
Chapter 16. Writing Extensions for gawk
It is possible to add new functions written in C or C++ to gawk using dynamically loaded libraries. This facility is available on systems that support the C
dlopen() and dlsym() functions. This chapter describes how to create extensions using code
written in C or C++.
If you don’t know anything about C programming, you can safely skip
this chapter, although you may wish to review the documentation on the
extensions that come with gawk (see The Sample Extensions in the gawk Distribution) and the information on the gawkextlib project (see The gawkextlib Project). The sample
extensions are automatically built and installed when gawk is.
Note
When --sandbox is specified, extensions are
disabled (see Command-Line Options).
Introduction
An extension (sometimes called a
plug-in) is a piece of external compiled code that gawk
can load at runtime to provide additional functionality, over and above
the built-in capabilities described in the rest of this book.
Extensions are useful because they allow you (of course) to extend
gawk’s functionality. For example, they
can provide access to system calls (such as chdir() to change directory) and to other C
library routines that could be of use. As with most software, “the sky is
the limit”; if you can imagine something that you might want to do and can
write in C or C++, you can write an extension to do it!
Extensions are written in C or C++, using the application
programming interface (API) defined for this purpose by the
gawk developers. The rest of this chapter explains the facilities that the
API provides and how to use them, and presents a small example extension.
In addition, it documents the sample extensions included in the gawk distribution and describes the gawkextlib project. See http://www.gnu.org/software/gawk/manual/html_node/Extension-Design.html
for a discussion of the extension mechanism goals and design.
Extension Licensing
Every dynamic extension must be distributed under a license that is compatible with the GNU GPL (see Appendix C).
In order for the extension to tell gawk that it is properly licensed, the extension
must define the global symbol plugin_is_GPL_compatible. If this symbol does
not exist, gawk emits a fatal error and
exits when it tries to load your extension.
The declared type of the symbol should be int. It does not need to be in any allocated
section, though. The code merely asserts that the symbol exists in the
global scope. Something like this is enough:
int plugin_is_GPL_compatible;
How It Works at a High Level
Communication between gawk and an
extension is two-way. First, when an extension is loaded, gawk passes it a pointer to a struct whose fields are function pointers. This
is shown in Figure 16-1.
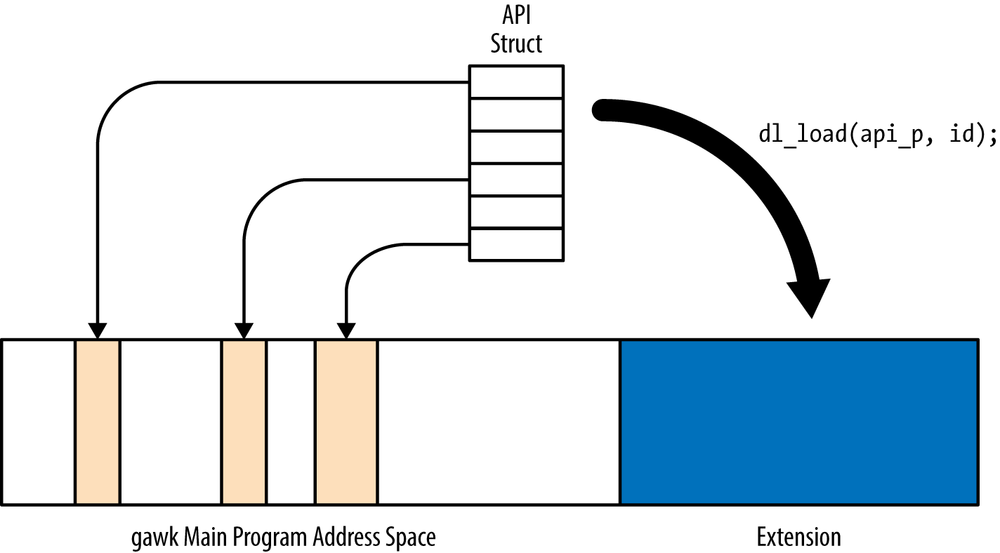
The extension can call functions inside gawk through these function pointers, at
runtime, without needing (link-time) access to gawk’s symbols. One of these function pointers
is to a function for “registering” new functions. This is shown in Figure 16-2.
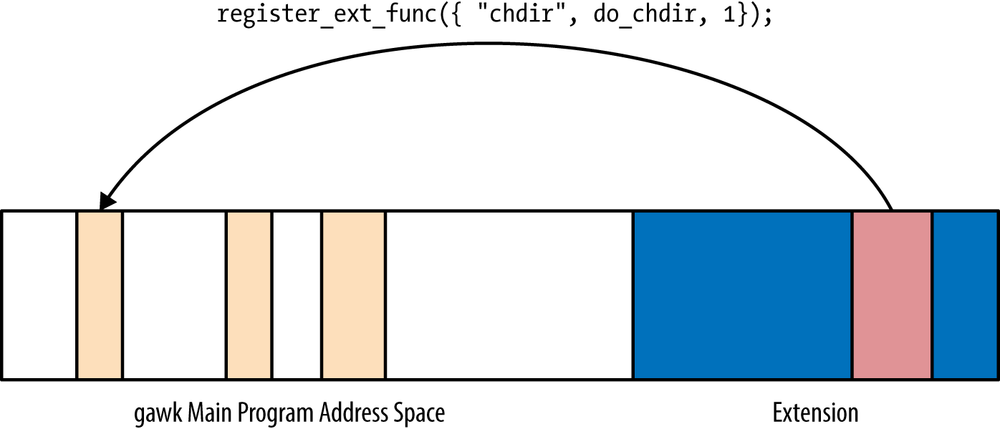
In the other direction, the extension registers its new functions
with gawk by passing function pointers
to the functions that provide the new feature (do_chdir(), for example). gawk associates the function pointer with a name
and can then call it, using a defined calling convention. This is shown in
Figure 16-3.
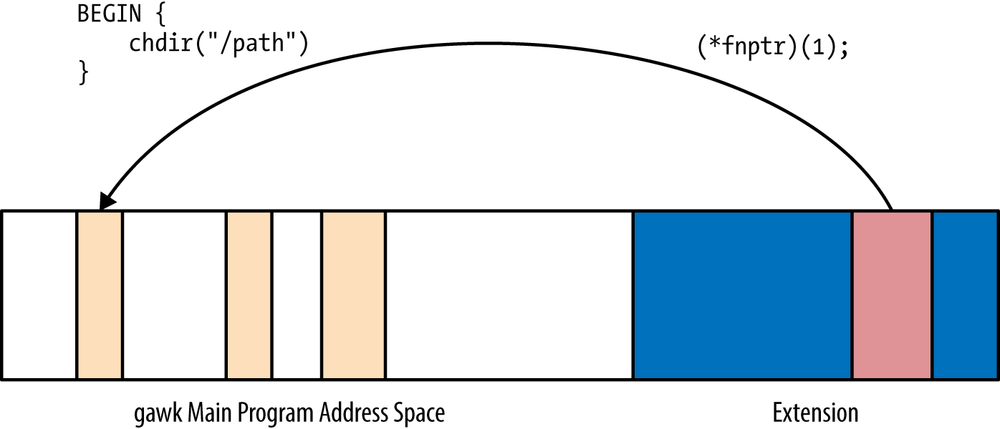
The do_ function, in
turn, then uses the function pointers in the API xxx()struct to do its work, such as updating
variables or arrays, printing messages, setting ERRNO, and so on.
Convenience macros make calling through the function pointers look like regular function calls so that extension code is quite readable and understandable.
Although all of this sounds somewhat complicated, the result is that
extension code is quite straightforward to write and to read. You can see
this in the sample extension filefuncs.c (see Example: Some File Functions) and also in the testext.c code for
testing the APIs.
Some other bits and pieces:
The API provides access to
gawk’sdo_values, reflecting command-line options, likexxxdo_lint,do_profiling, and so on (see API Variables). These are informational: an extension cannot affect their values insidegawk. In addition, attempting to assign to them produces a compile-time error.The API also provides major and minor version numbers, so that an extension can check if the
gawkit is loaded with supports the facilities it was compiled with. (Version mismatches “shouldn’t” happen, but we all know how that goes.) See API version constants and variables for details.
API Description
C or C++ code for an extension must include the header file
gawkapi.h, which declares the functions and defines the data types used to
communicate with gawk. This (rather
large) section describes the API in detail.
Introduction
Access to facilities within gawk is achieved by calling through function pointers passed into your
extension.
API function pointers are provided for the following kinds of operations:
Allocating, reallocating, and releasing memory.
Registration functions. You may register:
Extension functions
Exit callbacks
A version string
Input parsers
Output wrappers
Two-way processors
All of these are discussed in detail later in this chapter.
Printing fatal, warning, and “lint” warning messages.
Updating
ERRNO, or unsetting it.Accessing parameters, including converting an undefined parameter into an array.
Symbol table access: retrieving a global variable, creating one, or changing one.
Creating and releasing cached values; this provides an efficient way to use values for multiple variables and can be a big performance win.
Manipulating arrays:
Retrieving, adding, deleting, and modifying elements
Getting the count of elements in an array
Creating a new array
Clearing an array
Flattening an array for easy C-style looping over all its indices and elements
Some points about using the API:
The following types, macros, and/or functions are referenced in
gawkapi.h. For correct use, you must therefore include the corresponding standard header file before includinggawkapi.h:C entity
Header file
EOF<stdio.h>Values for
errno<errno.h>FILE<stdio.h>NULL<stddef.h>memcpy()<string.h>memset()<string.h>size_t<sys/types.h>struct stat<sys/stat.h>Due to portability concerns, especially to systems that are not fully standards-compliant, it is your responsibility to include the correct files in the correct way. This requirement is necessary in order to keep
gawkapi.hclean, instead of becoming a portability hodge-podge as can be seen in some parts of thegawksource code.The
gawkapi.hfile may be included more than once without ill effect. Doing so, however, is poor coding practice.Although the API only uses ISO C 90 features, there is an exception; the “constructor” functions use the
inlinekeyword. If your compiler does not support this keyword, you should either place ‘-Dinline=''’ on your command line or use the GNU Autotools and include aconfig.hfile in your extensions.All pointers filled in by
gawkpoint to memory managed bygawkand should be treated by the extension as read-only. Memory for all strings passed intogawkfrom the extension must come from calling one ofgawk_malloc(),gawk_calloc(), orgawk_realloc(), and is managed bygawkfrom then on.The API defines several simple
structs that map values as seen fromawk. A value can be adouble, a string, or an array (as in multidimensional arrays, or when creating a new array). String values maintain both pointer and length, because embedded NUL characters are allowed.Note
By intent, strings are maintained using the current multibyte encoding (as defined by
LC_environment variables) and not using wide characters. This matches howxxxgawkstores strings internally and also how characters are likely to be input into and output from files.When retrieving a value (such as a parameter or that of a global variable or array element), the extension requests a specific type (number, string, scalar, value cookie, array, or “undefined”). When the request is “undefined,” the returned value will have the real underlying type.
However, if the request and actual type don’t match, the access function returns “false” and fills in the type of the actual value that is there, so that the extension can, e.g., print an error message (such as “scalar passed where array expected”).
You may call the API functions by using the function pointers
directly, but the interface is not so pretty. To make extension code
look more like regular code, the gawkapi.h header file defines several macros
that you should use in your code. This section presents the macros as if they were
functions.
General-Purpose Data Types
I have a true love/hate relationship with unions.
—Arnold Robbins
That’s the thing about unions: the compiler will arrange things so they can accommodate both love and hate.
—Chet Ramey
The extension API defines a number of simple types and structures for general-purpose use. Additional, more specialized data structures are introduced in subsequent sections, together with the functions that use them.
The general-purpose types and structures are as follows:
typedef void *awk_ext_id_t;A value of this type is received from
gawkwhen an extension is loaded. That value must then be passed back togawkas the first parameter of each API function.#define awk_const …This macro expands to ‘
const’ when compiling an extension, and to nothing when compilinggawkitself. This makes certain fields in the API data structures unwritable from extension code, while allowinggawkto use them as it needs to.typedef enum awk_bool {awk_false = 0,awk_true} awk_bool_t;A simple Boolean type.
typedef struct awk_string {char *str; /* data */size_t len; /* length thereof, in chars */} awk_string_t;This represents a mutable string.
gawkowns the memory pointed to if it supplied the value. Otherwise, it takes ownership of the memory pointed to. Such memory must come from calling one of thegawk_malloc(),gawk_calloc(), orgawk_realloc()functions!As mentioned earlier, strings are maintained using the current multibyte encoding.
typedef enum {AWK_UNDEFINED,AWK_NUMBER,AWK_STRING,AWK_ARRAY,AWK_SCALAR, /* opaque access to a variable */AWK_VALUE_COOKIE /* for updating a previously created value */} awk_valtype_t;This
enumindicates the type of a value. It is used in the followingstruct.typedef struct awk_value {awk_valtype_t val_type;union {awk_string_t s;double d;awk_array_t a;awk_scalar_t scl;awk_value_cookie_t vc;} u;} awk_value_t;An “
awkvalue.” Theval_typemember indicates what kind of value theunionholds, and each member is of the appropriate type.#define str_value u.s#define num_value u.d#define array_cookie u.a#define scalar_cookie u.scl#define value_cookie u.vcUsings these macros makes accessing the fields of the
awk_value_tmore readable.typedef void *awk_scalar_t;Scalars can be represented as an opaque type. These values are obtained from
gawkand then passed back into it. This is discussed in a general fashion in the text following this list, and in more detail in Variable access and update by cookie.typedef void *awk_value_cookie_t;A “value cookie” is an opaque type representing a cached value. This is also discussed in a general fashion in the text following this list, and in more detail in Creating and using cached values.
Scalar values in awk are
either numbers or strings. The awk_value_t represents values. The val_type member indicates what is in the
union.
Representing numbers is easy—the API uses a C double. Strings require more work. Because gawk allows embedded NUL bytes in string
values, a string must be represented as a pair containing a data pointer
and length. This is the awk_string_t
type.
Identifiers (i.e., the names of global variables) can be
associated with either scalar values or with arrays. In addition,
gawk provides true arrays of arrays,
where any given array element can itself be an array. Discussion of
arrays is delayed until Array Manipulation.
The various macros listed earlier make it easier to use the
elements of the union as if they were
fields in a struct; this is a common
coding practice in C. Such code is easier to write and to read, but it
remains your responsibility to make sure that the
val_type member correctly reflects
the type of the value in the awk_value_t struct.
Conceptually, the first three members of the union (number, string, and array) are all that
is needed for working with awk
values. However, because the API provides routines for accessing and
changing the value of a global scalar variable only by using the
variable’s name, there is a performance penalty: gawk must find the variable each time it is
accessed and changed. This turns out to be a real issue, not just a
theoretical one.
Thus, if you know that your extension will spend considerable time
reading and/or changing the value of one or more scalar variables, you can obtain a
scalar cookie[95] object for that variable, and then use the cookie for
getting the variable’s value or for changing the variable’s value. The
awk_scalar_t type holds a scalar cookie, and the
scalar_cookie macro provides
access to the value of
that type in the awk_value_t struct. Given a scalar
cookie, gawk can directly retrieve or
modify the value, as required, without having to find it first.
The awk_value_cookie_t type and
value_cookie macro are similar. If
you know that you wish to use the same numeric or string
value for one or more variables, you can create the
value once, retaining a value cookie for it, and
then pass in that value cookie whenever you wish to set the value of a
variable. This saves storage space within the running gawk process and reduces the time needed to
create the value.
Memory Allocation Functions and Convenience Macros
The API provides a number of memory
allocation functions for allocating memory that can be passed to gawk, as well as a number of convenience
macros. This subsection presents them all as function prototypes, in the
way that extension code would use them:
void *gawk_malloc(size_t size);Call the correct version of
malloc()to allocate storage that may be passed togawk.void *gawk_calloc(size_t nmemb, size_t size);Call the correct version of
calloc()to allocate storage that may be passed togawk.void *gawk_realloc(void *ptr, size_t size);Call the correct version of
realloc()to allocate storage that may be passed togawk.void gawk_free(void *ptr);Call the correct version of
free()to release storage that was allocated withgawk_malloc(),gawk_calloc(), orgawk_realloc().
The API has to provide these functions because it is possible for
an extension to be compiled and linked against a different version of
the C library than was used for the gawk executable.[96] If gawk were to use its
version of free() when the memory
came from an unrelated version of malloc(), unexpected behavior would likely
result.
Two convenience macros may be used for allocating storage from gawk_malloc() and gawk_realloc(). If the allocation fails, they
cause gawk to exit with a fatal error
message. They should be used as if they were procedure calls that
do not return a value:
#define emalloc(pointer, type, size, message) …The arguments to this macro are as follows:
pointerThe pointer variable to point at the allocated storage.
typeThe type of the pointer variable. This is used to create a cast for the call to
gawk_malloc().sizeThe total number of bytes to be allocated.
messageA message to be prefixed to the fatal error message. Typically this is the name of the function using the macro.
For example, you might allocate a string value like so:
awk_value_t result; char *message; const char greet[] = "Don't Panic!"; emalloc(message, char *, sizeof(greet), "myfunc"); strcpy(message, greet); make_malloced_string(message, strlen(message), & result);
#define erealloc(pointer, type, size, message) …This is like
emalloc(), but it callsgawk_realloc()instead ofgawk_malloc(). The arguments are the same as for theemalloc()macro.
Constructor Functions
The API provides a number of constructor functions for creating string and numeric values, as well as a number of convenience macros. This subsection presents them all as function prototypes, in the way that extension code would use them:
static inline awk_value_t *make_const_string(const char *string, size_t length,awk_value_t *result);This function creates a string value in the
awk_value_tvariable pointed to byresult. It expectsstringto be a C string constant (or other string data), and automatically creates a copy of the data for storage inresult. It returnsresult.static inline awk_value_t *make_malloced_string(const char *string, size_t length,awk_value_t *result);This function creates a string value in the
awk_value_tvariable pointed to byresult. It expectsstringto be a ‘char *’ value pointing to data previously obtained fromgawk_malloc(),gawk_calloc(), orgawk_realloc(). The idea here is that the data is passed directly togawk, which assumes responsibility for it. It returnsresult.static inline awk_value_t *make_null_string(awk_value_t *result);This specialized function creates a null string (the “undefined” value) in the
awk_value_tvariable pointed to byresult. It returnsresult.static inline awk_value_t *make_number(double num, awk_value_t *result);This function simply creates a numeric value in the
awk_value_tvariable pointed to byresult.
Registration Functions
This section describes the API functions for registering parts of your extension with gawk.
Registering an extension function
Extension functions are described by the following record:
typedef struct awk_ext_func {
const char *name;
awk_value_t *(*function)(int num_actual_args, awk_value_t *result);
size_t num_expected_args;
} awk_ext_func_t;The fields are:
const char *name;The name of the new function.
awk-level code calls the function by this name. This is a regular C string.Function names must obey the rules for
awkidentifiers. That is, they must begin with either an English letter or an underscore, which may be followed by any number of letters, digits, and underscores. Letter case in function names is significant.awk_value_t *(*function)(int num_actual_args, awk_value_t *result);This is a pointer to the C function that provides the extension’s functionality. The function must fill in
*resultwith either a number or a string.gawktakes ownership of any string memory. As mentioned earlier, string memory must come from one ofgawk_malloc(),gawk_calloc(), orgawk_realloc().The
num_actual_argsargument tells the C function how many actual parameters were passed from the callingawkcode.The function must return the value of
result. This is for the convenience of the calling code insidegawk.size_t num_expected_args;This is the number of arguments the function expects to receive. Each extension function may decide what to do if the number of arguments isn’t what it expected. As with real
awkfunctions, it is likely OK to ignore extra arguments.
Once you have a record representing your extension function, you
register it with gawk using this
API function:
awk_bool_t add_ext_func(const char *namespace,const awk_ext_func_t *func);This function returns true upon success, false otherwise. The
namespaceparameter is currently not used; you should pass in an empty string (""). Thefuncpointer is the address of astructrepresenting your function, as just described.
Registering an exit callback function
An exit callback function is a function
that gawk calls before it
exits. Such functions are useful if you have general “cleanup”
tasks that should be performed in your extension (such as closing
database connections or other resource deallocations). You can
register such a function with gawk
using the following function:
void awk_atexit(void (*funcp)(void *data, int exit_status),void *arg0);The parameters are:
funcpA pointer to the function to be called before
gawkexits. Thedataparameter will be the original value ofarg0. Theexit_statusparameter is the exit status value thatgawkintends to pass to theexit()system call.arg0A pointer to private data that
gawksaves in order to pass to the function pointed to byfuncp.
Exit callback functions are called in last-in, first-out (LIFO)
order—that is, in the reverse order in which they are registered with
gawk.
Registering an extension version string
You can register a version string that indicates the name
and version of your extension, with gawk, as follows:
void register_ext_version(const char *version);Register the string pointed to by
versionwithgawk. Note thatgawkdoes not copy theversionstring, so it should not be changed.
gawk prints all registered
extension version strings when it is invoked with the --version
option.
Customized input parsers
By default, gawk reads text
files as its input. It uses the value of RS to find the end of the record, and then
uses FS (or FIELDWIDTHS or FPAT) to split it into fields (see Chapter 4). Additionally, it sets the value of
RT (see Predefined Variables).
If you want, you can provide your own custom input parser. An
input parser’s job is to return a record to the gawk record-processing code, along with
indicators for the value and length of the data to be used for
RT, if any.
To provide an input parser, you must first provide two functions
(where XXX is a prefix name for your
extension):
awk_bool_tXXX_can_take_file(const awk_input_buf_t *iobuf);This function examines the information available in
iobuf(which we discuss shortly). Based on the information there, it decides if the input parser should be used for this file. If so, it should return true. Otherwise, it should return false. It should not change any state (variable values, etc.) withingawk.awk_bool_tXXX_take_control_of(awk_input_buf_t *iobuf);When
gawkdecides to hand control of the file over to the input parser, it calls this function. This function in turn must fill in certain fields in theawk_input_buf_tstructure and ensure that certain conditions are true. It should then return true. If an error of some kind occurs, it should not fill in any fields and should return false; thengawkwill not use the input parser. The details are presented shortly.
Your extension should package these functions inside an awk_input_parser_t, which looks like
this:
typedef struct awk_input_parser {
const char *name; /* name of parser */
awk_bool_t (*can_take_file)(const awk_input_buf_t *iobuf);
awk_bool_t (*take_control_of)(awk_input_buf_t *iobuf);
awk_const struct awk_input_parser *awk_const next; /* for gawk */
} awk_input_parser_t;The fields are:
const char *name;The name of the input parser. This is a regular C string.
awk_bool_t (*can_take_file)(const awk_input_buf_t *iobuf);A pointer to your
XXX_can_take_file()awk_bool_t (*take_control_of)(awk_input_buf_t *iobuf);A pointer to your
XXX_take_control_of()awk_const struct input_parser *awk_const next;This is for use by
gawk; therefore it is markedawk_constso that the extension cannot modify it.
The steps are as follows:
Create a
static awk_input_parser_tvariable and initialize it appropriately.When your extension is loaded, register your input parser with
gawkusing theregister_input_parser()API function (described next).
An awk_input_buf_t
looks like this:
typedef struct awk_input {
const char *name; /* filename */
int fd; /* file descriptor */
#define INVALID_HANDLE (-1)
void *opaque; /* private data for input parsers */
int (*get_record)(char **out, struct awk_input *iobuf,
int *errcode, char **rt_start, size_t *rt_len);
ssize_t (*read_func)();
void (*close_func)(struct awk_input *iobuf);
struct stat sbuf; /* stat buf */
} awk_input_buf_t;The fields can be divided into two categories: those for use
(initially, at least) by XXX_can_take_file()XXX_take_control_of()
const char *name;The name of the file.
int fd;A file descriptor for the file. If
gawkwas able to open the file, thenfdwill not be equal toINVALID_HANDLE. Otherwise, it will.struct stat sbuf;If the file descriptor is valid, then
gawkwill have filled in this structure via a call to thefstat()system call.
The XXX_can_take_file()gawk state (the value of a variable
defined previously by the extension and set by awk code), the name of the file, whether or
not the file descriptor is valid, the information in the struct stat, or any combination of
these factors.
Once XXX_can_take_file()gawk has
decided to use your input parser, it calls XXX_take_control_of()get_record field or the read_func field in the awk_input_buf_t. It must also ensure that
fd is not set
to INVALID_HANDLE. The following
list describes the fields that may be filled by XXX_take_control_of()
void *opaque;This is used to hold any state information needed by the input parser for this file. It is “opaque” to
gawk. The input parser is not required to use this pointer.int (*get_record)(char **out,struct awk_input *iobuf,int *errcode,char **rt_start,size_t *rt_len);This function pointer should point to a function that creates the input records. Said function is the core of the input parser. Its behavior is described in the text following this list.
ssize_t (*read_func)();This function pointer should point to a function that has the same behavior as the standard POSIX
read()system call. It is an alternative to theget_recordpointer. Its behavior is also described in the text following this list.void (*close_func)(struct awk_input *iobuf);This function pointer should point to a function that does the “teardown.” It should release any resources allocated by
XXX_take_control_of()fdfield toINVALID_HANDLE.If
fdis still notINVALID_HANDLEafter the call to this function,gawkcalls the regularclose()system call.Having a “teardown” function is optional. If your input parser does not need it, do not set this field. Then,
gawkcalls the regularclose()system call on the file descriptor, so it should be valid.
The XXX_get_record()
char **outThis is a pointer to a
char *variable that is set to point to the record.gawkmakes its own copy of the data, so the extension must manage this storage.struct awk_input *iobufThis is the
awk_input_buf_tfor the file. The fields should be used for reading data (fd) and for managing private state (opaque), if any.int *errcodeIf an error occurs,
*errcodeshould be set to an appropriate code from<errno.h>.char **rt_startsize_t *rt_lenIf the concept of a “record terminator” makes sense, then
*rt_startshould be set to point to the data to be used forRT, and*rt_lenshould be set to the length of the data. Otherwise,*rt_lenshould be set to zero.gawkmakes its own copy of this data, so the extension must manage this storage.
The return value is the length of the buffer pointed to by
*out, or EOF if end-of-file was reached or an error
occurred.
It is guaranteed that errcode
is a valid pointer, so there is no need to test for a NULL value. gawk sets *errcode to zero, so there is no need to set
it unless an error occurs.
If an error does occur, the function should return EOF and set *errcode to a value greater than zero. In
that case, if *errcode does not
equal zero, gawk automatically
updates the ERRNO variable based on
the value of *errcode. (In general,
setting ‘*errcode = errno’ should do the
right thing.)
As an alternative to supplying a function that returns an input
record, you may instead supply a function that simply reads bytes, and
let gawk parse the data into
records. If you do so, the data should be returned in the multibyte
encoding of the current locale. Such a function should follow the same
behavior as the read() system call,
and you fill in the read_func
pointer with its address in the awk_input_buf_t structure.
By default, gawk sets the
read_func pointer to point to the
read() system call. So your
extension need not set this field explicitly.
Note
You must choose one method or the other: either a function
that returns a record, or one that returns raw data. In particular,
if you supply a function to get a record, gawk will call it, and will never call the
raw read function.
gawk ships with a sample
extension that reads directories, returning records for each entry in
a directory (see Reading Directories). You may
wish to use that code as a guide for writing your own input
parser.
When writing an input parser, you should think about (and
document) how it is expected to interact with awk code. You may want it to always be
called, and to take effect as appropriate (as the readdir extension does). Or you may want it
to take effect based upon the value of an awk variable, as the XML extension from the
gawkextlib project does (see The gawkextlib Project). In the latter case, code in a BEGINFILE section can look at FILENAME and ERRNO to decide whether or not to activate
an input parser (see The BEGINFILE and ENDFILE Special Patterns).
You register your input parser with the following function:
void register_input_parser(awk_input_parser_t *input_parser);Register the input parser pointed to by
input_parserwithgawk.
Customized output wrappers
An output wrapper is the mirror image of
an input parser. It allows an extension to take over the output to a
file opened with the ‘>’ or
‘>>’ I/O redirection
operators (see Redirecting Output of print and printf).
The output wrapper is very similar to the input parser structure:
typedef struct awk_output_wrapper {
const char *name; /* name of the wrapper */
awk_bool_t (*can_take_file)(const awk_output_buf_t *outbuf);
awk_bool_t (*take_control_of)(awk_output_buf_t *outbuf);
awk_const struct awk_output_wrapper *awk_const next; /* for gawk */
} awk_output_wrapper_t;const char *name;This is the name of the output wrapper.
awk_bool_t (*can_take_file)(const awk_output_buf_t *outbuf);This points to a function that examines the information in the
awk_output_buf_tstructure pointed to byoutbuf. It should return true if the output wrapper wants to take over the file, and false otherwise. It should not change any state (variable values, etc.) withingawk.awk_bool_t (*take_control_of)(awk_output_buf_t *outbuf);The function pointed to by this field is called when
gawkdecides to let the output wrapper take control of the file. It should fill in appropriate members of theawk_output_buf_tstructure, as described next, and return true if successful, false otherwise.awk_const struct output_wrapper *awk_const next;This is for use by
gawk; therefore it is markedawk_constso that the extension cannot modify it.
The awk_output_buf_t
structure looks like this:
typedef struct awk_output_buf {
const char *name; /* name of output file */
const char *mode; /* mode argument to fopen */
FILE *fp; /* stdio file pointer */
awk_bool_t redirected; /* true if a wrapper is active */
void *opaque; /* for use by output wrapper */
size_t (*gawk_fwrite)(const void *buf, size_t size, size_t count,
FILE *fp, void *opaque);
int (*gawk_fflush)(FILE *fp, void *opaque);
int (*gawk_ferror)(FILE *fp, void *opaque);
int (*gawk_fclose)(FILE *fp, void *opaque);
} awk_output_buf_t;Here too, your extension will define XXX_can_take_file()XXX_take_control_of()awk_output_buf_t.
The data members are as follows:
const char *name;The name of the output file.
const char *mode;The mode string (as would be used in the second argument to
fopen()) with which the file was opened.FILE *fp;The
FILEpointer from<stdio.h>.gawkopens the file before attempting to find an output wrapper.awk_bool_t redirected;This field must be set to true by the
XXX_take_control_of()void *opaque;This pointer is opaque to
gawk. The extension should use it to store a pointer to any private data associated with the file.size_t (*gawk_fwrite)(const void *buf, size_t size, size_t count,FILE *fp, void *opaque);int (*gawk_fflush)(FILE *fp, void *opaque);int (*gawk_ferror)(FILE *fp, void *opaque);int (*gawk_fclose)(FILE *fp, void *opaque);These pointers should be set to point to functions that perform the equivalent functions as the
<stdio.h>functions do, if appropriate.gawkuses these function pointers for all output.gawkinitializes the pointers to point to internal “pass-through” functions that just call the regular<stdio.h>functions, so an extension only needs to redefine those functions that are appropriate for what it does.
The XXX_can_take_file()name and mode fields, and any additional state (such
as awk variable values) that is
appropriate.
When gawk calls XXX_take_control_of()fp, which it should just use
normally.
You register your output wrapper with the following function:
void register_output_wrapper(awk_output_wrapper_t *output_wrapper);Register the output wrapper pointed to by
output_wrapperwithgawk.
Customized two-way processors
A two-way processor combines an input
parser and an output wrapper for two-way I/O with the ‘|&’ operator (see Redirecting Output of print and printf). It makes identical usage of the awk_input_parser_t and awk_output_buf_t structures as described earlier.
A two-way processor is represented by the following structure:
typedef struct awk_two_way_processor {
const char *name; /* name of the two-way processor */
awk_bool_t (*can_take_two_way)(const char *name);
awk_bool_t (*take_control_of)(const char *name,
awk_input_buf_t *inbuf,
awk_output_buf_t *outbuf);
awk_const struct awk_two_way_processor *awk_const next; /* for gawk */
} awk_two_way_processor_t;The fields are as follows:
const char *name;The name of the two-way processor.
awk_bool_t (*can_take_two_way)(const char *name);The function pointed to by this field should return true if it wants to take over two-way I/O for this filename. It should not change any state (variable values, etc.) within
gawk.awk_bool_t (*take_control_of)(const char *name,awk_input_buf_t *inbuf,awk_output_buf_t *outbuf);The function pointed to by this field should fill in the
awk_input_buf_tandawk_outut_buf_tstructures pointed to byinbufandoutbuf, respectively. These structures were described earlier.awk_const struct two_way_processor *awk_const next;This is for use by
gawk; therefore it is markedawk_constso that the extension cannot modify it.
As with the input parser and output processor, you provide “yes
I can take this” and “take over for this” functions, XXX_can_take_two_way()XXX_take_control_of()
You register your two-way processor with the following function:
void register_two_way_processor(awk_two_way_processor_t *two_way_processor);Register the two-way processor pointed to by
two_way_processorwithgawk.
Printing Messages
You can print different kinds of warning messages from your
extension, as described here. Note that for these functions, you
must pass in the extension ID received from gawk when the extension was loaded:[97]
void fatal(awk_ext_id_t id, const char *format, ...);Print a message and then cause
gawkto exit immediately.void warning(awk_ext_id_t id, const char *format, ...);Print a warning message.
void lintwarn(awk_ext_id_t id, const char *format, ...);Print a “lint warning.” Normally this is the same as printing a warning message, but if
gawkwas invoked with ‘--lint=fatal’, then lint warnings become fatal error messages.
All of these functions are otherwise like the C printf() family of functions, where the
format parameter is a string with
literal characters and formatting codes intermixed.
Updating ERRNO
The following functions allow you to update the ERRNO
variable:
void update_ERRNO_int(int errno_val);Set
ERRNOto the string equivalent of the error code inerrno_val. The value should be one of the defined error codes in<errno.h>, andgawkturns it into a (possibly translated) string using the Cstrerror()function.void update_ERRNO_string(const char *string);Set
ERRNOdirectly to the string value ofERRNO.gawkmakes a copy of the value ofstring.void unset_ERRNO(void);Unset
ERRNO.
Requesting Values
All of the functions that return values from gawk work in the same way. You pass in an awk_valtype_t value to indicate what kind of
value you expect. If the actual value matches what you requested, the
function returns true and fills in the awk_value_t result. Otherwise, the function
returns false, and the val_type
member indicates the type of the actual value. You may then print an
error message or reissue the request for the actual value type, as
appropriate. This behavior is summarized in Table 16-1.
Type of Actual Value | |||||
String | Number | Array | Undefined | ||
String | String | String | False | False | |
Number | Number if can be converted, else false | Number | False | False | |
Type | Array | False | False | Array | False |
Requested | Scalar | Scalar | Scalar | False | False |
Undefined | String | Number | Array | Undefined | |
Value cookie | False | False | False | False | |
Accessing and Updating Parameters
Two functions give you access to the arguments (parameters) passed to your extension function. They are:
awk_bool_t get_argument(size_t count,awk_valtype_t wanted,awk_value_t *result);Fill in the
awk_value_tstructure pointed to byresultwith thecountth argument. Return true if the actual type matcheswanted, and false otherwise. In the latter case,result->val_typeindicates the actual type (see Table 16-1). Counts are zero-based—the first argument is numbered zero, the second one, and so on.wantedindicates the type of value expected.awk_bool_t set_argument(size_t count, awk_array_t array);Convert a parameter that was undefined into an array; this provides call by reference for arrays. Return false if
countis too big, or if the argument’s type is not undefined. See Array Manipulation for more information on creating arrays.
Symbol Table Access
Two sets of routines provide access to global variables, and one set allows you to create and release cached values.
Variable access and update by name
The following routines provide the ability to access
and update global awk-level variables by name. In compiler
terminology, identifiers of different kinds are termed
symbols, thus the “sym” in the routines’ names.
The data structure that stores information about symbols is termed a
symbol table. The functions are as
follows:
awk_bool_t sym_lookup(const char *name,awk_valtype_t wanted,awk_value_t *result);Fill in the
awk_value_tstructure pointed to byresultwith the value of the variable named by the stringname, which is a regular C string.wantedindicates the type of value expected. Return true if the actual type matcheswanted, and false otherwise. In the latter case,result->val_typeindicates the actual type (see Table 16-1).awk_bool_t sym_update(const char *name, awk_value_t *value);Update the variable named by the string
name, which is a regular C string. The variable is added togawk’s symbol table if it is not there. Return true if everything worked, and false otherwise.Changing types (scalar to array or vice versa) of an existing variable is not allowed, nor may this routine be used to update an array. This routine cannot be used to update any of the predefined variables (such as
ARGCorNF).
An extension can look up the value of gawk’s special variables. However, with the
exception of the PROCINFO
array, an extension cannot change any of those
variables.
Caution
It is possible for the lookup of PROCINFO to fail. This happens if the
awk program being run does not
reference PROCINFO; in this case,
gawk doesn’t bother to create the
array and populate it.
Variable access and update by cookie
A scalar cookie is an opaque handle that
provides access to a global variable or array. It is an optimization that avoids looking up variables
in gawk’s symbol table every
time access is needed.
This was discussed earlier, in General-Purpose Data Types.
The following functions let you work with scalar cookies:
awk_bool_t sym_lookup_scalar(awk_scalar_t cookie,awk_valtype_t wanted,awk_value_t *result);Retrieve the current value of a scalar cookie. Once you have obtained a scalar cookie using
sym_lookup(), you can use this function to get its value more efficiently. Return false if the value cannot be retrieved.awk_bool_t sym_update_scalar(awk_scalar_t cookie, awk_value_t *value);Update the value associated with a scalar cookie. Return false if the new value is not of type
AWK_STRINGorAWK_NUMBER. Here too, the predefined variables may not be updated.
It is not obvious at first glance how to work with scalar cookies or what their
raison d’être really is. In theory, the sym_lookup() and sym_update() routines are all you really
need to work with variables. For example, you might have code that
looks up the value of a variable, evaluates a condition, and then
possibly changes the value of the variable based on the result of that
evaluation, like so:
/* do_magic --- do something really great */
static awk_value_t *
do_magic(int nargs, awk_value_t *result)
{
awk_value_t value;
if ( sym_lookup("MAGIC_VAR", AWK_NUMBER, & value)
&& some_condition(value.num_value)) {
value.num_value += 42;
sym_update("MAGIC_VAR", & value);
}
return make_number(0.0, result);
}This code looks (and is) simple and straightforward. So what’s the problem?
Well, consider what happens if awk-level code associated with your
extension calls the magic()
function (implemented in C by do_magic()), once per record, while
processing hundreds of thousands or millions of records. The MAGIC_VAR variable is looked up in the
symbol table once or twice per function call!
The symbol table lookup is really pure overhead; it is considerably more efficient to get a cookie that represents the variable, and use that to get the variable’s value and update it as needed.[98]
Thus, the way to use cookies is as follows. First, install your
extension’s variable in gawk’s
symbol table using sym_update(), as
usual. Then get a scalar cookie for the variable using sym_lookup():
static awk_scalar_t magic_var_cookie; /* cookie for MAGIC_VAR */
static void
my_extension_init()
{
awk_value_t value;
/* install initial value */
sym_update("MAGIC_VAR", make_number(42.0, & value));
/* get the cookie */
sym_lookup("MAGIC_VAR", AWK_SCALAR, & value);
/* save the cookie */
magic_var_cookie = value.scalar_cookie;
…
}Next, use the routines in this section for retrieving and
updating the value through the cookie. Thus, do_magic() now becomes something like
this:
/* do_magic --- do something really great */
static awk_value_t *
do_magic(int nargs, awk_value_t *result)
{
awk_value_t value;
if ( sym_lookup_scalar(magic_var_cookie, AWK_NUMBER, & value)
&& some_condition(value.num_value)) {
value.num_value += 42;
sym_update_scalar(magic_var_cookie, & value);
}
…
return make_number(0.0, result);
}Note
The previous code omitted error checking for presentation purposes. Your extension code should be more robust and carefully check the return values from the API functions.
Creating and using cached values
The routines in this section allow you to create and release
cached values. Like scalar cookies, in theory, cached values are not
necessary. You can create numbers and strings using the functions in
Constructor Functions. You can then assign those
values to variables using sym_update() or sym_update_scalar(), as you like.
However, you can understand the point of cached values if you
remember that every string value’s storage
must come from gawk_malloc(), gawk_calloc(), or gawk_realloc(). If you
have 20 variables, all of which have the same string value, you must
create 20 identical copies of the string.[99]
It is clearly more efficient, if possible, to create a value
once and then tell gawk to reuse
the value for multiple variables. That is what the routines in this
section let you do. The functions are as follows:
awk_bool_t create_value(awk_value_t *value, awk_value_cookie_t *result);Create a cached string or numeric value from
valuefor efficient later assignment. Only values of typeAWK_NUMBERandAWK_STRINGare allowed. Any other type is rejected.AWK_UNDEFINEDcould be allowed, but doing so would result in inferior performance.awk_bool_t release_value(awk_value_cookie_t vc);Release the memory associated with a value cookie obtained from
create_value().
You use value cookies in a fashion similar to the way you use scalar cookies. In the extension initialization routine, you create the value cookie:
static awk_value_cookie_t answer_cookie; /* static value cookie */
static void
my_extension_init()
{
awk_value_t value;
char *long_string;
size_t long_string_len;
/* code from earlier */
…
/* … fill in long_string and long_string_len … */
make_malloced_string(long_string, long_string_len, & value);
create_value(& value, & answer_cookie); /* create cookie */
…
}Once the value is created, you can use it as the value of any number of variables:
static awk_value_t *
do_magic(int nargs, awk_value_t *result)
{
awk_value_t new_value;
… /* as earlier */
value.val_type = AWK_VALUE_COOKIE;
value.value_cookie = answer_cookie;
sym_update("VAR1", & value);
sym_update("VAR2", & value);
…
sym_update("VAR100", & value);
…
}Using value cookies in this way saves considerable storage, as
all of VAR1 through VAR100 share the same value.
You might be wondering, “Is this sharing problematic? What
happens if awk code assigns a new
value to VAR1; are all the others
changed too?”
That’s a great question. The answer is that no, it’s not a
problem. Internally, gawk uses
reference-counted strings. This means that many variables can share the same string
value, and gawk keeps track of the
usage. When a variable’s value changes, gawk simply decrements the reference count
on the old value and updates the variable to use the new value.
Finally, as part of your cleanup action (see Registering an exit callback function) you should release any cached
values that you created, using release_value().
Array Manipulation
The primary data structure[100] in awk is the
associative array (see Chapter 8). Extensions need to be
able to manipulate awk arrays. The
API provides a number of data structures for working with arrays,
functions for working with individual elements, and functions for
working with arrays as a whole. This includes the ability to “flatten”
an array so that it is easy for C code to traverse every element in an
array. The array data structures integrate nicely with the data
structures for values to make it easy to both work with and create true
arrays of arrays (see General-Purpose Data Types).
Array data types
The data types associated with arrays are as follows:
typedef void *awk_array_t;If you request the value of an array variable, you get back an
awk_array_tvalue. This value is opaque[101] to the extension; it uniquely identifies the array but can only be used by passing it into API functions or receiving it from API functions. This is very similar to way ‘FILE *’ values are used with the<stdio.h>library routines.typedef struct awk_element {/* convenience linked list pointer, not used by gawk */struct awk_element *next;enum {AWK_ELEMENT_DEFAULT = 0, /* set by gawk */AWK_ELEMENT_DELETE = 1 /* set by extension */} flags;awk_value_t index;awk_value_t value;} awk_element_t;The
awk_element_tis a “flattened” array element.awkproduces an array of these inside theawk_flat_array_t(see the next item). Individual elements may be marked for deletion. New elements must be added individually, one at a time, using the separate API for that purpose. The fields are as follows:struct awk_element *next;This pointer is for the convenience of extension writers. It allows an extension to create a linked list of new elements that can then be added to an array in a loop that traverses the list.
enum { … } flags;A set of flag values that convey information between the extension and
gawk. Currently there is only one:AWK_ELEMENT_DELETE. Setting it causesgawkto delete the element from the original array upon release of the flattened array.indexvalueThe index and value of the element, respectively. All memory pointed to by
indexandvaluebelongs togawk.
typedef struct awk_flat_array {awk_const void *awk_const opaque1; /* for use by gawk */awk_const void *awk_const opaque2; /* for use by gawk */awk_const size_t count; /* how many elements */awk_element_t elements[1]; /* will be extended */} awk_flat_array_t;This is a flattened array. When an extension gets one of these from
gawk, theelementsarray is of actual sizecount. Theopaque1andopaque2pointers are for use bygawk; therefore they are markedawk_constso that the extension cannot modify them.
Array functions
The following functions relate to individual array elements:
awk_bool_t get_element_count(awk_array_t a_cookie, size_t *count);For the array represented by
a_cookie, place in*countthe number of elements it contains. A subarray counts as a single element. Return false if there is an error.awk_bool_t get_array_element(awk_array_t a_cookie,const awk_value_t *const index,awk_valtype_t wanted,awk_value_t *result);For the array represented by
a_cookie, return in*resultthe value of the element whose index isindex.wantedspecifies the type of value you wish to retrieve. Return false ifwanteddoes not match the actual type or ifindexis not in the array (see Table 16-1).The value for
indexcan be numeric, in which casegawkconverts it to a string. Using nonintegral values is possible, but requires that you understand how such values are converted to strings (see Conversion of Strings and Numbers); thus, using integral values is safest.As with all strings passed into
gawkfrom an extension, the string value ofindexmust come fromgawk_malloc(),gawk_calloc(), orgawk_realloc(), andgawkreleases the storage.awk_bool_t set_array_element(awk_array_t a_cookie,const awk_value_t *const index,const awk_value_t *const value);In the array represented by
a_cookie, create or modify the element whose index is given byindex. TheARGVandENVIRONarrays may not be changed, although thePROCINFOarray can be.awk_bool_t set_array_element_by_elem(awk_array_t a_cookie,awk_element_t element);Like
set_array_element(), but take theindexandvaluefromelement. This is a convenience macro.awk_bool_t del_array_element(awk_array_t a_cookie,const awk_value_t* const index);Remove the element with the given index from the array represented by
a_cookie. Return true if the element was removed, or false if the element did not exist in the array.
The following functions relate to arrays as a whole:
awk_array_t create_array(void);Create a new array to which elements may be added. See How to create and populate arrays for a discussion of how to create a new array and add elements to it.
awk_bool_t clear_array(awk_array_t a_cookie);Clear the array represented by
a_cookie. Return false if there was some kind of problem, true otherwise. The array remains an array, but after calling this function, it has no elements. This is equivalent to using thedeletestatement (see The delete Statement).awk_bool_t flatten_array(awk_array_t a_cookie, awk_flat_array_t **data);For the array represented by
a_cookie, create anawk_flat_array_tstructure and fill it in. Set the pointer whose address is passed asdatato point to this structure. Return true upon success, or false otherwise. See the next section for a discussion of how to flatten an array and work with it.awk_bool_t release_flattened_array(awk_array_t a_cookie,awk_flat_array_t *data);When done with a flattened array, release the storage using this function. You must pass in both the original array cookie and the address of the created
awk_flat_array_tstructure. The function returns true upon success, false otherwise.
Working with all the elements of an array
To flatten an array is to create a
structure that represents the full array in a fashion that makes it easy for C code to traverse the entire
array. Some of the code in extension/testext.c does this, and also
serves as a nice example showing how to use the APIs.
We walk through that part of the code one step at a time. First,
the gawk script that drives the
test extension:
@load "testext"
BEGIN {
n = split("blacky rusty sophie raincloud lucky", pets)
printf("pets has %d elements
", length(pets))
ret = dump_array_and_delete("pets", "3")
printf("dump_array_and_delete(pets) returned %d
", ret)
if ("3" in pets)
printf("dump_array_and_delete() did NOT remove index "3"!
")
else
printf("dump_array_and_delete() did remove index "3"!
")
print ""
}This code creates an array with split() (see String-Manipulation Functions) and then calls dump_array_and_delete(). That function looks
up the array whose name is passed as the first argument, and deletes
the element at the index passed in the second argument. The awk code then prints the return value and
checks if the element was indeed deleted. Here is the C code that
implements dump_array_and_delete().
It has been edited slightly for presentation.
The first part declares variables, sets up the default return
value in result, and checks that
the function was called with the correct number of arguments:
static awk_value_t *
dump_array_and_delete(int nargs, awk_value_t *result)
{
awk_value_t value, value2, value3;
awk_flat_array_t *flat_array;
size_t count;
char *name;
int i;
assert(result != NULL);
make_number(0.0, result);
if (nargs != 2) {
printf("dump_array_and_delete: nargs not right "
"(%d should be 2)
", nargs);
goto out;
}The function then proceeds in steps, as follows. First, retrieve the name of the array, passed as the first argument, followed by the array itself. If either operation fails, print an error message and return:
/* get argument named array as flat array and print it */
if (get_argument(0, AWK_STRING, & value)) {
name = value.str_value.str;
if (sym_lookup(name, AWK_ARRAY, & value2))
printf("dump_array_and_delete: sym_lookup of %s passed
",
name);
else {
printf("dump_array_and_delete: sym_lookup of %s failed
",
name);
goto out;
}
} else {
printf("dump_array_and_delete: get_argument(0) failed
");
goto out;
}For testing purposes and to make sure that the C code sees the
same number of elements as the awk
code, the second step is to get the count of elements in the array and
print it:
if (! get_element_count(value2.array_cookie, & count)) {
printf("dump_array_and_delete: get_element_count failed
");
goto out;
}
printf("dump_array_and_delete: incoming size is %lu
",
(unsigned long) count);The third step is to actually flatten the array, and then to
double-check that the count in the awk_flat_array_t is the same as the count
just retrieved:
if (! flatten_array(value2.array_cookie, & flat_array)) {
printf("dump_array_and_delete: could not flatten array
");
goto out;
}
if (flat_array->count != count) {
printf("dump_array_and_delete: flat_array->count (%lu)"
" != count (%lu)
",
(unsigned long) flat_array->count,
(unsigned long) count);
goto out;
}The fourth step is to retrieve the index of the element to be
deleted, which was passed as the second argument. Remember that
argument counts passed to get_argument() are zero-based, and thus the
second argument is numbered one:
if (! get_argument(1, AWK_STRING, & value3)) {
printf("dump_array_and_delete: get_argument(1) failed
");
goto out;
}The fifth step is where the “real work” is done. The function
loops over every element in the array, printing the index and element
values. In addition, upon finding the element with the index that is
supposed to be deleted, the function sets the AWK_ELEMENT_DELETE bit in the
flags field of the element. When
the array is released, gawk
traverses the flattened array, and deletes any elements that have this
flag bit set:
for (i = 0; i < flat_array->count; i++) {
printf(" %s["%.*s"] = %s
",
name,
(int) flat_array->elements[i].index.str_value.len,
flat_array->elements[i].index.str_value.str,
valrep2str(& flat_array->elements[i].value));
if (strcmp(value3.str_value.str,
flat_array->elements[i].index.str_value.str) == 0) {
flat_array->elements[i].flags |= AWK_ELEMENT_DELETE;
printf("dump_array_and_delete: marking element "%s" "
"for deletion
",
flat_array->elements[i].index.str_value.str);
}
}The sixth step is to release the flattened array. This tells
gawk that the extension is no
longer using the array, and that it should delete any elements marked
for deletion. gawk also frees any
storage that was allocated, so you should not use the pointer (flat_array in this code) once you
have called release_flattened_array():
if (! release_flattened_array(value2.array_cookie, flat_array)) {
printf("dump_array_and_delete: could not release flattened array
");
goto out;
}Finally, because everything was successful, the function sets the return value to success, and returns:
make_number(1.0, result);
out:
return result;
}Here is the output from running this part of the test:
pets has 5 elements
dump_array_and_delete: sym_lookup of pets passed
dump_array_and_delete: incoming size is 5
pets["1"] = "blacky"
pets["2"] = "rusty"
pets["3"] = "sophie"
dump_array_and_delete: marking element "3" for deletion
pets["4"] = "raincloud"
pets["5"] = "lucky"
dump_array_and_delete(pets) returned 1
dump_array_and_delete() did remove index "3"!How to create and populate arrays
Besides working with arrays created by awk code, you can create arrays and populate them as you see fit, and then awk code can access them and manipulate
them.
There are two important points about creating arrays from extension code:
You must install a new array into
gawk’s symbol table immediately upon creating it. Once you have done so, you can then populate the array.Similarly, if installing a new array as a subarray of an existing array, you must add the new array to its parent before adding any elements to it.
Thus, the correct way to build an array is to work “top down.” Create the array, and immediately install it in
gawk’s symbol table usingsym_update(), or install it as an element in a previously existing array usingset_array_element(). We show example code shortly.Due to
gawkinternals, after usingsym_update()to install an array intogawk, you have to retrieve the array cookie from the value passed in tosym_update()before doing anything else with it, like so:awk_value_t value; awk_array_t new_array; new_array = create_array(); val.val_type = AWK_ARRAY; val.array_cookie = new_array; /* install array in the symbol table */ sym_update("array", & val); new_array = val.array_cookie; /* YOU MUST DO THIS */If installing an array as a subarray, you must also retrieve the value of the array cookie after the call to
set_element().
The following C code is a simple test extension to create an
array with two regular elements and with a subarray. The leading
#include directives and boilerplate
variable declarations (see Boilerplate Code) are omitted for brevity. The
first step is to create a new array and then install it in the symbol
table:
/* create_new_array --- create a named array */
static void
create_new_array()
{
awk_array_t a_cookie;
awk_array_t subarray;
awk_value_t index, value;
a_cookie = create_array();
value.val_type = AWK_ARRAY;
value.array_cookie = a_cookie;
if (! sym_update("new_array", & value))
printf("create_new_array: sym_update("new_array") failed!
");
a_cookie = value.array_cookie;Note how a_cookie is reset
from the array_cookie field in the
value structure.
The second step is to install two regular values into new_array:
(void) make_const_string("hello", 5, & index);
(void) make_const_string("world", 5, & value);
if (! set_array_element(a_cookie, & index, & value)) {
printf("fill_in_array: set_array_element failed
");
return;
}
(void) make_const_string("answer", 6, & index);
(void) make_number(42.0, & value);
if (! set_array_element(a_cookie, & index, & value)) {
printf("fill_in_array: set_array_element failed
");
return;
}The third step is to create the subarray and install it:
(void) make_const_string("subarray", 8, & index);
subarray = create_array();
value.val_type = AWK_ARRAY;
value.array_cookie = subarray;
if (! set_array_element(a_cookie, & index, & value)) {
printf("fill_in_array: set_array_element failed
");
return;
}
subarray = value.array_cookie;The final step is to populate the subarray with its own element:
(void) make_const_string("foo", 3, & index);
(void) make_const_string("bar", 3, & value);
if (! set_array_element(subarray, & index, & value)) {
printf("fill_in_array: set_array_element failed
");
return;
}
}Here is a sample script that loads the extension and then dumps the array:
@load "subarray"
function dumparray(name, array, i)
{
for (i in array)
if (isarray(array[i]))
dumparray(name "["" i ""]", array[i])
else
printf("%s["%s"] = %s
", name, i, array[i])
}
BEGIN {
dumparray("new_array", new_array);
}Here is the result of running the script:
$ AWKLIBPATH=$PWD ./gawk -f subarray.awk
new_array["subarray"]["foo"] = bar
new_array["hello"] = world
new_array["answer"] = 42(See How gawk Finds Extensions for more information
on the AWKLIBPATH environment variable.)
API Variables
The API provides two sets of variables. The first provides information about the version of the
API (both with which the extension was compiled, and with which gawk was compiled). The second provides
information about how gawk was
invoked.
API version constants and variables
The API provides both a “major” and a “minor” version number. The API versions are available at compile time as constants:
GAWK_API_MAJOR_VERSIONThe major version of the API
GAWK_API_MINOR_VERSIONThe minor version of the API
The minor version increases when new functions are added to the
API. Such new functions are always added to the end of the API
struct.
The major version increases (and the minor version is reset to zero) if any of the data types change size or member order, or if any of the existing functions change signature.
It could happen that an extension may be compiled against one
version of the API but loaded by a version of gawk using a different version. For this
reason, the major and minor API versions of the running gawk are included in the API struct as read-only constant
integers:
api->major_versionThe major version of the running
gawkapi->minor_versionThe minor version of the running
gawk
It is up to the extension to decide if there are API incompatibilities. Typically, a check like this is enough:
if (api->major_version != GAWK_API_MAJOR_VERSION
|| api->minor_version < GAWK_API_MINOR_VERSION) {
fprintf(stderr, "foo_extension: version mismatch with gawk!
");
fprintf(stderr, " my version (%d, %d), gawk version (%d, %d)
",
GAWK_API_MAJOR_VERSION, GAWK_API_MINOR_VERSION,
api->major_version, api->minor_version);
exit(1);
}Such code is included in the boilerplate dl_load_func() macro provided in gawkapi.h
(discussed in Boilerplate Code).
Informational variables
The API provides access to several variables that describe whether the corresponding command-line options
were enabled when gawk was
invoked. The variables are:
do_debugThis variable is true if
gawkwas invoked with--debugoption.do_lintThis variable is true if
gawkwas invoked with--lintoption.do_mpfrThis variable is true if
gawkwas invoked with--bignumoption.do_profileThis variable is true if
gawkwas invoked with--profileoption.do_sandboxThis variable is true if
gawkwas invoked with--sandboxoption.do_traditionalThis variable is true if
gawkwas invoked with--traditionaloption.
The value of do_lint can
change if awk code modifies the
LINT predefined variable (see Predefined Variables). The others should not change
during execution.
Boilerplate Code
As mentioned earlier (see How It Works at a High Level), the function definitions as
presented are really macros. To use these macros, your extension must provide a small
amount of boilerplate code (variables and functions)
toward the top of your source file, using predefined names as described
here. The boilerplate needed is also provided in comments in the
gawkapi.h header file:
/* Boilerplate code: */
int plugin_is_GPL_compatible;
static gawk_api_t *const api;
static awk_ext_id_t ext_id;
static const char *ext_version = NULL; /* or … = "some string" */
static awk_ext_func_t func_table[] = {
{ "name", do_name, 1 },
/* … */
};
/* EITHER: */
static awk_bool_t (*init_func)(void) = NULL;
/* OR: */
static awk_bool_t
init_my_extension(void)
{
…
}
static awk_bool_t (*init_func)(void) = init_my_extension;
dl_load_func(func_table, some_name, "name_space_in_quotes")These variables and functions are as follows:
int plugin_is_GPL_compatible;This asserts that the extension is compatible with the GNU GPL. If your extension does not have this,
gawkwill not load it (see Extension Licensing).static gawk_api_t *const api;This global
staticvariable should be set to point to thegawk_api_tpointer thatgawkpasses to yourdl_load()function. This variable is used by all of the macros.static awk_ext_id_t ext_id;This global static variable should be set to the
awk_ext_id_tvalue thatgawkpasses to yourdl_load()function. This variable is used by all of the macros.static const char *ext_version = NULL; /* or … = "some string" */This global
staticvariable should be set either toNULL, or to point to a string giving the name and version of your extension.static awk_ext_func_t func_table[] = { … };This is an array of one or more
awk_ext_func_tstructures, as described earlier (see Registering an extension function). It can then be looped over for multiple calls toadd_ext_func().static awk_bool_t (*init_func)(void) = NULL;ORstatic awk_bool_t init_my_extension(void) { … }static awk_bool_t (*init_func)(void) = init_my_extension;If you need to do some initialization work, you should define a function that does it (creates variables, opens files, etc.) and then define the
init_funcpointer to point to your function. The function should returnawk_falseupon failure, orawk_trueif everything goes well.If you don’t need to do any initialization, define the pointer and initialize it to
NULL.dl_load_func(func_table, some_name, "name_space_in_quotes")This macro expands to a
dl_load()function that performs all the necessary initializations.
The point of all the variables and arrays is to let the dl_load()
function (from the dl_load_func()
macro) do all the standard work. It does the following:
Check the API versions. If the extension major version does not match
gawk’s, or if the extension minor version is greater thangawk’s, it prints a fatal error message and exits.Load the functions defined in
func_table. If any of them fails to load, it prints a warning message but continues on.If the
init_funcpointer is notNULL, call the function it points to. If it returnsawk_false, print a warning message.If
ext_versionis notNULL, register the version string withgawk.
How gawk Finds Extensions
Compiled extensions have to be installed in a directory where
gawk can find them. If gawk is configured and built in the default
fashion, the directory in which to find extensions is /usr/local/lib/gawk. You can also specify a
search path with a list of directories to search for compiled extensions.
See The AWKLIBPATH Environment Variable for more information.
Example: Some File Functions
No matter where you go, there you are.
—Buckaroo Banzai
Two useful functions that are not in awk are chdir() (so that an awk program can change its directory) and stat() (so that an awk program can gather information about a
file). In order to illustrate the API in action, this section implements
these functions for gawk in an
extension.
Using chdir() and stat()
This section shows how to use the new functions at the awk level once they’ve been integrated into
the running gawk interpreter.
Using chdir() is very
straightforward. It takes one argument, the new directory to change
to:
@load "filefuncs"
…
newdir = "/home/arnold/funstuff"
ret = chdir(newdir)
if (ret < 0) {
printf("could not change to %s: %s
", newdir, ERRNO) > "/dev/stderr"
exit 1
}
…The return value is negative if the chdir() failed, and ERRNO (see Predefined Variables) is set to a string indicating the
error.
Using stat() is a bit more
complicated. The C stat() function
fills in a structure that has a fair amount of information. The right
way to model this in awk is to fill
in an associative array with the appropriate information:
file = "/home/arnold/.profile"
ret = stat(file, fdata)
if (ret < 0) {
printf("could not stat %s: %s
",
file, ERRNO) > "/dev/stderr"
exit 1
}
printf("size of %s is %d bytes
", file, fdata["size"])The stat() function always
clears the data array, even if the stat() fails. It fills in the following
elements:
"name"The name of the file that was
stat()ed."dev""ino"The file’s device and inode numbers, respectively.
"mode"The file’s mode, as a numeric value. This includes both the file’s type and its permissions.
"nlink"The number of hard links (directory entries) the file has.
"uid""gid"The numeric user and group ID numbers of the file’s owner.
"size"The size in bytes of the file.
"blocks"The number of disk blocks the file actually occupies. This may not be a function of the file’s size if the file has holes.
"atime""mtime""ctime"The file’s last access, modification, and inode update times, respectively. These are numeric timestamps, suitable for formatting with
strftime()(see Time Functions)."pmode"The file’s “printable mode.” This is a string representation of the file’s type and permissions, such as is produced by ‘
ls -l’—for example,"drwxr-xr-x"."type"A printable string representation of the file’s type. The value is one of the following:
"blockdev""chardev"The file is a block or character device (“special file”).
"directory"The file is a directory.
"fifo"The file is a named pipe (also known as a FIFO).
"file"The file is just a regular file.
"socket"The file is an
AF_UNIX(“Unix domain”) socket in the filesystem."symlink"The file is a symbolic link.
"devbsize"The size of a block for the element indexed by
"blocks". This information is derived from either theDEV_BSIZEconstant defined in<sys/param.h>on most systems, or theS_BLKSIZEconstant in<sys/stat.h>on BSD systems. For some other systems, a priori knowledge is used to provide a value. Where no value can be determined, it defaults to 512.
Several additional elements may be present, depending upon the
operating system and the type of the file. You can test for them in your
awk program by using the in operator (see Referring to an Array Element):
"blksize"The preferred block size for I/O to the file. This field is not present on all POSIX-like systems in the C
statstructure."linkval"If the file is a symbolic link, this element is the name of the file the link points to (i.e., the value of the link).
"rdev""major""minor"If the file is a block or character device file, then these values represent the numeric device number and the major and minor components of that number, respectively.
C Code for chdir() and stat()
Here is the C code for these extensions.[102]
The file includes a number of standard header files, and then includes the gawkapi.h header file, which provides the API
definitions. Those are followed by the necessary variable declarations
to make use of the API macros and boilerplate code (see Boilerplate Code):
#ifdef HAVE_CONFIG_H #include <config.h> #endif #include <stdio.h> #include <assert.h> #include <errno.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include "gawkapi.h" #include "gettext.h" #define _(msgid) gettext(msgid) #define N_(msgid) msgid #include "gawkfts.h" #include "stack.h" static const gawk_api_t *api; /* for convenience macros to work */ static awk_ext_id_t *ext_id; static awk_bool_t init_filefuncs(void); static awk_bool_t (*init_func)(void) = init_filefuncs; static const char *ext_version = "filefuncs extension: version 1.0"; int plugin_is_GPL_compatible;
By convention, for an awk
function foo(), the C function that
implements it is called do_foo().
The function should have two arguments. The first is an
int, usually called nargs, that represents the number of actual
arguments for the function. The second is a pointer to an awk_value_t structure, usually named result:
/* do_chdir --- provide dynamically loaded chdir() function for gawk */
static awk_value_t *
do_chdir(int nargs, awk_value_t *result)
{
awk_value_t newdir;
int ret = -1;
assert(result != NULL);
if (do_lint && nargs != 1)
lintwarn(ext_id,
_("chdir: called with incorrect number of arguments, "
"expecting 1"));The newdir variable represents
the new directory to change to, which is retrieved with get_argument(). Note that the first argument
is numbered zero.
If the argument is retrieved successfully, the function calls the
chdir() system call. If the chdir() fails, ERRNO is updated:
if (get_argument(0, AWK_STRING, & newdir)) {
ret = chdir(newdir.str_value.str);
if (ret < 0)
update_ERRNO_int(errno);
}Finally, the function returns the return value to the awk level:
return make_number(ret, result); }
The stat() extension is more
involved. First comes a function that turns a numeric mode into a printable representation (e.g., octal
0644 becomes ‘-rw-r--r--’). This is omitted here for
brevity:
/* format_mode --- turn a stat mode field into something readable */
static char *
format_mode(unsigned long fmode)
{
…
}Next comes a function for reading symbolic links, which is also omitted here for brevity:
/* read_symlink --- read a symbolic link into an allocated buffer.
… */
static char *
read_symlink(const char *fname, size_t bufsize, ssize_t *linksize)
{
…
}Two helper functions simplify entering values in the array that
will contain the result of the stat():
/* array_set --- set an array element */
static void
array_set(awk_array_t array, const char *sub, awk_value_t *value)
{
awk_value_t index;
set_array_element(array,
make_const_string(sub, strlen(sub), & index),
value);
}
/* array_set_numeric --- set an array element with a number */
static void
array_set_numeric(awk_array_t array, const char *sub, double num)
{
awk_value_t tmp;
array_set(array, sub, make_number(num, & tmp));
}The following function does most of the work to fill in the
awk_array_t result array with values
obtained from a valid struct stat.
This work is done in a separate function to support the stat() function for gawk and also to support the fts() extension, which is included in the same
file but whose code is not shown here (see File-Related Functions).
The first part of the function is variable declarations, including a table to map file types to strings:
/* fill_stat_array --- do the work to fill an array with stat info */
static int
fill_stat_array(const char *name, awk_array_t array, struct stat *sbuf)
{
char *pmode; /* printable mode */
const char *type = "unknown";
awk_value_t tmp;
static struct ftype_map {
unsigned int mask;
const char *type;
} ftype_map[] = {
{ S_IFREG, "file" },
{ S_IFBLK, "blockdev" },
{ S_IFCHR, "chardev" },
{ S_IFDIR, "directory" },
#ifdef S_IFSOCK
{ S_IFSOCK, "socket" },
#endif
#ifdef S_IFIFO
{ S_IFIFO, "fifo" },
#endif
#ifdef S_IFLNK
{ S_IFLNK, "symlink" },
#endif
#ifdef S_IFDOOR /* Solaris weirdness */
{ S_IFDOOR, "door" },
#endif /* S_IFDOOR */
};
int j, k;The destination array is cleared, and then code fills in various
elements based on values in the struct
stat:
/* empty out the array */
clear_array(array);
/* fill in the array */
array_set(array, "name", make_const_string(name, strlen(name),
& tmp));
array_set_numeric(array, "dev", sbuf->st_dev);
array_set_numeric(array, "ino", sbuf->st_ino);
array_set_numeric(array, "mode", sbuf->st_mode);
array_set_numeric(array, "nlink", sbuf->st_nlink);
array_set_numeric(array, "uid", sbuf->st_uid);
array_set_numeric(array, "gid", sbuf->st_gid);
array_set_numeric(array, "size", sbuf->st_size);
array_set_numeric(array, "blocks", sbuf->st_blocks);
array_set_numeric(array, "atime", sbuf->st_atime);
array_set_numeric(array, "mtime", sbuf->st_mtime);
array_set_numeric(array, "ctime", sbuf->st_ctime);
/* for block and character devices, add rdev,
major and minor numbers */
if (S_ISBLK(sbuf->st_mode) || S_ISCHR(sbuf->st_mode)) {
array_set_numeric(array, "rdev", sbuf->st_rdev);
array_set_numeric(array, "major", major(sbuf->st_rdev));
array_set_numeric(array, "minor", minor(sbuf->st_rdev));
}The latter part of the function makes selective additions to the destination array, depending upon the availability of certain members and/or the type of the file. It then returns zero, for success:
#ifdef HAVE_STRUCT_STAT_ST_BLKSIZE
array_set_numeric(array, "blksize", sbuf->st_blksize);
#endif /* HAVE_STRUCT_STAT_ST_BLKSIZE */
pmode = format_mode(sbuf->st_mode);
array_set(array, "pmode", make_const_string(pmode, strlen(pmode),
& tmp));
/* for symbolic links, add a linkval field */
if (S_ISLNK(sbuf->st_mode)) {
char *buf;
ssize_t linksize;
if ((buf = read_symlink(name, sbuf->st_size,
& linksize)) != NULL)
array_set(array, "linkval",
make_malloced_string(buf, linksize, & tmp));
else
warning(ext_id, _("stat: unable to read symbolic link `%s'"),
name);
}
/* add a type field */
type = "unknown"; /* shouldn't happen */
for (j = 0, k = sizeof(ftype_map)/sizeof(ftype_map[0]); j < k; j++) {
if ((sbuf->st_mode & S_IFMT) == ftype_map[j].mask) {
type = ftype_map[j].type;
break;
}
}
array_set(array, "type", make_const_string(type, strlen(type), & tmp));
return 0;
}The third argument to stat()
was not discussed previously. This argument is optional. If present, it
causes do_stat() to use the stat() system call instead of the lstat() system call. This is done by using a
function pointer: statfunc. statfunc is initialized to point to lstat() (instead of stat()) to get the file information, in case
the file is a symbolic link. However, if the third argument is included,
statfunc is set to point to stat(), instead.
Here is the do_stat() function,
which starts with variable declarations and argument checking:
/* do_stat --- provide a stat() function for gawk */
static awk_value_t *
do_stat(int nargs, awk_value_t *result)
{
awk_value_t file_param, array_param;
char *name;
awk_array_t array;
int ret;
struct stat sbuf;
/* default is lstat() */
int (*statfunc)(const char *path, struct stat *sbuf) = lstat;
assert(result != NULL);
if (nargs != 2 && nargs != 3) {
if (do_lint)
lintwarn(ext_id,
_("stat: called with wrong number of arguments"));
return make_number(-1, result);
}Then comes the actual work. First, the function gets the
arguments. Next, it gets the information for the file. If the called
function (lstat() or stat()) returns an error, the code sets
ERRNO and returns:
/* file is first arg, array to hold results is second */
if ( ! get_argument(0, AWK_STRING, & file_param)
|| ! get_argument(1, AWK_ARRAY, & array_param)) {
warning(ext_id, _("stat: bad parameters"));
return make_number(-1, result);
}
if (nargs == 3) {
statfunc = stat;
}
name = file_param.str_value.str;
array = array_param.array_cookie;
/* always empty out the array */
clear_array(array);
/* stat the file; if error, set ERRNO and return */
ret = statfunc(name, & sbuf);
if (ret < 0) {
update_ERRNO_int(errno);
return make_number(ret, result);
}The tedious work is done by fill_stat_array(), shown earlier. When done,
the function returns the result from fill_stat_array():
ret = fill_stat_array(name, array, & sbuf);
return make_number(ret, result);
}Finally, it’s necessary to provide the “glue” that loads the new
function(s) into gawk.
The filefuncs extension also
provides an fts() function, which we
omit here (see File-Related Functions). For
its sake, there is an initialization function:
/* init_filefuncs --- initialization routine */
static awk_bool_t
init_filefuncs(void)
{
…
}We are almost done. We need an array of awk_ext_func_t structures for loading each
function into gawk:
static awk_ext_func_t func_table[] = {
{ "chdir", do_chdir, 1 },
{ "stat", do_stat, 2 },
#ifndef __MINGW32__
{ "fts", do_fts, 3 },
#endif
};Each extension must have a routine named dl_load() to load everything that needs to be
loaded. It is simplest to use the dl_load_func() macro in gawkapi.h:
/* define the dl_load() function using the boilerplate macro */ dl_load_func(func_table, filefuncs, "")
And that’s it!
Integrating the Extensions
Now that the code is written, it must be possible to add it at
runtime to the running gawk
interpreter. First, the code must be compiled. Assuming that the
functions are in a file named filefuncs.c, and
idir is the location of the gawkapi.h header file, the following
steps[103] create a GNU/Linux shared library:
$gcc -fPIC -shared -DHAVE_CONFIG_H -c -O -g -I$idirfilefuncs.cgcc -o filefuncs.so -shared filefuncs.o
Once the library exists, it is loaded by using the @load
keyword:
# file testff.awk
@load "filefuncs"
BEGIN {
"pwd" | getline curdir # save current directory
close("pwd")
chdir("/tmp")
system("pwd") # test it
chdir(curdir) # go back
print "Info for testff.awk"
ret = stat("testff.awk", data)
print "ret =", ret
for (i in data)
printf "data["%s"] = %s
", i, data[i]
print "testff.awk modified:",
strftime("%m %d %Y %H:%M:%S", data["mtime"])
print "
Info for JUNK"
ret = stat("JUNK", data)
print "ret =", ret
for (i in data)
printf "data["%s"] = %s
", i, data[i]
print "JUNK modified:", strftime("%m %d %Y %H:%M:%S", data["mtime"])
}The AWKLIBPATH environment variable tells gawk where to find
extensions (see How gawk Finds Extensions).
We set it to the current directory and run the program:
$ AWKLIBPATH=$PWD gawk -f testff.awk
/tmp
Info for testff.awk
ret = 0
data["blksize"] = 4096
data["devbsize"] = 512
data["mtime"] = 1412004710
data["mode"] = 33204
data["type"] = file
data["dev"] = 2053
data["gid"] = 1000
data["ino"] = 10358899
data["ctime"] = 1412004710
data["blocks"] = 8
data["nlink"] = 1
data["name"] = testff.awk
data["atime"] = 1412004716
data["pmode"] = -rw-rw-r--
data["size"] = 666
data["uid"] = 1000
testff.awk modified: 09 29 2014 18:31:50
Info for JUNK
ret = -1
JUNK modified: 01 01 1970 02:00:00The Sample Extensions in the gawk Distribution
This section provides a brief overview of the sample extensions that
come in the gawk
distribution. Some of them are intended for production use (e.g., the
filefuncs, readdir, and inplace extensions). Others mainly provide
example code that shows how to use the extension API.
File-Related Functions
The filefuncs extension
provides three different functions, as follows. The usage is:
@load "filefuncs"result = chdir("/some/directory")The
chdir()function is a direct hook to thechdir()system call to change the current directory. It returns zero upon success or a value less than zero upon error. In the latter case, it updatesERRNO.result = stat("/some/path", statdata[, follow])The
stat()function provides a hook into thestat()system call. It returns zero upon success or a value less than zero upon error. In the latter case, it updatesERRNO.By default, it uses the
lstat()system call. However, if passed a third argument, it usesstat()instead.In all cases, it clears the
statdataarray. When the call is successful,stat()fills thestatdataarray with information retrieved from the filesystem, as follows:Subscript
Field in struct stat
File type
"name"The filename
All
"dev"st_devAll
"ino"st_inoAll
"mode"st_modeAll
"nlink"st_nlinkAll
"uid"st_uidAll
"gid"st_gidAll
"size"st_sizeAll
"atime"st_atimeAll
"mtime"st_mtimeAll
"ctime"st_ctimeAll
"rdev"st_rdevDevice files
"major"st_majorDevice files
"minor"st_minorDevice files
"blksize"st_blksizeAll
"pmode"A human-readable version of the mode value, like that printed by
ls(for example,"-rwxr-xr-x")All
"linkval"The value of the symbolic link
Symbolic links
"type"The type of the file as a string—one of
"file","blockdev","chardev","directory","socket","fifo","symlink","door", or"unknown"(not all systems support all file types)All
flags = or(FTS_PHYSICAL, ...)result = fts(pathlist, flags, filedata)Walk the file trees provided in
pathlistand fill in thefiledataarray, as described next.flagsis the bitwise OR of several predefined values, also described in a moment. Return zero if there were no errors, otherwise return −1.
The fts() function provides a
hook to the C library fts() routines for traversing file
hierarchies. Instead of returning data about one file at a time in a
stream, it fills in a multidimensional array with data about each file
and directory encountered in the requested hierarchies.
The arguments are as follows:
pathlistAn array of filenames. The element values are used; the index values are ignored.
flagsThis should be the bitwise OR of one or more of the following predefined constant flag values. At least one of
FTS_LOGICALorFTS_PHYSICALmust be provided; otherwisefts()returns an error value and setsERRNO. The flags are:FTS_LOGICALDo a “logical” file traversal, where the information returned for a symbolic link refers to the linked-to file, and not to the symbolic link itself. This flag is mutually exclusive with
FTS_PHYSICAL.FTS_PHYSICALDo a “physical” file traversal, where the information returned for a symbolic link refers to the symbolic link itself. This flag is mutually exclusive with
FTS_LOGICAL.FTS_NOCHDIRAs a performance optimization, the C library
fts()routines change directory as they traverse a file hierarchy. This flag disables that optimization.FTS_COMFOLLOWImmediately follow a symbolic link named in
pathlist, whether or notFTS_LOGICALis set.FTS_SEEDOTBy default, the C library
fts()routines do not return entries for.(dot) and..(dot-dot). This option causes entries for dot-dot to also be included. (The extension always includes an entry for dot; more on this in a moment.)FTS_XDEVDuring a traversal, do not cross onto a different mounted filesystem.
filedataThe
filedataarray holds the results.fts()first clears it. Then it creates an element infiledatafor every element inpathlist. The index is the name of the directory or file given inpathlist. The element for this index is itself an array. There are two cases:- The path is a file
In this case, the array contains two or three elements:
"path"The full path to this file, starting from the “root” that was given in the
pathlistarray."stat"This element is itself an array, containing the same information as provided by the
stat()function described earlier for itsstatdataargument. The element may not be present if thestat()system call for the file failed."error"If some kind of error was encountered, the array will also contain an element named
"error", which is a string describing the error.
- The path is a directory
In this case, the array contains one element for each entry in the directory. If an entry is a file, that element is the same as for files, just described. If the entry is a directory, that element is (recursively) an array describing the subdirectory. If
FTS_SEEDOTwas provided in the flags, then there will also be an element named"..". This element will be an array containing the data as provided bystat().In addition, there will be an element whose index is
".". This element is an array containing the same two or three elements as for a file:"path","stat", and"error".
The fts() function returns zero
if there were no errors. Otherwise, it returns −1.
Note
The fts() extension does not
exactly mimic the interface of the C library fts() routines, choosing instead to provide
an interface that is based on associative arrays, which is more
comfortable to use from an awk
program. This includes the lack of a comparison function, because
gawk already provides powerful
array sorting facilities. Although an fts_read()-like interface could have been
provided, this felt less natural than simply creating a
multidimensional array to represent the file hierarchy and its
information.
See test/fts.awk in the
gawk distribution for an example use
of the fts() extension
function.
Interface to fnmatch()
This extension provides an interface to the C library fnmatch() function. The usage is:
@load "fnmatch"This is how you load the extension.
result = fnmatch(pattern, string, flags)The return value is zero on success,
FNM_NOMATCHif the string did not match the pattern, or a different nonzero value if an error occurred.
In addition to the fnmatch()
function, the fnmatch extension adds
one constant (FNM_NOMATCH), and an
array of flag values named FNM.
The arguments to fnmatch()
are:
patternThe filename wildcard to match
stringThe filename string
flagEither zero, or the bitwise OR of one or more of the flags in the
FNMarray
The flags are as follows:
Array element | Corresponding flag defined by fnmatch() |
|
|
|
|
|
|
|
|
|
|
|
|
Here is an example:
@load "fnmatch"
…
flags = or(FNM["PERIOD"], FNM["NOESCAPE"])
if (fnmatch("*.a", "foo.c", flags) == FNM_NOMATCH)
print "no match"Interface to fork(), wait(), and waitpid()
The fork extension adds three
functions, as follows:
@load "fork"This is how you load the extension.
pid = fork()This function creates a new process. The return value is zero in the child and the process ID number of the child in the parent, or −1 upon error. In the latter case,
ERRNOindicates the problem. In the child,PROCINFO["pid"]andPROCINFO["ppid"]are updated to reflect the correct values.ret = waitpid(pid)This function takes a numeric argument, which is the process ID to wait for. The return value is that of the
waitpid()system call.ret = wait()This function waits for the first child to die. The return value is that of the
wait()system call.
There is no corresponding exec() function.
Here is an example:
@load "fork"
…
if ((pid = fork()) == 0)
print "hello from the child"
else
print "hello from the parent"Enabling In-Place File Editing
The inplace extension emulates
GNU sed’s -i option,
which performs “in-place” editing of each input file. It uses the bundled inplace.awk include file to invoke the
extension properly:
# inplace --- load and invoke the inplace extension.
@load "inplace"
# Please set INPLACE_SUFFIX to make a backup copy. For example, you may
# want to set INPLACE_SUFFIX to .bak on the command line or in a BEGIN rule.
BEGINFILE {
inplace_begin(FILENAME, INPLACE_SUFFIX)
}
ENDFILE {
inplace_end(FILENAME, INPLACE_SUFFIX)
}For each regular file that is processed, the extension redirects
standard output to a temporary file configured to have the same owner
and permissions as the original. After the file has been processed, the
extension restores standard output to its original destination. If
INPLACE_SUFFIX is not an empty
string, the original file is linked to a backup filename created by
appending that suffix. Finally, the temporary file is renamed to the
original filename.
If any error occurs, the extension issues a fatal error to terminate processing immediately without damaging the original file.
Here are some simple examples:
$ gawk -i inplace '{ gsub(/foo/, "bar") }; { print }' file1 file2 file3To keep a backup copy of the original files, try this:
$gawk -i inplace -v INPLACE_SUFFIX=.bak '{ gsub(/foo/, "bar") }>{ print }' file1 file2 file3
Character and Numeric values: ord() and chr()
The ordchr extension adds two
functions, named ord()
and chr(), as follows:
These functions are inspired by the Pascal language functions of the same name. Here is an example:
@load "ordchr"
…
printf("The numeric value of 'A' is %d
", ord("A"))
printf("The string value of 65 is %s
", chr(65))Reading Directories
The readdir extension adds an
input parser for directories. The usage is as follows:
@load "readdir"
When this extension is in use, instead of skipping directories
named on the command line (or with getline), they are read, with each entry
returned as a record.
The record consists of three fields. The first two are the inode number and the filename, separated by a forward slash character. On systems where the directory entry contains the file type, the record has a third field (also separated by a slash), which is a single letter indicating the type of the file. The letters and their corresponding file types are shown in Table 16-2.
Letter | File type |
| Block device |
| Character device |
| Directory |
| Regular file |
| Symbolic link |
| Named pipe (FIFO) |
| Socket |
| Anything else (unknown) |
On systems without the file type information, the third field is
always ‘u’.
Note
On GNU/Linux systems, there are filesystems that don’t support
the d_type entry (see the
readdir(3) manual page), and so the file type is
always ‘u’. You can use the
filefuncs extension to call
stat() in order to get correct type
information.
Here is an example:
@load "readdir"
...
BEGIN { FS = "/" }
{ print "filename is", $2 }Reversing Output
The revoutput extension adds a
simple output wrapper that reverses the characters in each output line. Its main purpose is to
show how to write an output wrapper, although it may be mildly amusing
for the unwary. Here is an example:
@load "revoutput"
BEGIN {
REVOUT = 1
print "don't panic" > "/dev/stdout"
}The output from this program is ‘cinap
t'nod’.
Two-Way I/O Example
The revtwoway extension adds a
simple two-way processor that reverses the characters in each line sent to it for reading back by the
awk program. Its main purpose is to
show how to write a two-way processor, although it may also be mildly
amusing. The following example shows how to use it:
@load "revtwoway"
BEGIN {
cmd = "/magic/mirror"
print "don't panic" |& cmd
cmd |& getline result
print result
close(cmd)
}The output from this program also is: ‘cinap t'nod’.
Dumping and Restoring an Array
The rwarray extension adds two
functions, named writea() and reada(), as follows:
@load "rwarray"This is how you load the extension.
ret = writea(file, array)This function takes a string argument, which is the name of the file to which to dump the array, and the array itself as the second argument.
writea()understands arrays of arrays. It returns one on success, or zero upon failure.ret = reada(file, array)reada()is the inverse ofwritea(); it reads the file named as its first argument, filling in the array named as the second argument. It clears the array first. Here too, the return value is one on success and zero upon failure.
The array created by reada() is
identical to that written by writea()
in the sense that the contents are the same. However, due to
implementation issues, the array traversal order of the re-created array
is likely to be different from that of the original array. As array
traversal order in awk is by default
undefined, this is (technically) not a problem. If you need to guarantee
a particular traversal order, use the array sorting features in gawk to do so (see Controlling Array Traversal and Array Sorting).
The file contains binary data. All integral values are written in network byte order. However, double-precision floating-point values are written as native binary data. Thus, arrays containing only string data can theoretically be dumped on systems with one byte order and restored on systems with a different one, but this has not been tried.
Here is an example:
@load "rwarray"
…
ret = writea("arraydump.bin", array)
…
ret = reada("arraydump.bin", array)Reading an Entire File
The readfile extension adds a
single function named readfile(), and
an input parser:
@load "readfile"This is how you load the extension.
result = readfile("/some/path")The argument is the name of the file to read. The return value is a string containing the entire contents of the requested file. Upon error, the function returns the empty string and sets
ERRNO.BEGIN { PROCINFO["readfile"] = 1 }In addition, the extension adds an input parser that is activated if
PROCINFO["readfile"]exists. When activated, each input file is returned in its entirety as$0.RTis set to the null string.
Here is an example:
@load "readfile"
…
contents = readfile("/path/to/file");
if (contents == "" && ERRNO != "") {
print("problem reading file", ERRNO) > "/dev/stderr"
...
}Extension Time Functions
The time extension adds two
functions, named gettimeofday() and
sleep(), as follows:
@load "time"This is how you load the extension.
the_time = gettimeofday()Return the time in seconds that has elapsed since 1970-01-01 UTC as a floating-point value. If the time is unavailable on this platform, return −1 and set
ERRNO. The returned time should have sub-second precision, but the actual precision may vary based on the platform. If the standard Cgettimeofday()system call is available on this platform, then it simply returns the value. Otherwise, if on MS-Windows, it tries to useGetSystemTimeAsFileTime().result = sleep(seconds)Attempt to sleep for
secondsseconds. Ifsecondsis negative, or the attempt to sleep fails, return −1 and setERRNO. Otherwise, return zero after sleeping for the indicated amount of time. Note thatsecondsmay be a floating-point (nonintegral) value. Implementation details: depending on platform availability, this function tries to usenanosleep()orselect()to implement the delay.
API Tests
The testext extension exercises
parts of the extension API that are not tested by the other samples. The extension/testext.c file contains both the C
code for the extension and awk test
code inside C comments that run the tests. The testing framework
extracts the awk code and runs the
tests. See the source file for more information.
The gawkextlib Project
The gawkextlib project provides a number of
gawk extensions, including one for processing XML files. This is the evolution of the original xgawk (XML gawk) project.
As of this writing, there are seven extensions:
errnoextensionGD graphics library extension
PDF extension
PostgreSQL extension
MPFR library extension (this provides access to a number of MPFR functions that
gawk’s native MPFR support does not)Redis extension
XML parser extension, using the Expat XML parsing library
You can check out the code for the gawkextlib project using the Git distributed source code control
system. The command is as follows:
git clone git://git.code.sf.net/p/gawkextlib/code gawkextlib-code
You will need to have the Expat XML parser library installed in order to build and use the XML extension.
In addition, you must have the GNU Autotools installed (Autoconf, Automake, Libtool, and GNU gettext).
The simple recipe for building and testing gawkextlib is as follows. First, build and
install gawk:
cd .../path/to/gawk/code ./configure --prefix=/tmp/newgawk Install in /tmp/newgawk for now make && make check Build and check that all is OK make install Install gawk
Next, build gawkextlib and test
it:
cd .../path/to/gawkextlib-code ./update-autotools Generate configure, etc. You may have to run this command twice ./configure --with-gawk=/tmp/newgawk Configure, point at ``installed'' gawk make && make check Build and check that all is OK make install Install the extensions
If you have installed gawk in the
standard way, then you will likely not need the
--with-gawk option when configuring gawkextlib.
You may need to use the sudo
utility to install both gawk and
gawkextlib, depending upon how your
system works.
If you write an extension that you wish to share with other gawk users, consider doing so through the
gawkextlib project. See the project’s
website for more information.
Summary
You can write extensions (sometimes called plug-ins) for
gawkin C or C++ using the application programming interface (API) defined by thegawkdevelopers.Extensions must have a license compatible with the GNU General Public License (GPL), and they must assert that fact by declaring a variable named
plugin_is_GPL_compatible.Communication between
gawkand an extension is two-way.gawkpasses astructto the extension that contains various data fields and function pointers. The extension can then call intogawkvia the supplied function pointers to accomplish certain tasks.One of these tasks is to “register” the name and implementation of new
awk-level functions withgawk. The implementation takes the form of a C function pointer with a defined signature. By convention, implementation functions are nameddo_for someXXXX()awk-level functionXXXX()The API is defined in a header file named
gawkapi.h. You must include a number of standard header files before including it in your source file.API function pointers are provided for the following kinds of operations:
Allocating, reallocating, and releasing memory
Registration functions (you may register extension functions, exit callbacks, a version string, input parsers, output wrappers, and two-way processors)
Printing fatal, warning, and “lint” warning messages
Updating
ERRNO, or unsetting itAccessing parameters, including converting an undefined parameter into an array
Symbol table access (retrieving a global variable, creating one, or changing one)
Creating and releasing cached values; this provides an efficient way to use values for multiple variables and can be a big performance win
Manipulating arrays (retrieving, adding, deleting, and modifying elements; getting the count of elements in an array; creating a new array; clearing an array; and flattening an array for easy C-style looping over all its indices and elements)
The API defines a number of standard data types for representing
awkvalues, array elements, and arrays.The API provides convenience functions for constructing values. It also provides memory management functions to ensure compatibility between memory allocated by
gawkand memory allocated by an extension.All memory passed from
gawkto an extension must be treated as read-only by the extension.All memory passed from an extension to
gawkmust come from the API’s memory allocation functions.gawktakes responsibility for the memory and releases it when appropriate.The API provides information about the running version of
gawkso that an extension can make sure it is compatible with thegawkthat loaded it.It is easiest to start a new extension by copying the boilerplate code described in this chapter. Macros in the
gawkapi.hheader file make this easier to do.The
gawkdistribution includes a number of small but useful sample extensions. Thegawkextlibproject includes several more (larger) extensions. If you wish to write an extension and contribute it to the community ofgawkusers, thegawkextlibproject is the place to do so.
[95] See the “cookie” entry in the Jargon file for a definition of cookie, and the “magic cookie” entry in the Jargon file for a nice example.
[96] This is more common on MS-Windows systems, but it can happen on Unix-like systems as well.
[97] Because the API uses only ISO C 90 features, it cannot make use of the ISO C 99 variadic macro feature to hide that parameter. More’s the pity.
[98] The difference is measurable and quite real. Trust us.
[99] Numeric values are clearly less problematic, requiring only
a C double to store.
[100] OK, the only data structure.
[101] It is also a “cookie,” but the gawk developers did not wish to
overuse this term.
[102] This version is edited slightly for presentation. See
extension/filefuncs.c in the
gawk distribution for the
complete version.
[103] In practice, you would probably want to use the GNU Autotools (Automake, Autoconf, Libtool, and
gettext) to configure and build
your libraries. Instructions for doing so are beyond the scope of
this book. See The gawkextlib Project for Internet links to
the tools.