
Chapter 4
Syntax Analysis — Top-Down Parsers
Syntax analysis or parsing recognizes the syntactic structure of a programming language and transforms a string of tokens into a tree of tokens. Top-down parsers are simple to construct. Parsers are also used in natural language applications.
CHAPTER OUTLINE
The second phase in the process of compilation of a source program is syntax analysis. This phase comes after the lexical analysis phase. While lexical analyzer reads an input source program and produces an output—a sequence of tokens—the syntax analyzer verifies whether the tokens are properly sequenced in accordance with the grammar of the language. If not, the syntax analyzer detects the errors and produces proper sequence of error messages to the user and if possible recovers from the errors. The output of syntax analyzer is a parse tree, which is used in the subsequent phases of compilation. This process of analyzing the syntax of the language is done by a module in the compiler called parser. For performing syntax analysis, the grammar of the language has to be specified. Context Free Grammars (CFGs) are used to define standard syntax rules for the language. This process of verifying whether an input string matches the grammar of the language is called parsing. This chapter describes the process of parsing, error handling, types of parsers, and top-down parsing in detail.
4.1 Introduction
The syntax analyzer obtains a string of tokens from the lexical analyzer. It then verifies the syntax of the input string by verifying whether the input string can be derived from the grammar or not. If the input string is derivable from the grammar, then the syntax is correct; if the input string is not derivable, then the syntax is wrong. This is shown in Figure 4.1. The parser should also report syntactical errors in a manner that is easily understood by the user. It should also have procedures to recover from these errors and to continue parsing action.
The output of a parser is a parse tree for the set of tokens produced by the lexical analyzer. In practice, there are a number of tasks that are carried out during syntax analysis, such as collecting information about various tokens and storing into symbol table, performing type checking and semantic checking, and generating intermediate code. These tasks will be discussed in detail in syntax-directed translations.

Figure 4.1 Syntax Analysis
4.2 Error Handling in Parsing
Compiler construction would be very simple if it has to process only correct programs. But most of the programmers write incorrect programs; hence, a good compiler should always assist a programmer in identifying and detecting errors. Generally, programming languages do not specify how a compiler should respond to errors. The response is left to the compiler designer.
Generally, errors in programs are detected at different levels.
- At lexical analysis: Unrecognized group of characters like &abc, $abc, etc., which cannot be a keyword or identifier
- At syntax analysis: Missing operator/operands in expression
- At semantic analysis: Incompatible types of operands to an operator
- Logical errors: Infinite loop. Detecting logical errors at compile time is a tedious task.
In the compilation process, 90% of errors are captured during the syntax and semantic analysis phase.
That’s why error detection and recovery in compiler are centered on parsing. The main reason for this is that many errors are syntactic in nature or are captured when a stream of tokens from the lexer does not match with the grammar of the programming language. Another reason is the precision of modern parsing methods. They can detect the presence of syntax errors very efficiently. In this section, we shall discuss a few techniques for syntax error recovery.
Error-Recovery Strategies
There are four different error-recovery strategies generally used by parsers.
- Panic Mode
- Phrase Level
- Error Production
- Global Correction
4.2.1 Panic Mode Error Recovery
This is a simple method used by most of the parsers. On an error, the recovery strategy used by the parser is to skip input symbols one at a time until one of the designated synchronizing tokens is found. The synchronizing tokens can be ‘end’,’}’,’)’, ‘;’ whose role in the source program is well defined. The compiler designer must select the appropriate set of synchronizing tokens from the source language. For example, in “C” language, on detecting an error, it simply skips all characters till “;” since “;” is at the end of every statement.
4.2.2 Phrase Level Recovery
On detecting an error, the parser may perform some local corrections on the remaining input. It could be replacing an incorrect character with a correct one or swapping two adjacent characters such that the parser can continue with the process. The local correction is a choice left to the compiler designer. A token can be replaced, deleted, or inserted as a prefix to the input; this will enable the parser to continue with the process. We must be very careful while doing replacements. Sometimes, replacements may lead to infinite loops.
4.2.3 Error Productions
If the compiler designer has a good idea about possible errors, then he can add rules with the grammar of the programming language to handle erroneous constructs. A parser is constructed for this new grammar such that it handles errors. The error productions are used by the parser to issue appropriate error diagnostics on erroneous constructs in the input. Automatic parser generator “YACC”—yet another compiler compiler—uses this strategy.
4.2.4 Global Correction
Generally, it is preferred to have minimum changes, that is, corrections in the input string. There are algorithms to obtain a globally least cost corrections that help in choosing a minimal sequence of changes.
4.3 Types of Parsers
Parsers can broadly be classified into three types as shown in Figure 4.2.
4.3.1 Universal Parsers
Universal parsers perform parsing with any grammar. That’s why they are called universal parsers. They use parsing algorithms like Cocke-, Younger-, Kasami-algorithm or Earley’s algorithm. It uses the Chomsky Normal form of the CFG. This method is inefficient. So it is not used in commercial compilers.
Parsers that are commonly used in compilers are top-down parsers or bottom-up parsers.
4.3.2 Top-Down Parsers (TDP)
Top-down parsing involves generating the string starting from the start symbol repeatedly applying production rules for each nonterminal until we get a set of terminals. The output of any parser is a parse tree. A top-down parser constructs the parse tree starting with root and proceeds toward the children. Here it uses Left Most Derivation (LMD) in deriving the string. The task of a top-down parser at any time is to replace a nonterminal by the right hand side of the rule.
Consider the following example:
Example 1:
Grammar and input string
S → a A B e
A → b | b c
B → d
w = “abcde”
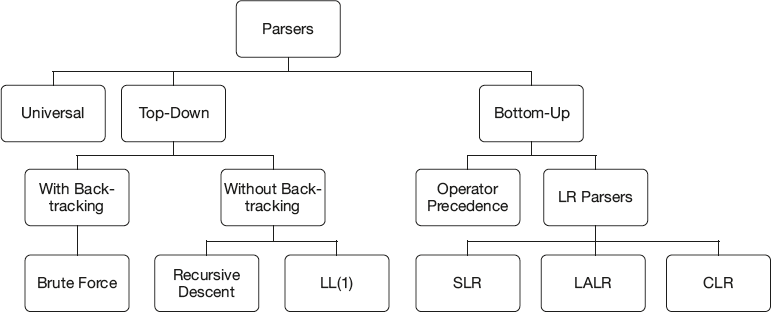
Figure 4.2 Types of Parsers
The construction of the top-down parser is shown in Figures 4.3 and 4.4. A top-down parser starts the parse tree with the start symbol, S.
Replace S by the right hand side, that is, “aABe”.
Now, in the expanded string there are two nonterminals, A and B. Which one do we expand first? This is resolved by the parser as follows. A TDP uses LMD in recognizing a sentence. Hence, the parser first selects “A” for expansion. Now nonterminal A has two alternative rules. Which one do we choose fist? This is the primary problem. Here, if we expand A by first alternative, that is, “b,” we cannot get the required string. The right choice here is the second alternative, that is, “bc.” So a top-down parser is constructed as follows:
Though the task of the top-down parser is very simple—replacing nonterminal by right hand side of rule—the primary problem in design is if a nonterminal has more than one alternative, then there should be some mechanism to decide the right choice for expansion. How can this problem be handled by the different types of top-down parsers? This is what we will discuss in the remaining topics.
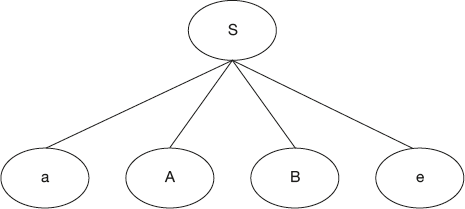
Figure 4.3 Top-Down Parser Construction
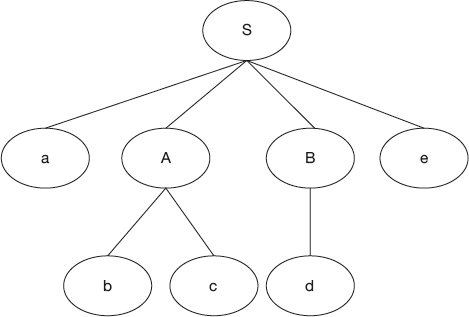
Figure 4.4 Top-Down Parser Construction
4.3.3 Bottom-Up Parsers
Bottom-up parsing is not simple like top-down parsing. Bottom-up parsing involves repeatedly reducing the input string until it ends up in the first nonerminal, that is, the start symbol of the grammar.
Let us look at the complexity of reducing the input string to start symbol. The task of a bottom up parser at any time is to identify a substring that matches with the right hand side.
Replace that string by the left hand side nonterminal.
Consider the following grammar and input string.
Example 2:
S → a A B e
A → b | b c
B → d
w = “abcde”
The construction of bottom-up parser is shown in Figure 4.5. A bottom-up parser looks at reducing the string “abcde” to start the symbol S. Now let us understand the complexity of reducing the string to the start symbol. If at all the string “abcde” is reduced to “a A B e,” then we can replace “aABe” with S. To reduce “abcde” to “aABe,” after the first “a,” “A” is required. “A” can be either “b” or “bc.” Since the task of a bottom-up parser at any time is to identify a substring that matches with right hand side, replace that string by the left hand side nonterminal. Hence, we can take string “b” then replace it by “A.” But if we do so, it cannot be reduced to the start symbol “S”. So this is not a valid reduction. How do we determine valid reductions? This is resolved as follows.
A bottom-up parser uses the reverse of right most derivation in reducing the input string to the start symbol. So whenever a substring is identified and reduced, it should give one step along the reverse of the right most derivation. So a bottom-up parser works as follows:
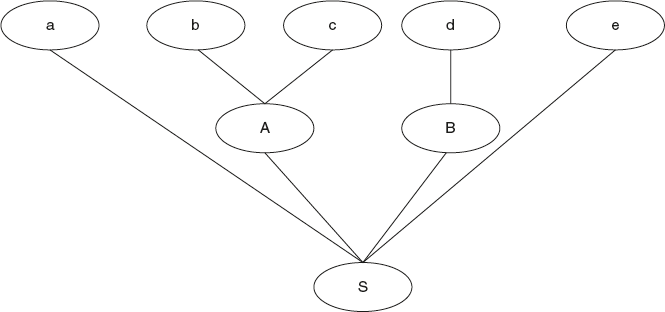
Figure 4.5 Bottom-up parser construction
So the task of a bottom-up parser at any time is to identify a substring that matches with the right hand side; if that substring is replaced by the left hand side nonterminal, it should give one step along the reverse of the right most derivation.
The main difficulty in bottom-up parsing is identifying the substring that is called handle.
Bottom-up parsing can be described as “detect the handle” and “reduce the handle.” The main difficulty is detecting the handle.
While discussing different top-down parsers and bottom-up parsers, we will see how this problem is handled in the design of such parsers. Let us consider top-down parsers first.
4.4 Types of Top-Down Parsers
Top-down parsing can be viewed as an attempt to construct a parse tree in a top-down manner for the given input. The tree is created by starting from the root and creating the nodes of the parse tree in preorder. It uses leftmost derivation.
In the above section, the process of top-down parsing and bottom-up parsing, the difficulties in design are introduced. Recall that top-down parsing is characterized as a parsing method, which begins with the start symbol, attempts to produce a string of terminals that is identical to a given source string. This matching process is executed by successively applying the productions of the grammar to produce substrings from nonterminals. Here we discuss several ways of performing top-down parsing.
The type of grammar that is used in parser construction is context free grammar. Empty productions (ε - rules) are also allowed with grammar.
Top-down parsers are broadly classified into two categories based on the design methodology used—with full backtracking and without backtracking. With full backtracking we have the Brute Force Technique.
4.4.1 Brute Force Technique
Top-down parsing with full backtracking is known as Brute Force Technique. Since it is top-down parser, it attempts to create the parse tree starting with root and proceeds to children. Whenever a nonterminal has more than one alternative, it follows the procedure given below in choosing the production.
- Whenever a nonterminal is to be expanded for the first time, always substitute with the first alternative only, that is, first time, first rule.
- Even in the newly expanded string the same procedure is repeated, i.e., first time first alternative only for expansion.
- This process continues until the nonterminal gets a string of terminals.
- Once the nonterminal gets the string of terminals, it compares that with the input string; if both of them match, it announces successful completion. Otherwise, it realizes that that is not the desired string. So it backtracks and now tries with the second alternative at the next level. Once all possibilities are exhausted at the lower level, and if too do not match, then it backtracks to the next level and repeats the same procedure until all combinations are verified.
As an example of the Brute Force Technique, consider the following grammar and input string w.
Example 3:
S → r Ad | r B
A → y | z
B → zzd | ddz
String w is: “rddz”
Let us see how the brute force parser works. This is shown in Figure 4.6. Parser starts with the root symbol S.
The parser replaces S by the first alternative, that is, “rAd.” In the newly expanded string “rAd,” A is to be replaced for the first time; hence the parser replaces by the first alternative only, that is, y. Now we get a string “ryd,” which is not the expected string.
So at the lower level, for A we have already tried the first rule; now it goes with the second rule, that is, z. Now we get a string “rzd,” which is not the expected string.
Since all the possibilities with “A” are exhausted, the parser now backtracks and goes with the first level, that is, S. With “S” all the possibilities with the first alternative are verified; it then backtracks and goes with second alternative rule, that is, “rB.” In the expanded string, “B” is to be expanded for the first time; hence, it goes with the first alternative only, that is, “zzd.” It gets a string “rzzd,” which is not the expected string. So it backtracks and goes with the second alternative, that is, “ddz.”. Then it gets the desired string “rddz.”
The main disadvantages of the Brute Force Technique are:
- Too much of backtracking is involved; hence, such parsers are dead slow.
- Error recovery is also difficult. Unless all the possibilities are verified, we cannot say anything about any error that could have occurred. Even if there is an error, we cannot say when exactly the error has occurred.
- Backtracking is costly.
That is why such parsers are not preferred for practical applications. Practically used parsers are under the second category, that is, without backtracking. These parsers are even called predictive parsers.
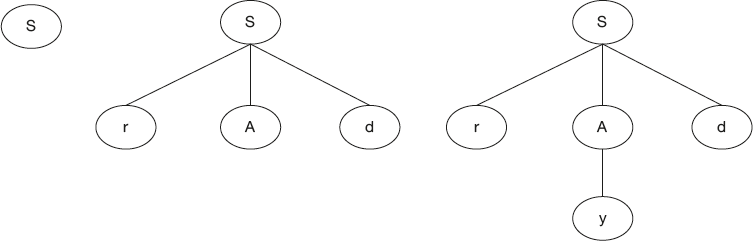
Figure 4.6(a) Brute Force Parser
Figure 4.6(b) Brute Force Parser
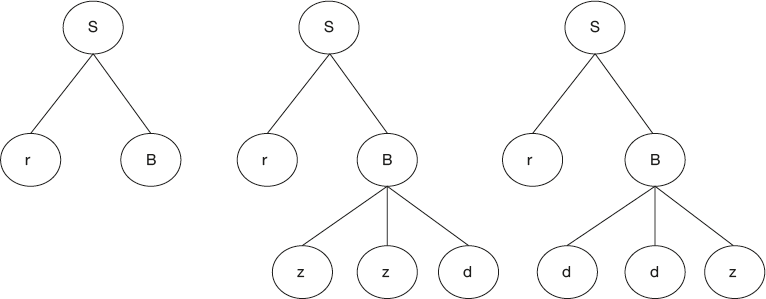
Figure 4.6(c) Brute Force Parser
4.5 Predictive Parsers
A predictive parser is capable of predicting the right choice for expanding a nonterminal. Given a grammar and input string, to design a predictive parser, there is a restriction on the grammar. The restriction is: The grammar should be free of left recursion and should be left factored. A predictive parser tries to predict which production produces the least chances of a backtracking and infinite looping. Predictive parsing relies on information about what first symbols can be generated from a production. If the first symbols of a production can be a nonterminal, then the nonterminal has to be expanded till we get a set of terminals.
There are two types of predictive parsers.
- Recursive descent parser
- Nonrecursive descent parser
The simplest is the recursive descent parser.
4.5.1 Recursive Descent Parser
The top-down parsing method given in the previous section is very general but can be very time consuming. A more efficient (but less general) method is recursive descent parsing. One of the most straightforward forms of top-down parsing is recursive descent parsing.
Recursive descent parsing is writing recursive procedures for each nonterminal. This is a top-down process in which the parser attempts to verify whether the syntax of the input string is correct as it is read from left to right. A top-down parser always expands a nonterminal by the right hand side of the rule at any time until it gets a string of terminals. The parser actually reads input characters from the input stream, symbol by symbol from left to right, and matching them with terminals from the grammar that describes the syntax of the input. Our recursive descent parsers will read one character at a time and advance the input pointer when the proper match occurs. The routine presented in the following figures accomplishes this matching and reading process.
Recursive descent parser actually performs a depth-first search of the derivation tree for the string being parsed; hence, the name “descent.” It uses a collection of recursive procedures; hence, the name “recursive descent.”
As our first example, consider the following simple grammar:
Example 4:
S → a + A
A → (S)
A → a
and the derivation tree for the expression a + (a + a) is shown in Figure 4.7.
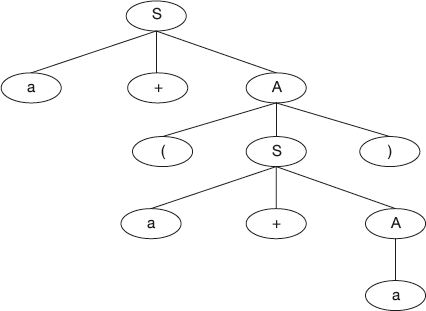
Figure 4.7 Derivation Tree for a + (a + a)
A recursive descent parser is a top-down parser and the parser works starting with the start symbol. Hence, it traverses the tree by first calling a procedure “S.” This procedure “S” reads the symbol “a” and “+” and then calls a procedure “A.”
Let the token to be read in the input stream be next_token. The function match() is matching the next token in the parsing with the current terminal derived in the grammar and advancing the input pointer, such that next_token points to the next token. match() is effectively a call to the lexical analyzer to get the next token. This would look like the following routine:
char next_token;
next_token = getchar();
int match(char terminal)
{if next_token == terminal then next_token = getchar();
else error ();
}
Note that “error” is a procedure that notifies the user that a syntax error has occurred and then possibly terminates execution.
S → a + A
For this rule, procedure for “S” is defined as follows:
Procedure S()
{if next_token == ‘a’ {
match(‘a’);
match(‘+’);
A();
}
else error();
}
A → (S) | a
In order to recognize “A,” the parser must decide which of the productions to execute. This is not difficult and is done based on the next input symbol to be recognized. The procedure can be defined as follows:
Procedure A()
{if next_token == ’(’ {
match (‘(’) ;
S();
match (‘)’);
}
else
if next == ‘a’ {
match(‘a’);
}
else error ();
}
In the above routine, the parser must decide whether “A” can be (S) or a. If it does not match these two then the error routine is called; otherwise, the respective symbols are recognized.
Here both the procedures S() and A() are nonrecursive as the rules defined for that nonterminal are nonrecursive. If the rules are recursive, procedures also become recursive.
Generally, the grammar is a set of recursive rules. Only because of recursion, with finite rules, we define infinite sentences. That’s why we say “recursive descent parsing is writing recursive procedures for each nonterminal.” So, all one needs to write a recursive descent parser is a nice grammar that is free of left recursion and is left factored.
Note that given a grammar, we can write a recursive descent parser without left factoring the grammar. Then that becomes a recursive descent parser without backtracking. So a recursive descent parser can be with backtracking or without backtracking. It depends on the grammar. Remember though it is simple, this is also of restricted use. If the language is simple, that is, if the grammar is simple, we can choose recursive descent parsing.
Out of all top-down parsers the most widely used parser is the nonrecursive descent parser, which is also called the LL(1) parser. This does not use any procedures but uses a table and a stack.
4.5.2 Nonrecursive Descent Parser-LL(1) Parser
It is possible to build a nonrecursive descent parser, also called LL (1) parser, by using a stack explicitly, rather than implicitly via recursive calls. The key problem in the design of predictive parser is that of determining the right production to be applied for a nonterminal. The nonrecursive parser looks up the production to be applied in parsing table. We shall see how the table can be constructed directly from the grammars. This is shown in Figure 4.8.
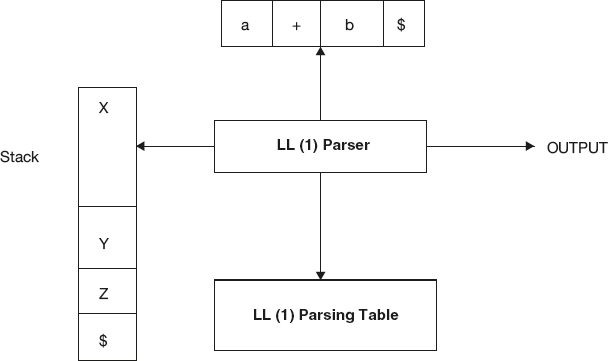
Figure 4.8 Nonrecursive Descent Parser/LL(1) Parser
A table-driven nonrecursive predictive parser uses an input buffer, a stack, a parsing table, and an output stream. The string to be parsed is read into the input buffer and “$” is appended at end. “$” is a symbol used as a right-end marker to indicate the end of the input string. The stack contains a sequence of grammar symbols at any time. Initially “$” is pushed on to the stack, indicating the bottom of the stack. A top-down parser starts working by pushing the start symbol of the grammar on to the stack. The parsing table is a two-dimensional array M [S,a] where “S” is a nonterminal and “a” is a terminal or the input right end marker “$.”
The parser works as follows: Suppose if “X” is the symbol on the top of the stack and “a,” the current input symbol. The current symbol pointer by input pointer at any time is called the look-ahead symbol. Parser always works by comparing the top of the stack ‘X’ with the look-ahead symbol “a.” These two symbols determine the action to be performed by the parser.
Depending on the top of the stack (grammar symbol) there are three possibilities.
- If X = = a = = $, that is, when the entire input string is read and by the time the stack becomes empty, the parser halts and announces successful completion of parsing.
- If ((X = = a)! = $), that is, if the top of the stack is a terminal matching with the look ahead symbol but it is not end of input, then the parser pops X off the stack and advances the input pointer to the next input symbol.
- If X is a nonterminal, the parser consults parsing table entry M[X,a]. This parsing table entry will be either a production of the grammar or blank entry. If, for example, M[X,a] = {X → UVW}, the parser replaces nonterminal X on top of the stack by WVU (with U on the top). If entry is blank then it is an error.
As output, we shall assume that the parser just prints the production used.
So the parser repeatedly uses step 2 or 3 until it reaches step 1. Coming to the error detection, in step 2, if the top of the stack is a terminal but does not match with the look ahead, then it is an error.
Similarly in step 3, when the top of the stack is a nonterminal, the parser refers to the parsing table for replacing X. If the respective entry in table is a blank entry, it announces error. Remember blank entries in parsing table indicate errors. If M[X,a] = error, the parser calls an error recovery routine.
The behavior of the parser can be well understood if we consider input with stack configurations that give the stack contents. Let us understand the LL(1) parsing algorithm with an example.
4.5.3 Algorithm for LL(1) Parsing
Input: An input string “w” and a parsing table M for grammar G.
Output: If w is in L(G), parse tree for string w; otherwise, an error.
Method: Initially, the parser has $S on the stack with start symbol “S” of Grammar “G” on top, and w$ in the input buffer.
The program that uses the predictive parsing table M to parse the given input is as follows:
set the input pointer “iptr” to point to the first look ahead symbol of w$.
repeat
let A be the top stack symbol and a the symbol pointed to by iptr.
if A is a terminal of $ then
if A == a then
pop X from the stack and advance iptr
else error()
else
if M[A,a] = A → Y1Y2...Yk then begin
pop A from the stack;
push Yk,Yk-1...Y1 onto the stack, with Y1 on top;
output the production A → Y1Y2...Yk
end
else error()
until A = $
Example 5:
Given a grammar and an input string,
E → E + T | T
T → T * F | F
F →(E)|id and string w = ‘id+id*id’
Let us understand how an LL(1) parser parses the input using the grammar.
Solution: Given a grammar, to construct LL(1) parser, there is a restriction on grammar. The grammar should be free of left recursion and should be left factored. So if we eliminate left recursion resulting grammar is as follows:
E → TE’
E’ → +TE’|e
T → FT’
T’ → *FT’|e
F → (E)|id
Use this grammar and construct the LL(1) parsing table. As we have not discussed the procedure of LL(1) table construction, let us take the table that is required for understanding the parsing algorithm. Later we will discuss how to construct such a table. LL(1) Table for the above grammar is:

With input string ‘i d + id * id’, the LL(1) parser makes a sequence of moves shown in Figure 4.9. Initially, the input pointer points to the leftmost symbol.
The output of a parser is a parse tree. The last step in parsing algorithm, that is, step 4 helps in constructing the parse tree. The order in which different nonterminals are used in parsing is listed in the above table. If we follow that order, that gives us a parse tree.
Given a grammar G to construct nonrecursive predictive parser, that is, LL(1), we use two functions, First and Follow. These functions allow us to fill in the entries of a predictive parsing table for G whenever possible. During panic-mode error recovery, set of tokens given by the “Follow” set can be used as synchronizing tokens. Let us understand these two functions now.
4.5.4 First(α), Where α Is Any String of Grammar Symbols
First(α) gives the set of terminals that begin the strings derived from α. If α* ⇒ ε or α → ε then ε is also in First(α).
To compute First(α) for all grammar symbols α, apply the following rules until no more terminals or e can be added to the First set. ‘α’ is a grammar symbol. Hence, two possibilities exist, “α” can be a terminal or nonterminal.
- If α is a terminal, then First(α) is {α}.
Example:
First(+) = {+}, First(*) = {*}, First(id) = {id}
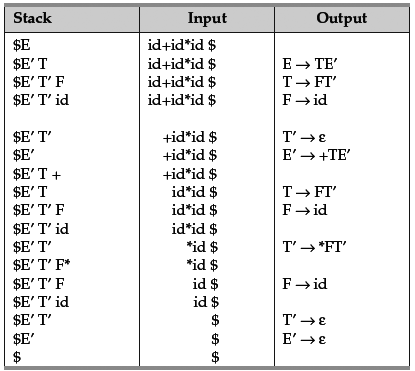
Figure 4.9 Sequence of Moves by the LL(1) Parser while Parsing “id + id * id”
- If “α” is a nonterminal, two possibilities exist: α may be defined with null production or non null production.
If “α” is a nonterminal
- & is defined with the null rule, that is, α → ε is a production, then add ‘ε’ to First(α).
- If α is a nonterminal and is defined with non null production like X → Y1Y2…Yk is a production, then
First(X) = First(Y1Y2…Yk) = First (Y1)
if Y1⇒ ε else
First(X) = First(Y1) ∪ First (Y2...Yk)
if Y1⇒ ε
Consider the example
Example 6:
S → a A b
A → cd | ef
Find First(S) and First(A).
Solution:
First(S) = First(aAd) = First(a) = {a}
First(A) = First(cd) ∪ First(ef) =
First(c) ∪ First(e) = {c,e}
Example 7:
E → TE’
E’ → +TE’|ε
T → FT’
T’ → *FT’|ε
F → (E)|id
Find first of each nonterminal.
Solution:
Apply the first function for each nonterminal on the L.H.S. of rule.
First(E) = First(T) = First(F) = First(‘(’) ∪ First(id) = {(,id}
First(E’) = First(+) ∪ First(ε) = {+, ε}
First(T) = First(E) = {(, id}
First(T’) = First(*) ∪ First(ε) = {*, ε}
First(F) = First(E) = {(, id}
Hence, first of each nonterminal is
First(E) = {(, id}
First(E’) = {+, ε}
First(T) = {(, id}
First(T’) = {*, ε}
First(F) = {(, id}
Example 8:
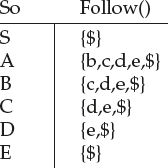
S → ACB | CbB | Ba
A → da | BC
B → g | ε
C → h | ε
Find first of each nonterminal.
First(S) = First(ACB) ∪ First(CbB) ∪ First(Ba)
First(ACB) = First(A) = {d} ∪ First(BC)
= {d} ∪ First(B) = {d} ∪ {g} ∪ First(C) ......as first(B) contains ε
= {d,g,h,ε} ….here we add ε as First(A) is ε because of ‘BC’&First(C)&First(B)
also contains ε. Hence add ε in First(ACB) at end.
First(CbB) = First(C) = First(C) is {h, ε}.so add only ‘h’ and apply First on next
symbol ‘b’ i.e First(b) = {b}. Hence
First(CbB) = {h,b}
Similarly,
First(Ba) = First(B) which is {b,ε}. Because of ε continues with a .Hence
First(Ba) = {g,a}
So First(S) = {d,g,hε,b,a,}
First(A) = {d,g,hε}
First(B) = {g,ε}
First(C) = {h,ε}

4.5.5 Follow(A) Where Ά’ is a Nonterminal
Follow (A), where A is a nonterminal, gives a set of terminals as output. This output set of terminals may appear immediately to the right of A in some sentential form. If A is the rightmost symbol in some sentential form, then $ is in Follow (A).
To compute the Follow(A) for all nonterminals A, apply the following rules until nothing can be added to any Follow set.
- If “A” is the start symbol and $ is the input right end marker, then place $ in Follow (A).
- If there is a production S→a A β where β is the string of grammar symbols, then First(β) except ε is placed in Follow(A).
- If there is production S → aA or a production A → aAβ where First (β) contains ε, then everything in Follow(S) is in Follow(A).
To find the first of nonterminal, we consider the rule that is defined for nonterminal. But for finding the follow of nonterminal, search for nonterminal on the right hand side of a rule.
If any rule contains that nonterminal, use that rule for evaluating Follow ().
Rule 2 says if there are some grammar symbols next to nonterminal A, then first of that string of grammar symbols is Follow (A).
If follow of string of grammar symbols ends with terminal set, evaluation ends here. If this first set contains an ε, then rule 2 as well as rule 3 must be applied.
Rule 3 says if there are no symbols next to nonterminal A, that is, if “A” happens to be rightmost on the right hand side, then the follow of the left hand side nonterminal, that is, “S” is follow(A).
Consider the following example to understand First and Follow functions.
Example 9:
Find the first and follow of all nonterminals in the Grammar-
E → TE’
E’ → +TE’ | ε
T → FT’
T’ → *FT’ | ε
F → (E) | id
Solution:
First(E) = {(, id}
First(E’) = {+, ε}
First(T) = {(, id}
First(T’) = {*, ε}
First(F) = {(, id}
Follow(E) = {$} by rule 1
= {)} by rule 2 on production F → (E) | id
= {$,)}
Follow(E’) = Follow(E) by rule 3 on production E → T E’
= {$,)}
Follow(T) = First(E’) by rule 2
= {+, ε}
= Follow(E) by rule 3 on production E → T E’
= {$,)}
= {+,), $}
Follow(T’) = Follow(T) by rule 3 on production T → F T’
= {+,), $}
Follow(F) = First(T’) by rule 2
= {*}
= Follow(T) by rule 3 on production T → F T’
= {+,), $}
= Follow(T’) by rule 3 on production T’ → F T’
= {+,), $}
= {+,), * , $}
Follow(E) = Follow(E’) = {),$}
Follow(T) = Follow(T’) = {+,),$}
Follow(F) = {+,*,),$}
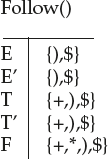
For example, by rule 3 First(E) = First(T) and First(T) = First(F); But First(F) is given by {id, (} because First(id) = (id) and First(‘(‘) = {(} by rule 1.
To compute Follow, we add $ in Follow (E) by rule 1 as E is start symbol. By rule 2 applied to production F→ (E), right parenthesis is also in Follow (E). By rule 3 applied to production E → TE’, $ and right parenthesis are in Follow (E’).
Example 10:
S → aABb
A → c | ε
B → d | ε
Find the Follow of each nonterminal.
Solution:
Follow(S) = {$} by rule 1.
Follow(A) = First(Bb) by rule 2
= {d, b} as First(B) contains e continues with b in ‘Bb’
= {d,b}
Follow(B) = {b} by rule 2
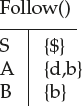
Example 11:
S → aBD h
B → c C
C → b C | ε
D → EF
E → g | ε
F → f | ε
Find Follow of each nonterminal.
Solution:
Follow(S) = {$} by rule 1.
Follow(B) = First(Dh)
First(D) = First(EF) since D → EF
First(E) = {g,ε}
since First(E) contains ε so continue with F for First(EF).
First(EF) = {g,f,ε} since this set contains ε
First(Dh) = {g,f,h}
Follow(C) = Follow(B) = {g,f,h}
Follow(D) = First(h) = {h}
Follow(E) = First(F) = {f, ε} since there is ε, apply rule 3
= {f} ∪ Follow(D) = {f,h}
Follow(F) = Follow(D) by rule 3
= {h}
Hence
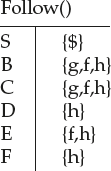
Now let us see how to make use of these two functions in constructing the parsing table.
4.6 Construction of Predictive Parsing Tables
Given a grammar to construct LL(1) parsing table, use the following procedure:
The rows in the table are given by nonterminals and columns in the table are given by terminals. For each nonterminal “A” there is a row “A” defined in the parsing table. So the number of rows is equal to the number of nonterminals. Coming to the columns, for each terminals, there a column defined in the parsing table and one extra column for $, which is the input right-end marker. So the number of columns is equal to the number of terminals +1. Construction of table mainly deals with determining the position of each rule in the table. For each rule S → a, place the rule in the row given by the left hand side nonterminal that is, S. So here without applying any procedure, we can determine in which row a rule is to be placed. The only information that needs to be determined is column information. For getting that information, we use first and follow function as follows.
For any grammar G, the following algorithm can be used to construct the predictive parsing table. The algorithm is:
Input: Grammar G
Output: Parsing table M
Method
- For each production S → a of the grammar, perform steps 2 and 3.
- For each terminal a in First (a), add S → a, to M[S,a].
- If ‘ε’ is in First (a), add S → a to M[S,b] for each terminal b in Follow(S). If ‘ε’ is in First (a) and $ is in Follow(S), add S → a to M[S,$].
The above algorithm can be applied to any grammar G to produce a parsing table M. If G is left recursive or ambiguous, then there will be at least one multiply-defined entry in the parsing table M. All undefined entries in symbol table are error entries.
4.7 LL(1) Grammar
When a predictive parsing table is constructed, if it doesn’t contain multiple entries, then such grammars are said to be LL(1) grammars. Any grammar that is LL(1), is an unambiguous grammar and does not have left recursion. Suppose the grammar has multiple-defined entries; then to convert it to LL(1), first eliminate left recursion and left factor it. This may not convert all CFGs to LL(1) as there are some grammars that will not give an LL(1) grammar after any kind of alteration. In general, there is no universal rule to convert multiple-defined entries into single-valued entries without affecting the language recognized by the parser.
Example 12:
Construct LL(1) parsing table for the following grammar.
S → a | (T)
T → T, S | S
Solution: First ensure that the grammar is free of left recursion and left factored. As there is left recursion, first eliminate left recursion.
S → a | (T)
T → S T’
T’ →, S T’ | ε
Find First and Follow sets
First(S) = {a,(}
First (T) = First(S) = {a, (}
First (T’) = {, , ε}
Follow(S) = {$}
Follow (T) = {)}
Follow (T’) = {)}
The LL(1) table is given by
Place S → a in row S and column first(a) = a
Place S → (T) in row S and column first((T)) = (
Place T → S T’ in row T and column first(S) = {a,(}
Place T’ → ,S T’ in row T’ and column first (,S T’) = {,}
Place T’ → ε in row T’ and column Follow(T/) = {)}

Example 13:
Consider the grammar
S → a B C d | d C B e
B → b B | ε
C → c a | a c | ε
- Compute the First sets and Follow sets for each of the nonterminals in the grammar.
- Construct a recursive decent parser in C for the grammar. You may assume that functions match() and error() are already available and global variable token is used to store the current token read by function match().
- Construct an LL(1) parsing table for the grammar.
Solution: a. FIRST(S) = {a, d}, FIRST(B) = {b, ε}, FIRST(C) = {a, c, ε}. FOLLOW(S) = {$}, FOLLOW(B) = {a, c, d, e}, FOLLOW(C) = {b, d, e}.
b.
void S () {
switch(token) {
case a: match(a); B(); C(); match(d); break;
case d: match(d); C(); B(); match(e); break;
default: error();
}
}
void B() {
switch(token) {
case b: match(b); B(); break;
case a: case c: case d: case e: break;
default: error ();
}
}
void C() {
switch(token) {
case c: match(c); match(a); break;
case a: match(a); match(c); break;
case b: case d: case e: break;
default: error();
}
}
c. The parsing table is as follows:

Example 14:
Construct LL(1) parsing table.
E → TE’
E’ → +TE’ | ε
T → FT’
T’ → *F T’ | ε
F → (E) | id
Solution: We have discussed first and follow sets for this grammar in Sections 4.5.4 and 4.5.5.
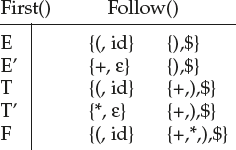
To construct LL(1) table, there has to be five rows since there are five nonterminals.
In the row E, place E → TE’ in the column given by First(TE’) = {(, id}
In the row E’, place E’ → +TE’ in the column given by First(+TE’) = {+}
In the row E’, place E’ → ε in the column given by Follow(E’) = {),$}
In the row T, place T → FT’ in the column given by First (FT’) = {(, id}
In the row T’, place T’ → *F T’ in the column given by First (*F T’) = {*}
In the row T’, place T’ → ε in the column given by Follow(T’) = {+,),$}
In the row F, place F → (E) in the column given by First ((E)) = {(}
In the row F, place F → id in the column given by First (id) = {id}
LL(1) Table for the above grammar is:

Check whether the following grammar is LL(1) or not.
S → aSbS | bSaS | ε
Solution: First construct the LL(1) table, then check for multiple entries.
To construct LL(1) table, there has to be only one row since there is only one nonterminal.
In the row S, place S → aSbS in the column given by First(aSbS) = {a}
In the row S, place S → bSaS in the column given by First (bSaS) = {b}
In the row S, place S → ε in the column given by Follow(S) = {a,b,$}
So table is

As there are multiple entries in table at a and b, the grammar is not LL(1). In fact the grammar is ambiguous grammar; hence, is not LL(1).
Example 16:
Check whether the following grammar is LL(1) or not.
S → AaAb | BbBa
A → ε
B → ε
Solution: First construct the LL (1) table, then check for multiple entries.
To construct LL (1) table, there are three rows as there are three nonterminals.
In the row S, place S → AaAb in the column given by First(AaAb) = {a} and place
S → BbBa in column given by First (BbBa) = {b}.
In the row A, place A → ε in the column given by Follow (A) = {a,b}
In the row B, place B → ε in the column given by Follow (B) = {b,a}
So the table is

As there are no multiple entries in table, the grammar is LL(1).
This method is an efficient one and eliminates backtracking but it has some limitations like
- Framing an unambiguous grammar for all possible constructs in the source language.
- Left recursion elimination and left factoring are simple to apply but they make the resulting grammar complex.
It is always better to use a predictive parser for control structures and use operator precedence for expression. However, if an LR parser generator is available, it is better choice as it would provide the benefits of predictive parsing and operator precedence automatically.
An LL(1) grammar indicates that grammar is suitable for LL(1) parser construction, that is, if LL(1) table is constructed there will not be any multiple entries. So there is no confusion for the parser. But given a grammar to check whether the grammar is LL(1) or not do we have to construct the complete table?
No not required. Without constructing the table also we can check the possibility of multiple entries as follows.
If every nonterminal in grammar is defined with one rule then there is no problem of multiple entries because the rule is one, in worst case placed under every column. But the possibility of multiple entry exists if each nonterminal is defined with more than one rule like A → a1 | a2 as both rules are to be placed in the same row A. So this can be stated as a rule as follows.
Rule 1:
A grammar without ε rules is LL(1) if for each production of the form
A → α1 | α2 | α3 | α4............ |αn, First(α1), First(α2), First(α3), First(α4),..are pair-wise mutually disjoint.
i.e. First(αi) ∩ First(αk) = Ø for i ≠ k
Rule 2:
A grammar with ε rules is LL(1) if for each production of the form
A → α | ε, First(α) and Follow(A) must be mutually disjoint.
i.e. First(α) ∩ Follow(A) = Ø
Let us look at why left recursion is not preferred by LL(1) parsers.
For example, let us check A → Aα | β is LL(1). Assume α, β to be terminals.
If it is LL (1), condition to be satisfied is First(Aα) First (β) = Ø
But First (Aα) contains β. So this condition can never be true.
Grammar is not LL(1). This can be generalized.
Rule 3:
Left recursive grammar cannot be LL(1).
Example 17:
Check whether the following grammar is LL(1) or not.
S → A | a, A → a
Solution: If this is LL(1), condition to be satisfied is, First(A) ∩ First (a) = Ø.
But First(A) = {a} so condition is not satisfied. In fact, the given grammar is ambiguous grammar. For string “a,” we get two parse trees. If grammar is ambiguous, condition will not be satisfied.
Rule 4:
Ambiguous grammar cannot be LL(1).
Check whether the following grammar is LL(1) or not.
S → A#; A → Bb | Cd; B → aB | ε; C → cC | ε
Solution:
As “S” is defined with one rule, there is no danger of multiple entries in row S.
For row A, First(Bb) ∩ First(Cd) = Ø
{a,b} ∩ {c,d} = Ø Condition satisfied so no problem.
For row B, First(aB) ∩ Follow(B) = Ø
{a} ∩ {b} = Ø Condition satisfied so no problem.
For row C, First(cC) ∩ Follow(C) = Ø
{c} ∩ {d} = Ø Condition satisfied so no problem.
Since condition is satisfied in each row, there are no multiple entries. Hence, grammar is LL(1).
Example 19:
Check whether the following grammar is LL(1) or not.
S → aSA | ∊
A → c | ∊
Solution: For row S condition to be satisfied is First(aSA) ∩ Follow(S) = Ø
i.e. {a} ∩ {$,First(A)} = Ø
{a} ∩ {$,c} = Ø … satisfied.
For row A condition to be satisfied is First(c) ∩ Follow(A) ≠ Ø
i.e. {c} ∩ {Follow(S)} = Ø
{c} ∩ {$,c} ≠ Ø … is not satisfied.
A grammar in which every alternative production for a rule starts with a different terminal is called simple grammar or S-Grammar. S-Grammar is suitable for LL(1).
For example,
S → aA | bB | cC A → dD | eE → B → fF | gG C → hH | kK is a S-grammar.
4.8 Error Recovery in Predictive Parsing
An error is detected during predictive parsing in two ways. One is when the terminal on top of the stack does not match with the next input symbol. Second is when nonterminal A is on top of the stack, “a” is the next input symbol, and the parsing table entry M[A,a] is empty. There are various techniques that can be applied when such an error occurs. One simple method that is discussed is panic mode error recovery.
Panic Mode Error Recovery
In this technique, either skip symbols on the input or ignore the top symbol from the stack until a synchronizing set of tokens appear on both input and stack top. The set should be chosen so that the parser recovers quickly from errors that are likely to occur in practice. The following are some heuristics that can be applied.
- We can place all the symbols in Follow(A) into the synchronizing set for nonterminal A. If an error occurs, then skip the tokens until an element of Follow(A) is seen; then pop the top element from the stack to continue the parsing.
- Sometimes it may not be sufficient to add the Follow(A) as the synchronizing set for A. For example, if “;” terminate statements, as in C, then keywords that begin statements may not appear in the Follow set of the nonterminal generating expressions. A missing semicolon after an assignment may therefore result in the keyword beginning the next statement being discarded. In general, any programming language specifies the hierarchical structure on constructs; where expressions appear within statements, statements appear within blocks and so on. We can add the symbols that begin the higher constructs to the synchronizing set of a lower construct; Where expressions may occur within statements, statements may occur within blocks and so on. We can add to the synchronizing set of a lower construct symbols that begin the higher constructs.
- Parsing can be resumed if symbols of First(A) are added to synchronizing set for A based on A is a symbol in First(A) appears in the input.
- If an empty string can be derived from a nonterminal, then use this as the default option. By using this option, the error may be missed or may be postponed to some other point. This approach reduces the number of nonterminals that have to be considered during error recovery.
- If the terminal on top of the stack cannot be matched, a simple solution is to pop the terminal and issue a message saying extra terminal and continue parsing.
Let us take an example.
Example 20:
Consider error recovery with input string “+id*+id$”.
To parse this we need LL(1) table for arithmetic expressions given by grammar
E → TE’
E’ → +TE’|e
T → FT’
T’ → *FT’|e
F → (E)|id
Solution:
Take the LL(1) table constructed in Example 13.
Let us use the above heuristics in a simple way with parsing algorithm as follows:
- Add “synch” (as synchronizing set of symbol) to Follow (E) except for those whose first(E) has ε.
- When parser looks up entry in table M, if entry is blank then input symbol is skipped.
- If entry is synch, then the terminal on top of the stack is popped.
- If terminal on top of the stack does not match, pop the stack.


Figure 4.10 Sequence of moves by LL(1) Parser while parsing “+ id * + id”
Synch is added in Follow (E), Follow(T) and Follow(F) as first of this nonterminals do not have ε.
With input string “+ id * + id,” LL(1) parser makes sequence of moves shown in Figure 4.10. Initially input pointer points to the leftmost symbol.
Solved Problems
- Find first () and follow () for each terminal.
S → ABCDE; A → a | ε; B → b | ε: C → c | ε; D → d | ε; E → e | ε
Solution: First(S) = First(ABCDE) = First(A) = {a,ε}
Since first(A) has ε, First(ABCDE) = {a} ∪ First(BCDE)
First(BCDE) = First(B) = {b,ε}
Since first(B) has ε, First(ABCDE) = {a,b} ∪ First(CDE)
First(CDE) = First(C) = {c,ε}
Since first(C) has ε, First(ABCDE) = {a,b,c} ∪ First(DE)
First(DE) = First(D) = {d,ε}
Since first(D) has ε, First(ABCDE) = {a,b,c,d} ∪ First(E)
First(E) = {e,ε}
Since first(E) has ε First(ABCDE) = {a,b,c,d,e,ε}

Follow(S) = {$} by rule 1.
Follow(A) = First(BCDE) by rule 2
= {b,c,d,e,ε}.
As First set contains ε, apply rule 3 also. Add all symbols excepts to ε Follow(A).
So Follow(A) = {b,c,d,e} u Follow(S) = {b,c,d,e,$}
Follow(B) = First(CDE) by rule 2
= {c,d,e,ε}.
As First set contains ε, apply rule 3 also. Add all symbols except ε to Follow(B).
So Follow(B) = {c,d,e} ∪ Follow(S) = {c,d,e,$}
Follow(C) = First(DE) by rule 2
= {d,e,ε}.
As First set contains ε, apply rule 3 also. Add all symbols except ε to Follow(C).
So Follow(C) = {d,e} ∪ Follow(S) = {d,e,$}
Follow(D) = First(E) by rule 2
= {e,ε}.
As First set contains ε, apply rule 3 also. Add all symbols excepts ε to Follow(D).
So Follow(D) = {e} ∪ Follow(S) = {e,$}
Follow(E) = Follow(S) = {$]
- *Compute First and Follow for each nonterminal and LL(1) table.
E → a A | (E)
A → + E | * E | ε
Solution: First (E) = {a, (}
First(A) = {+, *,ε}
Follow(E) = {$,)} by rule 1 & rule 2.
Follow(A) = Follow(E) = {$,)}
To construct LL(1) table, rows are two as there are two nonterminals.
In the row E, place E → a A in the column given by First(aA) = {a}
In the row E, place E → (E) in the column given by First((E)) = {(}
In the row A, place A → + E in the column given by First(+ E) = {+}
In the row A, place A → * E in the column given by First(* E) = {*}
In the row A, place A → ε in the column given by Follow(A) = {),$}
Now LL(1) table is

- *Build an LL(1) parser for the following grammar
- Program → begin d semi X end
- X → d semi X | S Y
- Y → semi S Y | ε
Solution: Place rule(1) in row ‘Program’ and column First(begin) = begin
Place rule(2) in row ‘X’ and column First(d) = d
Place rule(3) in row ‘Y’ and column First(semi) = semi
In parsing table let us place production numbers.

- Construct LL(1) parsing table.
S → qABC
A → a | bbD
B → a | ε
C → b | ε
D → c | ε
Solution: First find first and follow sets of each nonterminal.

The LL(1) table is

As there are no multiple entries, the grammar is LL(1);
- Construct LL(1) parsing table.
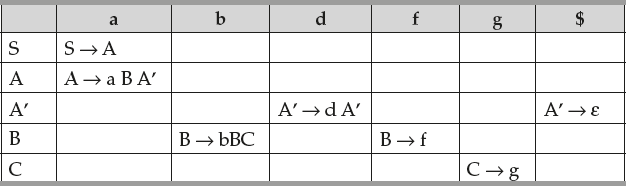
S → A, A → a B | Ad, B → bBC | f, C → g.
Solution: The given grammar is left recursive. So first eliminate left recursion. The resulting grammar is as follows:
S → A, A → a B A’, A’ → d A’ | ε, B → bBC | f, C → g.
Now find first and follow functions.

The LL(1) table is
- Check whether the following grammar is LL(1) or not. If it is not LL(1) where do you find multiple entries in parsing table?
S → AB | C, A → Bb | Cd, B → aB, C → ad
Solution: For grammar to be LL(1)
For row S, condition to be satisfied is ---- First(AB) ∩ First(C) = Ø
{a}∩ {a} ≠ Ø ..condition is not satisfied
The multiple entries would be S → AB, S → C.
For row A, condition to be satisfied is ---- First(Bb) ∩ First(Cd) = Ø
{a} ∩ {a} ≠ Ø condition is not satisfied. Hence grammar is not LL(1). We get multiple entries in the row A under the column “a”;
The multiple entries would be A → Bb, A → Cd.
Anyway nonterminal C is defined with one rule. Hence, no multiple entries in row C.
- Consider the grammar
S → a B C d | d C B e
B → b B | ε
C → c a | a c | ε
- What are the terminals, nonterminals, and the start symbol for the grammar?
- Give the parse tree for the input string abbcad.
- Compute the First sets and Follow sets for each of the nonterminals in the grammar.
Solution:
- terminals: {a, b, c, d, e}, nonterminals: {S, B, C}, start symbol: S.
-
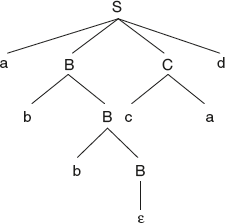
- FIRST(S) = {a, d}, FIRST(B) = {b, ε}, FIRST(C) = {a, c, ε}.
FOLLOW(S) = {$}, FOLLOW(B) = {a, c, d, e}, FOLLOW(C) = {b, d, e}.
- Construct a recursive decent parser in C for the grammar in problem 7.
Solution: Assume that functions match() and error() are already available and the global variable token is used to store the current token read by function match().
void S() {
switch (token) {
case a: match(a); B(); C(); match(d); break;
case d: match(d); C(); B(); match(e); break;
default: error ();
}
}
void C() {
switch(token) {
case c: match(c); match(a); break;
case a: match(a); match(c); break;
case b: case d: case e: break;
default: error ();
}
}
- Construct an LL(1) parsing table for the grammar in problem 7.
Solution:

- Consider the following grammar:
S → ScB | B
B → e | efg | efCg
C → SdC | S
Give an LL(1) grammar that generates the same lanuage.
First, eliminate left-recrsion:
S → BS’
S’→ cBS | ε
B → e | efg | efCg
C → SdC | S
Then, eliminate common prefixes by left-recrsion:
S → BS’
S’ → cBS’ | ε
B → eB’
B’ → ε | f B”
B” → g | C g
C → SC’
C’ → dC | ε

Summary
- The process of verifying whether an input string matches the grammar of the language is called parsing.
- The output of a parser is a parse tree for the set of tokens produced by the lexical analyzer.
- Parsers are broadly classified into two categories—Top-down parser or bottom-up parser based on the way the parse tree is constructed.
- Top-down parsers are simple to construct.
- Top-down parsing involves generating the string starting from the start symbol repeatedly applying production rules for each nonterminal until we get a set of terminals.
- Top-down parsers are broadly classified into two categories based on the design methodology used, with full backtracking and without backtracking. With full backtracking, we have Brute Force Technique.
- Brute Force Technique is not preferred practically because it is very slow.
- A predictive parser tries to predict which production produces the least chances of a backtracking and infinite looping.
- The advantage of eliminating left recursion is it avoids parser going into infinite loop.
- The advantage of left factoring is it avoids backtracking.
- Recursive descent parsing is writing recursive procedures for each nonterminal.
- Out of all top-down parsers the most widely used parser is nonrecursive descent parser, which is also called LL(1) parser. This does not use any procedures but uses a table and a stack.
- First (α) gives the set of terminals that begin the strings derived from α.
- Follow (A), for nonterminals A, gives a set of terminals that can appear immediately to the right of A in some sentential form.
- A grammar whose parsing table has no multiply defined entries is said to be LL(1) grammar.
Fill in the Blanks
- In LL(1), First L indicates _____.
- In LL(1), Second L indicates ______.
- In LL(1), “1” indicates _____.
- The requirements for LL(1) parser is _____.
- Is LL(1) parser a top-down parser or bottom-up parser? _____
- Can every unambiguous grammar be parsed by LL(1)? Yes/No
- The number of procedures to be defined in recursive descent parser is _____.
- The advantage of eliminating left recursion is _____.
- The advantage of left factoring is _____.
- For A → A α | β, equivalent grammar without left recursion is _____.
- Left factor the grammar A → α β1 | α β2 | α β3
- Is every LL(1) unambiguous? Yes/No._____
- Is left factoring compulsory in designing recursive descent parser? Yes/No_____
- _____ is the advantage of recursive descent parser.
- _____ is the disadvantage of recursive descent parser.
- Are the procedures in recursive descent parser recursive or nonrecursive?_____
- Can we design a recursive descent parser with ambiguous grammar? Yes/No
Objective Question Bank
- *The Grammar A → AA|(A) | ε is not suitable for predictive parsing because, the grammar is
- ambiguous
- left recursive
- right recursive
- None
- *Which of the following derivation does a top-down parser use while parsing an input string? The input is assumed to be in LR order.
- LMD
- Leftmost traced out in reverse
- RMD
- Rightmost traced out in reverse
- *Consider the grammar shown below
S’ → eS | ε
E → b
In LL(1) table M of this grammar, the entries M[S’,e] and M[S’, $] are
- S’ → eS & S’ → ε
- S’ → eS & {}
- S’ → ε & S’ → ε
- {S’ → eS & S’ → ε} & S’ → ε
- *Consider the grammar shown below
S → FR, R → *S | ε, F → id
In LL (1) table M of this grammar, the entries M[S, id] and M[R, $] are
- S → FR, R → ε
- S → FR & {}
- S → FR & R → *S
- F → id, R → ε
- * Which of the following suffices to convert an arbitrary CFG to an LL(1) Grammar?
- Removing left recursion alone
- Factoring grammar alone
- Removing left recursion and factoring the grammar
- None
- Consider the following grammar over the alphabet {b, g, h, i}:
A → B C D
B →b B | ε
C → C g | g | C h | i
D → A B | ε
Find follow(C)
- {$,g,b,i}
- {$,g,b}
- {$,g,b,i,h}
- None
- Consider the following grammar:
S → ScB | B
B → e | efg | efCg
C →SdC | S
Give an LL(1) grammar that generates the same language.
- S → B S’
S’ → c B S’ | ε
B → e B’
B’ → ε | f B”
B” → g | C g
C → S C’
C’ → d C | ε
- S → B S’
S’ → c B S’ | ε
B → e B’
B’ → ε | f B”
B” → g | C g
C → S C’
- S → B S’
S’ → c B S’| ε
B → e B”
B’ → ε | f B”
B” → g | C g
C → d C | ε
- none
- S → B S’
- The following grammar is
A → A x B
| x
B → x B
| x
- unambiguous
- left recursive
- right recursive
- ambiguous
- Eliminate left recursion from the following grammar:
A → Bd
| Aff
| CB
B → Bd
| Bf
| df
C → h
| g
- A → Bd AI | CB AI
A1 → ff AI | ε
B → df BI
B1 → d BI | fBI | ε
C → h
| g
- A → Bd AI | CB AI
A → ff AI | ε
B → df BI
BI → d BI | fBI | ε
C → h
| g
- A → Bd AI | CB AI
AI → ff AI
B → df BI
BI → d BI | fBI
C → h
| g
- A → Bd AI | CB
AI → ff AI | ε
B → df BI
BI → d BI | fB I | ε
C → h
| g
- A → Bd AI | CB AI
- Give the Follow set for the nonterminal E in the grammar.
EI → E
E → num
E → (+A)
A → AA
A → E
- {num, (,)}
- {(,) , num, $}
- {(, num, $}
- {), num, $}
- Give the Follow of B in the following grammar:
A → B C D
B → w
| B x
C → y C z
| m
D → D B
| a
Exercises
- Construct a recursive descent parser to parse the string “w” for the given grammar “G”
- w = id*id+id & grammar is E → E + T | T T → T * F | F F → id | (E)
- w = id + id*id & grammar is E → E + T | T T → T F | F F → F * | a | b
- w = bdc & grammar is S → Aa | bAc | dc | bda A → d
- Eliminate left recursion in the following grammar.
S → aAb; S → Ac | Sd | ε
- Eliminate left recursion in G.
S → aAcBe; A → Ab | b; B → d
- Eliminate left recursion in G.
S → L; L | L; L → LB | Β; B → 0 | 1
- Eliminate left recursion in
A → b | Bd; B → Bc | Ac
- Left factor the grammar
S → iE tS | a | iE SeS. E → b
- Left factor the grammar
S → aAd | aB
A → b | c; B → ccd | ddc
- Consider the following grammar, compute first () and follow () for each terminal. Check whether the grammar is LL (1).
S → ACB | CbB | Ba;
A → da | BC;
B → g | e;
C → h | ε
- Consider the following grammar, computer first () and follow () for each terminal. Check whether the grammar is LL (1).
S → ABCDE; A → a | ε; B → b | ε; C → c | ε; D → d | ε; E → e | ε
- Construct LL(1) parsing table and verify whether it is LL (1).
S → ABDh
B → cC
C → bC | ε
D → EF
E → g | e
F → f | ε
- Construct LL(1) parsing table and verify whether it is LL (1).
S → AaAb | BaBb is it LL (1)
A → ε, B → ε
- Construct LL (1) parsing table and verify whether it is LL (1).
S → a AB | ε
A → 1AC | 0C
B → 0S
C → 1
- Construct an LL(1) parser to parse the string “w” for the given grammar “G.”
id+ id*id & grammar is E → E + T | T T → T F | F F → F * | a | b
- Check whether the following grammar is LL (1).
S → A, A → a B | Ad, B → bBC | f, C → g.
- Check whether the following grammar is LL (1).
S → a SbS | bSaS | ε
- Convert the following grammar to unambiguous grammar. Check whether the resulting grammar is LL (1).
R → R + R | RR | R * | (R) | a | b
- Check whether the following grammar is LL (1).
bExpr → bExpr or bterm | bterm
bterm → bterm and bfactor | bfactor
bfactor → not bfactor | (bexpr) true | false.
- Check whether the above grammar is LL (1).
S → A | a, A → a
- Check whether the following grammar is LL (1).
S → iE tS S1 | a
S1 → ε | eS
E → b
- Check whether the following grammar is LL (1).
E → aA | (E)
A → +E | *E | ε
- Check whether the following grammar is LL (1).
S1 → S#
S → Aa | b | cB | d
A → a A | b
B → cB | d
- Check whether the following grammar is LL (1).
S1 → S#
S → AB
A → a | ε
B → b | ε
- Check whether the following grammar S-Grammar is LL (1).
S → aS | bA;
A → ccA | d
- Check whether the following grammar is LL (1).
S → aB | ε
B → bC | ε
C → cS | ε
- Check whether the following grammar is LL (1).
S1 → S#
S → aAa | ε
A → abS | c
- Check whether the following grammar is LL (1).
S1 → A#
A → Bb | Cd
B → aB | ε
C → cC | ε
- Construct the LL (1) parsing table for following grammar.
Program → begin d semi X end
X → d semi X | s Y
Y → semi s Y | ε
Key for Fill in the Blanks
- scanning of input from left to right
- parser uses LMD in deriving the string
- number of look ahead symbols used in taking the parsing decisions.
- Grammar should be free of left recursion and should be left factored.
- Top-down parser
- No
- Generally depends on number of nonterminals. For every nonterminal there should be a procedure.
- Avoids parser going into infinite loop
- Avoids backtracking
- A → βA′, A′ → αA′ | ε
- A → a A′, A′ → β 1 | β 2 | β 3
- Yes
- No
- Simple to construct
- Can be designed for small languages
- It depends on the production that is defined for the nonterminal. If production is recursive then procedure also will be recursive.
- No
Key for Objective Question Bank
- a
- a
- d
- a
- c
- c
- a
- d
- a
- b
- d
Programming on Parsers
Parsers Code:
- Write a C program for recursive descent parser for following grammar.
E → T E’
E’ → + TE’ | ε
T → FT’
T’ → *FT’ | ε
F → i
/* Recursive descent parser in C*/
/* match()- is to match terminal derived from grammar with lookahead */
#include<stdio.h>
#include<conio.h>
void E();
void E’();
void T();
void T’();
void F();
void match(char);
int flag = 1;
char l,t;
main()
{
Printf(“enter input string ”);
scanf(“%c”,&l);
E();
}
/* Procedure for matching terminal with token */
void match(char t)
{
if(l == t)
scanf(“%c”,&l);
else
{
flag = 0;
}
/* Procedure for nonterminal E */
void E()
{
T();
E’ ();
if((l == ’$’)&&(flag ! = 0))
printf(“successful ”);
else
printf(“unsuccessful ”);
}
/* Procedure for nonterminal E’ */
void E’ ()
{
if(l == ’+’)
{match(‘+’);
T();
E’();
}
else return;
}
/* Procedure for nonterminal T */
void T()
{
F();
T’ ();
}
/* Procedure for nonterminal T’ */
void T’ ()
{
if(l == ’*’)
{match(‘*’);
F();
T’ ();
}
}
/* Procedure for nonterminal F */
void F()
{
match(‘i’);
}
output:
Enter the input string:
i+i*i$
successful
i**i$
unsuccessful.
- Design LL(1) parser
Program logic- Read LL(1) table and input string to be parsed.
- Read terminals in array ‘ter’. This is used as columns of LL(1) table.
- Read non terminals in array ‘nter’ This is used as rows of LL(1) table.
- Now read table in two dimensional array of strings ‘table’.
- Use LL(1) parsing algorithm to parse the input string.
- Whenever top of the stack is a nonterminal, to replace that by corresponding production—use two functions get_nt(), get_t() to get row and column in table.
- Take the production from that row and column, reverse it and push symbol by symbol.
Coding:
/* LL(1) parser in C */
#include<stdio.h>
#include<ctype.h>
#include<string.h>
char table[10][10][10], nter[10],ter[10],inp[20],stack[20];
int nut,nun,i = 0,top = 0;
int get_nter(char);
int get_ter(char);void main()
{int i,j;
clrscr();
/* read terminals and nonterminals */
printf(“Enter number of terminals ”);
scanf(“%d”,&nut);
printf(“Enter number of nonterminals ”);
scanf(“%d”,&nun);
printf(“Enter all non terminals ”);
scanf(“%s”,nter);
printf(“Enter all terminals ”);
scanf(“%s”,ter);
for(i = 0;i<nut;i++) printf(“%c ”,nter[i]);
printf(” ”);
for(j = 0;j<nun;j++) printf(”%c ”,t[j]);
printf(“ ”);
/* read table */
for(i = 0;i<nun;i++)
for(j = 0; j<nut;j++)
{
printf(“Enter for %c and %c”,nter[i],ter[j]);
scanf(”%s”,table[i][j]);
}
/ * print table */
for(j = 0;j<nut;j++)
printf(“ %c”,ter[j]);
printf(“ ”);
for(i = 0;i<nun;i++)
{
printf(“%c ”,nter[i]);
for(j = 0;j<nut;j++)
{
printf(”%s ”,table[i][j]);
}
printf(” ”);
}
/* read input string to parse */
printf(“Enter the string to parse ”);
scanf(“%s”,inp);
/* use LL(1) algoritm */
stack[top++] = ’$’;
stack[top++] = nter[0];
i = 0;
while(1)
{
if((stack[top-1] == ’$’)&&(inp[i] == ’$’))
{
printf(“String accepted ”);
return;
}
else if(!isupper(stack[top-1]))
{
if(stack[top-1] == inp[i])
{
i++; top--;
}
else
{
printf(“error not accepted ”);
return;
}
}
else
{
replace(stack[top-1],inp[i]);
}
}
}
/* get index of nonterminals in nonterminals array */
int get_nter(char x)
{
int a;
for(a = 0;a<nun;a++)
if(x == nter[a]) return a;
return 100;
}
/* get index of terminal in terminal array */
int get_ter(char x)
{
int a;
for(a = 0;a<nut;a++)
if(x == ter[a]) return a;
}
void replace(char NT, char T)
{
int in1,it1,len;
char str[10];
in1 = get_nter(NT);
it1 = get_ter(T);
if((in1! = 100)&&(it1! = 100))
{
strcpy(str,table[in1][it1]);
if(strcmp(str,”#”) == 0)
{
printf(“Error ”);
exit();
}
if(strcmp(str,”@”) == 0)
top--;
else
{
top--;
len = strlen(str);
len--;
do
{
stack[top++] = str[len--];
}while(len> = 0);
}
}
else
{
printf(”Not valid ”);
}
}
INPUT:
Enter number of terminals: 6
Enter number of non terminals: 5
Enter all non terminals: E E’ T T’ F
Enter all terminals: id + * () $
Enter table- # for blank, @ for ε:
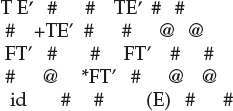
Enter the string to parse
id+id*id$
output:
String accepted