
14. Collection Interfaces with Standard Query Operators
The most significant features added in C# 3.0 were in the area of collections. Extension methods and lambda expressions enabled a far superior API for working with collections. In fact, in earlier editions of this book, the chapter on collections came immediately after the chapter on generics and just before the one on delegates. However, lambda expressions make such a significant impact on collection APIs that it is no longer possible to cover collections without first covering delegates (the basis of lambda expressions). Now that you have a solid foundation on lambda expressions from the preceding chapter, we can delve into the details of collections, a topic that spans three chapters.
To begin, this chapter introduces anonymous types and collection initializers, topics that we covered only briefly in a few Advanced Topic sections in Chapter 5. Next, this chapter covers the various collection interfaces and how they relate to one another. This is the basis for understanding collections, so readers should cover the material with diligence. The section on collection interfaces includes coverage of the IEnumerable<T> extension methods that were added in C# 3.0 to implement the standard query operators.
There are two categories of collection-related classes and interfaces: those that support generics and those that don’t. This chapter primarily discusses the generic collection interfaces. You should use collection classes that don’t support generics only when you are writing components that need to interoperate with earlier versions of the runtime. This is because everything that was available in the nongeneric form has a generic replacement that is strongly typed. Although the concepts still apply to both forms, we will not explicitly discuss the nongeneric versions.1
1. In fact, in both Silverlight and WinRT, the nongeneric collections have been removed.
Anonymous Types and Implicitly Typed Local Variables
C# 3.0 significantly improved support for handling collections of items. What is amazing is that to support this advanced API, fewer than nine new language enhancements were made. However, these enhancements are critical to why C# 3.0 was such a marvelous improvement to the language. Two such enhancements were anonymous types and implicit local variables.
Anonymous Types
Anonymous types are data types that are declared by the compiler, rather than through the explicit class definitions of Chapter 5. Like anonymous functions, when the compiler sees an anonymous type, it does the work to make that class for you and then lets you use it as though you had declared it explicitly. Listing 14.1 shows such a declaration.
Listing 14.1. Implicit Local Variables with Anonymous Types
using System;
class Program
{
static void Main()
{
new
{
Title = "Bifocals",
YearOfPublication = "1784"
};
var patent2 =
new
{
Title = "Phonograph",
YearOfPublication = "1877"
};
var patent3 =
new
{
patent1.Title,
// Renamed to show property naming.
Year = patent1.YearOfPublication
};
Console.WriteLine("{0} ({1})",
patent1.Title, patent1.YearOfPublication);
Console.WriteLine("{0} ({1})",
patent2.Title, patent2.YearOfPublication);
Console.WriteLine();
Console.WriteLine(patent1);
Console.WriteLine(patent2);
Console.WriteLine();
Console.WriteLine(patent3);
}
}
The corresponding output is shown in Output 14.1.
Bifocals (1784)
Phonograph (1784)
{ Title = Bifocals, YearOfPublication = 1784 }
{ Title = Phonograph, YearOfPublication = 1877 }
{ Title = Bifocals, Year = 1784 }
Anonymous types are purely a C# feature, not a new kind of type in the runtime. When the compiler encounters the anonymous type syntax, it generates a CIL class with properties corresponding to the named values and data types in the anonymous type declaration.
Implicitly Typed Local Variables (var)
Since an anonymous type by definition has no name, it is not possible to declare a local variable as explicitly being of an anonymous type. Rather, the local variable’s type is replaced with var. However, by no means does this indicate that implicitly typed variables are untyped. On the contrary, they are fully typed to the data type of the value they are assigned. If an implicitly typed variable is assigned an anonymous type, the underlying CIL code for the local variable declaration will be of the type generated by the compiler. Similarly, if the implicitly typed variable is assigned a string, its data type in the underlying CIL will be a string. In fact, there is no difference in the resultant CIL code for implicitly typed variables whose assignment is not an anonymous type (such as string) and those that are declared as type string. If the declaration statement is string text = "This is a test of the...", the resultant CIL code will be identical to an implicitly typed declaration, var text = "This is a test of the...". The compiler determines the data type of the implicitly typed variable from the expression assigned. In an explicitly typed local variable with an initializer (string s = "hello";), the compiler first determines the type of s from the declared type on the left-hand side, then analyzes the right-hand side and verifies that the expression on the right-hand side is assignable to that type. In an implicitly typed local variable, the process is in some sense reversed. First the right-hand side is analyzed to determine its type, and then the “var” is logically replaced with that type.
Although there is no available name in C# for the anonymous type, it is still strongly typed as well. For example, the properties of the type are fully accessible. In Listing 14.1, patent1.Title and patent2.YearOfPublication are called within the Console.WriteLine statement. Any attempts to call nonexistent members will result in compile errors. Even IntelliSense in IDEs such as Visual Studio 2012 works with the anonymous type.
You should use implicitly typed variable declarations sparingly. Obviously, for anonymous types, it is not possible to specify the data type, and the use of var is required. However, for cases where the data type is not an anonymous type, it is frequently preferable to use the explicit data type. As is the case generally, you should focus on making the semantics of the code more readable while at the same time using the compiler to verify that the resultant variable is of the type you expect. To accomplish this with implicitly typed local variables, use them only when the type assigned to the implicitly typed variable is entirely obvious. For example, in var items = new Dictionary<string, List<Account>>();, the resultant code is more succinct and readable. In contrast, when the type is not obvious, such as when a method return is assigned, developers should favor an explicit variable type declaration such as the following:
Dictionary<string, List<Account>> dictionary = GetAccounts();
Implicitly typed variables should generally be reserved for anonymous type declaration rather than used indiscriminately when the data type is known at compile time, unless the type assigned to the variable is entirely obvious.
More about Anonymous Types and Implicit Local Variables
In Listing 14.1, member names on the anonymous types are explicitly identified using the assignment of the value to the name for patent1 and patent2 (for example, Title = "Phonograph"). However, if the value assigned is a property or field call, the name may default to the name of the field or property rather than explicitly specifying the value. patent3, for example, is defined using a property named “Title” rather than an assignment to an explicit name. As Output 14.1 shows, the resultant property name is determined, by the compiler, to match the property from where the value was retrieved.
patent1 and patent2 both have the same property names with the same data types. Therefore, the C# compiler generates only one data type for these two anonymous declarations. patent3, however, forces the compiler to create a second anonymous type because the property name for the patent year is different from what it was in patent1 and patent2. Furthermore, if the order of the properties were switched between patent1 and patent2, these two anonymous types would also not be type-compatible. In other words, the requirements for two anonymous types to be type-compatible within the same assembly are a match in property names, data types, and order of properties. If these criteria are met, the types are compatible even if they appear in different methods or classes. Listing 14.2 demonstrates the type incompatibilities.
Listing 14.2. Type Safety and Immutability of Anonymous Types
class Program
{
static void Main()
{
var patent1 =
new
{
YearOfPublication = "1784"
};
var patent2 =
new
{
Title = "Phonograph"
};
var patent3 =
new
{
patent1.Title,
};
// ERROR: Cannot implicitly convert type
// 'AnonymousType#1' to 'AnonymousType#2'
patent1 = patent2;
// ERROR: Cannot implicitly convert type
// 'AnonymousType#3' to 'AnonymousType#2'
patent1 = patent3;
// ERROR: Property or indexer 'AnonymousType#1.Title'
// cannot be assigned to -- it is read only'
patent1.Title = "Swiss Cheese";
}
}
The resultant two compile errors assert the fact that the types are not compatible, so they will not successfully convert from one to the other.
The third compile error is caused by the reassignment of the Title property. Anonymous types are immutable, so it is a compile error to change a property on an anonymous type once it has been instantiated.
Although not shown in Listing 14.2, it is not possible to declare a method with an implicit data type parameter (var). Therefore, instances of anonymous types can only be passed outside the method in which they are created in only two ways. First, if the method parameter is of type object, the anonymous type instance may pass outside the method because the anonymous type will convert implicitly. A second way is to use method type inference, whereby the anonymous type instance is passed as a method type parameter that the compiler can successfully infer. Calling void Method<T>(T parameter) using Function(patent1), therefore, would succeed, although the available operations on parameter within Function() are limited to those supported by object.
In spite of the fact that C# allows anonymous types such as the ones shown in Listing 14.1, it is generally not recommended that you define them in this way. Anonymous types provide critical functionality with C# 3.0 support for projections, such as joining/associating collections, as we discuss later in the chapter. However, generally you should reserve anonymous type definitions for circumstances where they are required, such as aggregation of data from multiple types.
Collection Initializers
Another feature added to C# in version 3.0 was collection initializers. A collection initializer allows programmers to construct a collection with an initial set of members at instantiation time in a manner similar to array declaration. Without collection initialization, elements had to be explicitly added to a collection after the collection was instantiated—using something like System.Collections.Generic.ICollection<T>’s Add() method. With collection initialization, the Add() calls are generated by the C# complier rather than explicitly coded by the developer. Listing 14.3 shows how to initialize the collection using a collection initializer instead.
Listing 14.3. Filtering with System.Linq.Enumerable.Where()
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
List<string> sevenWorldBlunders;
sevenWorldBlunders = new List<string>()
{
// Quotes from Ghandi
"Wealth without work",
"Pleasure without conscience",
"Knowledge without character",
"Commerce without morality",
"Science without humanity",
"Worship without sacrifice",
"Politics without principle"
};
Print(sevenWorldBlunders);
}
private static void Print<T>(IEnumerable<T> items)
{
foreach (T item in items)
{
Console.WriteLine(item);
}
}
}
The syntax is similar not only to the array initialization, but also to an object initializer with the curly braces following the constructor. If no parameters are passed in the constructor, the parentheses following the data type are optional (as they are with object initializers).
A few basic requirements are needed in order for a collection initializer to compile successfully. Ideally, the collection type to which a collection initializer is applied would be of a type that implements System.Collections.Generic.ICollection<T>. This ensures that the collection includes an Add() that the compiler-generated code can invoke. However, a relaxed version of the requirement also exists and simply demands that one or more Add() methods exist on a type that implements IEnumerable<T>—even if the collection doesn’t implement ICollection<T>. The Add() methods need to take parameters that are compatible with the values specified in the collection initializer.
Allowing initializers on collections that don’t support ICollection<T> was important for two reasons. First, it turns out that the majority of collections (types that implement IEnumerable<T>) do not also implement ICollection<T>, thus significantly reducing the usefulness of collection initializers.
Second, matching on the method name and signature compatibility with the collection initializer items enables greater diversity in the items initialized into the collection. For example, the initializer now can support new DataStore(){ a, {b, c}} as long as there is one Add() method whose signature is compatible with a and a second Add() method compatible with b, c.
Note that you cannot have a collection initializer for an anonymous type since the collection initializer requires a constructor call, and it is impossible to name the constructor. The workaround is to define a method such as static List<T> CreateList<T>(T t) { return new List<T>(); }. Method type inference allows the type parameter to be implied rather than specified explicitly, and so this workaround successfully allows for the creation of a collection of anonymous types.
Another approach to initializing a collection of anonymous types is to use an array initializer. Since it is not possible to specify the data type in the constructor, array initialization syntax allows for anonymous array initializers using new[] (see Listing 14.4).
Listing 14.4. Initializing Anonymous Type Arrays
using System;
using System.Collections.Generic;
using System.Linq;
class Program
{
static void Main()
{
{
new
{
TeamName = "France",
Players = new string[]
{
"Fabien Barthez", "Gregory Coupet",
"Mickael Landreau", "Eric Abidal",
// ...
}
},
new
{
TeamName = "Italy",
Players = new string[]
{
"Gianluigi Buffon", "Angelo Peruzzi",
"Marco Amelia", "Cristian Zaccardo",
// ...
}
}
};
Print(worldCup2006Finalists);
}
private static void Print<T>(IEnumerable<T> items)
{
foreach (T item in items)
{
Console.WriteLine(item);
}
}
}
The resultant variable is an array of the anonymous type items, which must be homogeneous since it is an array.
What Makes a Class a Collection: IEnumerable<T>
By definition, a collection within .NET is a class that, at a minimum, implements IEnumerable<T> (or the nongeneric type IEnumerable). This interface is a key because implementing the methods of IEnumerable<T> is the minimum implementation requirement needed to support iterating over the collection.
Chapter 3 showed how to use a foreach statement to iterate over an array of elements. The syntax is simple and avoids the complication of having to know how many elements there are. The runtime does not directly support the foreach statement, however. Instead, the C# compiler transforms the code as described in this section.
foreach with Arrays
Listing 14.5 demonstrates a simple foreach loop iterating over an array of integers and then printing out each integer to the console.
Listing 14.5. foreach with Arrays
int[] array = new int[]{1, 2, 3, 4, 5, 6};
foreach (int item in array)
{
Console.WriteLine(item);
}
From this code, the C# compiler creates a CIL equivalent of the for loop, as shown in Listing 14.6.
Listing 14.6. Compiled Implementation of foreach with Arrays
int number;
int[] tempArray;
int[] array = new int[]{1, 2, 3, 4, 5, 6};
tempArray = array;
for (int counter = 0; (counter < tempArray.Length); counter++)
{
int item = tempArray[counter];
Console.WriteLine(item);
}
In this example, note that foreach relies on support for the Length property and the index operator ([]). With the Length property, the C# compiler can use the for statement to iterate through each element in the array.
foreach with IEnumerable<T>
Although the code shown in Listing 14.6 works well on arrays where the length is fixed and the index operator is always supported, not all types of collections have a known number of elements. Furthermore, many of the collection classes, including the Stack<T>, Queue<T>, and Dictionary<Tkey, Tvalue> classes, do not support retrieving elements by index. Therefore, a more general approach of iterating over collections of elements is needed. The iterator pattern provides this capability. Assuming you can determine the first, next, and last elements, knowing the count and supporting retrieval of elements by index is unnecessary.
The System.Collections.Generic.IEnumerator<T> and nongeneric System.Collections.IEnumerator interfaces (see Listing 14.8) are designed to enable the iterator pattern for iterating over collections of elements, rather than the length-index pattern shown in Listing 14.6. A class diagram of their relationships appears in Figure 14.1.
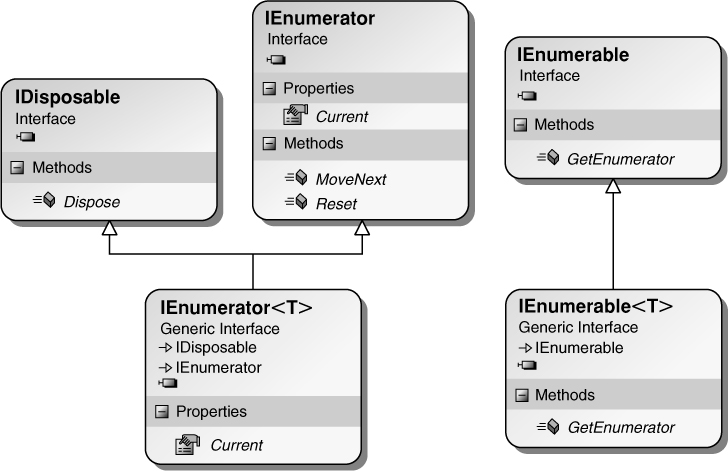
Figure 14.1. A Class Diagram of IEnumerator<T> and IEnumerator Interfaces
IEnumerator, which IEnumerator<T> derives from, includes three members. The first is bool MoveNext(). Using this method, you can move from one element within the collection to the next while at the same time detecting when you have enumerated through every item. The second member, a read-only property called Current, returns the element currently in process. Current is overloaded in IEnumerator<T>, providing a type-specific implementation of it. With these two members on the collection class, it is possible to iterate over the collection simply using a while loop, as demonstrated in Listing 14.7. (The Reset() method usually throws a NotImplementedException, and therefore should never be called. If you need to restart an enumeration, just create a fresh enumerator.)
Listing 14.7. Iterating over a Collection Using while
System.Collections.Generic.Stack<int> stack =
new System.Collections.Generic.Stack<int>();
int number;
// ...
// This code is conceptual, not the actual code.
while (stack.MoveNext())
{
number = stack.Current;
Console.WriteLine(number);
}
In Listing 14.7, the MoveNext() method returns false when it moves past the end of the collection. This replaces the need to count elements while looping.
Listing 14.7 uses a System.Collections.Generic.Stack<T> as the collection type. Numerous other collection types exist; this is just one example. The key trait of Stack<T> is its design as a last in, first out (LIFO) collection. It is important to note that the type parameter T identifies the type of all items within the collection. Collecting one particular type of object within a collection is a key characteristic of a generic collection. It is important that the programmer understands the data type within the collection when adding, removing, or accessing items within the collection.
The preceding example shows the gist of the C# compiler output, but it doesn’t actually compile that way because it omits two important details concerning the implementation: interleaving and error handling.
State Is Shared
The problem with an implementation such as Listing 14.7 is that if two such loops interleaved each other—one foreach inside another, both using the same collection—the collection must maintain a state indicator of the current element so that when MoveNext() is called, the next element can be determined. The problem is that one interleaving loop can affect the other. (The same is true of loops executed by multiple threads.)
To overcome this problem, the collection classes do not support IEnumerator<T> and IEnumerator interfaces directly. As shown in Figure 14.1, there is a second interface, called IEnumerable<T>, whose only method is GetEnumerator(). The purpose of this method is to return an object that supports IEnumerator<T>. Instead of the collection class maintaining the state, a different class, usually a nested class so that it has access to the internals of the collection, will support the IEnumerator<T> interface and will keep the state of the iteration loop. The enumerator is like a “cursor” or a “bookmark” in the sequence. You can have multiple bookmarks, and moving each of them enumerates over the collection independently of the other. Using this pattern, the C# equivalent of a foreach loop will look like the code shown in Listing 14.8.
Listing 14.8. A Separate Enumerator Maintaining State during an Iteration
System.Collections.Generic.Stack<int> stack =
new System.Collections.Generic.Stack<int>();
int number;
System.Collections.Generic.Stack<int>.Enumerator
enumerator;
// ...
// If IEnumerable<T> is implemented explicitly,
// then a cast is required.
// ((IEnumerable<int>)stack).GetEnumerator();
enumerator = stack.GetEnumerator();
while (enumerator.MoveNext())
{
number = enumerator.Current;
Console.WriteLine(number);
}
Cleaning Up Following Iteration
Since the classes that implement the IEnumerator<T> interface maintain the state, sometimes you need to clean up the state after it exits the loop (because either all iterations have completed or an exception is thrown). To achieve this, the IEnumerator<T> interface derives from IDisposable. Enumerators that implement IEnumerator do not necessarily implement IDisposable, but if they do, Dispose() will be called as well. This enables the calling of Dispose() after the foreach loop exits. The C# equivalent of the final CIL code, therefore, looks like Listing 14.9.
Listing 14.9. Compiled Result of foreach on Collections
System.Collections.Generic.Stack<int> stack =
new System.Collections.Generic.Stack<int>();
System.Collections.Generic.Stack<int>.Enumerator
enumerator;
IDisposable disposable;
enumerator = stack.GetEnumerator();
try
{
int number;
while (enumerator.MoveNext())
{
number = enumerator.Current;
Console.WriteLine(number);
}
}
finally
{
// Explicit cast used for IEnumerator<T>.
disposable = (IDisposable) enumerator;
disposable.Dispose();
// IEnumerator will use the as operator unless IDisposable
// support is known at compile time.
// disposable = (enumerator as IDisposable);
// if (disposable != null)
// {
// disposable.Dispose();
// }
}
Notice that because the IDisposable interface is supported by IEnumerator<T>, the using statement can simplify the code in Listing 14.9 to that shown in Listing 14.10.
Listing 14.10. Error Handling and Resource Cleanup with using
System.Collections.Generic.Stack<int> stack =
new System.Collections.Generic.Stack<int>();
int number;
System.Collections.Generic.Stack<int>.Enumerator
enumerator = stack.GetEnumerator())
{
while (enumerator.MoveNext())
{
number = enumerator.Current;
Console.WriteLine(number);
}
}
However, recall that the CIL also does not directly support the using keyword, so in reality, the code in Listing 14.9 is a more accurate C# representation of the foreach CIL code.
Do Not Modify Collections during foreach Iteration
Chapter 3 showed that the compiler prevents assignment of the foreach variable (number). As is demonstrated in Listing 14.10, an assignment to number would not be a change to the collection element itself, so the C# compiler prevents such an assignment altogether.
In addition, neither the element count within a collection nor the items themselves can generally be modified during the execution of a foreach loop. If, for example, you called stack.Push(42) inside the foreach loop, it would be ambiguous whether the iterator should ignore or incorporate the change to stack—in other words, whether iterator should iterate over the newly added item or ignore it and assume the same state as when it was instantiated.
Because of this ambiguity, an exception of type System.InvalidOperationException is generally thrown upon accessing the enumerator if the collection is modified within a foreach loop, reporting that the collection was modified after the enumerator was instantiated.
Standard Query Operators
Besides the methods on System.Object, any type that implements IEnumerable<T> is only required to implement one method, GetEnumerator(). And yet, it makes more than 50 methods available to all types implementing IEnumerable<T>, not including any overloading—and this happens without needing to explicitly implement any method except the GetEnumerator() method. The additional functionality is provided using C# 3.0’s extension methods and it all resides in the class System.Linq.Enumerable. Therefore, including the using declarative for System.Linq is all it takes to make these methods available.
Each method on IEnumerable<T> is a standard query operator; it provides querying capability over the collection on which it operates. In the following sections, we will examine some of the most prominent of these standard query operators.
Many of the examples will depend on an Inventor and/or Patent class, both defined in Listing 14.11.
Listing 14.11. Sample Classes for Use with Standard Query Operators
using System;
using System.Collections.Generic;
using System.Linq;
public class Patent
{
// Title of the published application
public string Title { get; set; }
// The date the application was officially published
public string YearOfPublication { get; set; }
// A unique number assigned to published applications
public string ApplicationNumber { get; set; }
public long[] InventorIds { get; set; }
public override string ToString()
{
return string.Format("{0}({1})",
Title, YearOfPublication);
}
}
public class Inventor
{
public long Id { get; set; }
public string Name { get; set; }
public string City { get; set; }
public string State { get; set; }
public string Country { get; set; }
public override string ToString()
{
return string.Format("{0}({1}, {2})",
Name, City, State);
}
}
class Program
{
static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
Print(patents);
Console.WriteLine();
IEnumerable<Inventor> inventors = PatentData.Inventors;
Print(inventors);
}
private static void Print<T>(IEnumerable<T> items)
{
foreach (T item in items)
{
Console.WriteLine(item);
}
}
}
public static class PatentData
{
public static readonly Inventor[] Inventors = new Inventor[]
{
new Inventor(){
Name="Benjamin Franklin", City="Philadelphia",
State="PA", Country="USA", Id=1 },
new Inventor(){
Name="Orville Wright", City="Kitty Hawk",
State="NC", Country="USA", Id=2},
new Inventor(){
Name="Wilbur Wright", City="Kitty Hawk",
State="NC", Country="USA", Id=3},
new Inventor(){
Name="Samuel Morse", City="New York",
State="NY", Country="USA", Id=4},
new Inventor(){
Name="George Stephenson", City="Wylam",
State="Northumberland", Country="UK", Id=5},
new Inventor(){
Name="John Michaelis", City="Chicago",
State="IL", Country="USA", Id=6},
new Inventor(){
Name="Mary Phelps Jacob", City="New York",
State="NY", Country="USA", Id=7},
};
public static readonly Patent[] Patents = new Patent[]
{
new Patent(){
Title="Bifocals", YearOfPublication="1784",
InventorIds=new long[] {1}},
new Patent(){
Title="Phonograph", YearOfPublication="1877",
InventorIds=new long[] {1}},
new Patent(){
Title="Kinetoscope", YearOfPublication="1888",
InventorIds=new long[] {1}},
new Patent(){
Title="Electrical Telegraph",
YearOfPublication="1837",
InventorIds=new long[] {4}},
new Patent(){
Title="Flying machine", YearOfPublication="1903",
InventorIds=new long[] {2,3}},
new Patent(){
Title="Steam Locomotive",
YearOfPublication="1815",
InventorIds=new long[] {5}},
new Patent(){
Title="Droplet deposition apparatus",
YearOfPublication="1989",
InventorIds=new long[] {6}},
new Patent(){
Title="Backless Brassiere",
YearOfPublication="1914",
InventorIds=new long[] {7}},
};
}
Listing 14.11 also provides a selection of sample data. Output 14.2 displays the results.
Bifocals(1784)
Phonograph(1877)
Kinetoscope(1888)
Electrical Telegraph(1837)
Flying machine(1903)
Steam Locomotive(1815)
Droplet deposition apparatus(1989)
Backless Brassiere(1914)
Benjamin Franklin(Philadelphia, PA)
Orville Wright(Kitty Hawk, NC)
Wilbur Wright(Kitty Hawk, NC)
Samuel Morse(New York, NY)
George Stephenson(Wylam, Northumberland)
John Michaelis(Chicago, IL)
Mary Phelps Jacob(New York, NY)
Filtering with Where()
In order to filter out data from a collection, we need to provide a filter method that returns true or false, indicating whether a particular element should be included or not. A delegate expression that takes an argument and returns a Boolean is called a predicate, and a collection’s Where() method depends on predicates for identifying filter criteria, as shown in Listing 14.12. (Technically, the result of the Where() method is a monad which encapsulates the operation of filtering a given sequence with a given predicate.) The output appears in Output 14.3.
Listing 14.12. Filtering with System.Linq.Enumerable.Where()
using System;
using System.Collections.Generic;
using System.Linq;
class Program
{
static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
patent => patent.YearOfPublication.StartsWith("18"));
Print(patents);
}
// ...
}
Phonograph(1877)
Kinetoscope(1888)
Electrical Telegraph(1837)
Steam Locomotive(1815)
Notice that the code assigns the output of the Where() call back to IEnumerable<T>. In other words, the output of IEnumerable<T>.Where() is a new IEnumerable<T> collection. In Listing 14.12, it is IEnumerable<Patent>.
Less obvious is that the Where() expression argument has not necessarily executed at assignment time. This is true for many of the standard query operators. In the case of Where(), for example, the expression is passed in to the collection and “saved” but not executed. Instead, execution of the expression occurs only when it is necessary to begin iterating over the items within the collection. A foreach loop, for example, such as the one in Print() (in Listing 14.11), will trigger the expression to be evaluated for each item within the collection. At least conceptually, the Where() method should be understood as a means of specifying the query regarding what appears in the collection, not the actual work involved with iterating over to produce a new collection with potentially fewer items.
Projecting with Select()
Since the output from the IEnumerable<T>.Where() method is a new IEnumerable<T> collection, it is possible to again call a standard query operator on the same collection. For example, rather than just filtering the data from the original collection, we could transform the data (see Listing 14.13).
Listing 14.13. Projection with System.Linq.Enumerable.Select()
using System;
using System.Collections.Generic;
using System.Linq;
class Program
{
static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
IEnumerable<Patent> patentsOf1800 = patents.Where(
patent => patent.YearOfPublication.StartsWith("18"));
patent => patent.ToString());
Print(items);
}
// ...
}
In Listing 14.13, we create a new IEnumerable<string> collection. In this case, it just so happens that adding the Select() call doesn’t change the output; but this is only because Print()’s Console.WriteLine() call used ToString() anyway. Obviously, a transform still occurred on each item from the Patent type of the original collection to the string type of the items collection.
Consider the example using System.IO.FileInfo in Listing 14.14.
Listing 14.14. Projection with System.Linq.Enumerable.Select() and new
// ...
IEnumerable<string> fileList = Directory.GetFiles(
rootDirectory, searchPattern);
IEnumerable<FileInfo> files = fileList.Select(
file => new FileInfo(file));
// ...
fileList is of type IEnumerable<string>. However, using the projection offered by Select, we can transform each item in the collection to a System.IO.FileInfo object.
Lastly, capitalizing on anonymous types, we could create an IEnumerable<T> collection where T is an anonymous type (see Listing 14.15 and Output 14.4).
Listing 14.15. Projection to an Anonymous Type
// ...
IEnumerable<string> fileList = Directory.GetFiles(
rootDirectory, searchPattern);
file =>
{
FileInfo fileInfo = new FileInfo(file);
return new
{
FileName = fileInfo.Name,
Size = fileInfo.Length
};
});
// ...
{ FileName = AssemblyInfo.cs, Size = 1704 }
{ FileName = CodeAnalysisRules.xml, Size = 735 }
{ FileName = CustomDictionary.xml, Size = 199 }
{ FileName = EssentialCSharp.sln, Size = 40415 }
{ FileName = EssentialCSharp.suo, Size = 454656 }
{ FileName = EssentialCSharp.vsmdi, Size = 499 }
{ FileName = EssentialCSharp.vssscc, Size = 256 }
{ FileName = intelliTechture.ConsoleTester.dll, Size = 24576 }
{ FileName = intelliTechture.ConsoleTester.pdb, Size = 30208 }
{ FileName = LocalTestRun.testrunconfig, Size = 1388 }
The output of an anonymous type automatically shows the property names and their values as part of the generated ToString() method associated with the anonymous type.
Projection using the Select() method is very powerful. We already saw how to filter a collection vertically (reducing the number of items in the collection) using the Where() standard query operator. Now, via the Select() standard query operator, we can also reduce the collection horizontally (making fewer columns) or transform the data entirely. In combination, Where() and Select() provide a means for extracting only the pieces of the original collection that are desirable for the current algorithm. These two methods alone provide a powerful collection manipulation API that would otherwise result in significantly more code that is less readable.
Counting Elements with Count()
Another common query performed on a collection of items is to retrieve the count. To support this LINQ includes the Count() extension method.
Listing 14.17 demonstrates that Count() is overloaded to simply count all elements (no parameters) or to take a predicate that only counts items identified by the predicate expression.
Listing 14.17. Counting Items with Count()
using System;
using System.Collections.Generic;
using System.Linq;
class Program
{
static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
Console.WriteLine("Patent Count: {0}", patents.Count());
Console.WriteLine("Patent Count in 1800s: {0}",
patents.Count(patent =>
patent.YearOfPublication.StartsWith("18")));
}
// ...
}
In spite of the simplicity of writing the Count() statement, IEnumerable<T> has not changed, so the executed code still involves iterating over all the items in the collection. Whenever a Count property is directly available on the collection, it is preferable to use that rather than LINQ’s Count() method (a subtle difference). Fortunately, ICollection<T> includes the Count property, so code that calls the Count() method on a collection that supports ICollection<T> will cast the collection and call Count directly. However, if ICollection<T> is not supported, Enumerable.Count() will proceed to enumerate all the items in the collection rather than call the built-in Count mechanism. If the purpose of checking the count is only to see whether it is greater than zero (if(patents.Count() > 0){...}), a preferable approach would be to use the Any() operator (if(patents.Any()){...}). Any() attempts to iterate over only one of the items in the collection to return a true result, rather than the entire sequence.
Deferred Execution
One of the most important concepts to remember when using LINQ is deferred execution. Consider the code in Listing 14.18 and the corresponding output in Output 14.5.
Listing 14.18. Filtering with System.Linq.Enumerable.Where()
using System;
using System.Collections.Generic;
using System.Linq;
// ...
IEnumerable<Patent> patents = PatentData.Patents;
bool result;
patents = patents.Where(
patent =>
{
if (result =
patent.YearOfPublication.StartsWith("18"))
{
// Side effects like this in a predicate
// are used here to demonstrate a
// principle and should generally be
// avoided.
Console.WriteLine(" " + patent);
}
return result;
});
Console.WriteLine("1. Patents prior to the 1900s are:");
foreach (Patent patent in patents)
{
}
Console.WriteLine();
Console.WriteLine(
"2. A second listing of patents prior to the 1900s:");
Console.WriteLine(
" There are {0} patents prior to 1900.",
patents.Count());
Console.WriteLine();
Console.WriteLine(
"3. A third listing of patents prior to the 1900s:");
patents = patents.ToArray();
Console.Write(" There are ");
Console.WriteLine("{0} patents prior to 1900.",
patents.Count());
// ...
1. Patents prior to the 1900s are:
Phonograph(1877)
Kinetoscope(1888)
Electrical Telegraph(1837)
Steam Locomotive(1815)
2. A second listing of patents prior to the 1900s:
Phonograph(1877)
Kinetoscope(1888)
Electrical Telegraph(1837)
Steam Locomotive(1815)
There are 4 patents prior to 1900.
3. A third listing of patents prior to the 1900s:
Phonograph(1877)
Kinetoscope(1888)
Electrical Telegraph(1837)
Steam Locomotive(1815)
There are 4 patents prior to 1900.
Notice that Console.WriteLine("1. Patents prior...) executes before the lambda expression. This is a very important characteristic to pay attention to because it is not obvious to those who are unaware of its importance. In general, predicates should do exactly one thing—evaluate a condition—and they should not have any side effects (even printing to the console, as in this example).
To understand what is happening, recall that lambda expressions are delegates—references to methods—that can be passed around. In the context of LINQ and standard query operators, each lambda expression forms part of the overall query to be executed.
At the time of declaration, lambda expressions do not execute. It isn’t until the lambda expressions are invoked that the code within them begins to execute. Figure 14.2 shows the sequence of operations.
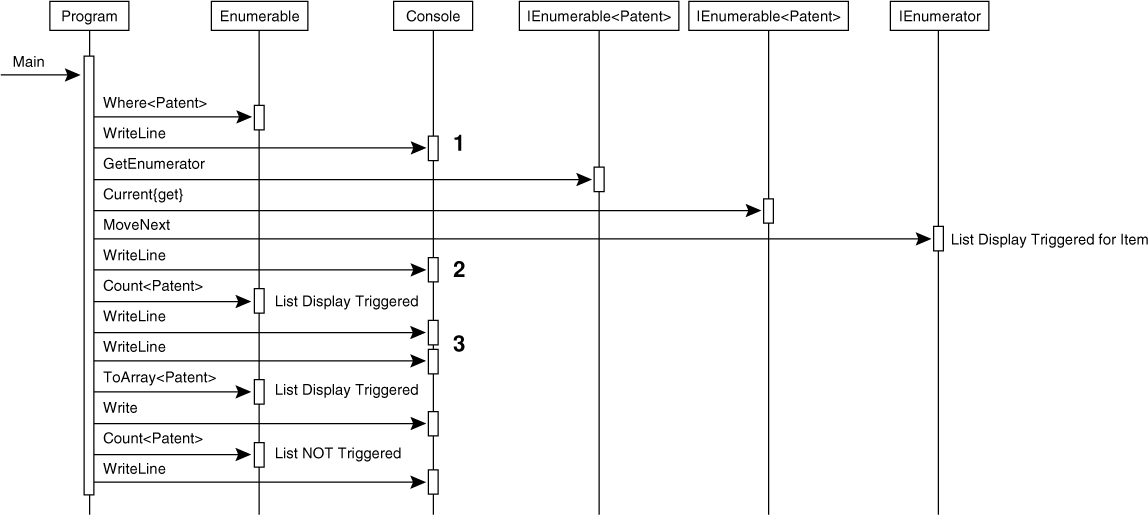
Figure 14.2. Sequence of Operations Invoking Lambda Expressions
As Figure 14.2 shows, three calls in Listing 14.16 trigger the lambda expression, and each time it is fairly implicit. If the lambda expression were expensive (such as a call to a database) it would be important to minimize the lambda expression’s execution.
First, the execution is triggered within the foreach loop. As we described earlier in the chapter, the foreach loop breaks down into a MoveNext() call and each call results in the lambda expression’s execution for each item in the original collection. While iterating, the runtime invokes the lambda expression for each item to determine whether the item satisfies the predicate.
Second, a call to Enumerable’s Count() (the function) triggers the lambda expression for each item once more. Again, this is very subtle since Count (the property) is very common on collections that have not been queried with a standard query operator.
Third, the call to ToArray() (or ToList(), ToDictionary(), or ToLookup()) triggers the lambda expression for each item. However, converting the collection with one of these “To” methods is extremely helpful. Doing so returns a collection on which the standard query operator has already executed. In Listing 14.16, the conversion to an array means that when Length is called in the final Console.WriteLine(), the underlying object pointed to by patents is in fact an array (which obviously implements IEnumerable<T>), and therefore, System.Array’s implementation of Length is called and not System.Linq.Enumerable’s implementation. Consequently, following a conversion to one of the collection types returned by a “To” method, it is generally safe to work with the collection (until another standard query operator is called). However, be aware that this will bring the entire result set into memory (it may have been backed by a database or file before this). Furthermore, the “To” method will snapshot the underlying data so that no fresh results will be returned upon requerying the “To” method result.
We strongly encourage readers to review the sequence diagram in Figure 14.2 along with the corresponding code and understand the fact that the deferred execution of standard query operators can result in extremely subtle triggering of the standard query operators; therefore, developers should use caution to avoid unexpected calls. The query object represents the query, not the results. When you ask the query for the results, the whole query executes (perhaps even again) because the query object doesn’t know that the results will be the same as they were during a previous execution (if one existed).
To avoid such repeated execution, it is necessary to cache the data that the executed query retrieves. To do this, you assign the data to a local collection using one of the “To” method’s collection methods. During the assignment call of a “To” method, the query obviously executes. However, iterating over the assigned collection after that will not involve the query expression any further. In general, if you want the behavior of an in-memory collection snapshot, it is a best practice to assign a query expression to a cached collection to avoid unnecessary iterations.
Sorting with OrderBy() and ThenBy()
Another common operation on a collection is to sort it. This involves a call to System.Linq.Enumerable’s OrderBy(), as shown in Listing 14.19 and Output 14.6.
Listing 14.19. Ordering with System.Linq.Enumerable.OrderBy()/ThenBy()
using System;
using System.Collections.Generic;
using System.Linq;
// ...
IEnumerable<Patent> items;
Patent[] patents = PatentData.Patents;
items = patents.OrderBy(
patent => patent.YearOfPublication).ThenBy(
patent => patent.Title);
Print(items);
Console.WriteLine();
items = patents.OrderByDescending(
patent => patent.YearOfPublication).ThenByDescending(
patent => patent.Title);
Print(items);
// ...
Bifocals (1784)
Steam Locomotive(1815)
Electrical Telegraph(1837)
Phonograph(1877)
Kinetoscope(1888)
Flying machine (1903)
Backless Brassiere(1914)
Droplet deposition apparatus(1989)
Droplet deposition apparatus(1989)
Backless Brassiere(1914)
Flying machine (1903)
Kinetoscope(1888)
Phonograph(1877)
Electrical Telegraph(1837)
Steam Locomotive(1815)
Bifocals (1784)
The OrderBy() call takes a lambda expression that identifies the key on which to sort. In Listing 14.19, the initial sort uses the year that the patent was published.
However, notice that the OrderBy() call takes only a single parameter, which uses the name keySelector, to sort on. To sort on a second column, it is necessary to use a different method: ThenBy(). Similarly, code would use ThenBy() for any additional sorting.
OrderBy() returns an IOrderedEnumerable<T> interface, not an IEnumerable<T>. Furthermore, IOrderedEnumerable<T> derives from IEnumerable<T>, so all the standard query operators (including OrderBy()) are available on the OrderBy() return. However, repeated calls to OrderBy() would undo the work of the previous call such that the end result would sort by only the keySelector in the final OrderBy() call. As a result, be careful not to call OrderBy() on a previous OrderBy() call.
Instead, you should specify additional sorting criteria using ThenBy(). Although ThenBy() is an extension method, it is not an extension of IEnumerable<T>, but rather IOrderedEnumerable<T>. The method, also defined on System.Linq.Extensions.Enumerable, is declared as follows:
public static IOrderedEnumerable<TSource>
ThenBy<TSource, TKey>(
this IOrderedEnumerable<TSource> source,
Func<TSource, TKey> keySelector)
In summary, use OrderBy() first, followed by zero or more calls to ThenBy() to provide additional sorting “columns.” The methods OrderByDescending() and ThenByDescending() provide the same functionality except with descending order. Mixing and matching ascending and descending methods is not a problem, but if sorting further, use a ThenBy() call (either ascending or descending).
Two more important notes about sorting: First, the actual sort doesn’t occur until you begin to access the members in the collection, at which point the entire query is processed. This occurs because you can’t sort unless you have all the items to sort; otherwise, you can’t determine whether you have the first item. The fact that sorting is delayed until you begin to access the members is due to deferred execution, as we describe earlier in this chapter. Second, each subsequent call to sort the data (Orderby() followed by ThenBy() followed by ThenByDescending(), for example) does involve additional calls to the keySelector lambda expression of the earlier sorting calls. In other words, a call to OrderBy() will call its corresponding keySelector lambda expression once you iterate over the collection. Furthermore, a subsequent call to ThenBy() will again make calls to OrderBy()’s keySelector.
Beginner Topic: Join Operations
Consider two collections of objects as shown in the Venn diagram in Figure 14.3.

Figure 14.3. Venn Diagram of Inventor and Patent Collections
The left circle in the diagram includes all inventors, and the right circle contains all patents. Within the intersection, we have both inventors and patents and a line is formed for each case where there is a match of inventors to patents. As the diagram shows, each inventor may have multiple patents and each patent can have one or more inventors. Each patent has an inventor, but in some cases inventors do not yet have patents.
Matching up inventors within the intersection to patents is an inner join. The result is a collection of inventor-patent pairs in which both patents and inventions exist for a pair. A left outer join includes all the items within the left circle regardless of whether they have a corresponding patent. In this particular example, a right outer join would be the same as an inner join since there are no patents without inventors. Furthermore, the designation of left versus right is arbitrary, so there is really no distinction between left and outer joins. A full outer join, however, would include records from both outer sides; it is relatively rare to perform a full outer join.
Another important characteristic in the relationship between inventors and patents is that it is a many-to-many relationship. Each individual patent can have one or more inventors (the flying machine’s invention by both Orville and Wilbur Wright, for example). Furthermore, each inventor can have one or more patents (Benjamin Franklin’s invention of both bifocals and the phonograph, for example).
Another common relationship is a one-to-many relationship. For example, a company department may have many employees. However, each employee can belong to only one department at a time. (However, as is common with one-to-many relationships, adding the factor of time can transform them into many-to-many relationships. A particular employee may move from one department to another so that over time, she could potentially be associated with multiple departments, making another many-to-many relationship.)
Listing 14.20 provides a sample listing of Employee and Department data, and Output 14.7 shows the results.
Listing 14.20. Sample Employee and Department Data
public class Department
{
public long Id { get; set; }
public string Name { get; set; }
public override string ToString()
{
return string.Format("{0}", Name);
}
}
public class Employee
{
public int Id { get; set; }
public string Name { get; set; }
public string Title { get; set; }
public int DepartmentId { get; set; }
public override string ToString()
{
return string.Format("{0} ({1})", Name, Title);
}
}
public static class CorporateData
{
public static readonly Department[] Departments =
new Department[]
{
new Department(){
Name="Corporate", Id=0},
new Department(){
Name="Finance", Id=1},
new Department(){
Name="Engineering", Id=2},
new Department(){
Name="Information Technology",
Id=3},
new Department(){
Name="Research",
Id=4},
new Department(){
Name="Marketing",
Id=5},
};
public static readonly Employee[] Employees = new Employee[]
{
new Employee(){
Name="Mark Michaelis",
Title="Chief Computer Nerd",
DepartmentId = 0},
new Employee(){
Name="Michael Stokesbary",
Title="Senior Computer Wizard",
DepartmentId=2},
new Employee(){
Name="Brian Jones",
Title="Enterprise Integration Guru",
DepartmentId=2},
new Employee(){
Name="Jewel Floch",
Title="Bookkeeper Extraordinaire",
DepartmentId=1},
new Employee(){
Name="Robert Stokesbary",
Title="Expert Mainframe Engineer",
DepartmentId = 3},
new Employee(){
Name="Paul R. Bramsman",
Title="Programmer Extraordinaire",
DepartmentId = 2},
new Employee(){
Name="Thomas Heavey",
Title="Software Architect",
DepartmentId = 2},
new Employee(){
Name="John Michaelis",
Title="Inventor",
DepartmentId = 4}
};
}
class Program
{
static void Main()
{
IEnumerable<Department> departments =
CorporateData.Departments;
Print(departments);
Console.WriteLine();
IEnumerable<Employee> employees =
CorporateData.Employees;
Print(employees);
}
private static void Print<T>(IEnumerable<T> items)
{
foreach (T item in items)
{
Console.WriteLine(item);
}
}
}
Corporate
Finance
Engineering
Information Technology
Research
Marketing
Mark Michaelis (Chief Computer Nerd)
Michael Stokesbary (Senior Computer Wizard)
Brian Jones (Enterprise Integration Guru)
Jewel Floch (Bookkeeper Extraordinaire)
Robert Stokesbary (Expert Mainframe Engineer)
Paul R. Bramsman (Programmer Extraordinaire)
Thomas Heavey (Software Architect)
John Michaelis (Inventor)
We will use the same data within the following section on joining data.
Performing an Inner Join with Join()
In the world of objects on the client side, relationships between objects are generally already set up. For example, the relationship between files and the directories in which they lie are preestablished with the DirectoryInfo.GetFiles() method and the FileInfo.Directory method. Frequently, however, this is not the case with data being loaded from nonobject stores. Instead, the data needs to be joined together so that you can navigate from one type of object to the next in a way that makes sense for the data.
Consider the example of employees and company departments. In Listing 14.21, we join each employee to his or her department and then list each employee with his or her corresponding department. Since each employee belongs to only one (and exactly one) department, the total number of items in the list is equal to the total number of employees—each employee appears only once (each employee is said to be normalized). Output 14.8 follows.
Listing 14.21. An Inner Join Using System.Linq.Enumerable.Join()
using System;
using System.Linq;
// ...
Department[] departments = CorporateData.Departments;
Employee[] employees = CorporateData.Employees;
var items = employees.Join(
departments,
employee => employee.DepartmentId,
department => department.Id,
(employee, department) => new
{
employee.Id,
employee.Name,
employee.Title,
Department = department
});
foreach (var item in items)
{
Console.WriteLine("{0} ({1})",
item.Name, item.Title);
Console.WriteLine(" " + item.Department);
}
// ...
Mark Michaelis (Chief Computer Nerd)
Corporate
Michael Stokesbary (Senior Computer Wizard)
Engineering
Brian Jones (Enterprise Integration Guru)
Engineering
Jewel Floch (Bookkeeper Extraordinaire)
Finance
Robert Stokesbary (Expert Mainframe Engineer)
Information Technology
Paul R. Bramsman (Programmer Extraordinaire)
Engineering
Thomas Heavey (Software Architect)
Engineering
John Michaelis (Inventor)
Research
The first parameter for Join() has the name inner. It specifies the collection, departments, that employees joins to. The next two parameters are lambda expressions that specify how the two collections will connect. employee => employee.DepartmentId (with a parameter name of outerKeySelector) identifies that on each employee the key will be DepartmentId. The next lambda expression (department => department.Id) specifies the Department’s Id property as the key. In other words, for each employee, join a department where employee.DepartmentId equals department.Id. The last parameter, the anonymous type, is the resultant item that is selected. In this case, it is a class with Employee’s Id, Name, and Title as well as a Department property with the joined department object.
Notice in the output that Engineering appears multiple times—once for each employee in CorporateData. In this case, the Join() call produces a Cartesian product between all the departments and all the employees such that a new record is created for every case where a record exists in both collections and the specified department IDs are the same. This type of join is an inner join.
The data could also be joined in reverse such that department joins to each employee so as to list each department-to-employee match. Notice that the output includes more records than there are departments because there are multiple employees for each department and the output is a record for each match. As we saw before, the Engineering department appears multiple times, once for each employee.
The code in Listing 14.22 and Output 14.9 is similar to that in Listing 14.21, except that the objects, Departments and Employees, are reversed. The first parameter to Join() is employees, indicating what departments joins to. The next two parameters are lambda expressions that specify how the two collections will connect: department => department.Id for departments and employee => employee.DepartmentId for employees. Just like before, a join occurs whenever department.Id equals employee.EmployeeId. The final anonymous type parameter specifies a class with int Id, string Name, and Employee Employee properties.
Listing 14.22. Another Inner Join with System.Linq.Enumerable.Join()
using System;
using System.Linq;
// ...
Department[] departments = CorporateData.Departments;
Employee[] employees = CorporateData.Employees;
var items = departments.Join(
employees,
department => department.Id,
employee => employee.DepartmentId,
(department, employee) => new
{
department.Id,
department.Name,
Employee = employee
});
foreach (var item in items)
{
Console.WriteLine("{0}",
item.Name);
Console.WriteLine(" " + item.Employee);
}
// ...
Corporate
Mark Michaelis (Chief Computer Nerd)
Finance
Jewel Floch (Bookkeeper Extraordinaire)
Engineering
Michael Stokesbary (Senior Computer Wizard)
Engineering
Brian Jones (Enterprise Integration Guru)
Engineering
Paul R. Bramsman (Programmer Extraordinaire)
Engineering
Thomas Heavey (Software Architect)
Information Technology
Robert Stokesbary (Expert Mainframe Engineer)
Research
John Michaelis (Inventor)
Grouping Results with GroupBy()
In addition to ordering and joining a collection of objects, frequently you might want to group objects with like characteristics together. For the employee data, you might want to group employees by department, region, job title, and so forth. Listing 14.23 shows an example of how to do this using the GroupBy() standard query operator (see Output 14.10 to view the output).
Listing 14.23. Grouping Items Together Using System.Linq.Enumerable.GroupBy()
using System;
using System.Linq;
// ...
IEnumerable<Employee> employees = CorporateData.Employees;
IEnumerable<IGrouping<int, Employee>> groupedEmployees =
employees.GroupBy((employee) => employee.DepartmentId);
foreach(IGrouping<int, Employee> employeeGroup in
groupedEmployees)
{
Console.WriteLine();
foreach(Employee employee in employeeGroup)
{
Console.WriteLine(" " + employee);
}
Console.WriteLine(
" Count: " + employeeGroup.Count());
}
// ...
Mark Michaelis (Chief Computer Nerd)
Count: 1
Michael Stokesbary (Senior Computer Wizard)
Brian Jones (Enterprise Integration Guru)
Paul R. Bramsman (Programmer Extraordinaire)
Thomas Heavey (Software Architect)
Count: 4
Jewel Floch (Bookkeeper Extraordinaire)
Count: 1
Robert Stokesbary (Expert Mainframe Engineer)
Count: 1
John Michaelis (Inventor)
Count: 1
Note that the items output from a GroupBy() call are of type IGrouping<TKey, TElement> which has a property for the key that the query is grouping on (employee.DepartmentId). However, it does not have a property for the items within the group. Rather, IGrouping<TKey, TElement> derives from IEnumerable<T>, allowing for enumeration of the items within the group using a foreach statement or for aggregating the data into something such as a count of items (employeeGroup.Count()).
Implementing a One-to-Many Relationship with GroupJoin()
Listing 14.21 and Listing 14.22 are virtually identical. Either Join() call could have produced the same output just by changing the anonymous type definition. When trying to create a list of employees, Listing 14.21 provides the correct result. department ends up as a property of each anonymous type representing the joined employee. However, Listing 14.22 is not optimal. Given support for collections, a preferable representation of a department would have a collection of employees rather than a single anonymous type record for each department-employee relationship. Listing 14.24 demonstrates; Output 14.11 shows the preferred output.
Listing 14.24. Creating a Child Collection with System.Linq.Enumerable.GroupJoin()
using System;
using System.Linq;
// ...
Department[] departments = CorporateData.Departments;
Employee[] employees = CorporateData.Employees;
var items = departments.GroupJoin(
employees,
department => department.Id,
employee => employee.DepartmentId,
(department, departmentEmployees) => new
{
department.Id,
department.Name,
Employees = departmentEmployees
});
foreach (var item in items)
{
Console.WriteLine("{0}",
item.Name);
foreach (Employee employee in item.Employees)
{
Console.WriteLine(" " + employee);
}
}
// ...
Corporate
Mark Michaelis (Chief Computer Nerd)
Finance
Jewel Floch (Bookkeeper Extraordinaire)
Engineering
Michael Stokesbary (Senior Computer Wizard)
Brian Jones (Enterprise Integration Guru)
Paul R. Bramsman (Programmer Extraordinaire)
Thomas Heavey (Software Architect)
Information Technology
Robert Stokesbary (Expert Mainframe Engineer)
Research
John Michaelis (Inventor)
To achieve the preferred result we use System.Linq.Enumerable’s GroupJoin() method. The parameters are the same as those in Listing 14.21, except for the final anonymous type selected. In Listing 14.21, the lambda expression is of type Func<Department, IEnumerable<Employee>, TResult> where TResult is the selected anonymous type. Notice that we use the second type argument (IEnumerable<Employee>) to project the collection of employees for each department onto the resultant department anonymous type.
(Readers familiar with SQL will notice that, unlike Join(), GroupJoin() doesn’t have a SQL equivalent since data returned by SQL is record-based, and not hierarchical.)
Calling SelectMany()
On occasion, you may have collections of collections. Listing 14.26 provides an example of such a scenario. The teams array contains two teams, each with a string array of players.
Listing 14.26. Calling SelectMany()
using System;
using System.Collections.Generic;
using System.Linq;
// ...
var worldCup2006Finalists = new[]
{
new
{
TeamName = "France",
Players = new string[]
{
"Fabien Barthez", "Gregory Coupet",
"Mickael Landreau", "Eric Abidal",
"Jean-Alain Boumsong", "Pascal Chimbonda",
"William Gallas", "Gael Givet",
"Willy Sagnol", "Mikael Silvestre",
"Lilian Thuram", "Vikash Dhorasoo",
"Alou Diarra", "Claude Makelele",
"Florent Malouda", "Patrick Vieira",
"Zinedine Zidane", "Djibril Cisse",
"Thierry Henry", "Franck Ribery",
"Louis Saha", "David Trezeguet",
"Sylvain Wiltord",
}
},
new
{
TeamName = "Italy",
Players = new string[]
{
"Gianluigi Buffon", "Angelo Peruzzi",
"Marco Amelia", "Cristian Zaccardo",
"Alessandro Nesta", "Gianluca Zambrotta",
"Fabio Cannavaro", "Marco Materazzi",
"Fabio Grosso", "Massimo Oddo",
"Andrea Barzagli", "Andrea Pirlo",
"Gennaro Gattuso", "Daniele De Rossi",
"Mauro Camoranesi", "Simone Perrotta",
"Simone Barone", "Luca Toni",
"Alessandro Del Piero", "Francesco Totti",
"Alberto Gilardino", "Filippo Inzaghi",
"Vincenzo Iaquinta",
}
}
};
IEnumerable<string> players =
worldCup2006Finalists.SelectMany(
team => team.Players);
Print(players);
// ...
The output from this listing has each player’s name displayed on its own line in the order in which it appears in the code. The difference between Select() and SelectMany() is the fact that Select() would return two items, one corresponding to each item in the original collection. Select() may project out a transform from the original type, but the number of items would not change. For example, teams.Select(team => team.Players) will return an IEnumerable<string[]>.
In contrast, SelectMany() iterates across each item identified by the lambda expression (the array selected by Select() earlier) and hoists out each item into a new collection that includes a union of all items within the child collection. Instead of two arrays of players, SelectMany() combines each array selected and produces a single collection of all items.
More Standard Query Operators
Listing 14.27 shows code that uses some of the simpler APIs enabled by Enumerable; Output 14.13 shows the results.
Listing 14.27. More System.Linq.Enumerable Method Calls
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
class Program
{
static void Main()
{
IEnumerable<object> stuff =
new object[] { new object(), 1, 3, 5, 7, 9,
""thing"", Guid.NewGuid() };
Print("Stuff: {0}", stuff);
IEnumerable<int> even = new int[] { 0, 2, 4, 6, 8 };
Print("Even integers: {0}", even);
IEnumerable<int> odd = stuff.OfType<int>();
Print("Odd integers: {0}", odd);
IEnumerable<int> numbers = even.Union(odd);
Print("Union of odd and even: {0}", numbers);
Print("Union with even: {0}", numbers.Union(even));
Print("Concat with odd: {0}", numbers.Concat(odd));
Print("Intersection with even: {0}",
numbers.Intersect(even));
Print("Distinct: {0}", numbers.Concat(odd).Distinct());
if (!numbers.SequenceEqual(
numbers.Concat(odd).Distinct()))
{
throw new Exception("Unexpectedly unequal");
}
else
{
Console.WriteLine(
@"Collection ""SequenceEquals""" +
" collection.Concat(odd).Distinct())");
Print("Reverse: {0}", numbers.Reverse());
Print("Average: {0}", numbers.Average());
Print("Sum: {0}", numbers.Sum());
Print("Max: {0}", numbers.Max());
Print("Min: {0}", numbers.Min());
}
}
private static void Print<T>(
string format, IEnumerable<T> items)
{
StringBuilder text = new StringBuilder();
foreach (T item in items.Take(items.Count()-1))
{
text.Append(item + ", ");
}
text.Append(items.Last());
Console.WriteLine(format, text);
}
private static void Print<T>(string format, T item)
{
Console.WriteLine(format, item);
}
}
Stuff: System.Object, 1, 3, 5, 7, 9, "thing"
24c24a41-ee05-41b9-958e-50dd12e3981e
Even integers: 0, 2, 4, 6, 8
Odd integers: 1, 3, 5, 7, 9
Union of odd and even: 0, 2, 4, 6, 8, 1, 3, 5, 7, 9
Union with even: 0, 2, 4, 6, 8, 1, 3, 5, 7, 9
Concat with odd: 0, 2, 4, 6, 8, 1, 3, 5, 7, 9, 1, 3, 5, 7, 9
Intersection with even: 0, 2, 4, 6, 8
Distinct: 0, 2, 4, 6, 8, 1, 3, 5, 7, 9
Collection "SequenceEquals"collection.Concat(odd).Distinct())
Reverse: 9, 7, 5, 3, 1, 8, 6, 4, 2, 0
Average: 4.5
Sum: 45
Max: 9
Min: 0
None of the API calls in Listing 14.20 requires a lambda expression. Table 14.1 and Table 14.2 describe each method and provide an example.
Table 14.1. Simpler Standard Query Operators
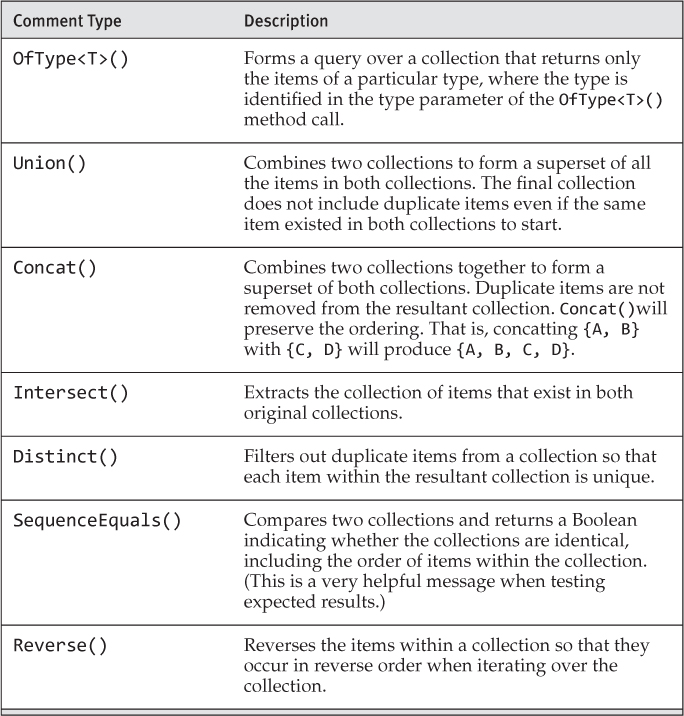
Table 14.2. Aggregate Functions on System.Linq.Enumerable

Included on System.Linq.Enumerable is a collection of aggregate functions that enumerate the collection and calculate a result. Count is one example of an aggregate function already shown within the chapter.
Note that each method listed in Tables 14.1 and 14.2 will trigger deferred execution.
Summary
After introducing anonymous types, implicit variables, and collection initializers, this chapter described the internals of how the foreach loop works and what interfaces are required for its execution. In addition, developers frequently filter a collection so that there are fewer items and project the collection so that the items take a different form. Toward that end, this chapter discussed the details of how to use the standard query operators, common collection APIs on the System.Linq.Enumerable class, to perform collection manipulation.
In the introduction to standard query operators, we spent a few pages detailing deferred execution and how developers should take care to avoid unintentionally reexecuting an expression via a subtle call that enumerates over the collection contents. The deferred execution and resultant implicit execution of standard query operators is a significant quality, especially when the query execution is expensive. Programmers should treat the query object as the query object, not the results, and expect the query to execute fully even if it executed already. The query object doesn’t know that the results will be the same as they were during a previous execution.
Listing 14.25 appeared within an Advanced Topic section because of the complexity of calling multiple standard query operators one after the other. Although requirements for similar execution may be common, it is not necessary to rely on standard query operators directly. C# 3.0 includes query expressions, a SQL-like syntax for manipulating collections in a way that is frequently easier to code and read, as we show in the next chapter.