
2  Defining an Agile Process
Defining an Agile Process
Quite often in the early stages of agile adoption, agile teams are able to be successful because they don’t have to comply with a lot of burdensome and stifling rules. In fact, using an initial controlled, pilot team approach that is outside of traditional governance is one that has been successful over decades at organizations ranging from Capital One, PayPal, Salesforce, Nike, Spotify, American Express, and the National Geographic Society to the U.S. Library of Congress and the U.S. Department of Homeland Security. If we want to institutionalize agile methods, however, a key job of the Agile VMO is to help develop enterprise-class agile processes and practices that not only support agile delivery but also make them well defined and repeatable.
In particular, many organizations that are publicly traded, highly regulated, or government agencies need to have defined, repeatable, auditable processes and evidence that the processes are being followed. Sadly, in many cases, the vast majority of the work in these types of organizations is still being executed in a traditional waterfall way. Even in 2020, these organizations retained vestiges of industrial-age management. Consequently, many of them have set up PMOs or centers of excellence to drive process standardization and excellence. In the past, these organizations have defined traditional linear processes that are now likely to be too slow, cumbersome, and expensive to be competitive. Misguided organizations will put in so much traditional oversight that they negate all of the benefits that they had hoped for.
Many of these same organizations are now attempting to transition to agile delivery at scale. Some have already been practicing some form of agile development at the team level for some time. Often, the agile work that has been happening has been operating somewhat under the radar from a process controls and audit standpoint. Not surprisingly, this under-the-radar agile work has often been very successful at the team level. Clearly, when you unburden teams from heavy, linear, and bureaucratic overhead and let them work in a more unregulated way they are able to get things done more quickly. This kind of success starts to get some attention. “We should do all of our work this way!” some senior executive might say. So, from the grassroots success comes the desire to scale agile so that more of the work is done in an agile way.
We need to be aware of the dark side when it comes to the organization at large. Even as teams have forged ahead, there has been a spotty application of common agile methods, lack of internal standards, relatively undefined and haphazard processes, confusion around process artifacts or deliverables, and undefined controls and metrics. Across teams, this quickly generates enormously high levels of redundancy, waste, and missed outcomes. As agile processes grow within any organization, the less likely it is that teams will continue to be able to fly under the radar. As large, regulated, audited firms grow their use of agile, they must come to terms with repeatability, auditability, controls, governance, and traceability. Are you seeing a potential problem looming here?
Organizations that seek to practice modern delivery methods need to be both agile and compliant, but achieving both will require significant changes to processes and controls. The challenge then, is to define repeatable and auditable processes that don’t actually end up killing the very agility, flexibility, and speed that we are trying to achieve. Known in lean circles as the six sigma paradox, the VMO’s challenge is to minimize process variability, slack, and redundancy by building variability, slack, and redundancy into our organizations. That is, we have to create standardized processes and controls at the program and enterprise levels that spur nonstandardized experimentation, risk-taking, and innovation at the team level.
To be successful and to achieve the goals of agile at scale, the VMO will need to instill this form of disciplined agility by doing the following:
• defining agile processes that actually allow or even enforce delivery of value to the organization early and often instead of getting in the way
• shifting the metrics and reporting that are used to measure project effectiveness away from traditional waterfall process-output metrics and toward business-outcome metrics
• changing the controls that are used to govern projects away from phase-based and paper-based artifacts to controls that enforce good agile practices
• creating flexibility in how results are achieved by making experimentation an expected part of the process
• minimizing low-value, high-overhead documentation or artifacts that are not natural outputs of an agile process
Before we dive into our agile processes for product development, let’s return to successful COVID-19 responses for a moment. Governments in Mongolia, Vietnam, Ghana, South Korea, and New Zealand acted speedily, with great discipline, and with end-to-end practices like rapid and widespread testing, border closures, contact tracing, prohibition of large public events, and funding of medical equipment and personnel.1 Their success in controlling the pandemic spread derived in large part from their leaders’ alacrity to establish sensible practices and their entire populations following those practices.
Establish High Discipline as the Driving Goal for All Your Agile Processes
To the uninitiated, agile methods can look like an unstructured and undisciplined approach to delivery, but this would be a gross mischaracterization and would also represent a lack of clear understanding. At their core, agile methods have their basis in lean manufacturing and the Toyota production system as conceptualized in figure 2.1. The Toyota production system is the basis for Toyota’s amazing success. Toyota reliably and routinely achieves business results that all organizations desire and need:
• high degrees of quality at scale
• high degrees of customer satisfaction
• low internal cost
• consistently high levels of profitability
This consistent level of profitability and quality is one reason why Toyota is one of the most studied organizations in the world. Toyota is a model for how lean thinking, continuous flow, and a zero-defect mentality can be a basis for process improvement in almost any business process.

Figure 2.1: The Toyota car factory as a model for lean thinking and continuous flow
Let’s be very clear here. Lean manufacturing is a highly successful, well-tested, scalable, and solid approach to industrial engineering. It is not a set of shortcuts, it is not hacking, and it is not achieved without serious industrial-scale process discipline. Lean’s process offspring, including agile product development, can and should be just as disciplined. All agile methods stress this discipline. At the team level, Scrum and Kanban espouse process discipline, just as extreme programming espouses engineering discipline. Other scaling methods, such as LeSS, Disciplined Agile, and SAFe, discussed later, all explicitly call for lean process discipline.
But in many organizations, due to a lack of knowledge, lack of experience, and a lack of clear expectations, agile teams sometimes work without the expected discipline. To many leaders, agile teams may look undisciplined. In some cases, perhaps they are. This is not how it is supposed to be, and it will be difficult to scale without a certain level of discipline. What is really sad is to hear agile team members say things like, “We are agile; we don’t have to estimate/plan/document.” This shows a clear lack of education and understanding, and it is worrisome that we would entrust millions of dollars in product engineering budget and trust the goodwill of our customers to this misguided thinking. In fact, agile methods have planning and plenty of it, which will be discussed in more detail in chapter 4.
Good agile teams are highly disciplined. Period. It takes a high degree of discipline to deliver working, tested software every two weeks. It is almost impossible to deliver quality software this quickly without it. The most highly disciplined teams that we have seen have been high-functioning agile teams. It is not uncommon for less disciplined teams to be precisely the ones that have difficulty delivering successfully against their commitments. All agile teams need to take a calibrated approach to defining their agile processes.
Take a Calibrated Approach to Defining Your Agile Processes
Agile is itself not a single process, but many processes are deemed to be agile. Defined in 2001 as an umbrella term for all agile processes at that time, the “Manifesto for Agile Software Development” is a set of 4 values and 12 principles that describe the characteristics of good agile development. Here are a few of the principles:
• customer satisfaction by early and continuous delivery of valuable software
• welcome changing requirements, even in late development
• deliver working software frequently (weeks rather than months)
• close, daily cooperation between businesspeople and developers
• working software is the primary measure of progress
• continuous attention to technical excellence and good design2
To reiterate, while agile itself is not a single process, many processes are agile, as indicated in figure 2.2, and are designed to achieve these principles. All of the agile approaches—such as Scrum, extreme programming, and Kanban at the team level and SAFe, Scrum at Scale, and Disciplined Agile at the program or portfolio level—can and should be highly disciplined and well executed.
The first step to a calibrated approach is to develop a basic-process road map.
Develop a Basic-Process Road Map
We wouldn’t expect a budding musician to play advanced music until years of fundamental skills have been established. However, we often expect teams that are new to agile to have perfect business goals, perfect requirements, perfect estimation, perfect planning, perfect technical practices, perfect communications, and perfect delivery. We expect that all of this be done with blinding speed, right from the beginning. This just isn’t going to happen.
Part of the VMO’s change strategy will be to lay out a basic agile-process road map with high-level goals and achievable timelines such as those in figure 2.3. For example, we might have a goal that, after the first six months, all teams are practicing all of the basic events and artifacts of Scrum and also have a basic automated smoke test in place. The VMO can then add metrics to see where the organization is in terms of meeting this goal.

Figure 2.2: The agile umbrella
Six months later, perhaps we are ready to take on an organizational goal of effective cross-team planning and cross-team integration. Another common management issue is trying to measure too many things too early, thereby loading the teams up with too many competing priorities and goals. Instead, we might plan for new metrics to be put in place only after successful cross-team builds have been established. By working this way, the organization is using metrics to both support and drive the change strategy. Additionally, we are making current goals and process expectations clear to teams.

Figure 2.3: Calibrated agile process road map
Start with Scrum or Kanban as Your Base Process
In the saying, a journey of a thousand miles begins with a single step. The first step in a multiyear agile journey is to establish a base process, and this is usually Scrum or Kanban or sometimes a hybrid of both, ScrumBan.
Scrum is a well-defined process for new product development. These practices can easily form the basis of a standard agile delivery process for individual teams and even teams of teams. We highlight Scrum because it is by far the most popular of the agile delivery processes and it has a fairly well-understood and accepted set of practices. The Scrum process, as it is commonly practiced, has five events that every team should be practicing and at least four core artifacts that are natural outputs of the process and that each team should be producing. Figure 2.4 and tables 2.1 and 2.2 outline the elements of commonly practiced Scrum.
Scrum seeks to instill a rolling-wave planning cycle where we plan out several weeks of work, execute and deliver that work, then plan the next few weeks. For plannable work, this can be great. However, in many areas, planning even two weeks’ worth of work may be almost impossible. A prime example is operational support. In the support world, planning can be extraordinarily difficult because we don’t know what is going to break tomorrow, how impactful the breakage will be, or how complex the solution will be. Support is often a very reactive function. The problem for us as leaders then is: How can we manage the unplannable?
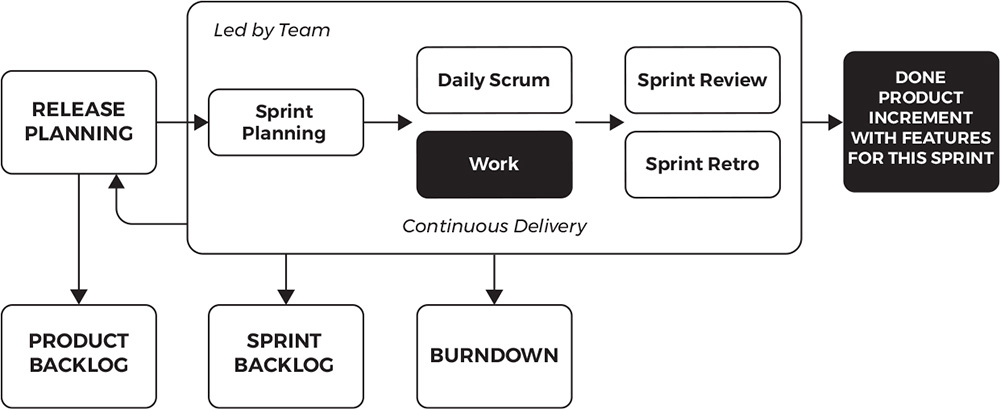
Figure 2.4: Basic Scrum process
Table 2.1. Scrum Events/Ceremonies
Scrum Event |
Description |
Release planning |
A timeboxed planning session that answers several key questions: What is the goal of the next release, what functionality will be in the release, and when will that release happen? While not a required process step, release planning is commonly performed. |
Sprint planning |
A short planning session that answers two key questions: What can be achieved in the upcoming Sprint and how can it be achieved? |
Sprint |
A timebox of one month or less during which a done, usable, and potentially releasable product increment is created. |
Daily Scrum |
A daily 15-minute event, also called stand-up, for the team to synchronize activities and create a plan for the next 24 hours. |
Sprint review |
Is held at the end of the Sprint to inspect the product increment and adjust the product backlog if needed. |
Sprint retrospective |
Happens after the Sprint review and addresses what went well during the Sprint, what could be improved, and what the team will commit to improve in the next Sprint. |
Scrum Artifact |
Description |
Product backlog |
An ordered list of everything that is known to be needed in the product. It is the single source of requirements. |
Sprint backlog |
The set of product backlog items selected for the Sprint. It makes visible all the work that the team needs to meet the Sprint goal. The backlog has enough detail that changes in progress can be understood on a daily basis in the daily scrum. |
Burndown chart |
A chart showing the number of stories or points still remaining to be completed within the Sprint. |
Product increment |
A body of inspectable work. The increment must be usable by customers. The entire point of scrum is to deliver a done increment. |
Another agile method that is quite popular for operational work is Kanban. Kanban is interrupt driven and is the obvious choice for operational work and also most work that is not new product development. In Kanban, we don’t lock the scope for even two weeks. Instead, we continuously reprioritize the work as it comes in. Our product owner sets priorities from day to day or even hour to hour and the team simply pulls the highest item off the list and works on it until done. We also impose work-in-progress (WIP) limits to prevent the team from working on too many items at once. By focusing on just a few top priority items at once, the team can achieve a continuous flow of delivery that is very reactive to the latest changing priorities. This does not mean that Kanban cannot be used for plannable work; it certainly can be. Likewise, Scrum, with some modifications, can be used to manage unplannable work too. Scrum is used more frequently for plannable work, and Kanban is used more frequently for unplannable work. Kanban sounds easy and simple, but having the discipline to do it well is in fact quite difficult. It requires extraordinary discipline.
Teams that say that they are doing Scrum should be able to demonstrate evidence of each of the previously mentioned events and artifacts in every Sprint. VMOs can start to help their organizations achieve consistency and repeatability by setting expectations that these very simple and natural outcomes of the Scrum process are expected from all Scrum teams. Likewise, Kanban teams should be able to show that they have a clearly prioritized backlog, have and adhere to WIP limits, have flow metrics, and perhaps have classes of delivery and can demonstrate a continuous flow of delivery.
From a process standpoint, there is nothing here that the vast majority of experienced people in the agile community should complain about, and this simple list of process controls is an adequate way to start putting discipline around agile delivery teams. These simple rules create the foundation for strong process discipline, create the foundation for organizational agility, and minimize nonagile overhead. At the same time, we need to remove legacy process controls that do not contribute to or encourage agility, such as the following:
• Most waterfall phase gates and reviews such as design reviews, architecture reviews, and security reviews. Review these frequently and iteratively instead.
• Heavy up-front documentation. We should go lightweight instead. Small, frequent deployments should require only small amounts of paperwork.
Scrum and Kanban are integral to all scaling methods and are the foundations on which all enterprise agile transformations should be built.
Take a Focused, Minimalist Approach to Scaling
When all of our individual teams operate with a relatively simple but powerful level of Scrum or Kanban discipline, we can begin to scale multiple teams in order to support larger and more complex efforts. When we scale, we combine the efforts of many teams into a single, larger endeavor or program. In these cases, the estimates, plans, and approaches that each team uses must somehow integrate well with the approaches that other teams are using. Beyond the individual team goals and plans, there need to be program- or product-level goals, plans, estimates, and schedules.
Larger agile programs need another level of process events and artifacts that integrate the efforts of the individual teams. This will add yet another layer of estimation, planning, and reporting, and it is difficult if not impossible to avoid this. Luckily, scaling methods, including the Scaled Agile Framework (SAFe) and Disciplined Agile, provide reasonably holistic ways to deal with both team level and program level planning and management. The several scaling approaches available have many common elements. Some elements common to all scaling methods are outlined in figure 2.5
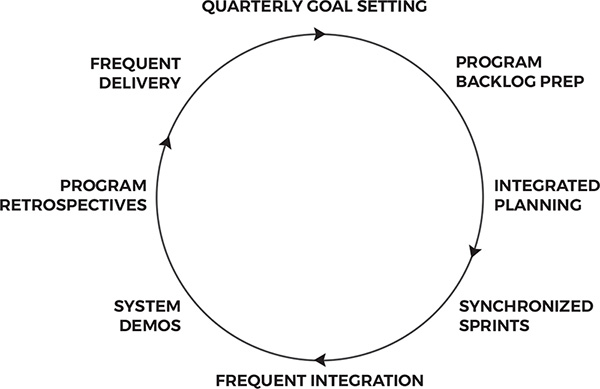
Figure 2.5: Common elements of agile at scale
Despite their commonalities, each scaling method is unique in some way to large-scale planning, delivery, integration, and reporting. Whichever scaling method we select, the VMO helps define clear program-level process expectations for scaled agile practices such as the following:
![]() multiteam planning events
multiteam planning events
![]() frequent multiteam integration and demos
frequent multiteam integration and demos
![]() frequent multiteam scrum of scrums
frequent multiteam scrum of scrums
![]() regular program-wide retrospectives
regular program-wide retrospectives
![]() demand versus capacity planning
demand versus capacity planning
![]() work-item prioritization based on weighted shortest job first
work-item prioritization based on weighted shortest job first
![]() clear, measurable business goals that are achievable in the near term
clear, measurable business goals that are achievable in the near term
![]() visible work management system—that is, program Kanban
visible work management system—that is, program Kanban
![]() plans that map stories or features for each team for the next several Sprints
plans that map stories or features for each team for the next several Sprints
![]() release burndown/burnup by feature
release burndown/burnup by feature
![]() program-level Sprint-over-Sprint velocity
program-level Sprint-over-Sprint velocity
No matter which scaling methodology we select, the same advice applies: if we want our teams to do good SAFe or good Disciplined Agile, then we should set clear expectations and not make them spend time on unnecessary activities that could be spent on the respective process. It’s really quite simple: do the agile process of your choice, do it very well, and minimize the time spent doing anything else.
Define Metrics That Support and Drive Dynamic Transformation
Another key area of focus for the VMO is metrics. Metrics have a big role in driving human behavior. Appropriate selection of metrics is therefore critical to agile transformation and execution to move us in the right direction. Metrics bring strong focus to process, to outcomes, and ultimately to behaviors. Chosen correctly, metrics will foster and accelerate agility. Chosen poorly, metrics will enforce the wrong process, the wrong outcomes, and the wrong behaviors. Many organizations make the classic mistake of trying to change the process while keeping the same metrics that they had previously in the hope that the new process will improve the old metrics. This is almost certainly doomed to fail. You may have heard that “What gets measured gets managed.” A corollary to this might be that you can’t manage if you are measuring the wrong thing. We will discuss some metrics that are appropriate for agile programs in more detail later.
Metrics should not remain static. We want the goals and challenges that we have early in our agile transformation to be different from the issues and goals that we have two years from now.
For example, early on in the agile journey, we often have problems just getting teams to perform good agile practices and helping them to better manage work in progress. It will be difficult to scale until we can get these basics under control. Later, as we scale, the challenges may move to those related to reliable integration, thorough system testing, dependency management, and business outcome measurement. Perhaps we are having technical issues around balancing quality and reliability, and so there may be a focus on DevOps technical practices which might drive another set of metrics. The point is that our challenges and goals will change over time, and the key metrics that we track should change also.
Balance Business and Information Technology Metrics
VMO leaders should measure both business and delivery metrics. In general, there is way too much focus on schedule and cost estimates, delivery metrics, and compliance metrics and not nearly enough focus on business value metrics (see figure 2.6). Many large, expensive programs are way overburdened with delivery metrics but have no business outcome metrics. Measurements of feature usage, customer satisfaction, program profitability, customer retention, and feature-level return on investment are scant if they even exist at all. Neglecting these business metrics leads to questionable investments and investment performance management at best and hampers business agility. We will discuss this topic in more detail in chapter 7, but for now, the message is that we need just as much focus on businessside value metrics as there is on delivery metrics
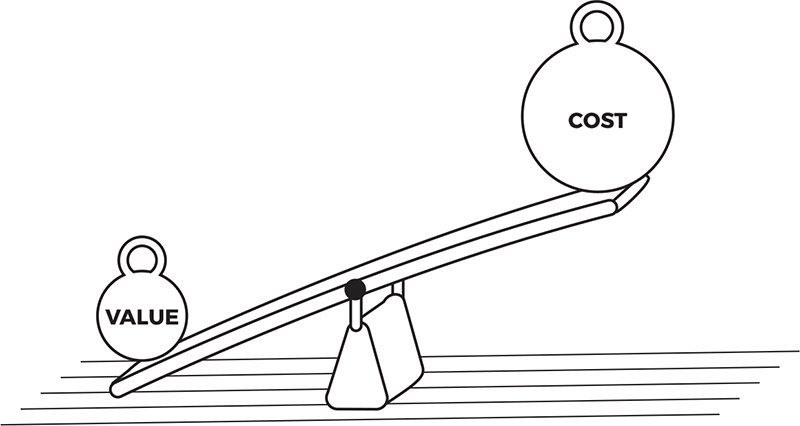
Figure 2.6: Balance value and cost
Unfortunately, business results or outcome metrics are lagging indicators in that they do not provide any measurement of success until after delivery happens. This feedback occurs way too late to be useful on traditional waterfall programs, because by the time we get the feedback, the program is over. However, there is one important way that the VMO should address the lagging indicator problem on agile programs: deliver early, deliver often, and measure business results repeatedly.
Using agile, we should be able to deliver something of value to a customer early and start to get fast and useful feedback as shown in figure 2.7. We do this over and over again and use that feedback to make each incremental release of the product better and better. Better can mean many things: increased customer usability, enhanced functionality, simplified functionality, and improved internal business results. Many organizations have a very misguided approach to agile in that they do not require that their programs deliver to production frequently enough. They go through many Sprints of development and try to maintain a single release near the end. This is basically just waterfall development and little more.
Figure 2.7: Incremental delivery
Agile is a feedback-based system, and the most reliable feedback is from real users, not from internal people who claim to speak on behalf of customers. To be agile, you need to deliver early and get the feedback, and the VMO should enforce this through governance and controls. In this regard, actual delivery metrics are critical. VMOs should measure how long it is before programs deliver their first release and how frequently they release. If there are no releases, then we simply aren’t doing agile.
That should take care of the lagging indicator issue to a great extent. That said, there are some leading indicators that can be measured during these short development cycles that might have value in predicting the likelihood of early delivery and of quality.
The classic Sprint and release burndown charts are great indicators of basic progress against scope and schedule (figure 2.8). Simply, a burndown chart shows what remains, while a burnup chart shows what has been done. The Sprint burndown gives an indication of short-term schedule performance. The release burnup gives an indication of longer-term schedule performance. They are both beautiful in their simplicity, yet sadly, many so-called agile teams neglect to produce them.
Sprint velocity is another simple and powerful metric that tries to show how predictable our teams are. Sprint-over-Sprint comparison of planned versus actual delivery measures what the teams estimated that they could get done versus what they actually got done, Sprint by Sprint, as shown in figure 2.9. Ideally, we’d like our teams to eventually get pretty good at being able to plan out what they can get done. The reality in many organizations, however, is that sometimes they get a lot done and sometimes they get zero done.
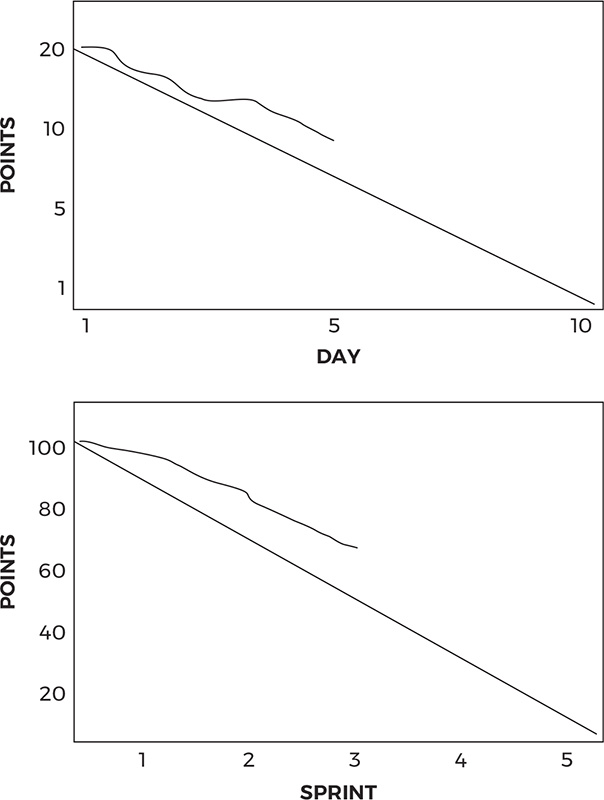
Figure 2.8: Sprint and release burndown charts
Problems can arise when teams have highly unpredictable delivery. It is hard to hit a planned delivery date when teams cannot reliably predict their velocity. Oftentimes, the issues are not the team’s fault. Just because a team cannot deliver what they planned does not mean the team is underperforming. There are often environment issues, data issues, network issues, team members getting pulled out to do other work, constant changes in priority, teams being asked to juggle three different efforts at the same time, and other things outside of their control that are causing the problems. Agile methods are fantastic for finding and highlighting all of the issues that keep us from delivering.

Figure 2.9: Estimation versus done in Sprint-by-Sprint comparison
Look for Patterns in the Metrics across Teams
Individual teams and their scrum masters and product owners will need to review their own data and develop action plans for continuous improvement. The VMO, however, should look a level up from the individual team metrics and try to uncover organizational patterns that are impacting multiple teams. If there are just a few teams that are struggling, then those particular teams may need attention and focus. In our experience, we usually see the opposite: most of the teams are struggling to deliver. If there are many teams that are unable to meet commitments, are experiencing serious issues, or have unpredictable delivery, then the problems are not with the teams themselves. When many teams experience challenges, this is a clear sign that larger organizational issues outside of any one team’s span of control are at play. Basically, leadership and management issues are not being adequately addressed.
Unfortunately, in many projectized organizations, there is no ownership of issues outside of individual teams or projects. There is often nobody who has clear ownership of how all projects interact with each other or how shared services and central financial systems and information security are supposed to integrate with a hundred different agile teams. The VMO should use the data that is coming in from the teams to try to uncover the larger issues that need higher levels of leadership to solve. Perhaps there are environment issues, database issues, tooling inadequacies, capacity issues, or other factors that are outside of any individual team’s ability to solve. This is one big area where the VMO can provide immense value: by addressing the systemic issues that keep the organization as a whole from being able to deliver.
Keep Metrics Simple and Small in Number
Table 2.3 has some sample metrics that some organizations use to measure agility at the team, program, and business level. These may be appropriate for an organization that is early in its agile maturity; more mature organizations may be ready to move on to the next level of performance metrics. Note that these are just a sample and your VMO should put significant thought into developing a small number of impactful metrics that will drive the kinds of specific behaviors and maturity that your organization needs in this particular moment.
Develop Process Controls as Natural Outputs of the Process
To have an auditable process, we need to have a defined process and clear evidence that it is being closely followed. This has an important corollary that VMOs are well advised to understand. Any activities that are required that are not a natural part of the agile process will take time away from the actual execution of the agile process. If you want teams to do good Scrum, then don’t make them spend tons of time doing things that aren’t Scrum.
For example, good agile teams will often develop big visible-information radiators that make plans and status and goals and priorities easily visible to all, as illustrated in figure 2.10. Taking a photo of team walls and regularly posting it to an internal wiki could potentially serve as evidence that the process is being followed without having to resort to creating time-consuming and soul-sapping documents that few are likely to ever read. By the 2020s pandemic age, most of us have transitioned to working from home and are using digital boards in tools like Jira. This has made process compliance easier, since all artifacts and reports are available in the tools themselves. Simple process controls such as these are not onerous or draconian or bureaucratic; quite simply, they are natural outcomes of good and disciplined execution of well-accepted agile process.
Metric Area |
Sample Metrics |
Business metrics |
Capture intended versus actual business outcome metrics per release or per quarter. These are the most important metrics but are often the most lacking. Examples include • account sign-ups • reduced help-desk calls • improved customer satisfaction surveys • improved customer retention • growth in application usage |
Program metrics |
• Number of integrations and system demos. It is only by integrating early and often, and by demoing the full system, that we can really know where we truly are in terms of progress and quality. All other interim metrics are guesses at best. • Feature-level progress. Features for the upcoming release will often be broken down into several lower-level user stories, and it can be advantageous to track how much of the planned feature is being delivered versus what was planned. This indicates the completeness of the feature. • Release burnup chart. Shows the cumulative point value of user stories planned for the release that are done as a function of time. By looking at this chart, we can estimate how much of the overall cumulative planned work for the release will be done by the planned release date. This indicates the completeness of the release versus what was planned. |
Team metrics |
• Points planned versus points delivered by Sprint in order to assess predictability • Sprint burndown to assess short-term schedule performance • Release burnup to assess long-term schedule performance • Mixture of work item types to measure how much of the team’s time is being applied to new-value delivery versus defect fixing or maintenance |

Figure 2.10: Information radiator
Embed Controls at Multiple Process Levels
As we scale agile to larger efforts with the approach we’ve laid out, we will have several levels of process discipline and controls. There are the team-level expectations that we discussed earlier. On top of that, we will likely need program-level controls to help manage the integrated efforts of many teams. And then portfolio-level controls are needed to effectively manage the overall flow of work through a larger organization. Once again, at each level, the controls should be natural outcomes of the agile process chosen. Table 2.4. is an example set of process controls at the team, program, and portfolio levels that are fairly consistent with most approaches to agile delivery. These can easily be tailored depending on your organization’s required level of audit and compliance rigor.
Table 2.4. Process Controls at Multiple Levels
Table 2.4 is just a sample of some of the key controls that your VMO will need to put in place in order to create an agile organization. These controls are all fairly natural outcomes of an organization that is operating using lean and agile principles. By this, we mean that these controls are organic to the process itself and that no additional documents or artifacts have been added simply because we’ve always done them or because they have been commonplace in the past.
Define Team-Level Agile Process Expectations
In talking with many teams over the years, we often hear that no clear expectations have been put in place around agile development and so they are left to define the process and the inputs and the outputs themselves. Naturally this leads to a significant amount of confusion and variation. In these organizations, no two agile teams operate the same way, few if any have a well-understood basic set of process steps, they often lack metrics, and they often skip key parts of the process such as continuous improvement or customer demos. Naturally, with not even basic standards in place, product development can often be somewhat chaotic. Note that this approach can and often does work at the individual team level. Small teams working on relatively small efforts that have minimal external dependencies may be able to work this way very successfully, but it is impossible to scale this level of variation across many teams without redundancy, waste, and misalignment between teams. It will also be difficult to use this sort of agile development to deliver large complex products. What works in a small team of 10 people with a few engineers and others who are creating a relatively small product will not likely work when you try to scale it up to hundreds or even thousands who are creating a power-plant control system, a satellite communications system, advanced embedded medical electronics, or financial trading systems that move billions of dollars. In addition, this level of variability likely will not meet the expectations for process definition and repeatability that most large organizations must be able to show. A basic level of process discipline is absolutely essential to create a larger agile organization. Watch out, though, because it is all too easy to kill agility with unnecessary overhead.
Define Program- and Portfolio-Level Agile Process Expectations
Similarly, multiple teams working at the program or portfolio levels should have clear expectations on what is required to pull the efforts of multiple teams together. Without strong coordination, each team can easily go in its own direction in terms of design decisions, user interface patterns, security, database access, and more. This can lead to some chaos where each team is meeting its individual goals but we are missing the attainment of a coherent, integrated system. To keep this from happening, we will need program-level expectations such as some of the following:
• frequent system builds, integration, testing, and demonstration
• forward planning sessions around dependency discovery, planning, and management
• architecture and design working groups who collaboratively decide and document how common technical issues will be handled
• program-wide retrospectives to improve coordination, planning, communications, and integration
• Scrum-of-scrums meetings where leaders from each team get together to jointly address challenges
• product-owner working groups that prioritize work for the program in a coherent way that results in useful functionality for the end user
The controls and process expectations needn’t be heavy or document rich. They do need to act as frequent checkpoints that constantly bring the teams back together again and work toward a single common system that doesn’t look and behave like it was created by 10 different teams.
Protect Delivery Teams from Bureaucracy
A fine balance is required if we are to be both disciplined and successful in achieving organizational agility. Teams cannot deliver valuable working software to customers if they are saddled with low-value, bureaucratic compliance overhead that detracts from their mission of delivery value to customers. The VMO must protect teams from this common issue. How can the VMO both protect teams from low-value process overhead while still achieving the high degrees of discipline needed to ship high-quality software early and often and have it done in ways that are defined and auditable? The answer is actually very simple: define what is meant by agile, set high expectations for teams to execute agile processes very well, and shield them from having to do anything that isn’t a normal part of generally accepted agile practices.
By working in this way, we achieve a well-defined process, a high degree of process excellence and repeatability, and a more agile organization.
CASE STUDY: PROCESS DEFINITION AT THE U.S. CITIZENSHIP AND IMMIGRATION SERVICES
The U.S. Citizenship and Immigration Services within the U.S. Department of Homeland Security is an amazing case study in large-scale organizational agility.3 The results of their agile adoption have been astounding, going from average release frequency of approximately every 180 days down to two weeks or less for most programs. Citizenship and Immigration Services started by developing a relatively simple process model that called for all teams to implement a handful of basic practices such as timeboxed iterations, continuous testing, iteration reviews, and retrospectives. The initial practices are marked by asterisks (*) in figure 2.11. Once a basic implementation of agile delivery had taken hold, they successively added additional process practices. These more advanced practices allowed the organization to mature and become successively more sophisticated in its adoption of agile.

Figure 2.11: Initial agile practices at U.S. Citizenship and Immigration Services
Summary
Scaling agility is difficult if not impossible without a certain level of process discipline. Agile methods allow us to move purposefully fast, and the faster we go, the more disciplined we need to be about our timing and practices. As we scale agility within our organizations, we reach a tipping point at which we are no longer able to fly under the radar and need to have a more defined, repeatable, and auditable agile process. The trick is to not overburden our processes with so much overhead that we lose the very agility that we seek. The key to scaling success is to maximize the extent to which we execute natural agile practices and minimize the extent to which we do anything that is not agile.
If our organization is going to scrum, then we should do scrum, do all of it, do it very well, and try to minimize the time that teams spend doing anything that isn’t scrum. Ditto for SAFe, Scrum at Scale, Nexus, Enterprise Kanban, or whatever framework we choose. Each of these frameworks comes with a natural set of process controls that will be organic outputs and outcomes of the process. Gravitate to these as your control points and standardize on these as ways to achieve both agility and compliance without excessive process overhead:
• Set firm process expectations that are grounded in a commonly accepted team-based or scaled agile approach.
• Do what the process frameworks call for, do it very well, and minimize any time doing process-related work that is not called for by the framework.
• Set expectations at multiple levels: team, program, and portfolio.
• Don’t expect to be great at everything right from the start. Choose a few practices to focus on at each level, and then add more advanced practices as the organization matures in its understanding of agile.
• Select a small number of metrics at the team, program, and business levels. Choose metrics that are focused on solving the problems that you are having today. Then later, when you have made progress on these problems, change the metrics to address the latest issues. In this way, you will have a measurement system that is relevant and useful for where your organization is right now.
• Combine the metrics to support a simple organizational change road map that takes you to higher and higher levels of agility. Use three levels of metrics to get a holistic view: business metrics, program metrics, and team metrics.
• Finally, focus on metrics patterns across teams. If many teams are struggling, the problem isn’t the teams, it is the organization in which they are trying to operate. Focus your energies on improving the organizational environment so that teams are working in a place where they can be successful. If many teams are unable to meet their objectives, then systemic issues in your organization likely are preventing most teams from getting work done. Get those addressed!