
Chapter 7. Provisioning and resolution
This chapter covers
- How to find the dependencies your bundles need to work properly
- Using additional constraints to avoid resolution problems
- How repositories and resolvers model bundles and other resources
- How to take advantage of provisioning when writing applications
You may remember that, back in chapter 4, we discussed the concepts of provisioning and resolution. These are two fundamental parts of enterprise OSGi deployment and, as such, are worth a second, deeper look. Although we stand by the statement that “provisioning is a relatively simple operation,” and the fact that many OSGi developers will succeed by treating provisioning as a black box, there are a few subtleties that you can use to your advantage. Understanding subtleties like these marks the difference between a competent enterprise OSGi developer and an expert. Now, adding in the more detailed understanding of OSGi packaging you learned in chapter 5 and armed with your Service Registry experience from chapter 6 we’re ready to discuss provisioning and resolution in more detail.
OSGi provisioning and resolution is covered by the OSGi Resource API Specification, the Resolver Service Specification, and the Repository Service Specification. Historically, these specifications were part of a single OSGi Bundle Repository Specification (often known as OBR). These specifications explain how bundles should be described, how dependencies between bundles are resolved, and how resolvers interact with bundle repositories, and describe a text format for representing bundle repository metadata. Although they define the standards for provisioning and resolution in OSGi, there are several other popular systems that also allow bundles to be automatically downloaded and installed based on analysis of their dependencies.
Let’s return to the world of provisioning and resolution by considering what gets provisioned and resolved—how do you tell the provisioner about your bundles?
7.1. Describing OSGi bundles
You already know that OSGi bundles contain a lot of metadata describing themselves. Metadata describes a bundle’s dependencies, the packages it exposes to the outside world, the bundle’s name and version, and more. As you’ve seen in section 5.1.2, some of a bundle’s metadata has metadata of its own; Import-Package and Export-Package allow packages to be decorated with attributes and either version ranges or versions, respectively. This metadata is rich with information, most of which is used by the OSGi framework resolver to determine whether a bundle is able to load classes.
As you learned in chapter 4, provisioning and resolution are closely related. That this processed information is necessary in the resolution process means that it’s also critical for provisioning. When attempting to resolve a partially complete dependency graph, a resolver may need to query a bundle repository to fill in the missing dependencies. To answer these questions from the resolver, a bundle repository must be able to describe the bundles it has to offer by modeling them, including all the information needed by the resolver.
If the resolver and the repository are to agree in their descriptions of bundles, then they need a common definition for describing OSGi bundles and their interactions with the outside world. This common description is provided in OSGi by the Resource API Specification through the use of generic Resource, Capability, and Requirement objects. Together these form a model for bundles—and lots of other things!
7.1.1. Describing bundles as resources
In the generic sense, a Resource is a vague object. A Resource can represent anything, from a binary or text file to a web service, an OSGi bundle, or something more bizarre like a treacle sponge pudding! The key details about a Resource object are as follows:
- All resources define a capability named osgi.identity that determines their type.
- Resources provide a set of Capability objects describing the features they provide.
- Resources provide a set of Requirement objects describing the features they need to run.
- Resources use the osgi.identity and the optional osgi.content capabilities to provide a set of named attributes describing the resource.
Despite the vague nature of Resource objects, these rules mean that they aren’t as complicated as you might think. In figure 7.1, you can see that a Resource is not much more than a holder for Requirement and Capability descriptions.
Figure 7.1. Resources may have requirements and capabilities.

Every resource exposes three mandatory attributes through the osgi.identity capability:
- type—The type of the resource
- osgi.identity—The symbolic name or identity of the resource
- version—The version of the resource
Other attributes, such as the license, description, and links to documentation, may also be included. Further predefined attributes that broadly correspond to other informational headers in the bundle manifest file are defined by the osgi.wiring.bundle, osgi.wiring.package, and osgi.wiring .host capabilities. Any of a resource’s capabilities may also contain arbitrary keys and values that are used in a resource type-specific way.
Identity of Resources
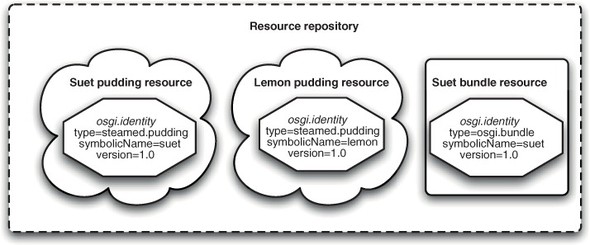
The identity of a resource is, unsurprisingly, defined by the attributes of the osgi.identity capability. For a particular type of resource, the combination of osgi.identity and version attributes provides a unique identifier, but it’s important to remember that, when comparing resources, they may not be of the same type. This is why it’s always important to refer to the whole osgi.identity capability. With the cornucopia of potential resource types, OSGi defines a standard type for OSGi bundles (osgi.bundle) and fragments (osgi.fragment). Any OSGi bundle modeled as a resource will have an identity type of osgi.bundle and an osgi.identity corresponding to its symbolic name, instantly separating it from the crowd of configuration property and steamed pudding resources in the repository, even if one of those puddings has exactly the same name and version as your bundle (see figure 7.2).
Figure 7.2. Resource repositories may contain resources of any type including, but not restricted to, bundles. Two resources may share a symbolic name and version as long as they’re different types.
7.1.2. Requirements and capabilities
As with a Resource, both a Requirement and a Capability are generic objects that can be used to express any dependency or exposed feature. As such, they’re more than capable of expressing the potential range of bundle dependencies and features. Requirements and capabilities define a namespace, which is like the type of the osgi.identity capability, indicating what sorts of things they require and provide. Requirements and capabilities are related in that a capability can satisfy a requirement if it meets three rules (see figure 7.3):
1. The requirement and capability share a namespace.
2. The requirement’s filter matches the attributes of the capability.
3. Any relevant directives are satisfied. We’ll cover these in more detail in section 7.1.3.
Figure 7.3. A requirement is satisfied by a capability if that capability is of a matching namespace, provides the attributes needed by the requirement, and has no conflicting constraints.

Requirements and capabilities share a similar structure. They both expose the following:
- A link back to the resource that owns this requirement or capability.
- A namespace. A particular resource may define requirements and capabilities from many namespaces. Critically, a capability and requirement can only match if they’re in the same namespace.
- A set of attributes that describe the required or provided feature. The attributes for a requirement are used to define the filter used for matching capabilities. The attributes for a capability must contain an entry whose key matches the capability’s namespace.
- A set of directives that are used to provide instructions to the matching algorithm, or to the OSGi runtime.
For OSGi bundles, there are standard mappings for the specification-defined capabilities and requirements. Headers such as Import-Package, Require-Bundle, and Fragment-Host correspond to requirements, whereas Export-Package and the existence of the bundle are capabilities.
Aside from the packages it exposes, a bundle still has other capabilities, though you probably wouldn’t think of them that way normally. These are the capability to be required by another bundle using Require-Bundle, and the capability to host a fragment when specified by Fragment-Host. These capabilities both loosely correspond to the Bundle-SymbolicName and Bundle-Version headers, and are therefore similar to the osgi.identity capability!
It may seem odd to model the bundle like this, but it makes a lot of sense. Require-Bundle and Fragment-Host are clearly dependencies that need to be mapped as requirements—therefore, there must be matching capabilities to satisfy them! The two capabilities are in the osgi.wiring.bundle and osgi.wiring.host namespaces for Require-Bundle and Fragment-Host, respectively.
We’ve discussed how requirements and capabilities are structured, and that a capability must provide the right attributes to satisfy a requirement. Although this model has an elegant simplicity, it isn’t, unfortunately, the full story. In addition to attributes and their namespaces, both requirements and capabilities can express directives that affect the way they resolve.
7.1.3. Directives affecting the resolver
As we’ve said before, resolution is closely tied to provisioning. Nowhere is this more clear than in the resolution directives that can be passed to the resolver through capabilities and requirements. Directives aren’t usually used directly to match requirements to capabilities (the mandatory directive is a notable exception), but instead offer instructions to the resolver saying how they should be processed. If you find yourself scratching—or banging!—your head about why a bundle won’t resolve when all the packages it imports are clearly available, check to see if there are any unsatisfied directives on the packages—there almost certainly will be!
Six standard directives can be applied to any namespace, which makes them particularly important to understand. These are the resolution directive, the mandatory directive, the cardinality directive, the uses directive, the effective directive, and the filter directive.
The Resolution Directive
The resolution directive serves a fairly simple purpose; it determines whether a requirement is optional or not. The resolution directive has two allowed values, optional and mandatory. The default value of this directive is mandatory.
The resolution directive can be applied to any requirement, and it’s also possible to specify it on requirement-like manifest headers:
Import-Package: fancyfoods.optional; resolution:=optional Require-Bundle: fancyfoods.needed.bundle; resolution:=mandatory
Warning: Directives in the Bundle Manifest
At first glance, there doesn’t seem to be any difference between the resolution directive and any other attribute on an Import-Package; however, if you look closely you’ll see that it’s specified using :=, not =. This is the key difference in syntax between an attribute and a directive. If you were to write resolution=optional, then your package import would still be mandatory and the resolver would try to find an exported package that defined an attribute called resolution with a value of optional.
The Mandatory Directive
The mandatory directive is somewhat more complicated than the other directives, primarily because it doesn’t apply to a requirement, but instead to a capability. Many people get confused by what the mandatory directive does, but there’s a reasonably simple way to think about it. When you specify attributes on a requirement, it means that the requirement can only be satisfied by a capability that provides all of those attributes; however, any capability that provides those attributes will do, even if it specifies a hundred extra attributes. The mandatory directive effectively provides the reverse mapping of this behavior. By using the mandatory directive, a capability can specify a set of attributes that a requirement must specify to be matched. Even if the capability supplies all of the attributes needed by the requirement, it won’t match unless the requirement supplies all of the mandatory attributes:

In this code snippet, you can see that the package import from bundle A looks as though it should match the export from bundle B. Bundle B, however, only allows importers that specify both that chocolate is nice and that cheese is yummy. As a result, poor bundle A must look elsewhere for its package (see figure 7.4).
Figure 7.4. If a capability includes the mandatory directive, requirements must specify the mandatory attributes to be satisfied. In this case, a bundle with a requirement for the fancyfoods.mandatory package must also specify that chocolate is nice and cheese is yummy for bundle B to satisfy the requirement.

The mandatory directive is a specialized tool, and we recommend avoiding it unless you really need it. One example of why you might want to use the mandatory directive is if you have a private SPI package that needs to be shared between two bundles (yuck!). In this case, you can add a mandatory attribute to the exported package so that you can’t wire to it accidentally, only if you supply the necessary attribute. Even though it’s unlikely that you’ll need to use it, we think it’s important that you know what it looks like and what it does, in case you see it in a bundle manifest somewhere.
The remaining directives are different from the resolution and mandatory directives in that they don’t have a corresponding entry in a bundle manifest. On the other hand, they’re extremely useful!
The Cardinality Directive
The cardinality directive is simple to understand; it’s applied to a requirement and determines the number of capabilities that can be wired to that requirement by the resolver. It has two values: single and multiple. The default value is single; however, the cardinality is determined by the interaction between the resolution directive and the cardinality directive (see figure 7.5 and table 7.1).
Figure 7.5. How many instances of a capability are resolved is determined by the combination of the cardinality directive and the resolution directive.

Table 7.1. Interaction between the resolution and cardinality directives
|
cardinality directive |
Number of wired capabilities |
|
|---|---|---|
| mandatory | single | Exactly one |
| mandatory | multiple | One or more |
| optional | single | Zero or one |
| optional | multiple | Zero or more |
The Uses Directive
The uses directive is a comma-separated list of packages used by a capability. The reason this information is interesting is because it helps the resolver ensure that the class space is consistent. Although you could generate uses directives by hand, it’s better to have a tool do it. We’ll come back to uses constraints in section 7.2.1.
The Effective Directive
The effective directive is almost certainly the one that you’ll have the least contact with. The effective directive applies to both requirements and capabilities, and is used to determine at what time that requirement is needed, or when the capability becomes available. There’s only one defined value, which is the default. This value is resolve. If a requirement is effective at resolve time, it must be taken into account during the resolution process. If a requirement is effective at any other time, it isn’t processed by the resolver because it has no resolution impact. Similarly, a resolve-time capability can be used by the resolver to satisfy requirements, but a capability with any other effective time can’t, and is ignored.
Given that an effective directive of anything other than resolve is more or less ignored by the OSGi resolver, you might think that it isn’t useful. This isn’t true, although its use is fairly specific. A good example of a nonresolve time requirement is configuration. The OSGi Compendium Specification defines the Configuration Admin service, which can inject configuration into managed services. To be injected with configuration, your managed service must specify a persistent identifier (PID), which identifies the configuration dictionary to be injected. This clearly has no impact on the resolution of your bundle; however, without the configuration dictionary your service will be relatively useless. Some proposed provisioning systems allow you to express an active time requirement on a configuration dictionary with a particular PID. This requirement allows the provisioning system to identify a configuration resource (with the right PID) and make the configuration available for you at runtime. The OSGi Resolver Service Specification suggests using a value of active for this case, but implementations are free to choose a value that makes sense within their requirement’s namespace.
The Filter Directive
As far as the resolution process is concerned, the filter directive is probably the most important of all the directives. The filter directive exists on a requirement and contains an LDAP filter that’s used to determine whether a particular capability satisfies this requirement. Despite being so important, the filter directive is almost always generated programmatically (the framework generates them for bundles), so it’s unlikely that a user would ever have to write one.
We’ve spent a reasonable amount of time looking at how bundles can be modeled programmatically using the OSGi Resource Specification, and how this fits into the OSGi resolver service, but we haven’t explained how these fit together with provisioning. We’re now ready, however, to look at provisioning using the OSGi Repository Service. One of the key aspects of the OSGi Repository Service is hinted at in its name, the repository. Repositories are a vital part of provisioning; without a repository it’s not possible to provision anything in a meaningful sense.
7.1.4. Repositories
Modeling bundles is an important job for an OSGi resolver, and it’s critical that the framework understand the relationships between OSGi bundles so that they can be resolved. This information isn’t just important to a framework resolver, but is also necessary in provisioning. A repository is a standard place in which bundles can be located and, if necessary, downloaded and installed. As the collection of OSGi bundles within your enterprise grows, you’ll almost certainly need a repository to store your bundles and allow applications to be provisioned against them. You may also want to make use of a number of publicly available repositories (more on public repositories in section 7.4.1).
Repositories make use of exactly the same Capability and Requirement interfaces as the resolver, which makes it easy for them to interoperate. Although a resolver is capable of large-scale complex dependency analysis, a repository can only provide responses to simple queries, listing the capabilities that match a supplied requirement. On the other hand, although a typical repository can contain a large variety of resource types, a resolver can typically only understand a limited number of resource types. For example, a framework resolver is only required to understand OSGi bundles.
Repository Services at Runtime
Repositories serve an important function at runtime. When the resolver is asked to determine whether a set of bundles can resolve or not, it makes use of an Environment. You can compare the Environment or a Repository to a helpful waiter in a restaurant that’s run out of menus. You might want to eat steak, or to order something served with asparagus. To find out what was available, you’d ask the waiter if they had any steak or asparagus on the menu. When the resolver comes across a dependency, it does more or less the same thing; it queries the environment for resources that expose particular capabilities. The resolver then attempts to determine the correct resolution for the bundles. Depending on how deep the dependency graph is (whether you want side dishes), this may involve further queries to the environment. The link between the environment and repositories is that the environment can be used to join the current state of the framework (the bundles that are already installed) with one or more repositories. This allows additional bundles to be dynamically provisioned into a system as necessary (see figure 7.6).
Figure 7.6. A resolver can make use of one or more repository services via the Environment to find out what capabilities are available.
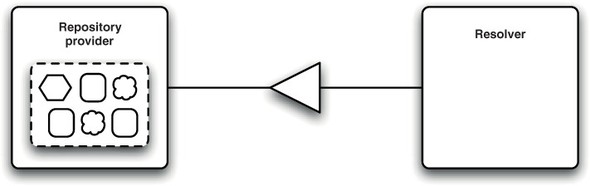
When the resolver has finished determining a resolvable set of resources, the repository services are no longer needed; however, it would be wasteful to get rid of them. If you needed the repositories for another resolution, you’d have to rebuild them by modeling all of the bundles, all over again. Even if you keep the repository services around for the entire lifetime of the framework, but they only exist in memory, they’ll still have to be rebuilt after every restart.
XML Repositories
A rather large amount of computational effort is required to generate the model for a bundle, so after it’s been done once, it’s preferable to save the information away. It’s clearly even better if this data is saved in a format that’s human-readable and freely interchangeable. This is why the Repositories Specification includes a standard XML form for a repository. The following listing shows a small snippet of a serialized repository.
Listing 7.1. An excerpt of a repository XML serialization
<repository
xmlns='http://www.osgi.org/xmlns/repository/v1.0.0'
name='Fancy Foods repository'>
<capability namespace='osgi.identity'>
<attribute name='osgi.identity' value='fancyfoods.api' />
<attribute name='version' type='Version' value='1.0.0'/>
<attribute name='type' value='osgi.bundle' />
</capability>
<capability namespace='osgi.wiring.bundle'>
<attribute name='osgi.wiring.bundle'
value='fancyfoods.api' />
<attribute name='bundle-version' type='Version' value='1.0.0' />
</capability>
<capability namespace='osgi.wiring.package'>
<attribute
name='osgi.wiring.package'
value='fancyfoods.food' />
<attribute
name='version'
type='Version'
value='1.0.0' />
<attribute
name='bundle-version'
type='Version'
value='1.0.0' />
<attribute
name='bundle-symbolic-name'
value='fancyfoods.food' />
</capability>
...
As you can see, one consequence of the repository allowing generic resources is that the XML form is verbose!
Repositories are important, and we’ll talk about them again later in this chapter. First, now that you have a better understanding of how bundles are modeled, we should take a deeper look at dependency provisioning, particularly how packages and services can be located within a repository.
7.2. Provisioning bundles
Now that you understand the generic descriptions of resources used by OSGi resolvers and repositories, it’s time to look back at how to provision bundles, and how you can achieve finer control with your applications if you need to.
Warning: Best Practices
One or two of the examples in this section may seem to deviate from the best practices outlined in chapter 5. As in all things, context is king. The examples we provide aim to demonstrate best practices; however, sometimes this doesn’t offer the most elucidating examples. The best practices from chapter 5 are good rules to follow, and we encourage you to do so, but sometimes they aren’t 100% appropriate. Perhaps in the future you too will find that the right thing to do in your project is to ignore one or more of the best practices. If it is, we wish you luck!
7.2.1. Package-based provisioning
When we looked at provisioning applications, we primarily focused on how an application manifest can require bundles within a range of versions. We also discussed the concept of a missing dependency. You may have noticed, at the time, that we never dug into how these missing dependencies were identified; more probably, you took for granted that it would work.
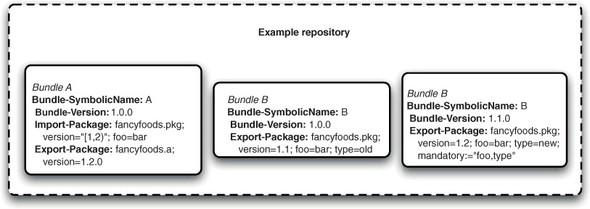
Now that you know how bundles can be modeled and made available through repositories, hopefully you can see how it might be possible to provision based on package dependencies. What you can do is provide an example of a real-world resolution involving a repository. Your repository will contain three bundles (listing 7.2 and figure 7.7).
Figure 7.7. Your example repository contains three bundles with a variety of package exports, versions, attributes, and directives.
Listing 7.2. The bundles in your repository
Bundle-SymbolicName: A Bundle-Version: 1.0.0 Import-Package: fancyfoods.pkg; version="[1,2)"; foo=bar Export-Package: fancyfoods.a; version=1.2.0 Bundle-SymbolicName: B Bundle-Version: 1.0.0 Export-Package: fancyfoods.pkg; version=1.1; foo=bar; type=old Bundle-SymbolicName: B Bundle-Version: 1.1.0 Export-Package: fancyfoods.pkg; version=1.2; foo=bar; type=new; mandatory:="foo,type"
Given the content of your repository, you’ll try to resolve the following bundle:
Bundle-SymbolicName: Test Bundle-Version: 1.0.0 Import-Package: fancyfoods.a; version="[1.1,2)", fancyfoods.z; version="[1,2)"; resolution:=optional
If you ask the resolver whether your test bundle can resolve, the following things will happen under the hood (we’ve represented the resolution logic as a flowchart in figure 7.8):
1. The resolver will model the Test bundle, determining that it has two dependencies: one for the fancyfoods.a package, and one for the fancyfoods.z package.
2. Having determined that the requirements can’t be satisfied by any other bundles known to the resolver (because there aren’t any!), the resolver asks the environment if there are any resources that can supply a package capability for fancyfoods.a between versions 1.1 and 2. The environment has no matches locally (because there are no other bundles) and so delegates to the repository.
3. The repository returns the resource A as a possibility, which the resolver determines to be a valid match, but requiring further dependencies. To determine whether these dependencies can be satisfied, the resolver asks the environment if there are any resources that can supply a package capability for fancyfoods.pkg between versions 1 and 2 that also specify the attribute foo with a value of bar.
4. The environment queries the repository and finds one match. Even though bundle B at version 1.0.0 and at version 1.1.0 both look like possible matches, the mandatory directive on version 1.1.0 of B means that the requirement doesn’t match (because it doesn’t specify type=old). Because of this, the repository returns fancyfoods.pkg exported at version 1.1 from B at version 1.0.0.
5. Neither A nor B has any further requirements. The resolver continues to process the Test bundle.
6. The resolver queries the environment for the second package import from the Test bundle. The environment has no local matches and queries the repository, which also returns no matches because there are no bundles exporting the fancyfoods.z package. Rather than fail the resolution at this stage, the resolver determines that the import is optional and doesn’t need to be satisfied for this resolution to be valid.
7. The resolver reports that the Test bundle can be successfully resolved, and that it requires both bundle A at version 1.0.0 and bundle B at version 1.0.0 to do so.
Figure 7.8. To resolve a bundle, a resolver will first model its requirements, and then query an environment for matching capabilities and any transitive requirements of the matching resources. It will then further refine possible matches based on the resource’s attributes and directives.

After you’ve determined that the necessary bundles required to make Test resolve are A and B at version 1.0.0, then the provisioner can ask the repository where the bundles are located and download them. If Test were the core content of an application, then you’d now have successfully determined the shared content you need to deploy it!
Export-Package and the Uses Clause
Packages have a rather special place in OSGi because they represent the unit of modularity. The problem with Java packages, however, is that they aren’t particularly well-defined units. On one level, a package is easy to define: every class declares which package it’s in. But overlaps between packages exist. Methods on an interface in one package can accept parameters, or return things, that are declared in another package. This causes a problem for you in OSGi.
The identity of a class is determined by two things: its fully qualified name and the ClassLoader that loaded it. Because each bundle has its own classloader, but also imports classes from other bundles, it’s possible that a class will exist more than once in a framework, but none of them will be the same class! Normally this isn’t a problem, because the resolver ensures that you’re only wired to a consistent set of bundles, but what if one of the packages you imported returned you an object from a different package? You would need to be certain that your view of that object was the same as the one from the imported package. If it wasn’t, you would get a ClassCastException!
This is where the uses clause comes in. The uses directive can be applied to almost any header, but it’s most often applied to Export-Package entries. It tells the framework about the other packages that are used by the exported package. This may mean that the exported package has method parameters or return values from those packages, or that they’re used internally by classes in the package in a way that might cause problems. The directive instructs the resolver that when someone imports this package, the user must share the same class space for all of the packages in the uses directive, as shown in listing 7.3.
Listing 7.3. Successfully resolving with a uses clause
Bundle-SymbolicName: Exporter Export-Package: fancyfoods.special; uses:="fancyfoods.used" Import-Package: fancyfoods.used; version="[1,2)" Bundle-SymbolicName: Importer Import-Package: fancyfoods.special, fancyfoods.used; version="[1,2)"
In listing 7.3, you can see two bundles. One bundle exports a package, fancyfoods.special, with a uses constraint of fancyfoods.used. The other bundle imports the fancyfoods.special and fancyfoods.used packages. The resolver knows that the importing bundle must be wired to the same instance of fancyfoods.used that the exporting bundle is, as shown here.
Listing 7.4. Successfully resolving with a uses clause
Bundle-SymbolicName: Exporter Export-Package: fancyfoods.special; uses:="fancyfoods.used" Import-Package: fancyfoods.used; version="[1,2)" Bundle SymbolicName: Importer Import-Package: fancyfoods.special
In listing 7.4, you can see two bundles similar to those in listing 7.3—one that exports package fancyfoods.special with a uses constraint of fancyfoods.used, and another that imports fancyfoods.special but not fancyfoods.used. In this case, the importing bundle can’t see the fancyfoods.used package at all. Because of this, the importing bundle is class-space compatible with any view of that package. This might sound odd, but think of it this way: the importing bundle has no way to get the fancyfoods.used package; therefore it can’t have an incompatible view! The end result of this is that, as in the following listing, we can successfully wire these bundles together.
Listing 7.5. Failure to resolve with a uses clause
Bundle-SymbolicName: Exporter Export-Package: fancyfoods.special; uses:="fancyfoods.used" Import-Package: fancyfoods.used; version="[1,2)" Bundle SymbolicName: Importer Import-Package: fancyfoods.special, fancyfoods.used; version="[2,3)"
Listing 7.5 is another variation on listing 7.3. Again, the Exporter hasn’t changed, but the Importer has a different import version range for fancyfoods.used. In this case, the importing bundle can see the fancyfoods.used package, but can never wire to the same package that the Exporter bundle does. Because of this, you can guarantee that the uses constraint on the fancyfoods.special package will never be satisfied. This means that the resolver can’t wire the import and export together, even though they look like they should match.
Warning: Complex Uses Constraints
The examples in this section show reasonably simple situations involving the uses directive, ones that are easy to understand. You should, however, be aware that resolution problems involving uses constraints can be nasty to debug. This is because the class space of a bundle includes not only the packages it imports, but any packages that are used by those packages. In a complex case, you may find that the uses constraint violation occurs because of a third bundle, one that isn’t even supplying the package you’re trying to import!
To minimize the risk of unpleasant uses problems, you should try to avoid making use of too many API packages from other bundles when defining your API. In general, this isn’t a huge problem; good API design tends to minimize the dependencies on other packages, and even in cases with large uses clauses, problems are comparatively rare.
Writing Uses Clauses
You may have noticed that you haven’t been adding uses clauses to your example bundles. There are three main reasons for this. The first is that you don’t want to overload your samples with new concepts. The second is that because all your API comes from a single, separate bundle, it must all be class-space consistent with itself, making you unlikely to suffer from uses problems (another good reason for doing what we suggest in section 5.2.1). The third reason is that writing accurate uses clauses is hard to do and hard to keep up to date. In the real world, almost all uses clauses are generated by tooling, which you’ll hear more about in chapter 8.
Package-based provisioning is extremely handy and is probably the most commonly used feature of an OSGi bundle repository. A well-structured repository, however, can offer more than packages for provisioning.
7.2.2. Service-based provisioning
Service-based provisioning works in exactly the same way as package-based provisioning, and it’s easy to see why. If you look back at the resolution process, you can see that despite the specific example, there was no reason that the requirements and capabilities had to be packages at all. In terms of your restaurant example, if your Test bundle had a requirement for toffee sauce (a requirement we can all get on board with!), then it could have been satisfied by a sticky toffee pudding in your repository. Fundamentally, there’s no difference between the two scenarios.
Having identified that service-based provisioning is a trivial extension of the package-based provisioning model, why does it warrant all of section 7.2? To answer that question, you need to look back at the most critical part of the resolution and provisioning process, the generation of the capabilities and requirements. For packages, all the information you need is handily expressed in the bundle manifest, making package dependencies easy to model. Unfortunately, for services the problem isn’t so simple, providing a key difference between services and packages.
Modeling OSGI Services
If an OSGi bundle uses the OSGi API to register and consume services, then there’s no metadata that describes the dependencies or capabilities offered. This causes a significant problem for modeling. How do you model things that are only expressed in the bytecode of a class file?
Bytecode analysis is a possibility for determining service registrations and lookups; however, it’s an extremely expensive operation. To model the bundle, you would need to perform an in-depth analysis of every class contained within it. If computational complexity were the only issue, then it probably wouldn’t be a problem; however, it isn’t. Analyzing the bytecode can’t always give you all the information you require.
It may seem odd that scanning the bytecode isn’t able to supply all the information you need, but in bytecode you can’t always tell what the value of variables are going to be at runtime. This means that if the interface name, the service properties, or the filter expression used when interacting with the Service Registry are able to vary at runtime, then it can be impossible to know what they’ll be. This isn’t the end of your problems, either. What if the registration of the service occurs in some other bundle that you import a package from? Also, how can you ever know if a service is optional or not?
Clearly, bytecode analysis is only feasible if you’ve found a way to solve the halting problem, which seems rather unlikely. What would be useful would be manifest headers like Import-Package and Export-Package. These would allow you to process the services in the same way you process packages.
Import-Service and Export-Service
Earlier versions of the OSGi core specification described two headers, Import-Service and Export-Service. These headers are fairly self-explanatory, and seem like the perfect solution to your problems. Unfortunately, there were several problems with these headers, which means that they were deprecated and withdrawn from the core specification. In case you’re worried that this means the OSGi alliance makes breaking changes to your bundles, be assured that this doesn’t constitute a breaking change. The fact that this wasn’t a breaking change even provides a good example of why the header wasn’t that useful in the first place.
The problems with Import-Service and Export-Service are rather wide ranging. First, the headers are purely informational—they have absolutely no effect on the resolver at all. This is why it wasn’t a problem for the OSGi alliance to remove them from the core specification. The informational nature of these headers, and the fact that they don’t affect resolution, was a big reason for removing them. Because they look so similar to Import-Package and Export-Package, most people mistakenly believed that the resolver would ensure that the necessary services were available for their bundle. Another problem with the headers was that, because they were informational, they were also optional. This made them impossible to rely upon, and therefore rather useless.
Furthering their confusing nature, Import-Service and Export-Service weren’t expressive enough to describe the myriad of services that can be exposed in the Service Registry. The big problem with these headers is that they have no way to type their attributes (the service properties), and no way to specify multiple values for the same property, either as an array or as a collection. Finally, the headers offered no way to identify the optionality or cardinality of required services. All in all, the headers were something of a disaster, which explains why they were removed from the specification.
Some people argue that, despite their shortcomings, Import-Service and Export-Service are the only sensible way to model dependencies and should be used to build Requirement and Capability descriptions. Others argue that co-opting headers that were (and still are) reserved by the OSGi alliance for something other than their original purpose is a bad idea. For what it’s worth, we don’t think that using Import-Service and Export-Service is a particularly good idea. They’re hard to keep in sync with your code, they can’t express more complex services and requirements, and it’s not a good idea when there’s a better alternative. If there’s an alternative, what is it?
Modeling Blueprint Services
The reason that you can’t easily provision against OSGi services is because you don’t have anywhere to find reliable descriptions of them. Luckily, this isn’t true for all OSGi services. Services that are exposed using the OSGi Blueprint container have an easily available, easily readable, and complete expression of all their properties—the Blueprint itself! By parsing the Blueprint definitions in a bundle repository, generators can quickly locate the services exported. As you saw in section 6.4.3, the service properties for a Blueprint exposed service are also easily accessible, as illustrated here.
Listing 7.6. A Blueprint service definition
<service ref="specialOffer"
interface="fancyfoods.offers.SpecialOffer">
<service-properties>
<entry key="shop" value="chocolate"/>
<entry key="open">
<value type="java.lang.Boolean">true</value>
</entry>
</service-properties>
</service>
Looking again at the Blueprint, you can see that all the relevant information describing your service is available to the modeler. You can see the advertised interface and all of the service properties. From this XML snippet, it’s a trivial exercise to build a Capability describing the service.
From this example, it’s clear that Blueprint offers a mechanism through which you can model exposed services, and fortunately service requirements are as easy.
Modeling Blueprint References
In Blueprint the logical partner of the service element is the reference element. Where service exposes a Blueprint bean in the Service Registry, reference defines a Blueprint bean representing a service from the Service Registry. Just as Blueprint services make good capabilities, Blueprint references can be turned into requirements, as shown in the following listing.
Listing 7.7. A Blueprint reference definition
<reference id="reference"
interface="fancyfoods.offers.SpecialOffer"
availability="optional"
filter="(open=true)">
</reference>
Once again, the Blueprint XML snippet provides you with all the information you need to build a requirement, in this case the required service interface, and an LDAP filter expression that can easily be turned into the requirement’s filter. Importantly, there are a few other pieces of information contained within this XML snippet that allow you to determine the directives, as well as the attributes, that you should add to this requirement.
The easiest directive to spot from listing 7.7 is the availability directive. In this case, your Blueprint reference is optional, which can be communicated to the resolver easily. The second directive is somewhat more difficult to spot because there’s no attribute that corresponds to it. It’s the element itself that defines it. Because you’re using a reference element, you’re looking for a single service instance. This means that your Requirement object should have a cardinality of single.
Requiring Multiple Services
As you may remember, in Blueprint it’s possible to require multiple services with the same service interface. This is done using the reference-list element. The reference-list element is similar to the reference element, and again provides an excellent way to model service dependencies, as can be seen in this listing.
Listing 7.8. A Blueprint reference-list definition
<reference-list id="ref-list"
interface="fancyfoods.offers.SpecialOffer"
availability="mandatory"
filter="(open=true)">
</reference-list>
In listing 7.8, you can see that the attributes for your Requirement will be exactly the same as the attributes for listing 7.7. The directives, however, will be different. In listing 7.8, your Requirement is now mandatory not optional, and because this is a reference-list element, the Requirement must have multiple cardinality.
Now that you’ve seen how bundles can be modeled to support provisioning by package and by service, it’s time to take a look at some of the technologies that can be used to provision bundles at runtime.
7.3. Provisioning technologies
We’ve taken a good look at how provisioning works, and the things you can do to describe your bundles. Now that you’re armed with all this knowledge, we can take a look at the implementations available to you for provisioning your bundles. Provisioning technologies are responsible for integrating one or more repositories, such that you can identify, locate, and obtain your dependencies from them. Because the final version of the OSGi repositories standard is new, implementations are still emerging. But the precursor to the OSGi Repository Specification (Felix OBR) is an excellent provisioner, and there are other provisioners not related to the OSGi specification that are still more than up to the job. We’ll focus on a selection of open source provisioners.
7.3.1. Apache Felix OBR
The OBR subproject in Apache Felix was originally known as the Oscar Bundle Repository, and was introduced as a way of easily provisioning dependencies to get bundles up and running. OBR offers the following useful features:
- Support for exposing XML-based repositories in the runtime
- A mechanism for federating multiple repositories into a single repository view
- The ability to automatically install identified dependencies into the framework
Felix OBR has been around for a long time, and predates both the OSGi Repository Service and the OSGi Resource API. In fact, the work done in Felix OBR was used to create both of these specifications! Although both the name and concepts are similar, the OSGi Repository Service and historical releases of Felix OBR aren’t the same thing. To further muddy the waters, the OSGi Repository Service Specification was known as OBR during its—long—gestation. Because OBR predates the standardized OSGi Repository Specification, it’s currently more widely used. You’ll have to work out for yourself whether products with OBR support mean Felix OBR, a draft version of the OSGi repositories specification (also known as OBR or RFC-112), or the final version of the specification. Critical differences exist between the technologies that may make compatibility difficult. For example, in their XML serializations, the draft specification uses <require> elements and attributes, whereas the final version uses <requirement> elements and namespace elements.
Felix OBR is widely used because of its simple API and long history, but there are other popular OSGi provisioners.
7.3.2. Equinox p2
The Eclipse Equinox project provides the reference implementation for the core OSGi framework, but it also provides a number of other projects. Equinox p2 is a provisioning system, but not just for OSGi. The p2 system is a generic constraints resolver, and has been applied to a wide variety of problems. Importantly, p2 is the provisioning system used by the Eclipse project where it manages updates that can be applied to Eclipse applications.
One of the key criticisms leveled at p2 is that it’s perceived as being difficult to use. This is probably because p2 is a more general provisioning solution, and so it’s typically more effort to achieve specific use cases. Despite this drawback, p2 offers two particularly useful features that other provisioners don’t.
Transactional Installation
If you have multiple dependencies that need to be provisioned, which you almost certainly do, then p2 can install them as a single logical unit within a transaction. If any failures occur, then all the bundles will be uninstalled. This is different from other provisioners, where a provisioning failure can leave you in an inconsistent state.
Garbage Collection
Over multiple provisioning operations, you may find that the same dependency is needed by multiple bundles. In OSGi this is a good thing, because you gain the benefits of runtime, as well as development time, reuse. Unfortunately, this can cause problems when you want to uninstall a particular bundle; you may know that no other bundle is relying upon the bundle you want to remove, but what about the rest of its dependency graph? After you remove one bundle, you may find that there are other bundles that are no longer needed. This can be a long and difficult process, and may remind you of Java’s garbage collection model. With p2, these bundles can be garbage collected automatically, saving effort for the runtime.
7.3.3. Apache ACE
Apache ACE is a fundamentally different kind of provisioner than either Felix OBR or p2. OBR and p2 operate on a pull model, where the client tries to find out what additional bundles it needs to get a particular bundle running. ACE, on the other hand, operates with a push model. With ACE, you pick a set of bundles to install on remote targets and then, as new remote targets become available, the ACE runtime will push these resources out to the target. It should be noted that neither of these models is truly pull or push, but it’s a useful analogy.
Apache ACE doesn’t provide the same resolution capabilities that you get with OBR or p2, meaning that it doesn’t fill many of the use cases we’ve discussed in this chapter. ACE is, however, able to do something neither of the other provisioners we’ve discussed can: ACE can manage multiple OSGi application environments at once. This facility is useful for enterprise OSGi where, as your scaling requirements grow, you’ll need to maintain more and more servers. Ideally, you would combine ACE with another provisioning technology to get the best of both worlds.
7.3.4. Standard OSGi repositories
Several implementations of the OSGi Repository Specification are being developed at the time of writing. JBoss is working on a well-supported implementation of the specification. Karaf Cave is a promising implementation, with support for both OSGi bundles and Karaf features. Karaf can also proxy other repositories and generate metadata on the fly. It will be interesting to see how these projects mature. The Apache Felix Sigil project provides another implementation, as well as a set of UI tools and build plug-ins. We also expect that the Felix OBR project will update its implementation to comply with the standard.
No matter which technology you choose, to get the most from a provisioner you need access to a repository of bundles to provision from. Fortunately, there are a number of public repositories and repository generation tools available for you to use.
7.4. Bundle repositories
Much like the word database, the phrase bundle repository is overloaded. Database can refer to a technology system that manages data, or to a collection of data. Similarly, repository can refer to the technology for describing a collection of bundles, or to the collection of bundles itself. Earlier, thinking of repository technology, we compared a repository to a waiter in a restaurant with no menus. In its other meaning, a repository is also like the food the restaurant has available. If he has bills to pay, the same waiter might work in multiple restaurants, serving different menus. A single restaurant might also employ multiple waiters, so that customers can inquire about asparagus, asperges, or Spargel.
So far we’ve been talking about repository technologies such as the standardized OSGi repositories, OBR, and p2. But you’re going to need food as well as waiters! A number of public repositories make open source bundles available for provisioning against, and you can also generate your own repositories for internal hosting. You’ll most likely want to take advantage of both options and use a mix of public bundle repositories and ones specific to your project.
7.4.1. Public bundle repositories
Several open source projects host bundle repositories that support one or more of the repository technologies we’ve discussed. If you don’t need OSGi-specific metadata for provisioning, there are also a number of public repositories and projects that expose OSGi bundles as Maven artifacts. We’ll cover these simpler repositories later in section 12.1.1.
At the time of writing, none of the repositories we’ll discuss support the new standard OSGi XML repository format. The repository specification has been under active development for a long time, and most OBR repositories are based on a relatively old public draft of the specification, when the specification was still called OBR! This XML is supported by current releases of Felix OBR and other tools in Apache Aries, but isn’t up to date with the final specification.
The Felix OBR Repository
As well as providing a repository implementation, the Felix OBR project hosts a repository of around three hundred Felix bundles. Unlike most other public repositories, the Felix repository includes information about service requirements and capabilities. It can be accessed at http://felix.apache.org/obr/releases.xml.
The Apache Sigil Repository
The Apache Felix Sigil project offers enriched OBR metadata for bundles hosted by SpringSource in the SpringSource Enterprise Bundle Repository (EBR).
The Knopflerfish Bundle Repository
Knopflerfish is another open source implementation of the OSGi core specification, but it also offers a number of other OSGi services through its bundle repository. It supports both the old-school Oscar Bundle Repository format, at http://www.knopflerfish.org/repo/repository.xml, and the draft OSGi specification, at http://www.knopflerfish.org/repo/bindex.xml. The Knopflerfish repository is considerably smaller than the SpringSource EBR, but it still contains a number of useful dependencies.
The Sonatype OSS Repository
Although Sonatype Nexus is best known for hosting Maven repositories, it can also generate and host OBR data for its Maven repositories. The Nexus public repositories therefore can be used for OSGi provisioning.
The Eclipse Marketplace
If you’re using p2 instead of OBR, a number of repositories, also known as update sites, are available. An Eclipse update site uses XML metadata to describe one or more OSGi bundles, typically deployed as a set that make up an Eclipse plug-in. Eclipse update sites don’t model the bundles they describe in the same way that we’ve described in this chapter, but are commonly used, particularly in conjunction with the p2 provisioner. The Eclipse Marketplace is an example of one of the many available Eclipse update sites.
What happens if the bundle you need isn’t available in one of the public repositories? If you want to provision against bundles you’ve written yourself, this is almost certainly the case. Even widely distributed bundles may not be available in a public OBR repository. The good news is that generating repositories is so easy, you may already be doing it.
7.4.2. Building your own repository
A number of tools are available that can generate repositories from Maven repositories or the filesystem. They can even be integrated into your build process.
Bindex
The most popular tool for generating OBR XML repositories is called Bindex. Bindex models the dependencies that are declared in the bundle manifest, and recent versions are able to use Blueprint and Declarative Services metadata to create requirements and capabilities for services.
The Maven Bundle Plug-in
Although Bindex has excellent function, it does need to be downloaded and explicitly run. A more convenient alternative is the maven-bundle-plugin, which embeds Bindex. The maven-bundle-plugin will automatically generate OBR metadata in a repository.xml file in the local Maven repository, so you may already be creating OBR repositories without even knowing it! The bundle plug-in has extra goals to deploy bundles to remote OBR repositories and generate an OBR repository from all the files in an existing Maven repository:
mvn org.apache.felix:maven-bundle-plugin:index
Listing 7.9 shows part of an OBR repository automatically generated by building the Fancy Foods application with Maven. If you compare it to the OSGi standard repository from listing 7.1, you’ll see it’s less generic but also more human-readable. We anticipate later versions of the Maven bundle will be able to produce both OBR and standard repository serializations.
Listing 7.9. An OBR repository.xml generated by the Maven bundle plug-in
<repository lastmodified='17874783'>
<resource
id='fancyfoods.department.chocolate/1.0.0'
symbolicname='fancyfoods.department.chocolate'
presentationname='Fancy Foods Chocolate Department'
uri='fancyfoods/fancyfoods.department.chocolate/1.0.0/
fancyfoods.department.chocolate-1.0.0.jar'
version='1.0.0'>
<size>5151</size>
<capability name='bundle'>
<p n='symbolicname' v='fancyfoods.department.chocolate'/>
<p n='presentationname' v='Fancy Foods Chocolate Department'/>
<p n='version' t='version' v='1.0.0'/>
<p n='manifestversion' v='2'/>
</capability>
<capability name='service'>
<p n='service' v='fancyfoods.offers.SpecialOffer'/>
</capability>
<capability name='package'>
<p n='package' v='fancyfoods.chocolate'/>
<p n='version' t='version' v='0.0.0'/>
<p n='uses:' v='fancyfoods.food,fancyfoods.offers'/>
</capability>
<require
name='package'
filter='(&(package=fancyfoods.food)(version>=1.0.0)
(!(version>=2.0.0)))'
extend='false'
multiple='false'
optional='false'>
</require>
The bundle plug-in can read an obr.xml file for supplemental information about requirements and capabilities. For example, if you need to document toffee sauce requirements, you can handle them with an obr.xml fragment.
Apache Aries Repository Builder
Apache Aries also provides a command-line repository building tool that models package dependencies, but also makes use of the Aries Blueprint implementation to model Blueprint services and references. The command syntax is as follows:
java -jar org.apache.aries.application.tooling.repository.generator-1.0.0.jar [repository xml location] url1 [url2...]
Nexus Repositories
If you’re using Nexus for Maven hosting, Nexus’s ability to expose an OBR-compatible view of the repository can be convenient. This provides an excellent way to share existing artifacts without impacting existing infrastructure.
Modeling by Hand
As we discussed in section 7.2.2, the ability of these tools to generate repositories that allow service-based provisioning depends on service metadata being available. For those of you that don’t want to use an injection container, or if you want to describe nonstandard requirements, all isn’t lost! Because there’s a standard XML serialization for OSGi repositories, it’s entirely possible to author your own resource descriptions. You need to be careful to keep the description of your resource up to date if your bundle ever changes, but it does give you all the flexibility you could ever need. You can also hand decorate the repository descriptions generated by a tool with additional service capabilities and requirements as necessary. The schema for the bundle repository format is available at http://www.osgi.org/xmlns/repository/v1.0.0/repository.xsd. Services should use the osgi.service namespace and objectClass attribute.
You can provision directly against repositories generated using one of these tools, or you can use one of the repository implementations we discussed in section 7.3 to create a federated view of your local repository and one or more of the public repositories.
7.4.3. Generating your repository
The Apache Aries repository generation tool processes a set of bundles in a directory, turning them into an XML repository. To start with, let’s put your application bundles in a directory on disk.
Now that you have a location on disk to scan, you need to get hold of the repository generator. The repository generator uses a live OSGi framework to model the bundles, which ensures that it can validate any extra namespaces used in your Blueprint bundles. To validate these namespaces, the repository generator also needs the bundles that provide these extra namespaces.
The Apache Aries modeler is new, and so isn’t available as a set of released modules. To get hold of the application modeler, you can either get one from a nightly snapshot of the Aries build, or by building Aries yourself. The bundles you need exist in the target directory of the application/application-tooling-repository-generator. If you copy the contents of this directory to somewhere a little more accessible, then you can use them to build your repository.xml using a single, simple command. Before you can launch the generator, you must remember to add the bundles that supply the namespace extensions that you used in your application. In this case, you need the transactions and JPA namespace handlers.
The transactions namespace handler is available as a released bundle called transaction.blueprint, or from a build in the transaction/transaction-blueprint/target directory. It also depends on the JTA API; this bundle can easily be retrieved from the test stack you used in chapter 3:
java -jar org.apache.aries.application.tooling.repository.generator-<version id>.jar [repository xml location] url1 [url2...]
In the command to launch the repository generator, you need to replace the <version id> with the build ID of your repository generator JAR. The repository xml location parameter is optional, and defaults to ./repository.xml. The URL that you supply points to a directory of bundles that you wish to build a repository from, and you may optionally supply further URLs to scan and aggregate into a single repository.
7.5. Summary
This chapter has covered the provisioning process in a lot of depth. We hope that by now you have a good understanding of how resolvers can solve the constraint problems offered by bundle dependency graphs. You’ve also learned how bundle repositories work and, if you wanted to, you could probably write your own tool for generating a repository, both at runtime and in XML.
You may have come to the end of this chapter thinking that there isn’t much reason for you to know about repositories and modeling to this level of detail. We, on the other hand, would disagree. The most common problem we come across when people are building enterprise OSGi applications is that their application doesn’t resolve. The next-most-common problem is that the application does resolve, but not in the way the developer was expecting. For many people, the errors output by the resolution process are completely opaque, as is the underlying process itself. Armed with the information in this chapter, you should have no difficulty in diagnosing any resolution problems you see; other developers will probably seek you out to help them as well!
Now that you’ve seen how repositories can be a useful tool for locating dependencies, it’s time for us to look at other tools that can speed and ease the enterprise OSGi development cycle.