
Chapter 2
Entity Identity Information and the CSRUD Life Cycle Model
Abstract
Chapter 2 lays the foundation for the book’s theme – recognizing and understanding the role of life cycle management in the context of entity information supporting master data management. The chapter defines a life cycle model called CSRUD as an extension and adaptation of existing models for general information life cycle management to the specific context of entity identity information.
Keywords
Entity Identity Information; Information Life Cycle; POSMAD; CRUD; CSRUDEntities and Entity References
For the purposes of this book, entities are defined to be distinguishable real-world objects such as people, products, or places. This definition does not include concepts or types as is often the case in defining entities in other contexts. So for this discussion, person as a concept or type is not an entity, whereas a particular person, i.e. an instance of the person type, is an entity. This approach is consistent with the object-oriented programming distinction between a class and an object as a specific instance of a class. At the same time, being an object or instance of a concept or type should not be confused with being intangible or nontactile. For example, events, though not tactile objects, are often considered entities. The key point is that each entity is distinct and distinguishable from every other entity of the same type.
Having said that, the distinction between entity and entity type is not always so clear. What is considered an entity really depends upon the viewpoint of the organization defining the entity and the design of its information system. For example, consider the case of product information. A particular product line, such as a Model XYZ Television, might be considered an entity as distinct from a Model ABC Toaster. At the same time, there are actually many instances of each product, i.e. many XYZ television sets and ABC toasters each labeled with a unique serial number. Each television and each toaster can also be considered an entity. However, most organization’s MDM system would treat each product line as an entity rather than each product instance, although other systems supported by the MDM system, such as inventory, may be concerned with tracking products at the instance level.
Understanding which attributes are most important for any given application is a key step in any data management process (Heien, Wu, & Talburt, 2010). In the context of MDM, each entity type has a set of attributes taking on different values that describe the entities’ characteristics. For student entities these might be the student’s name, date-of-birth, height, or weight. Entity attributes with the combination of values most useful for distinguishing one entity from another are called identity attributes.
From an information systems perspective it is important to make a clear distinction between an entity and a reference to an entity. Information systems do not manipulate physical entities; rather, they model the real world by creating and storing data that describe or reference entities in the real world.
An entity reference in an information system is a set of attribute-value pairs intended to describe a particular real-world entity in a particular context. An entity may have zero or more identities within a given domain. For example, a person may have two identities in a school system because he or she is both a student and an employee at the school. An entity may of course have different identities in different domains. For example, a person is a customer in Macy’s and has another identity being an employee at IBM (Josang & Pope, 2005). An entity identity expressed in a certain domain is referred to as a surrogate identity.
In a school information system a student walking around on the campus is the entity, and the various records in the school administration software system describing the student are the entity references. This usage of the term entity is at odds with the typical database modeling terminology in which each row of a student table would be called an entity rather than an entity reference.
The Unique Reference Assumption
An important assumption in the discussion of entity resolution (ER) is the “unique reference assumption.” This assumption states:
“In an information system, every entity reference is always created to refer to one, and only one, entity.”
The reason for this assumption is that, in practice, an information system reference may appear to be ambiguous, i.e. it could refer to more than one real-world entity or possibly not to any entity. A salesperson could write a product description on a sales order, but because the description is incomplete, a data-entry operator might enter the correct description, but enter the wrong product identifier. Now it is no longer clear whether the newly created reference in the information system refers to the product according to its description or according to its product identifier. Despite this problem, it was the intent of the salesperson to record the description of a specific product.
Sebastian-Coleman (2013) describes this same concept in terms of Shannon’s Schematic for Communication in which both the transmitter or creator of information and the receiver of the information make interpretations introducing noise into the communication channel. Similarly, Wang and Strong (1996) have recognized interpretability and understandability as key dimensions of their data quality framework. The degree of completeness, accuracy, timeliness, believability, consistency, accessibility, and many other aspects of reference data can dramatically affect the outcome of an ER process. This is one of the many reasons why ER is so integral to the field of information quality.
The Problem of Entity Reference Resolution
As defined in the previous chapter, ER is the process of determining whether two information system references to real-world objects are referring to the same object or to different objects. The term entity is used because of the references to real-world objects –persons, places, or things – and resolution because ER is fundamentally a decision process. Technically it would be better to describe it as entity reference resolution, but the current term is well-established. Jonas (2007) prefers the term “semantic reconciliation.”
Although ER is defined as a decision regarding a pair of references, these decisions can be systematically applied to a larger set of references in such a way that each reference is ultimately classified into a cluster of references, all of which are deemed to reference the same entity. These clusters will form a partition of the set of references so each reference will be classified into one and only one cluster. Viewed in this larger context, ER is also defined as “the process of identifying and merging records judged to represent the same real-world entity” (Benjelloun et al., 2009). This will be discussed in more detail in Chapter 3.
The Fundamental Law of Entity Resolution
The fundamental law of entity resolution recasts the data quality principle of entity identity integrity into the vocabulary of ER. When an ER process decides two references are equivalent, the decision is instantiated in the system through a special attribute added to each reference called a “link” attribute. The absolute value of the link attribute is not important; in ER what is important is its relative value, i.e. records determined to be equivalent by the ER process are given the same link values and records determined not to be equivalent are given different link values. The process of assigning these values is called “linking” and two references sharing the same link value are said to be “linked.” Therefore, the fundamental law of ER can be stated as
“An entity resolution system should link two references if and only if the references are equivalent.”
Failure to obey this law is manifest in two types of errors, false positive and false negative errors. As noted earlier, a false negative error occurs when the ER process fails to link two references that are equivalent, and a false positive error occurs when the ER process links two references that are not equivalent. The evaluation of ER process outcomes is essentially a matter of counting false positive and false negative errors.
Internal vs. External View of Identity
Entities are described in terms of their characteristics called attributes. The values of these attributes provide information about a specific entity. Identity attributes, when taken together, distinguish one entity from another. Identity attributes for people are things like name, address, date-of-birth, and fingerprints; the questions often asked in order to identify a person requesting a driver’s license or hospital admission provide good examples of identity attributes. For a product, the identity attributes might be model number, size, manufacturer, or Universal Product Code (UPC).
Fundamentally, the problem of ER is identity management, but from the outside looking in. Take the example of someone being admitted to the hospital. When that person provides the admitting information about identity, they are mapping or projecting some small portion of their overall identity into the information system. Once the information is in the system together with other references to this same patient and to other patients, an ER process tries to infer which references are equivalent and which are not equivalent based on these identity clues.
One way to describe this situation is in terms of an internal view versus an external view of identity (Talburt, Zhou, & Shivaiah, 2009). Figure 2.1 illustrates the basic elements of name and address contact history for a woman born “Mary Smith.” Because these are records of where this woman was living, it is also called an occupancy history. Figure 2.1 shows three occupancy records, each with a name, an address, and a period of time that the occupancy was valid. Also note the change in name between Occupancy 1 and Occupancy 2.
There are two ways to view the issue of identity shown in Figure 2.1. One is to start with the identity based on biographical information, e.g. Mary Smith, a female born on December 3, 1980, in Anytown, NY, to parents Robert and Susan Smith, and to follow the identity through its various representations of name and address. This internal view of identity as shown in Figure 2.1 is the view of Mary Smith herself and might well be the view of a sibling or other close relative, someone with first-hand knowledge about her occupancy history.
The internal view of identity represents a closed universe model in which, for a given set of identity attributes, all of the attribute values are known to the internal viewer, and any unknown value for one of these attributes must belong to a different identity. An ER system possessing this information could always correctly resolve whether any given name and address reference was part of a particular identity or not.
On the other hand, an external view of identity is one in which some number of attribute values for an identity have been collected, but it is not certain if it is a complete collection of values or even if all of the values are correct. When a system working from an external view is presented with a reference, the system must always decide whether the reference should be linked to an existing identity, or if it represents a new identity in the system. An external view of identity represents an open universe model because, unlike the internal view, the system cannot assume it has complete and correct knowledge of all identity values.
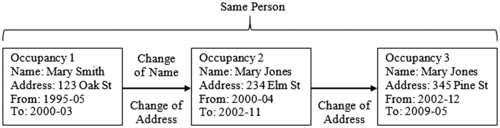
As an example, suppose a system has only Occupancy Records 1 and 2 of the identity in Figure 2.1. In that case the system’s knowledge of this identity is incomplete. It may be incomplete because Occupancy Record 3 has not been acquired or because it is in the system but has not been linked to Records 1 and 2. In the latter case, the system would treat Record 3 as part of a different identity. Even though an internal viewer would know that the Occupancy Record 3 should also be part of the identity in Figure 2.1, the system does not have sufficient information to make that decision.
In addition to the problem of creating an incomplete view of an identity, the system may assemble an inaccurate view of an identity. When presented with a new occupancy record, the system may erroneously link it with an existing identity to which it does not belong. Again, this speaks to the close ties between ER and IQ. In particular, it points out that the accuracy of data integration has two important components. First is the accuracy of the individual records, but the second is the correct aggregation of the records related to the same entity.
In an external view of identity, the collection of attribute values that have been linked together by the system comprises its view of the identity of the entity. In other words, an ER system based on an external view builds its knowledge about entity identities piece-by-piece. The external view of identity resembles how a business or a government agency would use ER tools in an effort to link their records into a single view of a customer or agency client.
All ER systems use identity at some level in order to resolve references, but not all ER systems implement identity management functions. For example, the simplest form of ER is the merge-purge process. It uses identity by assuming references with certain closely matching attribute values are equivalent and assigns these matching references the same link identifier. At the end of the merge-purge process, the system forms an external view of the identity of each entity represented in the file. This view comprises the information in the references linked together in the same cluster. However, after the merge-purge process has ended, the identity information in each cluster is lost. Merge-purge systems by their nature do not retain and manage entity identities for future processing. Each merge-purge process starts from scratch and the identity knowledge it assembles is transient, existing only during the processing of the current file.
Managing Entity Identity Information
As discussed in Chapter 1, Entity Identity Information Management (EIIM) is the extension of ER that focuses on storing and maintaining information relating to the identity of the entities under management. In EIIM, each entity is represented by a single knowledge structure called an entity identity structure (EIS). When an EIS is created, it is assigned a unique identifier which becomes the information system’s identifier for the real-world object corresponding to the EIS.
The goal of EIIM is two-fold. First is to achieve a state in which each EIS represents one, and only one, real-world entity, and different real-world entities are represented by different EIS. This is the goal of entity identity integrity as stated earlier. The second goal is to assure that when an EIS that is created to represent a given real-world entity is assigned a unique identifier, the EIS will continue to have that same identifier in the future. This is the goal of persistent identifiers. Despite best efforts, achieving these goals in all cases is almost impossible, especially for large numbers of entities and entity references. Due to differences in source data, timing, age of references, and other factors affecting the ability to correctly link references, some level of false positive and false negative errors will inevitably occur in any automated MDM system.
A false positive error occurs when an EIS has identity information for more than one real-world entity. A false positive violates the goal of entity identity integrity because a single EIS represents more than one real-world entity. It may also cause the system to violate the goal of maintaining persistent identifiers. When the information in the EIS is separated to correctly represent the identities of both entities, it may require creating a new EIS for each entity. The entity represented by the new EIS will have a new identifier creating a situation where the identifier for an identity has changed. Entities “split out” from the original EIS will require new identifiers. First, they were represented by the over-merged EIS, and then after the correction, they are represented by a new EIS with a different identifier.
The false negative error occurs when two or more EIS represent the same real-world entity. Clearly this violates entity identity integrity. The correction for this problem is to merge the EIS representing the same entity. Because each EIS should have only one identifier, only one of the original identifiers can survive after the merger, and the other identifiers must be retired. Again this creates a situation where the identifier for an identity has changed.
Entity Identity Integrity
A fundamental constraint of any database system is that different rows should not have the same identity. However, in most database models, identity is defined as the primary key value, i.e. no two rows should have the same primary key value. In the case where a table is intended to represent master data, this simple approach to identity does not take into consideration the question of reference. As anyone with any experience with database systems understands, just because two rows in a table have different primary key values, it does not necessarily follow that they are references to different entities.
In a master data table each entity should be represented by one, and only one, row. The most common failure of a master data table stems from more than one reference to the same object. This “over representation” of entities is often the root cause of many data quality issues in database systems. This kind of data redundancy in customer, student, patient, product, account, or other master data can cascade through the entire system, producing many other problems.
In most database tables, the primary key value is an arbitrarily assigned value, only there to guarantee the value is unique but unrelated to the values of the entity’s identity attributes. Assigning a primary key without regard for the represented identity may obey the letter of the primary key constraint, but it violates the spirit of entity identity integrity. Entity identity integrity is at the heart of MDM processing.
Entity identity integrity requires
• Each entity in a domain has one and only one representation in the system
• Distinct entities have distinct representations in the system
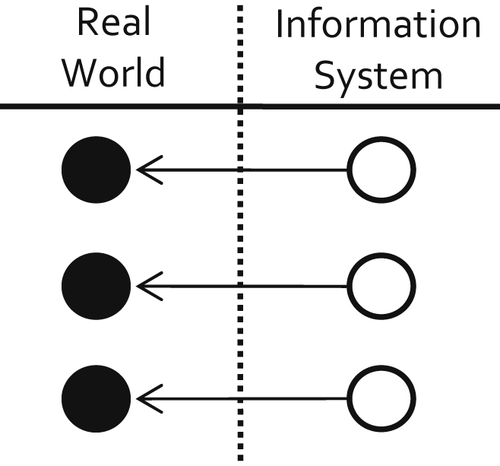
Figure 2.2 illustrates the state of entity identity integrity in which each real-world object has only one reference in the information system, and different objects have different references.
Entity identity integrity can be represented as a one-to-one, onto (in mathematical terminology, injective and surjective) function from the information system references to the real-world objects.
Huang, Lee, and Wang (1999) describe a concept similar to entity identity integrity called “proper representation.” Proper representation, shown in Figure 2.3, is less stringent than entity identity integrity because it only requires that different objects have different references but does not require each object to have only one reference.
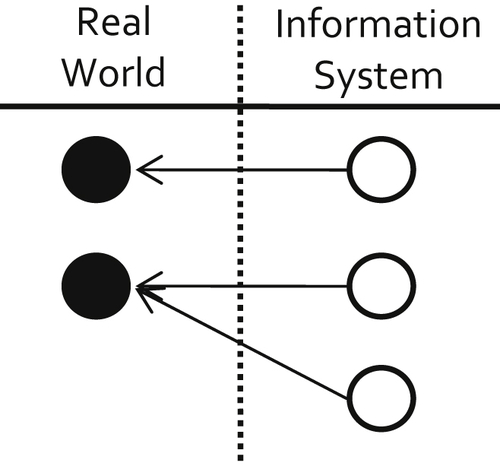
In proper representation, the mapping from the information systems references to the real-world objects is only required to be what is called a surjective function. A surjective function is one in which every element in the range of the function (in this case the real-world objects) has at least one element in the domain of the function (in this case the system references) mapped to it. Proper representation still allows for multiple references to the same object. Huang et al. (1999) use the term proper representation because in general there are cases where it is desirable to have many references to the same object in an information system. For example, when a table is holding sales transactions for a product, one would expect that there would be many different sales of the same product.
However, when the references are to master data, then proper representation really means redundant representation and signals the occurrence of a false negative error. A false negative occurs in an MDM system when there are two distinct references to the same entity.
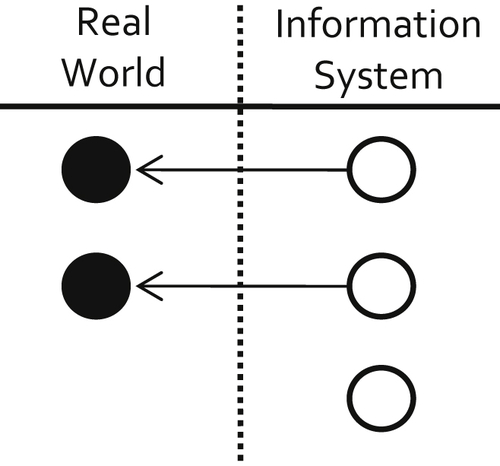
Huang et al. (1999) also describe a state called “ambiguous representation” shown in Figure 2.4. Ambiguous representation occurs when two or more distinct objects have only one reference in the information system. From an MDM perspective ambiguous representation represents a false positive error in which one reference refers to two distinct objects.
As noted earlier, every MDM system of any size will have some level of false negative and false positive errors. Moreover, these errors tend to be inversely related because the decisions are largely based on matching or similarity. When the match criteria are relaxed in order to correct false negatives in the data, it may create a situation in which previously true negative references match and are clustered together to create false positives. Similarly, imposing more stringent match conditions will tend to reduce false positives, but may in turn prevent true positive links, thereby increasing false negatives. Given a choice, most organizations prefer to make false negative errors over making positive errors.

There are several reasons for this tendency. In many customer-based applications, a false negative often has less business risk than a false positive. For example, a bank would rather fail to recognize that two accounts are owned by the same customer than to have two different customers assigned to and making transactions in the same account. The same example also illustrates a second reason. In general, it is easier to merge transactions for the same entity once separated by different identifiers than it is to sort out transactions belonging to different entities merged together by the same entity identifier.
A third reason is simply a matter of culture and expectation. Unfortunately, most people, including system managers, are somewhat accustomed to poor data quality. No one seems to be surprised when a system fails to bring together master records that are dissimilar. In some sense it is easier to explain, and perhaps there is more forgiveness for, why two master records for the same entity were not brought together than to explain why two master records were incorrectly merged.
A meaningless state (Huang et al., 1999) occurs when the SOR contains a reference unresolvable to any real-world object (Figure 2.5). Meaningless states can occur for different reasons. One is a lack of synchronization over time. A valid reference in the SOR may later become invalid – for example, a reference to a network circuit remaining in the system even though the circuit has been removed and no longer exists. In this case, the decision to keep the reference may be warranted for historical or archival reasons. However, most meaningless states arise due to data quality errors when identifiers and identity attribute values are corrupted by people and processes.
An incomplete state (Huang et al., 1999) exists when objects in the domain of interest do not have corresponding references in the information system (Figure 2.6). Incompleteness can manifest in an MDM system for different reasons. It can be during the initial implementation of the system when the existence and attribute values of the entities have yet to be established and registered. It can also occur when a new entity entering a system has delayed or failed system registration.
The process for establishing MDM registry entries often takes two forms, a formal registration and discovery by transaction. For the patient example, a formal process of admission gathers and enters registration information in detail. In a system with formal registration, no transaction can be recorded for an entity until that entity has been registered and has an identifier.

However, other MDM system designs are more dynamic and allow entities to be discovered through transactions. Discovery is often used for customer entities in businesses with no formal registration process. A person or company becomes a customer by simply making a purchase. As purchase transactions are processed, the system tries to determine if the purchaser is already registered as a customer entity. If not, the system establishes a new entry and identifier for the customer. Because a transaction will tend to have less identifying information than a full registration record, a system registering entities “on the fly” in this way typically requires more stewardship and adjustment than one in which entities are preregistered. Systems with dynamic registration have a higher probability of creating false negatives. As more information is accumulated in subsequent processes, what appeared initially to be a new entity is later determined to be a previously registered entity with somewhat different identifying information, such as the same customer with a new address.
The Need for Persistent Identifiers
By definition, ER attempts to achieve entity identity integrity at a particular point in time; that is, given a set of entity references, an ER process successively compares and sorts entity references into groups representing the same real-world entity. This sorting is typically followed by a purging process through which duplicate references are removed, leaving only one reference for each entity. ER used in this way is often referred to as a “merge-purge” process in which various files are reformatted into a common layout, merged into a single file, and the duplicate or redundant (equivalent) references are removed.
However, achieving entity identity integrity at a single point in time is not sufficient to support MDM. Another important requirement of MDM is that once an identifier for an entity is established in the information system, it will continue to have the same identifier over time, i.e. master data objects are given “persistent identifiers.” Although some operational processes can operate without persistent entity identifiers, the lack of persistence is a major problem for data warehouses that store historical data. If transactions for the same customer or patient are given different identifiers at different times, then it becomes extremely problematic to analyze the information and make effective decisions. Lee et al. (2006) list multiple sources of the same information as the first of the top ten root causes of data quality problems.
In order to create and maintain a persistent identifier, an ER process must also store and manage the identity information of the entity object so the same object can be recognized and given the same identifier in subsequent processes. Thus, MDM requires the application of ER processes to maintain entity identity integrity and also requires entity identity information management (EIIM) to maintain persistent identifiers.
Entity Identity Information Life Cycle Management Models
As has long been recognized in the field of information management, information has a life cycle. Information is not static; it changes over time. Several models of information life cycle management have been developed and a few of these are discussed here.
POSMAD Model
English (1999) formulated a five-phase information life cycle model of plan, acquire, maintain, dispose, and apply, adapted from a generalized resource management model. McGilvray (2008) later extended the model by adding a “store and share” phase and naming it the POSMAD life cycle model, an acronym for
• Plan for information
• Obtain the information
• Store and Share the information
• Maintain and manage the information
• Apply the information to accomplish your goals
• Dispose of the information as it is no longer needed
POSMAD is similar to the CRUD model long used by database modelers as primarily a process model for the basic database operations of creating rows (C), reading rows (R), updating rows (U), and deleting rows (D).
The Loshin Model
Entity information also has a life cycle, and understanding it is critical to successful EIIM. For example, Loshin (2009) has described a five-phase life cycle for master data objects similar to the POSMAD life cycle but cast in MDM and EIIM terminology. The five phases are
• Establishment
• Distribution
• Access and Use
• Deactivation and Retire
• Maintain and Update
The CSRUD Model
Following the lead of the CRUD model, another five-phase MDM life cycle model is proposed here that has a similar operational focus. The five phases of CSRUD are
• Capture – the initial creation of EIS for the system. Capture occurs when an MDM system is first installed. However, there is almost always some form of MDM, either in a dedicated system or an internal ad hoc system that must be migrated into the new system.
• Store and Share – the saving of EIS in a persistent format such as a database or flat-file format.
• Resolution and Retrieve – the actual use of the MDM information in which transactions with master data identifying information are compared (resolved) against the EIS in order to determine their identity. When an entity reference in a transaction is determined to be associated with a particular EIS, the EIS identifier is added to the transaction. For this reason, the process is sometimes called “link append” because the EIS identifier added to the transaction is used to link together transactions for the same entity.
• Update – the adding of new EIS related to new entities and updating previously created EIS with new information. The update process can be either automated or manual. Manual updates are often used to correct false positive and false negative errors introduced by the automated update process.
• Dispose – the retiring of EIS from the system. EIS are retired for two reasons. The first is the case where the EIS is correct, but is no longer active or relevant. The second is in the correction of false negative errors where two or more EIS are merged into a single EIS.
Concluding Remarks
The key take-away from Chapter 2 is MDM is an ongoing process, not a one-time event. Entity identity information will change, and the MDM system needs to have enough functionality to take these changes into account. The MDM system should be able to address all five phases of the CSRUD Life Cycle including the initial design and capture of the entity identity information, storing and sharing identity information, resolving inquiries for entity identity, updating entity identity information as it changes, and retirement of entities and entity identifiers. Each of the five phases will be discussed at length in the next chapters, as follows:
• Chapter 3, Capture Phase
• Chapter 4, Store and Share Phase
• Chapter 5, Update Phase and Dispose Phase
• Chapter 6, Resolve and Retrieve Phase.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.