
Chapter 9
Blocking
Abstract
The chapter discusses blocking as a technique for reducing the total number of pair-wise comparisons necessary for an ER algorithm to arrive at an acceptable clustering result. Blocking or some other type of comparison reduction must be used in order to implement a practical ER system. This chapter focuses on a particular type of blocking called match key blocking. It also discusses the importance of match-key-to-rule alignment, match key precision, match key recall, and strategies for creating and optimizing match key generators.
Keywords
Blocking; Match Key; Inverted IndexingBlocking
As necessary as the considerations discussed in Chapter 8 are to the design of a logically sound ER system, they are not sufficient to implement a usable ER system. As a practical matter, neither the One-Pass algorithm nor the R-Swoosh algorithm should be implemented exactly as described. The number of comparisons will be overwhelming. For both of these algorithms the number of comparisons grows as the square of the number of references processed. Twice as many references require four times as many comparisons, and three times as many references require nine times more, and so on. Implementing any of the design scenarios as described in a computer language such as C or Java will produce a system that will never be able to process more than a few thousand references in a reasonable amount of time, even with a fast computer.
To actually implement a practical ER system, one more ingredient is required for the ER recipe and that is blocking. For a given set of input references to an ER process, this simply means performing the ER process on specific subsets of the input instead of on the entire set of references. These subsets are called blocks, hence the name blocking. For example, if the input has 1,000 references, if an ER process is performed on the entire 1,000 references, processing will require on the order of 1,0002 or 1,000,000 comparisons to complete. However, if the references are partitioned into 10 disjoint blocks of 100 references, then the effort to perform the ER algorithm on each block will require on the order of 1002 or 10,000 comparisons. Thus, the overall effort for all 10 blocks will be on the order of 10 × 1002 or 100,000 comparisons, an order of magnitude less than performing the algorithm on the entire 1,000 references.
Of course, there is an obvious problem. Suppose that references R1 and R2 in the input match by the ER base rule. If the blocking process assigns R1 to block B1, and assigns R2 to a different block B2, then R1 and R2 will not be compared and the ER process will not find this match. The ER process will only make comparisons among the references within block B1 and within B2, but not between B1 and B2. Consequently, unless the blocking is done in such a way that the records that match are in the same block, the ER process will not be accurate.
This presents another ER conundrum. Putting the references into the proper block requires knowing ahead of time whether they will match or not. But finding equivalent references by matching is the whole purpose of the ER process. So if it were already known which references match, then there would be no need for the ER process in the first place.
In reality, the best that can be done is to assign references to the same block based on the likelihood that they will match. Because it is only a probability, some matching references may still end up in separate blocks, causing those matches to be lost and the overall accuracy of the process to be reduced. Like so many things in ER, blocking is a trade-off. In the case of blocking, the trade-off is between accuracy and performance.
Two Causes of Accuracy Loss
As discussed earlier, ER is about finding equivalent references, not just matching. The first loss in ER accuracy is introduced simply because matching is the primary tool for resolving equivalence. The fact that two references have similar values for identity attributes only increases the likelihood they are equivalent; it does not guarantee it. As discussed in Chapter 3, the loss of ER accuracy due to matching is measured in terms of false positive (FP) and false negative (FN) errors. From the perspective of matching, the accuracy of the ER process can be measured as
![]()
The introduction of blocking can further decrease the accuracy of ER. Blocking will never create new matches, so it cannot cause an increase in false positive links. However, it can increase the number of false negatives. Assume the majority of matches found by an ER process result in true positive links rather than false positive links and then the effect of blocking is to increase the number of false negatives. This happens when references that would have matched and created true positive links are placed into separate blocks where they remain unlinked. Although as a general rule blocking reduces accuracy by increasing false negatives, it is not absolute. There is always a small probability blocking could prevent a false positive match and increase the number of true negatives, thereby increasing accuracy.
Blocking is said to be in alignment with the ER process when it is true that every match that could have been found without blocking will still be found with blocking in place, i.e. the blocking does not prevent any matches. However, the fact that blocking is in 100% alignment with the ER process does not mean that the ER process is 100% accurate. The accuracy of the ER process is dependent on the false positive and false negative rates of the matching in the ER process itself. The point is accurate ER results depend upon both accurate matching and accurately aligned blocking.
Measuring the reduction of comparisons from blocking is easier than measuring the loss of accuracy from blocking. An empirical method to test the potential loss of accuracy from blocking is to first select some subset of the references small enough that the ER process can run without blocking. By analyzing the cluster results of running these references with blocking and without blocking it is possible to estimate the loss of matching that blocking has introduced. If no matches are lost by the blocking, then the cluster results should be identical.
It should also be noted that if some matches are lost by blocking, then the ER results with blocking will always have more clusters than the results without blocking. This is because all ER processes (except for certain types of assertion configurations) that link references together by matching rules and transitive closure will never split clusters apart, they will only bring clusters together. Therefore, with more matches found, the number of clusters decreases as the sizes of the clusters increase. In the extreme, if all references were to match, then the output would only be one cluster comprising all input references. At the other extreme, if no references were to match, then every reference will form its own cluster, i.e. N references will form N clusters, each containing a single reference.
Blocking as Prematching
The central issue of blocking is how to organize the references into subsets that contain the references most likely to match. The fact that matching is the primary tool for determining equivalence drives the blocking decisions. In essence, blocking is prematching. Blocking typically focuses on the similarity between references by one or two of their identity attributes to form the block, and then leaves the ER algorithm and the base matching rule to do the fine-grained resolution into clusters.
For example, if the base rule matches two customer references based on having similar names and addresses, then the strategy might be to organize the references into blocks according to the same postal code (e.g. zip code in the U.S.). The idea is that if two complete addresses match, they will have the same postal code. This example can be used to highlight some of the factors that influence the accuracy of blocking.
The first and most obvious factor is that the blocking value needs to be highly correlated to the matching logic. Using the postal code for blocking implies all references are expected to agree on address. If there are other agreement patterns that do not require agreement on address, then blocking by postal code may not be effective in bringing together the references that match by those patterns.
The second factor is the importance of data preparation. If the references being processed in this example had customer addresses that were entered by the customer, then some of the postal codes may be incorrect. Customers may not know their correct postal code or they might be mistyped. An important step would be to standardize the references using the appropriate postal authority so that each address has the correct postal code.
A third factor is the problem of missing values. If a blocking value is missing in a reference, then it is impossible to know to which block the reference should be assigned. In the example of the postal code, it may be possible to overcome the problem of missing values. If the street address and city-state elements of the address are complete, then it might be possible to determine the value of the postal code by using tables supplied by the relevant postal authority. However, in other cases it might be more difficult. For example, if blocking were by year-of-birth, then there may not be a way to impute a missing value based on other information in the reference.
Missing values are a problem for both blocking and matching. Just as a missing value can prevent a reference from being assigned to a block, it can also prevent references from being matched. If a match rule required agreement on the customer’s account number and the account number value in a reference is missing, then that reference cannot be matched to another reference based on account number agreement.
Because of the problem of missing values, matching is often based on more than one pattern of agreement. For example, student enrollment records might be matched based on the agreement of the student’s first name, student’s last name, and date-of-birth. If data analysis shows that some of the dates-of-birth are missing, the rule may be augmented to also allow a match based on the agreement of the student’s first name, student’s last name, and the house number of the student’s address. Allowing a match by either pattern could help compensate for instances where a reference is missing either a date-of-birth or the house number. However, this would not help if both are missing. Yet a third might be required that supports a match on other identity attributes when both date-of-birth and house number are missing.
Another important consideration for blocking is uniformity in block size. The uniform distribution of references to blocks is not an accuracy issue, but a performance issue. The purpose of blocking is to improve performance, but it is important to understand that the principle of blocking does not work based on the average size of the blocks; rather it depends on the absolute size of each block. Recalling the previous example, it does not help to partition 1,000 references into 10 blocks with an “average” size of 100 references if one of the blocks has 900 references. The loss in performance in processing the approximately 9002 or 810,000 comparison in the large block will negate any gains from faster processing of the 9 smaller blocks. So, in addition to the problem of organizing blocks by likelihood of matching, there is the additional consideration of uniform block size. The latter is sometimes called the “large entity” problem where the nature of the references and the base match rule interact to form very large clusters.
Blocking by Match Key
Many approaches to blocking have been developed. Christen (2012), Isele, Jentzsch and Bizer (2011), and Baxter, Christen, and Churches (2003) describe a number of these, including inverted indexing, sorted neighborhoods, Q-gram indexing, suffix-array indexing, canopy clustering, and mapping-based indexing. However, inverted indexing, sometimes called match key indexing or standard blocking (Christen, 2006), is one of the most common approaches to blocking in ER systems. In addition, match key blocking plays an important role in addressing ER and MDM for Big Data that will be discussed in the next chapter.
The example of blocking records by postal code described earlier is also a simple example of blocking by match key. The value used to partition references into blocks, such as the postal code, is called the match key. Sometimes the match key is simply the value of a single attribute of the reference such as the postal code. In other cases, the value may be modified in some way. The transformations that modify values to form the match key are called hashing algorithms, and the resulting values are sometimes called hash keys instead of match keys. The routines that create match keys are called match key generators.
Phonetic encoding algorithms such as Soundex (Holmes & McCabe, 2002), NYSIIS (Borgman & Siegfried, 1992), and Double-Metaphone (Philips, 2000) are commonly used hashing algorithms used to overcome phonetic variation in names. For example, the Soundex has an algorithm that transforms both “SMITH” and “SMYTHE” into the string value (hash value) of “S530.” There are many other hash algorithms including those that are simply string manipulation functions such as uppercasing letters, extracting specific character types such as digits, or extracting specific substrings. At the other extreme, some hashing functions perform mathematical operations on the underlying bits of the character string, transforming the string into an integer value. All of these hash functions can be used to create match keys.
In some cases, the match key is created from the values from several attributes. For example, if the base match rule requires agreement on the customer’s name as well as the address, then the size of each block can be reduced by constructing a compound match key by concatenating the customer’s last name with the postal code. As long as this is the only matching pattern, then using this compound key would improve performance without decreasing accuracy. The reason is the longer match key now requires two conditions to be met and would create smaller blocks. At the same time agreement on name also implies agreement on last name and agreement on address implies agreement on postal code, and therefore, the match key is aligned with the agreement pattern of the rule. Any pair of references that would match by the name and address pattern would be placed in the same block by the last name and postal code match key.
Match Key and Match Rule Alignment
As noted earlier, blocking is in 100% alignment with the base matching rule if any two references that match by the rule are always in the same block. For match key blocking, 100% alignment can be expressed this way. If it is true that whenever two references match by the rule, they also generate the same match key, then the match-key and rule are in alignment. For match key blocking, misalignment occurs when two references match each other, but do not generate the same match key.
A secondary goal of match key generation is to minimize the number of references that generate the same match key, but that do not match by the rules. So a natural question to ask is: why not make the match key generators the same as the match rules? In some simple scenarios this might be possible, but in most cases they must be different. The reason can be explained by the following example.
For simplicity, suppose that there is a single match rule for student enrollment records with a pattern that requires the last names to be the same (exact match), but allows the first name values to be nicknames for each other, e.g. for English names allowing “JAMES” and “JIM” to be a match. In this case using a match key made by combining the first and last name will not work properly. For example, the two records “JAMES DOE” and “JIM DOE” will match by the rule, but their match keys “JAMESDOE” and “JIMDOE” are not the same. Therefore, they would not be assigned to the same match key block and would never be compared and brought together in the same cluster.
Another match key strategy for this same rule might be to use the LeftSubstring(1) hash generator for the first name. Now the enrollment records “JAMES DOE” and “JIM DOE” match by the rule and also generate the same match key “JDOE”. However, this would still not bring the match key generator into 100% alignment with the rule. Take for example the enrollment records “ROBERT CAMP” and “BOB CAMP”. Because for English names, Bob is a common nickname for Robert, these two references would match by the rule, but their match keys “RCAMP” and “BCAMP” are not the same. Thus, the rule and the index generator are still not in 100% alignment.
The Problem of Similarity Functions
The problem with the previous example is caused when the comparator used in a rule is based on a similarity function rather than a hashing algorithm. A similarity function requires two input values in order to give a match result. In the example just given, the similarity function is the Nickname function. It takes the two first name values and looks them up in a table to see if one is a nickname for the other. On the other hand, a hashing algorithm operates on a single value to transform it, such as the SOUNDEX has an algorithm that transforms “Smith” into the value “S530.” When a hash function such as SOUNDEX is used as a comparator, it simply checks if two attribute values give the same hash value.
However, the nickname comparator can only operate when it knows both values. It is not a hash function because it is not possible to design an algorithm in such a way that if two names are processed independently by the algorithm, the names will produce the same output (hash) value if and only if they are nicknames of each other. In other words, a hash algorithm does not need information from other attribute values to produce its output.
It turns out many similarity functions are commonly used in ER matching rules. One example is the Levenshtein edit distance function discussed in Chapter 3. Given the string “KLAUS,” there are a hundreds, if not thousands, of other strings that are within 1 edit distance just by changing a single character, e.g. first character substitution “ALAUS”, “BLAUS”, “CLAUS”, etc. second character substitutions “KAAUS”, “KBAUS”, “KCAUS”, etc. and so on. Again, there is not a hashing algorithm that can act on every one of these variant strings independently and produce the same output value.
The worst case for match key blocking is when all of the comparators used in an agreement pattern of a rule are similarity functions that do not have corresponding hash algorithms. For example, consider a rule that matches student enrollment records by the pattern where first name is a nickname match and the last name is within one Levenshtein edit distance. In this case, a match key generator based on hashing algorithms cannot be constructed that will guarantee when two references match, their match keys will be the same. The blocking for a rule like this would best be done using a different technique other than match key blocking such as q-gram blocking as described by Christen (2012).
However, if the ER system is constrained to use match keys for blocking, other strategies can be adopted. One is to break the rule into multiple patterns in which each pattern has at least one comparator that corresponds to a hash generator. For example, instead of one agreement pattern of nickname match on the first name and edit distance of one on the last name, use two patterns. The first agreement pattern uses nickname on the first name, but requires an exact match on the last name. Then the second pattern could require exact match on the first name, but allow one edit distance difference on the last name. This would not be a perfect solution; at least it would allow for blocking by match key that would find those matches where the variation was only in the first name or the last name, but not in both.
Dynamic Blocking versus Preresolution Blocking
The example just given also shows why it is sometimes beneficial to create more than one match key per reference, when the match rule allows for more than one agreement pattern. However, the use of more than one match key leads to an implementation issue. The issue is the point in the process at which references are assigned to blocks. There are two approaches. One approach is to organize the input into blocks prior to starting the ER process (preresolution blocking), and the other approach is to create the blocks as the ER algorithm is executing (dynamic blocking or indexing).
First consider the case where there is only a single match key such as the postal code. In this case, preresolution blocking could be easily done by sorting all references by postal code before the ER process starts. Each block of references with the same postal code could then be read into the system and processed by the match rules and ER algorithm one block at a time. Because each block is independent of every other block, the blocks could be processed in parallel. By doing so, there will not only be a gain in performance by applying the ER algorithm to the smaller blocks of data, there will be an additional gain in performance by processing the blocks concurrently in different processor threads or on different processors.
The other approach is dynamic blocking by using an inverted index. In dynamic blocking, the input references do not have to be sorted or preordered. Instead, as each reference is read into the system, its match key is generated, and the reference is indexed in memory by its match key. In other words, the system keeps track of each reference through an inverted index built using the match key. When a new input reference is read into the system, its match key is generated and then through the inverted index, the match key is used to look up all of the previous processed references that also generated the same match key.
The set of references brought back by the inverted index is sometimes called the candidate list because the references returned by the index are the most likely to match the incoming reference. The candidate list produced by the inverted index comprises the block for that match key, at least as it exists at that point in the process. The blocks grow in size as each new input record is read and indexed by the system.
Now consider the case where there is more than one match key generator. For simplicity, suppose each student enrollment record generates two match keys, one based on first name and another based on last name. In this case, preresolution blocking can’t be done by sorting because there are two ways to sort, one by first name and the other by last name. On the other hand, the dynamic blocking by inverted index is largely unaffected. For example, if a reference for “John Doe” is read, then the system uses the inverted index to look up all previously processed references with the first name “John” and all previously processed references with the last name “Doe.” The union of these two sets of references then forms the candidate list of references that should be compared to the incoming reference “John Doe.”
Preresolution Blocking with Multiple Match Keys
When performance considerations require more than one match key, the problem of preresolution blocking becomes much more difficult. In dynamic match key blocking using an inverted index, the candidates for an input reference are assembled on demand as each input reference is processed. Because the inverted index is in memory, it is a simple matter to recall the relevant candidates for a given input.
That is not possible to do in preresolution blocking where all combinations have to be anticipated. For example, consider the same reference with the name “John Doe” in the case where both the first name and second name values act as match keys. In preresolution blocking the system needs to anticipate that the reference “John Doe” may match with other references with the first name “John” and the last name “Doe” just as in dynamic blocking. Therefore, all references with the first name “John” and the last name “Doe” must be brought into the same block.
However, if one of the references in the block with the first name “John” has the last name “Smith”, then preresolution blocking must anticipate this reference could match with other references that have the last name of “Smith”. Therefore, all references with the last name of “Smith” should also be brought into the block. If a reference with the last name “Smith” is brought into the block that has a first name of “James”, then by the same reasoning it is necessary to bring into the block all of the references with the first name of “James” as they may match. This chaining or transitive closure of the match keys can go on and on and potentially create very large blocks of references, exactly the opposite of what is desired.
The essential difference is that dynamic match key blocking by inverted index has the luxury of only dealing with one degree of connection (references with the same first name or same last name as the input reference) as each input reference is processed. On the other hand, preresolution match key blocking must anticipate all degrees of connection in advance by forming the transitive closure of all first and last name connections.
From this example it might appear dynamic blocking is the preferred method because it can easily accommodate multiple match keys. This is true as long as the volume of data to be processed allows the entire inverted index to reside in main memory. As data volumes grow into the big data range, this may no longer be possible or at least practical, from a systems implementation standpoint. Approaches to preresolution match key blocking for big data when multiple match keys are required will be discussed in the next chapter.
Blocking Precision and Recall
Just as match rules can be evaluated in terms of precision and recall, the same measure can be applied to blocking, especially match key blocking. Match keys can be thought of as an information retrieval (IR) strategy. Consider the case of dynamic match key blocking. As a new input reference enters the system, the goal is to retrieve all previously processed references likely to match the input reference. In the match key approach, the match key generated from the input reference is like a query that returns a list of candidates. Basically, two measures can be applied to the retrieved candidate list.
The first question is what proportion of the candidates in the list actually matches the input reference? The answer to this question is the precision measure of the match key query. In other words, if every candidate returned by the inverted index matches the input record, the query has 100% precision.
The second question to ask is whether there are references that match the input reference, but were not in the candidate list. The answer to this question is the recall measure of the match query. Recall is the proportion of all references that actually match the input reference that are actually returned in the candidate list. In other words, if every reference that will match the input reference is returned in the candidate list, then the query has 100% recall.
Yet another way to express match-key-to-rule alignment is to say that the match key index has 100% recall. In other words, if there is any reference that will match the input reference, then it will be in the candidate list produced by the match key query to the inverted index. The precision measure is not important for alignment (accuracy), but it is important for performance. The nonmatching references returned by the index represent overhead in the process as they force the system to make additional, nonproductive comparisons in order to find the actual matching references.
The scenarios in Figure 9.1 illustrate various relationships between precision and recall as Venn diagrams. If R is a set of references, then the background of the diagram represents all possible unordered pairs of references from R. The area enclosed by the solid circle represents the set of all pairs of references from R that satisfy the matching rule. The area enclosed by the dashed circle represents the set of all pairs of references from R that generate the same match key.
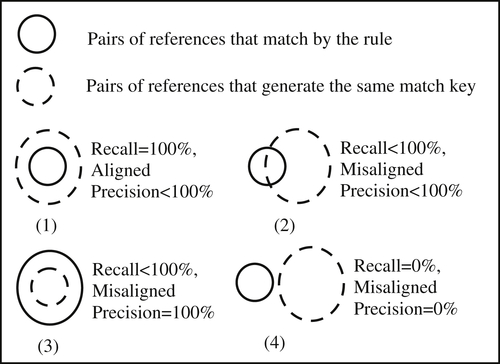
Alignment occurs when the recall measure is 100%, meaning the solid circle is completely enclosed in the dashed circle as shown in Scenario (1). The area between the two circles (inside the dashed and outside the solid) represents pairs that generate the same match key, but do not match by the rule. For this reason, the precision shown in Scenario (1) is less than 100%. In Scenario (2), the match key index recalls some, but not all, of the matching references along with many pairs that do not match. Both precision and recall in Scenario (2) are less than 100%.
In Scenario (3), every pair of references recalled by the match key index are matching references, and therefore, the precision of this scenario is 100%. The area between the circles (inside the solid and outside the dashed) represents matching pairs that are not recalled by the match key index, and therefore, the recall of Scenario (3) is less than 100%.
Scenario (4) shows complete misalignment between the rule and the match key index. None of the pairs that share the same match key match by the rule, and conversely, none of the pairs that match are returned by the index. In Scenario (4) both precision and recall are 0%.
The scenario shown in Figure 9.2 illustrates the strategy of using multiple match key generators. Each match key individually has less than 100% recall, but taken together (their union), they do achieve 100% recall. The areas outside of the solid oval but enclosed by one or more dashed circles represents the loss of precision, i.e. pairs that generate the same match key and are recalled by an index but do not match by the rule.

Match Key Blocking for Boolean Rules
The following XML segment shows how dynamic match key blocking might be defined for a Boolean rule in an ER system performing ER on school enrollment records (Zhou, Talburt, & Nelson, 2013).
The first section of the XML segment enclosed by the <IdentityRules> element defines the Boolean rule comprising two agreement patterns. The first agreement pattern is an exact match on social security number (SSN) and a SOUNDEX match on the first name. The second agreement pattern is a nickname match on first name and an exact match on both last name and year-of-birth (YOB).
The second section of the segment enclosed by the <Indices> element defines two match-key generators. Both generate compound keys. The first key comprises a simple hash of the SSN by the SCAN algorithm. The SCAN algorithm parameters specify a left-to-right (LR) scan to extract digits (DIGIT) up to the full length of the string (0), keeping the original case (KeepCase), and keeping the digits in the same order as in the original string (SameOrder). The second component of the first match key is the SOUNDEX hash of the first name.
The first match key index is in 100% alignment with the first agreement pattern, and in this case, it also achieves 100% precision. This is because every candidate brought back by the first index will match to the incoming reference because agreement on the match key is exactly the same as agreement on the rule pattern.
The second match key definition is necessary because the second agreement pattern uses the nickname similarity function for the first name attribute. To assure alignment, the second match key brings back candidates that agree on last name and year-of-birth. Both of the agreements are necessary but insufficient to satisfy the second rule pattern. In other words, candidates brought back by the second match key may not always match by the second pattern (because first names are different), but if any references do match by the second pattern, they will be brought back as candidates by this index.
Note that it is not always necessary to create a separate match key generator for every agreement pattern. Whether a new match key generator is needed will depend on the nature of the rules. Take as an example a Boolean rule for student enrollment that has two patterns. The first pattern requires exact agreement on first name, last name, and the difference in age value is 0, −1, or 1 (i.e. ages are within one year of each other). The second pattern requires exact agreement on first name, last name, and street number of the student’s address. A single match key comprised of the student’s first name and last name together would be in alignment with both patterns.
Match Key Blocking for Scoring Rules
The examples shown so far have been based on Boolean rules. Match key generation and rule alignment are essentially the same for scoring rules. The difference is the agreement patterns of Boolean rules are explicit in the definition of the rule, whereas understanding the agreement patterns for a scoring rule requires some analysis.
An agreement pattern in a Boolean rule is an AND clause, i.e. a sequence of comparator terms joined by the AND operator and separated from other patterns by the OR operator. In a Boolean rule, it is easy to find and examine each agreement pattern, then determine whether it requires defining a new match key generator, or if it is already in alignment with a previously defined match key.
For a scoring rule, it is not as simple. Scoring rules have patterns, but they are not obvious from inspecting the rule. For simplicity, suppose that a scoring rule compares four identity attributes A1, A2, A3, and A4, and the comparators for these attributes correspond to a hash algorithm. Further assume the scoring rule does not use value-based (frequency-based) weights, i.e. there is only one agreement and one disagreement weight for each of the four attributes.
This means when comparing any two references there are a total of 16 (24) possible patterns of agreement and disagreement, i.e. they could agree or disagree on A1, agree or disagree on A2, and the same for A3 and A4. Each of these patterns can be represented by a four-bit binary number where a 0 bit means disagreement and a 1 bit means agreement. For example, 1010 would represent agreement on A1, disagreement on A2, agreement on A3, and disagreement on A4.
Now assume each attribute has the following agreement and disagreement weights, A1(10, 0), A2(3, −4), A3(7, −1), A4(5, 2) where the first number of the ordered pair is the agreement weight and the second number is the disagreement weight. For example, the disagreement weight for A2 is −4. Given these weights, a total score can now be calculated for each of the 16 possible agreement patterns. For example, the pattern “1010” would have a score of 10 − 4 + 7 + 2 = 15.
Table 9.1 shows each of the 16 patterns ranked in descending order by their total score. Now suppose the match threshold set for this rule is 8, i.e. any pattern that gives a score of 8 or more will be considered a match. From this table it is clear the agreement patterns for the scoring rule are the first 10 patterns in Table 9.1 that have a score greater than or equal to 8.
Table 9.1
Pattern Scores in Descending Order
| Pattern | Score |
| 1111 | 25 |
| 1110 | 22 |
| 1011 | 18 |
| 1101 | 17 |
| 1010 | 15 |
| 0111 | 15 |
| 1100 | 14 |
| 0110 | 12 |
| 1001 | 10 |
| 0011 | 8 |
| 1000 | 7 |
| 0101 | 7 |
| 0010 | 5 |
| 0100 | 4 |
| 0001 | 0 |
| 0000 | −3 |
The pattern with the smallest score that satisfies the threshold value of 8 is the pattern “0011”. With the assumption thatall of the comparators correspond to a hash algorithm, it is possible to define a match key for each 10 patterns. For example, the match key for the pattern “0011” would be the hash value of A3 concatenated with the hash value of A4 (A3 + A4). This match key would clearly be in alignment with the pattern “0011” that it was generated from.
However, it is not necessary to define 10 different match keys in order to achieve alignment with all 10 match patterns. For example, the match key A3 + A4 derived from the pattern “0011” is also in alignment with the patterns “1111”, “1011”, and “0111” because these patterns also require agreement on A3 and A4. Next consider the pattern “1001” just above “0011”. A match key for this pattern would be A1 + A4. This match key would also be in alignment with the pattern “1101”. Thus, two match keys A3 + A4 and A1 + A4 align with 6 of the 10 patterns above the threshold. Furthermore, the match key A2 + A3 is in alignment with the pattern “0110” and “1110”, the match key A1 + A2 aligns with pattern “1100”, and finally match key A1 + A3 aligns with pattern “1010”. Thus, 5 match keys are sufficient to properly align with all 10 of the agreement-disagreement patterns of the scoring rule.
Although this example is simplistic, this approach to finding match keys for a scoring rule is basically sound. The actual analysis becomes more complicated when frequency- or value-based weights are used. Also, the assumption that each comparator corresponds to a hash algorithm may not hold in every situation.
Concluding Remarks
Even though blocking contributes to some loss of ER accuracy, it is absolutely essential. Even with the use of parallel and distributed computing, the power of O(n2) will eventually overwhelm any system that does not employ blocking. Although there are several strategies for blocking, the most commonly used is match key blocking. The loss of accuracy with match key blocking can be minimized by properly aligning the match keys with the matching rules. Match-key-to-rule alignment is easier to achieve in systems using Boolean rules, especially rules that rely primarily on hash function comparators rather than similarity functions. Match-key-to-rule alignment is more difficult in systems that use scoring (probabilistic) rules.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.