
Chapter 8. Building a text analysis toolkit
It’s now common for most applications to leverage user-generated-content (UGC). Users may generate content through one of many ways: writing blog entries, sending messages to others, answering or posing questions on message boards, through journal entries, or by creating a list of related items. In chapter 3, we looked at the use of tagging to represent metadata associated with content. We mentioned that tags can also be detected by automated algorithm.
In this chapter, we build a toolkit to analyze content. This toolkit will enable us to extract tags and their associated weights to build a term-vector representation for the text. The term vector representation can be used to
- Build metadata about the user as described in chapter 2
- Create tag clouds as shown in chapter 3
- Mine the data to create clusters of similar documents as shown in chapter 9
- Build predictive models as shown in chapter 10
- Form a basis for understanding search as used in chapter 11
- Form a basis for developing a content-based recommendation engine as shown in chapter 12
As a precursor to this chapter, you may want to review sections 2.2.3, 3.1–3.2, and 4.3. The emphasis of this chapter is in implementation, and at the end of the chapter we’ll have the tools to analyze text as described in section 4.3. We leverage Apache Lucene to use its text-parsing infrastructure. Lucene is a Java-based open source search engine developed by Doug Cutting. Nutch, which we looked at in chapter 6, is also based on Lucene. We begin with building a text-parsing infrastructure that supports the use of stop words, synonyms, and a phrase dictionary. Next, we implement the term vector with capabilities to add and compute similarities with other term vectors. We insulate our infrastructure from using any of Lucene’s specific classes in its interfaces, so that in the future if you want to use a different text-parsing infrastructure, you won’t have to change your core classes. This chapter is a good precursor to chapter 11, which is on intelligent search.
8.1. Building the text analyzers
This section deals with analyzing content—taking a piece of text and converting it into tags. Tags may contain a single term or multiple terms, known as phrases. In this section, we build the Java code to intelligently process text as illustrated in section 4.3. This framework is the foundation for dealing with unstructured text and converting it into a format that can be used by various algorithms, as we’ll see in the remaining chapters of this book. At the end of this section, we develop the tools required to convert text into a list of tags.
In section 2.2.3, we looked at the typical steps involved in text analysis, which are shown in figure 8.1:
1. Tokenize—Parsing the text to generate terms. Sophisticated analyzers can also extract phrases from the text.
2. Normalize—Converting text to lowercase.
3. Eliminate stop words—Eliminating terms that appear very often.
4. Stem—Converting the terms into their stemmed form; removing plurals.
Figure 8.1. Typical steps involved in analyzing text
![]()
At this point, it’s useful to look at the example in section 4.3, where we went through the various steps involved with analyzing text. We used a simple blog entry consisting of a title and a body to demonstrate analyzing text. We use the same example in this chapter.
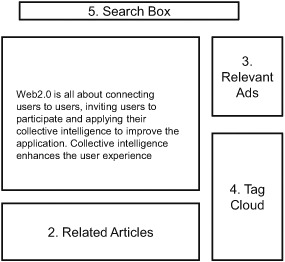
Figure 8.2, which shows a typical web page with a blog entry in the center of the page, demonstrates the applicability of the framework developed in this chapter. The figure consists of five main sections:
- Main context— The blog entry with the title and body is at the center of the page.
- Related articles— This section contains other related articles that are relevant to the user and to the blog entry in the first section. We develop this in chapter 12.
- Relevant ads— This section shows advertisements that are relevant to the user and to the context in the first section. Tags extracted from the main context and the user’s past behavior are used to show relevant advertisements.
- Tag cloud visualization— This section shows a tag cloud representation of the tags of interest to the user. This tag cloud (see chapter 3) can be generated by analyzing the pages visited by the user in the past.
- Search box— Most applications have a search box that allows users to search for content using keywords. The main content of the page—the blog entry—is indexed for retrieval via a search engine, as shown in chapter 11.
Figure 8.2. Example of how the tools developed in this chapter can be leveraged in your application
First, we need some classes that can parse text. We use Apache Lucene.
8.1.1. Leveraging Lucene
Apache Lucene[1] is an open source Java-based full-text search engine. In this chapter, we use the analyzers that are available with Lucene. For more on Lucene, Manning has an excellent book, Lucene in Action, by Gospodnetic and Hatcher. You’ll find the material in chapter 4 of the book to be particularly helpful for this section.
Lucene can be freely downloaded at http://www.apache.org/dyn/closer.cgi/lucene/java/. Download the appropriate file based on your operating system. For example, I downloaded lucene-2.2.0-src.zip, which contains the Lucene 2.2.0 source, and lucene-2.2.0.zip, which contains the compiled classes. Unzip this file and make sure that lucene-core-2.2.0.jar is in your Java classpath. We use this for our analysis.
The first part of the text analysis process is tokenization—converting text into tokens. For this we need to look at Lucene classes in the package org.apache.lucene.analysis.
Key Lucene Text-Parsing Classes
In this section, we look at the key classes that are used by Lucene to parse text. Figure 8.3 shows the key classes in the analysis package of Lucene. Remember, our aim is to convert text into a series of terms. We also briefly review the five classes that are shown in figure 8.3. Later, we use these classes to write our own text analyzers.
Figure 8.3. Key classes in the Lucene analysis package

An Analyzer is an abstract class that takes in a java.io.Reader and creates a Token-Stream. For doing this, an Analyzer has the following method:
public abstract TokenStream tokenStream(String fieldName, Reader reader);
The abstract class TokenStream creates an enumeration of Token objects. Each Tokenizer implements the method:
public Token next() throws IOException;
A Token represents a term occurring in the text.
There are two abstract subclasses for TokenStream. First is Tokenizer, which deals with processing text at the character level. The input to a Tokenizer is a java.io.Reader. The abstract Tokenizer class has two protected constructors. The first is a no-argument constructor; the second takes a Reader object. All subclasses of a Tokenizer have a public constructor that invokes the protected constructor for the parent Tokenizer class, passing in a Reader object:
protected abstract Tokenizer(Reader input)
The second subclass of TokenStream is TokenFilter. A TokenFilter deals with words, and its input is another TokenStream, which could be another TokenFilter or a Tokenizer. There’s only one constructor in a TokenFilter, which is protected and has to be invoked by the subclasses:
protected TokenFilter(TokenStream input)
The composition link from a TokenFilter (see the black diamond in figure 8.3) to a TokenStream in figure 8.3 indicates that token filters can be chained. A TokenFilter follows the composite design pattern and forms a “has a” relationship with another TokenStream.
Table 8.1 summarizes the five classes that we have discussed so far.
Table 8.1. Common terms used to describe attributes
Next, we need to look at some of the concrete implementations of these classes.
Lucene Tokenizers, Filters, and Analyzers
In this section, we look at the available implementations for tokenizers, token filters and analyzers from Lucene. We’ll leverage these when we develop our own analyzers.
First let’s look at the concrete implementations of Tokenizer provided by Lucene. As shown in figure 8.3, we’re currently interested in five of the available tokenizers. These are shown in table 8.2, which should give you a good flavor of available tokenizers. Of course, it’s simple enough to extend any of these Tokenizers. Either a StandardTokenizer or a LowercaseTokenizer should work well for most applications.
Table 8.2. Available tokenizers from Lucene
|
Tokenizer |
Details |
|---|---|
| StandardTokenizer | Tokenizer for most European languages. Removes punctuation and splits words at punctuation. But if a dot isn’t followed by white space, it’s considered part of the token. Splits words at hyphens unless there’s a number, in which case the whole token isn’t split. Recognizes Internet host names and email addresses. |
| CharTokenizer | An abstract base class for character-oriented simple Tokenizers. |
| WhitespaceTokenizer | Divides text at white spaces. |
| LetterTokenizer | Divides text at non-letters. Works well for European languages but not for Asian languages, where words aren’t separated by spaces. |
| LowerCaseTokenizer | Converts text into lowercase and divides text into non-words. |
| RussianLetterTokenizer | Extends LetterTokenizer by additionally looking up letters in a given “Russian charset.” |
Next, let’s look at the available set of TokenFilters, which is shown in figure 8.4. Table 8.3 contains details about a few of them.
Figure 8.4. Some of the concrete implementations for Tokenizer and TokenFilter
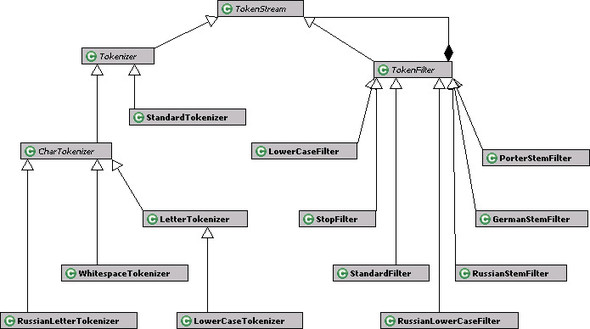
Table 8.3. Available filters from Lucene
|
TokenFilter |
Details |
|---|---|
| StandardFilter | Normalizes tokens by removing s, S, and periods. Works in conjunction with a StandardTokenizer. |
| LowerCaseFilter | Normalizes the token text to lowercase. |
| StopFilter | Removes words that appear in the provided stop word list from the token stream. |
| PorterStemFilter | Stems the token using the Porter stemming algorithm. Tokens are expected to be lowercase. |
| RussianLowerCaseFilter | Converts text into lowercase using a Russian charset. |
| RussianStemFilter | Stems Russian words, which are expected to be lowercase. |
| GermanStemFilter | A stem filter for German words. |
Of particular importance to us is the StopFilter, which we use for adding stop words, and the PorterStemFilter, which we use to stem words. Note that there are language-specific filters, for example, the RussianLowerCaseFilter and Russian-StemFilter for the Russian language, and the GermanStemFilter for German words.
Lastly, let’s look at some of the analyzers that are available from Lucene. Figure 8.5 shows some of the Analyzer classes available to us.
Figure 8.5. The Analyzer class with some of its concrete implementations

Table 8.4 contains the details about each of the available analyzers.
Table 8.4. Common Analyzer classes that are available in Lucene
|
Analyzer |
Details |
|---|---|
| SimpleAnalyzer | Uses the LowerCaseTokenizer |
| StopAnalyzer | Combines a LowerCaseTokenizer with a StopFilter |
| WhitespaceAnalyzer | Uses the WhitespaceTokenizer |
| PerFieldAnalyzerWrapper | Useful for when different fields need different Analyzers |
| StandardAnalyzer | Uses a list of English stop words and combines StandardTokenizer, StandardFilter, LowerCaseFilter, and StopFilter |
| GermanAnalyzer | Analyzer for German language |
| RussianAnalyzer | Analyzer for Russian language |
At this stage, we’re done with Lucene classes. We build on what we’ve learned so far in this chapter by leveraging the available Lucene analyzers and token filters to write two custom Analyzers:
- PorterStemStopWordAnalyzer: A custom analyzer that normalizes tokens; it uses stop words and Porter stemming.
- SynonymPhraseStopWordAnalyzer: An analyzer that injects synonyms and detects phrases. It uses a custom TokenFilter that we’ll build: the Synonym-PhraseStopWordFilter.
Figure 8.6 shows the class diagram for the two analyzers and token filter that we build next.
Figure 8.6. The Analyzer class with some of its concrete implementations

We next look at implementing the PorterStemStopWordAnalyzer.
8.1.2. Writing a stemmer analyzer
It’s helpful to have an analyzer that can take care of plurals by stemming words. We also want to add the capability to first normalize the tokens into lowercase and use a custom stop word list. PorterStemStopWordAnalyzer is such an analyzer; the code is shown in listing 8.1.
Listing 8.1. Implementation of the PorterStemStopWordAnalyzer

To keep things simple, we provide the analyzer with an internal stop word list. This list is customized according to the text analysis example we worked through in section 4.3. There are quite a few stop word lists that are available if you search the Web. For example, you can use Google’s stop word list[2] or a more detailed list.[3] You may want to customize your stop word list based on your application and the domain to which it’s applied.
3http://www.onjava.com/onjava/2003/01/15/examples/EnglishStopWords.txt
Our analyzer extends the Analyzer class from Lucene, and we need to implement one method:
public TokenStream tokenStream(String fieldName, Reader reader)
In this method, we first create a Tokenizer using the StandardTokenizer, which removes all punctuation and splits the text at punctuation.
Tokenizer tokenizer = new StandardTokenizer(reader);
Let’s write a simple test to see the effect of PorterStemStopWordAnalyzer on the text “Collective Intelligence and Web2.0.” Listing 8.2 shows the code for the test method.
Listing 8.2. Test method to see the effect of PorterStemStopWordAnalyzer
public void testPorterStemmingAnalyzer() throws IOException {
Analyzer analyzer = new PorterStemStopWordAnalyzer();
String text = "Collective Intelligence and Web2.0";
Reader reader = new StringReader(text);
TokenStream ts = analyzer.tokenStream(null, reader);
Token token = ts.next();
while (token != null) {
System.out.println(token.termText());
token = ts.next();
}
}
The output from the test program is three tokens:
collect intellig web2.0
Note that collective is stemmed to collect, while intelligence is stemmed to intellig. Also, web2.0 is a tag; the analyzer didn’t split the term web2.0.
Next, we chain three TokenFilter instances, starting with the LowerCaseFilter, followed by the StopFilter, and lastly the PorterStemFilter. We put this analyzer into practice later in section 8.2, when we look at building our text analysis infrastructure.
8.1.3. Writing a TokenFilter to inject synonyms and detect phrases
In section 4.3.5, we discussed the need for detecting multiple-term tokens when analyzing text. Multiple-term tags are more specific than single-term tags and typically have a higher inverse document frequency value. If you use human-generated tags, either through professionals or users, it’s necessary to detect multiple-term tags that may have been entered. These human-generated tags in essence form the universe of phrases that you’d be interested in detecting. Similarly, synonyms help in matching tags that have the same meaning. For example, CI is a commonly used synonym for collective intelligence.
In this section, we build a custom TokenFilter that does two things:
- It looks at two adjoining non–stop word terms to see if they form a phrase we’re interested in. If the bi-term is a valid phrase then it’s injected into the token stream.
- It looks at a synonym dictionary to see if any of the terms or phrases in the token stream have synonyms, in which case the synonyms are injected into the token stream.
To illustrate the process of how phrases can be detected, we use a fairly simple strategy—considering two adjoining non–stop word terms. You can enhance the phrase detection strategy by using more than two terms or using a longer window of terms to find phrases. A window size of two means considering the two terms adjoining to the term of interest. You’ll have to balance the benefits of performing complicated logic against the additional computation time required to analyze the text. You can also use a variable size window, especially if there is a set of phrases you’re trying to detect from the text.
Before we can write our custom token filter, we need to get access to phrases and synonyms. For this, we define two additional entities:
- PhrasesCache: to determine whether a phrase is of interest to us
- SynonymsCache: a cache of synonyms
Listing 8.3 shows the implementation for the interface PhrasesCache, which has only one method: isValidPhrase.
Listing 8.3. Interface to validate phrases
package com.alag.ci.textanalysis;
import java.io.IOException;
public interface PhrasesCache {
public boolean isValidPhrase(String text) throws IOException;
}
Listing 8.4 shows the implementation for SynonymsCache. It has only one method, getSynonym, which returns the list of synonyms for a given text.
Listing 8.4. Interface to access synonyms
package com.alag.ci.textanalysis;
import java.io.IOException;
import java.util.List;
public interface SynonymsCache {
public List<String> getSynonym(String text) throws IOException;
}
With this background, we’re now ready to write our custom token filter. Listing 8.5 shows the first part of the implementation of the SynonymPhraseStopWordFilter. This part deals with the attributes, the constructor, and the implementation of the next() method.
Listing 8.5. The next() method for SynonymPhraseStopWordFilter

The SynonymPhraseStopWordFilter extends the TokenFilter class. Its constructor takes in another TokenStream object, a SynonymsCache, and a PhraseCache. It internally uses a Stack to keep track of injected tokens. It needs to implement one method:
public Token next() throws IOException {
The attribute previousToken keeps track of the previous token. Phrases and synonyms are injected by the following code:
Token token = input.next();
if (token != null) {
String phrase = injectPhrases( token);
injectSynonyms(token.termText(), token);
injectSynonyms(phrase, token);
this.previousToken = token;
}
Note that the code
injectSynonyms(phrase, token);
checks for synonyms for the injected phrases also. Listing 8.6 contains the remainder of the class. It has the implementation for the methods injectPhrases and injectSynonyms.
Listing 8.6. Injecting phrases and synonyms

For injecting phrases, we first concatenate the text from the previous token, a space, and the current token text:
String phrase = this.previousToken.termText() + " " + currentToken.termText();
We check to see if this is a phrase of interest. If it is, a new Token object is created with this text and injected onto the stack.
To inject synonyms, we get a list of synonyms for the text and inject each synonym into the stack. Next, we leverage this TokenFilter to write an analyzer that uses it. This analyzer normalizes the tokens, removes stop words, detects phrases, and injects synonyms. We build this next.
8.1.4. Writing an analyzer to inject synonyms and detect phrases
In this section we write an analyzer that uses the token filter we developed in the previous section. This analyzer normalizes tokens, removes stop words, detects phrases, and injects synonyms. We use it as part of our text analysis infrastructure.
Listing 8.7 shows the implementation for the SynonymPhraseStopWordAnalyzer.
Listing 8.7. Implementation of the SynonymPhraseStopWordAnalyzer

SynonymPhraseStopWordAnalyzer extends the Analyzer class. Its constructor takes an instance of the SynonymsCache and the PhrasesCache. The only method that we need to implement is
public TokenStream tokenStream(String fieldName, Reader reader) {
For this method, we first normalize the tokens, remove stop words, and then invoke our custom filter, SynonymPhraseStopWordFilter.
Next, we apply our analyzer to the sample text: “Collective Intelligence and Web2.0.”
8.1.5. Putting our analyzers to work
Our custom analyzer, SynonymPhraseStopWordAnalyzer, needs access to an instance of a PhrasesCache and SynonymsCache. As shown in figure 8.7, we implement PhrasesCacheImpl and SynonymsCacheImpl. The common implementations for both classes will be in their base class, CacheImpl.
Figure 8.7. The implementations for the PhrasesCache and SynonymsCache

Listing 8.8 shows the implementation for the CacheImpl class. We want the lookup for phrases and synonyms to be independent of plurals; that’s why we compare text using stemmed values.
Listing 8.8. Implementation of the CacheImpl class

There’s only one method in this class:
String getStemmedText(String text) throws IOException
We use our custom analyzer PorterStemStopWordAnalyzer to get the stemmed value for a text. This method iterates over all the terms in the text to get their stemmed text and converts phrases with a set of quotes (“ ”) between the terms.
To keep things simple, we implement a class, SynonymsCacheImpl, which has only one synonym—collective intelligence has the synonym ci. For your application, you’ll probably maintain a list of synonyms either in the database or in an XML file. Listing 8.9 shows the implementation for SynonymsCacheImpl.
Listing 8.9. Implementation of SynonymsCacheImpl

Note that to look up synonyms, the class compares stemmed values, so that plurals are automatically taken care of. Similarly, in our PhrasesCacheImpl, we have only one phrase, collective intelligence. Listing 8.10 shows the implementation for the PhrasesCacheImpl class.
Listing 8.10. Implementation of the PhrasesCacheImpl

Again phrases are compared using their stemmed values. Now we’re ready to write a test method to see the output for our test case, “Collective Intelligence and Web2.0.” The code for analyzing this text using SynonymPhraseStopWordAnalyzer is shown in listing 8.11.
Listing 8.11. Test program using SynonymPhraseStopWordAnalyzer
public void testSynonymsPhrases() throws IOException {
SynonymsCache synonymsCache = new SynonymsCacheImpl();
PhrasesCache phrasesCache = new PhrasesCacheImpl();
Analyzer analyzer = new SynonymPhraseStopWordAnalyzer(
synonymsCache,phrasesCache);
String text = "Collective Intelligence and Web2.0";
Reader reader = new StringReader(text);
TokenStream ts = analyzer.tokenStream(null, reader);
Token token = ts.next();
while (token != null) {
System.out.println(token.termText());
token = ts.next();
}
}
The output from this program is
collective intelligence ci collective intelligence web2.0
As expected, there are five tokens. Note the token ci, which gets injected, as it’s a synonym for the phrase collective intelligence, which is also detected.
So far, we’ve looked at the available analyzers from Lucene and built a couple of custom analyzers to process text. Text comparisons are done using stemmed values, which take care of plurals.
Next, let’s look at how all this hard work we’ve done so far can be leveraged to build the term vector representation that we discussed in section 2.2.4 and a text analysis infrastructure that abstracts out terminology used by Lucene. That way, if tomorrow you need to use a different text-processing package, the abstractions we create will make it simple to change implementations.
8.2. Building the text analysis infrastructure
The core classes for our text analysis infrastructure will be independent of Lucene classes. This section is split into three parts:
- Infrastructure related to tags
- Infrastructure related to term vectors
- Putting it all together to build our text analyzer class
Figure 8.8 shows the classes that will be developed for this package. We define a class, Tag, to represent tags in our system. Tags can contain single terms or multiple-term phrases. We use the flyweight design pattern, where Tag instances are immutable and cached by TagCache. The TagMagnitude class consists of a magnitude associated with a Tag instance. The term vector is represented by the TagMagnitudeVector class and consists of a number of TagMagnitude instances. In the previous section, we already looked at the SynonymsCache and the PhrasesCache classes that are used to access synonyms and phrases. The TextAnalyzer class is the main class for processing text. The InverseDocFreqEstimator is used for getting the inverse document frequency associated with a Tag. The TextAnalyzer uses the TagCache, SynonymsCache, PhrasesCache, and InverseDocFreqEstimator to create a TagMagnitudeVector for the text.
Figure 8.8. The infrastructure for text analysis

Next, let’s look at developing the infrastructure related to tags.
8.2.1. Building the tag infrastructure
The four classes associated with implementing the tag infrastructure are shown in figure 8.9. These classes are Tag and its implementation TagImpl, along with TagCache and its implementation TagCacheImpl.
Figure 8.9. Tag infrastructure–related classes
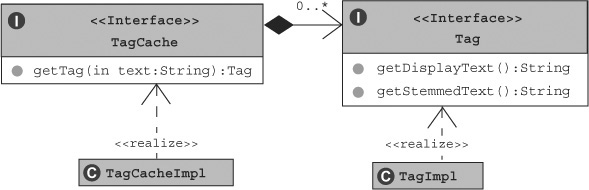
A Tag is the smallest entity in our framework. As shown in listing 8.12, a Tag has display text and its stemmed value. Remember we want to compare tags based on their stemmed values.
Listing 8.12. The Tag interface
package com.alag.ci.textanalysis;
public interface Tag {
public String getDisplayText();
public String getStemmedText();
}
Listing 8.13 shows the implementation for TagImpl, which implements the Tag interface. This is implemented as an immutable object, where its display text and stemmed values are specified in the constructor.
Listing 8.13. The TagImpl implementation

Note that two tags with the same stemmed text are considered equivalent. Depending on your domain, you could further enhance the tag-matching logic. For example, to compare multi-term phrases, you may want to consider tags with the same terms equivalent, independent of their position. Remember, from a performance point of view, you want to keep the matching logic as efficient as possible. Tag instances are relatively heavyweight and text processing is expensive. Therefore, we use the flyweight pattern and hold on to the Tag instances. The TagCache class is used for this purpose.
We access an instance of Tag through the TagCache. The TagCache interface has only one method, getTag, as shown in listing 8.14.
Listing 8.14. The TagCache interface
package com.alag.ci.textanalysis;
import java.io.IOException;
public interface TagCache {
public Tag getTag(String text) throws IOException ;
}
TagCache is implemented by TagCacheImpl, which is shown in listing 8.15. The implementation is straightforward. A Map is used to store the mapping between stemmed text and a Tag instance.
Listing 8.15. The implementation for TagCacheImpl

Note that lookups from the cache are done using stemmed text:
getStemmedText(text);
With this background, we’re now ready to develop the implementation for the term vectors.
8.2.2. Building the term vector infrastructure
Figure 8.10 shows the classes associated with extending the tag infrastructure to represent the term vector. The TagMagnitude interface associates a magnitude with the Tag, while the TagMagnitudeVector, which is a composition of TagMagnitude instances, represents the term vector.[4]
4Term vector and tag vector are used interchangeably here, though there’s a difference between terms and tags. Tags may be single terms or may contain phrases, which are multiple terms.
Figure 8.10. Term vector–related infrastructure
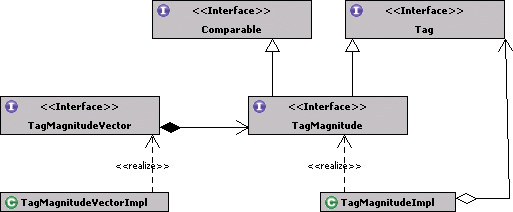
Tagmagnitude-Related Interfaces
Listing 8.16 shows the definition for the TagMagnitude interface. It extends the Tag and Comparable<TagMagnitude> interfaces. Implementing the Comparable interface is helpful for sorting the TagMagnitude instances by their weights.
Listing 8.16. The TagMagnitude interface
package com.alag.ci.textanalysis;
public interface TagMagnitude extends Tag, Comparable<TagMagnitude> {
public double getMagnitude();
public double getMagnitudeSqd();
public Tag getTag();
}
There are only three methods associated with the TagMagnitude interface: one to get the magnitude, a utility method to get the square of the magnitudes, and one to get the associated Tag object.
The TagMagnitudeImpl class implements the TagMagnitude interface and is shown in listing 8.17.
Listing 8.17. The implementation for TagMagnitudeImpl

Note that the TagMagnitudeImpl class is implemented as an immutable class. It has a magnitude attribute that’s implemented as a double. The TagMagnitudeImpl class has access to a Tag instance and delegates to this object any methods related to the Tag interface.
Tagmagnitudevector-Related Interfaces
Next, we’re ready to define the TagMagnitudeVector interface, which represents a term vector. Listing 8.18 contains the methods associated with this interface.
Listing 8.18. The TagMagnitudeVector interface

The TagMagnitudeVector has four methods. The first two, getTagMagnitudes() and getTagMagnitudeMap(), are to access the TagMagnitude instance. The third method, add(), is useful for adding two term vectors, while the last method, dotProduct(), is useful for computing the similarity between two term vectors.
Lastly, let’s look at the implementation for TagMagnitudeVectorImpl, which implements the TagMagnitudeVector interface. The first part of this implementation is shown in listing 8.19. We use a Map to hold the instances associated with the term vector. Typically, text contains a small subset of tags available. For example, in an application, there may be more than 100,000 different tags, but a document may contain only 25 unique tags.
Listing 8.19. The basic TagMagnitudeVectorImpl class

The TagMagnitudeVectorImpl class is implemented as an immutable object. It normalizes the input list of TagMagnitude objects such that the magnitude for this vector is 1.0. For the method getTagMagnitudes, the TagMagnitude instances are sorted by magnitude. Listing 8.20 contains the implementation for two methods. First is the dotProduct, which computes the similarity between the tag vector and another TagMagnitudeVector. The second method, add(), is useful for adding the current vector to another vector.
Listing 8.20. Computing the dot product in TagMagnitudeVectorImpl

To compute the dotProduct between a vector and another vector, the code finds the tags that are common between the two instances. It then sums the multiplied magnitudes between the two instances. For the add() method, we first need to find the superset for all the tags. Then the magnitude for the new vector for a tag is the sum of the magnitudes in the two vectors. At the end, the code creates a new instance
new TagMagnitudeVectorImpl(tagMagnitudesList);
which will automatically normalize the values in its constructor, such that the magnitude is one.
To compute the resulting TagMagnitudeVector by adding a number of TagMagnitudeVector instances
public TagMagnitudeVector add(Collection<TagMagnitudeVector> tmList)
we sum the squared magnitudes for a tag in all the TagMagnitudeVector instances. A new TagMagnitudeVector instance is created that has a superset of all the tags and normalized magnitudes. We use this method in clustering.
Next, let’s write a simple program to show how this term vector infrastructure can be used. The output from the code sample shown in listing 8.21 is
[b, b, 0.6963106238227914][c, c, 0.5222329678670935][a, a, 0.49236596391733095]
Note that there are three tags, and the two instances of the a tag are automatically merged. The sum of the squares for all the magnitudes is also equal to one.
Listing 8.21. A simple example for TagMagnitudeImpl
public void testBasicOperations() throws Exception {
TagCache tagCache = new TagCacheImpl();
List<TagMagnitude> tmList = new ArrayList<TagMagnitude>();
tmList.add(new TagMagnitudeImpl(tagCache.getTag("a"),1.));
tmList.add(new TagMagnitudeImpl(tagCache.getTag("b"),2.));
tmList.add(new TagMagnitudeImpl(tagCache.getTag("c"),1.5));
tmList.add(new TagMagnitudeImpl(tagCache.getTag("a"),1.));
TagMagnitudeVector tmVector1 = new TagMagnitudeVectorImpl(tmList);
System.out.println(tmVector1);
}
So far we’ve developed the infrastructure to represent a Tag and TagMagnitudeVector. We’re down to the last couple classes. Next, we look at developing the TextAnalyzer.
8.2.3. Building the Text Analyzer class
In this section, we implement the remaining classes for our text analysis infrastructure. Figure 8.11 shows the four classes that we discuss. The InverseDocFreqEstimator provides an estimate for the inverse document frequency (idf) for a Tag. Remember, the idf is necessary to get an estimate of how frequently a tag is used; the less frequently a tag is used, the higher its idf value. The idf value contributes to the magnitude of the tag in the term vector. In the absence of any data on how frequently various tags appear, we implement the EqualInverseDocFreqEstimator, which simply returns 1 for all values. The TextAnalyzer class is our primary class for analyzing text. We write a concrete implementation for this class called LuceneTextAnalyzer that leverages all the infrastructure and analyzers we’ve developed in this chapter.
Figure 8.11. The TextAnalyzer and the InverseDocFreqEstimator

Listing 8.22 shows the InverseDocFreqEstimator interface. It has only one method, which provides the inverse document frequency for a specified Tag instance.
Listing 8.22. The interface for the InverseDocFreqEstimator
package com.alag.ci.textanalysis;
public interface InverseDocFreqEstimator {
public double estimateInverseDocFreq(Tag tag);
}
Listing 8.23 contains a dummy implementation for InverseDocFreqEstimator. Here, EqualInverseDocFreqEstimator simply returns 1.0 for all tags.
Listing 8.23. The interface for the EqualInverseDocFreqEstimator
package com.alag.ci.textanalysis.lucene.impl;
import com.alag.ci.textanalysis.InverseDocFreqEstimator;
import com.alag.ci.textanalysis.Tag;
public class EqualInverseDocFreqEstimator implements
InverseDocFreqEstimator {
public double estimateInverseDocFreq(Tag tag) {
return 1.0;
}
}
Listing 8.24 contains the interface for TextAnalyzer, the primary class to analyze text.
Listing 8.24. The interface for the TextAnalyzer
package com.alag.ci.textanalysis;
import java.io.IOException;
import java.util.List;
public interface TextAnalyzer {
public List<Tag> analyzeText(String text) throws IOException;
public TagMagnitudeVector createTagMagnitudeVector(String text)
throws IOException;
}
The TextAnalyzer interface has two methods. The first, analyzeText, gives back the list of Tag objects obtained by analyzing the text. The second, createTagMagnitude-Vector, returns a TagMagnitudeVector representation for the text. It takes into account the term frequency and the inverse document frequency for each of the tags to compute the term vector.
Listing 8.25 shows the first part of the code for the implementation of LuceneText-Analyzer, which shows the constructor and the analyzeText method.
Listing 8.25. The core of the LuceneTextAnalyzer class
package com.alag.ci.textanalysis.lucene.impl;
import java.io.*;
import java.util.*;
import org.apache.lucene.analysis.*;
import com.alag.ci.textanalysis.*;
import com.alag.ci.textanalysis.termvector.impl.*;
public class LuceneTextAnalyzer implements TextAnalyzer {
private TagCache tagCache = null;
private InverseDocFreqEstimator inverseDocFreqEstimator = null;
public LuceneTextAnalyzer(TagCache tagCache,
InverseDocFreqEstimator inverseDocFreqEstimator) {
this.tagCache = tagCache;
this.inverseDocFreqEstimator = inverseDocFreqEstimator;
}
public List<Tag> analyzeText(String text) throws IOException {
Reader reader = new StringReader(text);
Analyzer analyzer = getAnalyzer();
List<Tag> tags = new ArrayList<Tag>();
TokenStream tokenStream = analyzer.tokenStream(null, reader) ;
Token token = tokenStream.next();
while ( token != null) {
tags.add(getTag(token.termText()));
token = tokenStream.next();
}
return tags;
}
protected Analyzer getAnalyzer() throws IOException {
return new SynonymPhraseStopWordAnalyzer(new SynonymsCacheImpl(),
new PhrasesCacheImpl());
}
The method analyzeText gets an Analyzer. In this case, we use SynonymPhraseStopWordAnalyzer. LuceneTextAnalyzer is really a wrapper class that wraps Lucene-specific classes into those of our infrastructure. Creating the TagMagnitudeVector from text involves computing the term frequencies for each tag and using the tag’s inverse document frequency to create appropriate weights. This is shown in listing 8.26.
Listing 8.26. Creating the term vectors in LuceneTextAnalyzer

To create the TagMagnitudeVector, we first analyze the text to create a list of tags:
List<Tag> tagList = analyzeText(text);
Next we compute the term frequencies for each of the tags:
Map<Tag,Integer> tagFreqMap = computeTermFrequency(tagList);
And last, create the vector by combining the term frequency and the inverse document frequency:
return applyIDF(tagFreqMap);
We’re done with all the classes we need to analyze text. Next, let’s go through an example of how this infrastructure can be used.
8.2.4. Applying the text analysis infrastructure
We use the same example we introduced in section 4.3.1. Consider a blog entry with the following text (see also figure 8.2):
Title: “Collective Intelligence and Web2.0”
Body: “Web2.0 is all about connecting users to users, inviting users to participate, and applying their collective intelligence to improve the application. Collective intelligence enhances the user experience.”
Let’s write a simple program that shows the tags associated with analyzing the title and the body. Listing 8.27 shows the code for our simple program.
Listing 8.27. Computing the tokens for the title and body

First we create an instance of the TextAnalyzer class:
TagCacheImpl t = new TagCacheImpl();
InverseDocFreqEstimator idfEstimator =
new EqualInverseDocFreqEstimator();
TextAnalyzer lta = new LuceneTextAnalyzer(t, idfEstimator);
Then we get the tags associated with the title and the body. Listing 8.28 shows the output. Note that the output for each tag consists of unstemmed text and its stemmed value.
Listing 8.28. Tag listing for our example
Analyzing the title .... [collective, collect] [intelligence, intellig] [ci, ci] [collective intelligence, collect intellig] [web2.0, web2.0] Analyzing the body .... [web2.0, web2.0] [about, about] [connecting, connect] [users, user] [users, user] [inviting, invit] [users, user] [participate, particip] [applying, appli] [collective, collect] [intelligence, intellig] [ci, ci] [collective intelligence, collect intellig] [improve, improv] [application, applic] [collective, collect] [intelligence, intellig] [ci, ci] [collective intelligence, collect intellig] [enhances, enhanc] [users, user] [experience, experi]
It’s helpful to visualize the tag cloud using the infrastructure we developed in chapter 3. Listing 8.29 shows the code for visualizing the tag cloud.
Listing 8.29. Visualizing the term vector as a tag cloud

The code for generating the HTML to visualize the tag cloud is fairly simple, since all the work was done earlier in chapter 3. We first need to create a List of TagCloud-Element instances, by iterating over the term vector. Once we create a TagCloud instance, we can generate HTML using the HTMLTagCloudDecorator class.
The title “Collective Intelligence and Web2.0” gets converted into five tags: [collective, collect] [intelligence, intellig] [ci, ci] [collective intelligence, collect intellig] [web2.0, web2.0]. This is also shown in figure 8.12.
Figure 8.12. The tag cloud for the title, consisting of five tags

Similarly, the body gets converted into 15 tags, as shown in figure 8.13.
Figure 8.13. The tag cloud for the body, consisting of 15 tags

We can extend our example to compute the tag magnitude vectors for the title and body, and then combine the two vectors, as shown in listing 8.30.
Listing 8.30. Computing the TagMagnitudeVector
TagMagnitudeVector tmTitle = lta.createTagMagnitudeVector(title); TagMagnitudeVector tmBody = lta.createTagMagnitudeVector(body); TagMagnitudeVector tmCombined = tmTitle.add(tmBody); System.out.println(tmCombined); }
The output from the second part of the program is shown in listing 8.31. Note that the top tags for this blog entry are users, collective, ci, intelligence, collective intelligence, and web2.0.
Listing 8.31. Results from displaying the results for TagMagnitudeVector
[users, user, 0.4364357804719848] [collective, collect, 0.3842122429322726] [ci, ci, 0.3842122429322726] [intelligence, intellig, 0.3842122429322726] [collective intelligence, collect intellig, 0.3842122429322726] [web2.0, web2.0, 0.3345216912320663] [about, about, 0.1091089451179962] [applying, appli, 0.1091089451179962] [application, applic, 0.1091089451179962] [enhances, enhanc, 0.1091089451179962] [inviting, invit, 0.1091089451179962] [improve, improv, 0.1091089451179962] [experience, experi, 0.1091089451179962] [participate, particip, 0.1091089451179962] [connecting, connect, 0.1091089451179962]
The same data can be better visualized using the tag cloud shown in figure 8.14.
Figure 8.14. The tag cloud for the combined title and body, consisting of 15 tags

So far, we’ve developed an infrastructure for analyzing text. The core infrastructure interfaces are independent of Lucene-specific classes and can be implemented by other text analysis packages. The text analysis infrastructure is useful in extracting tags and creating a term vector representation for the text. This term vector representation is helpful for personalization, building predicting models, clustering to find patterns, and so on.
8.3. Use cases for applying the framework
This has been a fairly technical chapter. We’ve gone through a lot of effort to develop infrastructure for text analysis. It’s useful to briefly review some of the use cases where this can be applied. This is shown in table 8.5.
Table 8.5. Some use cases for text analysis infrastructure
|
Use case |
Description |
|---|---|
| Analyzing a number of text documents to extract mostrelevant keywords | The term vectors associated with the documents can be combined to build a representation for the document set. You can use this approach to build an automated representation for a set of documents visited by a user, or for finding items similar to a set of documents. |
| Advertising | To show relevant advertisements on a page, you can take the keywords associated with the test and find the subset of keywords that have advertisements assigned. |
| Classification and predictive models | The term vector representation can be used as an input for building predictive models and classifiers. |
We’ve already demonstrated the process of analyzing text to extract keywords associated with them. Figure 8.15 shows an example of how relevant terms can be detected and hyperlinked. In this case, relevant terms are hyperlinked and available for a user and web crawlers, inviting them to explore other pages of interest.
Figure 8.15. An example of automatically detecting relevant terms by analyzing text
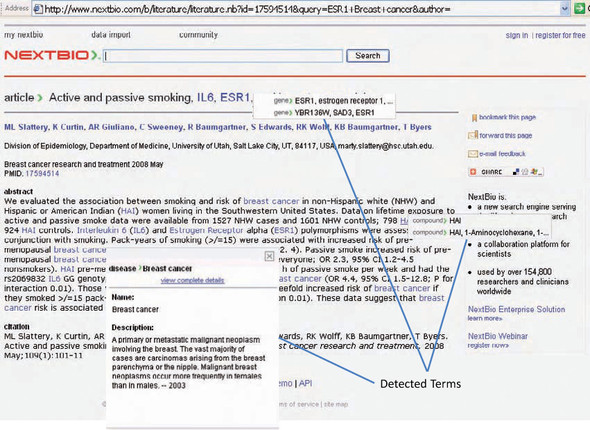
There are two main approaches for advertising that are normally used in an application. First, sites sell search words—certain keywords that are sold to advertisers. Let’s say that the phrase collective intelligence has been sold to an advertiser. Whenever the user types collective intelligence in the search box or visits a page that’s related to collective intelligence, we want to show the advertisement related to this keyword. The second approach is to associate text with an advertisement (showing relevant products works the same way), analyze the text, create a term vector representation, and then associate the relevant ad based on the main context of the page and who’s viewing it dynamically. This approach is similar to building a content-based recommendation system, which we do in chapter 12.
In the next two chapters, we demonstrate how we can use the term vector representation for text to cluster documents and build predictive models and text classifiers.
8.4. Summary
Apache Lucene is a Java-based open source text analysis toolkit and search engine. The text analysis package for Lucene contains an Analyzer, which creates a TokenStream. A TokenStream is an enumeration of Token instances and is implemented by a Tokenizer and a TokenFilter. You can create custom text analyzers by subclassing available Lucene classes. In this chapter, we developed two custom text analyzers. The first one normalizes the text, applies a stop word list, and uses the Porter stemming algorithm. The second analyzer normalizes the text, applies a stop word list, detects phrases using a phrase dictionary, and injects synonyms.
Next we discussed developing a text-analysis package, whose core interfaces are independent of Lucene. A Tag class is the fundamental building block for this package. Tags that have the same stemmed values are considered equivalent. We introduced the following entities: TagCache, through which Tag instances are created; PhrasesCache, which contains the phrases of interest; SynonymsCache, which stores synonyms used; and InverseDocFreqEstimator, which provides an estimate for the inverse document frequency for a particular tag. All these entities are used by the TextAnalyzer to create tags and develop a term (tag) magnitude vector representation for the text.
The text analysis infrastructure developed can be used for developing the metadata associated with text. This metadata can be used to find other similar content, to build predictive models, and to find other patterns by clustering the data. Having built the infrastructure to decompose text into individual tags and magnitudes, we next take a deeper look at clustering data. We use the infrastructure developed here, along with the infrastructure to search the blogosphere developed in chapter 5, in the next chapter.
8.5. Resources
Ackerman, Rich. “Vector Model Information Retrieval.” 2003. http://www.hray.com/5264/math.htm
Gospodnetic, Otis, and Erik Hatcher. Lucene in Action. 2004. Manning.
“Term vector theory and keywords.” http://forums.searchenginewatch.com/archive/index.php/t-489.html