
5
Identification
In this chapter, we consider the problem of selecting an appropriate GARCH or ARMA‐GARCH model for given observations X 1,…, X n of a centred stationary process. A large part of the theory of finance rests on the assumption that prices follow a random walk. The price variation process, X = (X t ), should thus constitute a martingale difference sequence, and should coincide with its innovation process, ε = (ε t ). The first question addressed in this chapter, in Section 5.1, will be the test of this property, at least a consequence of it: absence of correlation. The problem is far from trivial because standard tests for non‐correlation are actually valid under an independence assumption. Such an assumption is too strong for GARCH processes which are dependent though uncorrelated.
If significant sample autocorrelations are detected in the price variations – in other words, if the random walk assumption cannot be sustained – the practitioner will try to fit an ARMA(P, Q) model to the data before using a GARCH(p, q) model for the residuals. Identification of the orders (P, Q) will be treated in Section 5.2, identification of the orders (p, q) in Section 5.3. Tests of the ARCH effect (and, more generally, Lagrange multiplier (LM) tests) will be considered in Section 5.4.
5.1 Autocorrelation Check for White Noise
Consider the GARCH(p, q) model

with (η
t
) a sequence of iid centred variables with unit variance,
ω > 0,
α
i
≥ 0
(i = 1,…, q),
β
j
≥ 0
(j = 1,…, p). We saw in Section 2.2 that, whatever the orders
p
and
q
, the non‐anticipative second‐order stationary solution of model (5.1) is a white noise, that is, a centred process whose theoretical autocorrelations ![]() satisfy
ρ (h) = 0 for all
h ≠ 0.
satisfy
ρ (h) = 0 for all
h ≠ 0.
Given observations ε1,…, ε n , the theoretical autocorrelations of a centred process (ε t ), are generally estimated by the sample autocorrelations (SACRs)

for h = 0, 1,…, n − 1. According to Theorem 1.1, if (ε t ) is an iid sequence of centred random variables with finite variance, then
for all
h ≠ 0. For a strong white noise, the SACRs thus lie between the confidence bounds ![]() with a probability of approximately 95% when
n
is large. In standard software, these bounds at the 5% level are generally displayed with dotted lines, as in Figure 5.2. These significance bands are not valid for a weak white noise, in particular for a GARCH process (Exercises 5.3 and 5.4). Valid asymptotic bands are derived in the next section.
with a probability of approximately 95% when
n
is large. In standard software, these bounds at the 5% level are generally displayed with dotted lines, as in Figure 5.2. These significance bands are not valid for a weak white noise, in particular for a GARCH process (Exercises 5.3 and 5.4). Valid asymptotic bands are derived in the next section.
5.1.1 Behaviour of the Sample Autocorrelations of a GARCH Process
Let ![]() denote the vector of the first
m
SACRs, based on
n
observations of the GARCH(p, q) process defined by model ( 5.1). Let
denote the vector of the first
m
SACRs, based on
n
observations of the GARCH(p, q) process defined by model ( 5.1). Let ![]() denote a vector of sample autocovariances (SACVs).
denote a vector of sample autocovariances (SACVs).
Note that ![]() when (ε
t
) is a strong white noise, in accordance with Theorem 1.1.
when (ε
t
) is a strong white noise, in accordance with Theorem 1.1.
A consistent estimator ![]() of
of ![]() is obtained by replacing the generic term of
is obtained by replacing the generic term of ![]() by
by

with, by convention, ε
s
= 0 for
s < 1. Clearly, ![]() is a consistent estimator of
is a consistent estimator of ![]() and is almost surely invertible for
n
large enough. This can be used to construct asymptotic significance bands for the SACRs of a GARCH process.
and is almost surely invertible for
n
large enough. This can be used to construct asymptotic significance bands for the SACRs of a GARCH process.
Practical Implementation
The following R code allows us to draw a given number of autocorrelations ![]() and the significance bands
and the significance bands ![]() .
.
# autocorrelation functiongamma<-function(x,h){ n<-length(x); h<-abs(h);x<-x-mean(x)gamma<-sum(x[1:(n-h)]*x[(h+1):n])/n }rho<-function(x,h) rho<-gamma(x,h)/gamma(x,0)# acf function with significance bands of a weak white noisenl.acf<-function(x,main=NULL,method="NP"){n<-length(x); nlag<-as.integer(min(10*log10(n),n-1))acf.val<-sapply(c(1:nlag),function(h) rho(x,h)); x2<-x^2var<-1+(sapply(c(1:nlag),function(h) gamma(x2,h)))/gamma(x,0)^2band<-sqrt(var/n)minval<-1.2*min(acf.val,-1.96*band,-1.96/sqrt(n))maxval<-1.2*max(acf.val,1.96*band,1.96/sqrt(n))acf(x,xlab="Lag",ylab="SACR",ylim=c(minval,maxval),main=main)lines(c(1:nlag),-1.96*band,lty=1,col="red")lines(c(1:nlag),1.96*band,lty=1,col="red") }
In Figure 5.1 we have plotted the SACRs and their significance bands for daily series of exchange rates of the dollar, pound, yen and Swiss franc against the euro, for the period from 4 January 1999 to 22 January 2009. It can be seen that the SACRs are often outside the standard significance bands ![]() , which leads us to reject the strong white noise assumption for all these series. On the other hand, most of the SACRs are inside the significance bands shown as solid lines, which is in accordance with the hypothesis that the series are realizations of semi‐strong white noises.
, which leads us to reject the strong white noise assumption for all these series. On the other hand, most of the SACRs are inside the significance bands shown as solid lines, which is in accordance with the hypothesis that the series are realizations of semi‐strong white noises.

Figure 5.1 SACR of exchange rates against the euro, standard significance bands for the SACRs of a strong white noise (dotted lines) and significance bands for the SACRs of a semi‐strong white noise (solid lines).
5.1.2 Portmanteau Tests
The standard portmanteau test for checking that the data is a realization of a strong white noise is that of Ljung and Box (1978). It involves computing the statistic

and rejecting the strong white noise hypothesis if ![]() is greater than the (1 − α)‐quantile of a
is greater than the (1 − α)‐quantile of a ![]() .
2
.
2
Portmanteau tests are constructed for checking non‐correlation, but the asymptotic distribution of the statistics is no longer ![]() when the series departs from the strong white noise assumption. For instance, these tests are not robust to conditional heteroscedasticity. In the GARCH framework, we may wish to simultaneously test the nullity of the first
m
autocorrelations using more robust portmanteau statistics.
when the series departs from the strong white noise assumption. For instance, these tests are not robust to conditional heteroscedasticity. In the GARCH framework, we may wish to simultaneously test the nullity of the first
m
autocorrelations using more robust portmanteau statistics.
A portmanteau test of asymptotic level
α
based on the first
m
SACRs involves rejecting the hypothesis that the data are generated by a GARCH process if
Q
m
is greater than the (1 − α)‐quantile of a ![]() .
.
5.1.3 Sample Partial Autocorrelations of a GARCH
Denote by
r
m
(![]() ) the vector of the
m
first partial autocorrelations (sample partial autocorrelations (SPACs)) of the process (ε
t
). By Theorem B.3, we know that for a weak white noise, the SACRs and SPACs have the same asymptotic distribution. This applies in particular to a GARCH process. Consequently, under the hypothesis of GARCH white noise with a finite fourth‐order moment, consistent estimators of
) the vector of the
m
first partial autocorrelations (sample partial autocorrelations (SPACs)) of the process (ε
t
). By Theorem B.3, we know that for a weak white noise, the SACRs and SPACs have the same asymptotic distribution. This applies in particular to a GARCH process. Consequently, under the hypothesis of GARCH white noise with a finite fourth‐order moment, consistent estimators of ![]() are
are
where ![]() is the matrix obtained by replacing
ρ
X
(1),…,
ρ
X
(m) by
is the matrix obtained by replacing
ρ
X
(1),…,
ρ
X
(m) by ![]() ,…,
,…, ![]() in the Jacobian matrix
J
m
of the mapping
ρ
m
↦ r
m
, and
in the Jacobian matrix
J
m
of the mapping
ρ
m
↦ r
m
, and ![]() is the consistent estimator of
is the consistent estimator of ![]() defined after Theorem 5.1.
defined after Theorem 5.1.
Although it is not current practice, one can test the simultaneous nullity of several theoretical partial autocorrelations using portmanteau tests based on the statistics
with, for instance,
i = 2. From Theorem B.3, under the strong white noise assumption, the statistics ![]() ,
, ![]() , and
, and ![]() have the same
have the same ![]() asymptotic distribution. Under the hypothesis of a pure GARCH process, the statistics
asymptotic distribution. Under the hypothesis of a pure GARCH process, the statistics ![]() and
Q
m
also have the same
and
Q
m
also have the same ![]() asymptotic distribution.
asymptotic distribution.
5.1.4 Numerical Illustrations
Standard Significance Bounds for the SACRs are Not Valid
The right‐hand graph of Figure 5.2 displays the sample correlogram of a simulation of size n = 5000 of the GARCH(1, 1) white noise


Figure 5.2
SACRs of a simulation of a strong white noise (a) and of the GARCH(1, 1) white noise (5.4) (b). Approximately 95% of the SACRs of a strong white noise should lie inside the thin dotted lines  . Approximately 95% of the SACRs of a GARCH(1, 1) white noise should lie inside the thick dotted lines.
. Approximately 95% of the SACRs of a GARCH(1, 1) white noise should lie inside the thick dotted lines.
where (η
t
) is a sequence of iid ![]() variables. It is seen that the SACRs of order 2 and 4 are sharply outside the 95% significance bands computed under the strong white noise assumption. An inexperienced practitioner could be tempted to reject the hypothesis of white noise, in favour of a more complicated ARMA model whose residual autocorrelations would lie between the significance bounds
variables. It is seen that the SACRs of order 2 and 4 are sharply outside the 95% significance bands computed under the strong white noise assumption. An inexperienced practitioner could be tempted to reject the hypothesis of white noise, in favour of a more complicated ARMA model whose residual autocorrelations would lie between the significance bounds ![]() . To avoid this type of specification error, one has to be conscious that the bounds
. To avoid this type of specification error, one has to be conscious that the bounds ![]() are not valid for the SACRs of a GARCH white noise. In our simulation, it is possible to compute exact asymptotic bounds at the 95% level (Exercise 5.4). In the right‐hand graph of Figure 5.2, these bounds are drawn in thick dotted lines. All the SACRs are now inside, or very slightly outside, those bounds. If we had been given the data, with no prior information, this graph would have given us no grounds on which to reject the simple hypothesis that the data is a realization of a GARCH white noise.
are not valid for the SACRs of a GARCH white noise. In our simulation, it is possible to compute exact asymptotic bounds at the 95% level (Exercise 5.4). In the right‐hand graph of Figure 5.2, these bounds are drawn in thick dotted lines. All the SACRs are now inside, or very slightly outside, those bounds. If we had been given the data, with no prior information, this graph would have given us no grounds on which to reject the simple hypothesis that the data is a realization of a GARCH white noise.
Estimating the Significance Bounds of the SACRs of a GARCH
Of course, in real situations, the significance bounds depend on unknown parameters, and thus cannot be easily obtained. It is, however, possible to estimate them in a consistent way, as described in Section 5.1.1. For a simulation of model ( 5.4) of size n = 5000, Figure 5.3 shows as thin dotted lines the estimation thus obtained of the significance bounds at the 5% level. The estimated bounds are fairly close to the exact asymptotic bounds.

Figure 5.3 Sample autocorrelations of a simulation of size n = 5000 of the GARCH(1, 1) white noise ( 5.4). Approximately 95% of the SACRs of a GARCH(1, 1) white noise should lie inside the thin dotted lines. The exact asymptotic bounds are shown as thick dotted lines.
The SPACs and Their Significance Bounds
Figure 5.4 shows the SPACs of the simulation ( 5.4) and the estimated significance bounds of the ![]() , at the 5% level (based on
, at the 5% level (based on ![]() ). By comparing Figures 5.3 and 5.4, it can be seen that the SACRs and SPACs of the GARCH simulation look much alike. This is not surprising in view of Theorem B.4.
). By comparing Figures 5.3 and 5.4, it can be seen that the SACRs and SPACs of the GARCH simulation look much alike. This is not surprising in view of Theorem B.4.

Figure 5.4 Sample partial autocorrelations of a simulation of size n = 5000 of the GARCH(1, 1) white noise ( 5.4). Approximately 95% of the SPACs of a GARCH(1, 1) white noise should lie inside the thin dotted lines. The exact asymptotic bounds are shown as thick dotted lines.
Portmanteau Tests of Strong White Noise and of Pure GARCH
Table 5.1 displays p ‐values of white noise tests based on Q m and the usual Ljung–Box statistics, for the simulation of ( 5.4). Apart from the test with m = 4, the Q m tests do not reject, at the 5% level, the hypothesis that the data comes from a GARCH process. On the other hand, the Ljung–Box tests clearly reject the strong white noise assumption.
Portmanteau tests on a simulation of size n = 5000 of the GARCH(1, 1) white noise ( 5.4).
| m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Tests based on Q m , for the hypothesis of GARCH white noise | ||||||||||||
|
|
0.00 | 0.06 | 0.03 | 0.05 | 0.02 | 0.00 | 0.02 | 0.01 | 0.02 | 0.02 | 0.00 | 0.01 |
|
|
0.025 | 0.028 | 0.024 | 0.024 | 0.021 | 0.026 | 0.019 | 0.023 | 0.019 | 0.016 | 0.017 | 0.015 |
| Q m | 0.00 | 4.20 | 5.49 | 10.19 | 10.90 | 10.94 | 12.12 | 12.27 | 13.16 | 14.61 | 14.67 | 15.20 |
|
|
0.9637 | 0.1227 | 0.1391 | 0.0374 | 0.0533 | 0.0902 | 0.0967 | 0.1397 | 0.1555 | 0.1469 | 0.1979 | 0.2306 |
| Usual tests, for the strong white noise hypothesis | ||||||||||||
|
|
0.00 | 0.06 | 0.03 | 0.05 | 0.02 | 0.00 | 0.02 | 0.01 | 0.02 | 0.02 | 0.00 | 0.01 |
|
|
0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 |
|
|
0.01 | 16.78 | 20.59 | 34.18 | 35.74 | 35.86 | 38.05 | 38.44 | 39.97 | 41.82 | 41.91 | 42.51 |
|
|
0.9365 | 0.0002 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
Portmanteau Tests Based on Partial Autocorrelations
Table 5.2 is similar to Table 5.1, but presents portmanteau tests based on the SPACs. As expected, the results are very close to those obtained for the SACRs.
As Table 5.1, for tests based on partial autocorrelations instead of autocorrelations.
| m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|
GARCH white noise tests based on |
||||||||||||
|
|
0.00 | 0.06 | 0.03 | 0.05 | 0.02 | 0.00 | 0.02 | 0.01 | 0.01 | 0.02 | 0.00 | 0.01 |
|
|
0.025 | 0.028 | 0.024 | 0.024 | 0.021 | 0.026 | 0.019 | 0.023 | 0.019 | 0.016 | 0.017 | 0.015 |
|
|
0.00 | 4.20 | 5.49 | 9.64 | 10.65 | 10.650 | 11.92 | 12.24 | 12.77 | 14.24 | 14.24 | 14.67 |
|
|
0.9637 | 0.1227 | 0.1393 | 0.0470 | 0.0587 | 0.0998 | 0.1032 | 0.1407 | 0.1735 | 0.1623 | 0.2200 | 0.2599 |
|
Strong white noise tests based on |
||||||||||||
|
|
0.02 | 0.01 | 0.01 | 0.02 | 0.00 | 0.01 | 0.02 | 0.01 | 0.01 | 0.02 | 0.00 | 0.01 |
|
|
0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 | 0.014 |
|
|
0.01 | 16.77 | 20.56 | 32.55 | 34.76 | 34.76 | 37.12 | 37.94 | 38.84 | 40.71 | 40.71 | 41.20 |
|
|
0.9366 | 0.0002 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
An Example Showing that Portmanteau Tests Based on the SPACs Can Be More Powerful than Those Based on the SACRs
Consider a simulation of size n = 100 of the strong MA(2) model
By comparing the top two and bottom two parts of Table 5.3, we note that the hypotheses of strong white noise and pure GARCH are better rejected when the SPACs, rather than the SACRs, are used. This follows from the fact that, for this MA(2), only two theoretical autocorrelations are not equal to 0, whereas many theoretical partial autocorrelations are far from 0. For the same reason, the results would have been inverted if, for instance, an AR(1) alternative had been considered.
White noise portmanteau tests on a simulation of size n = 100 of the MA(2) model (5.5).
| m | 1 | 2 | 3 | 4 | 5 | 6 |
| Tests of GARCH white noise based on autocorrelations | ||||||
| Q m | 1.6090 | 4.5728 | 5.5495 | 6.2271 | 6.2456 | 6.4654 |
|
|
0.2046 | 0.1016 | 0.1357 | 0.1828 | 0.2830 | 0.3731 |
| Tests of GARCH white noise based on partial autocorrelations | ||||||
|
|
1.6090 | 5.8059 | 9.8926 | 16.7212 | 21.5870 | 25.3162 |
|
|
0.2046 | 0.0549 | 0.0195 | 0.0022 | 0.0006 | 0.0003 |
| Tests of strong white noise based on autocorrelations | ||||||
|
|
3.4039 | 8.4085 | 9.8197 | 10.6023 | 10.6241 | 10.8905 |
|
|
0.0650 | 0.0149 | 0.0202 | 0.0314 | 0.0594 | 0.0918 |
| Tests of strong white noise based on partial autocorrelations | ||||||
|
|
3.3038 | 10.1126 | 15.7276 | 23.1513 | 28.4720 | 32.6397 |
|
|
0.0691 | 0.0064 | 0.0013 | 0.0001 | 0.0000 | 0.0000 |
5.2 Identifying the ARMA Orders of an ARMA‐GARCH
Assume that the tools developed in Section 5.1 lead to rejection of the hypothesis that the data is a realisation of a pure GARCH process. It is then sensible to look for an ARMA(P, Q) model with GARCH innovations. The problem is then to choose (or identify) plausible orders for the model

under standard assumptions (the AR and MA polynomials having no common root and having roots outside the unit disk, with
a
P
b
Q
≠ 0, ![]() ), where (ε
t
) is a GARCH white noise of the form ( 5.1).
), where (ε
t
) is a GARCH white noise of the form ( 5.1).
5.2.1 Sample Autocorrelations of an ARMA‐GARCH
Recall that an MA(Q) satisfies ρ X (h) = 0 for all h > Q , whereas an AR( P ) satisfies r X (h) = 0 for all h > P . The SACRs and SPACs thus play an important role in identifying the orders P and Q .
Invalidity of the Standard Bartlett Formula and Modified Formula
The validity of the usual Bartlett formula rests on assumptions including the strong white noise hypothesis (Theorem 1.1) which are obviously incompatible with GARCH errors. We shall see that this formula leads to an underestimation of the variances of the SACRs and SPACs, and thus to erroneous ARMA orders. We shall only consider the SACRs because Theorem B.2 shows that the asymptotic behaviour of the SPACs easily follows from that of the SACRs.
We assume throughout that the law of
η
t
is symmetric. By Theorem B.5, the asymptotic behaviour of the SACRs is determined by the generalised Bartlett formula (B.15). This formula involves the theoretical autocorrelations of (X
t
) and ![]() , as well as the ratio
, as well as the ratio ![]() . More precisely, using Remark 1 of Theorem 7.2.2 in Brockwell and Davis (1991), the generalised Bartlett formula is written as
. More precisely, using Remark 1 of Theorem 7.2.2 in Brockwell and Davis (1991), the generalised Bartlett formula is written as
where
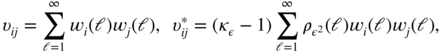
and
The following result shows that the standard Bartlett formula always underestimates the asymptotic variances of the sample autocorrelations in presence of GARCH errors.
Consider, by way of illustration, the ARMA(2,1)‐GARCH(1, 1) process defined by

Figure 5.5 shows the theoretical autocorrelations and partial autocorrelations for this model. The bands shown as solid lines should contain approximately 95% of the SACRs and SPACs, for a realisation of size
n = 1000 of this model. These bands are obtained from formula (B.15), the autocorrelations of ![]() being computed as in Section 2.5.3. The bands shown as dotted lines correspond to the standard Bartlett formula (still at the 95% level). It can be seen that using this formula, which is erroneous in the presence of GARCH, would lead to identification errors because it systematically underestimates the variability of the sample autocorrelations (Proposition 5.1).
being computed as in Section 2.5.3. The bands shown as dotted lines correspond to the standard Bartlett formula (still at the 95% level). It can be seen that using this formula, which is erroneous in the presence of GARCH, would lead to identification errors because it systematically underestimates the variability of the sample autocorrelations (Proposition 5.1).

Figure 5.5 Autocorrelations (a) and partial autocorrelations (b) for model (5.8). Approximately 95% of the SACRs (SPACs) of a realisation of size n = 1000 should lie between the bands shown as solid lines. The bands shown as dotted lines correspond to the standard Bartlett formula.
Algorithm for Estimating the Generalised Bands
In practice, the autocorrelations of (X
t
) and ![]() , as well as the other theoretical quantities involved in the generalized Bartlett formula (B.15), are obviously unknown. We propose the following algorithm for estimating such quantities:
, as well as the other theoretical quantities involved in the generalized Bartlett formula (B.15), are obviously unknown. We propose the following algorithm for estimating such quantities:
- Fit an AR(p 0) model to the data X 1,…, X n using an information criterion for the selection of the order p 0 .
- Compute the autocorrelations ρ 1(h), h = 1, 2,…, of this AR(p 0) model.
- Compute the residuals
 of this estimated AR(p
0).
of this estimated AR(p
0). - Fit an AR(p
1) model to the squared residuals
 , again using an information criterion for
p
1
.
, again using an information criterion for
p
1
. - Compute the autocorrelations ρ 2(h), h = 1, 2,…, of this AR(p 1) model.
- Estimate
 by
by  , where
, where


and ℓmax is a truncation parameter, numerically determined so as to have ∣ρ 1(ℓ)∣ and ∣ρ 2(ℓ)∣ less than a certain tolerance (for instance, 10−5 ) for all ℓ > ℓmax .
This algorithm is fast when the Durbin–Levinson algorithm is used to fit the AR models. Figure 5.6 shows an application of this algorithm (using the BIC information criterion).

Figure 5.6 SACRs (a) and SPACs (b) of a simulation of size n = 1000 of model ( 5.8). The dotted lines are the estimated 95% confidence bands.
5.2.2 Sample Autocorrelations of an ARMA‐GARCH Process When the Noise is Not Symmetrically Distributed
The generalised Bartlett formula (B.15) holds under condition (B.13), which may not be satisfied if the distribution of the noise
η
t
, in the GARCH equation, is not symmetric. We shall consider the asymptotic behaviour of the SACVs and SACRs for very general linear processes whose innovation (ε
t
) is a weak white noise. Retaining the notation of Theorem B.5, the following property allows the asymptotic variance of the SACRs to be interpreted as the spectral density at 0 of a vector process (see, for instance, Brockwell and Davis 1991, for the concept of spectral density). Let ![]() .
.
The matrix ![]() involved in (5.9) is called the long‐run variance in the econometric literature, as a reminder that it is the limiting variance of a sample mean. Several methods can be considered for long‐run variance estimation.
involved in (5.9) is called the long‐run variance in the econometric literature, as a reminder that it is the limiting variance of a sample mean. Several methods can be considered for long‐run variance estimation.
- (i) The naive estimator based on replacing the Γϒ(h) by the
 in
in  is inconsistent (Exercise 1.2). However, a consistent estimator can be obtained by weighting the
is inconsistent (Exercise 1.2). However, a consistent estimator can be obtained by weighting the  , using a weight close to 1 when
h
is very small compared to
n
, and a weight close to 0 when
h
is large. Such an estimator is called heteroscedastic and autocorrelation consistent (HAC) in the econometric literature.
, using a weight close to 1 when
h
is very small compared to
n
, and a weight close to 0 when
h
is large. Such an estimator is called heteroscedastic and autocorrelation consistent (HAC) in the econometric literature. - (ii) A consistent estimator of
 can also be obtained using the smoothed periodogram (see Brockwell and Davis 1991, Section 10.4).
can also be obtained using the smoothed periodogram (see Brockwell and Davis 1991, Section 10.4). - (iii) For a vector AR(r),

the spectral density at 0 is
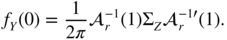
A vector AR model is easily fitted, even a high‐order AR, using a multivariate version of the Durbin–Levinson algorithm (see Brockwell and Davis 1991, p. 422). The following method can thus be proposed:
- 1. Fit AR(
r
) models, with
r = 0, 1…, R
, to the data
 where
where 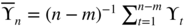 .
. - 2. Select a value r 0 by minimising an information criterion, for instance the BIC.
- 3. Take

with obvious notation.
In our applications, we used method (iii).
- 1. Fit AR(
r
) models, with
r = 0, 1…, R
, to the data
5.2.3 Identifying the Orders (P, Q)
Order determination based on the sample autocorrelations and partial autocorrelations in the mixed ARMA(P, Q) model is not an easy task. Other methods, such as the corner method, presented in the next section, and the epsilon algorithm, rely on more convenient statistics.
The Corner Method
Denote by D(i, j) the j × j Toeplitz matrix

and let Δ(i, j) denote its determinant. Since ![]() , for all
h > Q
, it is clear that
D(i, j) is not a full‐rank matrix if
i > Q
and
j > P
. More precisely,
P
and
Q
are minimal orders (that is, (X
t
) does not admit an ARMA(P
′, Q
′) representation with
P
′ < P
or
Q
′ < Q
) if and only if
, for all
h > Q
, it is clear that
D(i, j) is not a full‐rank matrix if
i > Q
and
j > P
. More precisely,
P
and
Q
are minimal orders (that is, (X
t
) does not admit an ARMA(P
′, Q
′) representation with
P
′ < P
or
Q
′ < Q
) if and only if

The minimal orders P and Q are thus characterised by the following table:
| ij | 1 | 2 | · | · | · | Q | Q + 1 | · | · | · | · | |
| 1 | ρ 1 | ρ 2 | · | · | · | ρ q | ρ q + 1 | · | · | · | · | |
| · | ||||||||||||
| · | ||||||||||||
| (T1) | · | |||||||||||
| P | × | × | × | × | × | × | ||||||
| P + 1 | × | 0 | 0 | 0 | 0 | 0 | ||||||
| × | 0 | 0 | 0 | 0 | 0 | |||||||
| × | 0 | 0 | 0 | 0 | 0 | |||||||
| × | 0 | 0 | 0 | 0 | 0 |
where Δ(j, i) is at the intersection of row i and column j , and × denotes a non‐zero element.
The orders P and Q are thus characterised by a corner of zeros in table (T 1), hence the term ‘corner method’. The entries in this table are easily obtained using the recursion on j given by
and letting Δ(i, 0) = 1, Δ(i, 1) = ρ X (∣i∣).
Denote by ![]() ,
, ![]() ,
, ![]() , … the items obtained by replacing {ρ
X
(h)} by
, … the items obtained by replacing {ρ
X
(h)} by ![]() in
D(i, j), Δ(i, j), (T1), …. Only a finite number of SACRs
in
D(i, j), Δ(i, j), (T1), …. Only a finite number of SACRs ![]() are available in practice, which allows
are available in practice, which allows ![]() to be computed for
i ≥ 1,
j ≥ 1 and
i + j ≤ K + 1. Table
to be computed for
i ≥ 1,
j ≥ 1 and
i + j ≤ K + 1. Table ![]() is thus triangular. Because
is thus triangular. Because ![]() consistently estimates Δ(j, i), the orders
P
and
Q
are characterised by a corner of small values in table
consistently estimates Δ(j, i), the orders
P
and
Q
are characterised by a corner of small values in table ![]() . However, the notion of ‘small value’ in
. However, the notion of ‘small value’ in ![]() is not precise enough.
3
is not precise enough.
3
It is preferable to consider the Studentised statistics defined, for i = − K,…, K and j = 0,…, K − ∣ i ∣ + 1, by

where ![]() is a consistent estimator of the asymptotic covariance matrix of the first
K
SACRs, which can be obtained by the algorithm of Section 5.2.1 or by that of Section 5.2.2, and where the Jacobian
is a consistent estimator of the asymptotic covariance matrix of the first
K
SACRs, which can be obtained by the algorithm of Section 5.2.1 or by that of Section 5.2.2, and where the Jacobian ![]() is obtained from the differentiation of (5.11):
is obtained from the differentiation of (5.11):

for k = 1,…, K , i = − K + j,…, K − j and j = 1,…, K .
When Δ(i, j) = 0, the statistic
t(i, j) asymptotically follows a ![]() (provided, in particular, that
(provided, in particular, that ![]() exists). If, in contrast, Δ(i, j) ≠ 0 then
exists). If, in contrast, Δ(i, j) ≠ 0 then ![]() when
n → ∞. We can reject the hypothesis Δ(i, j) = 0 at level
α
if ∣t(i, j)∣ is beyond the (1 − α/2)‐quantile of a
when
n → ∞. We can reject the hypothesis Δ(i, j) = 0 at level
α
if ∣t(i, j)∣ is beyond the (1 − α/2)‐quantile of a ![]() . We can also automatically detect a corner of small values in the table giving the
t(i, j), if no entry in this corner is greater than this (1 − α/2)‐quantile in absolute value. This practice does not correspond to any formal test at level
α
, but allows a small number of plausible values to be selected for the orders
P
and
Q
.
. We can also automatically detect a corner of small values in the table giving the
t(i, j), if no entry in this corner is greater than this (1 − α/2)‐quantile in absolute value. This practice does not correspond to any formal test at level
α
, but allows a small number of plausible values to be selected for the orders
P
and
Q
.
Illustration of the Corner Method
For a simulation of size n = 1000 of the ARMA(2,1)‐GARCH(1, 1) model ( 5.8), we obtain the following table:
.p.|.q..1....2....3....4....5....6....7....8....9...10...11...12...1 | 17.6-31.6-22.6 -1.9 11.5 8.7 -0.1 -6.1 -4.2 0.5 3.5 2.12 | 36.1 20.3 12.2 8.7 6.5 4.9 4.0 3.3 2.5 2.1 1.83 | -7.8 -1.6 -0.2 0.5 0.7 -0.7 0.8 -1.4 1.2 -1.14 | 5.2 0.1 0.4 0.3 0.6 -0.1 -0.3 0.5 -0.25 | -3.7 0.4 -0.1 -0.5 0.4 -0.2 0.2 -0.26 | 2.8 0.6 0.5 0.4 0.2 0.4 0.27 | -2.0 -0.7 0.2 0.0 -0.4 -0.38 | 1.7 0.8 0.0 0.2 0.29 | -0.6 -1.2 -0.5 -0.210 | 1.4 0.9 -0.211 | -0.2 -1.212 | 1.2
A corner of values which can be viewed as plausible realisations of the ![]() can be observed. This corner corresponds to the rows 3, 4, … and the columns 2, 3, …, leading us to select the ARMA(2, 1) model. The automatic detection routine for corners of small values gives:
can be observed. This corner corresponds to the rows 3, 4, … and the columns 2, 3, …, leading us to select the ARMA(2, 1) model. The automatic detection routine for corners of small values gives:
ARMA(P,Q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVELPROBA CRIT MODELS FOUND0.200000 1.28 ( 2, 8) ( 3, 1) (10, 0)0.100000 1.64 ( 2, 1) ( 8, 0)0.050000 1.96 ( 1,10) ( 2, 1) ( 7, 0)0.020000 2.33 ( 0,11) ( 1, 9) ( 2, 1) ( 6, 0)0.010000 2.58 ( 0,11) ( 1, 8) ( 2, 1) ( 6, 0)0.005000 2.81 ( 0,11) ( 1, 8) ( 2, 1) ( 5, 0)0.002000 3.09 ( 0,11) ( 1, 8) ( 2, 1) ( 5, 0)0.001000 3.29 ( 0,11) ( 1, 8) ( 2, 1) ( 5, 0)0.000100 3.72 ( 0, 9) ( 1, 7) ( 2, 1) ( 5, 0)0.000010 4.26 ( 0, 8) ( 1, 6) ( 2, 1) ( 4, 0)
We retrieve not only the orders (P, Q) = (2, 1) of the simulated model but also other plausible orders. This is not surprising since the ARMA(2, 1) model can be well approximated by other ARMA models, such as an AR(6), an MA(11) or an ARMA(1, 8) (but in practice, the ARMA(2, 1) should be preferred for parsimony reasons).
5.3 Identifying the GARCH Orders of an ARMA‐GARCH Model
The Box–Jenkins methodology described in Chapter 1 for ARMA models can be adapted to GARCH(p, q) models. In this section, we consider only the identification problem. First, suppose that the observations are drawn from a pure GARCH. The choice of a small number of plausible values for the orders p and q can be achieved in several steps, using various tools:
- (i) inspection of the sample autocorrelations and SPACs of
 ;
; - (ii) inspection of statistics that are functions of the sample autocovariances of
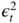 (corner method, epsilon algorithm, etc.);
(corner method, epsilon algorithm, etc.); - (iii) use of information criteria (AIC, BIC, etc.);
- (iv) tests of the significance of certain coefficients;
- (v) analysis of the residuals.
Steps (iii) and (v), and to a large extent step (iv), require the estimation of models and are used to validate or modify them. Estimation of GARCH models will be studied in detail in the forthcoming chapters. Step (i) relies on the ARMA representation for the square of a GARCH process. In particular, if (ε
t
) is an ARCH(q) process, then the theoretical partial autocorrelation function ![]() of
of ![]() satisfies
satisfies
For mixed models, the corner method can be used.
5.3.1 Corner Method in the GARCH Case
To identify the orders of a GARCH(p, q) process, one can use the fact that ![]() follows an ARMA
follows an ARMA![]() with
with ![]() and
and ![]() . In the case of a pure GARCH, (ε
t
) = (X
t
) is observed. The asymptotic variance of the SACRs of
. In the case of a pure GARCH, (ε
t
) = (X
t
) is observed. The asymptotic variance of the SACRs of ![]() can be estimated by the method described in Section 5.2.2 . The table of Studentised statistics for the corner method follows, as described in the previous section. The problem is then to detect at least one corner of normal values starting from the row
can be estimated by the method described in Section 5.2.2 . The table of Studentised statistics for the corner method follows, as described in the previous section. The problem is then to detect at least one corner of normal values starting from the row ![]() and the column
and the column ![]() of the table, under the constraints
of the table, under the constraints ![]() (because max(p, q) ≥ q ≥ 1) and
(because max(p, q) ≥ q ≥ 1) and ![]() . This leads to a selection of GARCH(p, q) models such that
. This leads to a selection of GARCH(p, q) models such that ![]() when
when ![]() and
and ![]()
![]() when
when ![]() .
.
In the ARMA‐GARCH case, the ε t is unobserved but can be approximated by the ARMA residuals. Alternatively, to avoid the ARMA estimation, residuals from fitted ARs, as described in steps 1 and 3 of the algorithm of Section 5.2.1 , can be used.
5.3.2 Applications
A Pure GARCH
Consider a simulation of size n = 5000 of the GARCH(2, 1) model

where (η
t
) is a sequence of iid ![]() variables,
ω = 1,
α = 0.1,
β
1 = 0.05 and
β
2 = 0.8.
variables,
ω = 1,
α = 0.1,
β
1 = 0.05 and
β
2 = 0.8.
The table of Studentised statistics for the corner method is as follows:
.max(p,q).|.p..1....2....3....4....5....6....7....8....9...10...11...12...13...14...15...1 | 5.3 2.9 5.1 2.2 5.3 5.9 3.6 3.7 2.9 2.9 3.4 1.4 5.8 2.4 3.02 | -2.4 -3.5 2.4 -4.4 2.2 -0.7 0.6 -0.7 -0.3 0.4 1.1 -2.5 2.8 -0.23 | 4.9 2.4 0.7 1.7 0.7 -0.8 0.2 0.4 0.3 0.3 0.7 1.4 1.44 | -0.4 -4.3 -1.8 -0.6 1.0 -0.6 0.4 -0.4 0.5 -0.6 0.4 -1.15 | 4.6 2.4 0.6 0.9 0.8 0.5 0.3 -0.4 -0.5 0.5 -0.86 | -3.1 -1.7 1.4 -0.8 -0.3 0.3 0.3 -0.5 0.5 0.47 | 3.1 1.2 0.3 0.6 0.3 0.2 0.5 0.1 -0.78 | -1.0 -1.3 -0.7 -0.5 0.8 -0.5 0.3 -0.69 | 1.5 0.3 0.2 0.7 -0.5 0.5 -0.710 | -1.7 0.1 0.3 -0.7 -0.6 0.511 | 1.8 1.2 0.6 0.7 -1.012 | 1.6 -1.3 -1.4 -1.113 | 4.2 2.3 1.414 | -1.2 -0.615 | 1.4
A corner of plausible ![]() values is observed starting from the row
values is observed starting from the row ![]() and the column
and the column ![]() , which corresponds to GARCH(p, q) models such that (max(p, q), p) = (2, 2), that is, (p, q) = (2, 1) or (p, q) = (2, 2). A small number of other plausible values are detected for (p, q).
, which corresponds to GARCH(p, q) models such that (max(p, q), p) = (2, 2), that is, (p, q) = (2, 1) or (p, q) = (2, 2). A small number of other plausible values are detected for (p, q).
GARCH(p,q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVELPROBA CRIT MODELS FOUND0.200000 1.28 ( 3, 1) ( 3, 2) ( 3, 3) ( 1,13)0.100000 1.64 ( 3, 1) ( 3, 2) ( 3, 3) ( 2, 4) ( 0,13)0.050000 1.96 ( 2, 1) ( 2, 2) ( 0,13)0.020000 2.33 ( 2, 1) ( 2, 2) ( 1, 5) ( 0,13)0.010000 2.58 ( 2, 1) ( 2, 2) ( 1, 4) ( 0,13)0.005000 2.81 ( 2, 1) ( 2, 2) ( 1, 4) ( 0,13)0.002000 3.09 ( 2, 1) ( 2, 2) ( 1, 4) ( 0,13)0.001000 3.29 ( 2, 1) ( 2, 2) ( 1, 4) ( 0,13)0.000100 3.72 ( 2, 1) ( 2, 2) ( 1, 4) ( 0,13)0.000010 4.26 ( 2, 1) ( 2, 2) ( 1, 4) ( 0, 5)
An ARMA‐GARCH
Let us resume the simulation of size
n = 1000 of the ARMA(2, 1)‐GARCH(1, 1) model ( 5.8). The table of Studentised statistics for the corner method, applied to the SACRs of the observed process, was presented in Section 5.2.3. A small number of ARMA models, including the ARMA(2, 1), were selected. Let ![]() denote the residuals when an AR(p
0) is fitted to the observations, the order
p
0
being selected using an information criterion.
4
Applying the corner method again, but this time on the SACRs of the squared residuals
denote the residuals when an AR(p
0) is fitted to the observations, the order
p
0
being selected using an information criterion.
4
Applying the corner method again, but this time on the SACRs of the squared residuals ![]() , and estimating the covariances between the SACRs by the multivariate AR spectral approximation, as described in Section 5.2.2 , we obtain the following table:
, and estimating the covariances between the SACRs by the multivariate AR spectral approximation, as described in Section 5.2.2 , we obtain the following table:
.max(p,q).|.p..1....2....3....4....5....6....7....8....9...10...11...12...1 | 4.5 4.1 3.5 2.1 1.1 2.1 1.2 1.0 0.7 0.4 -0.2 0.92 | -2.7 0.3 -0.2 0.1 -0.4 0.5 -0.2 0.2 -0.1 0.4 -0.23 | 1.4 -0.2 0.0 -0.2 0.2 0.3 -0.2 0.1 -0.2 0.14 | -0.9 0.1 0.2 0.2 -0.2 0.2 0.0 -0.2 -0.15 | 0.3 -0.4 0.2 -0.2 0.1 0.1 -0.1 0.16 | -0.7 0.4 -0.2 0.2 -0.1 0.1 -0.17 | 0.0 -0.1 -0.2 0.1 -0.1 -0.28 | -0.1 0.1 -0.1 -0.2 -0.19 | -0.3 0.1 -0.1 -0.110 | 0.1 -0.2 -0.111 | -0.4 0.212 | -1.0
A corner of values compatible with the ![]() is observed starting from row 2 and column 2, which corresponds to a GARCH(1, 1) model. Another corner can be seen below row 2, which corresponds to a GARCH(0, 2) = ARCH(2) model. In practice, in this identification step, at least these two models would be selected. The next step would be the estimation of the selected models, followed by a validation step involving testing the significance of the coefficients, examining the residuals and comparing the models via information criteria. This validation step allows a final model to be retained which can be used for prediction purposes.
is observed starting from row 2 and column 2, which corresponds to a GARCH(1, 1) model. Another corner can be seen below row 2, which corresponds to a GARCH(0, 2) = ARCH(2) model. In practice, in this identification step, at least these two models would be selected. The next step would be the estimation of the selected models, followed by a validation step involving testing the significance of the coefficients, examining the residuals and comparing the models via information criteria. This validation step allows a final model to be retained which can be used for prediction purposes.
GARCH(p,q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVELPROBA CRIT MODELS FOUND0.200000 1.28 ( 1, 1) ( 0, 3)0.100000 1.64 ( 1, 1) ( 0, 2)0.050000 1.96 ( 1, 1) ( 0, 2)0.020000 2.33 ( 1, 1) ( 0, 2)0.010000 2.58 ( 1, 1) ( 0, 2)0.005000 2.81 ( 0, 1)0.002000 3.09 ( 0, 1)0.001000 3.29 ( 0, 1)0.000100 3.72 ( 0, 1)0.000010 4.26 ( 0, 1)
5.4 Lagrange Multiplier Test for Conditional Homoscedasticity
To test linear restrictions on the parameters of a model, the most widely used tests are the Wald test, the LM test, and likelihood ratio (LR) test. The LM test, also referred to as the Rao test or the score test, is attractive because it only requires estimation of the restricted model (unlike the Wald and LR tests which will be studied in Chapter 8), which is often much easier than estimating the unrestricted model. We start by deriving the general form of the LM test. Then we present an LM test for conditional homoscedasticity in Section 5.4.2.
5.4.1 General Form of the LM Test
Consider a parametric model, with true parameter value θ 0 ∈ ℝ d , and a null hypothesis
where R is a given s × d matrix of full rank s , and r is a given s × 1 vector. This formulation allows one to test, for instance, whether the first s components of θ 0 are null (it suffices to set R = [I s : 0 s × (d − s)] and r = 0 s ). Let ℓ n (θ) denote the log‐likelihood of observations X 1,…, X n . We assume the existence of unconstrained and constrained (by H 0 ) maximum likelihood estimators, respectively, satisfying
Under some regularity assumptions (which will be discussed in detail in Chapter 7 for the GARCH(p, q) model), the score vector satisfies a CLT and we have
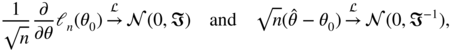
where ℑ is the Fisher information matrix. To derive the constrained estimator, we introduce the Lagrangian
We have
The first‐order conditions give
The second convergence in (5.14) thus shows that under H 0 ,
Using the convention ![]() for
a = b + c
, asymptotic expansions entail, under usual regularity conditions (more rigorous statements will be given in Chapter 7),
for
a = b + c
, asymptotic expansions entail, under usual regularity conditions (more rigorous statements will be given in Chapter 7),

which, by subtraction, gives

Finally, results (5.15) and (5.16) imply

and then

Thus, under H 0 , the test statistic
asymptotically follows a ![]() , provided that
, provided that ![]() is an estimator converging in probability to
ℑ
. In general one can take
is an estimator converging in probability to
ℑ
. In general one can take
The critical region of the LM test at the asymptotic level
α
is ![]() .
.
The Case Where the LM n Statistic Takes the Form nR 2
Implementation of an LM test can sometimes be extremely simple. Consider a non‐linear conditionally homoscedastic model in which a dependent variable
Y
t
is related to its past values and to a vector of exogenous variables
X
t
by ![]() , where ε
t
is iid
, where ε
t
is iid ![]() and
W
t
= (X
t
, Y
t − 1,…). Assume, in addition, that
W
t
and ε
t
are independent. We wish to test the hypothesis
and
W
t
= (X
t
, Y
t − 1,…). Assume, in addition, that
W
t
and ε
t
are independent. We wish to test the hypothesis
where

To retrieve the framework of the previous section, let R = [0 s × (d − s) : I s ] and note that

where Σ
λ
= (ℑ
22)−1
and
ℑ
22 = Rℑ
−1
R
′
is the bottom right‐hand block of
ℑ
−1
. Suppose that ![]() does not depend on
ψ
0
. With a Gaussian likelihood (Exercise 5.9) we have
does not depend on
ψ
0
. With a Gaussian likelihood (Exercise 5.9) we have

where ε
t
(θ) = Y
t
− F
θ
(W
t
), ![]() ,
, ![]() ,
, ![]() and
and

Partition ℑ into blocks as

where
ℑ
11
and
ℑ
22
are square matrices of respective sizes
d − s
and
s
. Under the assumption that the information matrix
ℑ
is block‐diagonal (that is,
ℑ
12 = 0), we have ![]() where
ℑ
22 = RℑR
′
, which entails Σ
λ
= ℑ
22
. We can then choose
where
ℑ
22 = RℑR
′
, which entails Σ
λ
= ℑ
22
. We can then choose
as a consistent estimator of Σ λ . We end up with

which is nothing other than
n
times the uncentred determination coefficient in the regression of ![]() on the variables
on the variables ![]() for
i = 1,…, s
(Exercise 5.10).
for
i = 1,…, s
(Exercise 5.10).
LM Test with Auxiliary Regressions
We extend the previous framework by allowing ℑ 12 to be not equal to zero. Assume that σ 2 does not depend on θ . In view of Exercise 5.9, we can then estimate Σ λ by 5
where

Suppose the model is linear under the constraint H 0 , so that
with
up to some negligible terms.
Now consider the linear regression
Exercise 5.10 shows that, in this auxiliary regression, the LM statistic for testing the hypothesis
is given by

This statistic is precisely the LM test statistic for the hypothesis
H
0 : ψ = 0 in the initial model. From Exercise 5.10, the LM test statistic of the hypothesis ![]() in model (5.19) can also be written as
in model (5.19) can also be written as
where ![]() , with
, with ![]() . We finally obtain the so‐called Breusch–Godfrey form of the LM statistic by interpreting
. We finally obtain the so‐called Breusch–Godfrey form of the LM statistic by interpreting ![]() as
n
times the determination coefficient of the auxiliary regression
as
n
times the determination coefficient of the auxiliary regression
where ![]() is the vector of residuals in the regression of
Y
on the columns of
F
β
.
is the vector of residuals in the regression of
Y
on the columns of
F
β
.
Indeed, in the two regressions ( 5.19) and (5.21), the vector of residuals is ![]() , because
, because ![]() and
and ![]() . Finally, we note that the determination coefficient is centred (in other words, it is the
R
2
which is provided by standard statistical software) when a column of
F
β
is constant.
. Finally, we note that the determination coefficient is centred (in other words, it is the
R
2
which is provided by standard statistical software) when a column of
F
β
is constant.
Quasi‐LM Test
When ℓ n (θ) is no longer supposed to be the log‐likelihood, but only the quasi‐log‐likelihood (a thorough study of the quasi‐likelihood for GARCH models will be made in Chapter 7), the equations can in general be replaced by

where
It is then recommended that the statistic (5.17) be replaced by the more complex, but more robust, expression

where ![]() and
and ![]() are consistent estimators of
I
and
J
. A consistent estimator of
J
is obviously obtained as a sample mean. Estimating the long‐run variance
I
requires more involved methods, such as those described in Section 5.2.2 (HAC or other methods).
are consistent estimators of
I
and
J
. A consistent estimator of
J
is obviously obtained as a sample mean. Estimating the long‐run variance
I
requires more involved methods, such as those described in Section 5.2.2 (HAC or other methods).
5.4.2 LM Test for Conditional Homoscedasticity
Consider testing the conditional homoscedasticity assumption
in the ARCH(q) model

At the parameter value θ = (ω, α 1,…, α q ) the quasi‐log‐likelihood is written, neglecting unimportant constants, as

with the convention ε t − i = 0 for t ≤ 0. The constrained quasi‐maximum likelihood estimator is 6

At θ 0 = (ω 0,…, 0), the score vector satisfies

under
H
0
, where
ω
0 = (ω
0,…, ω
0)′ ∈ ℝ
q
and
I
22
is a matrix whose diagonal elements are ![]() with
with ![]() , and whose other entries are equal to
, and whose other entries are equal to ![]() . The bottom right‐hand block of
I
−1
is thus
. The bottom right‐hand block of
I
−1
is thus
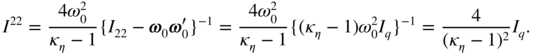
In addition, we have
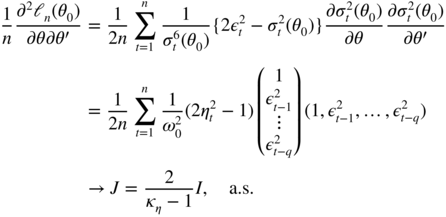
From the equality (5.23), using estimators of
I
and
J
such that ![]() , we obtain
, we obtain
Using the relation (5.24) and noting that

we obtain

Equivalence with a Portmanteau Test
Using

it follows from relation (5.25) that

which shows that the LM test is equivalent to a portmanteau test on the squares.
Expression in Terms of R 2
To establish a connection with the linear model, write
where
Y
is the
n × 1 vector ![]() , and
X
is the
n × (q + 1) matrix with first column
, and
X
is the
n × (q + 1) matrix with first column ![]() and (i + 1)th column
and (i + 1)th column ![]() . Estimating
I
by
. Estimating
I
by ![]() , where
, where ![]() , we obtain
, we obtain
which can be interpreted as
n
times the determination coefficient in the linear regression of
Y
on the columns of
X
. Because the determination coefficient is invariant by linear transformation of the variables (Exercise 5.11), we simply have LM
n
= nR
2
where
R
2
is the determination coefficient
7
of the regression of ![]() on a constant and
q
lagged variables
on a constant and
q
lagged variables ![]() . Under the null hypothesis of conditional homoscedasticity, LM
n
asymptotically follows a
. Under the null hypothesis of conditional homoscedasticity, LM
n
asymptotically follows a ![]() . The version of the LM statistic given in expression (5.27) differs from the one given in expression ( 5.25) because relation ( 5.24) is not satisfied when
I
is replaced by
. The version of the LM statistic given in expression (5.27) differs from the one given in expression ( 5.25) because relation ( 5.24) is not satisfied when
I
is replaced by ![]() .
.
5.5 Application to Real Series
Consider the returns of the CAC 40 stock index from 2 March 1990 to 29 December 2006 (4245 observations) and of the FTSE 100 index of the London Stock Exchange from 3 April 1984 to 3 April 2007 (5812 observations). The correlograms for the returns and squared returns are displayed in Figure 5.7. The bottom correlograms of Figure 5.7, as well as the portmanteau tests of Table 5.4, clearly show that, for the two indices, the strong white noise assumption cannot be sustained. These portmanteau tests can be considered as versions of LM tests for conditional homoscedasticity (see Section 5.4.2 ). Table 5.5 displays the n R 2 version of the LM test of Section 5.4.2 . Note that the two versions of the LM statistic are quite different but lead to the same unambiguous conclusions: the hypothesis of no ARCH effect must be rejected, as well as the hypothesis of absence of autocorrelation for the CAC 40 or FTSE 100 returns.

Figure 5.7 Correlograms of returns and squared returns of the CAC 40 index (2 March 1990 to 29 December 2006) and the FTSE 100 index (3 April 1984 to 3 April 2007).
Portmanteau tests on the squared CAC 40 returns (2 March 1990 to 29 December 2006) and FTSE 100 returns (3 April 1984 to 3 April 2007).
| m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Tests for non‐correlation of the squared CAC 40 | ||||||||||||
|
|
0.181 | 0.226 | 0.231 | 0.177 | 0.209 | 0.236 | 0.202 | 0.206 | 0.184 | 0.198 | 0.201 | 0.173 |
|
|
0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 |
|
|
138.825 | 356.487 | 580.995 | 712.549 | 896.465 | 1133.276 | 1307.290 | 1486.941 | 1631.190 | 1798.789 | 1970.948 | 2099.029 |
| p ‐value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Tests for non‐correlation of the squared FTSE 100 | ||||||||||||
|
|
0.386 | 0.355 | 0.194 | 0.235 | 0.127 | 0.161 | 0.160 | 0.151 | 0.115 | 0.148 | 0.141 | 0.135 |
|
|
0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 |
|
|
867.573 | 1601.808 | 1820.314 | 2141.935 | 2236.064 | 2387.596 | 964.803 | 1061.963 | 1118.258 | 1211.899 | 1296.512 | 1374.324 |
| p ‐value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
LM tests for conditional homoscedasticity of the CAC 40 and FTSE 100.
| m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Tests for absence of ARCH for the CAC 40 | |||||||||
| LM n | 138.7 | 303.3 | 421.7 | 451.7 | 500.8 | 572.4 | 600.3 | 621.6 | 629.7 |
| p ‐value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Tests for absence of ARCH for the FTSE 100 | |||||||||
| LM n | 867.1 | 1157.3 | 1157.4 | 1220.8 | 1222.4 | 1236.6 | 1237.0 | 1267.0 | 1267.3 |
| p ‐value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
The first correlogram of Figure 5.7 and the first part of Table 5.6 lead us to think that the CAC 40 series is fairly compatible with a weak white noise structure (and hence with a GARCH structure). Recall that the 95% significance bands, shown as dotted lines on the upper correlograms of Figure 5.7, are valid under the strong white noise assumption but may be misleading for weak white noises (such as GARCH). The second part of Table 5.6 displays classical Ljung–Box tests for non‐correlation. It may be noted that the CAC 40 returns series does not pass the classical portmanteau tests. 8 This does not mean, however, that the white noise assumption should be rejected. Indeed, we know that such classical portmanteau tests are invalid for conditionally heteroscedastic series.
Portmanteau tests on the CAC 40 (2 March 1990 to 29 December 2006).
| m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Tests of GARCH white noise based on Q m | ||||||||||||||||
|
|
0.016 | 0.020 | 0.045 | 0.015 | 0.041 | 0.023 | 0.025 | 0.014 | 0.000 | 0.011 | 0.010 | 0.014 | 0.020 | 0.024 | 0.037 | 0.001 |
|
|
0.041 | 0.044 | 0.044 | 0.041 | 0.043 | 0.044 | 0.042 | 0.043 | 0.041 | 0.042 | 0.042 | 0.041 | 0.043 | 0.040 | 0.040 | 0.040 |
| Q m | 0.587 | 1.431 | 5.544 | 6.079 | 9.669 | 10.725 | 12.076 | 12.475 | 12.476 | 12.718 | 12.954 | 13.395 | 14.214 | 15.563 | 18.829 | 18.833 |
| p ‐value | 0.443 | 0.489 | 0.136 | 0.193 | 0.085 | 0.097 | 0.098 | 0.131 | 0.188 | 0.240 | 0.296 | 0.341 | 0.359 | 0.341 | 0.222 | 0.277 |
| Usual tests for strong white noise | ||||||||||||||||
|
|
0.016 | 0.020 | 0.045 | 0.015 | 0.041 | 0.023 | 0.025 | 0.014 | 0.000 | 0.011 | 0.010 | 0.014 | 0.020 | 0.024 | 0.037 | 0.001 |
|
|
0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 | 0.030 |
|
|
1.105 | 2.882 | 11.614 | 12.611 | 19.858 | 22.134 | 24.826 | 25.629 | 25.629 | 26.109 | 26.579 | 27.397 | 29.059 | 31.497 | 37.271 | 37.279 |
| p ‐value | 0.293 | 0.237 | 0.009 | 0.013 | 0.001 | 0.001 | 0.001 | 0.001 | 0.002 | 0.004 | 0.005 | 0.007 | 0.006 | 0.005 | 0.001 | 0.002 |
Table 5.7 is the analog of Table 5.6 for the FTSE 100 index. Conclusions are more disputable in this case. Although some p ‐values of the upper part of Table 5.7 are slightly <5%, one cannot exclude the possibility that the FTSE 100 index is a weak (GARCH) white noise. On the other hand, the assumption of strong white noise can be categorically rejected, the p ‐values (bottom of Table 5.7) being almost equal to zero. Table 5.8 confirms the identification of an ARMA(0, 0) process for the CAC 40. Table 5.9 would lead us to select an ARMA(0, 0), ARMA(1, 1), AR(3) or MA(3) model for the FTSE 100. Recall that this a priori identification step should be completed by an estimation of the selected models, followed by a validation step. For the CAC 40, Table 5.10 indicates that the most reasonable GARCH model is simply the GARCH(1, 1). For the FTSE 100, plausible models are the GARCH(2, 1), GARCH(2, 2), GARCH(2, 3), or ARCH(4), as can be seen from Table 5.11. The choice between these models is the object of the estimation and validation steps.
Portmanteau tests on the FTSE 100 (3 April 1984 to 3 April 2007).
| m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Tests of GARCH white noise based on Q m | ||||||||||||||||
|
|
0.023 | 0.002 | 0.059 | 0.041 | 0.021 | 0.021 | 0.006 | 0.039 | 0.029 | 0.000 | 0.019 | 0.003 | 0.023 | 0.013 | 0.019 | 0.022 |
|
|
0.057 | 0.055 | 0.044 | 0.047 | 0.039 | 0.042 | 0.037 | 0.042 | 0.036 | 0.041 | 0.038 | 0.037 | 0.037 | 0.036 | 0.035 | 0.039 |
| Q m | 0.618 | 0.624 | 7.398 | 10.344 | 11.421 | 12.427 | 12.527 | 15.796 | 18.250 | 18.250 | 19.250 | 19.279 | 20.700 | 21.191 | 22.281 | 23.483 |
| p ‐value | 0.432 | 0.732 | 0.060 | 0.035 | 0.044 | 0.053 | 0.085 | 0.045 | 0.032 | 0.051 | 0.057 | 0.082 | 0.079 | 0.097 | 0.101 | 0.101 |
| Usual tests for strong white noise | ||||||||||||||||
|
|
0.023 | 0.002 | 0.059 | 0.041 | 0.021 | 0.021 | 0.006 | 0.039 | 0.029 | 0.000 | 0.019 | 0.003 | 0.023 | 0.013 | 0.019 | 0.022 |
|
|
0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 | 0.026 |
|
|
3.019 | 3.047 | 23.053 | 32.981 | 35.442 | 38.088 | 38.294 | 47.019 | 51.874 | 51.874 | 54.077 | 54.139 | 57.134 | 58.098 | 60.173 | 62.882 |
| p ‐value | 0.082 | 0.218 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Studentised statistics for the corner method for the CAC 40 series and selected ARMA orders.
.p.|.q..1....2....3....4....5....6....7....8....9...10...11...12...13...14...15...
1 | 0.8 -0.9 -2.0 0.7 -1.9 -1.0 -1.2 0.6 0.0 0.5 0.5 -0.7 0.9 1.2 1.8
2 | 0.9 0.8 1.1 -1.1 1.1 -0.3 0.8 0.2 -0.4 0.2 0.4 0.0 0.7 -0.1
3 | -2.0 1.1 -0.9 -1.0 -0.6 0.8 -0.5 0.4 -0.1 0.3 0.3 0.4 0.5
4 | -0.8 -1.1 1.0 -0.4 0.7 -0.5 0.2 0.4 0.4 0.3 -0.2 -0.3
5 | -2.0 1.1 -0.6 0.7 -0.6 0.3 -0.3 0.2 0.0 0.3 0.3
6 | 1.0 -0.3 -0.8 -0.5 -0.3 0.2 0.3 0.1 -0.2 0.3
7 | -1.1 0.7 -0.4 0.2 -0.3 0.3 -0.3 0.3 -0.3
8 | -0.4 0.0 -0.3 0.3 -0.1 -0.1 -0.3 0.4
9 | -0.1 -0.2 -0.1 0.3 -0.1 -0.1 -0.3
10 | -0.4 0.2 -0.3 0.2 -0.3 0.3
11 | 0.5 0.4 0.2 -0.1 0.2
12 | 0.8 0.1 -0.3 -0.3
13 | 1.0 0.8 0.5
14 | -1.1 -0.2
15 | 1.8
ARMA(P,Q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVEL
PROBA CRIT MODELS FOUND
0.200000 1.28 ( 1, 1)
0.100000 1.64 ( 1, 1)
0.050000 1.96 ( 0, 3) ( 1, 1) ( 5, 0)
0.020000 2.33 ( 0, 0)
0.010000 2.58 ( 0, 0)
0.005000 2.81 ( 0, 0)
0.002000 3.09 ( 0, 0)
0.001000 3.29 ( 0, 0)
0.000100 3.72 ( 0, 0)
0.000010 4.26 ( 0, 0)
|
Studentised statistics for the corner method for the FTSE 100 series and selected ARMA orders.
.p.|.q..1....2....3....4....5....6....7....8....9...10...11...12...13...14...15...
1 | 0.8 -0.1 -2.6 1.7 -1.0 -1.0 -0.3 1.8 1.6 0.0 1.1 -0.2 1.3 -0.7 1.2
2 | 0.1 0.8 1.2 0.2 1.0 0.3 0.9 1.0 0.6 -0.9 0.5 -0.8 0.6 -0.4
3 | -2.6 1.2 -0.7 -0.6 -0.7 0.8 -0.4 0.5 0.7 0.3 -0.3 -0.1 0.2
4 | -1.8 0.3 0.6 -0.7 0.6 0.0 -0.4 0.4 0.6 -0.3 0.1 -0.1
5 | -1.1 1.1 -0.7 0.6 -0.6 0.5 -0.3 0.5 0.5 0.1 0.2
6 | 1.1 0.5 -0.8 0.2 -0.4 0.6 0.5 0.5 0.4 0.2
7 | 0.0 0.9 -0.2 -0.3 0.0 0.5 0.5 0.4 0.3
8 | -1.6 0.7 -0.3 0.2 -0.4 0.4 -0.4 0.3
9 | 1.4 0.5 0.6 0.5 0.4 0.3 0.2
10 | 0.0 -0.9 -0.4 -0.2 -0.1 0.0
11 | 1.2 0.6 0.0 0.0 0.1
12 | 0.2 -0.8 0.0 0.0
13 | 1.3 0.6 0.1
14 | 0.5 -0.6
15 | 1.1
ARMA(P,Q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVEL
PROBA CRIT MODELS FOUND
0.200000 1.28 ( 0,13) ( 1, 1) ( 9, 0)
0.100000 1.64 ( 0, 8) ( 1, 1) ( 4, 0)
0.050000 1.96 ( 0, 3) ( 1, 1) ( 3, 0)
0.020000 2.33 ( 0, 3) ( 1, 1) ( 3, 0)
0.010000 2.58 ( 0, 3) ( 1, 1) ( 3, 0)
0.005000 2.81 ( 0, 0)
0.002000 3.09 ( 0, 0)
0.001000 3.29 ( 0, 0)
0.000100 3.72 ( 0, 0)
0.000010 4.26 ( 0, 0)
|
Studentised statistics for the corner method for the squared CAC 40 series and selected GARCH orders.
.max(p,q).|.p..1....2....3....4....5....6....7....8....9...10...11...12...13...14...15...
1 | 5.2 5.4 5.0 5.3 4.6 4.7 5.4 4.6 4.5 4.1 3.2 3.9 3.7 5.2 3.9
2 | -4.6 0.6 0.9 -1.4 0.2 1.0 -0.4 0.5 -0.6 0.2 0.4 -1.0 1.3 0.6
3 | 3.5 0.9 0.8 0.9 0.7 0.5 -0.2 -0.4 0.4 0.4 0.5 0.9 0.8
4 | -4.0 -1.5 -0.9 -0.4 0.0 0.4 -0.4 0.2 -0.3 -0.2 0.2 0.3
5 | 4.2 0.2 0.8 0.1 0.3 0.3 0.3 0.3 0.2 0.2 0.2
6 | -5.1 1.1 -0.6 0.4 -0.3 0.3 0.4 -0.2 -0.1 0.2
7 | 2.5 -0.3 -0.4 -0.4 0.3 0.4 0.2 0.1 0.2
8 | -3.5 0.5 0.3 0.3 -0.3 -0.1 -0.1 0.2
9 | 1.4 -0.9 0.4 -0.3 0.3 -0.1 0.1
10 | -3.4 0.3 -0.5 -0.2 -0.2 0.2
11 | 1.5 0.4 0.5 0.2 0.2
12 | -2.4 -1.0 -0.9 0.3
13 | 3.7 1.9 0.9
14 | -0.6 -0.1
15 | 0.1
GARCH(p,q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVEL
PROBA CRIT MODELS FOUND
0.200000 1.28 ( 2, 1) ( 2, 2) ( 0,13)
0.100000 1.64 ( 2, 1) ( 2, 2) ( 0,13)
0.050000 1.96 ( 1, 1) ( 0,13)
0.020000 2.33 ( 1, 1) ( 0,13)
0.010000 2.58 ( 1, 1) ( 0,13)
0.005000 2.81 ( 1, 1) ( 0,13)
0.002000 3.09 ( 1, 1) ( 0,13)
0.001000 3.29 ( 1, 1) ( 0,13)
0.000100 3.72 ( 1, 1) ( 0, 6)
0.000010 4.26 ( 1, 1) ( 0, 6)
|
Studentised statistics for the corner method for the squared FTSE 100 series and selected GARCH orders.
.max(p,q).|.p..1....2....3....4....5....6....7....8....9...10...11...12...13...14...15...
1 | 5.7 11.7 5.8 12.9 2.2 3.8 2.5 2.9 2.8 3.9 2.3 2.9 1.9 3.6 2.3
2 | -5.2 3.3 -2.9 2.2 -4.6 4.3 -1.9 1.5 -1.7 2.7 -1.0 -0.2 0.3 -0.2
3 | -0.1 -7.7 1.3 -0.2 0.6 -2.3 0.5 0.3 0.6 1.6 0.5 0.3 0.2
4 | -8.5 4.2 -0.1 -0.4 -0.1 1.2 -0.3 -0.7 -0.3 1.7 0.1 0.1
5 | -0.3 -1.6 0.5 -0.2 0.6 0.9 0.7 -0.2 0.8 1.4 -0.1
6 | -1.9 1.6 0.6 1.4 0.9 0.4 -0.7 0.9 -1.4 1.2
7 | 0.7 -1.0 -1.0 -0.8 0.3 -0.6 0.5 0.6 1.1
8 | -1.2 0.7 -0.3 0.5 -0.6 0.7 -0.8 -0.5
9 | -0.3 -1.0 0.5 0.1 -1.3 -0.4 1.1
10 | -1.6 1.2 -0.8 0.9 -0.9 1.1
11 | 0.6 0.7 0.7 0.2 1.1
12 | 1.8 -0.4 -0.9 -1.2
13 | 1.2 0.9 0.8
14 | 0.3 -0.9
15 | 0.8
GARCH(p,q) MODELS FOUND WITH GIVEN SIGNIFICANCE LEVEL
PROBA CRIT MODELS FOUND
0.200000 1.28 ( 1, 6) ( 0,12)
0.100000 1.64 ( 1, 4) ( 0,12)
0.050000 1.96 ( 2, 3) ( 0, 4)
0.020000 2.33 ( 2, 1) ( 2, 2) ( 0, 4)
0.010000 2.58 ( 2, 1) ( 2, 2) ( 0, 4)
0.005000 2.81 ( 2, 1) ( 2, 2) ( 0, 4)
0.002000 3.09 ( 2, 1) ( 2, 2) ( 0, 4)
0.001000 3.29 ( 2, 1) ( 2, 2) ( 0, 4)
0.000100 3.72 ( 2, 1) ( 2, 2) ( 0, 4)
0.000010 4.26 ( 2, 1) ( 2, 2) ( 1, 3) ( 0, 4)
|
5.6 Bibliographical Notes
In this chapter, we have adapted tools generally employed to deal with the identification of ARMA models. Correlograms and partial correlograms are studied in depth in the book by Brockwell and Davis (1991). In particular, they provide a detailed proof for the Bartlett formula giving the asymptotic behaviour of the sample autocorrelations of a strong linear process. The generalised Bartlett formula (B.15) was established by Francq and Zakoïan (2009d). The textbook by Li (2004) can serve as a reference for the various portmanteau adequacy tests, as well as Godfrey (1988) for the LM tests. It is now well known that tools generally used for the identification of ARMA models should not be directly used in presence of conditional heteroscedasticity, or other forms of dependence in the linear innovation process (see, for instance, Diebold 1986; Romano and Thombs 1996; Berlinet and Francq 1997; Francq, Roy, and Zakoïan 2005; Boubacar Maïnassara and Saussereau 2018). The corner method was proposed by Béguin, Gouriéroux, and Monfort (1980) for the identification of mixed ARMA models. There are many alternatives to the corner method, in particular the epsilon algorithm (see Berlinet 1984) and the generalised autocorrelations of Glasbey (1982).
Additional references on tests of ARCH effects are Engle (1982, 1984), Bera and Higgins (1997), and Li (2004).
In this chapter, we have assumed the existence of a fourth‐order moment for the observed process. When only the second‐order moment exists, Basrak, Davis, and Mikosch (2002) showed in particular that the sample autocorrelations converge very slowly. When even the second‐order moment does not exist, the sample autocorrelations have a degenerate asymptotic distribution.
Concerning the HAC estimators of a long‐run variance matrix, see, fo instance, Andrews (1991) and Andrews and Monahan (1992). The method based on the spectral density at 0 of an AR model follows from Berk (1974). A comparison with the HAC method is proposed in den Hann and Levin (1997).
5.7 Exercises
5.1 (Asymptotic behaviour of the SACVs of a martingale difference)
Let (ε
t
) denote a martingale difference sequence such that ![]() and
and ![]() . By applying Corollary A.1, derive the asymptotic distribution of
. By applying Corollary A.1, derive the asymptotic distribution of ![]() for
h ≠ 0.
for
h ≠ 0.
-
5.2 (Asymptotic behaviour of
 for an ARCH(1) process) Consider the stationary non‐anticipative solution of an ARCH(1) process5.28
for an ARCH(1) process) Consider the stationary non‐anticipative solution of an ARCH(1) process5.28
where (η t ) is a strong white noise with unit variance and μ 4 α 2 < 1 with
 . Derive the asymptotic distribution of
. Derive the asymptotic distribution of  .
. -
5.3 (Asymptotic behaviour of
 for an ARCH(1) process) For the ARCH(1) model of Exercise 5.2, derive the asymptotic distribution of
for an ARCH(1) process) For the ARCH(1) model of Exercise 5.2, derive the asymptotic distribution of  . What is the asymptotic variance of this statistic when
α = 0? Draw this asymptotic variance as a function of
α
and conclude accordingly.
. What is the asymptotic variance of this statistic when
α = 0? Draw this asymptotic variance as a function of
α
and conclude accordingly. -
5.4 (Asymptotic behaviour of the SACRs of a GARCH(1, 1) process)
For the GARCH(1, 1) model of Exercise 2.8, derive the asymptotic distribution of , for
h ≠ 0 fixed.
, for
h ≠ 0 fixed. - 5.5 (Moment of order 4 of a GARCH(1, 1) process) For the GARCH(1, 1) model of Exercise 2.8, compute Eε t ε t + 1ε s ε s + 2 .
-
5.6 (Asymptotic covariance between the SACRs of a GARCH(1, 1) process) For the GARCH(1, 1) model of Exercise 2.8, compute

-
5.7 (First five SACRs of a GARCH(1, 1) process) Evaluate numerically the asymptotic variance of the vector
 of the first five SACRs of the GARCH(1, 1) model defined by
of the first five SACRs of the GARCH(1, 1) model defined by
-
5.8 (Generalised Bartlett formula for an MA(q)‐ARCH(1) process) Suppose that
X
t
follows an MA(q) of the form

where the error term is an ARCH(1) process

How is the generalised Bartlett formula (B.15) expressed for i = j > q ?
-
5.9 (Fisher information matrix for dynamic regression model) In the regression model
 introduced in Section 5.4.1, suppose that (ε
t
) is a
introduced in Section 5.4.1, suppose that (ε
t
) is a  white noise. Suppose also that the regularity conditions entailing the two convergences ( 5.14) hold. Give an explicit form to the blocks of the matrix
I
, and consider the case where
σ
2
does not depend on
θ
.
white noise. Suppose also that the regularity conditions entailing the two convergences ( 5.14) hold. Give an explicit form to the blocks of the matrix
I
, and consider the case where
σ
2
does not depend on
θ
. -
5.10 (LM tests in a linear regression model) Consider the regression model

where Y = (Y 1,…, Y n ) is the dependent vector variable, X i is an n × k i matrix of explicative variables with rank k i ( i = 1, 2), and the vector U is a
 error term. Derive the LM test of the hypothesis
H
0 : β
2 = 0. Consider the case
error term. Derive the LM test of the hypothesis
H
0 : β
2 = 0. Consider the case  and the general case.
and the general case. -
5.11 (Centred and uncentred
R
2
) Consider the regression model
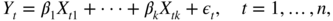
where the ε t are iid, centred, and have a variance σ 2 > 0. Let Y = (Y 1,…, Y n )′ be the vector of dependent variables, X = (X ij ) the n × k matrix of explanatory variables, ε = (ε1,…, ε n )′ the vector of the error terms and β = (β 1,…, β k )′ the parameter vector. Let P X = X(X ′ X)−1 X ′ denote the orthogonal projection matrix on the vector subspace generated by the columns of X .
The uncentred determination coefficient is defined by
5.29
and the (centred) determination coefficient is defined by
5.30
Let T denote a k × k invertible matrix, c a number different from 0 and d any number. Let
 and
and  . Show that if
. Show that if  and if
e
belongs to the vector subspace generated by the columns of
X
, then
and if
e
belongs to the vector subspace generated by the columns of
X
, then  defined by relation (5.29) is equal to the determination coefficient in the regression of
defined by relation (5.29) is equal to the determination coefficient in the regression of  on the columns of
on the columns of  .
.