
7 Regression diagnostics
There are some assumptions that must be fulfilled, so the regression will yield correct results (Wooldridge, 2016: 73–83; Meuleman, Loosveldt, Emonds, 2015). Therefore, it is strongly recommended to test these assumptions to see whether you can trust your conclusions. When you find out that there are great problems in the data, it might be a good idea to redo analyses, or find other data sources. The least you can do is report all the violations, so others can regard this when reading your paper.
If not otherwise stated, all diagnostics are applied to the following model we used in chapter six:
sysuse nlsw88, clear
regress wage c.ttl_exp i.union i.south c.grade
7.1 Exogeneity
The term exogeneity describes that the expected error, given all your independent variables, must be zero.47 Stated differently, any knowledge about your independent variables does not give you any information about the error term. When we come back to our example from the last chapter, this means that a union member has the same intelligence, motivation, etc… as a non-union member, unless these variables are also used as controls in the model.
This is a very strict assumption that cannot be tested statistically. When you want to pinpoint causal effects with your analyses, you have to make sure that you account for all possible further explanations, which is a difficult task. Refer to introductions to causal analysis, to learn more about that (see chapter five in this book, Morgan and Winship (2015) and De Vaus (2001)). For the moment, you should keep in mind that when you think that several other factors could have a causal influence on your dependent variable (that are in any way connected to one of your explaining (IV) variables), you have to control for these factors.
To summarize, there is no statistical test that tells you whether your model is “correct” and will calculate the desired causal effect. Nevertheless, there is one test you can try, the Ramsey test, to see whether there are general problems with the model.
estat ovtest

or click Statistics → Postestimation → Reports and statistics and choose Ramsey regression specification-error test.
If the p-value (Prob > F) is smaller than 0.05, then there are either important missing variables, or useless ones included in your model. As you see in the example, this is actually the case for our model (which is no big surprise, as this is an ad hoc demonstration which lacks any deeper theoretical justification). When you get such results, try to find other important variables that might help to explain your causal effects, and rethink your theoretical framework.
When you come to the conclusion that your theories and operationalization are fine, it is usually a good idea to prefer the theoretical argumentation over the p-value of one statistical test, and keep the model as it is.
7.2 Random sampling
The second basic assumption is that your data is from a (simple) random sample, meaning that every unit of the population has the same (nonzero) chance of getting picked for the sample. This assumption is often violated when clustering occurs. For example, when you want to collect general information about the population of a country, it would be desirable to sample from a national register that contains every single person. As this is often not available, a common step is to first sample cities and then sample from a city-based register. This is convenient and brings the cost down, as interviewers only have to visit a limited number of places. The problem is that persons within one cluster are probably somewhat similar, and, therefore, units are not completely independent of each other. Consequently, the random sampling assumption is violated. Other examples are regions, nested within countries, or people nested within families. When you are confronted with this problem, using multilevel models is a solution (Rabe-Hesketh and Skrondal, 2012: 73–137). Another remedy is to control for the stage-two variable (for example, the city). Estimated effects are then independent of place of sampling.
7.3 Linearity in parameters
In a linear regression the relationship between your dependent and independent variables has to be linear. For illustration, say the coefficient of the variable total work experience is 2.5, which means, one more year of job experience results in an income that is increased by 2.5$. This effect has to be stable, no matter whether the change of your experience is from 2 to 3 years or from 20 to 21 years. In reality, we experience that this assumption is often violated, especially when dealing with the variable age, as saturation effects occur. When we think about the effect of age on wages, we would expect that, for young people there is a positive relationship, as people gain experience over time, that makes them more valuable. This relationship will get weaker as people reach their peak performance. When people get even older, their energy and speed will decline, due to biological effects of aging, therefore, wages will start to decline. It is obvious that the relationship between age and wages is not constant over time, but looks like a reversed U. Whenever this occurs, the regression will yield biased results, as it assumes strict linearity. For illustration, the following graph shows the actual connection between age and household income, taken from the German ALLBUS dataset (N=2,572):

The first step is to check the relationship between the dependent variable and every independent variable graphically. Note that this only makes sense when the independent variable is metric, as binary (dummy) variables always have a linear relation to the dependent variable. A simple scatterplot gives you a first impression as to whether the relationship is linear or not.
twoway (scatter wage ttl_exp) ///
(lfit wage ttl_exp) (lowess wage ttl_exp)

This command creates three plots in one image. The first part creates a simple scatterplot which we already know. The second part lets Stata fit a straight line through the data points, while the last command creates a locally weighted graph which can be different from a straight line. Luckily we come to the conclusion that the relation of our only metric variable and the dependent variable is fairly linear, as the linear fit and the lowess fit are very close to each other (apart from a small region to the right). This means that our assumption is probably fulfilled. You can also use the binscatter CCS, which I personally enjoy very much (see page 58).
Another option is to use residuals to check for nonlinearity. When you run a regression, Stata can save the predicted value for each case. As we want to explain wages through some other variables, Stata can calculate the wage that is predicted by the model, for each case. The difference between the observed value of wage, and the predicted value, is the residual. For example, when a respondent has a wage of 10 and the regression predicts a wage of 12, then the residual is -2 for this person. Usually you want the residuals to be as small as possible. When we plot residuals against our variables and cannot detect any pattern in the data points, the relation seems linear. For point-and-click go Statistics -> Postestimation and choose Predictions -> Predictions and their SEs, leverage statistics, distance statistics, etc.
regress wage c.ttl_exp i.union i.south c.grade
predict r1, residuals //Create residuals
scatter r1 ttl_exp //No pattern visible

binscatter r1 ttl_exp //Alternative command with CCS

7.3.1 Solutions
When you come to the conclusion in your own analysis that a relation is not linear you can try to save your model by introducing higher ordered terms as additional variables in your model (polynomial regression). For example, let’s say the variable age causes the problem. Then you can use Stata’s factor variable notation (include the term c.age##c.age or even c.age##c.age##c.age, a three-way interaction).48 How exactly you want to model and transform your independent variable depends on the functional form of the relationship with the dependent variable. After you had your command run you can use the calculated R-squared to assess the model fit. When the value went up this tells you that your new model is probably better.
If this still does not help you, take a look at the idea of a piecewise regression, or at the commands gmm, nl or npregress kernel49 (warning: these are for experienced users and require a lot of understanding to yield valid results).
Nested models
Often you want to compare different models to find the variable transformation that helps you best to describe the distribution of your data points mathematically. R-squared is a statistic that is very commonly used to do this, as higher values indicate a better model fit. However, this is not without problems, especially when you want to compare nested models. A nested model is a subset of another model. For example, when you want to predict wage and use the variables south and union and after that, you run a second model which uses the variables south, union and work experience, then the first model is nested inside the second , as the explaining variables are a subset of the second model. By doing this you want to see which model is better to describe reality. The problem is that you usually cannot compare R-squared values over nested models. Luckily other statistics can help you out. Akaikes Information Criterion (AIC) or the Bayesian Information Criterion (BIC) are suited to do this. You can get them by running your model and typing
estat ic

or click Statistics → Postestimation → Reports and statistics.
So run both models, calculate the AIC (or BIC) for both and compare which model has the lower value (lower means better here).
That brings up another important step in data handling: when you want to compare nested models you have to make sure that the number of cases used is identical and thus comparable. For example, your second model includes one additional variable but has missing values. Then, as Stata throws out cases that have even one missing on any variable used (listwise deletion), model two will use fewer cases than model one. When you get different results this can be due to the fact that the new variable has a significant effect but can also arise when you analyze a different subgroup (for example, you include income, but rich people do not want to answer this question and thus have missing values. Consequently, many rich people are excluded from the analysis, which might bias your results). To avoid this mistake check the model with the highest number of variables included and delete (or flag) all cases that have one or more missings on the variables used.
You can also use Stata internals to make this more convenient. You start with your complex model (the one with the highest number of independent variables), store the results and then run the simple model, using only cases that are already in the complex one:
regress DP IV1 IV2 IV3 //MComplex
estimates store complex //Save results
regress DP IV1 if _est_complex //MSimple
7.4 Multicollinearity
When you have a large number of independent (control) variables it can be problematic if there are strong correlations among these. For example, you could have one variable age, measured in years, and you create a second variable which measures age in months. This variable is the value of the first variable multiplied by 12. This is a problem for Stata, as both variables basically contain the same information and one of the two variables must be dropped from the analysis (to be more precise: one of the two is a linear combination of the other). Sometimes there is no perfect linear combination that predicts another variable but a strong correlation, maybe when you use two operationalizations of intelligence that have a high correlation. If this happens the standard errors of estimated coefficients can be inflated, which you want to avoid. You can test for multicollinearity after you run your model with the command
estat vif

or click Statistics → Postestimation → Reports and statistics.
VIF is the variance inflation factor. As a rule of thumb, any values above 10 are probably critical and should be investigated. When you include squared terms, as described in chapter 7.3.1 to account for nonlinear relations it is normal that the added terms have a high multicollinearity with the variables from which they are derived.
7.4.1 Solutions
When you notice that some variables have an unusually large value for VIF it could help to exclude one them from the regression and check whether the problem persists. Another variable probably already accounts for a large part of the aspect you try to measure, as correlation is high. Also you should think theoretically how the variables you used are related to each other and whether there are any connections. Maybe you can find another variable that has a lower correlation with the other explaining variables but can account for a part of your theory or operationalization.
7.5 Heteroscedasticity
Like explained above, after running your regression you can easily compute residuals, which are the differences between predicted and actual values for each case. One assumption of regressions is that the variance of these errors is identical for all values of the independent variables (Kohler and Kreuter, 2012: 296). Stated otherwise, the variance of the residuals has to be constant.50 If this assumption is violated and the actual variance is not constant we call this heteroscedasticity.51 We can check this by plotting residuals against predicted values
rvfplot, yline(0)

or click Statistics → Linear models and related → Regression diagnostics → Residual-versus-fitted plot. Each data point represents one observation. We see that there is a pattern in the data: to the left the points are all very close to the dotted line while the distance grows the further we move to the right. We see like a triangular distribution of the dots which clearly indicates that the variance is not homogeneous and, therefore, the assumption is violated. We can also test this assumption numerically by typing
estat hettest

or click Statistics → Postestimation → Specification, diagnostic, and goodness-of-fit analysis and choose Tests for heteroscedasticity, then click Launch. The null hypothesis is that there is a constant variance of the residuals. As the p-value (Prob > chi2) is smaller than 0.05, we have to reject this assumption. This further underlines that there is a violation.52
7.5.1 Solutions
Heteroscedasticity often occurs when the distribution of the dependent variable is very skewed. It is a good idea to have a look at this, probably with a histogram
histogram wage //Graphic see page 51
This clearly shows that most values are between 0 and 15 and above that there are only a few cases left. There are many ways to solve this problem. What you should do depends on your goals. If you are only interested in interpreting signs and p-values (to see if there is any significant effect at all) you can transform the dependent variable and live with it. In contrast to that, when you want to make predictions and get more information out of the data, you will certainly need a re-transformation to yield interpretable values, which is a little more complex. Therefore, I will start with the simple solutions and proceed with a little more advanced options.
Signs and p-values
To receive trustable results with small standard errors when heteroscedasticity is present, it must be your goal to make the distribution of your dependent variable as symmetric and normal as possible. The idea is to apply a mathematical transformation to achieve this. The best way to start is often to check visually which transformation might be best. So type:
gladder wage

or click Statistics → Summaries, tables, and tests → Distributional plots and tests → Ladder of powers. You will receive several histograms that depict how the variable looks after performing a transformation. Pick the one that looks most symmetrical and normally distributed, in our case the log-transformation.
generate lwage = log(wage)53
quietly regress lwage c.ttl_exp i.union i.south c.grade
estat hettest

You will notice that the graphical distribution of the data points is much more equal and signals homogeneity. The numerical test is still significant, but the p-value is larger and thus we reduced the amount of the problem. If you think this is still not good enough, you can try the Box-Cox-transformation.
bcskew0 bcwage = wage
histogram bcwage

You find this command under Data → Create or change data → Other variable-creation commands → Box-Cox transform.
We conclude that this distribution is clearly more symmetrical than before. You can now run another regression with bcwage as the dependent variable and interpret the signs and p-values of the variables of interest. The problem of heteroscedasticity should be greatly reduced.
Predicted values
Often it is more important to actual predict values for certain constellations than to only conclude that a certain variable has a significant influence or not. If you need this, a little more work is required so you receive results that are accessible to non-statisticians. The first and super-easy option is run a normal regression model without any changes and specify robust standard errors. Stata will apply different algorithms that can deal better with heteroscedasticity.
regress wage c.ttl_exp i.union i.south c.grade, vce(robust)
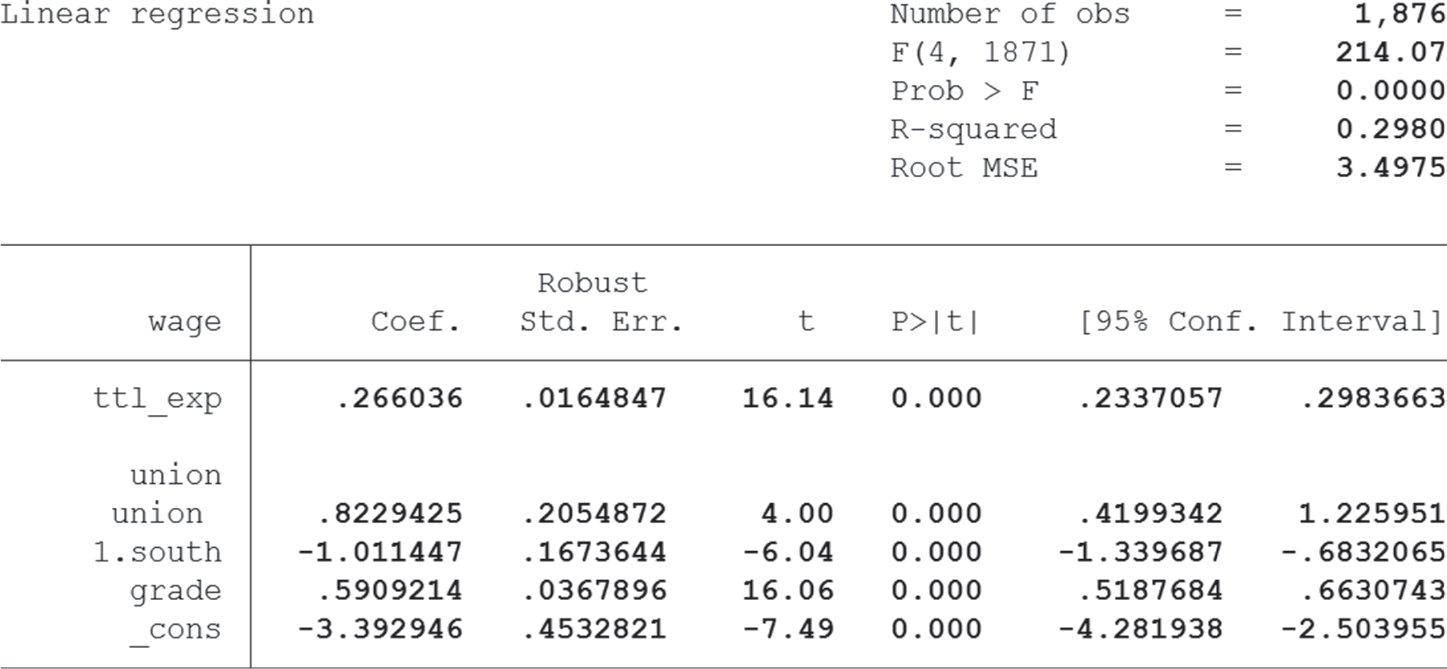
You will notice that the coefficients are identical to the normal regression, but the standard errors and, therefore, also the confidence intervals changed slightly. You can compare the results to the same model which uses regular standard errors (see page 92). To summarize it, you can use robust standard errors when you expect high heteroscedasticity but keep in mind that they are not magic and when your model is highly misspecified they will not save your results. Some statisticians recommend to calculate normal and robust standard errors and compare results: if the difference is large the model is probably poorly specified and should be revised carefully (King and Roberts, 2015). So you see, this option can be helpful in some cases, but sometimes it will not yield the best outcomes.
If you come to the conclusion that robust standard errors will not really improve your model, you can transform your dependent variable, as described above, and later re-transform the predictions to produce results that can be interpreted easily. We will choose a log-transformation for the example (make sure you have created the logged variable as explained before):
quietly regress lwage c.ttl_exp i.union i.south c.grade
margins union, at(ttl_exp=(0(4)24)) expression(exp(predict(xb)))
marginsplot

The magic happens in the option expression. We specify that the exponential-function (exp) should be applied to the result, as this is the inverse-function of the log-function. Finally, Stata produces a nice graph for us which shows the effect of union-membership for certain values of work experience. This method is not restricted to the log-function, as long as you specify the correct inverse-function for re-transformation. Note that this is an advanced topic and you should further research the literature, as the “best” transformation, or method, also depends on your research question and your variables. For example, some statisticians even prefer a poisson model over the regression with a log-transformed variable.54
7.6 Influential observations
Sometimes there are extraordinary cases in your dataset that can significantly influence results. It can be useful to find and investigate these cases in detail, as it might be better to delete them. This can be the case if they are extreme outliers, or display a very rare or special combination of properties (or just plain coding errors). To find these cases, Stata can compute different statistics.
7.6.1 Dfbetas
The first option for checking special cases are Dfbetas. Run your regression model as usual and type
dfbeta
or click Statistics → Linear models and related → Regression diagnostics → DFBETAs, name the new variable and click Submit.
Stata creates four new variables (one for each metric or binary variable and one for each category of a categorical variable). You can get a nice visualization by typing
scatter _dfbeta_1 idcode, mlabel(idcode)

The further the absolute distance of a value from zero the greater the influence. You can check the cases which seem the most distant and inspect them individually. Then repeat for all other created dfbetas. There is a rule of thumb to estimate the value above which cases are problematic, which is calculated by the formula , where n is the number of cases (observations) used in the model. In our example this would be
We can get a complete list of all cases that violate this limit by typing
list if abs(_dfbeta_1) > 0.0462 & !missing(_dfbeta_1)
count if abs(_dfbeta_1) > 0.0462 & !missing(_dfbeta_1)
- output omitted -
Do not forget to exclude cases with missing values, as otherwise these will be listed as well!
According to this, 83 cases are problematic (this is the result for the first dfbeta only). As there is no general rule for dealing with these cases, it is up to you to inspect and decide. When you do nothing and just ignore influential observations, it is also fine, as these are rarely discussed in research papers. When you are unsure what to do, consult your advisor (as he or she is the one who will grade your paper).
7.6.2 Cook’s distance
When you do not like Dfbetas, since they are tedious to check when you use a great number of variables in your model, an alternative is Cook’s distance which summarizes all information in just one variable. This measurement detects strange patterns and unusual variable constellations and can help to identify coding errors or problematic cases. As usual, run your model first and type
predict cook, cooksd
scatter cook idcode, mlabel(idcode)

or click Statistics → Linear models and related → Regression diagnostics → Cook’s distance, name the new variable and click Submit.
You can now inspect the scatterplot visually and have a look at the problematic cases that have unusually large values. One example is clearly case number 856, so we will list the relevant information for that particular observation.
list wage ttl_exp union south grade if idcode == 856

This person has an extraordinarily high income, although her education is only medium and she is from the south. In general, this is a strange constellation which causes the high leverage of this case on the results.
A final possibility is to use leverage-versus-squared-residual plots which combine information about the leverage and residuals. This makes detection of outliers easy. Just run your regression and type
lvr2plot, mlabel(idcode)

This plot shows for each case, the individual leverage (y-axis) and residual (x-axis). If the residual of a case is high, this tells us that our model makes a prediction that is quite off from the real outcome. Therefore, the residual is related to the dependent variable of the case. A high leverage of a case tells us that the constellations of independent variables of a certain case are so extreme, or uncommon, that they influence our final result over proportionally. Therefore, the leverage is related to the independent variables of a case. The two dotted lines in the graph show the means for both residuals and leverages. The diagnostics reported here are not exhaustive, as a much longer list of tests and method exists that can be used to assess the results of a regression. By listing the most important aspects that you should always control, I think that the results should be quite robust and suitable for publication. It is always a good idea to ask the people who will later receive your paper whether they have extra suggestions for tests that you should apply. Also, have a look at the literature and footnotes throughout the chapter, as they provide valuable information.
7.7 Summary
The following table (Table 7.1) will summarize the most important aspects we have learnt so far. Also keep in mind that bias is usually worse for your results than inflated standard errors.
Table 7.1: Summary of linear regression diagnostics.

Macros
Sometimes it is necessary to run a command several times, with different options, to compare results, or to just play around with specifications. When you use a command which includes many variables, typing it all the time can get tiring. Another very common scenario is that you run a model with some control variables and later get feedback from your colleagues who suggest that you add some more variables. Now, you probably have to add these new variables at every place in your do-file, to update your code, which is error-prone.
A solution to this is to use local macros which allow you to define lists of variables at one place and then use them en block. When you come back later and want to add or delete variables, you only have to do so in one place. The general syntax is easy:
local controls c.age c.tenure i.race
regress wage i.union `controls’55
The first line defines the macro with they keyword local. After that you put the name (“controls”). Then a list of all variables follows, here with factor variable notation. The second line runs a regression with wage as a dependent variable. There will be four independent variables, union and the three others, which are included in “controls”. The macro must be typed in a do-file and only “lives” as long as the do-file is executed. After that you cannot use the local again, say, in the command line.
The counterpart to local macros is global macros. The main difference is that these macros can be used as often as you want, and they will still be in memory after your do-file has run. You can change a global macro anytime by redefining it. The usage is similar:
global test grade wage
summarize $test
To refer to the global macro the dollar-sign is used as a prefix. Keep in mind that globals can be problematic when it comes to debugging, as old or “forgotten” macros might haunt you later on.