
Jerry Seinfeld does a routine where he wonders how mankind discovered that glue can be made from horses. He describes a scene where someone is trying unsuccessfully to stick two pieces of paper together, when, suddenly a horse rides by, causing an instant revelation of potential... “Hey, wait a minute!” he imagines the brilliant inventor saying. “How come I never thought of that before?” So it is, too, in IT. Sometimes, trends of technological innovation exist in parallel for a period of time before someone realizes that they can be put to work together, for a greater effect than either one on its own. There are some great examples of this from the history of technology, including the merging of recording technology and the telephone (creating the answering machine), the joining of the QWERTY keyboard with the cathode ray tube and the CPU (the modern computer), or the phone with the computer (networked computing).
Today, we are witnessing the parallel maturing of event-driven architecture (EDA) and productivity infrastructure, two separate, but potentially synergetic information technologies. Each is powerful in its own right, but together, they can create transcendent event-driven information processing environments. This chapter explores the potential integration of EDA with productivity infrastructure. In particular, we focus on the ways that productivity infrastructure empowers the human thinking and decision making that is often implicit in the process flow of an EDA.
![]() Understanding productivity infrastructure and its potential for integration with EDA
Understanding productivity infrastructure and its potential for integration with EDA
![]() Understanding the potential for enhancing the human decision-making capability within EDA through the integration of productivity infrastructure
Understanding the potential for enhancing the human decision-making capability within EDA through the integration of productivity infrastructure
![]() Connecting business process models from structured to unstructured process steps, spanning back-end systems and productivity tools, such as e-mail
Connecting business process models from structured to unstructured process steps, spanning back-end systems and productivity tools, such as e-mail
![]() Understanding approaches to determining a target architecture for EDA-productivity infrastructure integration
Understanding approaches to determining a target architecture for EDA-productivity infrastructure integration
As we have seen throughout this book, there are many instances where the corporate “nervous system” of EDA loops through a human decision-making process. In the airline traffic case, it was the flight operations managers who were called upon to make critical decisions about flight prioritization based on input from the EDA. In the anti–money laundering case, bank fraud staff were fed information about suspicious transactions for their review and decision on actions. This EDA-human connection makes sense much of the time. Indeed, there is often no substitute for a person, and his or her awareness of multiple influencing factors, in a business decision-making process. Artificial intelligence is suitable in some cases to make or support human decisions, but even in cases where decision making can be automated, there is frequently the need for a person to take responsibility for the decision. Alas, there is still no way to hold a computer accountable for the consequences of a decision that causes an airliner to crash or money to be stolen from a bank account. Given the inevitable presence of people in EDA-based decision process flows, one of the big challenges is relative inefficiency of human decision making.
Unlike computers, people are extraordinarily inefficient at decision making and are, in fact, quite high maintenance. Whereas a computer can execute a decision algorithm at any time within a fraction of a second, people need to be present (awake and focused) to make a specific decision at a specific time. This is not efficient, and in some cases, might be harmful to the business process that the EDA is meant to serve. And, in many cases, people need to make decisions in groups, a situation where the inefficiency of communication compounds the delay and quality of the decision. For example, if the air traffic EDA enables rapid decisions about prioritizing flight departure times, but the key decision maker needs to consult with a superior, who is out to lunch, the whole process could be delayed to the point where it compromises the whole intent of the system.
In other cases, people might need to access external sources of information to make decisions that feed into an EDA decision-making process. The bank antifraud staffer might have to review scanned document images to compare signatures on old checks before making a judgment call about whether to escalate a fraud investigation or notify law enforcement. This type of manual, or semimanual, process can cause harmful inefficiency for the EDA. In this instance, the antifraud staffer might have to manually write down the name of the suspected account, exit the EDA interface, open a records management application, and conduct a search for matching documents. After manually reviewing the documents, he or she might have to share the findings with other antifraud staffers or document review specialists before making a decision to escalate the case. Such a discussion could involve a combination of e-mail, phone, fax, or instant messaging. None of this is particularly horrible, but the cumulative effect of faults in the communication and manual process flows—spread out across multiple concurrent fraud cases—can result in a significant drag on performance and suboptimal antifraud efforts. The solution to these types of challenges is known broadly as productivity infrastructure, and it is maturing today at a rapid rate.
Productivity infrastructure (PI) is an umbrella term to describe people’s and organization’s increasingly connected and synergistic use of phone, e-mail, Internet, PDA, intranet, extranet, and desktop productivity applications. What was once a collection of essentially siloed productivity technologies and workflows—phone calls, e-mails, searching the Web, creating documents, using a PDA, and so on—are now merging into a combined infrastructure that drives personal and organizational productivity. In brand-name terms, productivity infrastructure is integrating the functionality of product sets such as Microsoft’s Office System, Cisco’s VOIP solutions, IBM’s Lotus suite, and Google’s Docs and gMail services, just to name a few.
To understand the importance and impact of productivity infrastructure, let’s use the creation of a sales proposal as a baseline example of the kind of unstructured type of workflow that typically challenges information workers to be productive. In contrast to structured tasks, such as those performed by customer service agents at a call center, a great deal of business work today involves unstructured tasks, which are unpredictable in terms of workflow step order, location of needed information, and stakeholder identities, roles, and responsibilities. In the case of creating a sales proposal, a number of different approval patterns, issues to be resolved, and decision makers might be involved at any given time. The processes, people, and underlying data and documents required to create the sales proposal might change from case to case. Though the process will contain the basic flow shown in Figure 9.1, in reality each situation will be slightly different. Managing this subjectivity within a tight time frame is the essence of productivity infrastructure.
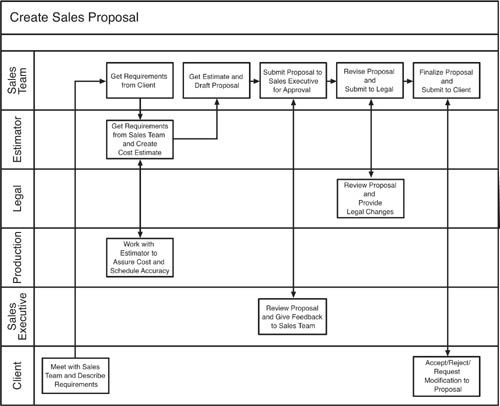
Each step in the creation of the sales proposal, as shown in Figure 9.1, involves multiple people, often from different work teams, in the sharing of information, documents, and knowledge. The more efficiently the people involved in completing this multistep, multiplayer process can get their work done, the better off the organization will be in productivity terms. The impetus behind the development of productivity infrastructure is the drive to enable workers in unstructured information work to get more done in less time, with less expenditure of resources.
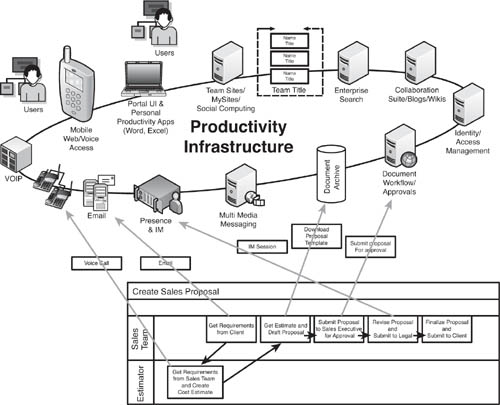
As Figure 9.2 shows, the steps in the sales proposal development process map to capabilities in the productivity infrastructure. In this example, VOIP technology speeds up the process of connecting the customer with the sales rep by automatically connecting a landline call to a mobile device. All participants in the process use e-mail to communicate, with relevant stakeholders able to share links to document repositories where proposal templates and other data are stored for common use. A portal user interface (UI) links stakeholders to the workflow management process as well as collaboration sites that contain blogs and wikis that publish up-to-date information needed for crafting the proposal. Social computing technologies like MySpace, FaceBook, and LinkedIn allow individuals to understand connections between stakeholders that might not be apparent through job titles or task assignments. Team sites enable stakeholders to make sure that their proposal is in alignment with team objectives and business goals, or clarify approvals required for the proposal. The real-time instant messaging or Web conferencing facilitates rapid resolution of open issues for the proposal.
Figure 9.2 Productivity infrastructure, which links workflow, collaboration, e-mail, phone, mobile, document repositories, and Web 2.0 technologies, such as blogs, wikis, mysites, and social computing, can drive efficiencies in the unstructured, multiplayer, iterative process flow required to create a sales proposal.
If everyone involved in creating the sales proposal were sitting in the same room at all times, then there would be no reason for the investment in productivity infrastructure. In fact, that’s how business worked until about 1890, when the telephone started to move people away from physical proximity to their business partners. Today, of course, the groups of people involved in getting business done are almost never all together, and certainly not in any reliable pattern or schedule that will allow them to get time-sensitive tasks done. And today, as we often find, it’s not just being able to communicate with others in a collaborative process that makes things flow smoothly. To get the tasks accomplished, each participant needs to know who the other players are, who they report to, what their priorities are. On top of all that, participants also often need access to information that is not easily located without the assistance of others in the group. To make access to needed information available without requiring time-consuming conversations or e-mails, participants need to be able to search for and find what they are looking for on their own.
Productivity infrastructure has the potential to drive more efficient workflows for unstructured tasks, assuming it is implemented properly. The time cycle for completing the entire process flow for creating a sales proposal, for example, becomes shorter with good productivity infrastructure, and the time investment of each participant goes down as well. Ideally, the accuracy and quality of the final product improves as an added bonus. However, productivity infrastructure can be complex to deploy, as it can raise some challenging security, compliance, and interoperability concerns. We mention this here just to assure you that we are not all starry-eyed about the ease of deploying such a comprehensive and interconnected infrastructure, and neither should you be. Nevertheless, we do believe that productivity infrastructure, once in place, can be leveraged further using EDA.
To see the potential for benefits of integrating EDA with PI, we should think about the advantages of linking the corporate nervous system of EDA with the comparable organizational nervous system of PI. With EDA, corporate systems can detect changes in state that affect business. Wherever the EDA needs human input, PI can speed up the EDA’s reaction time to the state change. PI can also improve the quality of the human input because it can link people with data sources, and each other, with high efficiency. Ultimately, there is the potential for the creation of loops of interaction between EDA and PI, where state changes noticed by the EDA elicit reactions from people though the PI, who, in turn, input their own changes of state to the EDA.
As shown in Figure 9.3, the integration of productivity infrastructure and EDA can be understood by considering a simple business process model that involves inputs from two enterprise systems that must be evaluated by people. Event Web services on applications A and B publish data about their state to the enterprise service bus (ESB), and on to an application built using a Business Process Modeling (BPM) tool. The process model calls for people to assess the data presented by the states of applications A and B, and for them to make a decision about what the states mean, and then take action either by instructing application C or terminating the process without taking action. The PI is designed to notify the decision makers of the change in state. After the decision is made, the reaction to the change in state flows back to the EDA through an event Web service located in the PI.
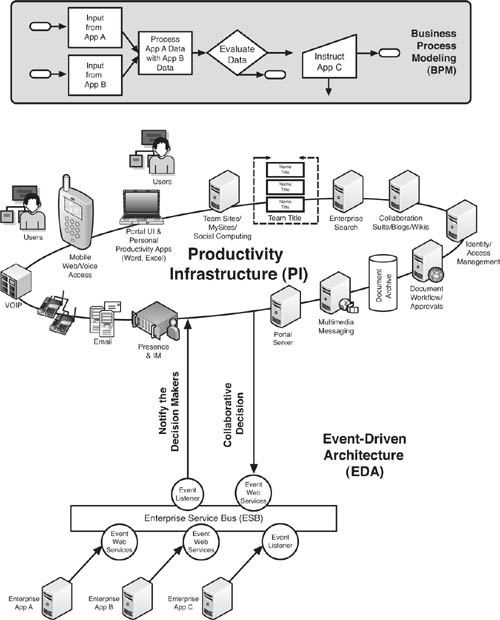
If there were just one person who could make the decision called for in the process, off the top of his or her head, there wouldn’t be much need for the kind of elaborate setup called for in Figure 9.3. However, let’s suppose that the decision being made in the process flow is complex, high risk, multistakeholder, and time sensitive. Imagine, for example, that it involves the decision to manufacture goods with costly inventory. The decision could have impact on financial statements, factory capacity, even labor unions, hence the decision to proceed could be a collaborative decision. In that kind of situation, a tight integration between the decision makers and the EDA could have a real impact on the business.
In the case of a manufacturer setting inventory levels, the time required to make a decision—the right decision, that is—is highly relevant to business success. If the manufacturer guesses wrong, and either overstocks an item whose product life is on the decline, or understocks a hot seller, the financial results will be less than optimal. In another example, preparation for a hurricane takes the coordinated effort of many disparate government agencies, safety personnel, health-care institutions, and so on. Because lives depend on the speed and accuracy of these efforts, you can see it’s extremely important that these efforts are in sync and in constant communication of state changes. In these kinds of situations, even the difference of an hour or two, or the lack of a few critical nuggets of business data, can have an impact on the overall objective of saving lives or protecting the bottom line. Imagine, for instance, if you decided to order a truckload of component parts for the manufacture of a product that was later determined to be unneeded. It might not be the end of the world, but it would create an accounting and logistical hassle to return the order. Multiply this type of problem across a large, global company, and the effect on earnings could reach into millions of dollars of direct and indirect costs. Consider, for example, the necessity of engaging accounting staff unnecessarily due to faulty decision making.
In addition to offering a shorter decision cycle time, the integrated EDA-PI approach has the potential to enable a higher quality of decision than the current state of integration between PI and enterprise systems. Keeping in mind with this example that we are dealing here with decisions that cannot be automated through rules engines, consider the factors that affect the quality of decision making among multiple stakeholders. In our view, the quality of a decision depends on the financial and human consequences of the decision. The decision that saves lives and saves money is the best one. Of course, there is a range of quality decisions between best and worst, but the goal should be to strive for the best decision in the largest number of cases. This concept is known as the “decision yield.”1
As anyone who has worked in a large, distributed organization could tell you, the quality of a decision depends on multiple interdependent factors, including knowledge of who the stakeholders are for a particular decision, equal simultaneous access to information, and equal understanding of information. Quality of decision making also depends on a productive engagement of stakeholders inside an organizational hierarchy. The higher level stakeholder might have the ability to overrule the correct decision through innate power, and the smarter subordinate might not have, or want, the opportunity to oppose the incorrect decision. Of course, productivity infrastructure cannot help an organization overcome this hierarchical flaw in process on its own. However, by providing open access to shared opinions and corporate knowledge, and real-time access to multiple points of view, the hierarchy effect can be mitigated in favor of discussion and group learning.
Integrating EDA and PI can improve the efficiency and quality of the information provided to workers who are tasked with making business decisions. Ultimately, this can result in reductions in overhead or increased utilization of staff for strategic business purposes. We felt this point was worth making because we have heard many dialogues about the value of service-oriented architecture (SOA) and EDA that make the assumption that there is a high-efficiency analysis apparatus available to parse the output of these systems. This is not necessarily so, and indeed, a lot of approaches to SOA dead-end into an empty seat called “stakeholders” and fail to generate good return on investment (ROI) as a result.
The productivity infrastructure itself can function as an event producer as well. A simple example might be an event announcing the presence of a stakeholder or that a new sales lead has been detected. Another example, which touches on an exciting new area of PI, is the concept of “active search” within the enterprise and its potential to function as an event producer from within the PI.
Figure 9.4 depicts an enterprise search solution allowing a productivity infrastructure to function as an event producer. To see how this works, we must first understand the process of an enterprise search solution, which is an increasingly common fixture in today’s enterprises. Like a Web search engine, the enterprise search solution contains three core elements: a query server, an index server, and “crawlers,” which read through documents and other data sources and feed their findings into the index server. The enterprise search index, like their corollaries in the Web search world, is a massive and exhaustive directory of information located within the enterprise. The enterprise search solution operates by taking queries from end users through a front-end UI (e.g., a search box in a portal interface), sending the queries through the query server to the index, and returning matching results back to the end user through the UI.
Figure 9.4 Active search involves the use of an enterprise search solution, which “crawls” repositories of unstructured data, indexes them, and then sends RSS feeds in response to preset search queries. The RSS feeds, which function to indicate the presence of specific information in unstructured data, can serve as event producers.
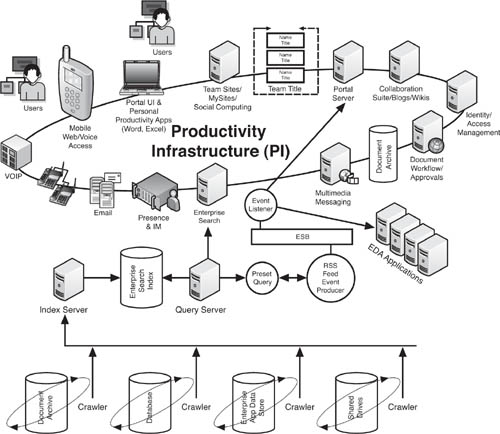
Some enterprise search solutions offer the ability to conduct active search, a process wherein certain queries are stored and continually rerun, with the search results being published to end users through RSS (Real Simple Syndication, a form of Extensible Markup Language [XML]). So, for example, an end user in a real estate development firm could use an enterprise search solution to query the company’s internal document libraries for data that matches the keyword of a particular neighborhood. If the user types “Chelsea” into the search box on the portal UI, that query will return any documents or other indexed data files that contain the word “Chelsea,” and the user could then learn about projects or people involving Chelsea. In an active search mode, the user could store the “Chelsea” search and instruct the search solution to issue him an RSS feed every day that contained the latest search results for “Chelsea” without the user having to run the query every day himself.
From an EDA perspective, it is possible to imagine how this active search function could turn into an event producer. The stored query, and resulting RSS feed, could be designed to publish changes in state that exist within unstructured data environments. In our real estate example, the query might feed into an algorithm that determines whether specific people or company divisions are working in Chelsea, a change in state that could drive action through the EDA. A customer relationship management (CRM) system attached to the EDA could flag the activity in Chelsea, based on the event data published through the enterprise search solution and PI, for follow-up by account executives in the neighborhood.
There is even the potential for EDA and PI to interoperate as looping, connected halves of a bigger EDA. Events published out through the EDA inform stakeholders and drive action through the PI, which, in turn, publishes back event data about stakeholder activities, presence, and data creation through the PI. Admittedly, this level of sophistication is fairly futuristic, even for this forward-looking book. However, we believe the potential for productivity improvements and information worker empowerment through the integration of EDA and PI are powerful and promising.
To see how EDA and PI could be integrated, we will use the example of a custom manufacturing business. To optimize the learning experience, we are going to keep the example fairly simple and focus on the aspects of this hypothetical business that are most general to all businesses. This company, which we call ProdCo, could stand in for a mass of businesses that perform custom services on a job-by-job basis. Within ProdCo, we focus on the sales proposal and order fulfillment process to highlight the potential EDA-PI integration.
The sales and fulfillment process at ProdCo is touched by a group of teams and individual stakeholders. To get a proposal out to a client and then fulfill the order, the Sales, Marketing, Production, Legal, Finance, and C-Suite executives need to be involved. Sales, of course, is the main point of contact with the client. Marketing engages in the process to assist with pricing and discount programs that might be tied to particular campaigns. Finance is involved to ensure that the pricing and costing of the job are appropriate, and that the HR aspects of the job are properly considered. Finance also weighs in with sourcing decisions and execution. Production is responsible for actually doing the work. The C-Suite has oversight, especially if the job is large or strategically significant.
Figure 9.5 shows the essential flow for ProdCo’s proposal-fulfillment-assessment process. The sales team drafts the proposal and circulates it through reviews by Legal, Production, Finance, and the C-Suite. If there are revisions, the review cycle might repeat in whole or part. After the client approves the proposal, the job goes into production, and is fulfilled. Finance becomes involved again for sourcing of materials and overseeing labor expenses, as well as invoicing and collection. At the end of the process flow, the Finance Department publishes the results of the job—if it made or lost money compared with the estimate—and all other departments receive this information and update their own knowledge bases. Or not...
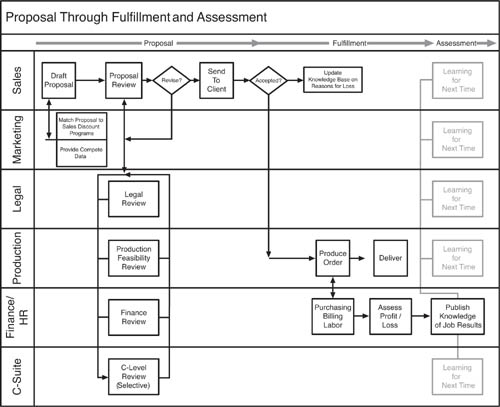
There are a couple of design flaws in this process, though to be fair to ProdCo, it’s about as good as it can be given the current state of technology. For one thing, the review loops for the proposal might be a lot more complicated and subjective than any process model can approximate. And, the assumption that the process flow makes is that everyone has access to relevant information on a timely basis. The Marketing Department might not know, for example, that certain types of projects lose money, so they ought to be dropped from the discount plan, and so forth. Most problematic, though, is that the process is very inefficient. The people and groups involved in this process waste time managing and finding the information they need to get the process finished as well as communicating with one another. A closer look at the way ProdCo has set up its productivity software and enterprise architecture can reveal some of the causes of this inefficiency.
Figure 9.6 shows how ProdCo has set up its productivity tools and enterprise applications. The Sales and Marketing teams have access to the CRM system, while Finance and Production use the enterprise resource planning (ERP) solution. Collaboration inside each team, and between teams, is a fairly ad hoc affair, with stakeholders e-mailing files back and forth and saving them on departmental shared drives that each team can access through a portal interface. It is possible for a non–team member to access a portal, but that person must first be granted access rights by a departmental administrator. Each team portal has calendaring capabilities, and everyone is able to schedule meetings using the e-mail suite. The C-Suite executives use a business intelligence dashboard that is fed by the finance staff because it does not tie directly into the ERP system.
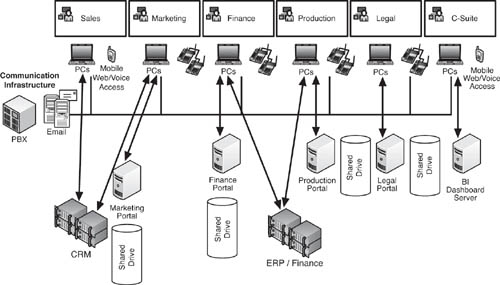
ProdCo’s productivity solutions and enterprise applications are too siloed to be highly efficient. There is no efficient way to share information or documents across the entire company—at least in a way that does not open access to the document to every single employee, which nobody wants. Connections between systems are haphazard or nonexistent. So, for example, there is no way to seamlessly import the terms of a sales proposal into the ERP system. It must be reentered when the order goes into production. Approvals on each phase of a proposal, and its subsequent production phase, are conducted by e-mail and phone. The ERP system does have automated approval functions, where executives can sign off on purchase orders, overtime schedules, and so forth. However, the problem is that these approvers must often communicate with others, such as the Legal Department, before proceeding. The efficiency of the automated approval function is mitigated by the slow, unstructured process of human-to-human communication within the firm. And, there is no way to keep track of recurring patterns of unstructured workflow that could save time in the future.
For example, imagine that certain types of orders require materials to be sourced from Mexico. The procurement staff has learned from experience that in the summer months, the heat inside the trucks coming from Mexico is so intense that it can ruin the parts in transit. They know now either to order these parts in advance, or actually pay for a refrigerated truck. Of course, this is more expensive, though paying the expense is preferable to delays and missing parts. However, the procurement staff has no way to keep this relevant fact in front of all stakeholders at all times. The ERP system has a “notes” section, where the procurement staff can write down a reminder to order a refrigerated truck with that SKU. Yet, when the sales team wants to make a deal, or the Marketing Department wants to create a discount campaign, they do so without realizing that their margin is lower than normal on the item that includes the Mexican components. The C-Suite, too, might lack visibility into the issue, and wonder why margins are low on this type of product.
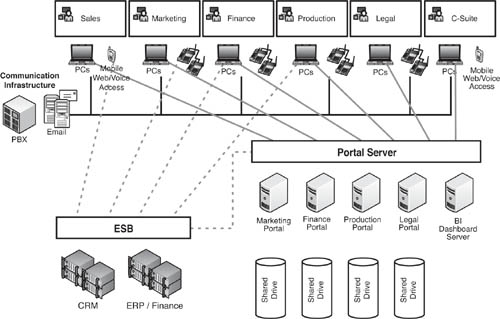
Being wise and forward-looking, ProdCo has decided to invest in shifting its architecture toward SOA and EDA. Figure 9.7 shows how this would work. ProdCo would install an enterprise service bus as an integration layer that exposes the functionality of both the CRM and ERP systems as sets of Web services. A portal server would provide access to the various department portals and also make certain CRM and ERP functions are available to users who didn’t have access to either the CRM or ERP client. The departmental portals themselves would remain essentially untouched, though their provisioning could now be centrally controlled and extension of existing portals could be governed more thoroughly than before. Communications would remain a silo.
Figure 9.7 ProdCo is considering a move toward an SOA and EDA, where the CRM and ERP/Finance applications would be exposed as Web services through the enterprise service bus. The departmental portals would be accessed through a central portal server, though their content and administration would remain essentially siloed. The communication infrastructure would remain unchanged.
To appreciate how the EDA approach would work for ProdCo, let’s look at a small part of the production process, the ordering of supplies based on a bill of materials. Figure 9.8 shows the flow for the bill of materials (BOM) process as well as the matchup between the process steps and the Web services enabled in the EDA. Certain steps, though, such as selecting the winning bids from the RFQ, are still human processes and cannot be fully automated. Other steps, such as requesting procurement, might be semiautomated, wherein the ERP system does all the work once a person has approved the request for RFQ.
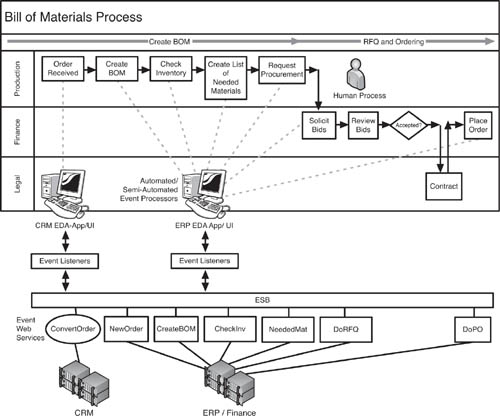
As shown in Figure 9.8, the bill of materials process consists of several automated/semiautomated steps that work off the event Web services, as well as a few that are completely human. Sales proposals exist in the CRM system, but when a customer makes the decision to buy, under the new EDA approach, the CRM system’s ConvertOrder Web service publishes the state change of the proposal from “Pending” to “Accepted.” The event listener in the ERP EDA application receives this state change information and, in reaction, takes the order data from the CRM system and transfers it to the ERP system. This step could be fully automated, meaning it could occur simply because of programmatic instruction, or it could be semiautomated, where a person gets a signal through the UI that the order is ready to convert and the human action of clicking a button on the interface actually completes the transfer from CRM to ERP systems.
The process flow then follows a series of event-triggered service steps. The ConvertOrder Web service in the CRM system results in the creation of a new order for production in the ERP system. The NewOrder Web service publishes that its state is “New,” which is listened to by the CreateBOM (Create Bill of Materials) Web service. The Web services CheckInv (check inventory) and NeededMat (Needed Materials) create a list of materials that are needed for the job but which are not in stock. The DoRFQ Web service is activated by the NeededMat Web service’s publishing of its change of state (from Nothing to List). Each of these Web services can be invoked manually or through an automated process.
Sending the RFQs out to vendors, though, is a manual step even if the actual work is done by the system. A procurement person ensures that the RFQ goes to suppliers who are appropriate for the materials needed. However, even this could be a fully automated process that reacts to the event of DoRFQ by generating a Request For Quote electronically and sending it to preapproved vendors through e-mail or online notification calling them to a vendor portal.
Assuming the EDA is implemented correctly, it provides numerous advantages to ProdCo’s operations. It renders the back end more flexible than a conventionally architected system. The EDA makes it simpler, faster, and cheaper to implement changes in the process flow for RFQs, and enables streamlined reporting and aggregation of data for consolidation of purchase orders and vendor management.
However, the human decision elements of the process flow are not much affected by the EDA. The act of soliciting bids from vendors is still either wholly or partly human, as is the selection of winning bids. It would be possible to automate both of those processes, though, and even include some fairly sophisticated rules sets to ensure best practices in procurement. Taking the human beings out of the picture for selecting vendors, for example, might occur if ProdCo could implement a set of business rules that awarded contracts to vendors with the lowest price, the best ranking for quality from production operations, and a consistent track record of on-time delivery. If this automation were implemented, the bill of materials process could proceed seamlessly without the messiness and delay of human actions. This area provides another great opportunity for ProdCo to expand its EDA innovation.
Returning to our example of goods from Mexico that melt in hot trucks in the Arizona sun (and we’re not making this up, either; it happened to one of us), we can see that there are still instances where there is a need for subjective human knowledge to get to the best possible business result from a process flow, even with an advanced EDA in place. And, this is where the efficiency of ProdCo’s EDA starts to falter.
As the automated, or semiautomated process of converting an order from proposal to sale, and the derivative bill of materials/RFQ steps cascade out from the entry of the sale into the ERP system, we still dead-end at a person—or group—that needs to decide which vendors get to bid on the order. In the best-case scenario, the vendor selection is done by an experienced person who understands all the subjective issues involved and acts promptly and decisively. In a less-rewarding scenario, the decision is made by a distributed group of people who might individually lack the knowledge of the subjective challenges to getting an optimal procurement accomplished. There are many scenarios in between, such as an inexperienced procurement person who cannot process the vendor selection quickly due to lack of information, or one who makes the wrong decisions based on lack of knowledge, or even a lack of awareness that certain types of knowledge are required to make the decision. In this situation, we see the promotion of the person who knows that one must request a refrigerated truck from Mexico, and his or her replacement being a person who doesn’t have any idea that such a problem exists. The new person will proceed, with the best of intentions, to repeat a mistake that has long since been solved.
There are several aspects to this poor quality decision cycle. If the communication process that connects the people in the decision loop is detached from the EDA and procurement interfaces, the communication itself risks being inefficient and inaccurate. For example, imagine that the vendor selection process is dependent on people reading long e-mail threads from the bottom up, assessing the situation, and making recommendations. (Surely, we’ve all been there...) This communication pattern is less than ideal for rendering a consistent, rapid set of correct decisions. However, because of the subjective nature of most unstructured processes, such as selecting a vendor using group knowledge as the basis for the decision, e-mail threading is probably unavoidable. At the very least, it is clumsy and unreliable. Even if everyone involved is paying attention and very well informed, the process could bog down if one or more participants is unreachable (or unfindable)—to the extent that production orders could back up because of communication breakdowns in the procurement process.
ProdCo’s EDA also lacks the capacity to store organizational knowledge. The specialized knowledge about the subtleties of procurement is not stored in a fashion where stakeholders can easily find or use the information. One enterprising person might create a procurement best-practices document that he or she can use, and perhaps even share with others. But, if that document is lost on a shared network drive, its contents might never reach other stakeholders who need it. If the creator of the document moves on, the document will likely disappear. A dedicated and well-managed procurement team could also create an intranet site on the portal server for collection of practices and settling of decision issues. This approach has some benefits over a totally uncoordinated procurement method, but it might still result in time lags and communication mistakes if the stakeholders still need to toggle back and forth between their intranet team site, e-mail, and the actual ERP system to make and implement decisions. At the very least, it is a largely unrepeatable pattern.
The integration of ProdCo’s productivity infrastructure with its EDA is a major contributor to solving this dilemma, where lost knowledge, lack of knowledge, and poor communication mitigates the positive impact of an EDA and improvement business process management. PI integration cannot solve this problem all by itself, of course. There are myriad challenges related to training, knowledge preservation, best-practices documentation, and so forth, that are required to ensure good human decision cycles in a process flow. However, the chances of ProdCo attaining the best human decisions in the EDA environment are greatly enhanced by the integration of the EDA and the PI. Without this integration, the likelihood that ProdCo will optimize the organizational impact of the EDA is slight.
We might be displaying some hubris by characterizing EDA/PI integration as a better proposal. The truth is, it’s a very new area and still quite theoretical. However, as we go through the potentialities of EDA/PI integration in the ProdCo case, we believe you will see some exciting possibilities for improving the way work gets done in practical terms, hence be able to apply these principles elsewhere.
Unstructured tasks, such as procurement staffers rounding up best-practices data from diverse stakeholders, tend to be messy and unpredictable. Given that reality, it is challenging to design any kind of technological solution that will consistently solve the problem and make the unstructured tasks faster, simpler, and cheaper to execute. In fact, there really isn’t much in the way of standard language or practice to even describe the kind of problems that IT solutions need to solve for unstructured tasks. For this reason, we are going to attempt to work backwards from identification of unstructured task problems, to causes that can be remedied by EDA/PI integration, and build a solution approach from there.
First, what problems does ProdCo face with procurement, and which can be traced back to inefficient unstructured tasks and poor EDA integration? Wasting of time ranks high on the list because slower procurement typically translates into slower production. Then there is the loss of knowledge over time, which can result in slow procurement or other costly errors in production. Then, there are just plain mistakes made through poor communication or inadequate decision-making processes.
Backing out of these problems, we can get to a set of business objectives for the integrated EDA/PI. ProdCo needs to have rapid procurement that is accurate. They need high quality and consistent knowledge transfer as team members move in and out of roles. And, they need transparent, well-documented decision processes that result in accurate, timely procurement without imposing an undue administrative burden. This last point is relevant because it is nearly always possible to cure a process by larding it up with many onerous administrative tasks and parameters. The net effect, though, is usually counter to the goal of efficiency. Getting the right process in place without choking the team members with bureaucracy is a fine balancing act.
In Figure 9.9, we see how productivity infrastructure can help ProdCo’s procurement staff collaborate with one another, as well as other groups, share knowledge, and communicate efficiently in the fulfillment of the RFQ process. In the early steps of the process, from “Order Received” through “Create List of Needed Materials,” the procurement staff is notified of changes in order status and impending RFQ workflow. The specific mechanism of notification could vary, though it would probably be an e-mail alert or a change in an order status screen on the intranet. As the procurement staff needs to solicit and review bids, they can use the team sites and search features of the PI to find expertise that might rest with individuals throughout the company. In our example, if the procurement staffer searched for the name of the product that gets shipped from Mexico, he or she might be directed to a wiki or blog that communicates the salient details of shipment in hot weather that would enable even an inexperienced procurement staffer to avoid the problem that has plagued others. Once that kind of knowledge is extant and searchable, it is harder for the organization to lose. The Web 2.0 type of features that allow individual users to create their own material easily—but also securely—is an underpinning of successful PI. Ultimately, the EDA can be extended to facilitate these types of investigatory searches simply by connecting the NeededMat (Needed Materials) event producer with the PI search.
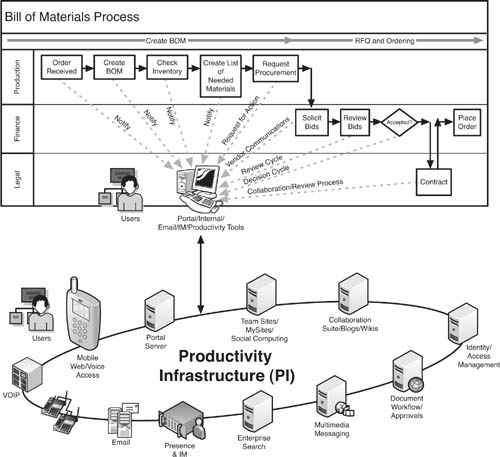
Stakeholders in the process can work on documents, such as contracts and RFQs, in a virtual collaboration environment and document management system. Throughout the process is communication, pervasive and real-time, through e-mail, phone, mobile devices, IM, and Web meetings. The net effect of this sophisticated PI is a faster procurement cycle with greater sharing of knowledge in real time and preservation of knowledge. PI has the potential to help ProdCo realize its business objective of rapid, accurate procurement.
You might imagine, based on robust productivity functionality shown in Figure 9.9, that even without integration of the underlying enterprise EDA applications, you would be ahead of the game. Having solid connectivity between stakeholders in real time, and streamlined access to documents and knowledge is a big boost to productivity, even without tight integration with ERP and CRM. However, as you start to tie sets of systems together, the benefits become striking.
What will it take to integrate ProdCo’s PI and EDA? To keep it simple and focused, so we can learn, we look at the functional requirements for EDA/PI integration as they relate to the procurement example only. The following are the requirements that would drive improved productivity in the procurement process through connection between the underlying EDA-enabled ERP and CRM applications and the productivity infrastructure. In keeping with our custom in this book, we also assign this hypothetical project a name. We are considering integrating ProdCo’s PI with its EDA, so the name PIEDA fits well. It sounds a bit like a geek fraternity, which in a sense, it is.
One of the first requirements that the PIEDA team will have to figure out is the interface. There are two basic choices: Integrate the productivity tools into the EDA-enabled ERP and CRM applications, or surface the ERP and CRM applications through the productivity infrastructure tools. Both options require the use of application programming interfaces (APIs) and custom tooling for implementation, though neither requires creating interfaces wholly from scratch. The major productivity suites are available with APIs and development kits that enable integration of interfaces and routing and transformation of messaging to and from enterprise systems.
The first option, which is shown in Figure 9.10, puts the EDA-enabled ERP app into the same UI as e-mail, document archive, search, and a team site with RSS feeds. In this kind of unified dashboard, the procurement staffer can work on specific RFQs and have a view of his or her e-mail, relevant documents, and team updates without leaving the ERP app. In the second option, the ERP app might appear as a sidebar in the e-mail client, for example. The best practice for this entire issue might be to do some research first, consulting the end users and showing them the mock-ups to get input on how they prefer to work before committing to one approach or another.
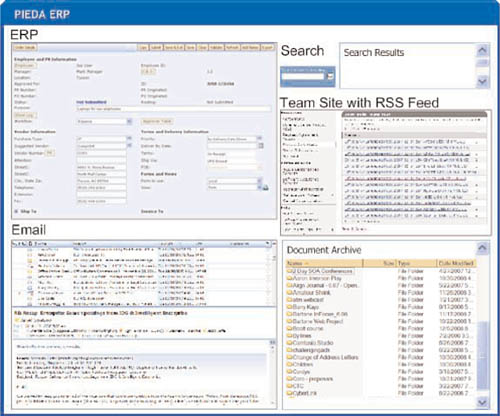
As shown in Figure 9.10, one of the most basic features of PIEDA is the ability to automate notification of procurement process status changes to stakeholders. When an order is received from the CRM system, the end user is notified, perhaps through an IM or RSS alert. Same thing when the “Create BOM” process is executed in the ERP system—the procurement person is notified, and so forth, through Check Inventory, and Create List of Needed Materials. This real-time (or rapid) notification of end users of changes in state in the EDA serves to prompt action on the part of the end user. For example, if the procurement staffer is alerted that an order is going into the “Check Inventory” state, then he or she can consult the team site for background information on this type of order and be ready to handle the vendor selection right away. In this way, PIEDA connects the enterprise nervous system of EDA right to the human thought processes necessary for completion of the process flow.
Following the process flow shown in Figure 9.9, the next requirement for PIEDA we need to address is the request for action that occurs when the process reaches the “Request Procurement” stage. When the bill of materials has been generated, and the inventory checked, and the list of needed materials drawn, the procurement is now ready to begin. PIEDA will alert the procurement staffer that he or she needs to create an RFQ and solicit bids. At first, this would probably be an e-mail that requests that action be taken. To make the process efficient, though, the e-mail should contain an embedded link that will take the end user to exactly the right screen in the ERP app where the RFQ can commence. If the end user simply receives an e-mail notifying him that he needs to go to the ERP system and start an RFQ, and making him look it up (perhaps by copying and pasting a job number into a search field), we have not accomplished very much in terms of efficiency.
This innate linking from e-mail, blog entries, IM texts, and documents through to the actual job page on the ERP system is an essential requirement to make PIEDA worth the effort and expense.
As the RFQ and bids go through the review loops, PIEDA needs to keep decision makers close to each other and to the related documents. The ERP app needs to show the presence of stakeholders so that all the people involved in the process can connect with one another—either through IM, e-mail, phone, or by looking up information that was authored by a particular person or team. In other words, if a procurement staffer receives an alert that he must review a draft of an RFQ, the draft of the document should appear in the same interface as the alert. Then, the draft should show the presence of its authors, with their availability for IM, e-mail, or phone instantly visible. Alternatively, a user should be able to link on the mysite, teamsite, or blog of any document author or group of authors to learn more about what they know about the procurement process.
It should be possible in PIEDA to conduct a search through the documents, blogs, wikis, teamsites, mysites, and ERP business data to find relevant information about the procurement, or the project itself. Through an enterprise search interface, and back-end enterprise search engine, the end user needs to be able to look up any missing information about the procurement. In our example, if the procurement staffer searches for the component that needs to be shipped in a refrigerated truck, he or she should see the pertinent notes about shipment in the search results—or at the very least, get a search result that points to documents that contain the needed information.
A more sophisticated version of the enterprise search scenario described previously involves including people in the search results. If the end user conducts a search for the bill-of-materials components, the search results could contain both a list of documents related to the components as well as the authors, including their presence and knowledge contributions to the organization. That way, if a procurement staffer cannot find exactly what he is looking for, he can click on the results of a people search and connect to expertise either live or through a published knowledge contribution such as a blog or wiki.
Business intelligence (BI) should be a requirement for PIEDA. Though not perhaps a drop-dead necessity, BI gives stakeholders the ability to analyze data and create reports that lead to organizational knowledge. For example, it might not be known that a certain component gets destroyed by heat in transit. If a procurement staffer ran a report on job orders that exceeded planned costs, he or she might notice that certain types of orders that contained a specific component (which melted in transit) all resulted in poor financial results for their respective orders. Of course, such BI functionality already exists in many ERP systems. The challenge for PIEDA is to make it available to users automatically, through the portal front end of the productivity infrastructure. This availability helps expose the knowledge potential of the business intelligence. And, going further, with RSS feeds and subscriptions, it becomes possible to alert people of new knowledge without the receivers of the knowledge needing to know in advance to look for it. Finally, with an EDA-PI connection, the RSS feed itself becomes an event with the potential to trigger action.
The collaborative workflow for document creation needs to manifest through PIEDA. As end users create documents and revise them, they must be able to see who has contributed to the drafts and be aware of their presence if they need to contact them. The document management functions of PIEDA need to be able to route documents along approval paths, allowing for final approvers to be aware that drafts have been created for their review. The ability to set up an instant online Web meeting or conference call to review a document in real time should be built into PIEDA.
Bottom line, PIEDA needs to provide users with real-time (or near-real-time) access and awareness about events that occur in the ERP and CRM systems. PIEDA needs to give users access to the people who create documents and data inputs to the system. The goal is streamlined, rapid decision making that results in the best possible decisions. PIEDA needs to stimulate the creation and distribution of knowledge in an effortless manner. Users need to find or receive knowledge passively.
Having outlined PIEDA’s functional requirements, the challenge now is to relate them to a target architecture for the development of a working EDA. After all, the goal of PIEDA is to reduce the amount of random and unstructured communication between people as they manage the information in the CRM and ERP systems. Doing this means connecting events in those systems to automated and semiautomated actions in the productivity infrastructure. The first step in this process is to understand how the functional requirements map to events in the overall architecture.
Figure 9.11 shows a target architecture for PIEDA. Notable is the contrast to earlier EDA examples we have explored, which have one area of event processing. PIEDA has three. There are events produced, listened for, and processed at the level of the CRM and ERP systems, shown as Area C in the figure. In addition, the productivity infrastructure itself has a whole event processing setup, shown as Area A in the figure. This is an interesting discovery for anyone getting under the hood of a productivity suite: It has many event-driven features right out of the box. Whether you’re dealing with Microsoft SharePoint and Office, IBM Lotus, or others, you will find a handsome complement of event processing going on inside the application suite. For example, SharePoint has numerous automated notifications of document draft changes and blog posts, and so forth.
Figure 9.11 Target architecture for PIEDA, showing three separate areas of event processing: The CRM and ERP systems cycle event data between themselves (Area C), as does the productivity infrastructure (Area A). PIEDA (Area B) listens for event data from both, and produces its own events. All three event processing areas listen for each other’s events.
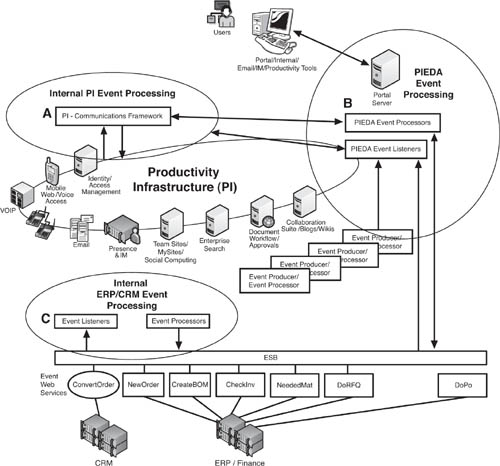
The third area of event processing—Area B—is PIEDA’s actual integration between areas A and C. As depicted in Figure 9.11, PIEDA’s event processing area is contained within the portal server. However, it need not be. We have approached PIEDA as if it were going to be developed using standard APIs built into the portal server. When undertaking a project such as PIEDA, many different alternatives might, in fact, be more attractive. For example, it might make the most sense to build PIEDA on top of the ERP-CRM service bus or develop it on its own stand-alone application server. The bottom line, though, is it will have to be built. At this time, there is no out-of-the-box solution for the kind of functionality envisioned for PIEDA.
Figure 9.11 is a rather complicated picture. However, PIEDA’s beauty is that Areas A and C can operate quite well on their own, even if you take out B, the PIEDA event processing center. PIEDA is an incremental upgrade to the architecture, and the event processing capabilities of the PI and the back end are not reliant on it. We mention this because some might look at Figure 9.11 and decide that the effort is not worth the complexity. On the contrary, the productivity gains justify the work of making it happen. Plus, if it’s done right, the complexity of PIEDA need not result in an excess of administrative load or inhibitions of process agility.
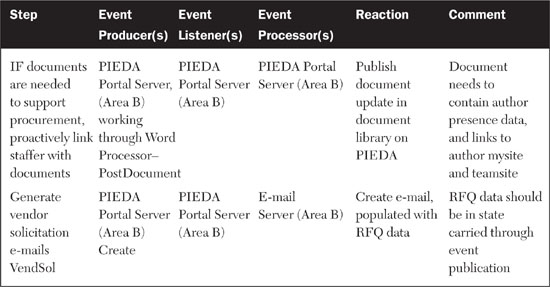
To illustrate how the target architecture for PIEDA fulfills the functional requirements, we’ll walk through one specific example of the event flow. Using the requirement of “Request Procurement,” let’s examine the specific EDA functions that PIEDA needs to realize to make the requirement work. The requirement specifies that the ERP system inform the procurement staffer of the procurement need for a list of items. The flow of process steps shown in Table 9.1 describes how this requirement is fulfilled, adding in the events that are produced and listened to at each step.

Once again, our old EDA friend—carrying state—surfaces in PIEDA. For an e-mail or IM session to be generated as a reaction to an event, the event processor must have access to the event state data in the event message. For example, if the user initiates the CreateIM command, which starts an instant message session with another stakeholder, the requirement is that the IM session will automatically contain data about the specific procurement under discussion, as well as links to the ERP system files as well as documents, that need to be discussed. To do this, the CreateIM command needs to contain a function that lets it search for already published event data about the procurement in question. In effect, CreateIM is a two-state command series that looks like this:
1. WHEN user initiates CreateIM command for procurement XYX, SEARCH message queue of events published for DoRFQ and FIND procurement XYZ data
2. INITIATE IM Session (through SIP), carrying XYZ data as XML bound to SIP
We use this IM example for a reason, namely that SIP to XML integration is not easy, and the standards involved continue to evolve. Binding SOAP to SIP is also challenging. Whichever method of integration is chosen, it needs to be flexible, allowing low friction for rapid changes in configuring IM session generation with changing business process models. It will take more than average effort to get it to work, but PIEDA should generate greater than average ROI.
The broader point is that PIEDA—Area B—needs to be a flexible switchboard connecting the event activities with Areas A and C to create ROI and justification of the whole project. If PIEDA is too rigid, and changes are time consuming or expensive, then the EDA PI integration will not serve its business purpose. Although this statement could be made about almost any application or architecture project, it is particularly true for PI. PI is inherently more unstructured and more unpredictable than conventional IT situations.
Given the complexity of PIEDA, achieving the high degree of flexibility envisioned is a double challenge. Not only does your development team have to create an architecture that is wholly new, and do so with custom development, they must create an architecture that is highly flexible too. Some wise people might declare the challenge not worth it at the outset.
Although these wise people wouldn’t be entirely wrong for wanting to avoid the hassle of entering uncharted waters, the good news is that PIEDA can actually be deployed in very small increments. Looking at Figure 9.11, you can understand that Area A already exists in some form. Virtually every sizable business in the world has an e-mail system, an intranet of some kind, and suites of productivity applications. VOIP and corporate IM are on the ascent as well. Building Area A from scratch is not an issue. Area C exists in its component parts, and exposing Web services and creating an EDA is a decision that is separate from building PIEDA. There would be a good rationale for creating an EDA at the CRM and ERP system level for its own sake.
We do not want to revisit EDA implementation in this chapter to the extent that it has been covered earlier. All of the multistakeholder buy-in and iterative design cycles discussed previously apply to PIEDA. The key takeaway for thinking about implementing PIEDA is to understand that Area B can be developed in stages. In fact, it can be deployed one feature at a time after a core set of EDA infrastructure pieces have been put in place. Unlike Area C, which needs a certain number of event producers, listeners, and processors to hit critical mass and function, PIEDA can start quite small. PIEDA can take one instance of event processing, such as “Request Procurement” and put it into full effect. This approach might even be the optimal way of getting it off the ground.
Given the fickle nature of human-machine interaction, which is truly at the heart of PIEDA, it would be wise to design, test, and deploy in tiny increments. Although the development team might think it’s really cool to have an automated IM session generated, users might scoff at such a feature. To save time and resources, and ensure the highest level of success, PIEDA’s implementation plan should include a thorough usability testing and feedback cycle. End users need to be included intensely throughout PIEDA’s life cycle. This is especially relevant because PIEDA does not rely on prepackaged software, which usually undergoes its own round of usability tests and market research. In the future, though, PIEDA type platforms might become common. Today, though, it’s an unexplored frontier. (Free tip for readers: If anyone is brave enough to stake a claim in this space, venture capitalists might find it interesting.)
![]() Most organizations have a large existing investment in a collection of productivity and communications technologies such as desktop file editors (e.g., Word, Excel), e-mail, instant messaging, content management, collaboration (e.g., SharePoint, Lotus Connections), VOIP, and so forth, that are known as productivity infrastructure. There is great interest in most companies to improve the utilization of these technologies, tie them more directly to business processes, and generate a strong ROI for the whole assemblage of disconnected parts. In this chapter, we look at ways to connect back-end systems exposed as event Web services to the end user in an event-driven productivity infrastructure.
Most organizations have a large existing investment in a collection of productivity and communications technologies such as desktop file editors (e.g., Word, Excel), e-mail, instant messaging, content management, collaboration (e.g., SharePoint, Lotus Connections), VOIP, and so forth, that are known as productivity infrastructure. There is great interest in most companies to improve the utilization of these technologies, tie them more directly to business processes, and generate a strong ROI for the whole assemblage of disconnected parts. In this chapter, we look at ways to connect back-end systems exposed as event Web services to the end user in an event-driven productivity infrastructure.
![]() Advantages of integrating back-end systems and productivity infrastructure using EDA include the ability of end users to interact on a social computing basis and the ability for end users to search back-end databases, as well as enterprise applications and content repositories to get an integrated view of a customer.
Advantages of integrating back-end systems and productivity infrastructure using EDA include the ability of end users to interact on a social computing basis and the ability for end users to search back-end databases, as well as enterprise applications and content repositories to get an integrated view of a customer.
![]() This chapter uses a case study where a company wants to improve the process that begins with a sales proposal and culminates with the fulfillment of a sales order. This involves a multistep process that begins with the mapping of the business process and then connecting those process steps with underlying applications and sources of data. Some of the data resides on back-end systems, while other parts of it are contained in various places within the productivity infrastructure. For example, information about a customer might reside on the CRM system, the ERP system, an e-mail archive, a collaboration suite, and a document repository.
This chapter uses a case study where a company wants to improve the process that begins with a sales proposal and culminates with the fulfillment of a sales order. This involves a multistep process that begins with the mapping of the business process and then connecting those process steps with underlying applications and sources of data. Some of the data resides on back-end systems, while other parts of it are contained in various places within the productivity infrastructure. For example, information about a customer might reside on the CRM system, the ERP system, an e-mail archive, a collaboration suite, and a document repository.
![]() To make event-driven productivity infrastructure work, the CRM and ERP systems must be exposed as Web services up to an ESB, which is then connected through to an integrated solution that can consume these Web services and correlate them to activity in the productivity infrastructure. Thus, for example, when a user is preparing an e-mail about a customer, that user can start an IM session in real time that automatically references the customer, or look up CRM or ERP information about that customer from the e-mail client. Each step in the sales proposal to order fulfillment process maps to a set of event listeners that surface data about the customer in real time.
To make event-driven productivity infrastructure work, the CRM and ERP systems must be exposed as Web services up to an ESB, which is then connected through to an integrated solution that can consume these Web services and correlate them to activity in the productivity infrastructure. Thus, for example, when a user is preparing an e-mail about a customer, that user can start an IM session in real time that automatically references the customer, or look up CRM or ERP information about that customer from the e-mail client. Each step in the sales proposal to order fulfillment process maps to a set of event listeners that surface data about the customer in real time.
1. Taylor, James and Raden, Neil. Smart Enough Systems. New Jersey: Prentice Hall, 2007.