
Chapter 4. Packaging your enterprise OSGi applications
This chapter covers
- The limitations of JARs and bundles for packaging large applications
- How enterprise OSGi applications can be packaged as a single unit
- Other solutions to the OSGi application packaging problem
- How to package your sample application as a single deployable unit
Over the past couple of chapters you’ve put together an application consisting of a number of application bundles. As the number of bundles increased, it’s quickly become unmanageable when you try to deploy it. Even with only a simple web frontend and the persisted backend that you added in the last chapter, the application has seven bundles to remember to install. It’s time to look at how you can package your application in a more convenient form.
Packaging an application has changed over time, in much the same way as writing an application has. Originally programs were small, and could easily be packaged as a single binary file. As programs grew in complexity, they also grew in size and were split into a number of discrete units, usually based on function. As Java developers, you’ll already be familiar with the concept of a JAR file and should also understand the structure of an OSGi bundle.
JARs and bundles are examples of coarse-grained packaging but, as you have already seen, they aren’t coarse enough to describe an entire application. Most of this chapter is dedicated to describing application packaging concepts. With an understanding of the basic concepts behind enterprise OSGi application packaging, it becomes a straightforward exercise to package any application. To start with, let’s try to understand the problem that application packaging is trying to solve. Why do you need something bigger than a bundle?
4.1. The need for more than modules
The OSGi specifications have described the interactions of bundles as a means for packaging code for many years, and before that the Java JAR specification defined a mechanism by which groups of classes could be delivered in a single unit. As a specialization of a JAR file, an OSGi bundle offers no greater structure than is present in Java SE. A single binary file may contain many classes or resources, logically arranged into packages, but it represents the largest packaging unit that can be deployed.
Because of their complex requirements and core business value, enterprise applications are usually quite large, and often are developed by distributed teams. Even if the entire development team works in the same location, in order for them to work effectively, it’s typical to develop the application as a set of modules (JARs) rather than as a single monolithic unit.
It’s almost certain that there will be classes that need to be shared between the individual modules of the application, but shouldn’t be shared with other applications. If application internals are allowed onto the classpath of other applications, the encapsulation of the application as a whole will be poor, even if the individual bundles are nicely encapsulated. Multibundle applications can also behave unpredictably in multitenanted systems. Applications may also get inappropriate visibility of utility libraries from other applications. If the versions are incompatible, or if state is stored statically, this classpath contamination can have disastrous effects that surface only in production.
As you learned in chapter 1, modularity is good, and so it would be a shame to collapse that complex enterprise application back into a single JAR file to distribute it and ensure encapsulation. Java EE recognized this problem early in its development, and created the Enterprise Archive (EAR).
4.1.1. Java EE applications
In the simplest sense, Java EE EARs can be thought of as bigger versions of Java SE JARs. EARs are in zip format, like JARs, but rather than containing Java classes, they contain enterprise modules such as WARs and EJB JARs. One other key difference between EARs and JARs is that an EAR contains an application descriptor called META-INF/application.xml rather than a standard manifest.
Listing 4.1. A simple application.xml

The application XML descriptor in listing 4.1 shows how a Java EE EAR provides a complete list of the content of the application (the WARs, EJBs, and library JARs that make up the application) and it can also contain security metadata. While it’s possible for the application.xml to reference a module that isn’t contained directly within the EAR, this is an extremely uncommon practice. Often the application.xml is used to do no more than restate the contents of the EAR and to provide context roots for any web modules.
Starting with Java EE 5, the application.xml descriptor became optional, only being specified if you needed to override any defaults. This helps to reduce the duplication typically present in the EAR metadata as modules inside an EAR no longer need to be listed in application.xml as well.
The Problem with Ears
Although they add a different level of granularity to Java, EARs don’t do much to help with Java modularity. EARs have no practical way to declare dependencies except to package all their required JARs inside themselves. This leads to big EARs! Carrying all your dependencies around with you is a blunt mechanism for dependency management, and it can cause considerable bloat at runtime. An application server can end up hosting many redundant copies of common libraries, one for each application.
A Java EE application server represents a large investment of money and computing resources, so they’re typically used to run a number of applications. As you can see from figure 4.1, when two applications make use of the same library, which happens quite a lot, they end up running side by side. In the worst cases, the modules within an EAR will also package duplicate libraries, and without careful management when packaging this can lead to considerable bloat.
Figure 4.1. Duplication of common libraries between EARs

Some application servers have added extensions to allow libraries to be shared between Java EE applications, but these extensions are unique to each vendor. EARs with shared library dependencies are therefore necessarily less portable than their bulkier self-contained equivalents. Installing such an EAR involves an extra set of vendor-specific installation steps. (“Make sure there is a copy of something.jar in lib, unless you’re on this other application server, in which case it’s the ext folder it needs to be copied to.”) Added to this complexity, there’s no way of knowing what the shared dependencies of an EAR are except through documentation. If the documentation is incomplete or missing, the application will probably deploy without error only to fail with an unpleasant ClassNotFoundException at runtime. Some missing dependencies might not be discovered until well into production.
Even if all the shared dependencies of an EAR are identified and installed, success isn’t guaranteed. What happens when different applications on the same server require different versions of the same common library? If the packages and class names are the same, one version will always come before the other one on the classpath. If the two versions have different sets of capabilities—or different sets of bugs—there may be runtime problems which are quite tricky to debug. The only solution for this problem is to repackage, redesign, or re-engineer the EARs and move the right version of each shared library back into an EAR. This can be particularly problematic for modules that you don’t have the source for.
4.1.2. Enterprise OSGi applications
In Java EE, the application packaging role is fulfilled by the EAR. Until recently, in OSGi there was no similar concept; application packaging units began and ended with bundles. As we’ve already mentioned, bundles aren’t a suitable packaging unit for large-scale applications. A typical application will be developed as several bundles, each with a well-defined API. In a standard OSGi framework, these bundles will need to be individually installed, which is far from ideal.
The lack of an aggregate deployment artifact in core OSGi is only one of its limitations. As we’ve previously discussed, OSGi provides an excellent platform for sharing code between different applications; however, because you never know what other bundles you might find in a framework, you often have no choice but to send all the bundles you might need to the application deployer, even though many of them may not be needed at runtime.
One final problem with enterprise OSGi application packaging is that it’s possible to have too much sharing! While sharing common APIs and libraries is a good idea, there are some parts of an application that are distinctly private. This may seem counterintuitive at first, but an enterprise OSGi application is a bit like a larger version of an OSGi bundle where, instead of packages, you have modules. Some modules you’re happy to have provided to you, like a bundle importing a package; some modules you’re happy to provide to the outside world, like a bundle exporting a package. Most importantly, there are some modules (like your internal payment processing implementation) that you don’t want other applications to be able to use! Application multitenancy is awkward in core OSGi frameworks, because there’s only one level of granularity.
Don’t let the previous paragraphs put you off. It’s true that enterprise OSGi has some hurdles to overcome when it comes to application packaging, but as with many other problems in software engineering, there are some interesting solutions in open source, and useful new specifications. Let’s start with a new standard for application packaging: subsystems.
4.2. Enterprise OSGi subsystems
OSGi subsystems are a new concept in release 5 of the OSGi Enterprise Specification. Subsystems are a more general concept than OSGi applications, which is why they’re called subsystems, and not applications! Although they solve many of the same problems, subsystems are also definitely more than an OSGi equivalent to EARs. Subsystems are nestable collections of bundles with a shared lifecycle. The subsystem contents can be packaged into an archive with a .esa extension, and so we’ll refer to them as Enterprise Subsystem Archives (ESAs).
Like an EAR, an ESA contains metadata describing the contents of an application and how it should be deployed; however, unlike an EAR, the metadata for an ESA uses a configuration by exception model, and so is entirely optional. Even the metadata file may be omitted if no defaults need to be changed.
There are three distinct kinds of subsystems: applications, features, and composites. All represent collections of bundles, but how permeable the boundaries are varies.
4.2.1. ESA structure
One of the most important details about an application packaging model is the structure it places on the application. If the structure is too loose or complex, then the applications are usually hard to generate, requiring special tools, or they become impossible to understand for anything but simple examples. On the other hand, if an application’s structure is too rigid, then it can end up being rather cumbersome and inflexible. The latter has plagued the EAR file format, requiring large monolithic files with redundant metadata.
In many senses, an ESA file is a lot like an EAR file. An ESA is a zip format archive that contains metadata in the form of an application manifest, and it also contains OSGi bundles in the root of the zip archive. An ESA file does differ from an EAR in structure in two key ways:
- Unlike an EAR file, the metadata for an ESA doesn’t need to be complete. Every piece of ESA metadata has a default value that’ll be used unless it’s overridden. This defaulting is so extensive that the metadata for an ESA may be omitted entirely if the defaults are acceptable.
- As we mentioned in section 4.1.1, an EAR almost always contains the entire content of the application, including shared libraries. An ESA can contain all the bundles needed to run the application but, commonly, only a small subset of the bundles that make up the application are included in the ESA. The remaining bundles are then provisioned from a bundle repository when the application is installed. We’ll talk about this more in section 4.2.5.
As you can see from figure 4.2, the structure of an ESA is similar to an EAR, but because the ESA doesn’t need to package all of its dependencies, the file is much smaller. In addition, the reduced number of modules in the ESA makes it simpler to understand—there are fewer unimportant dependencies to wade through.
Figure 4.2. An EAR and an ESA representing the same application. The EAR must include all its component JARs and all the libraries it depends on. The ESA, on the other hand, need only include its component bundles, and even those may be loaded by reference from a bundle repository.

Although the metadata is optional in general, it’s important to support applications that don’t contain all their modules.
4.2.2. Subsystem metadata
The metadata in an ESA is similar to that of an EAR, but specified differently. The first key difference is that ESA metadata isn’t stored as XML, as in an EAR, but using the Java manifest syntax in a file called META-INF/SUBSYSTEM.MF. This file defines the name and version of the application, which default to the name of the archive file and 0.0.0, and a human-readable description. Importantly, the subsystem manifest also defines the bundles that make up the core content of the subsystem, and any services that should be exposed or consumed by the application. For example:
Subsystem-ManifestVersion: 1
Subsystem-Name: The Fancy Foods online superstore
Subsystem-SymbolicName: fancyfoods.application
Subsystem-Version: 1.0
Subsystem-Content:
fancyfoods.api; version="[1.0.0,2.0.0)",
fancyfoods.business; version="[1.0.0,2.0.0)",
fancyfoods.web; version="[1.0.0,2.0.0)",
fancyfoods.department.chocolate; version="[1.0.0,2.0.0)",
fancyfoods.department.cheese; version="[1.0.0,2.0.0)",
fancyfoods.persistence; version="[1.0.0,2.0.0)",
Subsystem Content
The core content of an application isn’t an idea that exists in Java EE or standard OSGi, and so it’s something many people find slightly unnerving. The concept is simple: the core content represents the bundles that provide the application’s function, rather than common libraries, logging utilities, and so on. For most people, the core content of the application is exactly what they’d describe if asked what was inside their EAR; however, the EAR also has to include libraries and other dependencies and describe them in the application.xml descriptor. Unlike an EAR, the core content of an ESA need not (and usually doesn’t) represent the complete set of bundles that should be installed to run the application.
The core content of an ESA is selected using the Subsystem-Content: header in the application manifest:
Subsystem-Content: fancyfoods.web;version="[1.1.0,2.0.0)",
fancyfoods.department.chocolate;version="[1.0.0,2.0.0)
Core content may be declared optional.
Aside from not specifying the complete set of modules, there’s one other big difference between ESA metadata and EAR metadata. The content of an ESA subsystem selects bundles using their symbolic name and an OSGi-style version range. This means that the same OSGi subsystem may run different bundles over the course of its life! Because the metadata has a degree of flexibility built in, it allows the application to be updated with service fixes without being repackaged. This is a significant advantage over the static model used by EARs, which require a whole new application to be generated for even a minor update. When selecting by version range, the bundle used may be contained within the root of the ESA, like a module in an EAR file, or refer to a bundle within a bundle repository. In fact, unlike a typical EAR file, it’s likely that an ESA file won’t contain most of the modules that it needs. We’ll discuss more about bundle repositories, version ranges, and dependencies when we look at provisioning and resolution, but first we should take a brief look at scoping and subsystem types.
Subsystem Types and Scoping
We mentioned earlier that there are three distinct types of subsystems: applications, features, and composites. Application is the default, but other types may be selected using a Subsystem-Type: header. For example, to declare a feature, the header would be this:
Subsystem-Type: osgi.subsystem.feature
An application doesn’t export anything to the outside framework, but its contents have free access to the outside. A feature is designed for sharing, so it’s totally unscoped. Not only can its bundles see everything in the outside framework, the outside world can see all the bundles in the feature. A composite is a group of bundles that behaves like a single bundle; everything is private to the composite unless explicitly exported, and external dependencies must be explicitly imported.
The type of a subsystem also affects how its content is handled. A feature has complete visibility of the outside framework, so there’s no need to add content inside the feature beyond what’s already included. Composites and applications are less porous, and so it’s meaningful to ask what’s inside the subsystem and what’s in the outside framework. A provision-policy:=acceptDependencies directive may be added to the Subsystem-Type declaration. This tells the system that explicit content and indirect dependencies should be treated as part of the subsystem.
Stepping back, if content and dependencies aren’t packaged up in the ESA archive, where do they come from? So far you haven’t seen anything in the application manifest that shows how you cope when an ESA doesn’t contain all the bundles it needs. There’s a good reason for this, which is that none of this information is stored in the application metadata at all! To be run in an enterprise OSGi runtime, an ESA needs to undergo a process called deployment, where two important things happen: provisioning and resolution.
4.2.3. Provisioning and resolution
Provisioning and resolution are two different, but related, steps that are taken when deploying an enterprise OSGi application. Though both steps can occur independently, they’re often performed simultaneously. Unfortunately, this often leads to some confusion about the difference between provisioning and resolution, with many people thinking the terms are interchangeable names for the same thing. For simplicity’s sake, we’ll attempt to separate the two operations from one another as much as possible; however, it will be pretty clear that the most useful applications will rely upon the interplay between the provisioner and resolver. We’ll also come back to provisioning and resolution in chapter 7.
Provisioning
Fundamentally, provisioning is a relatively simple operation, but because it isn’t part of the Java EE application model it’s not immediately comfortable for many developers. Provisioning is a little more common in standard OSGi, but it’s still not a process that many OSGi developers would think about in detail. At its most basic, provisioning is the operation by which modules are located and deployed into the correct location.
Because Java EE EARs package all their modules inside themselves, provisioning isn’t necessary. The code needed to run the application is either available as a module within the EAR or from the application server itself. Nothing needs to be fetched from anywhere. As we’ve already discussed, ESAs are a bit different. Although an ESA may contain all the modules it needs, it will more commonly refer to bundles that aren’t contained inside it. It won’t be possible to run an OSGi application without having all of the bundles that it needs, so as part of the ESA deployment process it’s necessary to locate and obtain any bundles that aren’t already inside the ESA. This process typically makes use of one or more bundle repositories to locate and download the bundles that are needed (see figure 4.3).
Figure 4.3. This subsystem refers to two bundles, both of which are available in the repository, but one of which is present in the ESA at a higher version. The higher-version bundle from the ESA is used at runtime, but the other bundle is provisioned from a remote location found in the repository.
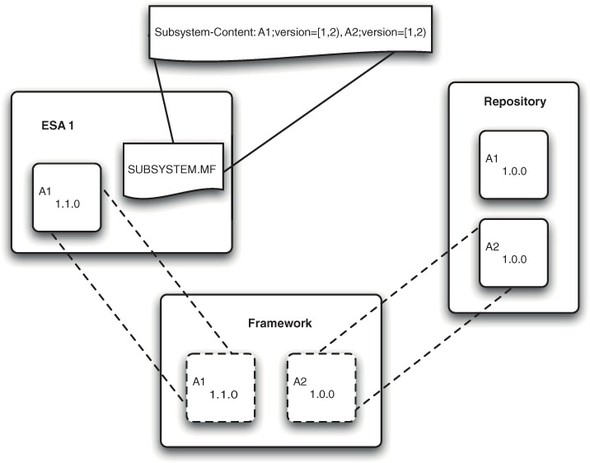
For a typical enterprise OSGi application, one or more bundles will need to be downloaded as part of the deployment operation. This means that there needs to be some way of uniquely identifying the bundle and finding out where it can be downloaded from. Fortunately, OSGi provides a symbolic name for each bundle that, in conjunction with a version, uniquely identifies a particular bundle. A simple bundle repository can therefore be thought of as being a bit like an organized music store; you can search for music by a particular artist, and then pick a particular song. The store will then present you with a URL from which you can start downloading the song.
Version Ranges, Undeclared Dependencies, and Provisioning
We’re sure you’ll agree that provisioning is, at its heart, a fairly simple process. Why do so many people find it confusing? To start with, the example above is rather simplified! Provisioning an ESA that exactly specifies the symbolic names and versions of all the bundles it needs is indeed easy. In the real world, ESAs don’t express themselves like this.
The most common reason that bundles can’t be provisioned is because the bundles in an ESA aren’t normally specified with an exact version. In fact, the ability to specify bundles with a version range is a key advantage of ESA metadata. If a range of versions is acceptable, it isn’t possible to look for a single bundle in a repository. In this case, you could make the simplifying assumption that you want the highest available version of the bundle that fits within the version range, but what do you do about the dependencies of an ESA that aren’t directly declared? For example, what happens when packages are imported by bundles inside the ESA? Even the symbolic name of the providing bundle won’t be known!
One of the key drivers for the adoption of OSGi is classpath hell; it’s difficult in Java SE and Java EE to know what classes you need and which JAR provides them. OSGi bundles are different: they define their imports and exports, making it clear whether the bundle will work at runtime. Unfortunately, the number of packages imported by a bundle can be large (although it usually isn’t for a well-written bundle) and it isn’t always easy to find a bundle that exports them. Even when you have found a bundle that supplies the required package, you also have to satisfy any packages requirements that the bundle has! This process can be long and difficult, and it would be annoying to have to do it manually for anything other than a trivial example. This problem illustrates the need for the resolution stage of an enterprise OSGi application deployment.
Resolution
As with a provisioner, the fundamental job of a resolver isn’t difficult to describe, but it’s a concept that doesn’t exist in Java EE or Java SE and so can be quite confusing for developers with those backgrounds when they first encounter it. OSGi developers, on the other hand, are familiar with the resolution process, even if they’ve never used a resolver to help them with it. This is because all OSGi bundles must be resolved within a runtime framework before they can be used. If you’re still a little rusty about the OSGi classloading model and the bundle resolution process, it would be a good idea to get comfortable with section A.4.3 of appendix A before continuing here.
At the core of the resolution phase of ESA deployment is a single goal: to identify the set of bundles that need to be installed to satisfy the dependencies of this application. Without running through a resolution phase first, one of two things will happen to an ESA when it’s started:
- If the ESA has no missing dependencies in its metadata, then it will already successfully resolve within the runtime. In this case, you’re lucky and the application will work correctly when it’s started.
- In the more common case where an ESA has external dependencies that aren’t specified in the application manifest, for example, on a common utility library, the application won’t be deployed properly. At the point the application is started, one or more of the application bundles won’t be able to be resolved by the OSGi framework. These unresolved bundles won’t be able to start, and the application won’t work correctly.
In Java EE it would be almost impossible to identify missing dependencies in advance of a runtime failure; however, all OSGi bundles provide a detailed description of not only their dependencies, but also the capabilities they provide. Using this metadata, a resolver can identify all of the dependencies of the bundles within an ESA, find which dependencies are satisfied internally within the ESA, and then locate other bundles that satisfy any remaining dependencies.
Interacting with the provisioner
When the resolver is processing the application content of an ESA, it needs to know which bundles to look at, and what their bundle metadata is, to find out their dependencies. This is the point at which resolution and provisioning can become quite intertwined, and is the reason why many people struggle to understand the difference. If an ESA specifies a version range for its application content, then how are you ever going to find its dependencies—you don’t even know which bundles to start with!
The notion of a missing dependency is a little subjective. It boils down to your interpretation of what makes up the application and what makes up your server runtime. At its heart, a missing dependency is a package import, or for servers that offer OSGi service–based provisioning, a service dependency, made by a Subsystem-Content bundle that isn’t satisfied by another bundle within the subsystem content. Some people argue that if this dependency is supplied by the server runtime rather than a shared library bundle, then the dependency isn’t missing; however, as server runtimes differ, a dependency may be missing on one server but not on another. This scenario is the main reason that even though ESAs are portable artifacts, they still have to be redeployed if moved to a different server environment.
In essence, the resolver and the provisioner have to work together to provide a deployment for an ESA. The resolver typically only needs access to the metadata for a bundle, not the entire archive, so a typical resolver will generate a model from the metadata of the bundles available in a repository. This is a comparatively small amount of information, but provides the resolver with a complete description of all the bundle dependencies. The resolver can then use this information to calculate a resolved set of bundles for the ESA. This will include all of the application content bundles and any other bundles obtained via a repository to match missing dependencies (see figure 4.4). It’s possible that the resolver won’t be able to find a set of bundles that has no missing dependencies, or even that it won’t be able to locate one of the application content bundles. This is known as a resolution failure, and indicates that the ESA can’t be deployed successfully. Resolution failures can typically be fixed either by adding missing bundles to the ESA archive, or preferably for shared bundles, by adding them to a bundle repository against which the ESA is being resolved.
Figure 4.4. If you want to install this application bundle into a framework, then you need to ensure that the fancyfoods.logging package is available. This is provided by a bundle that has a dependency on the common.logging.framework package, which must also be satisfied by the resolution process. In this case, you pull in a third bundle that can supply the package and has no further missing dependencies.
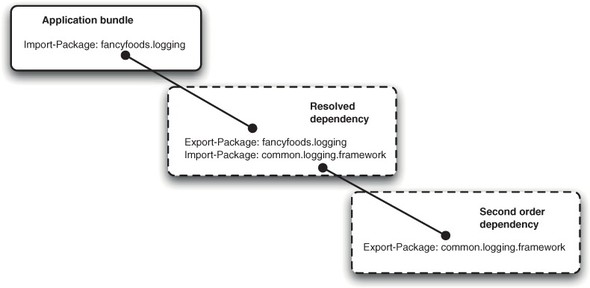
When an ESA can be successfully resolved, you find that there’s another constraint on the versions of bundles that make up the application content—it makes sense to take a version of a bundle that can resolve. Rather than selecting the highest version of a bundle that fits into the required range, deployments will select the highest version of the bundle that can be resolved given the other bundles known to the resolver. Having selected the bundles that are to be deployed, the result of the resolution is then passed to the provisioner. At this point, the provisioner can download all the bundles needed to run the ESA and the flexibility of the application manifest is collapsed into a single, repeatable deployment. (To ensure the deployment is repeatable, it’s stored as a DEPLOYMENT.MF file.) This means that there’s no risk of the application installing different bundles into the framework each time it’s started, which would make problems hard to debug!
The version ranges used in ESAs are important, and as with any version range we strongly advise the use of semantic versioning to limit the range of acceptable bundles. For example, you may require a particular bug fix, establishing a micro version minimum, and wish to avoid function creep, with version="[1.0.3,1.1.0)". Other applications may be a little looser and choose to allow functional enhancements. Critically, regardless of the version range you provide, after the application is deployed, a single version has been selected in the resolution phase. This is the bundle that will be used when running the application. Some runtimes will let you reresolve a deployed application to pick up updates, selecting a new fixed bundle version that will be used from then on.
As you’ve now seen, the interplay between provisioning and resolution can be quite involved, which is one of the main reasons that so many people struggle to differentiate the two processes. If you find yourself a little confused, remember the following: Provisioning is about locating and downloading bundles that aren’t contained in the ESA. Resolution is about determining what additional bundles are needed to make the application content work at runtime.
Because subsystems were introduced after a number of alternate solutions such as EBAs, PARs, and Karaf features had already been developed, it may take a while for the fragmentation in this area to be eliminated. The OSGi subsystems specification standardizes many of the best bits of the earlier OSGi application models. We’ll consider these alternatives in sections 4.3 and 4.4. (In case you’re wondering, subsystems were also introduced after the first draft of this book was complete. This is the challenge of writing about exciting emerging technologies!) Subsystems implementations are being developed as we write, but it will take time for them to be finished. We expect support for plans, PARs, Karaf features, and EBAs will continue for some time, even after portable subsystems implementations have been released.
4.3. The Enterprise Bundle Archive (EBA)
Apache Aries defines a concept similar to the ESA called the Enterprise Bundle Archive (EBA). The design of the EBA was one of the principal inspirations for the subsystems specification. If you understand subsystems, you’ll understand a lot about EBAs by swapping the word subsystem for the word application. EBAs are packaged in .eba files, and the metadata is defined in an optional APPLICATION.MF file.
The headers are similar as well. For example, the core content of an EBA is selected using the Application-Content: header in the application manifest:
Application-Content: fancyfoods.web;version="[1.1.0,2.0.0)",
fancyfoods.department.chocolate;version="[1.0.0,2.0.0)"
Like ESAs, EBAs may use a version range for the content bundles. Although ESAs can nest other ESAs, EBA content is restricted to bundles. The implications of being listed in the Application-Content: header are also different for EBAs.
4.3.1. Sharing and isolation
Although in general EBAs are similar to ESAs, one area where they differ significantly is scoping and isolation. Whereas ESAs offered lots of flexibility in terms of how content was scoped—with applications, features, and composites as precanned variants—options for EBAs are more limited.
As well as minimizing the amount of extra information that you need to supply when writing the metadata, the Application-Content: header has an important role to play in the structure of an enterprise OSGi application. The application content represents the core of an application, and will include APIs and services that the modules use to communicate with each another, but that aren’t intended for public use. In Java EE this is accomplished by completely separating all parts of the applications. Enterprise OSGi could do the same thing by creating a separate OSGi framework for each application, but this would prevent any level of sharing or reuse within the runtime, essentially eliminating many of the advantages you switched to OSGi for in the first place!
Laying out the guts of your application for all the world to see isn’t a good idea, but you don’t want to hide everything else that could be shared, either. Fortunately, in enterprise OSGi you don’t have to do either. The Application-Content: header of an EBA also defines the isolated content of the application. Isolated content is about as simple as it sounds; the isolated bundles can see each other, but can’t be seen by shared bundles or by other applications. The clever part is that, because of the loose coupling that OSGi provides, the isolated bundles can still import packages from the shared bundles. This means that shared code can contribute packages to multiple applications, but your payment processing system can only be seen by your online store web application (see figure 4.5). This is identical to the application semantics for subsystems.
Figure 4.5. Isolation allows both Application 1 and Application 2 to share code with a single instance of a shared bundle without exposing their internal bundles.

But Aries EBAs don’t have the notion of features or composites. They also don’t have any option to accept dependencies; all dependencies listed in the Application-Content: header are included in the application, whether they were packaged in the application archive or not. All dependencies not included in the core content are considered to be shared and scoped outside the application, in the shared outer framework.
Bundles can be isolated from one another in several ways, with various advantages and drawbacks. From an application perspective, the mechanism by which isolation is achieved is relatively unimportant; the key detail is that services and packages exposed by isolated bundles can only be used by other isolated bundles in the same application.
You’ll see an example of using an Aries application in section 4.5, but first we’ll consider some of the other technologies that were also developed before OSGi subsystems.
4.4. Alternative approaches
The main focus of this chapter is the use of the EBA as a packaging model for enterprise OSGi, and the EBA will remain the application artifact for the rest of this book. Clearly you’re keen to start packaging up your example application as soon as possible, but it wouldn’t be fair to continue without at least briefly discussing some of the alternative application packaging approaches that have been offered for OSGi.
4.4.1. Spring plan and PAR files
The SpringSource dm Server runtime, which has now become the Eclipse Virgo project, was one of the first server runtimes that could host OSGi applications, and so it also encountered the limitations of the OSGi bundle as an artifact for application packaging. The first versions of dm Server allowed applications to be deployed as a PAR file.
The PAR
In many senses a PAR file is like an EBA: it’s a JAR file archive that contains a collection of OSGi bundles. In a way similar to an EBA, the PAR file defines an application scope. When the bundles in a PAR are deployed into an OSGi framework, they’re isolated from other bundles in the runtime. Where the PAR file differs from the EBA is as follows:
- A PAR file doesn’t provide metadata to allow bundles to be provisioned from elsewhere; they must be contained within the PAR file, increasing its size.
- When a PAR file is deployed into an OSGi framework, it doesn’t allow for shared content to be deployed around it.
- Missing dependencies within a PAR aren’t guaranteed to be satisfied when it’s installed; this means that the only safe way to write a PAR that’s portable across runtimes would be to contain all of your dependencies.
In an effort to improve upon the PAR file, later versions of dm Server added support for a new application descriptor known as a plan file.
The Plan File
To maintain a level of backward compatibility with PAR files, and to reduce cognitive load on developers, a plan file is similar in concept to a PAR file, and also to an EBA. Compared to a PAR file, though, a plan file goes to the opposite extreme, so where a PAR file must contain all its bundles, a plan file contains none!
A plan file is an XML descriptor for an OSGi application that has a .plan extension. Like a PAR file, it describes a collection of bundles; however, a plan file may also refer to other plan files or PAR files as sources of content. Plan files also loosen the scoping restriction of PAR files, in that a plan file need not isolate its bundles within the OSGi framework.
Interestingly, a plan file shares many characteristics with an EBA, but different ones than a PAR file shares with an EBA. Several key differences are these:
- A plan file doesn’t provide any mechanism to allow bundles to be provided within the archive. All bundles, no matter how private, esoteric, or customized, must be made available in a centralized repository, either as the bundle itself, or within a PAR. There’s also no way to easily provide a single artifact to machines with limited network connectivity.
- When a plan file is deployed into an OSGi framework, it may define shared content and use PAR files to provide isolated sections of the application, but this does require the generation of multiple deployment artifacts.
- Like a PAR file, a plan file provides no guarantees that missing dependencies will be satisfied when it’s installed. Any dependencies must be listed at some scope within the application. This approach is brittle because you must encode the name of the bundle that provides your dependency, rather than the packages that need to be provided.
PAR files and plan files are, in many ways, similar to the EBA model, and in combination can be used to achieve almost identical results to EBA deployment. There are a few ways to look at this. One mean-hearted way to look at it is to say that the EBA was a case of not invented here syndrome; another, slightly kinder, viewpoint would be that an EBA is a restatement of PAR and plan files to provide all the benefits within a single packaging. In our (not completely unbiased) perspective, we suggest that there’s one other EBA idiom that’s completely absent from the PAR/plan model, which is the concept of inclusion by version range. Both PAR and plan files require you to specify specific versions at development time. There’s no flexibility for future bug fixes or feature enhancements. New code can’t be delivered as a new bundle, only as a completely new application.
SpringSource dm Server/Eclipse Virgo isn’t the only OSGi application platform available that doesn’t make use of EBA packaging. Another popular platform is Apache Karaf, with its feature model.
4.4.2. Apache Karaf features
Karaf features are another way of describing an OSGi application, and are rather similar to a plan file from Spring dm Server. Like plan files, Karaf features use XML to describe the set of modules that are to be deployed. One key difference between Karaf features and the other application packaging artifacts we’ve been looking at is that a single XML file may define multiple features (applications). Even more flexibly, features can depend on other features. These things are definitely not possible in Java EE EARs.
Because of their ability to define multiple features, Karaf features are sometimes referred to as repositories. Each feature in the repository defines the bundles that should be installed to activate the feature, because with plan files, the bundles are referred to directly with no version range. One advantage of features over plan files is that the bundles are defined as references within a Maven repository. The modules referred to don’t even have to be bundles; native JAR files can be automagically wrapped into OSGi bundles.
Although wrapping a JAR might seem like the best feature in the world, allowing the benefits of OSGi without any effort from the developer, it should be noted that there are some big drawbacks. Automatic wrapping of bundles means there’s no way to distinguish an API from internals, so it typically exposes everything from the JAR. It’s also difficult to determine the dependencies of an arbitrary JAR file, so the imports for a wrapped bundle aren’t always correct. Automatic wrapping also has no context for determining the versions at which packages should be exported, nor the version ranges that should be used for imports. Finally, wrapping a JAR at runtime leaves no way to determine dependencies ahead of time; there’s no possibility of a resolution phase, so whether your application can run is a crapshoot.
In summary:
- Karaf features are simple XML files and so don’t provide any mechanism to allow bundles to be provided within the archive. Bundles are expected to be retrieved from a Maven repository, or a repository available to the rest of the server runtime.
- Karaf features offer no real concept of scoping; applications share the same OSGi framework for all their bundles, allowing for unforeseen interactions when new applications are deployed.
- Like a plan file, a Karaf feature provides no guarantees that missing dependencies will be satisfied when it’s installed and you must encode the name of the bundle that provides your dependency. Adding wrappered JAR files provides yet further uncertainty because it isn’t clear what packages are needed or exported.
We believe that as implementations of the subsystems specification become available, the amount of fragmentation in the area of OSGi application packaging will reduce. But it may take a while because technologies are a bit like genies—it’s hard to make them go away once they’ve been released! Although we think subsystems are the future of OSGi applications, we expect you want to try something out now. At the time of writing, Apache Aries is working on a subsystems implementation, but none have been released. But EBAs provide a good alternative. We hope it’s clear to you what the advantages of an EBA are over the other models we’ve discussed, primarily around flexibility of management. Although the names have changed round, EBAs are also the starting point for subsystems, so time spent understanding EBA concepts won’t be wasted. For now, we’ve spent enough time discussing what an EBA is, and we’re ready to package our superstore application as an EBA.
4.5. Developing an enterprise OSGi application
Having learned about application packaging, and particularly about the EBA packaging model for enterprise OSGi applications, it’s time to build an application from the bundles that you’ve been playing with so far. By the end of this section, you should have an EBA that can be deployed on your development stack or on top of an application server that supports EBA-packaged OSGi applications. The EBA you produce will, broadly speaking, follow the best practices for application packaging; however, at one or two points you’ll have to make allowances for the limitations of the development platform.
The main limitation you face is that the development platform doesn’t offer any way to configure bundle repositories to use for remote provisioning. As a result, although you could add an OSGi Bundle Repository (OBR) –based resolver to your platform, there wouldn’t be much point!
You’ll therefore have to include all the bundles needed by the application (including shared code) inside the EBA, which acts as a local repository. On a beefier server this could be done more elegantly. One other limitation of this development platform is that it can’t define datasources, so you have to build your own datasource bundles. To avoid complexity in this application, we’ll ignore the datasource bundle, but to run the application it would need to be added. In the real world this wouldn’t be necessary.
One more thing to note is that the development stack you’re using doesn’t enforce any of the application isolation boundaries. You could add a few more Aries bundles to enable this, but it isn’t necessary for any of the examples covered here. The EBAs described in the enterprise OSGi 5 specification will include isolation.
4.5.1. Building your metadata
The most important part of the application, from a structural perspective, is the application manifest, but if you were happy to have no sharing between your application and others, then it could be entirely omitted. This sort of application isn’t particularly interesting, but it does give you an excellent way to build up the application, filling in metadata as you go. Let’s start with the most basic metadata—none!
The Zero Metadata Application
If you include no metadata in your application, then you must include the bundles that make it up inside the EBA. This tells the server that the bundles inside the EBA are the application content. The current application would look like figure 4.6.
Figure 4.6. The minimum-effort EBA contains no metadata, only bundles.

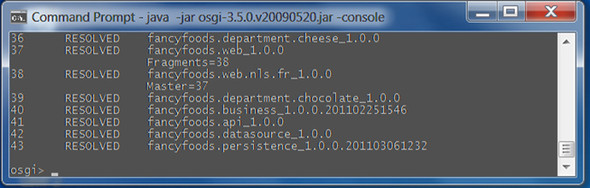
This figure shows how simple an EBA can be; the zip archive fancyfoods.eba contains the six application bundles from chapter 3. No other metadata is required for this application, which is called fancyfoods, versioned at 0.0.0, and it runs all six bundles as isolated content. To run the EBA application, start the development stack with a clean load directory, and then drop the EBA into it. The runtime will detect the EBA, resolve it, and install it. With a little extra configuration you could get your development stack to automatically start the EBA as well. For the time being, if you want to check that the application still works, then you can start the bundles yourself from the Equinox console. You should be able to use the application as before (as long as you remembered to add the datasource bundle into the EBA!). See figure 4.7.
Figure 4.7. The installed EBA. Because the development stack doesn’t support isolation, all of the application bundles are visible using the ss command. These bundles have been installed, but not started, by the application runtime.
Although this EBA was easy to create, it doesn’t offer much control. What if you want to change the name and version of your EBA?
Taking Control of the Metadata
When an application is under active development, it’s convenient to avoid specifying any metadata, but this quickly becomes problematic as the application becomes more mature and needs to be passed to others for testing. At this point, it’s much better to give the application a sensible name and, as with any OSGi artifact, a version. This information can be supplied as shown in the following listing.
Listing 4.2. The manifest for the Fancy Foods EBA
Manifest-Version: 1.0 Application-ManifestVersion: 1.0 Application-Name: The Fancy Foods online superstore Application-SymbolicName: fancyfoods.application Application-Version: 1.0
The example manifest in listing 4.2 contains two pieces of metadata describing the format of the application manifest itself and three pieces about the application. You’ll start by describing the two pieces of formatting information that are required for any application manifest (if it’s present):
- The Manifest-Version: 1.0 header and value is required by the Java manifest specification to indicate that this metadata file uses standard Java manifest syntax.
- The Application-ManifestVersion: 1.0 header and value is required by the enterprise OSGi runtime to recognize this file as an application manifest. Don’t worry that it might be out of date; at the time of writing only version 1.0 exists, and there are no plans to add a new version.
If the idea of writing EBA manifests by hand doesn’t appeal, don’t worry—the Apache Aries project has developed a Maven plug-in, called the eba-maven-plugin, that generates EBA archives. We’ll show it in detail in section 8.2.5, along with the other build tools. The Aries project is also working on an esa-maven-plugin for generating subsystem archives.
The other important information in listing 4.2 has to do with the application:
- Applications are easier to recognize if they have a human-readable name. This is added using the Application-Name: header. In this case, the name of your application is The Fancy Foods online superstore.
- It’s also important to provide a unique name for your application that won’t clash with others. This is like a bundle’s symbolic name, so unsurprisingly it uses the Application-SymbolicName: header to call your application fancyfoods.application.
- Finally, it’s vital to version your application. This, in conjunction with the application’s symbolic name, provides a unique identifier just like a bundle. You’ll use the Application-Version: header to version your application 1.0.0.
Application symbolic names are exactly like bundle symbolic names. In fact, they are so similar that applications and bundles share the same namespace and can be confused in the OSGi framework. Because these names can clash, you should be careful when naming your application. It’s easy to give the application the same name as one of your bundles, at which point you often have a painful debugging job before a rather embarrassing aha! moment...
If you add this manifest to the EBA from section zero metadata EBA at the location META-INF/APPLICATION.MF you end up with another deployable EBA. Feel free to try the new application; there should no difference at runtime, but more advanced stacks will display a sensible name for your application.
You’re starting to get somewhere now, but you’re still relying on defaulting to determine the structure of your application. It’s time to take a deeper look at how your application fits together.
Structuring Your Application
So far, your application bundles have been entirely isolated within the runtime. Clearly this works, but it isn’t the best way to share code or reduce your runtime footprint. What you want to do is isolate the core content while sharing the API and library code. To do this, the first thing you need to do is look at the application to identify the bundles that can be safely removed.
As you can see from figure 4.8, the bundles in your application are interconnected.
Figure 4.8. The relationships between bundles in your EBA. All of the bundles have a package dependency on the API bundle. The two department bundles expose services that are consumed by the business bundle. The web bundle consumes services from the business and persistence bundles indirectly, by JNDI.

At first glance it may seem as though all the bundles represent core content; however, looking deeper, this isn’t quite correct. Core content bundles typically expose an endpoint (like a WAB) or provide an implementation of a service used within the application. In this case, the Fancy Foods API bundle does neither; it exposes packages to the implementation bundles, making it an excellent candidate for sharing.
Now that you’ve identified that the API bundle doesn’t need to be isolated, but that the rest of the bundles do, you have two options. One option would be to add the API bundle to a repository and remove it from the EBA. This would mean it was no longer defaulted as core content and could be provisioned as a resolved dependency. Unfortunately, this isn’t possible with the development stack you have. Your other option is to leave the API bundle in the EBA, which is what you’ll do here.
In this example, the bundle you’re sharing represents the core API of your application. We’ve chosen this bundle because it’s a good example of the type of bundle that can be safely shared. In the general case, it’s unlikely that you’d want to share the internal API of your application, so it isn’t particularly valuable to do so. The best things to share are common libraries that are used, or are likely to be used, in multiple applications.
This information is easily added to your application manifest. Note that the datasource bundle isn’t part of your application content, but it’s required for the EBA to run on your development stack:
Application-Content: fancyfoods.web;version="[1.0.0,2.0.0)",
fancyfoods.web.nls.fr;version="[1.0.0,2.0.0)",
fancyfoods.persistence;version="[1.0.0,2.0.0)",
fancyfoods.business;version="[1.0.0,2.0.0)",
fancyfoods.department.chocolate;version="[1.0.0,2.0.0)",
fancyfoods.department.cheese;version="[1.0.0,2.0.0)"
Adding this line to your existing application manifest changes it significantly, but if you deploy the application again you can see the framework still contains the API bundle (see figure 4.9).
Figure 4.9. The resolved EBA. As before, all of the application bundles are visible using the ss command. This also shows that the API bundle has been installed, even though it wasn’t part of the application content, because it was needed as a dependency.
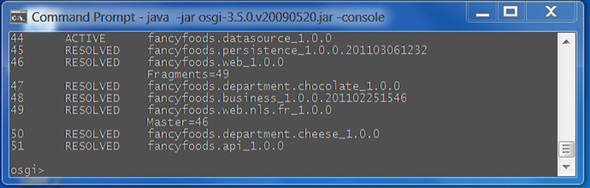
The API bundle is still installed because the resolver determined that it was needed to provide the dangling dependencies of your EBA. If your runtime supported provisioning from a repository, you’d be able to remove the API bundle from the EBA entirely, reducing the size and complexity of your EBA.
4.6. Summary
In this chapter we’ve discussed the need for a packaging model beyond the OSGi bundle and we’ve also looked at what’s provided by Java EE EARs, both the good and bad points. EBAs provide a familiar, powerful packaging model that leverages the modularity of OSGi bundles to provide great flexibility at runtime.
Most importantly, having packaged up the Fancy Foods application, you should now know enough about the structure of an EBA to be able to build your own. With a little experience, you’ll quickly see how bundles can be packaged together to take advantage of resolution and provisioning, reducing the size and complexity of your applications. Having added to your knowledge of WABs, persistence bundles, and Blueprint, you can now begin to think of yourself as a real enterprise OSGi developer.
For those of you who are interested in more than a basic understanding of enterprise OSGi, our journey is far from over. In the next part of this book, we’ll take a look at some of the more advanced features of enterprise OSGi.