
Perfection is achieved not when you have nothing more to add, but when you have nothing left to take away. | ||
| --Antoine de Saint-Exupery | ||
XML, the eXtensible Markup Language, is a reasonably young innovation. It’s just becoming a teenager, but we use it so commonly these days that it’s hard to believe there were times without it. The World Wide Web Consortium (W3C) standardized the first version of XML in 1996.
The widespread use of XML and worldwide adoption of Java took place at about the same time. This may be one of the reasons why the Java platform developed such excellent support for working with XML. Not only are there the built-in SAX and DOM APIs, but many other libraries have appeared over time for parsing and creating XML and for working with it using standards such as XPath.
The topic of XML has the unusual property of being simple and complex at the same time. XML is straightforward until you bring in namespaces, entities, and the like. Similarly, although it’s feasible to demonstrate one way of working with XML fairly simply, giving a good overview of all (or even most) of the ways of working with XML would require more space than we have in this book. We will concentrate on the new capabilities that Groovy brings, as well as mention the enhanced support for the DOM API. Even limiting ourselves to these topics doesn’t let us explore every nook and cranny.
This chapter is broadly divided into three parts. First, you’ll see the different techniques available for parsing XML in Groovy. Second, you will learn some tricks about processing and transforming XML. Finally, we will examine the Groovy support for web services—one of the most common uses of XML in business today.
We assume you already have a reasonable understanding of XML. If you find yourself struggling with any of the XML concepts we use in this chapter, please refer to one of the many available XML books.[1]
XML processing typically starts with reading an XML document, which is our first topic.
When working with XML, we have to somehow read it to begin with. This section will lead you through the many options available in Groovy for parsing XML: the normal DOM route, enhanced by Groovy; Groovy’s own XmlParser and XmlSlurper classes; SAX event-based parsing; and the recently introduced StAX pull-parsers.
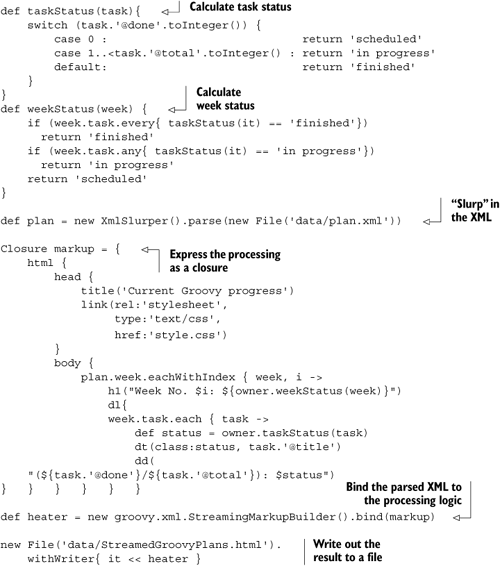
Let’s suppose we have a little datastore in XML format for planning our Groovy self-education activities. In this datastore, we capture how many hours per week we can invest in this training, what tasks need to be done, and how many hours each task will eat up in total. To keep track of our progress, we will also store how many hours are “done” for each task.
Listing 12.1 shows our XML datastore as it resides in a file named data/plan.xml.
Example 12.1. The example datastore data/plan.xml
<plan>
<week capacity="8">
<task done="2" total="2" title="read XML chapter"/>
<task done="3" total="3" title="try some reporting"/>
<task done="1" total="2" title="use in current project"/>
</week>
<week capacity="8">
<task done="0" total="1" title="re-read DB chapter"/>
<task done="0" total="3" title="use DB/XML combination"/>
</week>
</plan>We plan for two weeks, with eight hours for education each week. Three tasks are scheduled for the current week: reading this chapter (two hours for a quick reader), playing with the newly acquired knowledge (three hours of real fun), and using it in the real world (one hour done and one still left).
This will be our running example for most of the chapter.
For reading such a datastore, we will present several different approaches: first using technologies built into the JRE, and then using the Groovy parsers. We’ll start with the more familiar DOM parser.
Why do we bother with Java’s classic DOM parsers? Shouldn’t we restrict ourselves to show only Groovy specifics here?
Well, first of all, even in Groovy code, we sometimes need DOM objects for further processing, for example when applying XPath expressions to an object as we will explain in section 12.2.3. For that reason, we show the Groovy way of retrieving the DOM representation of our datastore with the help of Java’s DOM parsers. Second, there is basic Groovy support for dealing with DOM NodeLists, and Groovy also provides extra helper classes to simplify common tasks within DOM. Finally, it’s much easier to appreciate how slick the Groovy parsers are after having seen the “old” way of reading XML.
We start by loading a DOM tree into memory.
Not surprisingly, the Document Object Model is based around the central abstraction of a document, realized as the Java interface org.w3c.dom.Document. An object of this type will hold our datastore.
The Java way of retrieving a document is through the parse method of a DocumentBuilder (= parser). This method takes an InputStream to read the XML from. So a first attempt of reading is
def doc = builder.parse(new FileInputStream('data/plan.xml'))Now, where does builder come from? We are working slowly backward to find a solution. The builder must be of type DocumentBuilder. Instances of this type are delivered from a DocumentBuilderFactory, which has a factory method called newDocumentBuilder:
def builder = fac.newDocumentBuilder()
def doc = builder.parse(new FileInputStream('data/plan.xml'))Now, where does this factory come from? Here it is:
import javax.xml.parsers.DocumentBuilderFactory
def fac = DocumentBuilderFactory.newInstance()
def builder = fac.newDocumentBuilder()
def doc = builder.parse(new FileInputStream('data/plan.xml'))Java’s XML handling API is designed with flexibility in mind.[2] A downside of this flexibility is that for our simple example, we have a few hoops to jump through in order to retrieve our file. It’s not too bad, though, and now that we have it we can dive into the document.
The document object is not yet the root of our datastore. In order to get the toplevel element, which is plan in our case, we have to ask the document for its documentElement property:
def plan = doc.documentElement
We can now work with the plan variable. It’s of type org.w3c.dom.Node and so it can be asked for its nodeType and nodeName. The nodeType is Node.ELEMENT_NODE, and nodeName is plan.
The design of such DOM nodes is a bit strange (to put it mildly). Every node has the same properties, such as nodeType, nodeName, nodeValue, childNodes, and attributes (to name only a few; see the API documentation for the full list). However, what is stored in these properties and how they behave depends on the value of the nodeType property.
We will deal with types ELEMENT_NODE, ATTRIBUTE_NODE, and TEXT_NODE (see the API documentation for the exhaustive list).
It is not surprising that XML elements are stored in nodes of type ELEMENT_NODE, but it is surprising that attributes are also stored in node objects (of nodeType ATTRIBUTE_NODE). To make things even more complex, each value of an attribute is stored in an extra node object (with nodeType TEXT_NODE). This complexity is a large part of the reason why simpler APIs such as JDOM, dom4j, and XOM have become popular.
As an example, the nodes and their names, types, and values are depicted in figure 12.1 for the first week element in the datastore.
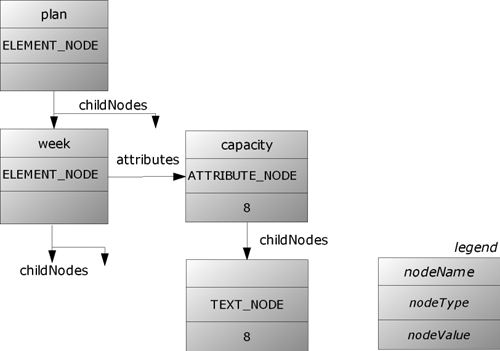
The fact that node objects behave differently with respect to their nodeType leads to code that needs to work with this distinction. For example, when reading information from a node, we need a method such as this:
import org.w3c.dom.Node
String info(node) {
switch (node.nodeType) {
case Node.ELEMENT_NODE:
return 'element: '+ node.nodeName
case Node.ATTRIBUTE_NODE:
return "attribute: ${node.nodeName}=${node.nodeValue}"
case Node.TEXT_NODE:
return 'text: '+ node.nodeValue
}
return 'some other type: '+ node.nodeType
}With this helper method, we have almost everything we need to read information from our datastore. Two pieces of information are not yet explained: the types of the childNodes and attributes properties.
The childNodes property is of type org.w3c.dom.NodeList. Unfortunately, it doesn’t extend the java.util.List interface but provides its own methods, getLength and item(index). This makes it inconvenient to work with. However, as you saw in section 9.1.3, Groovy makes its object iteration methods (each, find, findAll, and so on) available on that type.
The attributes property is of type org.w3c.dom.NamedNodeMap, which doesn’t extend java.util.Map either. We will use its getNamedItem(name) method.
Listing 12.2 puts all this together and reads our plan from the XML datastore, walking into the first task of the first week.

Note how we use the object iteration method find ![]() to access the first
to access the first week element under plan. We use indexed access to the first task child node at ![]() . But why is the index one and not zero? Because in our XML document, there is a line break between
. But why is the index one and not zero? Because in our XML document, there is a line break between week and task. The DOM parser generates a text node containing this line break (and surrounding whitespace) and adds it as the first child node of week (at index zero). The task node floats to the second position with index one.
Groovy wouldn’t be groovy without a convenience method for the lengthy parsing prework:
def doc = groovy.xml.DOMBuilder.parse
(new FileReader('data/plan.xml'))
def plan = doc.documentElementNote
The DOMBuilder is not only for convenient parsing. As the name suggests, it is a builder and can be used like any other builder (see chapter 8). It returns a tree of org.w3c.dom.Node objects just as if they’d been parsed from an XML document. You can add it to another tree, write it to XML, or query it using XPath (see section 12.2.3).
Dealing with child nodes and attributes as in listing 12.2 doesn’t feel groovy either. Therefore, Groovy provides a DOMCategory that you can use for simplified access. With this, you can index child nodes via the subscript operator or via their node name. You can refer to attributes by getting the @attributeName property:
use(groovy.xml.dom.DOMCategory){ assert 'plan' == plan.nodeName assert 'week' == plan[1].nodeName assert 'week' == plan.week.nodeName assert '8' == plan[1].'@capacity' }
Although not shown in the example, DOMCategory has recently been improved to provide additional syntax shortcuts such as name, text, children, iterator, parent, and attributes. We explain these shortcuts later in this chapter, because they originated in Groovy’s purpose-built XML parsing classes. Consult the online Groovy documentation for more details.
This was a lot of work to get the DOM parser to read our data, and we had to face some surprises along the way. We will now do the same task using the Groovy parser with less effort and fewer surprises.
The Groovy way of reading the plan datastore is so simple, we’ll dive headfirst into the solution as presented in listing 12.3.
Example 12.3. Reading plan.xml with Groovy’s XmlParser
def plan = new XmlParser().parse(new File('data/plan.xml'))
assert 'plan' == plan.name()
assert 'week' == plan.week[0].name()
assert 'task' == plan.week[0].task[0].name()
assert 'read XML chapter' == plan.week[0].task[0].'@title'No fluff, just stuff. The parsing is only a one-liner. Because Groovy’s XmlParser resides in package groovy.util, we don’t even need an import statement for that class. The parser can work directly on File objects and other input sources, as you will see in table 12.2. The parser returns a groovy.util.Node. You already came across this type in section 8.2. That means we can easily use GPath expressions to walk through the tree, as shown with the assert statements.
Up to this point, you have seen that Groovy’s XmlParser provides all the functionality you first saw with the DOM parser. But there is more to come. In addition to the XmlParser, Groovy comes with the XmlSlurper. Let’s explore the commonalities and differences between those two before considering more advanced usages of each.
Let’s start with the commonalities of XmlParser and XmlSlurper: They both reside in package groovy.util and provide the constructors listed in table 12.1.
Table 12.1. Common constructors of XmlParser and XmlSlurper
Parameter list | Note |
|---|---|
| Parameterless constructor. |
| After parsing, the document can be validated against a declared DTD, and namespace declarations shall be taken into account. |
| If you already have a |
| If you already have a |
Besides sharing constructors with the same parameter lists, the types share parsing methods with the same signatures. The only difference is that the parsing methods of XmlParser return objects of type groovy.util.Node whereas XmlSlurper returns GPathResult objects. Table 12.2 lists the uniform parse methods.
Table 12.2. Parse methods common to XmlParser and XmlSlurper
Signature | Note |
|---|---|
| Reads from an |
| Reads from an |
| Reads from an |
| Reads from an |
| Reads the resource that the |
| Uses the |
These are the most commonly used methods on XmlParser and XmlSlurper. The description of additional methods (such as for using specialized DTD handlers and entity resolvers) is in the API documentation.
The result of the parse method is either a Node (for XmlParser) or a GPathResult (for XmlSlurper). Table 12.3 lists the common available methods for both result types. Note that because both types understand the iterator method, all object iteration methods are also instantly available.
Table 12.3. Common methods of groovy.util.Node and GPathResult
Node method | GPathResult method | Shortcut | ||
|---|---|---|---|---|
|
|
|
| |
|
|
|
| |
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
| |
|
|
|
|
|
|
|
|
| |
[a] Strictly speaking, | ||||
GPathResult and groovy.util.Node provide additional shortcuts for method calls to the parent object and all descendent objects. Such shortcuts make reading a GPath expression more like other declarative path expressions such as XPath or Ant paths.[3]
Objects of type Node and GPathResult can access both child elements and attributes as if they were properties of the current object. Table 12.4 shows the syntax and how the leading @ sign distinguishes attribute names from nested element names.
Table 12.4. Element and attribute access in groovy.util.Node and GPathResult
|
| Meaning |
|---|---|---|
|
| All child elements of that name |
|
| |
|
| Child element by index |
|
| |
|
| The attribute value stored under that name |
|
Listing 12.4 plays with various method calls and uses GPath expressions to work on objects of type Node and GPathResult alike. It uses XmlParser to return Node objects and XmlSlurper to return a GPathResult. To make the similarities stand out, listing 12.4 shows doubled lines, one using Node, one using GPathResult.
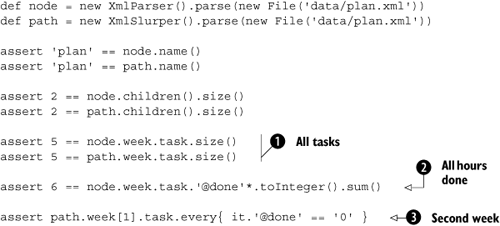
Note that the GPath expression node.week.task ![]() first collects all child elements named
first collects all child elements named week, and then, for each of those, collects all their child elements named task (compare the second row in table 12.4). In the case of node.week.task, we have a list of task nodes that we can ask for its size. In the case of path.week.task, we have a GPathResult that we can ask for its size. The interesting thing here is that the GPathResult can determine the size without collecting intermediate results (such as week and task nodes) in a temporary datastructure such as a list. Instead, it stores whatever iteration logic is needed to determine the result and then executes that logic and returns the result (the size in this example).
At ![]() , you see that in GPath, attribute access has the same effect as access to child elements;
, you see that in GPath, attribute access has the same effect as access to child elements; node.week.task.'@done' results in a list of all values of the done attribute of all tasks of all weeks. We use the spread-dot operator (see section 7.5.1) to apply the toInteger method to all strings in that list, returning a list of integers. We finally use the GDK method sum on that list.
The line at ![]() can be read as: “Assert that the
can be read as: “Assert that the done attribute in every task of week[1] is '0'.” What’s new here is using indexed access and the object iteration method every. Because indexing starts at zero, week[1] means the second week.
This example should serve as an appetizer for your own experiences with applying GPath expressions to XML documents.
In addition to the convenient GPath notation, you might also wish to make use of traversal methods; for example, we could add the following lines to listing 12.4:
assert 'plan->week->week->task->task->task->task->task' ==
node.breadthFirst()*.name().join('->')
assert 'plan->week->task->task->task->week->task->task' ==
node.depthFirst()*.name().join('->')So far, you have seen that XmlParser and XmlSlurper can be used in a similar fashion to produce similar results. But there would be no need for two separate classes if there wasn’t a difference. That’s what we cover next.
Despite the similarities between XmlParser and XmlSlurper when used for simple reading purposes, there are differences when it comes to more advanced reading tasks and when processing XML documents into other formats.
XmlParser uses the groovy.util.Node type and its GPath expressions result in lists of nodes. That makes working with XmlParser feel like there always is a tangible object representation of elements—something that we can inspect via toString, print, or change in-place. Because GPath expressions return lists of such elements, we can apply all our knowledge of the list datatype (see section 4.2).
This convenience comes at the expense of additional up-front processing and extra memory consumption. The GPath expression node.week.task.'@done' generates three lists: a temporary list of weeks[4] (two entries), a temporary list of tasks (five entries), and a list of done attribute values (five strings) that is finally returned. This is reasonable for our small example but hampers processing large or deeply nested XML documents.
XmlSlurper in contrast does not store intermediate results when processing information after a document has been parsed. It avoids the extra memory hit when processing. Internally, XmlSlurper uses iterators instead of extra collections to reflect every step in the GPath. With this construction, it is possible to defer processing until the last possible moment.
Note
This does not mean that XmlSlurper would work without storing the parsed information in memory. It still does, and the memory consumption rises with the size of the XML document. However, for processing that stored information via GPath, XmlSlurper does not need extra memory.
Table 12.5 lists the methods unique to Node. When using XmlParser, you can use these methods in your processing.
Table 12.5. XmlParser: methods of groovy.util.Node not available in GPathResult
Method | Note | |
|---|---|---|
|
| Retrieves the payload of the node, either the |
|
| Changes the payload |
|
| Shortcut to |
|
| Provides namespace support for selecting child elements by their |
|
| Pretty-printing with |
Table 12.6 lists the methods that are unique to or are optimized in GPathResult. As an example, we could add the following line to listing 12.4 to use the optimized findAll in GPathResult:
assert 2 == path.week.task.findAll{ it.'@title' =~ 'XML' }.size()Table 12.6. XmlSlurper: methods of GPathResult not available in groovy.util.Node
Method | Note | |
|---|---|---|
|
| Represents all parent elements on the path from the current element up to the root |
|
| Registers namespace prefixes and their URIs |
|
| Converts a |
|
| The number of result elements (memory optimized implementation) |
|
| Overrides the object iteration method |
|
| Overrides the object iteration method |
Additionally, some classes may only work on one type or the other; for example, there is groovy.util.XmlNodePrinter with method print(Node) but no support for GPathResult. Like the name suggests, XmlNodePrinter pretty-prints a Node tree to a PrintStream in XML format.
You have seen that there are a lot of similarities and some slight differences when reading XML via XmlParser or XmlSlurper. The real, fundamental differences become apparent when processing the parsed information. Coming up in section 12.2, we will look at these differences in more detail by exploring two examples: processing with direct in-place data manipulation and processing in a streaming scenario. However, first we are going to look at event style parsing and how it can be used with Groovy. This will help us better position some of Groovy’s powerful XML features in our forthcoming more-detailed examples.
In addition to the original Java DOM parsing you saw earlier, Java also supports what is known as event-based parsing. The original and most common form of event-based parsing is called SAX. SAX is a push-style event-based parser because the parser pushes events to your code.
When using this style of processing, no memory structure is constructed to store the parsed information; instead, the parser notifies a handler about parsing events. We implement such a handler interface in our program to perform processing relevant to our application’s needs whenever the parser notifies us.
Let’s explore this for our simple plan example. Suppose we wish to display a quick summary of the tasks that are underway and those that are upcoming; we aren’t interested in completed activities for the moment. Listing 12.5 shows how to receive start element events using SAX and perform our business logic of printing out the tasks of interest.

Note that with this style of processing, we have more work to do. When our startElement method is called, we are provided with SAX event information including the name of the element (along with a namespace, if provided) and all the attributes. It’s up to us to work out whether we need this information and process or store it as required during this method call. The parser won’t do any further storage for us. This minimizes memory overhead of the parser, but the implication is that we won’t be able to do GPath-style processing and we aren’t in a position to manipulate a tree-like data structure. We’ll have more to say about SAX event information when we explore XmlSlurper in more detail in section 12.2.
In addition to the push-style SAX parsers supported by Java, a recent trend in processing XML with Java is to use pull-style event-based parsers. The most common of these are called StAX-based parsers.[5] With such a parser, you are still interested in events, but you ask the parser for events (you pull events as needed) during processing[6], instead of waiting to be informed by methods being called.
Listing 12.6 shows how you can use StAX with Groovy. You will need a StAX parser in your classpath to run this example. If you have already set up Groovy-SOAP, which we explore further in section 12.3, you may already have everything you need.

Note that this style of parsing is similar to SAX-style parsing except that we are running the main control loop ourselves rather than having the parser do it. This style has advantages for certain kinds of processing where the code becomes simpler to write and understand.
Suppose you have to respond to many parts of the document differently. With push models, your code has to maintain extra state to know where you are and how to react. With a pull model, you can decide what parts of the document to process at any point within your business logic. The flow through the document is easier to follow, and the code feels more natural.
We have now explored the breadth of parsing options available in Groovy. Next we explore the advantages of the Groovy-specific parsing options in more detail.
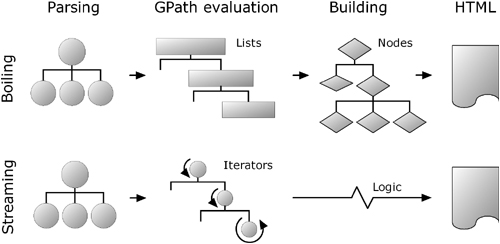
Many situations involving XML call for more than just reading the data and then navigating to a specific element or node. XML documents often require transformation, modification, or complex querying. When we look at the characteristics of XmlParser and XmlSlurper when processing XML data in these ways, we see the biggest differences between the two. Let’s start with a simple but perhaps surprising analogy: heating water.
There are essentially two ways of boiling water, as illustrated in figure 12.2. You can pour water into a tank (called a boiler), heat it up, and get the hot water from the outlet. The second way of boiling is with the help of a continuous-flow heater, which heats up the water while it streams from the cold-water inlet through the heating coil until it reaches the outlet. The heating happens only when requested, as indicated by opening the outlet tap.
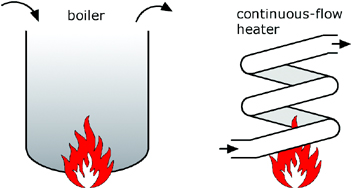
How does XML processing relate to boiling water? Well, processing XML means you are not just using bits of the stored information, but retrieving it, adding some new quality to it (making it hot in our analogy), and outputting the whole thing. Just like boiling water, this can be done in two ways: by storing the information in memory and processing it in-place, or by retrieving information from an input stream, processing it on the fly, and streaming it to an output device.
In general, processing XML with XmlParser (and groovy.util.Node) is more like using a boiler, whereas XmlSlurper can serve as a source in a streaming scenario analogous to continuous-flow heating.
We’re going to start by looking at the “boiling” strategy of in-place modification and processing and then proceed to explore streamed processing and combinations with XPath.
In-place processing is the conventional means of XML processing. It uses the XmlParser to retrieve a tree of nodes. These nodes reside in memory and can be rearranged, copied, or deleted, and their attributes can be changed. We will use this approach to generate an HTML report for keeping track of our Groovy learning activities.
Suppose the report should look like figure 12.3. You can see that new information is derived from existing data: tasks and weeks have a new property that we will call status with the possible values of scheduled, in progress, and finished.
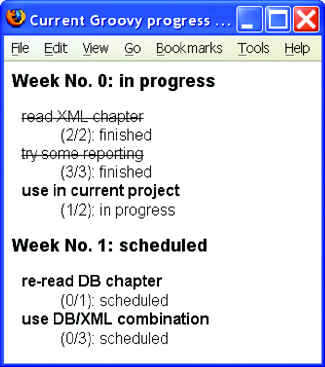
For tasks, the value of the status property is determined by looking at the done and total attributes. If done is zero, the status is considered scheduled; if done is equal to or exceeds total, the status is finished; otherwise, the status is in progress.
Weeks are finished when all contained tasks are finished. They are in progress when at least one contained task is in progress.
This sounds like we are going to do lots of number comparisons with the done and total attributes. Unfortunately these attributes are stored as strings, not numbers. These considerations lead to a three-step “heating” process:
Convert all string attribute values to numbers where suitable.
Add a new attribute called
statusto all tasks, and determine the value.Add a new attribute called
statusto all weeks, and determine the value.
With such an improved data representation, it is finally straightforward to use MarkupBuilder to produce the HTML report.
We have to produce HTML source like
<html>
<head>
<title>Current Groovy progress</title>
<link href='style.css' type='text/css' rel='stylesheet' />
</head>
<body>
<h1>Week No. 0: in progress</h1>
<dl>
<dt class='finished'>read XML chapter</dt>
<dd>(2/2): finished</dd>
...
</dl>
</body>
</html>where the stylesheet style.css contains the decision of how a task is finally displayed according to its status. It can for example use the following lines for that purpose:
dt { font-weight:bold }
dt.finished { font-weight:normal; text-decoration:line-through }Listing 12.7 contains the full solution. The numberfy method implements the string-to-number conversion for those attributes that we expect to be of integer content. It also shows how to work recursively through the node tree.
The methods weekStatus and taskStatus make the new status attribute available on the corresponding node, where weekStatus calls taskStatus for all its contained tasks to make sure it can work on their status inside GPath expressions.
The final htmlReport method is the conventional way of building HTML. Thanks to the “heating” prework, there is no logic needed in the report. The report uses the status attribute to assign a stylesheet class of the same value.

After the careful prework, the code in listing 12.7 is not surprising. What’s a bit unconventional is having a lot of closing braces on one line at the end of htmlReport. This is not only for compact typesetting in the book. We also sometimes use this style in our everyday code. We find it nicely reveals what levels of indentation are to be closed and still allows us to check brace-matching by column. It would be great to have IDE support for toggling between this and conventional code layout.
Now that you have seen how to use the in-memory “boiler,” let’s investigate the streaming scenario.
In order to demonstrate the use of streaming, let’s start with the simplest kind of processing that we can think of: pumping out what comes in without any modification. Even this simple example is hard to understand when you first encounter it. We recommend that if you find it confusing, keep reading, but don’t worry too much about the details. It’s definitely worth coming back later for a second try, though—in many situations, the benefits of stream-based processing are well worth the harder conceptual model.
You use XmlSlurper to parse the original XML. Because the final output format is XML again, you need some device that can generate XML in a streaming fashion. The groovy.xml.StreamingMarkupBuilder class is specialized for outputting markup on demand—in other words, when an information sink requests it. Such a sink is an operation that requests a Writable—for example, the leftshift operator call on streams or the evaluation of GStrings. The trick that StreamingMarkupBuilder uses to achieve this effect is similar to the approach of template engines. StreamingMarkupBuilder provides a bind method that returns a WritableClosure. This object is a Writable and a closure at the same time. Because it is a Writable, you can use it wherever the final markup is requested. Because it is a closure, the generation of this markup can be done lazily on-the-fly, without storing intermediate results.
Listing 12.8 shows this in action. The bind method also needs the information about what logic is to be applied to produce the final markup. Wherever logic is needed, closures are the first candidate, and so it is with bind. We pass a closure to the bind method that describes the markup logic.
For our initial example of pumping the path through, we use a special feature of StreamingMarkupBuilder that allows us to yield the markup generation logic to a Buildable, an object that knows how to build itself. It happens that a GPathResult (and thus path) is buildable. In order to yield the building logic to it, we use the yield method. However, we cannot use it unqualified because we would produce a <yield/> markup if we did. The special symbol mkp marks our method call as belonging to the namespace of markup keywords.
Example 12.8. Pumping an XML stream without modification
import groovy.xml.StreamingMarkupBuilder
def path = new XmlSlurper().parse(new File('data/plan.xml'))
def builder = new StreamingMarkupBuilder()
def copier = builder.bind{ mkp.yield(path) }
def result = "$copier"
assert result.startsWith('<plan><week ')
assert result.endsWith('</week></plan>')There is a lot going on in only a few lines of code. The result variable for example refers to a GString with one value: a reference to copier. Note that we didn’t call it “copy” because it is not a thing but an actor.
When we call the startsWith method on result, the string representation of the GString is requested, and because the one GString value copier is a Writable, its writeTo method is called. The copier was constructed by the builder such that writeTo relays to path.build().
Figure 12.4 summarizes this streaming behavior.
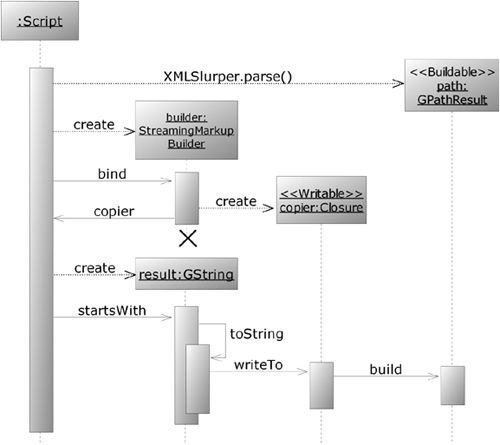
Note how in figure 12.4, the processing doesn’t start before the values are requested. Only after the GString’s toString method is called does the copier start running and is the path iterated upon. Until then, the path isn’t touched! No memory representation has been created for the purpose of markup or iteration. This is a simplification of what is going on. XmlSlurper does have memory requirements. It stores the SAX event information you saw in section 12.1.3 but doesn’t process or store it in the processing-friendly Node objects.
Calling startsWith is like opening the outlet tap to draw the markup from the copier, which in turn draws its source information from the path inlet. Any code before that point is only the plumbing.
As a variant of listing 12.8, you can also directly write the markup onto the console. Use the following:
System.out << copier
Remember that System.out is an OutputStream that understands the leftshift operator with a Writable argument.
For this simple example, we could have used the SAX or StAX approaches you saw earlier. They would be even more streamlined solutions. Not only would they not need to process and store the tree-like data structures that XmlParser creates for you, but they also wouldn’t need to store the SAX event information. The same isn’t true for the more complicated scenarios that follow. As is common in many XML processing scenarios, the remaining examples have processing requirements that span multiple elements. Such scenarios benefit greatly from the ability to use GPath-style expressions.
Until now, we copied only the “cold” input. It’s time to light our heater. The goal is to produce the same GUI as in figure 12.3.
We start with the basis of listing 12.8 but enhance the markup closure that gets bound to the builder. In listing 12.9, building looks almost the same as in the “boiling” example of listing 12.7; only the evaluation of the week and task status needs to be adapted. We do not calculate the status in advance and store it for later reference, but do the classification on-the-fly when the builder lazily requests it.
The cool thing here is that at first glance it looks similar to listing 12.7, but it works very differently:
All evaluation is done lazily.
Memory consumption for GPath operations is minimized.
No in-memory assembly of HTML representation is built before outputting.
This allows us to produce lots of output, because it is not assembled in memory but directly streamed to the output as the building logic demands. However, because of the storage of SAX event information on the input, this approach will not allow input documents as large as would be possible with SAX or StAX.
Figure 12.5 sketches the differences between both processing approaches with respect to processing requirements and memory usage. The process goes from left to right either in the top row (for “boiling”) or in the bottom row (for “streaming”). Either process encompasses parsing, evaluating, building, and serializing to HTML, where evaluating and building are not necessarily in strict sequence. This is also where the differences are: working on intermediate data structures (trees of lists and nodes) or on lightweight objects that encapsulate logic (iterators and closures).
That’s it for the basics of processing XML with the structures provided by the Groovy XML parsers.
In section 12.1.1, you saw that classic Java DOM parsers return objects of type org.w3c.dom.Node, which differs from what the Groovy parsers return. The Java way of processing such nodes is with the help of XPath. The next section shows how Java XPath and Groovy XML processing can be used in combination.
XPath is for XML what SQL select statements are for relational databases or what regular expressions are for plain text. It’s a means to select parts of the whole document and to do so in a descriptive manner.
An XPath is an expression that appears in Java or Groovy as a string (exactly like regex patterns or SQL statements do). A full introduction to XPath is beyond the scope of this book, but here is a short introduction from a Groovy programmer’s point of view.[7]
Just like a GPath, an XPath selects nodes. Where GPath uses dots, XPath uses slashes. For example
/plan/week/task
selects all task nodes of all weeks below plan. The leading slash indicates that the selection starts at the root element. In this expression, plan, week, and task are each called a node test. Each node test may be preceded with an axis specifier from table 12.7 and a double colon.
Table 12.7. XPath axis specifiers
Selects nodes | Shortcut | |
|---|---|---|
| Directly below | nothing or * |
| Directly above | .. |
| The node itself (use for further references) | . |
| All above | |
| All above including self | |
| All below | |
| All below including self | // |
| All on the same level trailing in the XML document | |
| All with the same parent trailing in the XML document | |
| All on the same level preceding in the XML document | |
| All with the same parent preceding in the XML document | |
| The attribute node | @ |
| The namespace node |
With these specifiers, you can select all task elements via
/descendant-or-self::task
With the shortcut syntax, you can select all total attribute nodes of all tasks via
//task/@total
A node test can have a trailing predicate in square brackets to constrain the result. A predicate is an expression made up from path expressions, functions, and operators for the datatypes node-set, string, number, and boolean. Table 12.8 lists what’s possible.[8]
Table 12.8. XPath predicate expression cheat sheet
Category | Appearance | Note |
|---|---|---|
Path operators |
| As above |
Union operator |
| Union of two node-sets |
Boolean operators |
|
|
Arithmetic operators |
| |
Comparison operators |
| |
String functions |
| See the docs for exact meanings and parameters |
Number functions |
| |
Node functions |
| |
Context functions |
|
|
Conversion functions |
|
Table 12.9 shows some examples.
Table 12.9. XPath examples
Meaning and notes | Note | |
|---|---|---|
| First[a] | Indexing starts at one |
| All unfinished tasks | Auto-conversion to a number |
| All tasks in progress | Implicit |
| Total hours in the first week | Returns a number |
[a] More specifically: the | ||
The next obvious question is how to use such XPath expressions in Groovy code.
Groovy comes with all the support you need for using XPath expressions in your code. This is because of the xml-apis*.jar and xerces*.jar files in your GROOVY_HOME/lib dir. In case you are running Groovy in an embedded scenario, make sure these jars are on your classpath.
We will use XPath through the convenience methods in org.apache.xpath. XPathAPI. This class provides lot of static helper methods that are easy to use even though the implementation is not always efficient.[9] We will use
Node selectSingleNode(Node contextNode, String xpath) NodeList selectNodeList (Node contextNode, String xpath) XObject eval (Node contextNode, String xpath)
where XObject wraps the XPath datatype that eval returns. For converting it into a Groovy datatype, we can use the methods num, bool, str, and nodelist.
In practice, we may want to do something with all weeks. We select the appropriate list of nodes via XPathAPI.selectNodeList(plan,'week'). Because this returns a NodeList, we can use the object iteration methods on it to get hold of each week:
XPathAPI.selectNodeList(plan, 'week').eachWithIndex{ week, i ->
// do something with week
}For each week, we want to print the sum of the total and done attributes with the help of XPath. Each week node becomes the new context node for the XPath evaluation:
XPathAPI.selectNodeList(plan, 'week').eachWithIndex{ week, i ->
println "
Week No. $i
"
println XPathAPI.eval(week, 'sum(task/@total)').num()
println XPathAPI.eval(week, 'sum(task/@done)').num()
}Listing 12.10 puts all this together with a little reporting functionality that produces a text report for each week, stating the capacity, the total hours planned, and the progress in hours done.

XPath is used in two ways here—the querying capability is used to select all the week elements ![]() , and then attributes
, and then attributes total and done are extracted with the eval method ![]() . We mix and match ways of accessing attributes, using
. We mix and match ways of accessing attributes, using DOMCategory to access the capacity attribute with the node.@attributeName syntax ![]() .
.
Such a text report is fine to start with, but it would certainly be nicer to show the progress in a chart. Figure 12.6 suggests an HTML solution. In a normal situation, we would use colors in such a report, but they would not be visible in the print of this book. Therefore, we use only a simple box representation of the numbers.
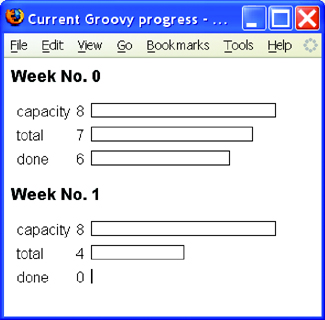
Each box is made from the border of a styled div element. The style also determines the width of each box.
This kind of HTML production task calls for a templating approach, because there are multiple recurring patterns for HTML fragments: for the boxes, for each attribute row, and for each week. We will use template engines, GPath, and XPath in combination to make this happen.
Listing 12.11 presents the template that we are going to use. It is a simple template as introduced in section 9.4. It assumes the presence of two variables in the binding: a scale, which is needed to make visible box sizes from the attribute values, and weeks, which is a list of week maps. Each week map contains the keys 'capacity', 'total', and 'done' with integer values.
The template resides in a separate file. We like to name such files with the word template in the name and ending in the usual file extension for the format they produce. For example, the name GroovyPlans.template.html reveals the nature of the file, and we can still use it with an HTML editor.
Example 12.11. HTML reporting layout in data/GroovyPlans.template.html
<html>
<head>
<title>Current Groovy progress</title>
</head>
<body>
<% weeks.eachWithIndex{ week, i -> %>
<h1>Week No. $i</h1>
<table cellspacing="5" >
<tbody>
<% ['capacity','total','done'].each{ attr -> %>
<tr>
<td>$attr</td>
<td>${week[attr]} </td>
<td>
<div style=
"border: thin solid #000000; width: ${week[attr]*scale}px">
</div>
</td>
</tr>
<% } // end of attribute %>
</tbody>
</table>
<% } // end of week %>
</body>
</html>This template looks like a JSP file, but it isn’t. The contained logic is expressed in Groovy, not plain Java. Instead of being processed by a JSP engine, it will be evaluated by Groovy’s SimpleTemplateEngine as shown in listing 12.12. We use XPath expressions to prepare the values for binding. A special application of GPath comes into play when calculating the scaling factor.
Scaling is required so that the longest capacity bar is of length 200, so we have to find the maximum capacity for the calculation. Because we have already put these values in the binding, we can use a GPath to get a list of those and play our GDK tricks with it (calling max).

The code did not change dramatically between the text reporting in listing 12.10 and the HTML reporting in listing 12.12. However, listing 12.12 provides a more general solution, because we can also get a text report from it solely by changing the template.
The kind of transformation from XML to HTML that we achieve with listing 12.12 is classically addressed with XML Stylesheet Transformation (XSLT), which is a powerful technology. It uses stylesheets in XML format to describe a transformation mapping, also using XPath and templates. Its logical means are equivalent to those of a functional programming language.
Although XSLT is suitable for mapping tree structures, we often find it easier to use the Groovy approach when the logic is the least bit complex. XPath, templates, builders, and the Groovy language make a unique combination that allows for elegant and concise solutions. There may be people who are able to look at significant amounts of XSLT for more than a few minutes at a time without risking their mental stability, but they are few and far between. Using the technologies you’ve encountered, you can play to your strengths of understanding Groovy instead of using a different language with a fundamentally different paradigm.
Before wrapping up our introduction of processing XML with Groovy, we should mention that although we think that you will find Groovy’s built-in XML features are suitable for many of your processing needs, you are not locked into using just those APIs. Because of Groovy’s Java heritage, many libraries and technologies are available for you to consider. We have already mentioned StAX and Jaxen. Here are a few more of our favorites:[10]
Although
XmlParser,XmlSlurper, and of course the Java DOM and SAX should meet most of your needs, you can always consider JDOM, dom4j, or XOM.If you need to compare two XML fragments for differences, consider XMLUnit.
If you wish to process XML using XQuery, consider Saxon.
If you need to persist your XML, consider JAXB or XmlBeans.
If you need to do high-performance streaming, consider Nux.
Our introduction to Groovy XML could finish at this point, because you have seen all the basics of XML manipulation. You should now be able to write Groovy programs that read, process, and write XML in a basic way. You will need more detailed documentation when the need arises to deal with more advanced issues such as namespaces, resolving entities, and handling DTDs in a customized way.
The final section of this chapter deals not with the details of XML but with one of its most important modern applications: exchanging data between systems, and talking to web services in particular.
XML describes data in a system-independent way. This makes it an obvious candidate for exchanging data across a network. Interconnected systems can be heterogeneous. They may be written in different languages, run on different platforms (think .NET vs. Java), use different operating systems, and run on different hardware architectures. But no matter how different these systems are, they can exchange data through XML, so long as both sides have some idea of how to interpret the XML they are given.
At a simple level, sharing data happens every time you surf the Web. With the help of your browser, you request a URL. The server responds with an HTML document that your browser knows how to display. The server and the browser are interconnected through the Hypertext Transfer Protocol (HTTP) that implements the request-response model, and they use HTML as the data-exchange format.
Now imagine a program that surfs the Web on your behalf. Such a program could visit a list of URLs to check for updates, browse a list of news providers for new information about your favorite topics (we suggest “Groovy”), access a stock ticker to see whether your shares have exceeded the target price, and check the local weather service to warn you about upcoming thunderstorms.
Such a program would have significant difficulties to overcome if it had to find the requested information in the HTML of each web site. The HTML describes not only what the data is, but also how it should broadly be presented. A change to the presentation aspect of the HTML could easily break the program that was trying to understand the data. Instead of dealing with the two aspects together, it would be more reliable if there were an XML description of the pure content. This is what web services are about.
A full description of all web service formats and protocols is beyond the scope of this book, but we will show how you can use some of them with Groovy. We cover reading XML resources via RSS and ATOM, followed by using REST and Groovy’s special XML-RPC support on the client and server side, and finally request SOAP services from Groovy as well as writing a simple web service using Groovy.
In case REST and SOAP make it sound like we’re talking about having a bath instead of accessing web services, you’ll be pleased to hear we’re starting with a brief description of some of these protocols and conventions.
Web service solutions cover a spectrum of approaches from the simple to what some regard as extremely complex. Perhaps the simplest approach is to use the stateless HTTP protocol to request a resource via a URL. This is the basis of the Representational State Transfer (REST) architecture. The term REST has also been used more widely as a synonym for any mechanism for exposing content on the Web via simple XML.
The REST architecture is popular for making content of weblogs available. Two of the most commonly used formats in this area are Really Simple Syndication[11] (RSS) and ATOM (RFC-4287). The next logical extension from using a URL to request a resource is to use simple XML embodied within a normal HTTP POST request. This also can be regarded as a REST solution. We will examine an XML API of this nature as part of our REST tour.
When the focus is not on the remote resource but on triggering an operation on the remote system, the XML Remote Procedure Call (XML-RPC) can be used. XML-RPC uses HTTP but adds context, which makes it a stateful protocol (as opposed to REST).
The SOAP[12] protocol extends the concept of XML-RPC to support not only remote operations but even remote objects. Web service enterprise features that build upon SOAP provide other functionality such as security, transactions, and reliable messaging, to name a few of the many advanced features available.
Now that you have your bearings, let’s look at how Groovy can access two of the most popular web service formats in use today.
Let’s start our day by reading the news. The BBC broadcasts its latest news on an RSS channel. Because we are busy programmers, we are interested only in the top three headlines. A little Groovy program fetches them and prints them to the console. What we would like to see is the headline, a short description, and a URL pointing to the full article in case a headline catches our interest.
Here is some sample output:
The top three news items today: Three Britons kidnapped in Gaza http://news.bbc.co.uk/go/rss/-/1/hi/world/middle_east/4564586.stm Three British citizens have been kidnapped by unidentified gunmen in southern Gaza, police say. ---- Geldof defends Tory adviser role http://news.bbc.co.uk/go/rss/-/1/hi/uk_politics/4564130.stm Bob Geldof promises to stay politically "non-partisan" after agreeing to advise the Tories on global poverty. ---- Glitter 'pays money to accusers' http://news.bbc.co.uk/go/rss/-/1/hi/world/asia-pacific/4563542.stm Former singer Gary Glitter paid his alleged victims' families "for co- operation", his Vietnamese lawyer says. ----
Listing 12.13 implements this newsreader. It requests the web resource that contains the news as XML. It finds the resource by its URL. Passing the URL to the parse method implicitly fetches it from the Web. The remainder of the code can directly work on the node tree using GPath expressions.
Example 12.13. A simple RSS newsreader
def base = 'http://news.bbc.co.uk/rss/newsonline_uk_edition/'
def url = base +'front_page/rss091.xml'
println 'The top three news items today:'
def items = new XmlParser().parse(url).channel[0].item
for (item in items[0..2]) {
println item.title.text()
println item.link.text()
println item.description.text()
println '----'
}Of course, for writing such code, we need to know what elements and attributes are available in the RSS format. In listing 12.13, we assumed that at least the following structure is available:
<rss ...>
<channel>
...
<item>
<title>... </title>
<description>...</description>
<link>... </link>
...This is only a small subset of the full information. You can find a full description of the RSS and ATOM formats and their various versions in RSS and ATOM in Action.[13]
Reading an ATOM feed is equally easy, as shown in listing 12.14. It reads the weblog of David M. Johnson, one of the fathers of the weblog movement. At the time of writing this chapter, it prints
Sun portal 7 to include JSPWiki, hey what about LGPL? ApacheCon Tuesday ApacheCon Tuesday: Tim Bray's keynote ...
One thing that’s new in listing 12.14 is the use of XML namespaces. The ATOM format makes use of namespaces like so:
<feed xmlns="http://www.w3.org/2005/Atom">
...
<entry>
<title>Sun portal ...</title>
...In order to traverse nodes that are bound to namespaces with GPath expressions, qualified names (QName objects) are used. A QName object can be retrieved from a Namespace object by requesting the property of the corresponding element name.
Example 12.14. Reading an ATOM feed
import groovy.xml.Namespace
def url = 'http://rollerweblogger.org/atom/roller?catname=/Java'
def atom = new Namespace('http://www.w3.org/2005/Atom')
def titles = new XmlParser().parse(url)[atom.entry][atom.title]
println titles*.text().join("
")That was all fairly easy, right? The next topic, REST, will be more elaborate but covers a wider area of applicability, because it is a more general approach.
Although most web services are bound to a standard, REST is an open concept rather than a standard. The common denominator of REST services is that
No binding standard describes the structure of the XML that is sent around. You need to look into the documentation of each REST service to find out what information is requested and provided.
For an example, we will look into the REST services of the BackPack web application. BackPack is an online authoring system based on the Wiki[14] concept: It publishes web pages that the author can edit through the browser. You can find it at http://www.backpackit.com. If you want to run the examples from this section, you need to create a free account. You will receive a user-id and a 40-character token for identification. In the following examples, we will use the user-id user and *** as the token. When trying the examples, you need to replace these placeholders with your personal values.
Occasionally, it’s helpful to update the published information programmatically through the REST API. Suppose you have published information about your favorite books’ selling rank, your corporate web site’s Alexa[15] rating, or your current project’s tracking status. With the REST API, you can update such information automatically.
BackPack describes its REST API under http://www.backpackit.com/api. You will find 32 operations together with the XML structure they expect in the request and the XML they respond with.
For example, the create new page operation is available under the URL
http://user.backpackit.com/ws/pages/newIt expects this XML in the request:
<request> <token>***</token> <page> <title>new page title</title> <description>initial page body</description> </page> </request>
If the operation is successful, it returns
<response success='true'>
<page title='new page title' id='1234' />
</response>Now, how do you get this running from Groovy? You need some way to connect to the URL and send the request XML. You can do this with a UrlConnection and the POST method. The API additionally demands that you set the request header 'X-POST_DATA_FORMAT' to 'xml'. It would be nice to put all the infrastructure code in one place and provide your own little Groovy-friendly API.
To use this API to create a new page, update the content, and finally delete it, the code should be as simple as in Listing 12.15.
Example 12.15. BackPack page manipulation through the Groovy REST API
def bp = new BackPack(account:"user", key:"***") def response = bp.newPage("Page Title", "Page Description") def pageId = response.page.@id println "created page $pageId" response = bp.updateBody(pageId, "new Body") println "updating body ok: ${response.@success}" response = bp.destroyPage(pageId) println "destroying page ok: ${response.@success}"
When every operation succeeds (and when you have the appropriate API in place), listing 12.15 prints
created page 383655 updating body ok: true destroying page ok: true
The infrastructure class BackPack that implements the Groovy API to the BackPack REST API was written by John Wilson, the grandmaster of Groovy XML, and the full version is available at http://www.wilson.co.uk/Groovy/BackpackAPI.txt.
Listing 12.16 shows a stripped-down version of the original, not covering all operations and without proper error handling. This implementation makes the code in listing 12.15 run, shows the infrastructure code needed for using the HTTP POST method, uses the typical Groovy trick of overriding invokeMethod to make a nice API, and is another compelling example of using builders and parsers with streams.

A call to bp.newPage will be handled by invokeMethod, which looks up the name newPage in the methods map declared at ![]() . The
. The methods map stores a closure under that name, which invokeMethod immediately calls ![]() , relaying all parameters (
, relaying all parameters (title and description) to it.
The closure calls the makeRemoteCall method, providing the distinctive part of the URL that locates the service and a markup closure that is used at ![]() to build the request XML.
to build the request XML.
When using a REST API, it is often beneficial to create an infrastructure class like BackPack in listing 12.16. It is hardly possible to provide a more general solution that can be used with every REST service, because there is no standard that you can build upon.
You will see how useful such a standard is when we look into XML-RPC in the next section.
The XML-RPC specification is almost as old as XML. It is extremely simple and concise. See http://www.xmlrpc.com for all details.
Thanks to this specification, Groovy can provide a general implementation for many of the infrastructure details that you have to write for REST. This general implementation comes with the Groovy distribution.[16] There is nothing extra you have to do or install to make this easy distributed processing environment work.
Perhaps the best way to convince you of its merits is by example. Suppose you have a simple XML-RPC server running on your local machine on port 8080 that exposes an echo operation that returns whatever it receives. Using this service from a Groovy client is as simple as
import groovy.net.xmlrpc.XMLRPCServerProxy as Proxy
def remote = new Proxy('http://localhost:8080/')
assert 'Hello world!' == remote.echo('Hello world!')Installing a server that implements the echo operation is equally easy. Create a server instance, and assign a closure to its echo property:
import groovy.net.xmlrpc.XMLRPCServer as Server
def server = new Server()
server.echo = { return it }Finally, the server must be started on a ServerSocket before the client can call it, and it must be stopped afterward. Listing 12.17 installs the echo server, starts it, requests the echo operation, and stops it at the end.

Having client and server together as shown in listing 12.17 is useful for testing purposes, but in production these two parts usually run on different systems.
XML-RPC also defines fault handling, which in Groovy XML-RPC is available through the XMLRPCCallFailureException with the properties faultString and faultCode.
The areas of applicability for XML-RPC are so wide that any list we could come up with would be necessarily incomplete. It is used for reading and posting to blogs, connecting to instant messaging systems (over the Jabber protocol for systems such as GoogleTalk[17]), news feeds, search engines, continuous integration servers, bug-tracking systems, and so on.
It’s appealing because it is powerful and simple at the same time. Let’s for example find out information about the projects managed at Codehaus.[18] Codehaus provides the JIRA[19] bug-tracking system for its hosted projects.
Printing all project names can be done easily with the following code:
import groovy.net.xmlrpc.XMLRPCServerProxy as Proxy
def remote = new Proxy('http://jira.codehaus.org/rpc/xmlrpc')
def loginToken = remote.jira1.login('user','***')
def projects = remote.jira1.getProjects(loginToken)
projects.each { println it.name }It’s conventional for operations exposed via XML-RPC to have a dot-notation like jira1.login. Groovy’s XML-RPC support can deal with that.
However, if you call a lot of methods, using remote.jira1. gets in the way of readability. It would be nicer to avoid that. Listing 12.18 has a solution. Calls to proxy methods can always optionally take a closure. Inside that closure, method names are resolved against the proxy. We extend this behavior with a specialized JiraProxy that prefixes method calls with jira1..
To make things a bit more interesting this time, we print some information about the Groovy project in the Codehaus JIRA.
Example 12.18. Using the JIRA XML-RPC API on the Groovy project
import groovy.net.xmlrpc.XMLRPCServerProxy as Proxy
class JiraProxy extends Proxy {
JiraProxy (url) { super ( url ) }
Object invokeMethod(String methodname, args) {
super.invokeMethod('jira1.'+methodname, args)
}
}
def jira = new JiraProxy('http://jira.codehaus.org/rpc/xmlrpc')
jira.login('user','***') { loginToken ->
def projects = getProjects(loginToken)
def groovy = projects.find { it.name == 'groovy' }
println groovy.key
println groovy.description
println groovy.lead
}This prints
GROOVY Groovy JVM language. guillaume
Note the simplicity of the code. Unlike with REST, you don’t need to work on XML nodes, either in the request or in the response. You can just use Groovy datatypes such as strings (user), lists (projects), and maps (groovy). Who can ask for more?
There would be a book’s worth more to say about XML-RPC and its Groovy module, especially about implementing the server side. But this book has only so many pages, and you need to refer to the online documentation for more details and usage scenarios.
You now have the basic information to start your work with XML-RPC. Try it! Of all the distributed processing approaches, this is the one that feels the most groovy to us.
We will close our tour through the various options for distributed processing with the all-embracing solution: SOAP.
SOAP is the successor of XML-RPC and follows the approach of providing a binding standard. This standard is maintained by the W3C; see http://www.w3.org/TR/soap/.
The SOAP standard extends the XML-RPC standard in multiple dimensions. One extension is datatypes. Where XML-RPC allows only a small fixed set of datatypes, SOAP provides means to define new service-specific datatypes. Other frameworks, including CORBA, DCOM, and Java RMI, provide functionality similar to that of SOAP, but SOAP messages are written entirely in XML and are therefore platform and language independent. The general approach of SOAP is to allow a web service to describe its public API: where it is located, what operations are available, and the request and response formats (called messages). A SOAP service makes this information available via the Web Services Definition Language (WSDL).
SOAP has been widely adopted by the industry, and numerous free services are available, ranging from online shops through financial data, maps, music, payment systems, online auctions, order tracking, blogs, news, picture galleries, weather services, credit card validation—the list is endless.
Numerous programming languages and platforms provide excellent support for SOAP. Popular SOAP stack implementations on the Java platform include Jakarta Axis (http://ws.apache.org/axis/) and XFire (http://xfire.codehaus.org/). Built-in SOAP support for Groovy is still in its infancy, but it’s already in use for production projects. First, we will explore how you can use SOAP with pure Groovy in an effective yet concise manner.
Our example uses a web service at http://www.webservicex.net, which provides a lot of interesting public web services. First, we fetch the service description for its currency converter like so:
import groovy.xml.Namespace
def url = 'http://www.webservicex.net/CurrencyConvertor.asmx?WSDL'
def wsdl = new Namespace('http://schemas.xmlsoap.org/wsdl/','wsdl')
def doc = new XmlParser().parse(url)
println doc[wsdl.portType][wsdl.operation].'@name'This prints the available operations:
["ConversionRate", "ConversionRate", "ConversionRate"]
The service exposes three operations named ConversionRate with different characteristics.[20] We are interested in one that takes FromCurrency and ToCurrency as input parameters and returns the current conversion rate. Currencies can be expressed using a format like 'USD' or 'EUR'.
SOAP uses something called an envelope format for the request. The details are beyond the scope of this chapter—see the specifications for details. Our envelope looks like this:
<?xml version="1.0" encoding="utf-8"?>
<soap:Envelope
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<ConversionRate xmlns="http://www.webserviceX.NET/">
<FromCurrency>${from}</FromCurrency>
<ToCurrency>${to}</ToCurrency>
</ConversionRate>
</soap:Body>
</soap:Envelope>As you see from the ${} notation, this envelope is a template that we can use with a Groovy template engine.
Listing 12.19 reads this template, fills it with parameters for US dollar to euro conversion, and adds it to a POST request to the service URL. The request needs some additional request headers—for example, the SOAPAction to make the server understand it. We explicitly use UTF-8 character encoding to avoid any cross-platform encoding problems.
The service responds with a SOAP result envelope. We know it contains a node named ConversionRateResult belonging to the service’s namespace. We locate the first such node in the response and get the conversion rate as its text value.

At the time of writing, it prints
Current USD to EUR conversion rate: 0.8449
This is straightforward in terms of each individual step, but taken as a whole, the code is fairly cumbersome. One point to note about the implementation is hidden in locating the result in the response envelope. We use the serv namespace and ask it for its ConversionRateResult property, which returns a QName. We assign it to the result variable and make use of the fact that QName implements the equals method with strings such that we find the proper node.
SOAP is verbose compared to other approaches. It is verbose in the code it demands for execution and—more important—it is verbose in its message format. It is not unusual for SOAP messages to have 10 times more XML markup then the payload size.
However, the SOAP standard makes it possible to provide general tools for dealing with its complexity.
One of these tools is the GroovySOAP module, which eases the process of using web services. Download the required jar files as outlined at http://groovy.codehaus.org/Groovy+SOAP, and drop them into your GROOVY_HOME/lib directory. As an example of what you get from the GroovySOAP, listing 12.20 implements the SOAP client for the conversion rate service with a minimum of effort.
Example 12.20. Using the SoapClient from the GroovySOAP module
import groovy.net.soap.SoapClient
def url = 'http://www.webservicex.net/CurrencyConvertor.asmx?WSDL'
def remote = new SoapClient(url)
println 'USD to EUR rate: '+remote.ConversionRate('USD', 'EUR')Now, that’s a lot groovier! Should your server be using a complex datatype in its response, GroovySOAP will unmarshall it and define a variable in your script. This can be demonstrated using the weather forecast located at webservicex.net. Using a place name located in the USA as an input, the web service replies with a one-week weather forecast in a complex document. Listing 12.21 nicely presents the data with the help of GroovySOAP.
Example 12.21. Using complex data types with the SoapClient
import groovy.net.soap.SoapClient
def url = 'http://www.webservicex.net/WeatherForecast.asmx?WSDL'
def proxy = new SoapClient(url)
def result=proxy.GetWeatherByPlaceName("Seattle")
println result.latitude
println result.details.weatherData[0].weatherImage47.6114349 http://www.nws.noaa.gov/weather/images/fcicons/sct.jpg
Suppose now that you want to develop your own server. GroovySOAP allows the construction of such a service from a simple Plain Old Groovy Object (POGO) representing your business logic. If you wanted to set up a small math server,[21] you could have a script that looks like listing 12.22.
Example 12.22. The Groovy SOAP service script MathService.groovy
double add(double op1, double op2) {
return (op1 + op2)
}
double square(double op1) {
return (op1 * op1)
}Note that there is nothing about the script that suggests it has anything to do with a web service. Listing 12.23 exposes this POGO as a web service.
Example 12.23. Using the SoapServer from the GroovySOAP module
import groovy.net.soap.SoapServer
def server = new SoapServer("localhost", 6990)
server.setNode("MathService")
System.out.println("start Math Server")
server.start()This little bit of magic is possible thanks to the delegation pattern and introspection that enables GroovySOAP to generate automatically the web service interface by filtering the methods inherited from the GroovyObject interface.
It’s worth paying attention to this area of ongoing Groovy development. We anticipate that before long, new SOAP tools will arise and provide more functionality for using web services with Groovy.
XML is such a big topic that we cannot possibly touch all bases in an introductory book on Groovy. We have covered the most important aspects in enough detail to provide a good basis for experimentation and further reading. When pushing the limits with Groovy XML, you will probably encounter topics that are not covered in this chapter. Don’t hesitate to consult the online resources.
At this point, you have a solid basis for understanding the different ways of working with XML in Groovy.
Using the familiar Java DOM parsers in Groovy enables you to work on the standard org.w3c.com.Node objects whenever the situations calls for it. Such nodes can be retrieved from the DOMBuilder, conveniently accessed with the help of DOMCategory, and investigated with XPath expressions. Groovy makes life with the DOM easier, but it can’t rectify some of the design decisions that give surprises or involve extra work for no benefit.
Groovy’s internal XmlParser and XmlSlurper provide access to XML documents in a Groovy-friendly way that supports GPath expressions for working on the document. XmlParser provides an in-memory representation for in-place manipulation of nodes, whereas XmlSlurper is able to work in a more stream-like fashion. For even further memory reductions, you can also use SAX and StAX.
Finally, it’s easy to send XML around the world to make networked computers work together, sharing information and computing power. XML-RPC and SOAP have support in the Groovy libraries, although that support is likely to change significantly over time. REST can’t benefit from such support as easily (not even in the dynamic world of Groovy) due to a lack of standardization, but you have seen how the use of builders can make the development of an API for a specific REST service straightforward.
Whatever your XML-based activity, Groovy is likely to have something that will ease your work. By now, that shouldn’t come as a surprise.
[1] We recommend XML Made Simple by Deane and Henderson (Made Simple, 2003) as an introductory text and XML 1.1 Bible by Elliotte Rusty Harold (Wiley, 2004) for more comprehensive coverage.
[2] The DocumentBuilderFactory can be augmented in several ways to deliver various DocumentBuilder implementations. See its API documentation for details.
[4] This is short for: a list of references to objects of type groovy.util.Node with name()=='week'.
[5] See http://www.xml.com/pub/a/2003/09/17/stax.html for a tutorial introduction.
[6] This is the main event-based style supported by .NET and will also be included with Java 6.
[7] For a full description of the standard, see http://www.w3.org/TR/xpath; and for a tutorial, see http://www.w3schools.com/xpath/.
[8] This covers only XPath 1.0 because XPath 2.0 is not yet finalized at the time of writing.
[9] When performance is crucial, consider using the Jaxen XPath library which is used by JDOM, dom4j, and XOM for their processing needs as well as being useful on its own.
[10] More information is available at: http://xmlbeans.apache.org/, http://saxon.sourceforge.net/, http://dsd.lbl.gov/nux/, http://xmlunit.sourceforge.net/, and http://java.sun.com/webservices/jaxb/.
[11] Also called Rich Site Summary (RSS 0.9x) or Resource Description Framework (RDF) Site Summary (RSS 1.0).
[12] SOAP used to stand for Simple Object Access Protocol, but this meaning has been dropped since version 1.2 because SOAP does more than access objects and the word simple was questionable from the start.
[13] Dave Johnson, RSS and ATOM in Action (Manning, 2006).
[14] Bo Leuf and Ward Cunningham, The Wiki Way: Quick Collaboration on the Web (Addision-Wesley Professional, 2001).
[15] www.alexa.com is a rating service for the popularity of web sites.
[16] It’s not in groovy-all-*.jar but in the GROOVY_HOME/lib directory.
[17] See Guillaume’s excellent article on how to use GoogleTalk through Groovy at http://glaforge.free.fr/weblog/index.php?itemid=142.
[18] www.codehaus.org is the open source platform that hosts popular open source projects such as Groovy and Maven.
[19] Find information about the JIRA XML-RPC methods at http://confluence.atlassian.com/display/JIRA/JIRA+XML-RPC+Overview.
[20] For advice on how to read a WSDL service description, refer to http://www.w3.org/TR/wsdl.
[21] Simple calculations and currency conversions have become the “hello world” of web service examples.