
Chapter 8
Grouping and Bucketing Data
In This Chapter
![]() Making top and bottom displays
Making top and bottom displays
![]() Using histograms to track groups
Using histograms to track groups
![]() Creating histograms with pivot tables
Creating histograms with pivot tables
![]() Highlighting top and bottom values in charts
Highlighting top and bottom values in charts
It’s often helpful to organize your analyses into logical groups of data. Grouping allows you to focus on manageable sets that have key attributes. For example, rather than look at all customers in one giant view, you can analyze customers who buy only one product. Then you can focus attention and resources on those customers who have the potential to buy more products.
The benefit of grouping data is that you can more easily pick out groups that fall outside the norm for your business.
In this chapter, I help you explore some of the techniques you can use to create components that group and bucket data.
Creating Top and Bottom Displays
When you look at the list of Fortune 500 companies, you often look for the top 20 companies. Then perhaps you look at who eked out a spot in the bottom 20 slots. It’s unlikely that you would check to see which company came in at number 251. It’s not necessarily because you don’t care about number 251; it’s just that you can’t spend the time or energy to process all 500 companies. So you process the top and bottom of the list.
This concept is the same one behind creating top and bottom displays. Your audience has only a certain amount of time and resources to dedicate to solving any issues you can emphasize on your dashboard. Showing them the top and bottom values in your data can help them pinpoint where and how they can have the most impact with the time and resources they possess.
Incorporating top and bottom displays into dashboards
The top and bottom displays you create can be as simple as source data that you incorporate into your dashboard. Typically placed to the right of a dashboard, this data can emphasize details that a manager may use to take action on a metric. For example, the simple dashboard shown in Figure 8-1 shows sales information with top and bottom sales reps.
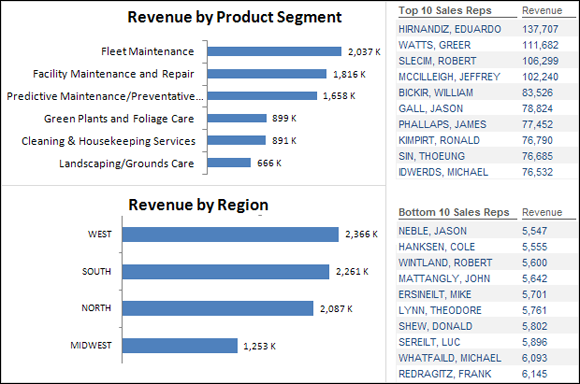
Figure 8-1: Top and bottom displays that emphasize certain metrics.
To get a little fancier, you can supplement the top and bottom displays with some ranking information, some in-cell bar charts, or some conditional formatting; see Figure 8-2.

Figure 8-2: You can use conditional formatting to add visual components to your top and bottom displays.
You can create the in-cell bar charts with the Data Bars conditional formatting function, covered in Chapter 5. The arrows are also simple conditional formatting rules that are evaluated against the variance in current and preceding months’ ranks.
Using pivot tables to get top and bottom views
If you’ve read Chapter 6, you know that a pivot table is an amazing tool that can help create interactive reporting. Take a moment now to look over an example of how pivot tables can help you build interactive top and bottom displays.
 Open the Chapter 8 Samples file, found on this book’s companion website, to follow along.
Open the Chapter 8 Samples file, found on this book’s companion website, to follow along.
Follow these steps to display Top and Bottom filters with a pivot table:
-
Start with a pivot table that shows the data you want to display with the top and bottom views.
In this case, the pivot table shows Sales Rep and Sales_Amount; see Figure 8-3.
-
Right-click the field you want to use to determine the top values — in this example, use the Sales Rep field — and then choose Filter ⇒ Top 10 from the menu that appears, as shown in Figure 8-4.
The Top 10 Filter (Sales Rep) dialog box appears, as shown in Figure 8-5.
-
In the Top 10 Filter (Sales Rep) dialog box, define the view you’re looking for.
In this example, you want the Top 10 Items (Sales Reps) as defined by the Sales_Amount field.
-
Click OK to apply the filter.
At this point, the pivot table is filtered to show the top ten sales reps for the selected region and market. You can change the Market filter to Charlotte and get the top ten sales reps for Charlotte only; see Figure 8-6.
- To view the bottom ten Sales Rep list, copy the entire pivot table and paste it next to the existing one.
-
Repeat Steps 2 through 4 in the newly copied pivot table — except this time, choose to filter the bottom ten items as defined by the Sales_Amount field.
If all goes well, you now have two pivot tables similar to those in Figure 8-7: one that shows the top ten sales reps and one that shows the bottom ten. You can link back to these two pivot tables in the analysis layer of your data model using formulas. This way, when you update the data, the top and bottom values display the new information.

Figure 8-3: Start with a pivot table that contains the data you want to filter.

Figure 8-4: Select the Top 10 filter option.

Figure 8-5: Specify the filter you want to apply.

Figure 8-6: You can interactively filter the pivot table report to instantly show the top ten sales reps for any region and market.
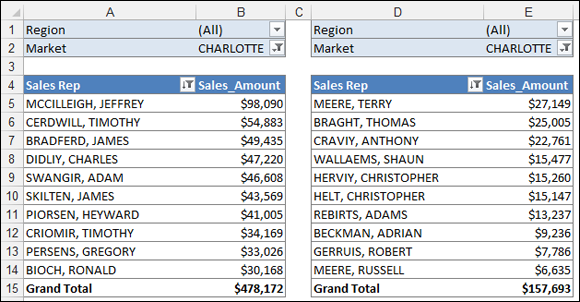
Figure 8-7: You now have two pivot tables that show top and bottom displays.
 If there’s a tie for any rank in the top or bottom values, Excel shows you all tied records, so you may get more than the number you filtered for. If you filtered for the top 10 sales reps and there’s a tie for the number 5 rank, Excel shows you 11 sales reps. (Both reps ranked at number 5 are shown.)
If there’s a tie for any rank in the top or bottom values, Excel shows you all tied records, so you may get more than the number you filtered for. If you filtered for the top 10 sales reps and there’s a tie for the number 5 rank, Excel shows you 11 sales reps. (Both reps ranked at number 5 are shown.)
Top Values in Charts
Sometimes a chart is indeed the best way to display a set of data, but you still want to call attention to the top values in that chart. In these cases, you can use a technique that highlights the top values in your charts. That is to say, you can use Excel to figure out which values in your data series are in the top nth value and then apply special formatting to them. Figure 8-8 illustrates an example in which the top five quarters are highlighted and given a label.

Figure 8-8: This chart highlights the top five quarters with different font and labeling.
The secret to this technique is Excel’s obscure LARGE function. The LARGE function returns the nth largest number from a dataset. In other words, you tell it where to look and the number rank you want.
To find the largest number in the dataset, you enter the formula LARGE(Data_Range, 1). To find the fifth largest number in the dataset, use LARGE(Data_Range, 5). Figure 8-9 illustrates how the LARGE function works.

Figure 8-9: Using the LARGE function returns the nth largest number from a dataset.
The idea is fairly simple: To identify the top five values in a dataset, you first need to identify the fifth largest number (LARGE function to the rescue) and then test each value in the dataset to see whether it’s bigger than the fifth largest number. Here’s what you do:
-
Build a chart feeder that consists of formulas that link back to your raw data.
The feeder should have two columns: one to hold data that isn’t in the top five and one to hold data that is in the top five; see Figure 8-10.
-
In the first row of the chart feeder, enter the formulas shown in Figure 8-10.
The formula for the first column (F4) checks to see whether the value in cell C4 is less than the number returned by the LARGE formula (the fifth largest value). If it is, the value in cell C4 is returned. Otherwise, NA is used. The formula for the second column works in the same way, except the IF statement is reversed: If the value in cell C4 is greater than or equal to the number returned by the LARGE formula, the value is returned; otherwise, NA is used.
- Copy down the formulas to fill the table.
-
Use the chart feeder table to plot the data into a stacked column chart.
You immediately see a chart that displays two data series: one for data points not in the top five and one for data points in the top five; see Figure 8-11.
Notice that the chart in Figure 8-11 shows some rogue zeros. You can complete the next few steps to fix the chart so that the zeros don’t appear.
-
Right-click any of the data labels for the “not in top 5” series and choose Format Data Labels from the menu that appears.
The Format Data Labels dialog box appears.
- In this dialog box, expand the Numbers section and select Custom in the Category list.
- Enter #,##0;; as the custom number format, as shown in Figure 8-12.
- Click Add and then click Close.

Figure 8-10: Build a new chart feeder that consists of formulas that plot values into one of two columns.

Figure 8-11: After you add data labels to the top five data series and do a bit of formatting, your chart should look similar to the one shown here.

Figure 8-12: Entering #,##0;; as the custom format for a data label hides all zeros in that data series.
When you go back to the chart, you see that the rogue zeros are now hidden and the chart is ready for colors, labels, and other formatting you want to apply.
You can apply the same technique to highlight the bottom five values in your dataset. The only difference is that instead of using the LARGE function, you use the SMALL function. Whereas the LARGE function returns the largest nth value from a range, the SMALL function returns the smallest nth value.
Figure 8-13 illustrates the formulas you use to apply the same technique outlined here for the bottom five values.

Figure 8-13: Use the SMALL function to highlight the bottom values in a chart.
The formula for the first column (F22) checks to see whether the value in cell C22 is greater than the number returned by the SMALL formula (the fifth smallest value). If it is, the value in cell C22 is returned. Otherwise, NA is used. The formula for the second column works in the same way except the IF statement is reversed: If the value in cell C22 is greater than the number returned by the SMALL formula, NA is used; otherwise, the value is returned.
Using Histograms to Track Relationships and Frequency
A histogram is a graph that plots frequency distribution. A frequency distribution shows how often an event or category of data occurs. With a histogram, you can visually see the general distribution of a certain attribute.
Take a look at the histogram shown in Figure 8-14. This histogram represents the distribution of units sold in one month among your sales reps. As you can see, most reps sell somewhere between 5 and 25 units per month. As a manager, you want the hump in the chart to move to the right — more people selling a higher number of units per month. So you set a goal for a majority of the sales reps to sell between 15 and 25 units within the next three months. With this histogram, you can visually track the progress toward that goal.

Figure 8-14: A histogram showing the distribution of units sold per month among the sales force.
This section discusses how to create a histogram using various methods available to you. These techniques allow for a level of automation and interactivity, which comes in handy when updating dashboards each month.
See how to develop a data model in Chapter 2.
Creating a formula-driven histogram
If you don’t have Excel 2016, or if you want a bit more involvement in creating your histogram charts, you can create a formula-driven histogram. This technique fits nicely in data models in which you separate data, analysis, and presentation information.
Follow these steps to create a formula-driven histogram:
-
Before you create the histogram, you need a table that contains your raw data, and you need to create a bin table; see Figure 8-15.
The raw data should ideally consist of records that represent unique counts for the data you want to group. For instance, the raw data table in Figure 8-15 contains unique sales reps and the number of units each has sold.
The bin table dictates the grouping parameters used to break your raw data into the frequency groups. The bin table tells Excel to cluster all sales reps selling fewer than 5 units into the first frequency group, any sales reps selling 5 to 14 units in the second frequency group, and so on.
You can freely set your own grouping parameters when you build the bin table. However, you should generally keep parameters as equally spaced as possible. You typically want to end your bin tables with the largest number in the dataset. This gives you clean groupings that end in a finite number — not in an open-ended greater-than designation. -
Create a new column in the bin table to hold the FREQUENCY formulas, and then name the new column Frequency Formulas, as shown in Figure 8-16.
Excel’s FREQUENCY function counts how often values occur within the ranges you specify in a bin table.
- Select the cells in the newly created column.
-
Type the FREQUENCY formula you see in Figure 8-16 and then press Ctrl+Shift+Enter on the keyboard.
The FREQUENCY function has a quirk that often confuses first-time users. The FREQUENCY function is an array formula — a formula that returns many values at one time. For this formula to work properly, you have to press Ctrl+Shift+Enter on the keyboard after typing the formula. If you press only the Enter key, you don’t get the results you need.At this point, you should have a table that shows the number of sales reps that fall into each of your bins. You could chart this table, but the data labels would come out wonky. For the best results, build a simple chart feeder table that creates appropriate labels for each bin. You do this in the next step.
-
Create a new table that feeds the charts a bit more cleanly; see Figure 8-17.
Use a simple formula that concatenates bins into appropriate labels. Use another formula to bring in the results of your FREQUENCY calculations.
In Figure 8-17, the formulas in the first record of the chart feeder table are visible. These formulas are essentially copied down to create a table that’s appropriate for charting.
-
Use the newly created chart feeder table to plot the data into a column chart.
Figure 8-18 illustrates the resulting chart. You can very well use the initial column chart as your histogram.
If you like your histograms to have spaces between the data points, you’re done. If you like the continuous, blocked look you get with no gaps between the data points, follow the next few steps.
-
Right-click any of the columns in the chart and choose Format Data Series from the menu that appears.
The Format Data Series dialog box appears.
- Adjust the Gap Width property to 0%, as shown in Figure 8-19.

Figure 8-15: Start with your raw data table and a bin table.

Figure 8-16: Type the FREQUENCY formula you see here and then be sure to hold down the Ctrl+Shift+Enter keys on your keyboard.

Figure 8-17: Build a simple chart feeder table that creates appropriate labels for each bin.

Figure 8-18: Plot your histogram data into a column chart.

Figure 8-19: To eliminate the spaces between columns, set the Gap Width to 0%.
Adding a cumulative percent
A nice feature to add to your histograms is a cumulative percent series. With a cumulative percent series, you can show the percent distribution of the data points to the left of the point of interest.
Figure 8-20 shows an example of a cumulative percent series. At each data point in the histogram, the cumulative percent series tells you the percent of the population that fills all the bins up to that point. For instance, you can see that 25% of the sales reps represented sold 15 units or less. In other words, 75% of the sales reps sold more than 15 units.
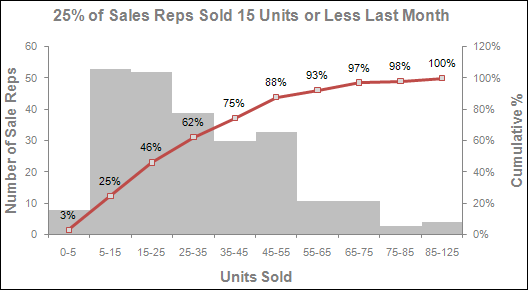
Figure 8-20: The cumulative percent series shows the percent of the population that fills all the bins up to each point in the histogram.
Take another look at the chart in Figure 8-20 and find the point where you see 75% on the cumulative series. At 75%, look at the label for that bin range (you see 35–45). The 75% mark tells you that 75% of sales reps sold between 0 and 45 units. This means that only 25% of sales reps sold more than 45 units.
To create a cumulative percent series for the histogram, follow these steps:
-
Perform Steps 1 through 5 of creating a histogram (in the “Creating a formula-driven histogram” section) and then add a column to your chart feeder table that calculates the percent of total sales reps for the first bin; see Figure 8-21.
Note the dollar symbols ($) used in the formula to lock the references while you copy down the formula.
- Copy down the formula for all bins in the table.
-
Use the chart feeder table to plot the data into a line chart.
As you can see in Figure 8-22, the resulting chart needs some additional formatting.
- Right-click the series that makes up your histogram (Count of Sales Reps), select Change Chart Type from the menu that appears, and then change the chart type to a column chart.
- Right-click any of the columns in the chart and choose Format Data Series.
- Adjust the Gap Width property to 0%, as demonstrated earlier, in Figure 8-19.
- Right-click Cumulative % series in the chart and choose Format Data Series.
- In the Format Data Series dialog box, change the Plot Series On option to Secondary Axis.
-
Right-click Cumulative % series in the chart and choose Add Data Labels.
At this point, your base chart is complete. It should look similar to the one shown at the beginning of this section, in Figure 8-20. When you get to this point, you can adjust the colors, labels, and other formatting.

Figure 8-21: In a new column, create a formula that calculates the percent of total sales reps for the first bin.

Figure 8-22: The initial chart will need some formatting to make it look like a histogram.
Using a pivot table to create a histogram
Did you know you can use a pivot table as the source for a histogram? That’s right. With a little-known trick, you can create a histogram that’s as interactive as a pivot table!
As in the formula-driven histogram, the first step in creating a histogram with a pivot table is to create a frequency distribution. Just follow these steps:
-
Create a pivot table and plot the data values in the row area (not the data area).
As you can see in Figure 8-23, the SumOfSales_Amount field is placed in the ROWS drop zone. Place the Sales Rep field in the VALUES drop zone.
-
Right-click any value in the ROWS area and choose Group from the menu that appears.
The Grouping dialog box appears, as shown in Figure 8-24.
-
In this dialog box, set the Starting At and Ending At values and then set the interval.
This step creates the frequency distribution. In Figure 8-24, the distribution is set to start at 5,000 and to create groups in increments of 1,000 until it ends at 100,000.
-
Click OK to confirm your settings.
The pivot table calculates the number of sales reps for each defined increment, just as in a frequency distribution; see Figure 8-25. You can now leverage this result to create a histogram!

Figure 8-23: Place your data values in the ROWS drop zone and the Sales Rep field in the VALUES drop zone as a Count.

Figure 8-24: The Grouping dialog box.

Figure 8-25: The result of grouping the values in the row area is a frequency distribution that can be charted into a histogram.
The obvious benefit to this technique is that after you have a frequency distribution and a histogram, you can interactively filter the data based on other dimensions, like region and market. For instance, you can see the histogram for the Canada market and then quickly switch to see the histogram for the California market.
Note that you can’t add cumulative percentages to a histogram based on a pivot table.
Using Excel’s Histogram statistical chart
If you’re using Excel 2016, you get the luxury of using Excel’s new statistical charts. Statistical charts help calculate and visualize common statistical analyses without the need to engage in brain-busting calculations. This new chart type lets you essentially point and click your way into a histogram chart, leaving all the mathematical heavy lifting to Excel.
To create a histogram chart with the new statistical chart type, follow these steps:
-
Start with a dataset that contains values for a unique group you want to bucket and count.
For instance, the raw data table in Figure 8-26 contains unique sales reps and the number of units each has sold.
- Select your data, click the Statistical Charts icon found on the Insert tab and then select the Histogram chart from the drop-down menu that appears. (See Figure 8-27.)

Figure 8-26: Start with a raw data table.

Figure 8-27: Creating a histogram chart.
Note, in Figure 8-27, that you can also have Excel create a histogram with a cumulative percentage. This would output a histogram with a supplemental line showing the distribution of values, similar to the chart illustrated earlier, in Figure 8-20.
Excel outputs a histogram chart based on the values in your source dataset. As you can see in Figure 8-28, Excel attempts to derive the best configuration of bins based on your data.

Figure 8-28: Excel auto-generates a histogram based on its own derived bins.
You can always change the configuration of the bins if you’re not happy with what Excel has come up with. Simply right-click the x-axis and select Format Axis from the menu that appears. In the Axis Options section (see Figure 8-29), you see a few settings that allow you to override Excel’s automatic bins:
- Bin width: Select this option to specify how big the range of each bin should be. For instance, if you were to set the bin width to 12, each bin would represent a range of 12 numbers. Excel would then plot as many 12-number bins as it needs to account for all the values in your source data.
- Number of bins: Select this option to specify the number of bins to show in the chart. All data will then be distributed across the bins so that each bin has approximately the same population.
- Overflow bin: Use this setting to define a threshold for creating bins. Any value above the number to set here will be placed into a kind of “all other” bin.
- Underflow bin: Use this setting to define a threshold for creating bins. Any value below the number to set here will be placed into a kind of “all other” bin.
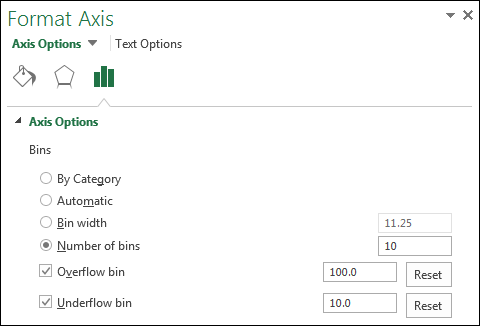
Figure 8-29: Configure the x-axis to override Excel’s default bins.
Figure 8-30 illustrates how the histogram would change when the following settings are applied:
- Number of bins: 10
- Overflow bin: 100
- Underflow bin: 10

Figure 8-30: Histogram with configured bins.