
In the classic movie, Airplane, the director of the airport orders his men to “dump all the lights you have on the runway” as an ailing plane prepares to make an emergency landing. In the next shot, a large dump truck unloads hundreds of table lamps, sending them crashing to the runway pavement. Though surely not produced with EDA in mind (who asked Shirley, anyway?), this scene illustrates one of the great vulnerabilities of airline flight control. Though airline flight control involves a lot of complex, logistical matters, it relies to a great degree on human-to-human voice communication or dead-ended and circumscribed views of disconnected information systems.
Of course, much of the system is automated, but there is significant room for improvement. In this case study, we look at how an EDA approach can solve one of the major deficits of existing airline flight control systems, which is their inability to provide comprehensive updates in real time to all stakeholders who experience the “ripple effect” of a serious service disruption.
Air traffic flow management is a fantastically complex subject, and a lot of very smart people are thinking about how to improve it as part of their daily work. Our goal in this chapter, therefore, is not to solve the whole problem, but rather to highlight how an EDA approach can help yield desired results in this challenging situation. We refer to existing expert research and discussion of the subject throughout.
![]() Understanding how EDA can offer a unique solution to a complex, multiplayer problem in the real world
Understanding how EDA can offer a unique solution to a complex, multiplayer problem in the real world
![]() Getting a basic sense of the life cycle for a large EDA project
Getting a basic sense of the life cycle for a large EDA project
![]() Understanding the flow of work from concept through deployment in a large EDA project
Understanding the flow of work from concept through deployment in a large EDA project
![]() Understanding the governance issues inherent in a complex, multistakeholder EDA
Understanding the governance issues inherent in a complex, multistakeholder EDA
Airline Flight Control is a high-stakes matter. In the United States alone, commercial air travel was a $163 billion business in 2006,1 and overall, it’s not an industry in particularly good health. Several of the largest carriers are either operating in bankruptcy or have just recently emerged from bankruptcy. The industry has been less than profitable in the years since the 9/11 attacks, and while things have picked up for the airlines in 2006 and 2007, the industry is still struggling and savagely competitive.
The numbers involved are staggering. In the 12 months ending in February 2007, U.S. airlines embarked on 10,576,953 flights, flying over 7 billion route miles and logging 17,804, 595 hours in the air.2 And, as we know, service could be better. In the same period, between 22% and 32% of all those flights were late.3
Although many factors contribute to low profitability and poor on-time records for airlines, one of the biggest culprits identified in the industry dialogues is the core set of systems and processes that governs the flow of airline traffic around the country. Expert after expert suggests that improvements in the Air Traffic Control System Command Center, and its various systems, subsystems, and territorial centers, could lead to increased efficiencies in air traffic flow and improved industry on-time performance and financial results. The airline industry, hurting as it is, could certainly use such an improvement. Besides, the volume of flights keeps increasing every year, so the matter is as urgent as ever.
As we discuss inefficiencies and potential improvements in the air traffic management problem, we do not want to do a disservice to the existing systems. Indeed, there is an impressive array of information gathering and distribution technologies at work keeping 45,000 flights safely in the air every day in the United States! However, as with any large-scale work in progress, there is always room to make things better.
Figure 7.1 shows a screen capture of one aspect of the FAA’s Air Traffic Control System Command Center (ATCSCC) software. The ATCSCC, which is a bundle of related and connected systems from across the country, tracks all the flights in the air and on the ground, serving up information about flight status and flight volume to air traffic control managers and other stakeholders. Many operational decisions at airports, airlines, and support providers, such as refueling services, are based on information provided minute by minute during the day from the ATCSCC.
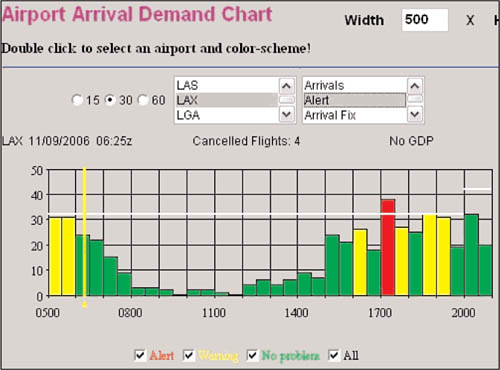
In this case, the application is showing a graphic display of the capacity of Los Angeles International Airport to handle the expected flow of incoming flights over a period of hours. The thin, white horizontal line indicates the maximum flight-handling capacity of the airport. As we can see, the day looks like smooth flow until 1700 hours, when the number of inbound flights will exceed the airport’s capacity. The red bar shows this alert. The result of this overflow will be a delay to some flights. The graphical display gives airport personnel and the airlines opportunity to work around the impending overflow and try to mitigate its impact on the schedule. The yellow bars show time slots where there is a risk of going over capacity and causing delays.
When most of us think of flight control systems, we picture airplanes and control towers. The planes, though, are only one part of a large, complex system with many moving parts and separate participants, each of which plays an integral role in keeping the planes moving on time. There are airports, with their limited gate capacity and ground support services, including fueling and maintenance. There are personnel such as pilots and flight crews. There is the air traffic control network itself, which tracks the whereabouts of each plane and guides its path. There is the schedule and route network, which contains thousands of multistop flights and arrival-contingent departures, and so on. For example, if a plane is late, it might throw subsequent flights in the day off schedule and disrupt the utilization of support services and airport capacity in other cities as a result.
The airline flight control system is one of numerous and intricate dependencies between the multiple parties involved. And, it is a global system, even if our focus is only North America. For example, if JFK Airport in New York City were to close, even for a couple of hours, flights all around the world would be affected. New York–bound flights would not be able to take off, which would cause any number of cascading backups elsewhere. Flights from New York would be delayed, which would aggravate schedules in yet another collection of cities. In each place, airlines would have to scramble to find alternatives, such as flying to Newark, canceling flights, waiting to fly to JFK, and possibly taxing ground services and crews, and so on.
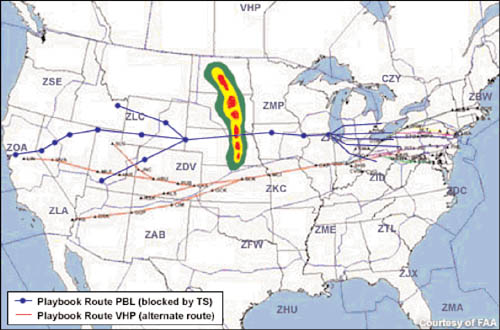
At present, the airline flight control system is pretty responsive to service disruptions, but its performance is not reliable nor is it particularly efficient. Figure 7.2 shows the “playbook,” one factor in the system’s responsiveness to disruptions. In the event of a major weather pattern, the playbook suggests a rerouting pattern for flights. Here is where the system works well but also has some major deficiencies. Much airline flight scheduling and airport traffic control is automated, based on integration with the FAA’s systems and its response to playbook rerouting.
However, other aspects of the system are automated but not connected to related operational areas. For example, the flight refueling service at an airport might have a computerized schedule, but changes to the schedule based on flight delays might be manual, or rely on manual or verbal overrides. Notifications about major disruptions in service are almost completely manual, or highly reliant on human interpretation of automated system data and transposition of system data to verbal dissemination. In some respects, this is a good aspect of the system. Some of the stakes involved, such as safety, are quite high, and it is probably for the best that people are the key conveyers of information. Human involvement ensures a level of control over the situation, and allows a degree of flexibility that averts potentially disastrous results. However, the distributed and haphazard nature of the airline flight control systems leads to less-than-optimal results in terms of overall airline performance. This is what airline managers call the ripple effect.
The ripple effect is the set of consequences that arise when there is a major disruption, such as the closing of an airport due to bad weather. As we saw with the example of JFK closing, the ripples can flow worldwide. The issue for us is this: How bad will those ripples be, what level of service disruption will result, and how can it be avoided? The problem is that the closure of an airport is bad enough, but sluggish responses to the closure can compound the ripples of disruption because of the network of dependencies that exists in the system. For example, if JFK is closed for one hour, let’s say, due to a security alarm, but the word goes out that the airport is closed indefinitely, then an excessive number of flights will be diverted or canceled, a move that might overtax services at the diversion destinations and back the whole system up for a day or more.
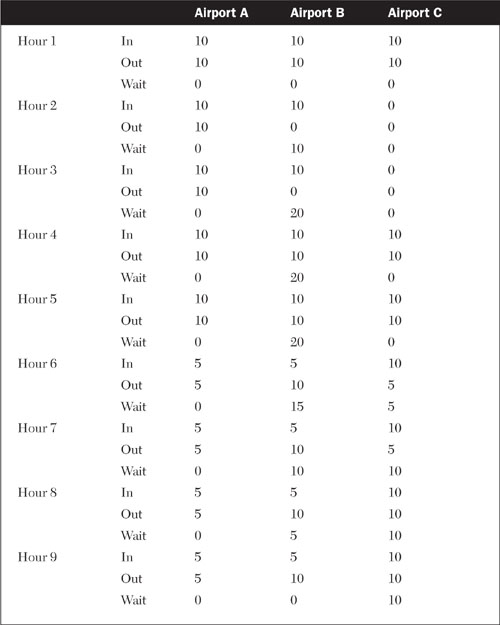
In quantitative terms, the backlog in flights resulting from an outage resembles a buildup in work in process inventory on a factory floor when a key manufacturing process goes offline. The result is a bottleneck, with the slowest cycle setting the pace for the whole operation. Table 7.1 shows a simplified model of air traffic, with flights going in sequence from Airport A, to B, to C. Each airport can handle 10 flights per hour, and has 10 flights per hour traveling in and out. The result is stasis, with zero delay for any flight. In the second hour, Airport C is blocked. Over the next few hours, flights start to pile up at Airport B and then A as the chain of dependent connections is blocked. The delay would, in fact, be permanent if the rush of oncoming flights didn’t slow down in the later hours. We’re not making this up. A good recent example of the day-to-day realities of this problem could be found in the May 22, 2007, announcement that United Airlines was shifting a number of its morning flights to 5:30 AM to ease congestion at O’Hare airport. The 6 to 7 slot was so packed that the flights inevitably got delayed because the airport’s capacity was maxed out at the later hour.
Though the airlines, the FAA, airports, and service providers work hard on solving the ripple effect, the volume of information that must be managed in a tight time frame leads to inevitable inefficiencies and suboptimal solutions to incidents that slow down air traffic. For example, although the FAA provides very good data, the airlines are not always completely able to integrate delay and playbook type of information into their flight scheduling. Certainly, most of the support providers lack tight integration with the FAA and airline scheduling systems. As a result, the flow of flights in an airport outage or slowdown might cause a severe overloading of an alternate landing site’s capacity, a problem which then creates its own downstream delays.
The financial stakes are high. The hard-dollar costs of late flights can be significant, especially in an industry that is struggling to be profitable. For example, an Airbus 320 airliner sitting on the runway with its engines idling burns $400 of fuel an hour. A delayed airliner waiting to land or diverted to an alternative site burns fuel at an even higher rate. Add to that figure crew overtime, passenger refunds, and the cost of a $50,000,000 jet being underutilized, and multiply by thousands of flights per year. Throw in high-value intangibles such as customer attitude and airline reputation, and you’re talking about a multibillion dollar problem.
The incentive to fix the ripple effect is very clear and strong, and the players are eager to find solutions. Indeed, there are many solutions being pursued or partially in place at this time. However, what’s missing in the airline flight control system is a way for all the participants in the dance of coordinating flights to have access to reliable real-time information about the flight factors that affect their particular aspect of the system. To date, most attempts to solve the ripple effect have suffered from high costs of integrating systems, as well as the organizational complexity and inhibitions regarding integrating with third parties and competitors. For these reasons, EDA emerges as a workable solution approach to tie together the highly distributed, multiple parties involved in air traffic and the ripple effect.
To a limited extent, the air traffic control systems already use an EDA, albeit one that relies extensively on human interactions to reach its full extent. As data flows out of the FAA systems, a series of phone and radio voice communications brings event data to a combination of systemic and human event processors. For example, as the capacity of an airport is reached, a verbal discussion might determine that flowing excess traffic to later arrival times is an optimal fix to the problem. However, because this overly human EDA is missing the full event picture, the people using their brains as event processors might actually compound the problem by pushing flights to a time of day when refueling capacity or gate capacity is severely limited.
Having defined the problem, let’s now imagine that we have been tasked with designing an EDA that can have a tangible impact on the ripple effect. Let’s call it FEDA for flight event-driven architecture. FEDA is an EDA that brings together the key players in airline flight control and enables them to share flight event data in real time. Throughout the rest of the chapter, we explore how an FEDA might ideally mitigate the ripple effect. To maximize the learning opportunity, we simplify certain aspects of the flight control problem and focus on architectural issues rather than deeply realistic descriptions of the various systems involved. However, even if you are a seasoned FAA programmer, you might still find the following exercise to be thought-provoking.
Any successful IT program must begin with identification of major objectives and buy-in from key stakeholders. In the case of FEDA, there are two types of stakeholders: direct and indirect. Direct stakeholders would include the airlines, the FAA, airports, aviation service providers such as refueling and maintenance, weather services, information technology service providers to all parties, and key personnel in each group. Indirect stakeholders would be passengers and crew, who are affected by airline flight control but do not exercise any influence over it. For FEDA, we will concern ourselves only with direct stakeholders.
The good news for an idea like FEDA is that there is a simple overall goal for the project, and a high degree of alignment in desiring the goal among the stakeholders. Everyone wants to cut down the financial impact and stress of the ripple effect. In specific terms, we see two groupings of project objectives for FEDA: functional and architectural requirements.
![]() Real-time awareness, for both human and machine users of FEDA, of airline flight control events that affect each FEDA stakeholder—FEDA needs to give stakeholders a better idea of what is going on with the flow of flights than they could get by picking up the phone or assessing multiple data inputs manually. In this context, a stakeholder could be either a person, such as an airport operations manager, or a system, such as a gate scheduling program.
Real-time awareness, for both human and machine users of FEDA, of airline flight control events that affect each FEDA stakeholder—FEDA needs to give stakeholders a better idea of what is going on with the flow of flights than they could get by picking up the phone or assessing multiple data inputs manually. In this context, a stakeholder could be either a person, such as an airport operations manager, or a system, such as a gate scheduling program.
![]() Autonomic response—FEDA should have some level of autonomic response capability. The EDA cannot rely solely on human decision making and event processing. If that were the case, FEDA would simply be a costly version of the current manual system. FEDA needs to be able to make, or at least recommend, routing and scheduling options for flights and airport operations. Then, based on human approvals, FEDA should have the ability to communicate specific routing and scheduling information to each stakeholder system seamlessly. For example, if a backlog of arriving flights has been described by FEDA, FEDA should have a level of integration with airport operations and support services’ systems so that those systems can receive complete updated schedules automatically from FEDA.
Autonomic response—FEDA should have some level of autonomic response capability. The EDA cannot rely solely on human decision making and event processing. If that were the case, FEDA would simply be a costly version of the current manual system. FEDA needs to be able to make, or at least recommend, routing and scheduling options for flights and airport operations. Then, based on human approvals, FEDA should have the ability to communicate specific routing and scheduling information to each stakeholder system seamlessly. For example, if a backlog of arriving flights has been described by FEDA, FEDA should have a level of integration with airport operations and support services’ systems so that those systems can receive complete updated schedules automatically from FEDA.
![]() Extensible, customizable front ends—FEDA should contain a number of basic functions at the outset, but the EDA and its related front-end interfaces, both human and machine, should be extensible and open to customization for specific stakeholder needs.
Extensible, customizable front ends—FEDA should contain a number of basic functions at the outset, but the EDA and its related front-end interfaces, both human and machine, should be extensible and open to customization for specific stakeholder needs.
![]() Extensible for new stakeholders—FEDA should have application programming interfaces (APIs) capable of easily adding new types of system users. For example, an airport shuttle service or baggage handler union might also want to have better knowledge of flight schedules so that it can optimize its own operations. FEDA’s design must allow for defining and provisioning the system to new user types.
Extensible for new stakeholders—FEDA should have application programming interfaces (APIs) capable of easily adding new types of system users. For example, an airport shuttle service or baggage handler union might also want to have better knowledge of flight schedules so that it can optimize its own operations. FEDA’s design must allow for defining and provisioning the system to new user types.
![]() Advanced bottleneck awareness—For FEDA to have high value, the system needs to show conflicts and potential delays before they happen. In other words, FEDA must be able to “think ahead” and develop airline traffic flow scenarios and describe their potential impacts on each stakeholders’ operations.
Advanced bottleneck awareness—For FEDA to have high value, the system needs to show conflicts and potential delays before they happen. In other words, FEDA must be able to “think ahead” and develop airline traffic flow scenarios and describe their potential impacts on each stakeholders’ operations.
![]() “What-if” modeling at the stakeholder level—FEDA should be able to give stakeholders the ability to run what-if scenarios on impending traffic flows and scheduling. The system should allow for a local playbook type model that can be stored for future use. Ideally, the system will enable systemic learning, giving users the opportunity to review past scenarios and understand how optimal flow can be achieved in the future.
“What-if” modeling at the stakeholder level—FEDA should be able to give stakeholders the ability to run what-if scenarios on impending traffic flows and scheduling. The system should allow for a local playbook type model that can be stored for future use. Ideally, the system will enable systemic learning, giving users the opportunity to review past scenarios and understand how optimal flow can be achieved in the future.
![]() Bottleneck resolution capacity—FEDA should do more than just report potential delays and map out a playbook for easing the resulting ripple-effect congestion. The system should contain a set of functions for stakeholders to use in resolving ripple-effect flight backlogs in a way that is fair and optimal to each entity. For example, as Steven Waslander has suggested in his research, the airlines might benefit from the ability to buy and sell traffic flow factors to discover and realize an optimal financial result from a particular traffic pattern. FEDA could enable this type of flight delay and airport capacity “auction.”
Bottleneck resolution capacity—FEDA should do more than just report potential delays and map out a playbook for easing the resulting ripple-effect congestion. The system should contain a set of functions for stakeholders to use in resolving ripple-effect flight backlogs in a way that is fair and optimal to each entity. For example, as Steven Waslander has suggested in his research, the airlines might benefit from the ability to buy and sell traffic flow factors to discover and realize an optimal financial result from a particular traffic pattern. FEDA could enable this type of flight delay and airport capacity “auction.”
![]() Interstakeholder communication capabilities at the system level—For FEDA to deliver better airline traffic results than the current semiautomated, phone- and computer-based systems, each stakeholder in FEDA must be able to communicate with each other at the system level. Data about airline traffic patterns and potential schedule changes must flow from system to system within FEDA as data. FEDA should not be reliant on a person transmitting data to another person in the system to achieve a result. Of course, human users can modify data in the system in real time and override FEDA’s scheduling algorithms for a myriad of reasons, not the least of which would be safety.
Interstakeholder communication capabilities at the system level—For FEDA to deliver better airline traffic results than the current semiautomated, phone- and computer-based systems, each stakeholder in FEDA must be able to communicate with each other at the system level. Data about airline traffic patterns and potential schedule changes must flow from system to system within FEDA as data. FEDA should not be reliant on a person transmitting data to another person in the system to achieve a result. Of course, human users can modify data in the system in real time and override FEDA’s scheduling algorithms for a myriad of reasons, not the least of which would be safety.
![]() Reliability, security, reporting, and audit—It’s a given that FEDA must be highly reliable, scalable, and secure. Any system of this type has to meet strict standards for performance and security. The system needs to enable extensive reporting and potential integration with analytics tools. And, it must be able to pass the test of auditors who want to assure stakeholders that the data in the system is confidential and accurate.
Reliability, security, reporting, and audit—It’s a given that FEDA must be highly reliable, scalable, and secure. Any system of this type has to meet strict standards for performance and security. The system needs to enable extensive reporting and potential integration with analytics tools. And, it must be able to pass the test of auditors who want to assure stakeholders that the data in the system is confidential and accurate.
![]() Bottleneck analytics—Over time, FEDA should be able to show analysts where bottlenecks occur in the overall flight traffic system and highlight potential solutions. With a root-cause analysis, for example, FEDA might be able to show that recurring delays stem from a lack of gate capacity at a specific airport. Such data could be used to justify additional investment in gate facilities at the airport to relieve congestion.
Bottleneck analytics—Over time, FEDA should be able to show analysts where bottlenecks occur in the overall flight traffic system and highlight potential solutions. With a root-cause analysis, for example, FEDA might be able to show that recurring delays stem from a lack of gate capacity at a specific airport. Such data could be used to justify additional investment in gate facilities at the airport to relieve congestion.
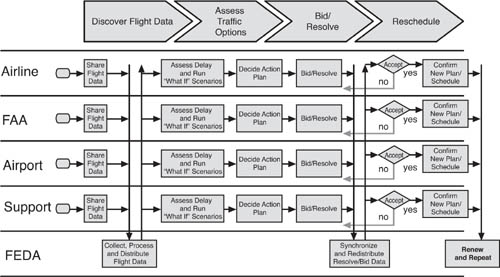
Figure 7.3 shows how FEDA works in resolving a ripple-effect delay situation by involving the air traffic stakeholders in a multitrack business process flow. FEDA is at the heart of this process flow, collecting and synchronizing air traffic and other operational data and distributing it to stakeholder systems (FEDA client applications and human users). FEDA also collects, synchronizes, and distributes the collaborative bid/resolve communications that occur among the stakeholders as they interpret real-time event data and make operating decisions based on the ripple’s impact on their business.
FEDA will naturally encompass hundreds of heterogeneous systems across a comparable number of organizations. To work, FEDA must comprise a set of system requirements that enable such a broad level of integration. To that end, it’s a given that FEDA will be based on SOAP XML Web services functioning in a service-oriented architecture (SOA) type architecture. As such, FEDA should mesh with most of the developing SOA initiatives that are likely to be under way at the stakeholders. In addition, FEDA should include the following high-level system requirements:
![]() Data transformation—FEDA will fail if it requires stakeholders to modify their current data models. FEDA needs to contain extensive data-transformation capabilities, as well as an extensible data dictionary, for smooth interoperation of component systems.
Data transformation—FEDA will fail if it requires stakeholders to modify their current data models. FEDA needs to contain extensive data-transformation capabilities, as well as an extensible data dictionary, for smooth interoperation of component systems.
![]() FEDA should be highly extensible—The EDA should be designed for a high level of component reuse. For example, a weather event service should be able to flow event data to event listeners of multiple types, including those not immediately envisioned for the initial deployment.
FEDA should be highly extensible—The EDA should be designed for a high level of component reuse. For example, a weather event service should be able to flow event data to event listeners of multiple types, including those not immediately envisioned for the initial deployment.
![]() Processing of relevant airline flight control events at the local, stakeholder level—FEDA connects thousands of independent event streams, from regional and international airports and a myriad of other systems. FEDA must be designed at all levels—from local implementation to global architecture, to enable event origination at the smallest level of granularity and locality.
Processing of relevant airline flight control events at the local, stakeholder level—FEDA connects thousands of independent event streams, from regional and international airports and a myriad of other systems. FEDA must be designed at all levels—from local implementation to global architecture, to enable event origination at the smallest level of granularity and locality.
![]() Cost-effective integration—FEDA must have the capability for existing and new stakeholders to connect with the airline flight control EDA at a reasonable cost.
Cost-effective integration—FEDA must have the capability for existing and new stakeholders to connect with the airline flight control EDA at a reasonable cost.
![]() Minimal impact on existing systems in their day-to-day operations—FEDA must “do no harm” to existing systems. Rather, it should expose event data as event services by riding on top of existing systems.
Minimal impact on existing systems in their day-to-day operations—FEDA must “do no harm” to existing systems. Rather, it should expose event data as event services by riding on top of existing systems.
FEDA is going to be a complex EDA. To make sense of it, we think it is wise to describe the architecture in two steps. First, we will outline a high-level view of the EDA. Then, we will plunge into detail. Figure 7.4 shows such a high-level architectural view. As we can see, event data originates at the top of the diagram, with the systems of the respective stakeholders. The control towers and FAA systems are the event producers that generate a set of event streams that describe flight departures and arrival times. The airline systems produce their own comparable event streams. Fueling and maintenance services produce event streams that describe their progress in servicing flights on the ground, while weather services generate event data about conditions that might affect flight operations.
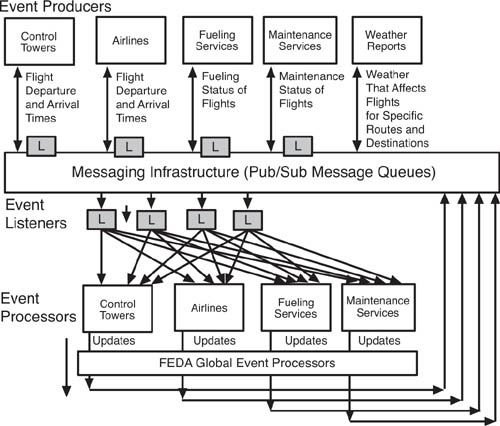
Event data flows to the messaging infrastructure. The event producers publish event information through event (Web) services. Event listeners subscribe to the event streams published by the event services. Through the messaging infrastructure, the event listeners flow event data to the event processors as instructed by the subscription settings of the event processors. For example, Southwest Airlines operations at LAX would not subscribe to event data that described flight capacity at London’s Heathrow airport. Yet, Southwest would certainly be made aware of any major outage at Heathrow that flowed back by ripple effect all the way to LAX. FEDA is a global system, and all subscribers (event processors) are able to see information that affects their operating conditions.
The information architecture issue here is how to present data to stakeholders. It would be impossible and undesirable to have every airline operations center view every single event in the entire world every second. There needs to be a primary operational field of vision for a specific airline at a specific airport. At a secondary level, FEDA needs to provide stakeholders with situational information that might affect their operations.
FEDA has multiple sets of event processors that perform functions related to their location and stakeholder. At the level of the individual airport, including the airlines that operate there and their respective service providers, FEDA event processors provide basic visibility into the flow of inbound and outbound flights. Working to the degree of automation that is user-specified, they can help stakeholders optimize their operations in that airport. The local level FEDA event processors power scenario modeling, interstakeholder communication, and the bid/resolve functions that allow stakeholders to pay, or get paid, for shifting traffic flow. In essence, the local level (airport) event processor lets the stakeholder ask, “What does an event pattern mean to me? Is there a bottleneck forming downstream from me? What would a thunderstorm mean to my flights/fueling schedule/maintenance planning this afternoon? What should I do about it? Accept, modify, resolve/bid?”
At the airline level, FEDA has to have the capacity to aggregate traffic flow data to reflect the scope of flight operations relevant to the airline in a particular scenario. For example, a regional carrier such as Alaska Airlines might set its FEDA event processors to track air traffic flow through Mexico, Los Angeles, San Francisco, Portland, and Seattle, where a large number of its flights travel multiple times a day. An airline will inevitably have multiple points of control in FEDA, usually at the local airport level, but an airline should also be able to synchronize its FEDA event processors and drive traffic decisions across as many local points of control as it needs.
At the global level, the global processing tier shown in the figure, FEDA aggregates all event data, and stakeholder inputs—which themselves become events—processes them into usable pattern data, and then reflows that data back to the stakeholders as a new event stream. The stakeholders can then adjust their plans accordingly. In this way, FEDA is an event loop, constantly refreshing itself to provide stakeholders with the latest model of what is happening in their airspace and on the ground. From the individual stakeholder perspective, others’ actions contribute to my event pattern. My actions contribute to others’ actions—and then we engage in a feedback loop.
Globally, FEDA also performs analytics across multiple localities and stakeholders, discovering bottlenecks and their causes. Each FEDA event processor employs its own algorithms to investigate, model, and interpret the event stream it is presented with. FEDA would ship with certain algorithms out of the box, but there would also be a development kit to enable stakeholders to add new algorithms of their own or tweak existing ones. Ideally, FEDA would have a facility for sharing algorithms as Web services through a systemwide Universal Description, Discovery, and Integration (UDDI).
FEDA is a multitiered EDA, with each tier functioning as an event producer, event listener, and event processor to the extent that it is required. The local level produces event data, but also listens for new event data from the global FEDA event processors that have a systemwide view. The tiers are dependent on one another, though any tier can also receive event data that is wholly new. For example, a terrorist threat that shuts down all airports in the United States would be a new input at the global level flowing down the local tier. FEDA is also a complex, implicit EDA—implicit because it harvests event data from the ongoing operations of stakeholder systems.
Creating and running FEDA would be an extremely challenging job. On a technological level, FEDA is a highly complex architecture involving thousands of different systems administered by hundreds of separate stakeholders. The key to pulling it off is to drive functionality and adoption without tightly coupling stakeholders’ component systems. Some of the other key enabling technology factors include the following:
![]() Common data model—Although the component systems of FEDA, the systems that drive airline, airport, and support service operations, need not change to participate in FEDA, FEDA still needs to operate on a common data model. To make this work, FEDA needs to function using a broad set of standards-based data transformation capabilities. Event data produced by local systems using their native data model and format must flow into FEDA after being transformed into a FEDA-friendly data model. A key enabler of this would be a FEDA data dictionary that lets developers implement data transformation at the local deployment level.
Common data model—Although the component systems of FEDA, the systems that drive airline, airport, and support service operations, need not change to participate in FEDA, FEDA still needs to operate on a common data model. To make this work, FEDA needs to function using a broad set of standards-based data transformation capabilities. Event data produced by local systems using their native data model and format must flow into FEDA after being transformed into a FEDA-friendly data model. A key enabler of this would be a FEDA data dictionary that lets developers implement data transformation at the local deployment level.
![]() Agreement among stakeholders regarding event definition—For FEDA to work, the stakeholders must agree what constitutes an event. For example, capacity of a fueling service must be harvested from existing systems (or manually input)—in a way that is rendered uniform across the system, for example, 737s per hour, not litres per minute.
Agreement among stakeholders regarding event definition—For FEDA to work, the stakeholders must agree what constitutes an event. For example, capacity of a fueling service must be harvested from existing systems (or manually input)—in a way that is rendered uniform across the system, for example, 737s per hour, not litres per minute.
![]() Federated, standards-based messaging infrastructure—FEDA needs to transmit millions of messages among its thousands of constituent systems. To do this, it will require a standards-based messaging infrastructure. Given the current state of the industry, that will likely mean enterprise service buses (ESBs) from multiple vendors and open source providers. The ESBs need to be federated so that messages can flow freely and easily between event producers, listeners, and processors that are attached to the ESBs. Included in such a messaging infrastructure would be the following specifications:
Federated, standards-based messaging infrastructure—FEDA needs to transmit millions of messages among its thousands of constituent systems. To do this, it will require a standards-based messaging infrastructure. Given the current state of the industry, that will likely mean enterprise service buses (ESBs) from multiple vendors and open source providers. The ESBs need to be federated so that messages can flow freely and easily between event producers, listeners, and processors that are attached to the ESBs. Included in such a messaging infrastructure would be the following specifications:
![]() A standards-based message format, such as SOAP
A standards-based message format, such as SOAP
![]() Reliable, secure networks
Reliable, secure networks
![]() Mediation capability between divergent ESBs—ESB solutions from different sources do not necessarily share identical implementations of the standards. In addition, some of the networks that connect to FEDA will inevitably run different message transport protocols (for example, Java Message Service [JMS] and Hypertext Transfer Protocol [HTTP]). To work, FEDA must be able to mediate between these potentially incompatible systemic components.
Mediation capability between divergent ESBs—ESB solutions from different sources do not necessarily share identical implementations of the standards. In addition, some of the networks that connect to FEDA will inevitably run different message transport protocols (for example, Java Message Service [JMS] and Hypertext Transfer Protocol [HTTP]). To work, FEDA must be able to mediate between these potentially incompatible systemic components.
![]() Firm governance guidelines—The governance and administration of FEDA needs to accommodate the local and global requirements of the system itself as well as those of the stakeholders.
Firm governance guidelines—The governance and administration of FEDA needs to accommodate the local and global requirements of the system itself as well as those of the stakeholders.
As you might have noticed, there is an organizational aspect in each of these technological factors. Local and global control, federated message, agreement as to event definition, and so forth are all both technical and organizational in nature. We deal with the purely organizational issues later on in this chapter.
Being a complex, implicit EDA, FEDA brings together the output of numerous systemic components. As Figure 7.5 shows, even in a still simplified view, FEDA is a monster of architectural complexity. For each stakeholder, we have a set of core systems functioning as event producers through event Web services, an ESB(s), event listeners, event processors, and n-layers of integrated subsystems that feed their own event streams into ESB as well. Some of these stakeholders themselves might have immense enterprise architectures. For example, each airline would have global operations systems and airport local systems functioning as event producers. Ideally, stakeholders with such complex and multilayered systems would use ESBs and SOA for integration, simplifying the task of publishing event data to FEDA using SOAP XML.
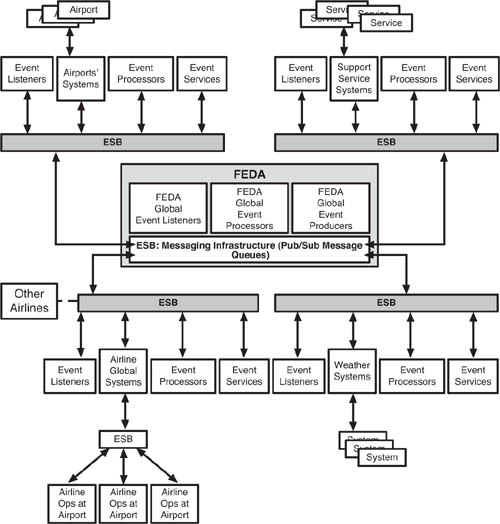
FEDA itself is based on an ESB model, which is set up to receive all stakeholder event stream data from their respective event Web services. FEDA functions as an event listener, event processor, and event producer, flowing event data back to stakeholder systems by publishing event data onto its ESBs. FEDA is also based on SOAP XML Web services for its messaging functions. It publishes its event stream back to the stakeholders using Web services to the ESB.
FEDA relies on ESB federation to function. SOAP messages published by a stakeholder must be able to travel freely from the originating event Web service through to any event listener Web service consumer on FEDA’s ESB. Going in the other direction, SOAP messages originating from FEDA’s event services (the updating loop) must be understandable at the event listeners’ resident on the stakeholder side. And, this mediation must be achieved without adding a sticky layer of integration on top of all of the other moving parts in FEDA. If that were the solution to the mediation issue, FEDA would become too costly and complex to manage.
For example, in Figure 7.6, let’s imagine that there is an event Web service on the airline side that publishes data about flight arrival times. The SOAP messages from that Web service originate from a .NET application and flows to an open source ESB over HTTP. The SOAP message is then routed to FEDA, and then through FEDA to an Oracle ESB for consumption by a J2EE Web service consumer on the support stakeholder systems. The message must be able to travel across these different SOAP implementations and transport protocols—in this case, from SOAP on HTTP to SOAP on JMS. As anyone involved in the SOA field knows, not all vendor platforms are identical when it comes to standards implementations. Some run SOAP 1.1, some run SOAP 1.2, and so on. It is an essential requirement that Web services providers and consumers operating on separate ESBs and platforms, as well as networks, be able to interoperate smoothly. Specialized solutions are typically needed to enable this functioning.
Figure 7.6 ESB mediation is a critical capability for FEDA. In this example, the event Web service on the airline side originates from a .NET application and flows to an open source ESB before being routed to FEDA, and then through FEDA to an Oracle ESB for consumption by a J2EE Web service consumer at the support stakeholder systems. The message must be able to travel across these different SOAP implementations and transport protocols—in this case, from SOAP on HTTP to SOAP on JMS.
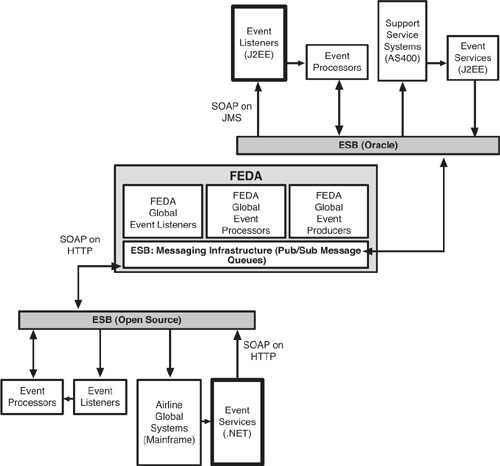
The data that flows to FEDA from the event producing Web services comes from underlying systems that were, in all likelihood, never designed with EDA in mind. In the example shown in Figure 7.6, the airline’s operational data about flights is generated from a mainframe computer running a COBOL application on CICS. The mainframe is exposed to the ESB as an event Web service using a Microsoft .NET application. FEDA, in turn, must receive data in a standardized form or the system will never work. As a result, each FEDA stakeholder must have the capability to transform its own system data into a form that FEDA can use and understand. In concrete terms, this means that FEDA must be sent SOAP XML messages that match an agreed-upon schema. This can happen in a number of ways, but typically, each stakeholder would utilize the data-transformation capabilities that came with their particular ESB and SOA platform.
For example, the airline’s mainframe might characterize a flight arrival time in the following way:

On the other end, at the support services, such as refueling, which need to plan their schedules based on flight schedules, the systems need to see data that will be understood by the following model:
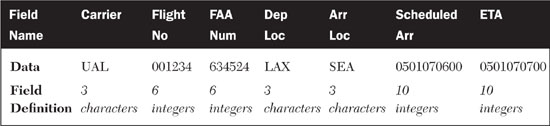
Let’s look at the differences in the data sets and data models. For the airline, the data is described in a format standard to mainframe systems. The airline knows who it is, so it doesn’t need to say, “United Flight 1234.” It just says FlightNumber=1234 and it knows what that means. The mainframe also knows what day it is, so it doesn’t have to keep track of the date in this particular data set.
FEDA, in turn, needs to receive the data about flight arrivals in a universally understandable, standardized form. It must be able to consume a SOAP XML message that contains the following data:

As you can see, FEDA modifies the data model for flight arrival time by splitting the carrier and flight number, and adding a separate FAA flight identification number that is standard across all carriers and airports. FEDA also has mostly different field names. FEDA isn’t trying to be difficult by picking different names for the same data—for example, “ArrLoc” instead of “Destination.” However, in addition to being an EDA, FEDA is an application connected to a database itself. The event processors and event producers that make FEDA work at the core need to have a working data model, and the one that FEDA’s designers pick needs to be enforced throughout the stakeholders.
To resolve discrepancies between data models and enforce its data model in a standard way across stakeholder systems—without affecting the way those systems work internally—FEDA’s designers need to define and publish a standard SOAP schema for use by stakeholders.
FEDA would share the schema it needed through a Web Services Description Language (WSDL) for the flight arrival event Web service. FEDA would direct stakeholders to the WSDL by pointing to it on the FEDA registry, or UDDI. To turn the published SOAP schema into a usable event Web service, the stakeholders would utilize several functions of their SOA platforms and ESBs. They would use the WSDL in their Web services development tools (e.g., Eclipse or Visual Studio) to expose their operational systems as event Web services. Because they were based on the WSDL and the SOAP schema it embodied, the event Web service would conform to the FEDA standard. In addition, the stakeholder would likely need to take advantage of the data-transformation capabilities of their ESB and SOA platforms to achieve the translation between the desired FEDA data model and their own native data model.
With the data-transformation layers of the ESBs involved, the body of a SOAP message communicating a flight’s arrival time would resemble the following, regardless of the data model used in the underlying systems:
<carrier>UAL</carrier>
<FlightNo>001234</FlightNo>
<FAANum>634524</FAANum>
<DepLoc> LAX </DepLoc>
< ArrLoc > SEA </ ArrLoc >
< ScheduledArr >0501070600</ ScheduledArr >
< ETA >0501070700</ ETA >
EDAs communicate changes in state. In the example we are working with, United Airlines Flight 1234 from Los Angeles to Seattle is an hour late. The hour delay is the change in state that FEDA needs to communicate to its stakeholders. The challenge, though, is to make such a state change understandable and actionable in a complex, implicit EDA that cuts across multiple stakeholders and systems. In a silo application, there is probably no need to communicate a complete set of data relating to state. In fact, it would be a waste of network bandwidth and developer resources. In the example, the United Airlines systems might communicate the delay of flight 1234 from 9 to 10 o’clock with an eight integer message that said, “12341000.” The systems involved, such as those of United’s local airport operations or payroll application, would understand, based on syntax, exactly what 12341000 meant. This is not a good setup for an EDA, however.
As we have noted earlier in the book, conventional application integration usually involves a high level of preconception from one system to another, resulting in tight coupling. If the payroll system at United is configured to understand what the message “12341000” means when it arrives from the airline’s operational system, that payroll system has to maintain a high level of preconception about the operational system. It has to know, for one thing, that the system represents United Airlines, and not any other. It has to know what day the operational system has in mind when it simply says 1000, for 10 o’clock. In this last instance, there might be a hard-coded calendar somewhere in the enterprise architecture that synchronizes all of United’s systems on a common time framework. The tight coupling results from the reality that an external system that wants to integrate with United’s operational system and payroll system would need to understand the condensed message syntax used to communicate changes in flight time as well as the tightly coupled time stamp involved. Although it would not be a superhuman challenge to integrate in this way, the costs and complexity of integrating a large number of airlines with comparable data models and high levels of preconception would be prohibitive.
If the messages about flight times only need to remain in the tightly coupled world of United Airlines, there is no problem. When other stakeholders need to know about state change, we run into trouble. The scheduling system for a fueling contractor at LAX might have no way of understanding what 12341000 meant. How would the system know it meant United Airlines flight #1234? How would they know what day the flight was arriving, and so on?
In a complex, implicit EDA, the messages that communicate changes in state need to contain complete information about the state change. In our example, instead of saying “12341000” to indicate that United Flight 1234 was an hour late, FEDA would need to receive, and transmit, the complete SOAP message shown above. The United systems that normally communicated “12341000,” would have to employ a data-transformation capability to fill in the blanks and transmit the complete SOAP message that detailed the name of the airline, the FAA number, the destination, and so on, to the other stakeholders as well as FEDA itself. It might help to think of this process as data enrichment as much as data transformation.
Because FEDA spans both a large group of separate stakeholders and a new set of technologies, the system requires two levels of governance. There is organizational governance, which manages how the system is used, who controls it, and so forth. We discuss that shortly. On a technological level, FEDA requires strong governance of the Web services and SOA that comprise its numerous component parts. The following section touches on the emerging specialization of SOA governance, which has achieved a certain prominence with the rise of Web services in the IT industry.
IT governance is nothing new, but Web services, with their universal accessibility and standards-based messaging, are so inherently chaotic and wild that they require a thorough and disciplined approach to governance. Simply put, SOA governance is the set of technologies, processes, and practices that provide assurance to system owners that the SOA is performing as it is intended to in terms of security and reliability. Of course, realizing this goal can involve some highly intricate patterns of implementation, but the objective should remain clear. To make FEDA, which is an EDA and an SOA, secure and reliable, it takes a strong governance solution.
SOA governance is a broad subject, one that could probably fill a book of its own. To keep the issue focused, we concentrate on the ways in which policies, or rules, for the SOA/EDA are defined and enforced. Policy is the essential ingredient for governance. In the context of SOA/EDA, you will typically hear policy referred to as Web services policy. For example, there is an emerging standard known as WS-Policy Metadata Exchange, or WS-MEX. WS-MEX is a standard for communicating governance policies that apply to Web services in an SOA or EDA.
Security and governance has a tendency to put new labels on old, familiar concepts. A policy is, in essence, a rule. Some policies are clearly identifiable as rules, as in access control or encryption policies that mandate adherence to a specific procedure. Other policies can be seen as rules implicitly. For example, a Quality of Service policy, or service-level agreement (SLA) might specify a threshold of acceptable performance for a Web service. The EDA can function if the SLA is not honored, but the policy stating the desired service level will have been broken. The trick in that case, of course, is to be aware of the SLA violation.
The work of SOA governance, then, involves the definition and enforcement of Web services policies. Definition of policies is a two-part process. At a high level, the stakeholders in the EDA—in our case, the people and organizations that come together to build FEDA—must decide which policies they want to define, and then flesh them out with specific policy detail. For example, FEDA’s governing body (more on this later) must decide whether they want to encrypt traffic on the EDA. Encryption might be desirable, as it would thwart possible eavesdropping by malicious parties. However, the desire for encryption would have to be balanced against its cost, complexity, and systemic performance drag. Is FEDA flight data as sensitive as health records? This is the kind of high-level policy definition decision that must be made. From this process comes a list of Web services policies that FEDA needs to define in detail.
Detailed policy definition involves adding meat to the basic policy required. If there is going to be encryption, what kind will it be? How will the keys be managed? Will all messages require encryption, or just those of a small set of FEDA component systems? Keep in mind, also, that policy definitions tend to change over time. Ideally, FEDA will have a dynamic policy definition capability, where policies can be modified as needed on a continuous basis.
After FEDA has defined its Web services policies for its SOA/EDA governance, it needs to enforce those policies. After all, it is meaningless to have a policy that cannot be enforced. It would be a waste of time, or even dangerous, to allow FEDA stakeholders to develop and deploy event Web services on FEDA that were not subject to the policies specified for governance. For example, if a FEDA event service lacked a failover capability, and the event service failed, then FEDA would be blind to the output of that event service. The result would be a great diminution of FEDA’s capacity to manage traffic flow. If such breakdowns occurred early in FEDA’s life, the whole system might appear flawed and fail to achieve broad adoption.
FEDA needs a way to make sure that the governance-related policies it has defined get enforced when the system is deployed. FEDA has to have a high level of confidence that the Web services that run on its ESBs and those of it stakeholders are running in accordance with stated policies. What this involves, typically, is the use of a dedicated software agent to enforce policy. We explore this in detail in the next section.
Finally, FEDA needs to have the ability to audit policy enforcement. For many reasons, ranging from practical management issues to compliance and risk management, FEDA has to be able to generate and examine high-integrity reports on its system usage and Web service policy enforcement. To continue with our previous example, if flight arrival time SOAP messages are required to be encrypted, FEDA needs to have an audit log that shows that each and every SOAP message was encrypted. The production of audit-worthy logs is the only way that FEDA will be sure that the policies it defines are being enforced to an acceptable level. Now, to answer the question that is surely (there she is again!) on your mind, how do you actually develop and deploy an EDA with these sophisticated governance capabilities? The answer is that you have to design governance right into the EDA itself, as part of the architecture.
Returning to the issue of SOA governance and infrastructure that we introduced at a high level in Chapter 5, “The SOA-EDA Connection,” let’s now see how these ideas connect with a practical EDA example. Figure 7.7 brings back the SOA governance and infrastructure reference model from Chapter 5, at least the bottom portion, which contains the SOA management solution, UDDI registry, and policy metadata repository.
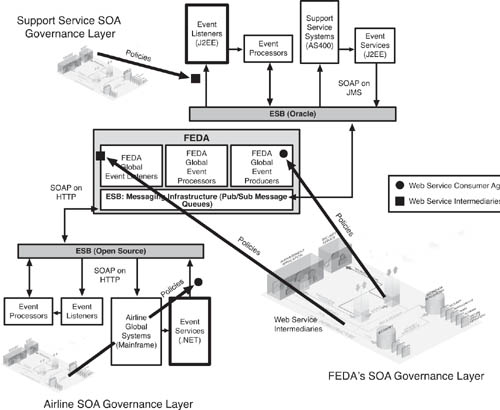
To refresh from Chapter 5, we govern the runtime SOA/EDA by defining policies and storing them in the policy metadata repository. As Web services are deployed, the policies that govern them are bound to them through their listings in the UDDI registry as metadata transported from the metadata repository. The standard used to make this binding of policy to the Web service is WS-Policy, which transmits policy metadata to and from the metadata repository in policy attachments. In practical terms, the registry and metadata repository might be tables in the same database running on the SOA management solution.
Actual policy enforcement at runtime comes from the provisioning of intermediaries that stand in front of the event Web services and agents that act as gateways for outbound SOAP requests emanating from the Web service consumers. The intermediaries and agents get their instructions from the Web services management solution, which itself gets its policy information from the registry and metadata repository.
For FEDA, there would ideally be one central registry and metadata repository to govern all the Web services that make up FEDA, whether or not they are actually part of the FEDA system itself. In reality, however, the individual stakeholders would probably have their own SOA governance infrastructure, registries, and metadata repositories. That is only logical because not every Web service existing in the enterprise architecture of a stakeholder would necessarily be connected with FEDA. The challenge in that situation would be to have some type of federated governance so that FEDA Web services policies could be defined and enforced for stakeholder Web services that touched FEDA. In particular, that might mean a federation of registries. Let’s look at our example and see what that means.
In our example, shown in Figure 7.6, the airline publishes a flight time though an event Web service (event producer) that is available through the airline’s ESB. From a governance perspective, the stakeholders will have a number of criteria by which they want to monitor and control their Web services, including security, reliability, and performance. Take access control, for example. The airline needs to (or should want to) control who has access to that event Web service. That access control is governed by the airline’s SOA governance layer, shown at the lower left of the diagram. The UDDI registry that lists the flight time event Web service and the policy metadata repository for that service are both controlled by the airline. The consumer of the flight time Web service is located within FEDA, and as such is governed by FEDA’s SOA governance layer, shown at the lower-right corner of the diagram. FEDA, in turn, publishes the flight data back out to other stakeholders, who themselves will have some type of SOA governance layer. The UDDI registries and metadata repositories need to be federated to work together providing uniform governance policy across the entire FEDA system. Let’s look at several other governance activities that will require UDDI federation.
Basic performance monitoring of Web services is a policy matter. In a critical system like FEDA, Web services must be managed for Quality of Service (QOS) or service-level agreement (SLA). For a call-and-response Web service, the SLA might stipulate the expected response time for an invocation of that Web service. The response time threshold is stored as a data point in the metadata repository and deployed to the intermediary that governs the Web service. If the Web service response fails to meet the service-level agreement, the intermediary will know this, and notify the SOA management solution that the SLA has been violated. Typically, an SLA violation will trigger a Simple Network Management Protocol (SNMP) alert to whatever system management console (for example, Tivoli Enterprise Console, Unicenter, Microsoft System Center, HP Openview). In this way, the QOS of Web services in a large, complex SOA/EDA like FEDA can be monitored by central system administrators.
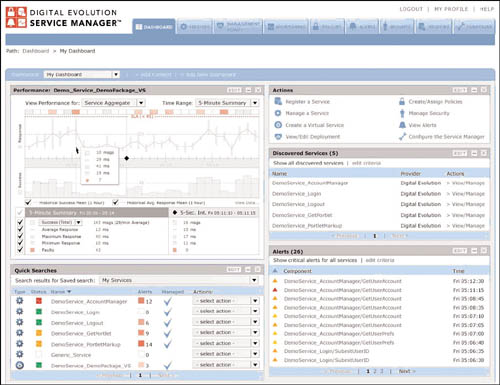
Figure 7.8 shows what a system administrator might actually see when monitoring Web services that are in production. This figure is taken from a real SOA management/governance product, the SOA Software Service Manager. (Disclosure: Two of us are affiliated with SOA Software, but we do not want you to think we are playing favorites. The console view shown in the figure is comparable to many similar solutions on the market today.) The console displays Web service performance metrics and charts whether the Web services are functioning within the service-level agreement. The console also highlights alerts and service discovery. The tabs for other functions of the solution allow for provisioning of intermediaries and programming of governance policies.
Figure 7.8 SOA Management Solution—This screen show shows a typical Web service management/SOA governance solution at work. The console provides a real-time view of Web performance and adherence and deviations from service-level agreements. At the lower right, alerts for service level and security issues are displayed for system administrators to see.
(Courtesy of SOA Software)
The flight time arrival Web service should have an SLA. The SLA for this service might include confirmation of message delivery to the ESB, response time, as well as a live/dead message for the Web service that is monitored by the SOA management solution and enterprise console. Many ESBs have a built-in feature for reliable and persistent messaging, so enforcing an SLA for message reliability might be automatic. The intermediary is programmed, through the metadata repository, to listen for the heartbeat and report in to the SOA management solution if the heartbeat flatlines.
Routing and protocol transformation are another area where policy enforcement is needed to ensure reliability and performance of Web services. As the SOAP messages travel across the three ESBs and platforms that make up FEDA and the stakeholders’ individual architectures, they must be transformed and controlled at each step. In addition to the data transformation we discussed earlier, the SOAP messages must be changed to travel on HTTP to JMS. They must be modified to be acceptable to an Oracle platform, having been generated on a .NET platform, each of which has minor discrepancies in standards implementation that require mediation. In addition, the three governance layers involved must achieve a mutual understanding of optimal routing, failover, load balancing, version control, and security.
Dozens of security parameters must be considered in this example, but in addition to access control, the owners of the stakeholder systems and of FEDA must think through nonrepudiation, audit logging, certificates, signatures, and keys, if encryption is an issue. With the kind of risks associated with airline traffic, including safety, liability, and terrorism, the stakeholders might want to opt for highly secure data transmissions, including signatures and encryption, so that no one can eavesdrop on message traffic or modify a message in transit.
Let’s go deeper and see how policy enforcement actually works. Figure 7.9 shows a simplified view of FEDA, but one that expands the view of Web service intermediary governing the flight arrival time event Web service. The intermediary consists of a pluggable pipeline architecture. As the SOAP messages travel from the Web service consumer, which is an event listener in FEDA, to the event Web service, located on the airline’s ESB, they are intercepted by the intermediary. The intermediary runs the SOAP message through a series of policy enforcement pipeline components.
Figure 7.9 Expanded view of the Web service intermediary, showing the pluggable pipeline architecture of the intermediary. There is a pipeline of policy enforcement components for both the Web service request and response. The policies that are enforced by the intermediary as well as the actual selection of pipeline components meant to be deployed are controlled by the SOA governance layer of the respective stakeholders. To work with FEDA, there must be federation between the governance layers, mostly their UDDIs and policy metadata repositories.
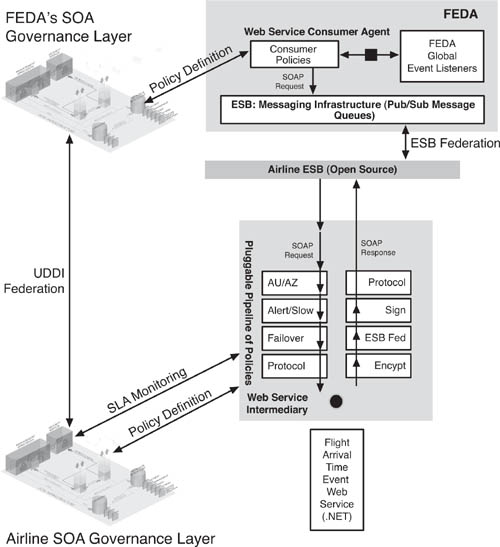
In the example shown in Figure 7.9, the inbound SOAP message goes through four pipeline components. In the first pipeline component, AU/AZ, the Web service consumer is authenticated and authorized. To accomplish this essential security step, the pipeline component in the intermediary reads the SOAP header and establishes the identity of the consumer. Then, by communicating with the SOA governance layer, which contains an access control list and identity store—or integration with those types of systems at the stakeholder level—it either clears the authorization and authentication of the consumer or rejects the SOAP request.
Then, the SOAP message passes through a pipeline component that monitors the performance of the Web service. The intermediary places a time stamp on the SOAP message, which is then used to track the response time of the Web service. Performance data flows back to the SOA governance layer from the intermediary, creating a performance log. The Web service performance data from the intermediary is used at the governance layer to issue an alert to system managers if the Web service is slow or not working at all. The intermediary’s pipeline on the inbound SOAP side also contains a failover component, which redirects the SOAP message to another instance of the Web service if the original one has failed. Finally, the pipeline flows the SOAP message through a protocol transformation step because the Web service that is being requested is on a different transport protocol from the Web service message that originated the SOAP request. The SOAP message changes as it moves through the pipeline. In this example, the SOAP message that emerges from the pipeline looks different from the one that entered the first pipeline component.
There is a pipeline of policy enforcement components for both the Web service request and response. There are pipeline components to process the inbound and outbound SOAP messages. They are not necessarily the same components, either. In some cases, there is a pipeline at the consumer agent as well, such as in situations where the SOAP request needed to be encrypted. What if it’s a one-way service, which simply publishes event data to the ESB without requiring a specific invocation? In that case, you can still define and enforce governance policies using an intermediary. The intermediary only has a one-way pipeline, though. For performance monitoring in a one-way situation, some SOA designers specify a “heartbeat,” where the Web service emits a standard, time-stamped SOAP message to the SOA governance layer at regular intervals. In that way, the governance layer knows if the Web service is down.
The policies that are enforced by the intermediary as well as the actual selection of pipeline components meant to be deployed are controlled by the SOA governance layer of the respective stakeholders. To work with FEDA, there must be federation between the governance layers, mostly their UDDIs and policy metadata repositories.
One point that’s worth making here is to highlight the utility of the SOA governance solutions. Each stakeholder in FEDA can have its own SOA governance solution for use in whatever Web service and SOA construct it wants. That same SOA governance solution can also be adapted for use by the EDA. There is no need to acquire a separate SOA infrastructure or governance solution to build an EDA or participate in an EDA. The standards make it possible. As long as the Web services used in the EDA and the governance solution used to manage them are based on standards, the stakeholder’s main SOA can be extended into an EDA with relatively modest effort and additional investment. Of course, getting to that first rung of the SOA governance ladder might take some time and money, but once there, the EDA possibilities present themselves.
It might seem as if we are going out of sequence by discussing runtime governance of our SOA/EDA first, and then describing the Web service life cycle. However, based on our experience, we believe that comprehensive SOA governance is a necessary requirement to implement before development of constituent Web services can be undertaken. Of course, you could develop your event Web services first, and figure out how to govern them later, and indeed many SOA/EDAs work this way, but it is far from optimal. Web services are inherently chaotic and open, so ideally they should be controlled very tightly at all stages of their life cycle. In FEDA, with its multiple, independent stakeholders, the need for strong governance is all the more crucial as each stakeholder develops and deploys Web services and exposes them to FEDA.
To illustrate the importance of governance to the Web service life cycle, let’s take a look at the life cycle of a completely ungoverned Web service. Of course, no serious IT professional would ever do such a thing, but the contrasts that become evident between governed and ungoverned Web services can be quite educational. If a developer at the airline in our example wanted to create a flight arrival time event Web service, he or she could do so using a number of Integrated Development Environments (IDEs) or tools that are generally available. For instance, he or she could use a Microsoft Visual Studio .NET or IBM’s Rational Eclipse based IDE and expose the program functionality of the airline’s flight scheduling system as a SOAP Web service. After generating a WSDL document that enabled any developer anywhere to create a consumer for the Web service, he or she could publish the Web service’s location on a publicly accessible UDDI.
In an ideal world, only FEDA stakeholders with legitimate business would create consumers for the flight arrival time event Web service and subscribe (listen) to its output. Each FEDA stakeholder who wanted to access this Web service would contact the owner of the service and make sure that the provisioning of the service would not overtax the infrastructure supporting the functioning of the service. If there were a performance problem, the stakeholder and Web service owner could be in touch and resolve the relevant issues. Alas, this is not how the world of IT works, even with the best of intentions.
You can get into several levels of trouble with an ungoverned Web service, or even a semigoverned one. In broad terms, they fall into two groups: security and performance trouble you can have as a result of planned connections with upstanding and well-intentioned professional colleagues, and security and performance trouble you can have from inadvertent dealings with bad or irresponsible strangers. We look first at the trouble you have with people with whom you want to connect.
If you simply publish a Web service without any governance, or with deficient governance, even legitimate users can cause showstopping security and performance problems. In terms of security, you would lack authentication and authorization, so you might be allowing access to the Web service to unauthorized people. Remember, a pure Web service is open to access through Port 80 on the firewall, so literally anyone can come in and use it. Even if you restrict access to the Web service to users from trusted domains, you still have little or no control over who is actually accessing the service. Web services are machine to machine in nature, so they don’t recognize human users without the help of a governance solution. The “user” of a Web service is another application. You might not care, but you should because not everyone should be allowed to access your Web service, even if they work for a trusted entity.
Ungoverned, you are also open to risks of repudiation. Without a certificate or auditable Web service transaction log, you are vulnerable to the accusation that your Web service did not deliver results for a request. Or, you might be unable to charge for the use of the Web service (if that is your arrangement) because you have no proof of the occurrence of an invocation of the Web service.
And, in the ungoverned SOA, the data you are transmitting to consumers of your Web services is vulnerable to eavesdropping and modification in midstream. Without a digital signature and/or encryption, you cannot prove that your SOAP message arrived at the consumer with integrity and confidentiality. Even while working with trusted partners, there is room for misunderstanding and conflict if there is little or no assurance of integrity and confidentially of message traffic.
In the realm of performance, the ungoverned Web service is vulnerable to a number of risks. If the provisioning of the Web service cannot be controlled, it is easy to run into a situation where the load on the Web service is unsustainable—a problem that can result in slow performance or even a crashing of the infrastructure supporting the service. In addition, if you have ungoverned Web services, they are highly vulnerable to outages caused by version changes or lack of failover. A complementary issue here is routing and protocol transformation. If the SOAP message needs to travel across networks that run on incompatible transport protocols, such as JMS and HTTP, the Web service might not work properly, or at all. Certainly, if the location of the consumer or Web service changes, there is a great risk of the connection being broken from this kind of problem.
So, with all of these security and performance problems evident even when working with trusted partners, imagine how severe the exposure to risk can be when confronting the idea of malicious users. In our age of threatened “digital warfare,” you could envision a lot of scenarios where people might want to wreck a system like FEDA. Overloading Web services, unauthorized access, compromised messages—all of these look a lot more disastrous when contemplating the actions of bad people.
The bottom line here is that you must develop your Web services with governance in mind. Or, to be more complete, the best practice to follow is to design and implement a comprehensive SOA governance solution before embarking on any Web service development. If you don’t, you are courting disaster. To put this into a practical framework, we want to introduce a concept now known as the “loop” of SOA governance.
Whether you realize it or not, when you develop and deploy Web services with an SOA governance solution, you are engaging in a loop of policy definition, policy enforcement, and audit. As shown in Figure 7.10, the activities of defining governance policies for a Web service at design time, enforcing them at runtime, and auditing whether the defined policies were actually enforced are all connected. Best practices dictate that you should want to enforce the governance policies that you define and that you should have a high-integrity audit log of Web service transactions to validate the enforcement of your policies.
Figure 7.10 The loop of SOA governance. Policies that are defined for a Web service at design time need to be enforced at runtime. The enforcement should be fully auditable, an outcome that is best ensured through the use of a “closed loop” of SOA governance, where design time, runtime, and audit are completely integrated.
(Courtesy of SOA Software)
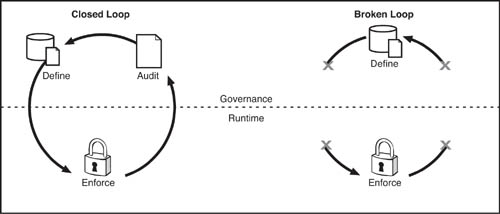
The optimal way to ensure enforcement and auditability of Web service/SOA governance policies that you define is to develop and deploy your Web services using a “closed-loop” approach to SOA governance. In a closed-loop SOA governance model, whatever policies you define for a Web service at design time are automatically enforced at runtime. The audit capability of the closed-loop SOA governance model (typically built into the SOA governance solution that is utilized) provides a record of the deployment and can ensure that policies are enforced as intended.
This might seem obvious, but practice shows that it is not always so evident. What a lot of IT professionals are discovering lately is that it is all well and good to define governance policies for Web services at design time. However, upon promoting those Web services to production, there is a risk of a drop-off in policy enforcement. A lot of smart people are actually working with a “broken loop” of SOA governance, whereby they “define and hope” that policies will be enforced. There is a surefire way to get to a closed loop, though, and that involves integrating design-time and runtime UDDIs, and their respective policy metadata repositories.
If you are curious about how this actually works, take a look at Figure 7.11, which shows a closed-loop SOA governance model in action. In this situation, Web services that are being developed are given defined governance policies that are stored in the design-time UDDI and policy metadata repository. When the Web service is put into production, the integrated runtime UDDI and policy metadata repository pick up those defined policies and enforce them. The integrated UDDIs enable the creation of an audit log that reports on the policy enforcement. Again, the standards of WS-Policy and WS-MEX make this possible. The trick, though, is for the integration of design-time and runtime UDDIs to be solid. Some solutions on the market today favor a metadata replication approach and this has a risk of disaggregation of policy metadata between design time and runtime.
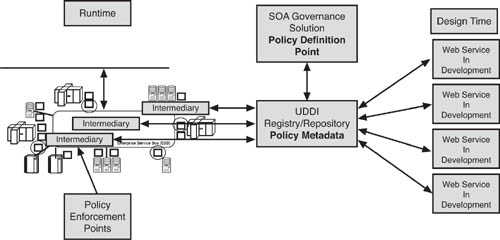
Now, we are going to assume that FEDA builds in a closed-loop SOA governance model, with integrated design-time and runtime UDDIs. In addition, we are going to assume that FEDA stakeholders will be required to federate their design-time and runtime UDDIs and metadata repositories with FEDA’s for the purpose of ensuring a closed loop. What this means, in our example, is that when the airline develops the flight arrival time event Web service, it defines the governance policies for it in a UDDI/repository that is integrated with the airline’s runtime UDDI/repository. The airline’s runtime UDDI/repository is, in turn, federated with FEDA’s runtime UDDI/repository. The intermediaries and agents that are deployed to enforce those policies are instructed by the federated UDDIs/repositories. As a result, there will be an assurance that the governance policies defined for the flight arrival time Web service will be enforced as desired, and that there will be an audit log available to prove it. As new Web services are rolled out across FEDA, the intermediaries and agents will be able to discover them and automatically bind them to runtime policies that have been specified at design time.
After all this, you might be thinking that this SOA governance stuff is a heck of a lot of overhead to deal with. And, you would be right, except that it is truly mission critical. As we have discussed, it would be irresponsible or downright self-destructive to compromise on governance. Keep in mind that FEDA will have hundreds or even thousands of stakeholders and potentially tens of thousands of Web services—there can be no expectation of stakeholders knowing each other or agreeing to work together. Even with good intentions, there is a lot of room for trouble unless governance is ironclad.
The good news here is that the parallel emergence of strong standards for governance and mature governance solutions makes this seemingly daunting task fairly livable. All the major platform players who would be the likely solution providers for FEDA’s working parts are aware of the criticality of governance through the full Web service life cycle, so you can have a high level of confidence that the platforms used for FEDA would contain governance features. Of course, you would have to know how to use them, and what the best practices include, to make it all work correctly. This chapter should give you an introduction to what’s involved. The complexity of governing FEDA at a technological level, though, is also a good segue to the even more nuanced issue of how the system should be governed by the people and organizations involved.
As you have read through the sophisticated and complex technologies required to attain a fully functioning FEDA, you might have wondered just how it was all going to happen on a human, organizational, and financial level. The truth is, succeeding with a project of FEDA’s size and scope is only partly a matter of technology. Even calling it a project is probably a misnomer. FEDA would likely be its own organization. In a basic sense, FEDA would be no different from any other large multistakeholder IT endeavor, with which the airline industry is already familiar. However, the nature of EDA and SOA bring some additional challenges to the realization of FEDA as an organizational success. The following section looks at some of the prominent risks associated with FEDA and some ideas on how those risks might be best mitigated. The goal is to achieve success with FEDA from design, launch, and sustained operation over the long term.
There are myriad risks to undertaking a massive IT initiative like FEDA. Not only does FEDA bring together a large collection of stakeholders who have not all collaborated before (if they had, FEDA might not be necessary), but FEDA also simultaneously introduces a variety of new technologies. For some stakeholders, FEDA might be the first time they are working with production-level Web services connecting outside their own enterprises. Some of the major risks include the following:
![]() Build it, and they won’t come—FEDA must have a high level of participation if it is to have a chance of success. If even a small number of major airlines balk and don’t participate, FEDA will fail. FEDA must have a high membership rate from as many stakeholders as possible.
Build it, and they won’t come—FEDA must have a high level of participation if it is to have a chance of success. If even a small number of major airlines balk and don’t participate, FEDA will fail. FEDA must have a high membership rate from as many stakeholders as possible.
![]() Build it, but it doesn’t work—This might seem obvious, but technological risk is a huge factor in the success or failure. At each stage of FEDA’s life cycle, technological performance is a nonnegotiable requirement. FEDA cannot fail and then be brought to proper functioning over time. It must launch in good working order.
Build it, but it doesn’t work—This might seem obvious, but technological risk is a huge factor in the success or failure. At each stage of FEDA’s life cycle, technological performance is a nonnegotiable requirement. FEDA cannot fail and then be brought to proper functioning over time. It must launch in good working order.
![]() Build it, but it is unmanageable—Organizational risk could be deadly to FEDA. With all the stakeholders involved, FEDA will depend on a strong organizational governance model and agreement among stakeholders about how the system will be managed, maintained, and modified. FEDA will need to have robust rules about stakeholder conduct, conflict resolution, Quality of Service, financial obligations, limitations of liability, and so forth. These rules need to be enforced through an organizational structure that all stakeholders accept.
Build it, but it is unmanageable—Organizational risk could be deadly to FEDA. With all the stakeholders involved, FEDA will depend on a strong organizational governance model and agreement among stakeholders about how the system will be managed, maintained, and modified. FEDA will need to have robust rules about stakeholder conduct, conflict resolution, Quality of Service, financial obligations, limitations of liability, and so forth. These rules need to be enforced through an organizational structure that all stakeholders accept.
![]() Build it, but it is insecure—A security breach could weaken the chance for FEDA’s success at launch or long-term viability. FEDA must be designed for security from start to finish, and have security standards and policies that stakeholders can embrace for the long haul.
Build it, but it is insecure—A security breach could weaken the chance for FEDA’s success at launch or long-term viability. FEDA must be designed for security from start to finish, and have security standards and policies that stakeholders can embrace for the long haul.
![]() Build it, they come, and then half of them leave—As they say in Hollywood, the only thing worse than a bad movie is half a bad movie. FEDA does not need the participation of every single stakeholder to succeed, but if a sizeable portion of airline traffic players opt out, the system will never attain its potential for utility. Defections of key stakeholders could turn into a stampede, ultimately ruining the system.
Build it, they come, and then half of them leave—As they say in Hollywood, the only thing worse than a bad movie is half a bad movie. FEDA does not need the participation of every single stakeholder to succeed, but if a sizeable portion of airline traffic players opt out, the system will never attain its potential for utility. Defections of key stakeholders could turn into a stampede, ultimately ruining the system.
![]() Build it, but go broke—Whether it’s excessive development costs or ongoing maintenance budgets that are too rich for stakeholders, financial risk threatens FEDA’s success. This is a multitiered risk. At the minimum, the project needs to be managed well enough to avoid financial surprises or cost overruns. On a more substantive level, though, FEDA needs to create financial value for stakeholders or it will be quickly abandoned. How much is too much to spend on FEDA? We will try to answer that question. Whatever the number is, though, FEDA must be worth it for stakeholders. A related risk to this problem is the potential for a single vendor to gain too much control over FEDA and start using its position to charge excessive fees for system maintenance.
Build it, but go broke—Whether it’s excessive development costs or ongoing maintenance budgets that are too rich for stakeholders, financial risk threatens FEDA’s success. This is a multitiered risk. At the minimum, the project needs to be managed well enough to avoid financial surprises or cost overruns. On a more substantive level, though, FEDA needs to create financial value for stakeholders or it will be quickly abandoned. How much is too much to spend on FEDA? We will try to answer that question. Whatever the number is, though, FEDA must be worth it for stakeholders. A related risk to this problem is the potential for a single vendor to gain too much control over FEDA and start using its position to charge excessive fees for system maintenance.
With these risks in mind, consider the following approaches to risk mitigation and ensuring success for FEDA. Let’s start with the organization of FEDA itself. In our view, an EDA of the magnitude of FEDA should comprise its own independent organization. Whatever its structure (corporation, partnership), FEDA needs to be able to make and enforce rules for stakeholders. A well-designed and properly managed organization can drive mitigation of almost every significant area of risk to the project, including technology risks.
Technology risks are, of course, based mostly on technical specifications and best practices, which we have outlined throughout this chapter. However, the realization of such specifications across multiple stakeholders is mostly a matter of organization and governance, not technology per se. FEDA might specify use of SOAP XML, but only a credible governing body can enforce use of the standard.
There are many possible styles of organization for FEDA, though three possibilities jump out as good candidates for running such a complex IT solution. One approach is to create an organization with a strong, respected leader. For example, there might be a retired airline president or Air Force General who can assume a mantle of leadership and bring the stakeholders to agreement and productive collaboration. Another workable approach is to develop a highly democratic organization with leadership shared across stakeholders based on their investment into FEDA. This approach requires good leadership as well, though it is less reliant on a star personality to make it all click. Yet another approach is to find a suitable industry organization that could sponsor FEDA and make it part of its larger organizational matrix. That would obviate the need to create a wholly new entity and infrastructure for FEDA, which might be appealing to the stakeholders.
FEDA’s organization need not be overly large or cumbersome. It needs a steering committee, for sure, to run the project itself, but also probably the organization as well. Under the steering committee, there should be a committee, or team, responsible for each of several key project areas, such as software development, architecture, standards, security, infrastructure, finance, rules, and stakeholder management. Ideally, representatives of major stakeholders would sit on relevant teams and the steering committee. One of the main goals here is to develop a system where stakeholders feel that they have a say, or at least have a chance to have a say, in how it all works.
As a mirror of the stakeholder organizations, the teams and steering committee should allow for participation of stakeholder employees from different levels of their respective organizations. The steering committee is a likely place to find executive representatives of stakeholder firms, while the teams would find a good fit for stakeholder developers and other IT pros, including vendors.
The FEDA organization will need a mechanism for agreeing on the rules of the system. We are not big advocates of needless bureaucracy, but as with so many other aspects of a project like this, with so many stakeholders, there has to be some kind of structured and enforceable governance. At a minimum, there should be some kind of “constitution” or bylaws for the way that FEDA is run, even if it is part of a larger organization. This agreement—it should have a legally enforceable dimension as well—should specify the rules of FEDA, the process of adopting new rules or changing existing ones, penalties for noncompliance, and so forth. The best approach would be to give the steering committee final say on the content of the constitution, with input from the subcommittees and leadership, representing the interests of the stakeholders.
Financially, FEDA needs to be self-sustaining. Running FEDA will not be cheap, so key stakeholders will have to be ready to contribute to its operating budget. Minor stakeholders should also be required to pay for access to FEDA, but on an equitable basis. One of the main functions of the steering committee will be to set budget levels and manage financial commitments from stakeholders. FEDA should also undergo an external audit to satisfy all stakeholders that their funds have been used appropriately.
FEDA will also need, in all likelihood, to have a number of full-time employees, supplemented by contractors. Whether or not FEDA has a high-profile industry executive at its helm, the FEDA organization needs an executive director and support staff. FEDA should have a chief architect, head of development, and head of infrastructure, all with supporting staff as needed. Though much of the day-to-day work of developing and running FEDA would probably be handled by vendors, FEDA would be well served by having a dedicated group of full-time people responsible to the organization and its stakeholders for implementation of their plans and rules and expenditure of funds.
One interesting aspect of FEDA governance that came out of our brainstorming was the need for an agreement among the stakeholders not to exploit FEDA for their individual commercial gain. Many FEDA stakeholders are fierce competitors and there might be a temptation to use data from FEDA to gain an unfair advantage in the marketplace. For example, an airline might use FEDA data to plan ways to throw delays at a competitor on a particular route, or publicize FEDA data to make a competitor look bad. All of these types of issues must be addressed.
Though FEDA is much more than just an IT project, the way that the design, development, and rollout of the system is managed, in project terms, can serve to mitigate many of the risks associated with the whole endeavor. At the beginning, the development of FEDA is a project, for sure, though in a broader organizational context. As such, it must be approached with all the rigor and best practices of a demanding enterprise IT project.
We all know about project management, so we will not belabor basic project steps here. Rather, we want to highlight certain aspects of FEDA that need special attention because of the nature of EDA. The newness of the technologies and the broad set of stakeholders make effective project management all the more critical and challenging.
As we go through some of the established project life cycle steps, keep in mind that the project itself will be sponsored by the kind of organization we have previously identified for FEDA. At a high level, best practices would dictate that FEDA’s initial rollout proceed according to a project life cycle that resembled the following:
1. Consensus Building
a. Agreement among stakeholders to pursue FEDA
b. Agreement to form FEDA organization and ratification of its makeup
c. Preproject training
2. Discovery
a. Technological audit of stakeholders
b. Stakeholder requirements gathering
c. Core FEDA requirements gathering
3. Drafting of Project Plan
a. Project life cycle outline
i. Pilot deliverables
iii. Stage 1 requirements
1. Core FEDA functionality
2. Stakeholder integration capabilities
3. New stakeholder on-ramping software kit
iv. Stage 2 requirements
1. Advanced analytics
2. Multilanguage UI capability
b. Assignment of responsibilities to individuals and vendors
c. Vendor RFIs and draft RFPs
d. Draft Enterprise Architecture Plan
i. Web services standards specifications
ii. SOA governance specifications
iii. SOA platform selection guidelines for stakeholders
e. Draft infrastructure requirements
f. Draft security plan
g. Draft training plan for stakeholders
4. Review and Discussion of Project Plan
5. Approval of Project Plan and RFPs
6. Solicitation of Vendor Bids
7. Review and Approval of Vendor Bids
8. Pilot Development
9. Review of Pilot and Modifications to Project Plan
10. Stage 1 Development
11. Beta Release and Review by Stakeholders and Core FEDA Team
12. Stage 1 Test
13. Stage 1 Deploy
14. Stage 2 Development, Test, Deploy
15. Annual Review and Follow-On Project Planning
One notable difference between FEDA and a conventional IT project can be found in the first step we suggest for the project. Before embarking on FEDA, there needs to be agreement among the stakeholders that the basic idea is a good idea, and that the suggested organizational structure will work. Then, there needs to be a training program to get stakeholders up to speed on what they are actually going to be doing. It would be a mistake to start writing a plan and RFPs without the ones paying the bills—and using the system—having a deep understanding of the EDA approach. As EDA matures, this step would become less critical. One aspect of consensus building that might need attention, too, is to present FEDA to stakeholders as a system they will own. The risk is that stakeholders will perceive FEDA as a vendor-driven sales pitch: a big budget that they want to get approved—this would be disastrous because it would cause all sorts of unnecessary tension and faults in the execution plan. The challenge is for the leadership of FEDA to assert the broad ownership of the project and assign roles to vendors without giving too much leverage to the vendors.
After consensus, we have discovery, which culminates with the creation of a thorough project plan for FEDA. This document should reflect the sum total of FEDA’s design, project milestones, and organizational guidelines. As the governing document of the project to design, develop, and implement FEDA, the project plan must be approved by FEDA’s governing body and reflect the intent of the project managers to honor the wishes of that governing body in technological, organizational, and financial terms.
The development cycle looks like a standard IT project, and it is not much different, except that there is a threshold of success in FEDA, or any multimember EDA, that is pretty high compared with most projects. It’s a new technology, a new paradigm, and multiple stakeholders all at once. Our recommendation in this kind of situation would be to invest deeply in piloting the idea and getting feedback and enabling broad learning at these early stages. The time spent on this approach early on can pay dividends later as the system goes live.
Returning to the original risk list, let’s see how the organization of FEDA can mitigate risks of many different kinds:
![]() Build it, and they won’t come—If the organization does its work of managing the expectations of stakeholders, ensuring fairness in organizational governance, technological neutrality, and financial responsibilities, the risk that FEDA will become an orphan is greatly reduced.
Build it, and they won’t come—If the organization does its work of managing the expectations of stakeholders, ensuring fairness in organizational governance, technological neutrality, and financial responsibilities, the risk that FEDA will become an orphan is greatly reduced.
![]() Build it, but it doesn’t work—By managing the project plan carefully and exercising sound oversight over the vendors and technology leads on FEDA, the organization can mitigate the risk of technological failure.
Build it, but it doesn’t work—By managing the project plan carefully and exercising sound oversight over the vendors and technology leads on FEDA, the organization can mitigate the risk of technological failure.
![]() Build it, but it is unmanageable—The organization can set the tone for manageability of FEDA, and it can also lay down specific rules, SLAs, and contractual terms to make FEDA manageable.
Build it, but it is unmanageable—The organization can set the tone for manageability of FEDA, and it can also lay down specific rules, SLAs, and contractual terms to make FEDA manageable.
![]() Build it, but it is insecure—If the organization takes its responsibility for setting security policy and standards, and creating a tone of seriousness and accountability about security, the security risk(s) can be mitigated. The organization should also provide external audits for security to assure stakeholders that FEDA is secure.
Build it, but it is insecure—If the organization takes its responsibility for setting security policy and standards, and creating a tone of seriousness and accountability about security, the security risk(s) can be mitigated. The organization should also provide external audits for security to assure stakeholders that FEDA is secure.
![]() Build it, they come, and then half of them leave—The organization has the power, if it chooses, to ensure the ongoing success of FEDA. This might be the greatest challenge of all—to provide a continuing basis for reliability, value, and fairness among all stakeholders.
Build it, they come, and then half of them leave—The organization has the power, if it chooses, to ensure the ongoing success of FEDA. This might be the greatest challenge of all—to provide a continuing basis for reliability, value, and fairness among all stakeholders.
![]() Build it, but go broke—The organization should endeavor, from the very beginning, to ensure financial responsibility and fairness into the design of the system and the structure and governance of the organization itself. By exercising fiscal responsibility, demonstrating value for stakeholders proactively (for example, showing value generation reports) and managing vendors effectively, FEDA can survive for the long haul in financial terms.
Build it, but go broke—The organization should endeavor, from the very beginning, to ensure financial responsibility and fairness into the design of the system and the structure and governance of the organization itself. By exercising fiscal responsibility, demonstrating value for stakeholders proactively (for example, showing value generation reports) and managing vendors effectively, FEDA can survive for the long haul in financial terms.
In each case, it is the organization that has the power to mitigate the risk, even if the risk itself it not organizational in nature. Technological, security, and financial risks need to be looked at through the lens of organization. Only the organization can provide the important human dimension of mitigating these risks and ensuring success for FEDA.
Before work can begin on even the most preliminary aspects of creating FEDA, the leadership of the organization must have a deep understanding of the reasons why FEDA should exist. FEDA is meant to solve a set of problems. For FEDA to make sense to its backers, any charter for a FEDA organization, and any project plan or vision statement, needs to identify how FEDA will solve those problems. And, although it might be generally understood that FEDA is intended to alleviate airline traffic congestion, the best-practices approach to undertaking such a large IT endeavor dictates that the plan for FEDA include specific success metrics.
FEDA’s plan should contain a set of quantitative objectives that FEDA can help realize. These objectives might include a reduction in delayed flights, a savings of fuel used in taxiing, improved customer satisfaction ratings, a decrease in crew overtime, and so on. The reason why it is essential that such objectives be defined at the outset, and built into any organizational and project plan, is that FEDA is a costly program, and it must make economic sense to its stakeholders.
It is hard to put a dollar figure on FEDA, but the kind of work we envision for it would probably put the total cost for first year and launch in the range of 50 million dollars, with an ongoing commitment of perhaps 10 million dollars per year. That is a lot of money, especially for financially pinched airlines. FEDA needs to justify itself, first at the beginning, but then on a continual basis.
The good news is that the savings are not that difficult to identify. For example, the airline industry in the United States alone consumes over $30 billion in fuel. If FEDA can help realize even a 1% decrease in fuel consumption through improved efficiency of traffic flow and reduced airliner waiting times, that’s a $300,000,000 savings for the stakeholders! The key, though, is to embed these success metrics into the fabric of the complete work of creating FEDA and its sponsoring organization.
Success with FEDA means overcoming myriad challenges and executing well on a highly complex technological and organizational plan. We could only touch on a few of the high-level issues in this chapter. However, we hope that you take away at least one significant concept for program success with a large-scale EDA: the completeness of vision required for success.
Delivering a successful FEDA involves the realization of an idea that spans technology, organization, and finance. FEDA is more than the sum of its parts. It is an advanced technology, but it is also more than that. It is a sophisticated multistakeholder organization, but also more than just people. It exists for financial reasons, but money is merely a metric for FEDA, not its sole reason for existing.
The key to success lies in leadership. In this case, and so many others that you might encounter in your work, a complex event-driven architecture brings together many people, technologies, and agendas. Only very solid leadership at the individual, team, and organizational level can ensure success throughout. To undertake FEDA without being sure of the leadership involved would be to court problems and expose the program to undue risk. On the other hand, with capable leadership in all critical areas, FEDA can develop and prosper over the long term, regardless of the challenges and risks it faces.
![]() The challenge of managing airline traffic flow presents a great opportunity to explore how an EDA can help solve a complex real-world problem with multiple stakeholders. With thousands of flights a day operating in the United States, disruptions to air traffic caused by weather, for example, can create very costly delays to airlines through a ripple effect where a disruption at one airport causes backlogs of flights in other cities and cascading delays that can take hours or even days to clear up. With fuel costs now so high, even modest improvements in flight traffic efficiency can be financially very rewarding for airlines.
The challenge of managing airline traffic flow presents a great opportunity to explore how an EDA can help solve a complex real-world problem with multiple stakeholders. With thousands of flights a day operating in the United States, disruptions to air traffic caused by weather, for example, can create very costly delays to airlines through a ripple effect where a disruption at one airport causes backlogs of flights in other cities and cascading delays that can take hours or even days to clear up. With fuel costs now so high, even modest improvements in flight traffic efficiency can be financially very rewarding for airlines.
![]() An event-driven architecture is a good candidate for solving the air traffic management problem because the problem itself is composed of multiple sets of events that originate in separate entities and are tracked by separate information systems. If one common system could have knowledge of the many different event streams that create air traffic congestion—weather, flight delays, mechanical problems, and so forth—and that knowledge could be accessed by all stakeholders easily, then the worst kinds of disruption could be avoided.
An event-driven architecture is a good candidate for solving the air traffic management problem because the problem itself is composed of multiple sets of events that originate in separate entities and are tracked by separate information systems. If one common system could have knowledge of the many different event streams that create air traffic congestion—weather, flight delays, mechanical problems, and so forth—and that knowledge could be accessed by all stakeholders easily, then the worst kinds of disruption could be avoided.
![]() This chapter sets up a hypothetical project called FEDA, or Flight EDA, which would gather all event streams needed to provide stakeholders with information they could use to manage flight operations. In this chapter, we take the perspective of those who would be responsible for creating FEDA, and examine the high-level requirements and realistic issues that would arise in the development of such a system.
This chapter sets up a hypothetical project called FEDA, or Flight EDA, which would gather all event streams needed to provide stakeholders with information they could use to manage flight operations. In this chapter, we take the perspective of those who would be responsible for creating FEDA, and examine the high-level requirements and realistic issues that would arise in the development of such a system.
![]() The goal of FEDA is to create real-time awareness of flight conditions that can be used both by airline personnel, the FAA, and flight support services, as well as by the information systems of each stakeholder group. It would need to be able to respond to flight traffic situations both autonomically and through human decision making.
The goal of FEDA is to create real-time awareness of flight conditions that can be used both by airline personnel, the FAA, and flight support services, as well as by the information systems of each stakeholder group. It would need to be able to respond to flight traffic situations both autonomically and through human decision making.
![]() In functional terms, FEDA would need to be highly extensible, allowing for adaptation and use by unknown stakeholders. It would need to enable modeling of what-if scenarios for users and contain a capability for stakeholders to conduct trades of flight schedules. Of course, it would need to be highly reliable and scalable.
In functional terms, FEDA would need to be highly extensible, allowing for adaptation and use by unknown stakeholders. It would need to enable modeling of what-if scenarios for users and contain a capability for stakeholders to conduct trades of flight schedules. Of course, it would need to be highly reliable and scalable.
![]() FEDA would expose applications used by each stakeholder as SOAP Web services and surface them through ESBs. The FEDA system would consume these flight information Web services through event listeners, process the event information, and publish the information back to stakeholders in aggregated and digested forms. FEDA would be an event processing loop, where stakeholders could change event parameters in real time and thus reiterate the event overview for all to see.
FEDA would expose applications used by each stakeholder as SOAP Web services and surface them through ESBs. The FEDA system would consume these flight information Web services through event listeners, process the event information, and publish the information back to stakeholders in aggregated and digested forms. FEDA would be an event processing loop, where stakeholders could change event parameters in real time and thus reiterate the event overview for all to see.
![]() One of the most critical aspects of developing FEDA is the resolution of SOA governance issues. For FEDA to function, it must provide a high level of control over access and integrity of the Web services it consumes. At the same time, FEDA’s governance must be flexible enough so as not to impede system adoption and expansion. One possible approach is to deploy intermediaries that authenticate and authorize the Web service consumers based on a central SOA governance policy registry. In addition, FEDA needs to have ESB federation capabilities, as it will inevitably be exposing and consuming Web services on ESBs and SOA platforms from multiple vendors. All must work together seamlessly to make FEDA a success.
One of the most critical aspects of developing FEDA is the resolution of SOA governance issues. For FEDA to function, it must provide a high level of control over access and integrity of the Web services it consumes. At the same time, FEDA’s governance must be flexible enough so as not to impede system adoption and expansion. One possible approach is to deploy intermediaries that authenticate and authorize the Web service consumers based on a central SOA governance policy registry. In addition, FEDA needs to have ESB federation capabilities, as it will inevitably be exposing and consuming Web services on ESBs and SOA platforms from multiple vendors. All must work together seamlessly to make FEDA a success.