
Chapter 6
Resolve and Retrieve Phase – Identity Resolution
Abstract
The resolve and retrieve phase of the CSRUD life cycle is the primary use case for MDM as an application. Client systems provide entity identity information in exchange for the identifier of an entity, a process called identity resolution. From an MDM perspective, two important aspects of identity resolution guides its implementation and underlying architecture. These are its mode of access – batch versus interactive – and its universe model – open universe versus closed universe.
Keywords
Identity resolution; batch access; interactive access; closed universe; open universeIdentity Resolution
Identity resolution is an EIIM configuration where the input is entity identity information and the output is the identifier of the EIS representing the entity. Identity resolution can be thought of as a recognition process. In other words, does the MDM system recognize the identity information given to it as referencing one of the entities the system has under management? In CDI, the customer version of MDM, identity resolution is often referred to as customer recognition.
Identity resolution is perhaps the most important configuration in EIIM. One of the fundamental principles of information quality is that information only creates value when it is used (McGilvray, 2008; Talburt, 2011). In addition, as McGilvray also points out, the planning, obtaining, storing, sharing, maintenance, and disposal of information are all necessary parts of the information life cycle, but they represent overhead cost. The benefits that offset cost and create information value are only realized when the information is used to accomplish some purpose. In MDM, the purpose is to provide the enterprise with persistent entity identifiers having the highest possible identity integrity.
Two major considerations influencing the implementation of the identity resolution configuration are access mode and universe model.
Identity Resolution Access Modes
Client systems obtain entity identifiers from the IKB through the EIIM identity resolution configuration in two primary ways. The first is batch mode and the second is interactive mode (Kobayashi, Nelson, & Talburt, 2011). Many MDM systems support both modes of identity resolution.
Batch Identity Resolution
Although batch is often associated with processing large files of records, the fundamental difference between batch and interactive mode is not so much about the quantity as it is about time. When the client system submits entity references to an EIIM identity resolution configuration in batch mode, it is with the expectation that the identifiers for the entities will be returned at a later time. How much later the identifiers are returned can vary considerably from hours to days depending upon the nature of the application. Often the delay between submission and reply is governed by a service level agreement (SLA) setting out requirements for the maximum amount of delay.
The schema for a typical batch identity resolution process is shown in Figure 6.1. The client system submits entity references to the EIIM system for resolution. The references usually undergo standardization and other data quality cleansing and validation operations at the staging step. The entity resolution system attempts to match each input reference to one of the EIS under management in the IKB. If a match is found, then the identifier of the matching EIS is paired with the identifier of the reference in the link index table. If a match is not found, the system will pair the reference with a special identifier discussed in more detail later. After the references have been processed, the system writes the link index table and makes it available to the client system.
It is usually the responsibility of the client system to read the link index table, and to update the original input reference with its resolved entity identifier from the link index table. The first column of the link index table is the list of identifiers for all of the references input into the system. The second column of the table contains the entity identifier corresponding to the reference identifier in the first column. If the input references are in a relational database table, then the link index table can also be written directly to, or loaded into, the same database. At this point the entity identifiers from the link index table can be easily appended to their corresponding references through a simple database join operation.
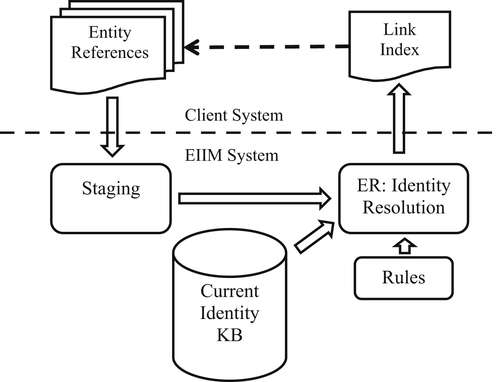
If the reference file is too large for a traditional relational database, then both the references and link index can be loaded into a NoSQL data store such as the Hadoop Files System (HDFS) or HBase. Big Data stores like HDFS and HBase store data as key-value pairs. Unlike traditional relational databases, the data are often left unnormalized and the keys are not required to be unique. The join operations for these systems are accomplished through Hadoop map/reduce jobs instead of an SQL query.
Some EIIM systems are designed to update the input references directly. Rather than creating a separate link index table, the EIIM system writes the entity identifier directly into a user-designated field of the input reference. In these types of systems, the identity resolution configuration is often referred to as the link append process, because the EIIM system appends the entity identifier value to the input reference.
Managed and Unmanaged Entity Identifiers
The value of the identity resolution process is that it greatly reduces the effort the client system must expend to detect equivalent references. All of the references for the same entity should be paired with (or have appended) the same entity identifier in the link index table. This makes finding equivalent (duplicate) references a simple matter of sorting the link index table by the entity identifier column. Where the link index is in a Big Data store as key-value pairs and the key in the reference identifier, the sort will take the form of a map/reduce step. The mapper inverts the link index, i.e. it makes the entity identifier the key and the reference identifier the value. The reduce step then shuffles (sorts) and brings together all of the references with the same entity identifier.
For example, if the input references represent customer sales transactions and the entities under management are the customers, then after the identity resolution process all of the transactions for the same customer will have the same customer identifier. In this respect, MDM can be viewed as a technique for reuse of ER effort.
An identifier assigned to one of the EIS under management in an MDM system is called a managed entity identifier. To this point the discussion has been based on the assumption there is a matching EIS and, consequently, a managed entity identifier for reference input into the identity resolution process. However, this is not always the case. There may be instances where an input reference does not match any of the EIS under management in the IKB. In this situation, the MDM system will create a default entity identifier. Because the default entity identifier is not saved or maintained in the IKB, the default identifiers are also called unmanaged entity identifiers.
There are two main strategies for unmanaged entity identifiers. The first strategy is to pair the reference identifier with a special identifier value set aside for this purpose. When a value is returned as the identifier it tells the client system no match was found. In this strategy, all no-match references are given this same no-match identifier value. Furthermore, the no-match identifier value is created in a way to guarantee it will not collide with any of the managed entity identifiers. It is the responsibility of the client system to recognize the no-match identifier value and to implement any logic to properly handle it differently than it would a managed identifier.
An alternate no-match strategy is to create a temporary or local entity identifier for references not matching a managed entity. In this case, the unmanaged identifier is created by hashing certain identity attribute values in the reference. For example, in a customer reference, the unmanaged entity identifier might be created by concatenating the first letter of the first name, the first eight letters of the last name, and the street number of the address. Even though these hash keys are unmanaged, they can provide more value to the client system than simply providing the single, no-match indicator of the first strategy.
The reason they are useful is that the unmanaged hash keys are essentially match keys. Two references will only produce the same unmanaged identifier if the identity attribute values used to produce the identifier are similar. Consequently, when the client system brings together references appended with same entity identifiers, there is a higher likelihood the references with the same unmanaged identifiers are equivalent. The likelihood of equivalence may not be as high as it would be for two references given the same managed entity identifier, but nevertheless it provides some guidance to the client system about possible equivalent references. Just as with the special no-match identifier of the first strategy, the unmanaged identifiers created by hashing are formatted in such a way that the client system can easily discriminate between the managed and unmanaged entity identifiers.
The identity resolution configuration of EIIM in Figure 6.1 is similar to the automated identity update configuration shown in Figure 5.1, but with some important differences. The first and most important difference is the IKB is not updated in the identity resolution process. In identity resolution, the input references act only as inquiries into the IKB to retrieve entity identifiers. The content of the IKB is not altered by the identity resolution process.
That is not to say that identity update does not provide identifiers, because it does. The automated update process also provides the client with a link index as one of its outputs, thus it also performs identity resolution. However, the identity resolution provided by the automated update process through the link index is really a byproduct of the process, not its primary purpose. The primary purpose of the update process, both automated and manual, is to enrich the IKB with new entity identity information from high-quality entity reference sources.
Because the IKB is not expected to be altered in the identity resolution configuration, the quality of the input references can be much lower than the threshold required in the identity update configuration. Of course, the garbage-in-garbage-out (GIGO) rule still applies. The quality of a reference input into the identity resolution process will still influence the quality of the output. However, the difference is that in the identity resolution configuration, low quality input references will not lower the identity integrity of the IKB.
Interactive Identity Resolution
Interactive identity resolution takes place when a client system submits an entity reference to the MDM system with the expectation that the identifier for the corresponding entity will be returned in real time. Because real time is generally understood to mean the client system will hold further processing until the reply is received, the actual amount of time will depend upon the application. Again using the example of customer MDM, if the application is to support a point-of-sale (POS) transaction in a store, the time between entering customer identity information and receiving the managed identifier for the customer may be a matter of a few seconds. As long as the delay does not burden either the customer or the sales person, then it is considered a real-time transaction.
For system-to-system transactions, the bar may be set orders of magnitude higher and subsecond response times may be necessary. Another consideration is the total volume of transactions and the impact on the overall throughput of the system. For example, if a POS transaction needs to be completed in one second for each user, but one thousand user transactions are expected to arrive each second, then each of these requests must be serviced in one-thousandth of a second in order for each user to experience no more than one second of delay. For this reason, an SLA for response-time performance can be even more important for interactive identity resolution than it is for batch identity resolution.
As shown in Figure 6.2, interactive identity resolution is usually mediated through an application programming interface (API). An API is basically a contract between two systems specifying that when a defined set of input values are given, a defined set of output values will be returned. In the case of identity resolution, the inputs are values of entity identity attributes, and the value returned is the entity identifier, either managed or unmanaged.
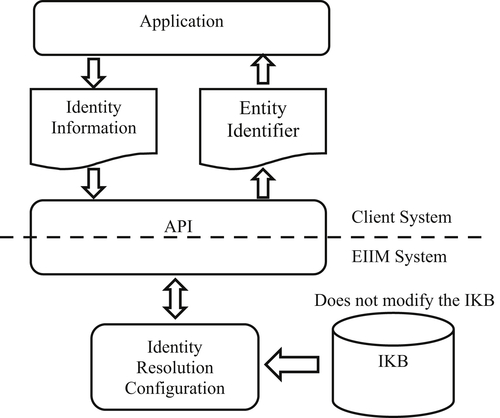
Identity Resolution API
Many options for the implementation of an API for identity resolution follow a number of API standards such as Common Object Request Broker Architecture (CORBA) and the Representational State Transfer (REST) architecture of the World Wide Web (so called RESTful APIs). However, the purpose of the discussion here is not to delve into the details of implementation, but to simply point out some of the high-level design considerations.
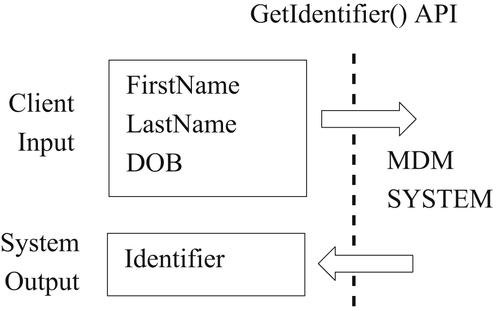
The primary trade-off in API design is between control and complexity. Take as an example a simple identity resolution API shown in Figure 6.3 for a student MDM application. Here the client exchanges the student’s first name, last name, and date-of-birth for the student’s identifier.
The simplicity of the GetIdentifier() design comes with a certain surrender of control by the client. Except for the choice of search values, all other aspects of the exchange are determined by the system hub. For example, the only options for client input are the three identity attributes of first name, last name, and date-of-birth, even though there could be many other searchable attributes such as middle name, address, or gender.
The GetIdentifier() API in Figure 6.3 does not allow the client to specify any matching criteria. In fact, the matching criteria are not exposed. It would be up to the client to understand exactly how matching takes place, and to assess its suitability for a particular application. Understanding the API documentation would also be important to know how likely it is that when GetIdentifier() returns a managed identifier, it is the correct identifier for the reference. For example, if the input reference matches two or more entities, does the API simply select one at random or is other logic invoked? When the GetIdentifier() API returns an unmanaged identifier, how does the client know the reason? Was it because no match was found? Or was it because the reference matched more than one entity?
Giving the client more control is a usually a design choice of making a more complex API to accommodate more client parameters and choices, or to create multiple APIs where each API implements only part of the logic. When a decision is for a family of APIs, then the client may need to make several calls to different APIs to complete a process.
API Families
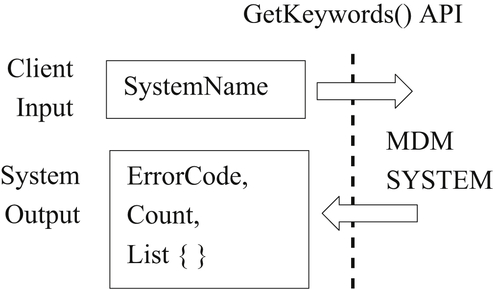
The notion of an API family is similar to class libraries in object-oriented programming languages such as Java. The API family supports overall objectives such as facilitating identity resolution, but each API in the family is responsible for only one particular task or function. Figures 6.4 and 6.5 show a GetKeywords() API and a GetIdentifierList() API working together to give the client system more control over the identity resolution configuration.
The GetKeywords() shown in Figure 6.4 returns as output a list of string values representing all of the searchable identity attributes for the system named in the input. More specifically, GetKeywords() returns three outputs. The first is an error code signaling the client whether the API transaction was executed successfully, or if not, some indication of why the transaction did not complete. For example, one value of the error code might indicate that the system name given was invalid, or another value that the requested system was unavailable at the time the API was invoked. Providing an error code or completion code to the client is always a good API design choice. The second output of GetKeywords() is the number of keywords returned, and the third output is the actual list of keywords.
For example, suppose the client system is a visualization tool supporting the manual update process as described in Chapter 5. Then the GetKeywords() might be called at system initialization time to populate a dropdown list of search qualifiers or to validate search qualifiers manually entered by the operator.
Unlike the simple GetIdentifier() API of Figure 6.3, the GetIdentifierList() shown in Figure 6.5 allows the client to search on any combination of identity attribute values. For example, suppose the GetKeywords() returns the list “First”, “Middle”, “Last”, “DOB”, and “Gender”. Then the list given as input to the GetIdentifierList() might look like “First:Geneva”, “Gender:F”, “DOB:19970507” where the client specifies a search for female students with first name “Geneva” and born on May 7, 1997.
In addition to allowing the client to select its own combination of search terms, the GetIdentifierList() API allows the client more control over the matching process. The assumption for this example is that the GetIdentifierList() API is using a scoring rule such as the one described in Chapter 3 to match search terms to EIS. The first input of the GetIdentifierList(), shown as “Threshold” in Figure 6.5, establishes the minimum score constituting a match.
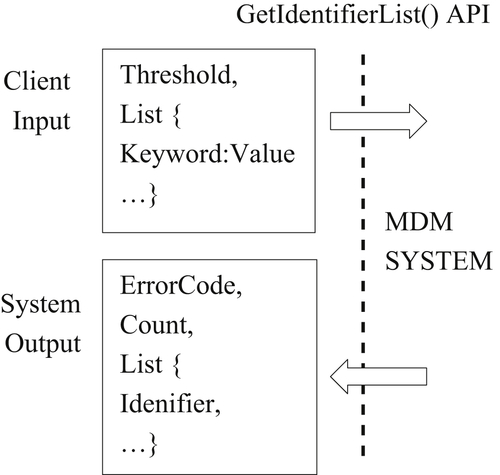
The output from GetIdentifierList() is similar to the output from GetKeywords(). The client system receives an error code indicating the success or failure of the invocation, the number of EIS matching the search query, and the list of identifiers for the matching EIS.
The APIs given here by no means constitute a complete design. They are only given to illustrate some of the features and considerations going into API design. This family could have many other APIs. For example, another API might be named SetWeights() allowing the client to set the agreement and disagreement weights of a scoring rule that does the matching. Other APIs might be related to security and governance; for example, there could be an API requiring the client to give a username and password in exchange for an access token required to invoke other APIs.
Confidence Scores
In many respects, the two API examples discussed here represent the extremes. The simple GetIdentifier() makes all of the decisions about the matching and gives the client a single answer. On the other hand, the API family including functions such as GetKeywords() and GetIdentifierList() would give the client access to a detailed level of information and empower more sophisticated decision-making on the client side. An API family providing this level of detail would be needed to support complex applications, such as a visualization tool where domain experts need to review information in detail before making correction and confirmation decisions.
However, if the client is another automated system, then an intermediate strategy is often a better fit, one allowing the client system to participate in making a decision about the output. One technique is to provide the client with a single output identifier, and along with it, a second value called a confidence score or confidence factor. The purpose of the confidence score is to give the client system some quantitative measure of the likelihood the identifier provided by the identity resolution API is the correct identifier for input reference.
Given a reference having some level of match to one or more managed EIS, the calculation of a confidence score needs to take three factors into account – the depth of match, the degree of match, and the match context. The depth of match is measured by how many different identity attribute values participate in the match, whereas the degree of match is how closely the values of each attribute match. Finally, the match context comprises all of the EIS having defined some level of match to the reference in question.
Depth and Degree of Match
Decisions about the depth and degree of match not only have a bearing on identity resolution but are also an integral part of the crafting of ER match rules for the capture and update configuration. In considering whether a match rule will predict equivalence, both influences must be considered. Take, as an example, the process of crafting Boolean rules for student MDM. Match depth is about how many identity attributes should participate in a match. Is a match on first name and last name enough? In most cases, probably not. For common names, many different students could share the same first and last name. An extension would be to add agreement on date-of-birth to the rule. Now the question becomes whether there also different students who share the same first name, last name, and date-of-birth. As new attributes are added, it becomes increasingly likely that the references agreeing on all of the values are equivalent and less likely they would not be equivalent.
As a reminder, high-quality MDM can only be attained when the answers to questions like the ones here are answered through data analysis rather than heuristics or intuition, as is so often the case. The effort expended in developing and using the techniques of truth set development, benchmarking, and problem sets discussed in Chapter 3 is an investment that will pay back many times in the long term.
At the same time, the depth of match must be tempered with the degree of match. The pervasiveness of poor data quality usually requires agreement between values that must be defined as something less than identical, i.e. less than an exact match. The recognition that the values of identity attributes will almost always have variations and corruptions has driven the development of a plethora of matching algorithms. Each algorithm is designed to overcome some particular type of variation known to occur in identity attribute values. These approximate or fuzzy matching techniques provide a way to measure the degree of match.
Take, as a simple example, the maximum q-gram similarity, which is a special case of the Jaccard Index character strings. Given two string values, the maximum q-gram similarity is the length of the longest shared substring divided by the length of the longest string. For example, consider the two string values “HALVERS” and “EVERST”. The longest substring that they share is “VERS” with a length of 4 characters. Because the longest string “HALVERS” has 8 characters, the maximum q-gram similarity is 4/8 = 0.50 or 50%. It is also easy to see that the maximum q-gram similarity can only be 100% when the two strings are identical, and the similarity will be 0% for two strings not having any characters in common.
Given a depth of match and a degree of match, a reference-to-reference match may be assigned a score using several methods. Suppose the depth of match is a set of N identity attributes and the degree of match is determined by a similarity function F (like maximum q-gram) taking on values between 0 and 1. If aj represents the value of the j-th identity attribute of the first reference A, and bj represents the corresponding j-th attribute of the second reference B, then a commonly used pattern to calculate a match score follows the formulation
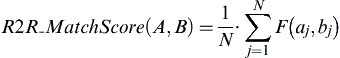
The match score is simply the average of the similarity scores between each of the corresponding attribute values of the two references.
For example, suppose N = 2, and the two attributes are student first name and last name. Let reference A be (“JON”, “HALVERS”) and reference B be (“JOE”, “EVERST”). Also, let F be the maximum q-gram similarity function. Then
![]()
A more sophisticated version of this formulation allows the user to assign different weights to each attribute. This is helpful when the similarity for certain identity attributes is a better predictor of equivalence than other attributes, as these can be given higher weights.
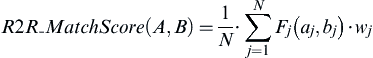
where
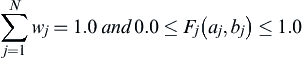
The second formulation also allows attributes to be compared by different similarity functions. For instance, if one of the identity attributes is date-of-birth, then a similarity function designed to measure similarity in the number of days between two date values would be more appropriate than something comparing string similarity like the maximum q-gram similarity function.
All similarity functions are required to return values between 0 and 1 and the weights assigned to each attribute must total 1.0 to ensure the match score value will also be a value between 0 and 1.
However, in identity resolution the match is between a reference and a managed EIS in the IKB. What is needed is a reference-to-structure score. Again, a reference-to-structure match score may be formulated in many ways and will depend upon the architectural design of the EIS. For systems that implement record-based EIS design, as discussed in Chapter 4, a reference-to-structure match score can be easily formulated as follows. Let A represent a reference with N attributes and let S represent a record-based EIS containing M references R1, R2, …, RM. Then a reference-to-structure match score can be defined by
![]()
In this formulation, the reference-to-structure match score is simply the largest reference-to-reference match score taken over all of the references comprising the record-based EIS.
Match Context
The third component of an identity resolution confidence score is the match context. While it is important to understand the level of match between a reference and any one particular EIS, it is also important to understand how many other EIS also have some level of match to the same reference. These other EIS and the reference form the match context. However, the way in which a match context interacts with reference-to-structure match scores to create a confidence score will depend upon the universe model of the identity resolution configuration.
Closed and Open Universe Models
An identity resolution configuration is said to use a closed universe model if all of the input references requesting an identifier from the system are references to entities already under management. In other words, only references to managed entities are given as input to the identity resolution configuration. In a closed universe, the question is not whether a reference is to a managed entity; rather it is only which managed entity is being referenced.
On the other hand, an identity resolution configuration is using an open universe model if some of the input references requesting an identifier from the system are references to entities not under management. In an open universe model the system is being asked to recognize whether a reference is to an entity under management with the expectation some references will not be recognized. The identity resolution configuration will return an unmanaged entity identifier in response to an unrecognized reference, but it will not update the system.
Open and closed universe models describe the context of the identity resolution configuration and not the MDM system itself. The same MDM system may run an identity resolution configuration in both open and closed models at different times. Take, as an example, a student MDM system for a school. Suppose all of the students in the school or in a particular class take a standardized examination. When taking the examination students fill in their multiple-choice answers on a scan sheet along with their name and date-of-birth. These answer sheets are then scanned and captured as electronic records. Finally, the answer sheet records are submitted to an identity resolution configuration of the student MDM system to obtain the student’s managed identifier.
In this examination scenario, the identity configuration is operating in a closed universe model because the expectation is that every test record references a student under management in the MDM system. However, the closed universe model does not necessarily guarantee every reference will have a managed identifier appended. There could be many reasons why an answer sheet fails to receive a proper identifier, such as a scanning error corrupting the information, a damaged scan sheet, or the student incorrectly entered information. Nevertheless, each record generated from a scan sheet is intended to reference one of the students in the school or class who took the examination.
In a different scenario, the school is sponsoring an event open to the public. However, students of the school sponsoring the event are entitled to a special discount on their registration fee. One of the functions of the event registration system is to pass each attendee’s registration information to an identity resolution configuration of the school’s MDM system to determine if the attendee is a student. In this open universe scenario, only the registration records for students of the sponsoring school are expected to match and return a managed identifier, while the records for other attendees should not.
Confidence Score Model
To understand the confidence score model, first consider the case of closed universe identity resolution. Here the guiding principle is any match is a good match. This is because in a closed universe model the input reference is presumed to match one of the EIS, and therefore, it is presumed to be the EIS with the highest reference-to-structure match regardless of the actual score.
Consider an example where the depth is 3 attributes all with equal weights. Suppose an input reference R has a 0.333 match score with a structure S because it has an exact match on one attribute, but the values of the other two attribute values are missing. Further suppose R has a 0.000 match with all other structures in the IKB, i.e. R and S form the complete context. Even though this is a low match score in absolute terms, because of the closed universe assumption, the confidence score for the match to S is essentially 1.00 or 100%. In other words, the API would give the client the managed identifier of S with a confidence score 1.000 that it is the correct identifier even though the reference-to-structure match score is only 0.333.
Now suppose reference R is more complete with only one attribute value missing. Further suppose the two non-null attributes are an exact match to structure S1 giving it a 0.667 reference-to-structure match score. Also suppose R has a 0.500 match score with structure S2, and a 0.000 match score with all other structures. Even in this case the API should return to the client the managed identifier of S1 with a confidence of 100%. The reason is that R is known to match one of the structures and because S1 provides the highest match, it must be the one.
The only exception to the highest-score-wins principle is when two structures have the same, or essentially the same, match scores. Now it becomes ambiguous as to which structure is the correct one. For example, if R has a 0.667 match with both structures S1 and S2, then the API would return the identifier for S1 (or S2), but with a confidence score of 0.500 or 50% because there is essentially a 50/50 chance it could be equivalent to either one. Similarly, if R matched S1, S2, and S3 with the same score of 0.667, then the confidence score for the identifier of S1 would be 0.333 or 33%, the equal distribution of the 100% among the three competing EIS.
Although this is greatly simplified, the underlying principle holds. If the structure with the highest match score is a clear winner in the context of other structures, then its identifier should be returned along with the maximum confidence score. If there is a tie for the highest level of match, then the identifier for the one the EIS and confidence score returned is the maximum score divided by the number of matching EIS.
Again due to data quality issues, it is unlikely the confidence score for the highest reference-to-structure match will always be 100%. For example, in a customer MDM, suppose that S1 is a structure representing customer Mary Smith. If Mary were to change her name to Mary Jones, then it would be possible that a reference R with the name Mary Jones may generate a higher reference-to-structure score with some structure R2 representing a different customer, also with the last name of Jones. These and other possible scenarios would indicate that the confidence score would tend to decrease as the highest reference-to-structure score decreases.
The function G plotted in Figure 6.6 shows this relationship. In the closed universe, the confidence remains high even for smaller match scores. However, Figure 6.7 shows that in the open universe model, the behavior of the function G is much different.
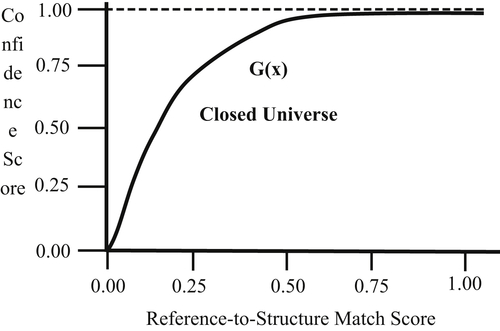
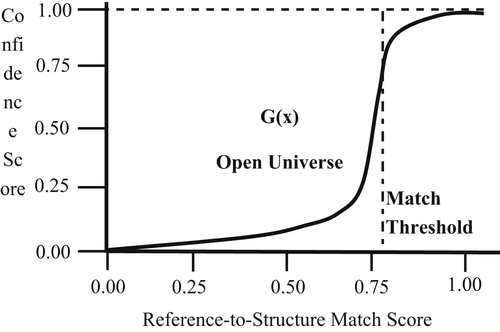
In the open universe model the probability that an identifier is correct for a given reference remains small until the value approaches the match threshold. The match threshold is the degree of match equivalent to an ER match rule used in a capture or update configuration.
The only remaining factor is in defining whether the EIS with the highest match score to the reference is a clear winner. Within a given match context, several EIS could have the same or similar match scores as the highest match score. To address this issue, let R be the input reference, let Γrepresent the set of EIS having a nonzero match score with R, i.e. R and Γ are the match context. If μ represents the reference-to-structure match score function and E0 represents the EIS in Γ having the highest match score with R, then define
![]()
T is the count of EIS having match scores within δ of the highest match score. Because this includes E0, T must be at least 1. Just as with the probability function G, the value of δ should be determined empirically.
Applying these principles, the confidence score for both the closed and open universe models can be formulated as
![]()
Concluding Remarks
The resolve and retrieve phase is the most important of all the CSRUD MDM life cycle phases. Resolving an entity reference to its correct entity (EIS) is the primary use case for MDM – the phase producing value for the enterprise.
A major issue for the resolve and retrieve phase is the synchronization of identifiers in the MDM hub with identifiers residing in client systems. As identifiers change in the hub, the changes must somehow be propagated to the clients’ systems. The two primary strategies are periodically pulling source records from the clients’ systems back to the hub for re-resolution to refresh the identifiers, and pushing changes from the hub to client systems as they occur. The pull model is the simpler of the two strategies, but for some organizations and applications, the pull model may not meet the business and functions requirements for the MDM application.
In addition to synchronization, quantifying the reliability of a resolved identifier is also a problem. The reliability of identification will vary from inquiry to inquiry depending upon the depth, breadth, and context of the match to the EIS in the identity knowledge base. In order to provide guidance to the inquiring client system, some MDM systems compute a confidence score for each inquiry providing the client system with an estimate of the likelihood that a resolved identifier is correct.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.