
Chapter 4. Extracting intelligence from content
Content as used in this chapter is any item that has text associated with it. This text can be in the form of a title and a body as in the case of articles, keywords associated with a classification term, questions and answers on message boards, or a simple title associated with a photo or video. Content can be developed either professionally by the site provider or by users (commonly known as user-generated content), or be harvested from external sites via web crawling.[1]
Content is the fundamental building block for developing applications. This chapter provides background on integrating and analyzing content in your application. It’ll be helpful to go through the example developed in section 4.3, which illustrates how intelligence can be extracted from analyzing content.
In this chapter, we take a deeper look into the many types of content, and how they can be integrated into your application for extracting intelligence. A book on collective intelligence wouldn’t be complete without a detailed discussion of content types that get associated with collective intelligence and involve user interaction: blogs, wikis, groups, and message boards. Next, we use an example to demonstrate step by step how intelligence can be extracted from content. Having learned the similarities among these content types, we create an abstraction model for analyzing the content types for extracting intelligence.
4.1. Content types and integration
Classifying content into different content types and mapping each content type into an abstraction (see section 4.4) allows us to build a common infrastructure for handling various kinds of content.
In this section, we look at the many forms of content in an application and the various forms of integration that you may come across to integrate these content types.
4.1.1. Classifying content
Table 4.1 shows some of the content types that are used in applications along with the way they’re typically created. Chances are that you’re already familiar with most of the content types.
Table 4.1. The different content types
You’re probably familiar with articles and products. We talked about classification terms in section 3.2.1 and their use for dynamic navigation links. Classification terms are any ad hoc terms that may be created; they’re similar to topic headers. An example best illustrates them.
Let’s say that one of the features in your application is focused on providing relevant news items. You know that global warming is an important area of interest to your users. So you create the classification term global warming and assign it appropriate tags or keywords. Then the process of finding relevant content for this term for a user can be treated as a classification problem—using the user’s profile and the keywords assigned to the term, find other items that the user will be interested in. The other content types could be news articles, blog entries, information from message boards and chat logs, videos, and so on.
Another manifestation of classification terms is when information is extracted from a collection of content items to create relevant keywords. In the previous example, rather than assigning tags or keywords to the term global warming, you’d take a set of items that you think best represents the topic and let an automated algorithm extract tags from the set of articles. In essence, you’ll get items that are similar to the set of learning items.
In section 4.2, we take a more detailed look at three content types that are normally associated with collective intelligence: blogs, wikis, and groups and message boards. All three of these involve user-generated content. The remaining content types are fairly straightforward.
So far we’ve looked at some of the different kinds of content that you may use in your application. We need to integrate these content types into our intelligence learning services that we talked about in section 2.1.
4.1.2. Architecture for integrating content
At the beginning of chapter 2, we looked at the architecture for integrating intelligence into your application. Let’s extend it for integrating content into your application. Based on your business requirements and existing infrastructure, you’ll face one of the following three ways to integrate content into your application:
- Use standalone, freely available open source or commercial software within your firewall, hosted as a separate instance.
- Rebuild the basic functionality within your application.
- Integrate data from an externally hosted site.
This section covers how each of these cases can be integrated into your application to extract data. There are two forms of information that we’re interested in:
- The user interaction with the content. This could be in the form of authoring the content, rating it, reading it, bookmarking it, sharing it with others, and so on.
- The actual content itself. We need it to index it in our search engine and extract metadata from it.
Let’s look at the first case, in which the functionality is available in a server hosted within your firewall but as a separate instance.
Internally Hosted Separate Instance
Figure 4.1 shows the architecture for integrating content from separate servers hosted within your firewall. Here, the application server could either make REST calls to the other server or redirect the HTTP request to the external server. Since all calls go through the application server, both user interaction information and the content when edited can be persisted to the database for use by the intelligence learning services.
Figure 4.1. Architecture for integrating internally hosted separate instances server

Integrated into the Application
The second case is when the basic functionality for the feature—for example, blogs—is built within the web app of your application server. You may choose this approach to integrate this functionality into your application when you need a lot more control over the look-and-feel than hosting it as a separate instance. In this case, the architecture for learning is the same as we covered in section 2.1.
Externally Hosted
Many times you may have a relationship with an external vendor to outsource certain features of your application, or need to integrate content from another partner. The simplest way to integrate is to provide a link to the externally hosted server. In essence, as users click on the link, they’re transferred to the other site—your application loses the user. There’s no information available to your application, unless the external site posts you that information, as to what the user did on the site. If you want to learn from what users did at the external site, you’ll need their user-interaction information and the text for the content.
Another challenge is coordinating sessions. The user’s session shouldn’t time out in your application as she interacts on the other site. Managing single-signons and receiving data are some of the technical challenges that you’ll face in this approach. Though this is probably the easiest approach to add new functionality, it’s the least user friendly and least desirable approach from an intelligence point of view.
So far, we’ve classified content into different content types and looked at three ways of integrating them in your application. Next, let’s take a more detailed look at a few of the content types that are associated with collective intelligence.
4.2. The main CI-related content types
In this section, we look at three content types that are typically associated with collective intelligence: blogs, wikis, and groups and message boards. All these content types are user generated, and users through their opinions and contributions with these content types shape the thoughts of others.
User-generated content plays an important part in influencing others—here’s an example of how they affected me last year. Last summer, my printer stopped working after I’d changed the cartridge. After reinstalling the cartridge a few times and trying to print, I gave up. On searching the web, I found an online community where others had written in detail about similar problems with the same brand of printer. Evidently, there was a problem with the way the printing head was designed that caused it to fail occasionally while changing cartridges. Going through the postings, I found that initially a number of users had expressed their frustration at the failure of the printer, promising never to buy again from the vendor. After a few initial postings, I found that someone had left information about how to contact the customer support department for the vendor. The manufacturer was shipping an upgraded version of the printer to anyone who had experienced the problem. The recent postings tended to have a positive tone, as the users got a brand-new printer from the manufacturer. The next morning, I called the manufacturer’s customer support number and had a new printer in a few days.
For each of these three content types, we describe what they are and how they are used, and model the various elements and develop the persistence schema. We use blogs as an example to illustrate the process of extracting intelligence from content in the second and third part of the book. It’s therefore helpful to understand the structure of a blog in detail.
4.2.1. Blogs
Blogs, short for weblogs, are online personal journals where you write about things you want to share with others; others can comment on your entries and link to your site. Blogs typically are written in a diary style and contain links to other websites. There are blogs on virtually every topic; a blog may cover a range of topics from the personal to the political, or focus on one narrow subject.
Use of Blogs
As a part of writing this book, I went through numerous blogs. There were blogs on almost every topic covered in this book, as you can see from the references in the various chapters. The popularity of blogs can be measured by both the number of blogs in the blogosphere and the references to blogs that people cite in publications.
Blogs appear in three different contexts:
- In a corporate website —Corporations use blogs to connect with their shareholders, customers, staff, and others. Blogs can be used to solicit feedback on important decisions and policies. Blogs also serve as a good forum for conveying the rationale for certain decisions or policies and for getting feedback on product features that you’re developing. An internal blog within the company may be a good medium for groups to collaborate together, especially if they’re geographically dispersed. Similarly, consultants often develop their brands and reputations with their blogs.
- Within your application— Applications can leverage blogs both internally and externally by providing contextually relevant information. Allowing users to blog within your application generates additional content that can be viewed by others. User-generated content and blogging in particular can help improve the visibility of your application and boost your search index ranking. If your blog is widely followed, with a number of people linking to it, it’ll show up higher in search engine results. Furthermore, if your application or corporate website is linked to your blog, its ranking will be boosted further, since it’s connected to a highly linked page.
- All other blogs in the blogosphere— Other blogs in the blogosphere can have an impact on your brand. A favorable blog entry by an influential person can create a buzz around your product, while a negative reference could spell doom for the product.
So far we’ve looked at what blogs are and how they’re used. If you’re thinking of building blogs in your application, it’s useful to look at the various elements of a blog. Reviewing the class diagram to model blogs and a typical persistence schema for blogs should help you understand the basic elements. This information will also be useful in the next chapter, where we look at searching the blogosphere. We review these next.
Modeling the Elements of Blog
As shown in figure 4.2, a Blog consists of a number of blog entries such as BlogEntry—a BlogEntry is fully contained in a Blog. Associated with a BlogEntry are comments made by others, represented as a List of BlogEntryComments. The BlogEntry may have been tagged by the author; this is contained in BlogEntryTag. References by other blogs are contained in a List of ReferenceWeblogs.
Figure 4.2. Class model for representing a blog for a user

Using the class diagram, we can build a corresponding persistence schema for blogs using five tables, as described in table 4.2.
Table 4.2. Description of the tables used for persistence
|
Table |
Description |
|---|---|
| blog | Represents the blogs for the various users. |
| blog entry | Each blog entry is represented as a row. If you allow users to modify their blogs and want to keep a history of changes then you need to keep a version ID. The version id is incremented after every modification to the blog-entry. |
| blog entry history | This is a history table that’s updated via a trigger whenever there’s a modification to the BlogEntry table. The primary key for this table is blog entry id, version id. |
| reference-weblog | Stores the list of blogs referencing the blog entry. |
| blog Entry comment | This stores the list of comments associated with the blog entry. |
Figure 4.3 shows the persistence schema for a blog. There are a few things to note about the schema design. If you want to keep a history of modifications made by users in their blog entries, you need to have a version_id associated with every blog entry. This gets updated after every modification. There’s a corresponding history table blog_entry_history that can be populated via a database trigger.
Figure 4.3. Persistence schema for blogs

Using the class diagram and the persistence schema, you should have a good understanding of elements of a blog, blog entries, blog comments, and reference weblogs. This information is also useful in the next chapter, which deals with searching the blogosphere. Next, we briefly look at the second content type that is associated with collective intelligence: wikis.
4.2.2. Wikis
In May 2006, Meebo (www.meebo.com) was getting requests for Spanish-language translations of its application. Meebo is a startup company that uses AJAX to build a browser-based application that can connect to multiple instant messengers in one location. Meebo set up a wiki and allowed their users to submit translations in different languages. Last I checked, there were more than 90 different languages that users were contributing to.
Wikipedia, with more than five million articles in 229 languages, is probably the poster child of how wikis can be used to develop new applications. Wikipedia is cited by Alexa as one of the top 20 visited sites and is widely cited. If you’re interested in a topic and search for it, chances are that a Wikipedia article will show up in the first few listings—the breadth of topics, number of articles, and the large number of external sites (blogs, articles, publications) linking to its articles boost the ranking of Wikipedia pages.
Wikis are good for online collaboration, since users can easily edit, add, or delete web pages. All changes are stored in the database. Each modification can be reviewed and information can be reverted back if required. The wiki style of development promotes consensus or democratic views on a topic.
We briefly review how wikis are used. Model the elements of a wiki and develop its persistence model to understand a wiki’s core components.
Use of Wikis
Nowadays, almost all software projects use a wiki as a collaboration tool for documenting and developing software. There are a number of open source wiki implementations, so the cost associated with having a wiki is low. Table 4.3 list some of the ways that wikis are used.
Table 4.3. Uses of wikis
|
Use |
Description |
|---|---|
| Online collaboration | They’re good for online collaborations between groups. Each person can contribute her thoughts and the information is accessible to anyone with access to the wiki. |
| Harnessing user contributions—crowd sourcing | Wikis are good at involving your users to develop your product. You may want to start a wiki in your application, perhaps to develop an FAQ, an installation guide, help section, or anything where the collective power of user contributions can be leveraged. Users get a sense of ownership and cover a wide range of use cases that would otherwise be too difficult or expensive to build. |
| Boosting search engine ranking | As with all user-generated content, wiki content, especially if it’s extensively linked, can help improve the search rank visibility of your application. |
| Knowledge repository | How many times have you been working on a project and someone starts an email chain discussing an issue? As the email chain gets longer and longer, it’s more and more difficult and time consuming to keep up with it. This information is also available to only those who participate in the email chain. The barrage of emails can also slow productivity for those who don’t want to actively participate in the discussion. Wikis offer an excellent alternative. Unlike email, Wiki content is available for anyone and can be searched and retrieved easily. |
There are literally hundreds of Wiki software programs available in dozens of languages (see http://c2.com/cgi/wiki?WikiEngines). Wikipedia has a good comparison between the features of the top WikiEngines at http://en.wikipedia.org/wiki/Comparison_of_wiki_software. There is good information on how to choose a Wiki at http://c2.com/cgi/wiki?ChoosingaWiki.
Modeling the Users, Pages, and Categories
Every wiki consists of a number of categories. Within each category are zero or more pages, as shown in figure 4.4. A page can belong to one or more categories. Users create and edit pages, categories, and the relationship between the pages and the categories.
Figure 4.4. Relationship between a page, a category, and a user in a wiki
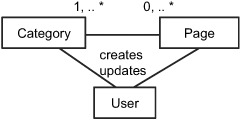
The category page is an example of the CompositeContentType that we introduce in section 4.4 for extracting intelligence.
Figure 4.5 shows a persistence model for a wiki. Also, a blob is used for the text of a page, allowing the users to create a large document.
Figure 4.5. Persistence model for a wiki

We’ve briefly reviewed wikis: what they are, how they’re used, the elements of a wiki, and how they can be persisted. Lastly, let’s look at the third content type associated with collective intelligence: groups and message boards.
4.2.3. Groups and message boards
Message boards are places where you can ask questions and others can respond to them, as well as rate them for usefulness. Message boards are usually associated with groups. A group is a collection of users that share a common interest, where users can participate in threaded conversations. Groups usually have a mailing list associated with them where members can get updates over email. Yahoo! has more than a million groups on virtually every subject, from data mining, to groups on companies, dogs, and marathons. There are hundreds of message boards, and you can find a list of them at http://www.topology.org/net/mb.html and http://dmoz.org/Computers/Internet/On_the_Web/Message_Boards/.
Use of Message Boards
Groups can be useful in your application for bringing together people with similar interests and tastes. In a blog, people respond to writing by a single user or a group of bloggers, who collectively share the responsibility of writing blog entries; this is especially true in the case of corporate blogs. However, in a group or a message board, any user can pose a question to which others can respond. Message boards along with wikis are more collaborative. Since multiple people can post and comment on questions, message boards need to be moderated and managed to weed out spam and flames. Each entry in a message board should be indexed separately by a search engine.
Modeling Groups and Message Boards
As shown in table 4.4, groups, topics, questions, messages, and users are the main entities for groups and message boards.
Table 4.4. Entities for message boards and groups
|
Entity |
Description |
|---|---|
| Groups | Collections of users that have a common cause or interest |
| Topics | Groups consist of a number of topics or categories |
| Questions | Users pose questions within a topic |
| Messages | Posted in response to a question or an answer provided |
| User | Can create, become a member of, view, or rate any of the above entities |
As shown in figure 4.6, each group consists of a number of topics; each topic has a number of questions; each question has a number of messages or answers. A user can belong to multiple groups; can create a group, topic, question, or answer; and can rate any of these entities. Again, groups, topics, and question are all examples of CompositeContentTypes, which we discuss in section 4.3. Figure 4.7 shows the schema for the elements of a message board.
Figure 4.6. Modeling a message board or a group

Figure 4.7. The schema for the elements of a message board

In this section, we’ve looked at three content types that are typically associated with collective intelligence: blogs, wikis, and groups and message boards. We’ve looked at the elements of these content types, how they’re used, and the relationship between their various elements. Now we’re ready to take a more detailed look at how intelligence is extracted from analyzing content.
4.3. Extracting intelligence step by step
In section 2.2.3, we introduced the use of term vectors to represent metadata associated with text. We also introduced the use of term frequency and inverse document frequency to compute the weight associated with each term. This approach is an example of using the content to generate the metadata. In section 3.3, we demonstrated a collaborative approach using user tagging to generate similar metadata with text.
At this stage, it’s helpful to go through an example of how the term vector can be computed by analyzing text. The intent of this section is to demonstrate concepts and keep things simple; therefore we develop simple classes for this example. Later, in chapter 8, we use open source libraries for analyzing text, but going through the code developed in this chapter should give you good insight into the fundamentals involved.
If you haven’t done so already, it’s worthwhile to review section 2.2.3, which gives an overview of generating metadata (term vectors) from text, and section 3.2.1 on tag clouds, which we use to visualize the data.
Remember, the typical steps involved in text analysis are shown in figure 4.8:
1. Tokenization—Parse the text to generate terms. Sophisticated analyzers can also extract phrases from the text.
2. Normalize—Convert them to lowercase.
3. Eliminate stop words—Eliminate terms that appear very often.
4. Stemming—Convert the terms into their stemmed form—remove plurals.
Figure 4.8. Typical steps involved in analyzing text
![]()
In this section, we set up the example that we’ll use. We first use a simple but naïve way to analyze the text—simply tokenizing the text, analyzing the body and title, and taking term frequency into account. Next, we show the results of the analysis by eliminating the stop words, followed by the effect of stemming. Lastly, we show the effect of detecting phrases on the analysis.
4.3.1. Setting up the example
Let’s assume that a reader has posted the following blog entry:
- Title: Collective Intelligence and Web2.0 Body: Web2.0 is all about connecting users to users, inviting users to participate, and applying their collective intelligence to improve the application. Collective intelligence enhances the user experience.
There are a few interesting things to note about the blog entry:
- It discusses collective intelligence, Web 2.0, and how they affect users.
- There are a number of occurrences of user and users.
- The title provides valuable information about the content.
We’ve talked about metadata and term vectors; code for this is fully developed in chapter 8. So as not to confuse things for this example, simply think of metadata being represented by an implementation of the interface MetaDataVector, as shown in listing 4.1.
Listing 4.1. The MetaDataVector interface

We have two methods: one for getting the terms and their weights and the second to add another MetaDataVector. Further, assume that we have a way to visualize this MetaDataVector; after all, it consists of tags or terms and their relative weights.[2]
2 If you really want to see the code for the implementation of the MetaDataVector, jump ahead to chapter 8 or download the available code.
Let’s define an interface MetaDataExtractor for the algorithm that will extract metadata, in the form of keywords or tags, by analyzing the text. This is shown in listing 4.2.
Listing 4.2. The MetaDataExtractor interface
package com.alag.ci.textanalysis;
import com.alag.ci.MetaDataVector;
public interface MetaDataExtractor {
public MetaDataVector extractMetaData(String title, String body);
}
The interface has only one method, extractMetaData, which analyzes the title and body to generate a MetaDataVector. The MetaData-Vector in essence is the term vector for the text being analyzed.
Figure 4.9 shows the hierarchy of increasingly complex text analyzers that we use in the next few sections. First, we use a simple analyzer to create tokens from the text. Next, we remove the common words. This is followed by taking care of plurals. Lastly, we detect multi-term phrases. With this background, we’re now ready to have some fun and work through some code to analyze our blog entry!
Figure 4.9. The hierarchy of analyzers used to create metadata from text

4.3.2. Naïve analysis
Let’s begin by tokenizing the text, normalizing it, and getting the frequency count associated with each term. We also analyze the body and text separately and then combine the information from each. For this we use SimpleMetaDataExtractor, which is a naïve implementation for our analyzer, shown in listing 4.3.
Listing 4.3. Implementation of the SimpleMetaDataExtractor

Since the title provides valuable information as a heuristic, let’s say that the resulting MetaDataVector is a combination of the MetaDataVectors for the title and the body. Note that as tokens or tags are extracted from the text, we need to provide them with a unique ID; the method getTokenId takes care of it for this example. In your application, you’ll probably get it from the tags table.
The following code extracts metadata for the article:
MetaDataVector titleMDV = getMetaDataVector(title); MetaDataVector bodyMDV = getMetaDataVector(body); return titleMDV.add(bodyMDV);
Here, we create MetaDataVectors for the title and the body and then simply combine them together.
As new tokens are extracted, a unique ID is assigned to them by the code:
private Long getTokenId(String token) {
Long id = this.idMap.get(token);
if (id == null) {
id = this.currentId ++;
this.idMap.put(token, id);
}
return id;
}
The remaining piece of code, shown in listing 4.4, is a lot more interesting.
Listing 4.4. Continuing with the implementation of SimpleMetaDataExtractor

Here, we use a simple StringTokenizer to break the words into their individual form:
StringTokenizer st = new StringTokenizer(text);
while (st.hasMoreTokens()) {
We want to normalize the tokens so that they’re case insensitive—that is, so user and User are the same word—and also remove the punctuation (comma and period).
String token = normalizeToken(st.nextToken());
The normalizeToken simply lowercases the tokens and removes the punctuation:
protected String normalizeToken(String token) {
String normalizedToken = token.toLowerCase().trim();
if ( (normalizedToken.endsWith(".")) ||
(normalizedToken.endsWith(",")) ) {
int size = normalizedToken.length();
normalizedToken = normalizedToken.substring(0, size -1);
}
return normalizedToken;
}
We may not want to accept all the tokens, so we have a method acceptToken to decide whether a token is to be expected:
if (acceptToken(token)) {
All tokens are accepted in this implementation.
The logic behind the method is simple: find the tokens, normalize them, see if they’re to be accepted, and then keep a count of how many times they occur. Both title and body are equally weighted to create a resulting MetaDataVector. With this, we’ve met our goal of creating a set of terms and their relative weights to represent the metadata associated with the content.
A tag cloud is a useful way to visualize the output from the algorithm. First, let’s look at the title, as shown in figure 4.10. The algorithm tokenizes the title and extracts four equally weighted terms: and, collective, intelligence, and web2.0. Note that and appears as one of the four terms and collective and intelligence are two separate terms.
Figure 4.10. The tag cloud for the title consists of four terms.

Similarly, the tag cloud for the body of the text is shown in figure 4.11. Note that words such as the and to occur frequently, and user and users are treated as separate terms. There are a total of 20 terms in the body.
Figure 4.11. The tag cloud for the body of the text

Combining the vectors for both the title and the body, we get the resulting MetaDataVector, whose tag cloud is shown in figure 4.12.
Figure 4.12. The resulting tag cloud obtained by combining the title and the body

The three terms collective, intelligence, and web2.0 stand out. But there are quite a few noise words such as all, and, is, the, and to that occur so frequently in the English language that they don’t add much value. Let’s next enhance our implementation by eliminating these terms.
4.3.3. Removing common words
Commonly occurring terms are also called stop terms (see section 2.2) and can be specific to the language and domain. We implement SimpleStopWordMetaDataExtractor to remove these stop words. The code for this is shown in listing 4.5.
Listing 4.5. Implementation of SimpleStopWordMetaDataExtractor

This class has a dictionary of terms that are to be ignored. In our case, this is a simple list; for your application this list will be a lot longer.
private static final String[] stopWords =
{"and","of","the","to","is","their","can","all", ""};
The acceptToken method is overwritten to not accept any tokens that are in the stop word list:
protected boolean acceptToken(String token) {
return !this.stopWordsMap.containsKey(token);
}
Figure 4.13 shows the tag cloud after removing the stop words. We now have 14 terms from the original 20. The terms collective, intelligence, and web2.0 stand out. But user and users are still fragmented and are treated as separate terms.
Figure 4.13. The tag cloud after removing the stop words

To combine user and users as one term, we need to stem the words.
4.3.4. Stemming
Stemming is the process of converting words to their stemmed form. There are fairly complex algorithms for doing this, Porter stemming being the most commonly used.
There’s only one plural in our example: users. For now, we enhance our implementation with SimpleStopWordStemmerMetaDataExtractor, whose code is in listing 4.6.
Listing 4.6. Implementation of SimpleStopWordStemmerMetaDataExtractor

Here, we overwrite the normalizeToken method. First, it checks to make sure that the token isn’t a stop word:
protected String normalizeToken(String token) {
if (acceptToken(token)){
token = super.normalizeToken(token);
Then it simply removes “s” from the end of terms.
Figure 4.14 shows the tag cloud obtained by stemming the terms. The algorithm transforms user and users into one term: user.
Figure 4.14. The tag cloud after normalizing the terms

We now have four terms to describe the blog entry: collective, intelligence, user, and web2.0. But collective intelligence is really one phrase, so let’s enhance our implementation to detect this term.
4.3.5. Detecting phrases
Collective intelligence is the only two-term phrase that we’re interested in. For this, we will implement SimpleBiTermStopWordStemmerMetaDataExtractor, the code for which is shown in listing 4.7.
Listing 4.7. Implement SimpleBiTermStopWordStemmerMetaDataExtractor

Here, we overwrite the getMetaDataVector method. We create a list of valid tokens and store them in a list, allTokens.
Next, the following code combines two tokens to check whether they’re valid:
String firstToken = allTokens.get(0);
for (String token: allTokens.subList(1, allTokens.size())) {
String biTerm = firstToken + " " + token;
if (isValidBiTermToken(biTerm)) {
In our case, there’s only one valid phrase, collective intelligence, and the check is done in the method.
private boolean isValidBiTermToken(String biTerm) {
if ("collective intelligence".compareTo(biTerm) == 0) {
return true;
}
return false;
}
Figure 4.15 shows the tag cloud for the title of the blog after using our new analyzer. As desired, there are four terms: collective, collective intelligence, intelligence, and web2.0.
Figure 4.15. Tag cloud for the title after using the bi-term analyzer

The combined tag cloud for the blog now contains 14 terms, as shown in figure 4.16. There are five tags that stand out: collective, collective intelligence, intelligence, user, and web2.0.
Figure 4.16. Tag cloud for the blog after using a bi-term analyzer

Using phrases in the term vector can improve finding other similar content. For example, if we had another article, “Intelligence in a Child,” with tokens intelligence and child, there’d be a match on the term intelligence. But if our analyzer was intelligent enough to simply extract collective intelligence without the terms collective and intelligence, there would be no match between the two pieces of content.
Hopefully, this gives you a good overview of how text can be analyzed automatically to extract relevant keywords or tags and build a MetaDataVector.
Now, every item in your application has an associated MetaDataVector. As users interact on your site, you can use the MetaDataVector associated with the items to develop a profile for the user. Finding similar items deals with finding items that have similar MetaDataVectors.
Intelligence in your application will manifest itself in three main forms—predictive models, search, and recommendation engines—each of which is covered in the latter half of this book.
In this section, we’ve worked with a simple example to understand how intelligence can be extracted from text. Text processing involves a number of steps, including creating tokens from the text, normalizing the text, removing common words that aren’t helpful, stemming the words to their roots, injecting synonyms, and detecting phrases. With this basic understanding of text processing, we can now tie this back to section 4.1, where we discussed the different content types. For text processing, we can classify content into two types: simple and composite.
4.4. Simple and composite content types
In your application, you may want to show related videos for an article, or related blog entries for a product. Classifying the content into content types as done in section 4.4.1 enables you to do this analysis. Basically, you should consider only desired content types as candidate items. The content types we’ve developed are mutually exclusive; an item can only belong to one content type. Therefore, we enhance the Item table introduced in section 2.3.1 to also contain the content type. There’s also another table, content_type, that contains a list of content types, as shown in figure 4.17.
Figure 4.17. Adding item_type to the item table

Based on how the term vectors for the content types are extracted, we can define content types—SimpleContentType and CompositeContentType—shown in figure 4.18.
Figure 4.18. Classifying content types
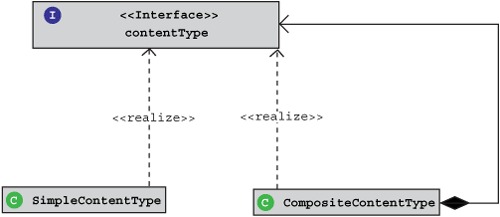
Both the simple and the composite content types are described in table 4.5.
Table 4.5. Content type categorization
|
Content Type |
Description |
Examples |
|---|---|---|
| Simple content type | Items of this content type aren’t dependent on other items. | Articles, photos, video, blogs, polls, products |
| Composite content type | Items of this content type are dependent on other items. | Questions with their associated set of answers Categorized terms with an associated set of items to describe the term Boards with associated group of messages Categories of items |
Note that for certain content types such as questions and answers, answers are fully contained within the context of the question. You typically won’t show the answer without the context of the question. The same is true for a list of items that a user may have saved together. The term vectors for CompositeContentType are obtained by combining the term vectors for each of their children items. The MetaDataVector for a CompositeContentType is obtained by combining the MetaDataVector for each of its children items.
4.5. Summary
Content is the foundation for building applications. It’s one of the main reasons why users come to your application. There are a number of different types of content, such as articles, photos, video, blogs, wikis, classification terms, polls, lists, and so forth. These can be created professionally, created by users, or aggregated from external sites. Depending on your business requirements, there are three main ways of integrating content into your application: on a separate server hosted within your firewall, embedded in your application, and linked to an external site.
Intelligence or metadata can be extracted by analyzing text. The process consists of creating tokens, normalizing the tokens, validating them, stemming them, and detecting phrases. This metadata is in addition to the collaborative approach for generating metadata for content that we looked at in chapter 3.
Blogs, wikis, and groups are some ways by which users interact, both within and outside your application. Each tool is potentially useful within your application. User-generated content in your application can boost your search engine ranking, influence users, make your application stickier, and increase the content available in your application.
Content can be classified into simple and composite content types based on how metadata is extracted.
In the last three chapters, we looked at gathering intelligence from information within your application. The next two chapters deal with collecting information from outside your application. Chapter 5 deals with searching the blogosphere for relevant content, while chapter 6 introduces how to crawl the web in search of relevant content. Both techniques can be helpful in aggregating external relevant information for your application.
4.6. Resources
“All Things Web 2.0: Message Boards.” http://www.allthingsweb2.com/component/option,com_mtree/task,search/Itemid,26/searchword,message%20boards/cat_id,0/
“Axamol Message Board.” http://www.slamb.org/projects/axamol/message-board/
“Blog Software Breakdown.” http://asymptomatic.net/blogbreakdown.htm
“Blog software comparison chart.” Online Journalism Review. http://www.ojr.org/ojr/images/blog_software_comparison.cfm
“Blogging Strategy 101: A Primer.” http://www.scoutblogging.com/blogs101.html
“Blogs Will Change Your Business.” May 2, 2005. BusinessWeek. http://www.businessweek.com/magazine/content/05_18/b3931001_mz001.htm
“Blogware choice.” http://asymptomatic.net/2004/05/28/2040/blogware-choice
“Building Online Communities, Chromatic.” O’Reilly. October 2002. http://www.oreillynet.com/pub/a/network/2002/10/21/community.html
“Choosing a Wiki”, http://c2.com/cgi/wiki?ChoosingaWiki
“Comparison of Wiki Software.” http://en.wikipedia.org/wiki/Comparison_of_wiki_software
“Corporate Blogging: Is it worth the hype?” Backbone Media, 2005. http://www.backbonemedia.com/blogsurvey/blogsurvey2005.pdf
Edelman, Richard. “A Commitment.” October 16, 2006. http://www.edelman.com/speak_up/blog/archives/2006/10/a_commitment.html#trackbacks
Fish, Shlomi. “July 2006 Update to Which Wiki.” http://www.shlomifish.org/philosophy/computers/web/which-wiki/update-2006-07/
———“Which Open Source Wiki Works For You?” November, 2004. http://www.onlamp.com/pub/a/onlamp/2004/11/04/which_wiki.html
———“Fortune 500 Business Blogging Wiki.” http://www.socialtext.net/bizblogs/index.cgi
Friedman, Tom. The World is Flat. 2005. Penguin Books.
Gardner, Susannah. “Time to check: Are you using the right blogging tool?” Online Journalism Review. July 14, 2005. http://www.ojr.org/ojr/stories/050714gardner/
Goodnoe, Ezra. “How To Use Wikis For Business.” InformationWeek, August 8, 2005. http://informationweek.com/shared/printableArticle.jhtml?articleID=167600331
Green, Heather. “Meebo and its Language Wiki.” BusinessWeek. July 11, 2006. http://www.businessweek.com/the_thread/blogspotting/archives/2006/07/meebo_and_its_m.html?chan=search
Hof, Rob. “JotSpot Intros Wiki 2.0.” BusinessWeek. July 24, 2006. http://www.businessweek.com/the_thread/techbeat/archives/2006/07/jotspot_intros.html?chan=search
Holohan, Catherine. “Six Apart’s Booming Blogosphere.” September 25, 2006. BusinessWeek. http://www.businessweek.com/technology/content/sep2006/tc20060925_607937.htm?chan=search
Horrigan, John, and Lee Rainie. “The Internet’s Growing Role in Life’s Major Moments.” http://www.pewinternet.org/pdfs/PIP_Major%20Moments_2006.pdf
“Internet Message Boards.” http://www.topology.org/net/mb.html
Kirkby, Jennifer. “Welcome to the Blogosphere.” The Customer Management Community. http://www.insightexec.com/newswire_archive/20060322_monthly.html
Lee, Felicia. “Survey of the Blogosphere Finds 12 Million Voices.” New York Times. July 20, 2006. http://select.nytimes.com/search/restricted/article?res=FA0613F63D5B0C738EDDAE0894DE404482
Li, Charlene. “Blogging policy examples.” November 8, 2004. http://forrester.typepad.com/charleneli/2004/11/blogging_policy.html
Lenhrt, Amanda, and Susannah Fox. “Bloggers: A portrait of the internet’s new storytellers.” July 19, 2006. Pew Internet & American Life Project. http://www.pewinternet.org/PPF/r/186/report_display.asp
Leuf, Bo, and Ward Cunningham. “The Wiki Way: Collaboration and Sharing on the Internet.” 2001. Addison Wessley.
“Message Boards.” http://dmoz.org/Computers/Internet/On_the_Web/Message_Boards/
“Online Community Toolkit.” http://www.fullcirc.com/community/communitymanual.htm
Open Directory, Message Boards. http://dmoz.org/Computers/Internet/On_the_Web/Message_Boards/
“Open Source Bloggers in Java.” http://java-source.net/open-source/bloggers
Pilgrim, Mark. “What is RSS?” XML.com. 2002. http://www.xml.com/pub/a/2002/12/18/dive-into-xml.html
Quick, William. “Blogosphere.” http://www.iw3p.com/DailyPundit/2001_12_30_dailypundit_archive.php#8315120
“Reports Family, Friends, and Community.” http://www.pewinternet.org/report_display.asp?r=47
“Roller open source blog server.” http://rollerweblogger.org/
Scoble, Robert, and Shell Israel. “Naked Conversations: How Blogs Are Changing the Way Businesses Talk with Customers.” Wiley. 2006.
Sifry, Dave. “State of the Blogosphere, August 2005, Part 1: Blog Growth.” August 2, 2005. http://www.technorati.com/weblog/2005/08/34.html
Singer, Suzette Cavanaugh. “NeoMarketing.” June, 2006. Class notes, UC SC Extension.
“State of the Blogosphere, April 2006, Part 1: Blog Growth.” August 2, 2006. http://technorati.com/weblog/2006/04/96.html
“State of the Blogosphere, August 2005, Part 2: Posting Volume.” August 2, 2005. http://technorati.com/weblog/2005/08/35.html
“The Best of Web2.0 Wiki.” http://www.allthingsweb2.com/component/option,com_mtree/task,listcats/cat_id,120/Itemid,26/
“Top ten Wiki Engines.” http://c2.com/cgi-bin/wiki?TopTenWikiEngines
“Twiki.” http://www.twiki.org/
Udell, John. “Year of the enterprise Wiki.” InfoWorld. December 2004. http://www.infoworld.com/article/04/12/30/01FEtoycollab_1.html
“Virtual Community, Wikipedia.” http://en.wikipedia.org/wiki/Virtual_community
“What is Wiki?” Wiki.org. http://wiki.org/wiki.cgi?WhatIsWiki
“Wiki Engines.” http://c2.com/cgi/wiki?WikiEngines
Wolley, David. “Forum Software for the Web: An independent guide to discussion forum & message board software.” http://thinkofit.com/webconf/forumsoft.htm
“10 Tips for Becoming a Great Corporate Blogger.” Backbone Media. http://www.scoutblogging.com/tips.html