
Chapter 7
Theoretical Foundations
Abstract
This chapter contains a discussion of three major theoretical models supporting modern MDM systems: the Fellegi-Sunter Theory of record linkage that laid the foundation for both Boolean and scoring rule design and the notion of clerical review; the Stanford Entity Resolution Framework (SERF) that gives a mathematical definition of entity resolution of a set of references and algorithms always arriving at resolution; and the Entity Identity Information Management (EIIM) model that extends entity resolution to address the life cycle management of information and how it articulates with both the Fellegi-Sunter and SERF models of ER.
Keywords
Fellegi-Sunter model; SERF; EIIM; Stanford entity resolution framework; entity identity information managementThe Fellegi-Sunter Theory of Record Linkage
In 1969, I.P. Fellegi and A.B Sunter, statisticians working at the Dominion Bureau of Statistics in Canada, published a paper titled A Theory for Record Linkage (Fellegi & Sunter, 1969) describing a statistical model for entity resolution. Known as the Fellegi-Sunter Model, it has been foundational to ER, and by extension MDM, in several fundamental ways:
• It described record linking, a particular configuration of ER, in a rigorous way using the language of mathematics and statistics.
• Although the structure of the matching rule is no longer used exactly as they described it, it still informs both of the most frequently used styles of matching used today, Boolean rules and scoring rules.
• It emphasized the role and importance of entity resolution analytics. The fundamental theorem is about optimizing match rules with respect to a maximum allowable false positive rate and a maximum allowable false negative rate.
• It defined a method for generating clerical review indicators. The proof of the fundamental theorem relies on the assumption that human reviewers will always be able to correctly decide if a pair of references indicated for review are equivalent or not equivalent.
The Context and Constraints of Record Linkage
The theory of record linkage is set in a special context of linking across two lists of references. It addresses the problem of finding equivalences between pairs of references where one reference is in the first list and the other reference is in the second list. In the proof of the theorem, they generously assumed the list had no equivalences. In other words, no two references within the same list were equivalent; equivalences could only be found between the two lists. This is much different than the context described in the previous chapters where the input is a single set of references. Although the EIIM configuration of merge-purge is often called record linking, technically record linking and merge-purge are different processes. In the merge-purge configuration of EIIM, a single list of references is partitioned in clusters of presumed equivalent references, whereas record linking takes place only between two separate lists of references.
From an analytical perspective, if X and Y represent the two lists, then the number of pairs to be considered for record linking will be |X|∗|Y|, the size of the cross product X× Y. In merge-purge, there are (|X| + |Y|)∗(|X| + |Y|−1)/2 pairs to consider. Moreover, in record linking, the maximum number of equivalences possible will be Minimum{|X|, |Y|} because each reference in List X can only be equivalent to, at most, one reference in List Y. If a reference in List X were equivalent to two references in List Y, then by transitivity of equivalence, the two references in List Y would necessarily be equivalent and contradict the assumption that no two pairs of references in List Y are equivalent. A similar argument holds that each reference in List Y can only be equivalent to, at most, one reference in List X.
However, the confusion is forgivable. Just from a practical viewpoint, starting an ER process with two lists where each list is known to be free of equivalent references is rare. Given two lists of references in the real world there could well be equivalent references within each list as well as between the two lists. As a practical matter, record linking is often implemented by first merging the two lists into a single list, then running a merge-purge or identity capture configuration. If the two lists are truly free of internal equivalences, then each cluster formed in the merge-purge process can comprise only a single reference or two references where each is from a different list. The latter indicates a link between the two lists. On the other hand, if a cluster contains two references from the same list, then the two references are presumably equivalent and this indicates the assumption was not justified. In this way, equivalence references can be found in one process both between the lists and within each list.
The Fellegi-Sunter Matching Rule
An understanding of the Fellegi-Sunter matching rule is essential to understanding the overall theorem. Another assumption is the two lists of references have the same number and types of identity attributes. In other words, there is a one-to-one correspondence between the identity attributes in the first list and the identity attributes in the second list. Suppose in the first list, List X, each reference has N identity attributes x1, x2, …, xN, and in the second list, List Y, each reference has the corresponding identity attributes y1, y2, …, yN.
An agreement pattern between two references from Lists X and Y is an N-bit binary number where the k-th bit of the binary number represents the state of agreement between the k-th identity attribute of List X (xk) and the k-th identity attribute of List Y (yk). If the k-th bit of the pattern is a 1, then the two attributes agree in value. If the k-th bit of the pattern is a 0, then the two attributes disagree in value.
Take, as a simple example, two Lists X and Y sharing three identity attributes, say first name, middle name, and last name of a customer. Then the agreement patterns will be 3-bit binary numbers. For example, the agreement pattern 101 means the values of the first name attribute agree (1), the values of the middle name attribute disagree (0), and the values of the last name attribute agree (1). In this example of three identity attributes there are 8 = 23 possible agreement patterns corresponding to the 8 binary numbers from 000 to 111. In general, for N corresponding identity attributes there will be 2N possible agreement patterns.
It should also be noted that agreement does not necessarily mean the two identity attribute values are exactly the same. It could be defined to mean agreement on Soundex code, or having a q-Gram similarity of 80% or larger, or any other type of ER comparator. Moreover, agreement can be defined differently for each attribute.
In this respect, agreement patterns are a special type of Boolean match rule. In the previous example the 101 pattern might be interpreted as the proposition “(First name values agree on Soundex match) AND (NOT(middle name values agree by Exact match)) AND (last name values agree by Exact match)”. However, most systems supporting Boolean rules do not implement the NOT operator. Instead, the identity attributes not required to match are not specified in the rule and treated as “don’t care” states. In other words, the Boolean rule “First name values agree on Soundex AND last name values agree by exact” would be True as long there was agreement on the first and last name regardless of whether the middle name values agree or not. Thus, this Boolean version of the rule would encompass both the 101 and 111 Fellegi-Sunter agreement patterns.
Given two lists of references, List X and List Y, sharing N identity attributes, define Γ to be the set of 2N possible agreement patterns. Then a Fellegi-Sunter matching rule is defined by three sets A, R, and V where
1. A⊆Γ, R⊆Γ, V⊆Γ
2. A∩R = ∅, A∩V = ∅, R∩V = ∅
3. A∪R∪V = Γ
Although A, R, and V are nonoverlapping sets covering Γ, they do not always form a partition of Γ because they are not required to be nonempty subsets of Γ.
Now let x∈X, y∈X, and let γ∈Γ represent the agreement pattern between values of the identity attributes of the references x and y. Then the Fellegi-Sunter matching rule F = {A,R,V} states
1. If γ∈A, then always link reference x and y,
2. Else if γ∈R, then always reject linking (never link) reference x and y,
3. Else if γ∈V, then a person must verify that x and y are, or are not, equivalent and link accordingly.
All of this is just a mathematical way of saying divide all of the possible agreement patterns into three nonoverlapping groups, A, R, and V. When comparing references from Lists X and Y, if the values of the corresponding identity attributes conform to an agreement pattern in the set A, then the rule is to always link the references together. If the agreement pattern is in the set R, then the rule is to never link the references together. If the agreement pattern is in the set V, then the rule is a person must verify whether the two references should be linked or not.
The Fundamental Fellegi-Sunter Theorem
The crux of the Fellegi-Sunter theory rests on one fundamental theorem. The fundamental theorem adds two more elements to the context besides to the two lists of references. These elements are two constraint values: the maximum allowable false negative rate denoted by λ and the maximum false positive rate denoted by μ.
The fundamental theorem of the Fellegi-Sunter theory says, given the context of two lists X and Y and constraints λ and μ, then it will always be possible to find a Fellegi-Sunter match rule F = {A, R, V} that is optimal with respect to the following:
1. The false positive rate from always linking reference pairs with agreement patterns in A will not exceed μ;
2. The false negative rate from never linking reference pairs with agreement patterns in R will not exceed λ; and
3. The number of reference pairs with agreement patterns in V requiring manual verification will be minimized.
Fortunately the proof of the theorem is a constructive proof, i.e. the proof of the theorem shows how to construct the rule F = {A, R, V} satisfying these conditions.
The construction starts with the two lists of references X and Y. Let X×Y represent all possible pairs of these references (x, y) where x∈X and y∈Y, and γ∈Γ is one of the agreement patterns. Now let E⊆X×Y represent the pairs of references actually equivalent to each other. The construction of the rule is fairly straightforward and relies primarily on the following formula:
![]()
The fraction Rγ is called the Pattern Ratio for pattern γ. The numerator of the ratio is the probability two equivalent references will conform to the agreement pattern γ, and the denominator is the probability that two nonequivalent references will conform to γ. Because these fractions can be very large or very small, the theorem also defines Wγ the Pattern Weight for γ by simply converting the ratio Rγ to its logarithmic value, i.e.
![]()
The pattern ratio and pattern weight measure the predictive power of each pattern for equivalence or nonequivalence. If the probability that equivalent references satisfy a given pattern is high and the probability that nonequivalent references satisfy the same pattern is low, the ratio will be very large. It also means the pattern is a good predictor of whether the two references should be linked because it is associated with a high probability of equivalence, thus creating a true positive link. As the numerator approaches 1 and the denominator approaches 0, the value of the ratio becomes unbounded. To avoid the problem of division by zero, the denominator is never allowed to be smaller than a very small, but fixed, value.

On the other hand, if the numerator is small and the denominator is large, the ratio will be small and weight will be a small negative value. In this case the pattern predicts that the references should not be linked because the references are more likely to be true negatives.
From this it is easy to see that the highest weight patterns are the best choices for members of the set A of the rule (always link), and the lowest weight patterns are the best choices for members of the set R of the rule (never link). In the proof of the theorem the patterns are ordered from highest to lowest weight.
The ordering and candidates for the members of the A, V, and R set of the rules are shown in Figure 7.1. The only question is how many of the patterns with high weights should go into A and how many with the lowest weights should go into R. The answers to these questions are determined by the constraints λ and μ.
Note that if a pattern is selected for the set A, then any pair of references conforming to the pattern will be linked. Linking will either result in a true positive or a false positive. Patterns in A never create false negative links. They can only make true or false positives. Also, unless the denominator of the pattern ratio equals 0, the pattern will make some false positive links, i.e. it will link two nonequivalent references. The false positive rate for a pattern in A is the ratio of the number of nonequivalent pairs of references it links together to the total number of nonequivalent pairs.
The algorithm for selecting patterns for membership in A proceeds as follows, starting with A empty and the cumulative false positive rate equal to zero. Start with the pattern having the highest weight. If the pattern’s false positive rate is greater than μ, then the algorithm stops and A remains empty. Otherwise add the pattern to A, add its false positive rate to the cumulative false positive rate, and select the pattern with the next highest weight. If the cumulative false positive rate plus the false positive rate of the next pattern is greater than μ, then the algorithm stops. Otherwise add this pattern to A, add its false positive rate to the cumulative false positive rate, and select the pattern with the next highest weight. This process continues until a pattern is selected causing the cumulative false positive rate of the patterns in A to exceed μ, the maximum allowable false positive rate.
After the members of A are selected, the next step is to select the agreement patterns for R. If a pattern is selected for the set R, then any pair of references conforming to the pattern will not be linked. Therefore, patterns in R can only create true negatives or false negatives. When two equivalent references conform to a pattern in R, then the pattern will create a false negative. The false negative rate of a pattern in R is the ratio of the number of equivalent pairs satisfying the pattern to the total number of equivalent pairs.
The algorithm for selecting patterns for membership in R follows a similar algorithm to the one for A, starting with R empty and the cumulative false negative rate equal to zero. Start with the pattern having the lowest weight. If its false negative rate is greater than λ, then the algorithm stops and R remains empty. Otherwise add the pattern to R, add its false negative rate to the cumulative false negative rate, and select the pattern with the next lowest weight. If the cumulative false negative rate plus the false negative rate of the next pattern is greater than λ, then the algorithm stops. Otherwise put this pattern in R, add its false negative rate to the cumulative false negative rate, and select the pattern with the next lowest weight. This process continues until a pattern is selected that causes the cumulative false negative rate of the patterns in R to exceed λ or until there are no other patterns remaining to select (not already selected for A).
The members of set V are determined by default. If after selecting the members of A and R patterns still remain, then these patterns comprise V. The construction of the Fellegi-Sunter rule F = {A, R, V} is now complete.
Since its original publication, a number of authors have described many extensions and improvements of the Fellegi-Sunter Model. Most notably William Winkler at the U.S. Bureau of the Census has published on the application of expectation-maximization methods (Winkler, 1988) ways to adjust for lack of conditional independence among attributes (Winkler, 1989a), and the automation of weight calculations (Winkler, 1989b).
Attribute Level Weights and the Scoring Rule
Although the theorem and the construction of the Fellegi-Sunter rule are elegant, the theory presents some practical challenges in its implementation. One of the biggest problems is with the number of possible patterns that must be analyzed. It might not be uncommon in an application to have 10 identity attributes. To develop a Fellegi-Sunter rule for such an application would require the analysis of 1,024 = 210 agreement patterns.
However, if prepared to make the assumption that the identity attributes are conditionally independent, then the problem can be greatly simplified. The conditional independence assumption is that the probability of agreement or disagreement between two values of one identity attribute does not affect the probability of agreement or disagreement between two values of any other identity attribute. Of course in most applications, this is not entirely true. For example, if two addresses were to agree on a state, then the agreements on city will be limited to the names of cities in that state. However, in general, the benefits of assuming conditional independence outweigh these concerns.
The benefit of assuming conditional independence of the identity attributes is that the calculation of the pattern weight can be estimated by calculating the weight of each identity attribute. In their book, Herzog, Scheuren, and Winkler (2007) give an excellent exposition of the method for calculating pattern weights from the estimated probabilities of agreement and disagreement on individual identity attributes. Given the attributes are conditionally independent, the pattern weight calculation is
![]()
![]()
![]()
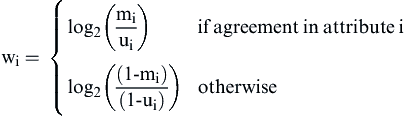
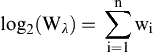
By using this calculation, the estimate for each pattern weight can be calculated by summing the ratios associated with individual attributes. Using the previous example of the agreement pattern 101, then
![]()
where m1 is the probability that equivalent records agree on first name, and u1 is the probability that nonequivalent records agree on first name. The values of m2 and u2 are for similar probabilities on values of middle name, and m3 and u3 for values of last name.
In this scheme each attribute has two weights, an agreement weight and a disagreement weight. These weights are summed to estimate the weight of the complete pattern. When implemented in software, this “on-the-fly” generation of the pattern weight is called a scoring rule as discussed in Chapter 3. The example given in Figure 3.4 shows the automatic generation of the weight for the agreement pattern 10110.
When scoring rules are implemented in ER systems, the patterns comprising the A subset of patterns in the Fellegi-Sunter linking rule (always link) are determined by a value called the match threshold. Just as shown in Figure 3.4, if two references conform to an agreement pattern generating a weight above the match threshold, the references are linked. This corresponds to a value between Wγ4 and Wγ5 in Figure 7.1 defining the boundary of the A patterns. In addition, many scoring rule systems implement a second threshold called the review threshold that is smaller than the match threshold. Pairs of references generating a pattern weight smaller than the match threshold but greater than the review threshold are logged for clerical review. The review threshold corresponds to a value between WγN−3 and WγN−2 in Figure 7.1, separating the V patterns from the R patterns.
Frequency-based Weights and the Scoring Rule
One further refinement of estimating pattern weight from attribute weights is called frequency-based weights. Frequency-based weighting is simply a reinterpretation of the probability mi and ui from agreement on attributes to agreement on specific attribute values. Thus, if v is a value of the i-th identity attribute then
mi(v) = probability equivalent references agree on the value v in attribute i
ui(v) = probability nonequivalent references agree on the value v in attribute i
In this scheme, each identity attribute has many weights, potentially one for every value the attribute can take on. However, as the name implies, the value weights are usually only generated for the most frequently encountered values. The assumption is that more frequently encountered values are more likely to be associated with many different entities and consequently should have a lower weight than less frequently used values, which are more likely associated with fewer entities.
A case in point for party entities are name attributes. For example, consider first name. Given a population, it may be determined that many different customers have the first name “JOHN” versus many fewer different customers having the first name “FREDRICK”. If the first name is the first identity attribute, this means the probability nonequivalent references will agree on “JOHN” is greater than the probability nonequivalent references will agree on “FREDRICK”, i.e. u1(“JOHN”) > u1(“FREDRICK”). The net effect will be the weight for agreement on “JOHN” in the first name attribute will be smaller than the weight for agreement on “FREDRICK”.
The nuanced adjustment in weight based on frequency can make the scoring rule an accurate tool in certain MDM domains. The trade-off is the increased analytical effort to initially determine the weights and the ongoing effort to keep the weights in adjustment. Another issue with both frequency-based and attribute-based weights in general is they do not perform well on sets of references with identity attributes having a significant number of missing values. The setting of the weights depends on the probabilities of agreement and disagreement, but when one or both values are missing, agreement and disagreement cannot be determined.
The Stanford Entity Resolution Framework
Another significant contribution to the theory of entity resolution is the Stanford Entity Resolution Framework (SERF) developed by researchers at the Stanford InfoLab led by Hector Garcia-Molina (Benjelloun et al., 2009). The main contributions of the SERF are:
2. In addition to a pair-wise matching operation, it described a new operation merging (creates clusters of) references to form new objects (the EIS of EIIM) that can also be acted upon by the match and merge operations.
3. Using abstract mathematical descriptions of the match and merge operations, it formally defined what it means for a set of objects (clusters) produced by the match and merge operations acting on a set of references to comprise the entity resolution of those references.
4. It established the properties the match and merge operations must satisfy in order to assure the unique entity resolution of a set of references will exist.
5. In the case where the match and merge operations have the properties necessary to produce a unique entity resolution of a set of references, it defined an algorithm for applying the match and merge operations to the set of references always ending with the clusters that comprise their entity resolution.
Abstraction of Match and Merge Operations
The foundation of SERF is an abstraction of the match and merge operations as functions operating on an abstract set of entity references. Whereas the Fellegi-Sunter model focuses on the actual mechanics of matching in terms of agreement and disagreement of identity attribute values, the SERF takes a more abstract approach. If M represents the match operation and D represents its domain, then the match function M is defined as
![]()
M is simply a function assigning each pair of elements in its domain a True or False value. Similarly for the same domain D, the merge operation μ is defined as
![]()
The merge function simply maps pairs of matching elements in D to another element in D. Because both x and y are elements in D, it is possible in some instances either μ(y, x) = x or μ(x, y) = x. When this happens, then x is said to “dominate” y.
So what is the domain D? If R is a set of entity references, then the domain D is the closure of R with respect to M and μ. In other words, D is the set of all objects possibly formed by starting with R, then repeatedly finding matching references and merging the matching references.
As a warning, even though these operations are called match and merge, and R is said to be a set of entity references, this is strictly a set theoretic definition, and at this point in the model, these names do not imply any particular real-world behavior or structure. For example, there is nothing in the definition of M that requires M(x, x) = True. In other words, the elements of D are not required to match themselves, a fairly basic expectation of real data matching. There is also no assumption that M(x, y) = M(y, x) or that μ(x, x) = x.
To illustrate this point, consider the case where R = {1}, the set containing only the integer value of one. Furthermore, define the operations M and μ as follows
![]()
![]()
Having defined R, M, and μ, the next question is what is D? Given that R only has one element 1, the only place to start is with the question: Is M(1, 1) True or False? Because 1 is odd, the answer is True. Therefore, the merge function can operate on the pair (1, 1) resulting in a new object μ(1, 1) = 1+1 = 2.
At this point D has expanded from {1} to {1, 2}. Now there are 4 pairs in D to test for matching with M. If any of those pairs match, then the merge function can be applied and will possibly generate new objects in D. As it turns out, M(1, 2) = True, thus μ(1, 2) = 3 thereby expanding D = {1,2,3}. By following this pattern it is easy to see D can be extended to include all positive integers Z+ = {1, 2, 3, …} an infinite set.
The Entity Resolution of a Set of References
Given a set of entity reference R, a match operation M, and a merge operation μ, then a set ER(R) is said to be the entity resolution of R, provided ER(R) satisfies the following conditions:
1. ER(R)⊆D. This condition requires ER(R) to be a subset of D.
2. If x∈D, then
a. Either x∈ER(R), or
b. There exists a y∈ER(R) such that μ(x, y) = y or μ(y, x) = y.
This condition states every element of D must either be in the entity resolution of R or be dominated by an element in the entity resolution or R.
3. If x, y∈ER(R), then
a. Either M(x, y) = False, or
b. μ(x, y) ≠ x, μ(x, y) ≠ y, μ(y, x) ≠ x and μ(y, x) ≠ y.
This condition states for any two elements in the entity resolution of R, they either don’t match, or if they do match, then one does not dominate the other.
Given the previous example where R = {1} and D = Z+, what is ER(R)? The first thing to note is by the definition of the merge function, no two elements of D can ever dominate each other. Because x and y are positive integers, and μ(x, y) = x + y, it follows that x + y > x and x + y > y. Therefore by Condition 1 of the definition, the only candidate for ER(R) is D. However, for D to be ER(R), D must also satisfy Condition 2. For Condition 2, there are two cases for x, y∈D to consider. One is when x is even. If x is even, then M(x, y) = False and Condition 2 is satisfied. On the other hand if x is odd, then M(x, y) = True. However, μ(x, y) = x + y can’t be equal to x or y by the same argument as in Condition 1. Thus ER(R), the entity resolution of R exists and is unique, but it is infinite. It is not difficult to construct other examples where ER(R) does not exist or where there is more than one ER(R).
Consistent ER
The SERF also answers the question of when the match and merge operations will produce a unique and finite ER(R), called consistent ER. Consistent ER will occur if and only if the match and merge operations have the following properties, called the ICAR properties:
• For every x∈D, M(x, x) =True, and μ(x, x) = x (Idempotent)
• For every x, y∈D, M(x, y) = M(y, x), and μ(x, y) = μ(y, x) (Commutative)
• For every x, y, z∈D, μ(x, μ(y, z)) = μ (μ (x, y), z) (Associative)
• If M(x, y) = M(y, z) = True, then M(x, μ (y, z)) = M(μ (x, y), z) = True (Representativity)
The R-Swoosh Algorithm
The SERF also includes a number of algorithms for actually producing the set of elements in D comprising the ER(R). The most important of these is the R-Swoosh algorithm. Given match and merge operations satisfying the conditions of the consistent ER, the R-Swoosh algorithm was shown to require the least number of operations to produce ER(R) in the worst case scenario. The details of the R-Swoosh ER algorithm are discussed in the next chapter.
The next chapter also compares the R-Swoosh algorithm with the One-Pass algorithm. The One-Pass algorithm is simpler (requires fewer operations) than the R-Swoosh algorithm, but it is only guaranteed to produce ER(R) when additional conditions are applied to the match and merge functions. However, these extra conditions are often imposed for typical EIIM and MDM systems; thus R-Swoosh is not often used in commercial applications.
Entity Identity Information Management
Entity Identity Information Management (EIIM) is the main theme of this book, and has been discussed extensively in previous chapters. As stated in Chapter 1, EIIM is the collection and management of identity information with the goal of sustaining entity identity integrity over time (Zhou & Talburt, 2011b). While the primary focus of the EIIM model is on addressing the life cycle of entity identity information, EIIM draws from, and is consistent with, both the Fellegi-Sunter and the SERF models of ER.
EIIM and Fellegi-Sunter
The manual update configuration of EIIM discussed in Chapter 5 and the importance of assessing ER outcomes discussed in Chapter 3 are both drawn directly from the work of Fellegi and Sunter. As noted earlier, the proof of their fundamental theorem of record linkage depends on the assumption that some number of matches will require manual review. Furthermore, it prescribes a method for identifying the pairs of references needing to be reviewed, namely the pairs having agreement patterns comprising the verify subset V of the Fellegi-Sunter matching rule. Although the method of the theorem minimizes the number of pairs satisfying these “soft” rules, they do require verification by a domain expert. Unfortunately, this important aspect of ER is absent in many MDM systems that rely entirely on automated ER matching decisions.
The reliance on automated ER coupled with a lack of ER analytics is a recipe for low-quality MDM if not outright failure. Even at small levels, false positive and false negative errors will accumulate over time and progressively degrade the level of entity identity integrity in an MDM system.
In addition to clerical review of matching, the Fellegi-Sunter Model is framed around accuracy in the form of limits on false positive and false negative rates. However, these constraints are meaningless if these values are not known. Measurement of entity identity integrity attainment is yet another important aspect of ER absent in many MDM systems. Few MDM stewards can offer reliable, quantitative estimates of the false positive and false negative rates of their systems. Even though almost every chief data officer (CDO) or chief information officer (CIO) would state that their goal is to make their MDM systems as accurate as possible, few actually undertake systematic measures of accuracy. Without meaningful measurements it is difficult to tell if changes aimed at improving accuracy are really effective.
EIIM and the SERF
The EIIM Model elaborates on several features of the SERF. For example, it explores in more detail the characteristics of the merge operation. In the EIIM Model, the results of merging references are characterized as entity identity structures (EIS). The EIIM further describes the interaction between the match and merge operations in terms of EIS projection. The next chapter discusses EIS projection in more detail and also investigates the consequences of design choices for both EIS and EIS projection. These include the most commonly used designs of survivor record, exemplar record, attribute-based, and record-based EIS. In particular, the chapter shows that a simplified version of the R-Swoosh algorithm called One-Pass is sufficient to reach ER(R) when the record-based projection of EIS is used.
The EIIM automated update configuration is equivalent to the SERF notion of incremental resolution (Benjalloun et al., 2009). Whereas the SERF focuses primarily on the efficiency of resolution, the focus of EIIM is on sustaining entity identity integrity through the incremental resolution (update) cycles including the use of manual update (assertion).
Concluding Remarks
The primary theoretical foundations for ER are the Fellegi-Sunter Theory of Record Linkage and the Stanford Entity Resolution Framework. Their basic principles still underpin ER today. Deterministic matching, probabilistic matching, ER metrics, ER algorithms, clerical review indicators, and clerical review and correction all have their origin in these models. However, in order for ER to effectively support MDM, some additional functionality is required. EIIM describes additional functionality in terms of creating and maintaining EIS. The EIS are essential for preserving entity identity information and maintaining persistent entity identifiers from ER process to ER process.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.