right—but familiarity breeds contempt, and it’s all too easy to miss errors within loop constructs because you’re so used to seeing them in method after method.
A second issue with the enhanced for statement brings us closer to closures, however. Clearly it’s useful to have a for loop that iterates through every item in a collection—otherwise Groovy wouldn’t have it, for starters. (Groovy’s for statement is somewhat broader in scope than Java 5’s—see chapter 6 for more details.) It’s useful, but it’s not everything we could wish for. There are common patterns for why we want to iterate through a collection, such as finding whether a particular condition is met by any element, finding all the elements met by a condition, or transforming each element into another, thereby creating a new collection.
It would be madness to have a specialized syntax for all of those patterns. Making a language too smart in a non-extensible way ends up like a road through the jungle—it’s fine when you’re doing something anticipated by the designers, but as soon as you stray off the path, life is tough. So, without direct language support for all those patterns, what’s left? Each of the patterns relies on executing a particular piece of code again and again, once for each element of the collection. Java has no concept of “a particular piece of code” unless it’s buried in a method. That method can be part of an interface implementation, but at that point each piece of code needs its own (possibly anonymous) class, and life gets very messy.
Groovy uses closures to specify the code to be executed each time and adds the extra methods (each, find, findAll, collect, and so forth) to the collection classes to make them readily available. Those methods aren’t magic, though—they’re simple Groovy, because closures allow the controlling logic (the iteration) to be separated from the code to execute for every element. If you find yourself wanting a similar construct that isn’t already covered by Groovy, you can add it easily.
Separating iteration logic from what to do on each iteration is not the only reason for introducing the closure concept. A second reason that may be even more important is the use of closures when handling resources.
How many times have you seen code that opens a stream but calls close at the end of the method, overlooking the fact that the close statement may never be reached when an exception occurs while processing? So, it needs to be protected with a try-catch block. No—wait—that should be try-finally, or should it? And inside the finally block, close can throw another exception that needs to be handled. There are too many details to remember, and so resource handling is often implemented incorrectly. With Groovy’s closure support, you can put that logic in one place and use it like this:
new File('myfile.txt').eachLine { println it }The eachLine method of File now takes care of opening and closing the file input stream properly. This guards you from accidentally producing a resource leak of file handles.
Streams are just the most obvious tip of the resource-handling iceberg. Database connections, native handles such as graphic resources, network connections—even your GUI is a resource that needs to be managed (that is, repainted correctly at the right time), and observers and event listeners need to be removed when the time comes, or you end up with a memory leak.
Forgetting to clean up correctly in all situations ought to be a problem that only affects neophyte Java programmers, but because the language provides little help beyond try-catch-finally, even experienced developers end up making mistakes. It is possible to code around this in an orderly manner, but Java leads inexperienced programmers away from centralized resource handling. Code structures are duplicated, and the probability of not-so-perfect implementations rises with the number of duplicates.
Resource-handling code is often tested poorly. Projects that measure their test coverage typically struggle to fully cover this area. That is because duplicated, widespread resource handling is difficult to test and eats up precious development time. Testing centralized handlers is easy and requires only a single test.
Let’s see what resource handling solutions Java provides and why they are not used often, and then we’ll show the corresponding Groovy solutions.
In order to do centralized resource handling, you need to pass resource-using code to the handler. This should sound familiar by now—it’s essentially the same problem we encountered when considering collections: The handler needs to know how to call that code, and therefore it must implement some known interface. In Java, this is frequently implemented by an inner class for two reasons: First, it allows the resource-using code to be close to the calling code (which is often useful for readability); and second, it allows the resource-using code to interact with the context of the calling code, using local variables, calling methods on the relevant object, and so on.
By the Way
JUnit, one of the most prominent Java packages outside the JDK, follows this strategy by using the Runnable interface with its runProtected method.
Anonymous inner classes are almost solely used for this kind of pattern—if Java had closures, it’s possible that anonymous inner classes might never have been invented. The rules and restrictions that come with them (and with plain inner classes) make it obvious what a wart the whole “feature” really is on the skin of what is otherwise an elegant and simple language. As soon as you have to start typing code like MyClass.this.doSomething, you know something is wrong—and that’s aside from the amount of distracting clutter required around your code just to create it in the first place. The interaction with the context of the calling code is limited, with rules such as local variables having to be final in order to be used making life awkward.
In some ways, it’s the right approach, but it looks ugly, especially when used often. Java’s limitations get in the way too much to make it an elegant solution. The following example uses a Resource that it gets from a ResourceHandler, which is responsible for its proper construction and destruction. Only the boldface code is really needed for doing the job:
// Java
interface ResourceUser {
void use(Resource resource)
}
resourceHandler.handle(new ResourceUser(){
public void use (Resource resource) {
resource.doSomething()
}
});The Groovy equivalent of this code reveals all necessary information without any waste:
resourceHandler.handle { resource -> resource.doSomething() }
Groovy’s scoping is also significantly more flexible and powerful, while removing the “code mess” that inner classes introduce.
Another strategy to centralize resource handling in Java is to do it in a superclass and let the resource-using code live in a subclass. This is the typical implementation of the Template Method [GOF] pattern.
The downside here is that you either end up with a proliferation of subclasses or use (maybe anonymous) inner subclasses, which brings us back to the drawbacks discussed earlier. It also introduces penalties in terms of code clarity and freedom of implementation, both of which tend to suffer when inheritance is involved. This leads us to take a close look at the dangers of abstraction proliferation.
If there were only one interface that could be used for the purpose of passing logic around, like our imaginary ResourceUser interface from the previous example, then things would not be too bad. But in Java there is no such beast—no single ResourceUser interface that serves all purposes. The signature of the callback method use needs to adapt to the purpose: the number and type of parameters, the number and type of declared exceptions, and the return type.
Therefore a variety of interfaces has evolved over time: Runnables, Observers, Listeners, Visitors, Comparators, Strategies, Commands, Controllers, and so on. This makes their use more complicated, because with every new interface, there also is a new abstraction or concept that needs to be understood.
In comparison, Groovy closures can handle any method signature, and the behavior of the controlling logic may even change depending on the signature of the closure provided to it, as you’ll see later.
These two examples of pain-points in Java that can be addressed with closures are just that—examples. If they were the only problems made easier by closures, closures would still be worth having, but reality is much richer. It turns out that closures enable many patterns of programming that would be unthinkable without them.
Before you can live your dreams, however, you need to learn more about the basics of closures. Let’s start with how we declare them in the first place.
So far, we have used the simple abbreviated syntax of closures: After a method call, put your code in curly braces with parameters delimited from the closure body by an arrow.
Let’s start by adding to your knowledge about the simple abbreviated syntax, and then we’ll look at two more ways to declare a closure: by using them in assignments and by referring to a method.
Listing 5.1 shows the simple closure syntax plus a new convenience feature. When there is only one parameter passed into the closure, its declaration is optional. The magic variable it can be used instead. See the two equivalent closure declarations in listing 5.1.
Example 5.1. Simple abbreviated closure declaration
log = ''
(1..10).each{ counter -> log += counter }
assert log == '12345678910'
log = ''
(1..10).each{ log += it }
assert log == '12345678910'Note that unlike counter, the magic variable it needs no declaration.
This syntax is an abbreviation because the closure object as declared by the curly braces is the last parameter of the method and would normally appear within the method’s parentheses. As you will see, it is equally valid to put it inside parentheses like any other parameter, although it is hardly ever used this way:
log = ''
(1..10).each({ log += it })
assert log == '12345678910'This syntax is simple because it uses only one parameter, the implicit parameter it. Multiple parameters can be declared in sequence, delimited by commas. A default value can optionally be assigned to parameters, in case no value is passed from the method to the closure. We will show examples in section 5.4.
A second way of declaring a closure is to directly assign it to a variable:
def printer = { line -> println line }The closure is declared inside the curly braces and assigned to the printer variable.
There is also a special kind of assignment, to the return value of a method:
def Closure getPrinter() {
return { line -> println line }
}Again, the curly braces denote the construction of a new closure object. This object is returned from the method call.
Tip
Curly braces can denote the construction of a new closure object or a Groovy block. Blocks can be class, interface, static or object initializers, or method bodies; or can appear with the Groovy keywords if, else, synchronized, for, while, switch, try, catch, and finally. All other occurrences are closures.
As you see, closures are objects. They can be stored in variables, they can be passed around, and, as you probably guessed, you can call methods on them. Being objects, closures can also be returned from a method.
The third way of declaring a closure is to reuse something that is already declared: a method. Methods have a body, optionally return values, can take parameters, and can be called. The similarities with closures are obvious, so Groovy lets you reuse the code you already have in methods, but as a closure. Referencing a method as a closure is performed using the reference.& operator. The reference is used to specify which instance should be used when the closure is called, just like a normal method call to reference.someMethod(). Figure 5.1 shows an assignment using a method closure, breaking the statement up into its constituent parts.
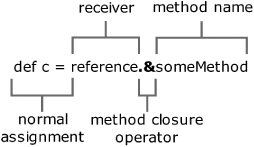
Listing 5.2 demonstrates method closures in action, showing two different instances being used to give two different closures, even though the same method is invoked in both cases.

Each instance (created at ![]() ) has a separate idea of how long a string it will deem to be valid in the
) has a separate idea of how long a string it will deem to be valid in the validate method. We create a reference to that method with first.&validate at ![]() and
and second.&validate, showing that the reference can be assigned to a variable which is then passed (at ![]() ) or passed as a parameter to the
) or passed as a parameter to the find method at ![]() . We use a sample list of words to check that the closures are doing what we expect them to.
. We use a sample list of words to check that the closures are doing what we expect them to.
Method closures are limited to instance methods, but they do have another interesting feature—runtime overload resolution, also known as multimethods. You will find out more about multimethods in chapter 7, but listing 5.3 gives a taste.
Example 5.3. Multimethod closures—the same method name called with different parameters is used to call different implementations

Here a single instance is used, and indeed a single closure (at ![]() )—but each time it’s called, a different method implementation is invoked, at
)—but each time it’s called, a different method implementation is invoked, at ![]() . We don’t want to rush ahead of ourselves, but you’ll see a lot more of this kind of dynamic behavior in chapter 7.
. We don’t want to rush ahead of ourselves, but you’ll see a lot more of this kind of dynamic behavior in chapter 7.
Now that you’ve seen all the ways of declaring a closure, it’s worth pausing for a moment and seeing them all together, performing the same function, just with different declaration styles.
Listing 5.4 shows all of these ways of creating and using closures: through simple declaration, assignment to variables, and method closures. In each case, we call the each method on a simple map, providing a closure that doubles a single value. By the time we’ve finished, we’ve doubled each value three times.

In ![]() , we pass the closure as the parameter directly. This is the form you’ve seen most commonly so far.
, we pass the closure as the parameter directly. This is the form you’ve seen most commonly so far.
The declaration of the closure in ![]() is disconnected from its immediate use. The curly braces are Groovy’s way to declare a closure, so we assign a closure object to the variable
is disconnected from its immediate use. The curly braces are Groovy’s way to declare a closure, so we assign a closure object to the variable doubler. Some people incorrectly interpret this line as assigning the result of a closure call to a variable. Don’t fall into that trap! The closure is not yet called, only declared, until we reach it. There you see that passing the closure as an argument to the each method via a reference is exactly the same as declaring the closure in-place, the style that we followed in all the previous examples.
The method declared in ![]() is a perfectly ordinary method. There is no trace of our intention to use it as a closure.
is a perfectly ordinary method. There is no trace of our intention to use it as a closure.
In ![]() , the
, the reference.& operator is used for referencing a method name as a closure. Again, the method is not immediately called; the execution of the method occurs as part of the next line. This is just like ![]() . The closure is passed to the
. The closure is passed to the each method, which calls it back for each entry in the map.
Typing[2] is optional in Groovy, and consequently it is optional for closure parameters. A special thing about closure parameters with explicit types is that this type is not checked at compile-time but at runtime.
In order to fully understand how closures work and how to use them within your code, you need to find out how to invoke them. That is the topic of the next section.
So far, you have seen how to declare a closure for the purpose of passing it for execution, to the each method for example. But what happens inside the each method? How does it call your closure? If you knew this, you could come up with equally smart implementations. We’ll first look at how simple calling a closure is and then move on to explore some advanced methods that the Closure type has to offer.
Suppose we have a reference x pointing to a closure; we can call it with x.call() or simply x(). You have probably guessed that any arguments to the closure call go between the parentheses.
We start with a simple example. Listing 5.5 shows the same closure being called both ways.
Example 5.5. Calling closures
def adder = { x, y -> return x+y }
assert adder(4, 3) == 7
assert adder.call(2, 6) == 8We start off by declaring pretty much the simplest possible closure—a piece of code that returns the sum of the two parameters it is passed. Then we call the closure both directly and using the call method. Both ways of calling the closure achieve exactly the same effect.
Now let’s try something more involved. In listing 5.6, we demonstrate calling a closure from within a method body and how the closure gets passed into that method in the first place. The example measures the execution time of the closure.

Do you remember our performance investigation for regular expression patterns in listing 3.7? We needed to duplicate the benchmarking logic because we had no means to declare how to benchmark something. Now you know how. You can pass a closure into the benchmark method, where some pre- and post-work takes control of proper timing.
We put the closure parameter at the end of the parameter list in ![]() to allow the simple abbreviated syntax when calling the method. In the example, we declare the type of the closure. This is only to make things more obvious. The
to allow the simple abbreviated syntax when calling the method. In the example, we declare the type of the closure. This is only to make things more obvious. The Closure type is optional.
We effectively start timing the benchmark at ![]() . From a general point of view, this is arbitrary pre-work like opening a file or connecting to a database. It just so happens that our resource is time.
. From a general point of view, this is arbitrary pre-work like opening a file or connecting to a database. It just so happens that our resource is time.
At ![]() , we call the given closure as many times as our
, we call the given closure as many times as our repeat parameter demands. We pass the current count to the closure to make things more interesting. From a general point of view, a resource is passed to the closure.
We stop timing at ![]() and calculate the time taken by the closure. Here is the place for the post-work: closing files, flushing buffers, returning connections to the pool, and so on.
and calculate the time taken by the closure. Here is the place for the post-work: closing files, flushing buffers, returning connections to the pool, and so on.
The payoff comes at ![]() . We can now pass logic to the
. We can now pass logic to the benchmark method. Note that we use the simple abbreviated syntax and use the magic it to refer to the current count. As a side effect, we learn that the general number division takes more than 15 times longer than the optimized intdiv method.
By the Way
This kind of benchmarking should not be taken too seriously. There are all kinds of effects that can heavily influence such wall-clock based measurements: machine characteristics, operating system, current machine load, JDK version, Just-In-time compiler and Hotspot settings, and so on.
Figure 5.2 shows the UML sequence diagram for the general calling scheme of the declaring object that creates the closure, the method invocation on the caller, and the caller’s callback to the given closure.
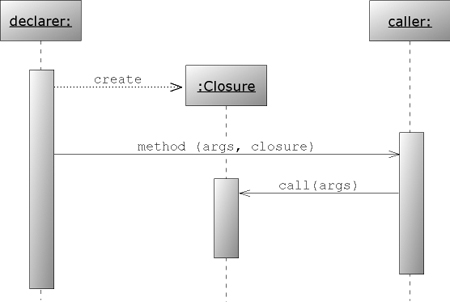
Figure 5.2. UML sequence diagram of the typical sequence of method calls when a declarer creates a closure and attaches it to a method call on the caller, which in turn calls that closure’s call method
When calling a closure, you need to pass exactly as many arguments to the closure as it expects to receive, unless the closure defines default values for its parameters. This default value is used when you omit the corresponding argument. The following is a variant of the addition closure as used in listing 5.5, with a default value for the second parameter and two calls—one that passes two arguments, and one that relies on the default:
def adder = { x, y=5 -> return x+y }
assert adder(4, 3) == 7
assert adder.call(7) == 12For the use of default parameters in closures, the same rules apply as for default parameters for methods. Also, closures can be used with a parameter list of variable length in the same way that methods can. We will cover this in section 7.1.2.
At this point, you should be comfortable with passing closures to methods and have a solid understanding of how the callback is executed—see also the UML diagram in figure 5.2. Whenever you pass a closure to a method, you can be sure that a callback will be executed one way or the other (maybe only conditionally), depending on that method’s logic. Closures are capable of more than just being called, though. In the next section, you see what else they have to offer.
The class groovy.lang.Closure is an ordinary class, albeit one with extraordinary power and extra language support. It has various methods available beyond call. We will present the most the important ones—even though you will usually just declare and call closures, it’s nice to know there’s some extra power available when you need it.
A simple example of how useful it is to react on the parameter count of a closure is map’s each method, which we discussed in section 4.3.2. It passes either a Map.Entry object or key and value separately into the given closure, depending on whether the closure takes one or two arguments. You can retrieve the information about expected parameter count (and types, if declared) by calling closure’s getParameterTypes method:
def caller (Closure closure){
closure.getParameterTypes().size()
}
assert caller { one -> } == 1
assert caller { one, two -> } == 2As in the Map.each example, this allows for the luxury of supporting closures with different parameter styles, adapted to the caller’s needs.
Currying is a technique invented by Moses Schönfinkel and Gottlob Frege, and named after the logician Haskell Brooks Curry (1900..1982), a pioneer in functional programming. (Unsurprisingly, the functional language Haskell is also named after Curry.) The basic idea is to take a function with multiple parameters and transform it into a function with fewer parameters by fixing some of the values. A classic example is to choose some arbitrary value n and transform a function that sums two parameters into a function that takes a single parameter and adds n to it.
In Groovy, Closure’s curry method returns a clone of the current closure, having bound one or more parameters to a given value. Parameters are bound to curry’s arguments from left to right. Listing 5.7 gives an implementation.
Example 5.7. A simple currying example
def adder = {x, y -> return x+y}
def addOne = adder.curry(1)
assert addOne(5) == 6We reuse the same closure you’ve seen a couple of times now for general summation. We call the curry method on it to create a new closure, which acts like a simple adder, but with the value of the first parameter always fixed as 1. Finally, we check our results.
If you’re new to closures or currying, now might be a good time to take a break—and pick the book up again back at the start of the currying discussion, to read it again. It’s a deceptively simple concept to describe mechanically, but it can be quite difficult to internalize. Just take it slowly, and you’ll be fine.
The real power of currying comes when the closure’s parameters are themselves closures. This is a common construction in functional programming, but it does take a little getting used to.
For an example, suppose you are implementing a logging facility. It should support filtering of log lines, formatting them, and appending them to an output device. Each activity should be configurable. The idea is to provide a single closure for a customized version of each activity, while still allowing you to implement the overall pattern of when to apply a filter, do the formatting, and finally output the log line in one place. The following shows how currying is used to inject the customized activity into that pattern:

Closures ![]() and
and ![]() are like recipes: Given any filter, output format, destination, and a line to potentially log, they perform the work, delegating appropriately. The short closures in
are like recipes: Given any filter, output format, destination, and a line to potentially log, they perform the work, delegating appropriately. The short closures in ![]() are the specific ingredients in the recipe. They could be specified every time, but we’re always going to use the same ingredients. Currying (at
are the specific ingredients in the recipe. They could be specified every time, but we’re always going to use the same ingredients. Currying (at ![]() ) allows us to remember just one object rather than each of the individual parts. To continue the recipe analogy, we’ve put all the ingredients together, and the result needs to be put in the oven whenever we want to do some logging.
) allows us to remember just one object rather than each of the individual parts. To continue the recipe analogy, we’ve put all the ingredients together, and the result needs to be put in the oven whenever we want to do some logging.
Logging is often dismissed as a dry topic. But in fact, the few lines in the preceding code prove that conception wrong. As a mindful engineer, you know that log statements will be called often, and any logging facility must pay attention to performance. In particular, there should be the least possible performance hit when no log is written.
The time-consuming operations in this example are formatting and printing. Filtering is quick. With the help of closures, we laid out a code pattern which ensures that the expensive operations are not called for lines that don’t need to be printed. The configurator and appender closures implement that pattern.
This pattern is extremely flexible, because the logic of how the filtering works, how the formatting is applied, and how the result is written is fully configurable (even at runtime).
With the help of closures and their curry method, we achieved a solution with the best possible coherence and lowest possible coupling. Note how each of the closures completely addresses exactly one concern.
This is the beginning of functional programming. See Andrew Glover’s excellent online article on functional programming with Groovy closures at http://www-128.ibm.com/developerworks/library/j-pg08235/. It expands on how to use this approach for implementing your own expression language, capturing business rules, and checking your code for holding invariants.
Closures implement the isCase method to make closures work as classifiers in grep and switch. In that case, the respective argument is passed into the closure, and calling the closure needs to evaluate to a Groovy Boolean value (see section 6.1). As you see in
assert [1,2,3].grep{ it<3 } == [1,2]
switch(10){
case {it%2 == 1} : assert false
}this allows us to classify by arbitrary logic. Again, this is only possible because closures are objects.
For the sake of completeness, it needs to be said that closures support the clone method in the usual Java sense.
The asWriteable method returns a clone of the current closure that has an additional writeTo(Writer) method to write the result of a closure call directly into the given Writer.
Finally, there are a setter and getter for the so-called delegate. We will cross the topic of what a delegate is and how it is used inside a closure when investigating a closure’s scoping rules in the next section.
You have seen how to create closures when they are needed for a method call and how to work with closures when they are passed to your method. This is very powerful while still simple to use.
This section looks under the hood and deepens your understanding of what happens when you use this simple construction. We explore what data and methods you can access from a closure, what difference using the this reference makes, and how to put your knowledge to the test with a classic example designed to test any language’s expressiveness.
This is a bit of a technical section, and you can safely skip it on first read. However, at some point you may want to read it and learn how Groovy can provide all those clever tricks. In fact, knowing the details will enable you to come up with particularly elegant solutions yourself.
What is available inside a closure is called its scope. The scope defines
What local variables are accessible
What
this(the current object) refers toWhat fields and methods are accessible
We start with an explanation of the behavior that you have seen so far. For that purpose, we revisit a piece of code that does something 10 times:
def x = 0 10.times { x++ } assert x == 10
It is evident that the closure that is passed into the times method can access variable x, which is locally accessible when the closure is declared. Remember: The curly braces show the declaration time of the closure, not the execution time. The closure can access x for both reading and writing at declaration time.
This leads to a second thought: The closure surely needs to also access x at execution time. How could it increment it otherwise? But the closure is passed to the times method, a method that is called on the Integer object with value 10. That method, in turn, calls back to our closure. But the times method has no chance of knowing about x. So it cannot pass it to the closure, and it surely has no means of finding out what the closure is doing with it.
The only way in which this can possibly work is if the closure somehow remembers the context of its birth and carries it along throughout its lifetime. That way, it can work on that original context whenever the situation calls for it.
This birthday context that the closure remembers needs to be a reference, not a copy. If that context were a copy of the original one, there would be no way of changing the original from inside the closure. But our example clearly does change the value of x—otherwise the assertion would fail. Therefore, the birthday context must be a reference.
Figure 5.3 depicts your current understanding of which objects are involved in the times example and how they reference each other.
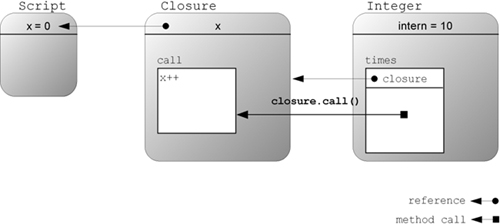
Figure 5.3. Conceptual view of object references and method calls between a calling script, an Integer object of value 10 that is used in the script, and the closure that is attached to the Integer’s times method for defining something that has to be done 10 times
The Script creates a Closure that has a back reference to x, which is in the local scope of its declarer. Script calls the times method on the Integer 10 object, passing the declared closure as a parameter. In other words, when times is executed, a reference to the closure object lies on the stack. The times method uses this reference to execute Closure’s call method, passing its local variable count to it. In this specific example, the count is not used within Closure.call. Instead, Closure.call only works on the x reference that it holds to the local variable x in Script.
Through analysis, you see that local variables are bound as a reference to the closure at declaration time.
It would not be surprising if other scope elements were treated the same as local variables: the value of this, fields, methods, and parameters.
This generalization is correct, but the this reference is a special case. Inside a closure, you could legitimately assume that this would refer to the current object, which is the closure object itself. On the other hand, it should make no difference whether you use this.reference or plain reference for locally accessible references. The first approach has long been used in Groovy but was changed in favor of the latter by the JSR expert group.[3]
A reference to the declaring object is held in a special variable called owner. Listing 5.8 extends the purpose of the initial example to reveal the remaining scope elements.
We implement a small class Mother that should give birth to a closure through a method with that name. The class has a field, another method, parameters, and local variables that we can study. The closure should return a list of all elements that are in the current context (aka scope). Behind the scenes, these elements will be bound at declaration time but not evaluated until the closure is called. Let’s investigate the result of such a call.

We added the optional return type to the method declaration in ![]() to point out that this method returns a closure object. A method that returns a closure is not the most common usage of closures, but every now and then it comes in handy. Note that we are at declaration time in this method. The list that the closure will return when called doesn’t exist yet.
to point out that this method returns a closure object. A method that returns a closure is not the most common usage of closures, but every now and then it comes in handy. Note that we are at declaration time in this method. The list that the closure will return when called doesn’t exist yet.
After having constructed a new Mother, we call its birth method at ![]() to retrieve a newly born closure object. Even now, the closure hasn’t been called. The list of elements is not yet constructed.
to retrieve a newly born closure object. Even now, the closure hasn’t been called. The list of elements is not yet constructed.
Rubber meets road at ![]() . Now we call the closure using the explicit call syntax to make it stand out. The closure constructs its list of elements from what it remembers about its birth. We store that list in a variable for further inspection. Notice that we pass ourselves as a parameter into the closure in order to make it available inside the closure as the
. Now we call the closure using the explicit call syntax to make it stand out. The closure constructs its list of elements from what it remembers about its birth. We store that list in a variable for further inspection. Notice that we pass ourselves as a parameter into the closure in order to make it available inside the closure as the caller.
At ![]() the example should print the script class name by the time you are reading this. Groovy versions before 1.0 printed the closure type.
the example should print the script class name by the time you are reading this. Groovy versions before 1.0 printed the closure type.
The instance variable field, the result of calling foo(), the local variable local, and the parameter param all have the expected values, as demonstrated in ![]() , although they were not known to the
, although they were not known to the Script when it executed the closure. This is the birthday recall that we expected. Only foo() is a bit tricky. As always, it is a shortcut for this.foo(), and as we said, this refers to the closure, not to the declaring object. At this point, closures play a trick for us. They delegate all[4] method calls to a so-called delegate object, which by default happens to be the declaring object (that is, the owner). This makes the closure appear as if the enclosed code runs in the birthday context.
Passing the caller explicitly into the closure is the way to make it accessible inside. We demonstrate this at ![]() . Throughout all previous closure examples in this book, the calling and the declaring object were identical. Therefore, we could easily apply side effects on it. You may have thought we were side-effecting the caller while we were working on the declarer. If this sounds totally crazy to you, don’t worry. The concept may be a bit too unfamiliar. Start over with the
. Throughout all previous closure examples in this book, the calling and the declaring object were identical. Therefore, we could easily apply side effects on it. You may have thought we were side-effecting the caller while we were working on the declarer. If this sounds totally crazy to you, don’t worry. The concept may be a bit too unfamiliar. Start over with the times example, if you want. Breathe deeply. It’ll come in time.
Inside a closure, the magic variable owner refers to the declaring object, as shown at ![]() .
.
At ![]() you see that with every call to
you see that with every call to birth, a new closure is constructed. Think of the closures’ curly braces as if the word new appeared before them. Behind this observation is a fundamental difference between closures and methods: Methods are constructed exactly once at class-generation time. Closures are objects and thus constructed at runtime, and there may be any number of them constructed from the same lines of code.
Figure 5.4 shows who refers to whom in listing 5.8.
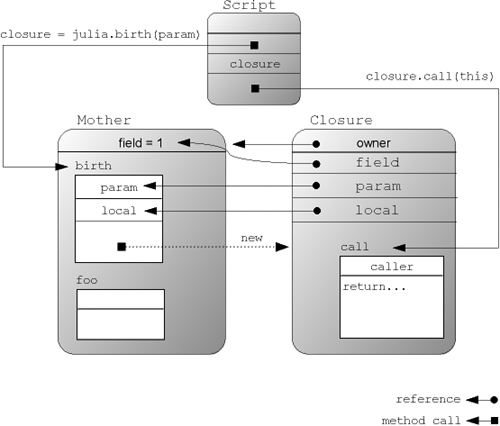
Figure 5.4. Conceptual view of object references and method calls for the general scoping example in listing 5.8, revealing the calls to the julia instance of Mother for creating a closure that is called in the trailing Script code to return all values in the current scope
Lectures about lexical scoping and closures from other languages such as Lisp, Smalltalk, Perl, Ruby, and Python typically end with some mind-boggling examples about variables with identical names, mutually overriding references, and mystic rebirth of supposed-to-be foregone contexts. These examples are like puzzles. They make for an entertaining pastime on a long winter evening, but they have no practical relevance. We will not provide any of those, because they can easily undermine your carefully built confidence in the scoping rules.
Our intention is to provide a reasonable introduction to Groovy’s closures. This should give you the basic understanding that you need when hunting for more complex examples in mailing lists and on the Web. Instead of giving a deliberately obscure example, however, we will provide one that shows how closure scopes can make an otherwise complex task straightforward.
There is a classic example to compare the power of languages by the way they support closures. One of the things it highlights is the power of the scoping rules for those languages as they apply to closures. Paul Graham first proposed this test in his excellent article “Revenge of the Nerds” (http://www.paulgraham.com/icad.html). Beside the test, his article is very interesting and informative to read. It talks about the difference a language can make. You will find good arguments in it for switching to Groovy.
In some languages, this test leads to a brain-teasing solution. Not so in Groovy. The Groovy solution is exceptionally obvious and straightforward to achieve.
Here is the original requirement statement:
“We want to write a function that generates accumulators—a function that takes a number
n, and returns a function that takes another numberiand returnsnincremented byi.”
The following are proposed solutions for other languages:
In Lisp:
(defun foo (n) (lambda (i) (incf n i)))
In Perl 5:
sub foo {
my ($n) = @_;
sub {$n += shift}
}In Smalltalk:
foo: n |s| s := n. ^[:i| s := s+i. ]
The following steps lead to a Groovy solution, as shown in listing 5.9:
We need a function that returns a closure. In Groovy, we don’t have functions, but methods. (Actually, we have not only methods, but also closures. But let’s keep it simple.) We use
defto declare such a method. It has only one line, which afterreturncreates a new closure. We will call this methodfooto make the solutions comparable in size. The namecreateAccumulatorwould better reflect the purpose.Our method takes an initial value
nas required.Because
nis a parameter to the method that declares the closure, it gets bound to the closure scope. We can use it inside the closure body to calculate the incremented value.The incremented value is not only calculated but also assigned to
nas the new value. That way we have a true accumulation.
We add a few assertions to verify our solution and reveal how the accumulator is supposed to be used. Listing 5.9 shows the full code.
Example 5.9. The accumulator problem in Groovy
def foo(n) {
return {n += it}
}
def accumulator = foo(1)
assert accumulator(2) == 3
assert accumulator(1) == 4All the steps that led to the solution are straightforward applications of what you’ve learned about closures.
In comparison to the other languages, the Groovy solution is not only short but also surprisingly clear. Groovy has passed this language test exceptionally well.
Is this test of any practical relevance? Maybe not in the sense that we would ever need an accumulator generator, but it is in a different sense. Passing this test means that the language is able to dynamically put logic in an object and manage the context that this object lives in. This is an indication of how powerful abstractions in that language can be.
So far, you have seen how to declare closures and how to call them. However, there is one crucial topic that we haven’t touched yet: how to return from a closure.
In principle, there are two ways of returning:
The last expression of the closure has been evaluated, and the result of this evaluation is returned. This is called end return. Using the
returnkeyword in front of the last expression is optional.The
returnkeyword can also be used to return from the closure prematurely.
This means the following ways of doubling the entries of a list have the very same effect:
[1, 2, 3].collect{ it * 2 }
[1, 2, 3].collect{ return it * 2 }A premature return can be used to, for example, double only the even entries:
[1, 2, 3].collect{
if (it%2 == 0) return it * 2
return it
}This behavior of the return keyword inside closures is simple and straightforward. You hardly expect any misconceptions, but there is something to be aware of.
Outside a closure, any occurrence of return leaves the current method. When used inside a closure, it only ends the current evaluation of the closure, which is a much more localized effect. For example, when using List.each, returning early from the closure doesn’t return early from the each method—the closure will still be called again with the next element in the list.
While progressing further through the book, we will hit this issue again and explore more ways of dealing with it. Section 13.1.8 summarizes the topic.
Design patterns are widely used by developers to enhance the quality of their designs. Each design pattern presents a typical problem that occurs in object-oriented programming along with a corresponding well-tested solution. Let’s take a closer look at the way the availability of closures affects how, which, and when patterns are used.
If you’ve never seen design patterns before, we suggest you look at the classic book Design Patterns: Elements of Reusable Object-Oriented Software by Gamma et al, or one of the more recent ones such as Head First Design Patterns by Freeman et al or Refactoring to Patterns by Joshua Kerievsky, or search for “patterns repository” or “patterns catalog” using your favorite search engine.
Although many design patterns are broadly applicable and apply to any language, some of them are particularly well-suited to solving issues that occur when using programming languages such as C++ and Java. They most often involve implementing new abstractions and new classes to make the original programs more flexible or maintainable. With Groovy, some of the restrictions that face C++ and Java do not apply, and the design patterns are either of less value or more directly supported using language features rather than introducing new classes. We pick two examples to show the difference: the Visitor and Builder patterns. As you’ll see, closures and dynamic typing are the key differentiators in Groovy that facilitate easier pattern usage.
The Visitor pattern is particularly useful when you wish to perform some complex business functionality on a composite collection (such as a tree or list) of existing simple classes. Rather than altering the existing simple classes to contain the desired business functionality, a Visitor object is introduced. The Visitor knows how to traverse the composite collection and knows how to perform the business functionality for different kinds of a simple class. If the composite changes or the business functionality changes over time, typically only the Visitor class is impacted.
Listing 5.10 shows how simple the Visitor pattern can look in Groovy; the composite traversal code is in the accept method of the Drawing class, whereas the business functionality (in our case to perform some calculations involving shape area) is contained in two closures, which are passed as parameters to the appropriate accept methods. There is no need for a separate Visitor class in this simple case.
Example 5.10. The Visitor pattern in Groovy
class Drawing {
List shapes
def accept(Closure yield) { shapes.each{it.accept(yield)} }
}
class Shape {
def accept(Closure yield) { yield(this) }
}
class Square extends Shape {
def width
def area() { width**2 }
}
class Circle extends Shape {
def radius
def area() { Math.PI * radius**2 }
}
def picture = new Drawing(shapes:
[new Square(width:1), new Circle(radius:1)] )
def total = 0
picture.accept { total += it.area() }
println "The shapes in this drawing cover an area of $total units."
println 'The individual contributions are: '
picture.accept { println it.class.name + ":" + it.area() }The Builder pattern serves to encapsulate the logic associated with constructing a product from its constituent parts. When using the pattern, you normally create a Builder class, which contains logic determining what builder methods to call and in which sequence to call them to ensure proper assembly of the product. For each product, you must supply the appropriate logic for each relevant builder method used by the Builder class; each builder method typically returns one of the constituent parts.
Coding Java solutions based on the Builder pattern is not hard, but the Java code tends to be cumbersome and verbose and doesn’t highlight the structure of the assembled product. For that reason, the Builder pattern is rarely used in Java; developers instead use unstructured or replicated builder-type logic mixed in with their other code. This is a shame, because the Builder pattern is so powerful.
Groovy’s builders provide a solution using nested closures to conveniently specify even very complex products. Such a specification is easy to read, because the appearance of the code reflects the product structure. Groovy has built-in library classes based on the Builder pattern that allow you to easily build arbitrarily nested node structures, produce markup like HTML or XML, define GUIs in Swing or other widget toolkits, and even access the wide range of functionality in Ant. You will see lots of examples in chapter 8, and we explain how to write your own builders in section 8.6.
Almost all patterns are easier to implement in Groovy than in Java. This is often because Groovy supports more lightweight solutions that make the patterns less of a necessity—mostly because of closures and dynamic typing. In addition, when patterns are required, Groovy often makes expressing them more succinct and simpler to set up.
We discuss a number of patterns in other sections of this book, patterns such as Strategy (see 9.1.1 and 9.1.3), Observer (see 13.2.3), and Command (see 9.1.1) benefit from using closures instead of implementing new classes. Patterns such as Adapter and Decorator (see 7.5.3) benefit from dynamic typing and method lookup. We also briefly discuss patterns such as Template Method (see section 5.2.2), the Value Object pattern (see 3.3.2), the incomplete library class smell (see 7.5.3), MVC (see 8.5.6), and the DTO and DAO patterns (see chapter 10). Just by existing, closures can completely replace the Method Object pattern.
Groovy provides plenty of support for using patterns within your own programs. Its libraries embody pattern practices throughout. Higher-level frameworks such as Grails take it one step further. Grails provides you with a framework built on top of Groovy’s libraries and patterns support. Because using such frameworks saves you from having to deal with many pattern issues directly—you just use the framework—you will automatically end up using patterns without needing to understand the details in most cases. Even then, it is useful to know about some of the patterns we have touched upon so that you can leverage the maximum benefit from whichever frameworks you use.
You have seen that closures follow our theme of everything is an object. They capture a piece of logic, making it possible to pass it around for execution, return it from a method call, or store it for later usage.
Closures encourage centralized resource handling, thus making your code more reliable. This doesn’t come at any expense. In fact, the codebase is relieved from structural duplication, enhancing expressiveness and maintainability.
Defining and using closures is surprisingly simple because all the difficult tasks such as keeping track of references and relaying method calls back to the delegating owner are done transparently. If you don’t care about the scoping rules, everything falls into place naturally. If you want to hook into the mechanics and perform tasks such as deviating the calls to the delegate, you can. Of course, such an advanced usage needs more care. You also need to be careful when returning from a delegate, particularly when using one in a situation where in other languages you might use a for loop or a similar construct. This has surprised more than one new Groovy developer, although the behavior is logical when examined closely. Re-read section 5.6 when in doubt.
Closures open the door to several ways of doing things that may be new to many developers. Some of these, such as currying, can appear daunting at first sight but allow a great deal of power to be wielded with remarkably little code. Additionally, closures can make familiar design patterns simpler to use or even unnecessary.
Although you now have a good understanding of Groovy’s datatypes and closures, you still need a means to control the flow of execution through your program. This is achieved with control structures, which form the topic of the next chapter.
[1] The Groovy designers considered making the Groovy for loop appear exactly as it does in Java 5, but they found that the colon was an unfortunate choice because you cannot read the expression fluently without replacing the colon with an English word. Using the in keyword better reveals the meaning of the expression and the role of the operands in use.
[2] The word typing has two meanings: declaring object types and typing keystrokes. Although Groovy provides optional typing, you still have to key in your program code.
[3] The implementation of the new behavior was not yet available at the time of writing. Therefore the example contains no respective assertion but only a println.
[4] Strictly speaking, not all method calls but only those that the closure cannot answer itself.