
8
Tests Based on the Likelihood
In the previous chapter, we saw that the asymptotic normality of the QMLE of a GARCH model holds true under general conditions, in particular without any moment assumption on the observed process. An important application of this result concerns testing problems. In particular, we are able to test the IGARCH assumption, or more generally a given GARCH model with infinite variance. This problem is the subject of Section 8.1.
The main aim of this chapter is to derive tests for the nullity of coefficients. These tests are complex in the GARCH case because of the constraints that are imposed on the estimates of the coefficients to guarantee that the estimated conditional variance is positive. Without these constraints, it is impossible to compute the Gaussian log‐likelihood of the GARCH model. Moreover, asymptotic normality of the QMLE has been established assuming that the parameter belongs to the interior of the parameter space (assumption A5 in Chapter 7). When some coefficients,
α
i
or
β
j
, are null, Theorem 7.2 does not apply. It is easy to see that, in such a situation, the asymptotic distribution of ![]() cannot be Gaussian. Indeed, the components,
cannot be Gaussian. Indeed, the components, ![]() of
of ![]() , are constrained to be positive or null. If, for instance
θ
0i
= 0, then
, are constrained to be positive or null. If, for instance
θ
0i
= 0, then ![]() for all
n
and the asymptotic distribution of this variable cannot be Gaussian.
for all
n
and the asymptotic distribution of this variable cannot be Gaussian.
Before considering the significance tests, we shall, therefore, establish in Section 8.2 the asymptotic distribution of the QMLE without assumption A5, at the cost of a moment assumption on the observed process. In Section 8.3, we present the main tests (Wald, score and likelihood ratio) used for testing the nullity of some coefficients. The asymptotic distribution obtained for the QMLE will lead to modification of the standard critical regions. Two cases of particular interest will be examined in detail: the test of nullity of only one coefficient and the test of conditional homoscedasticity, which corresponds to the nullity of all the coefficients α i and β j . Section 8.4 is devoted to testing the adequacy of a particular GARCH(p, q) model, using portmanteau tests. The chapter also contains a numerical application in which the pre‐eminence of the GARCH(1, 1) model is questioned.
8.1 Test of the Second‐Order Stationarity Assumption
For the GARCH(p, q) model defined by Eq. (7.1), testing for second‐order stationarity involves testing

Introducing the vector c = (0, 1, …, 1)′ ∈ ℝ p + q + 1 , the testing problem is
In view of Theorem 7.2, the QMLE ![]() of
θ
0
satisfies
of
θ
0
satisfies
under assumptions which are compatible with H 0 and H 1 . In particular, if c ′ θ 0 = 1 we have
It is thus natural to consider the Wald statistic

where ![]() and
and ![]() are consistent estimators in probability of
κ
η
and
J
. The following result follows immediately from the convergence of
T
n
to
are consistent estimators in probability of
κ
η
and
J
. The following result follows immediately from the convergence of
T
n
to ![]() when
c
′
θ
0 = 1.
when
c
′
θ
0 = 1.
Note that for most real series (see, for instance Table 7.4), the sum of the estimated coefficients ![]() and
and ![]() is strictly less than 1: second‐order stationarity thus cannot be rejected, for any reasonable asymptotic level (when
T
n
< 0, the
p
‐value of the test is greater than 1/2). Of course, the non‐rejection of
H
0
does not mean that the stationarity is proved. It is interesting to test the reverse assumption that the data‐generating process is an IGARCH, or more generally that it does not have moments of order 2. We thus consider the problem
is strictly less than 1: second‐order stationarity thus cannot be rejected, for any reasonable asymptotic level (when
T
n
< 0, the
p
‐value of the test is greater than 1/2). Of course, the non‐rejection of
H
0
does not mean that the stationarity is proved. It is interesting to test the reverse assumption that the data‐generating process is an IGARCH, or more generally that it does not have moments of order 2. We thus consider the problem
As an application, we take up the data sets of Table 7.4 again, and we give the p ‐values of the previous test for the 11 series of daily returns. For the FTSE (DAX, Nasdaq, and S&P 500), the assumption of infinite variance cannot be rejected at the 5% (3%, 2%, and 1%) level (see Table 8.1). The other series can be considered as second‐order stationary (if one believes in the GARCH(1, 1) model, of course).
Test of the infinite variance assumption for 11 stock market returns.
| Index |
|
p ‐Value |
| CAC | 0.983 (0.007) | 0.0089 |
| DAX | 0.981 (0.011) | 0.0385 |
| DJA | 0.982 (0.007) | 0.0039 |
| DJI | 0.986 (0.006) | 0.0061 |
| DJT | 0.983 (0.009) | 0.0023 |
| DJU | 0.983 (0.007) | 0.0060 |
| FTSE | 0.990 (0.006) | 0.0525 |
| Nasdaq | 0.993 (0.003) | 0.0296 |
| Nikkei | 0.980 (0.007) | 0.0017 |
| SMI | 0.962 (0.015) | 0.0050 |
| S&P 500 | 0.989 (0.005) | 0.0157 |
Estimated standard deviations are in parentheses.
8.2 Asymptotic Distribution of the QML When θ 0 is at the Boundary
In view of the form of the parameter space (7.3), the QMLE ![]() is constrained to have a strictly positive first component, while the other components are constrained to be positive or null. A general technique for determining the distribution of a constrained estimator involves expressing it as a function of the unconstrained estimator
is constrained to have a strictly positive first component, while the other components are constrained to be positive or null. A general technique for determining the distribution of a constrained estimator involves expressing it as a function of the unconstrained estimator ![]() (see Gouriéroux and Monfort 1995). For the QMLE of a GARCH, this technique does not work because the objective function
(see Gouriéroux and Monfort 1995). For the QMLE of a GARCH, this technique does not work because the objective function
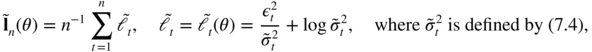
cannot be computed outside Θ (for an ARCH(1), it may happen that ![]() is negative when
α
1 < 0). It is thus impossible to define
is negative when
α
1 < 0). It is thus impossible to define ![]() .
.
The technique that we will utilise here (see, in particular, Andrews 1999), involves writing ![]() with the aid of the normalised score vector, evaluated at
θ
0
:
with the aid of the normalised score vector, evaluated at
θ
0
:
with

where the components of ∂ l n (θ 0)/∂θ and of J n are right derivatives (see (a) in the proof of Theorem 8.1 below).
In the proof of Theorem 7.2, we showed that
For any value of
θ
0 ∈ Θ (even when ![]() ), it will be shown that the vector
Z
n
is well defined and satisfies
), it will be shown that the vector
Z
n
is well defined and satisfies
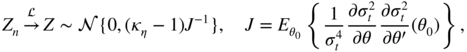
provided J exists. By contrast, when
Result (8.4) is no longer valid. However, we will show that the asymptotic distribution of ![]() is well approximated by that of the vector
n
1/2(θ − θ
0) which is located at the minimal distance of
Z
n
, under the constraint
θ ∈ Θ. Consider thus a random vector
is well approximated by that of the vector
n
1/2(θ − θ
0) which is located at the minimal distance of
Z
n
, under the constraint
θ ∈ Θ. Consider thus a random vector ![]() (which is not an estimator, of course) solving the minimisation problem
(which is not an estimator, of course) solving the minimisation problem
It will be shown that J n converges to the positive definite matrix J . For n large enough, we thus have
where ![]() is a distance between two points
x
and
y
of ℝ
p + q + 1
.
is a distance between two points
x
and
y
of ℝ
p + q + 1
.
We allow θ 0 to have null components, but we do not consider the (less interesting) case where θ 0 reaches another boundary of Θ. More precisely, we assume that
where ![]() and
and ![]() . In this case
. In this case ![]() and
and ![]() belong to the ‘local parameter space’
belong to the ‘local parameter space’
where Λ1 = ℝ, for i = 2, …, p + q + 1, Λ i = ℝ if θ 0i ≠ 0 and Λ i = [0, ∞) if θ 0i = 0. With the notation
we thus have, with probability 1,
The vector ![]() is the projection of
Z
n
on Λ, with respect to the norm
is the projection of
Z
n
on Λ, with respect to the norm ![]() (see Figure 8.1). Since Λ is closed and convex, such a projection is unique. We will show that
(see Figure 8.1). Since Λ is closed and convex, such a projection is unique. We will show that

Figure 8.1
ARCH(1) model with
θ
0 = (ω
0, 0) and  :
:  is the grey area;
is the grey area;  ;
;  and
and  have the same asymptotic distribution.
have the same asymptotic distribution.
Since (Z
n
, J
n
) tends in law to (Z, J) and ![]() is a function of (Z
n
, J
n
) which is continuous everywhere except at the points where
J
n
is singular (that is, almost everywhere with respect to the distribution of (Z, J) because
J
is invertible), we have
is a function of (Z
n
, J
n
) which is continuous everywhere except at the points where
J
n
is singular (that is, almost everywhere with respect to the distribution of (Z, J) because
J
is invertible), we have ![]() , where
λ
Λ
is the solution of limiting problem
, where
λ
Λ
is the solution of limiting problem
In addition to B1, we retain most of the assumptions of Theorem 7.2:
- B2: θ 0 ∈ Θ and Θ is a compact set.
- B3:
γ(A
0) < 0 and for all
θ ∈ Θ,
 .
. - B4:
 has a non‐degenerate distribution with
has a non‐degenerate distribution with 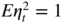 .
. - B5: If
p > 0,
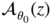 , and
, and  do not have common roots,
do not have common roots,  , and
α
0q
+ β
0p
≠ 0.
, and
α
0q
+ β
0p
≠ 0. - B6:
 .
.
We also need the following moment assumption:
- B7:
 .
.
When ![]() , we can show the existence of the information matrix
, we can show the existence of the information matrix

without moment assumptions similar to B7. The following example shows that, in the ARCH case, this is no longer possible when we allow θ 0 ∈ ∂Θ.
We then have the following result.
8.2.1 Computation of the Asymptotic Distribution
In this section, we will show how to compute the solutions of the optimization problem ( 8.10). Switching the components of
θ
, if necessary, it can be assumed without loss of generality that the vector ![]() of the first
d
1
components of
θ
0
has strictly positive elements and that the vector
of the first
d
1
components of
θ
0
has strictly positive elements and that the vector ![]() of the last
d
2 = p + q + 1 − d
1
components of
θ
0
is null. This can be written as
of the last
d
2 = p + q + 1 − d
1
components of
θ
0
is null. This can be written as
More generally, it will be useful to consider all the subsets of these constraints. Let
be the set of the matrices obtained by deleting no, one, or several (but not all) rows of K. Note that the solution of the constrained minimisation problem ( 8.10) is the unconstrained solution λ = Z when the latter satisfies the constraint, that is, when
When Z ∉ Λ, the solution λ Λ coincides with that of an equality constrained problem of the form
An important difference, compared to the initial minimisation program ( 8.10), is that the minimisation is done here on a vectorial space. The solution is given by a projection (non‐orthogonal when J is not the identity matrix). We thus obtain (see Exercise 8.1)
is the projection matrix (orthogonal for the metric defined by J) on the orthogonal subspace of the space generated by the rows of
K
i
. Note that ![]() does not necessarily belong to Λ because
K
i
λ = 0 does not imply that
Kλ ≥ 0. Let
does not necessarily belong to Λ because
K
i
λ = 0 does not imply that
Kλ ≥ 0. Let ![]() be the class of the admissible solutions. It follows that the solution that we are looking for is
be the class of the admissible solutions. It follows that the solution that we are looking for is
This formula can be used in practice to obtain realisations of
λ
Λ
from realisations of
Z
. The ![]() can be obtained by writing
can be obtained by writing
Another expression (of theoretical interest) for λ Λ is

where ![]() and the
and the ![]() form a partition of ℝ
p + q + 1
. Indeed, according to the zone to which
Z
belongs, a solution
form a partition of ℝ
p + q + 1
. Indeed, according to the zone to which
Z
belongs, a solution ![]() is obtained. We will make explicit these formulas in a few examples. Let
d = p + q + 1,
z
+ = z
is obtained. We will make explicit these formulas in a few examples. Let
d = p + q + 1,
z
+ = z
![]() (0, + ∞)(z) and
z
− = z
(0, + ∞)(z) and
z
− = z
![]() (− ∞ , 0)(z).
(− ∞ , 0)(z).
8.3 Significance of the GARCH Coefficients
We make the assumptions of Theorem 8.1 and use the notation of Section 8.2. Assume ![]() , and consider the testing problem
, and consider the testing problem
Recall that under H 0 , we have
where the distribution of λ Λ is defined by
with ![]() .
.
8.3.1 Tests and Rejection Regions
For parametric assumptions of the form (8.19), the most popular tests are the Wald, score, and likelihood ratio tests.
Wald Statistic
The Wald test looks at whether ![]() is close to 0. The usual Wald statistic is defined by
is close to 0. The usual Wald statistic is defined by
where ![]() is a consistent estimator of Σ = (κ
η
− 1)J
−1.
is a consistent estimator of Σ = (κ
η
− 1)J
−1.
Score (or Lagrange Multiplier or Rao) Statistic
Let

denote the QMLE of
θ
constrained by
θ
(2) = 0. The score test aims to determine whether ![]() is not too far from 0, using a statistic of the form
is not too far from 0, using a statistic of the form

where ![]() and
and ![]() denote consistent estimators of
κ
η
and
J
.
denote consistent estimators of
κ
η
and
J
.
Likelihood Ratio Statistic
The likelihood ratio test is based on the fact that under
H
0 : θ
(2) = 0, the constrained (quasi) log‐likelihood ![]() should not be much smaller than the unconstrained log‐likelihood
should not be much smaller than the unconstrained log‐likelihood ![]() . The test employs the statistic
. The test employs the statistic
Usual Rejection Regions
From the practical viewpoint, the score statistic presents the advantage of only requiring constrained estimation, which is sometimes much simpler than the unconstrained estimation required by the two other tests. The likelihood ratio statistic does not require estimation of the information matrix
J
, nor the kurtosis coefficient
κ
η
. For each test, it is clear that the null hypothesis must be rejected for large values of the statistic. For standard statistical problems, the three statistics asymptotically follow the same ![]() distribution under the null. At the asymptotic level
α
, the standard rejection regions are thus
distribution under the null. At the asymptotic level
α
, the standard rejection regions are thus
where ![]() is the (1 − α)‐quantile of the
χ
2
distribution with
d
2
degrees of freedom. In the case
d
2 = 1, for testing the significance of only one coefficient, the most widely used test is Student's
t
test, defined by the rejection region
is the (1 − α)‐quantile of the
χ
2
distribution with
d
2
degrees of freedom. In the case
d
2 = 1, for testing the significance of only one coefficient, the most widely used test is Student's
t
test, defined by the rejection region
where ![]() . This test is equivalent to the standard Wald test because
. This test is equivalent to the standard Wald test because ![]() (
t
n
being here always positive or null, because of the positivity constraints of the QML estimates) and
(
t
n
being here always positive or null, because of the positivity constraints of the QML estimates) and
Our testing problem is not standard because, by Theorem 8.1, the asymptotic distribution of ![]() is not normal. We will see that, among the previous rejection regions, only that of the score test asymptotically has the level
α
.
is not normal. We will see that, among the previous rejection regions, only that of the score test asymptotically has the level
α
.
8.3.2 Modification of the Standard Tests
The following proposition shows that for the Wald and likelihood ratio tests, the asymptotic distribution is not the usual ![]() under the null hypothesis. The proposition also shows that the asymptotic distribution of the score test remains the
under the null hypothesis. The proposition also shows that the asymptotic distribution of the score test remains the ![]() distribution. The asymptotic distribution of
R
n
is not affected by the fact that, under the null hypothesis, the parameter is at the boundary of the parameter space. These results are not very surprising. Take the example of an ARCH(1) with the hypothesis
H
0 : α
0 = 0 of absence of ARCH effect. As illustrated by Figure 8.2, there is a non‐zero probability that
distribution. The asymptotic distribution of
R
n
is not affected by the fact that, under the null hypothesis, the parameter is at the boundary of the parameter space. These results are not very surprising. Take the example of an ARCH(1) with the hypothesis
H
0 : α
0 = 0 of absence of ARCH effect. As illustrated by Figure 8.2, there is a non‐zero probability that ![]() be at the boundary, that is, that
be at the boundary, that is, that ![]() . Consequently
. Consequently ![]() admits a mass at 0 and does not follow, even asymptotically, the
admits a mass at 0 and does not follow, even asymptotically, the ![]() law. The same conclusion can be drawn for the likelihood ratio test. On the contrary, the score
n
1/2
∂
l
n
(θ
0)/∂θ
can take as well positive or negative values, and does not seem to have a specific behaviour when
θ
0
is at the boundary.
law. The same conclusion can be drawn for the likelihood ratio test. On the contrary, the score
n
1/2
∂
l
n
(θ
0)/∂θ
can take as well positive or negative values, and does not seem to have a specific behaviour when
θ
0
is at the boundary.

Figure 8.2
Concentrated log‐likelihood (solid line)  for an ARCH(1) model. Assume there is no ARCH effect: the true value of the ARCH parameter is
α
0 = 0. In the configuration on the right, the likelihood maximum does not lie at the boundary and the three statistics
W
n
,
R
n
, and
L
n
take strictly positive values. In the configuration on the left, we have
for an ARCH(1) model. Assume there is no ARCH effect: the true value of the ARCH parameter is
α
0 = 0. In the configuration on the right, the likelihood maximum does not lie at the boundary and the three statistics
W
n
,
R
n
, and
L
n
take strictly positive values. In the configuration on the left, we have  and
and  , whereas
, whereas  continues to take a strictly positive value.
continues to take a strictly positive value.
8.3.3 Test for the Nullity of One Coefficient
Consider the case
d
2 = 1, which is perhaps the most interesting case and corresponds to testing the nullity of only one coefficient. In view of relations (8.15), the last component of
λ
Λ
is equal to ![]() . We thus have
. We thus have
where ![]() . Using the symmetry of the Gaussian distribution, and the independence between
Z
*2
and
. Using the symmetry of the Gaussian distribution, and the independence between
Z
*2
and ![]() when
Z
*
follows the real normal law, we obtain
when
Z
*
follows the real normal law, we obtain
Testing
can thus be achieved by using the critical region ![]() at the asymptotic level
α ≤ 1/2. In view of Remark 8.3, we can define a modified likelihood ratio test of critical region
at the asymptotic level
α ≤ 1/2. In view of Remark 8.3, we can define a modified likelihood ratio test of critical region ![]() . Note that the standard Wald test
. Note that the standard Wald test ![]() has the asymptotic level
α/2, and that the asymptotic level of the standard likelihood ratio test
has the asymptotic level
α/2, and that the asymptotic level of the standard likelihood ratio test ![]() is much larger than
α
when the kurtosis coefficient
κ
η
is large. A modified version of the Student
t
test is defined by the rejection region
is much larger than
α
when the kurtosis coefficient
κ
η
is large. A modified version of the Student
t
test is defined by the rejection region
We observe that commercial software – such as GAUSS, R, RATS, SAS, and SPSS – do not use the modified version (8.25), but the standard version (8.21). This standard test is not of asymptotic level α but only α/2. To obtain a t test of asymptotic level α , it then suffices to use a test of nominal level 2α .
8.3.4 Conditional Homoscedasticity Tests with ARCH Models
Another interesting case is that obtained with d 1 = 1, θ (1) = ω , p = 0, and d 2 = q . This case corresponds to the test of the conditional homoscedasticity null hypothesis
in an ARCH(q) model

We will see that for testing problem (8.26), there exist very simple forms of the Wald and score statistics.
Simplified Form of the Wald Statistic
Using Exercise 8.6, we have

Since KΣK ′ = I q , we obtain a very simple form for the Wald statistic:

Asymptotic Distribution W and L
A trivial extension of Example 8.3 yields
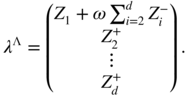
The asymptotic distribution of ![]() is thus that of
is thus that of

wherethe
Z
i
's are independent and ![]() -distributed. Thus, in the case where an ARCH(q) is fitted to a white noise we have
-distributed. Thus, in the case where an ARCH(q) is fitted to a white noise we have
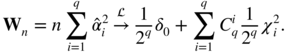
This asymptotic distribution is tabulated and the critical values are given in Table 8.2. In view of Remark 8.3, Table 8.2 also yields the asymptotic critical values of the modified likelihood ratio statistic ![]() . Table 8.3 shows that the use of the standard
. Table 8.3 shows that the use of the standard ![]() ‐based critical values of the Wald test would lead to large discrepancies between the asymptotic levels and the nominal level
α
.
‐based critical values of the Wald test would lead to large discrepancies between the asymptotic levels and the nominal level
α
.
Asymptotic critical value
c
q, α
, at level
α
, of the Wald test of rejection region ![]() for the conditional homoscedasticity hypothesis
H
0 : α
1 = ⋯ = α
q
= 0 in an ARCH(q) model.
for the conditional homoscedasticity hypothesis
H
0 : α
1 = ⋯ = α
q
= 0 in an ARCH(q) model.
| q | α (%) | |||||
| 0.1 | 1 | 2.5 | 5 | 10 | 15 | |
| 1 | 9.5493 | 5.4119 | 3.8414 | 2.7055 | 1.6424 | 1.0742 |
| 2 | 11.7625 | 7.2895 | 5.5369 | 4.2306 | 2.9524 | 2.2260 |
| 3 | 13.4740 | 8.7464 | 6.8610 | 5.4345 | 4.0102 | 3.1802 |
| 4 | 14.9619 | 10.0186 | 8.0230 | 6.4979 | 4.9553 | 4.0428 |
| 5 | 16.3168 | 11.1828 | 9.0906 | 7.4797 | 5.8351 | 4.8519 |
Exact asymptotic level (%) of erroneous Wald tests, of rejection region ![]() , under the conditional homoscedasticity assumption
H
0 : α
1 = ⋯ = α
q
= 0 in an ARCH(q) model.
, under the conditional homoscedasticity assumption
H
0 : α
1 = ⋯ = α
q
= 0 in an ARCH(q) model.
| q | α (%) | |||||
| 0.1 | 1 | 2.5 | 5 | 10 | 15 | |
| 1 | 0.05 | 0.5 | 1.25 | 2.5 | 5 | 7.5 |
| 2 | 0.04 | 0.4 | 0.96 | 1.97 | 4.09 | 6.32 |
| 3 | 0.02 | 0.28 | 0.75 | 1.57 | 3.36 | 5.29 |
| 4 | 0.02 | 0.22 | 0.59 | 1.28 | 2.79 | 4.47 |
| 5 | 0.01 | 0.17 | 0.48 | 1.05 | 2.34 | 3.81 |
Score Test
For the hypothesis (8.26) that all the α coefficients of an ARCH(q) model are equal to zero, the score statistic R n can be simplified. To work within the linear regression framework, write
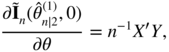
where
Y
is the vector of length
n
of the ‘dependent’ variable ![]() , where
X
is the
n × (q + 1) matrix of the constant
, where
X
is the
n × (q + 1) matrix of the constant ![]() (in the first column) and of the ‘explanatory’ variables
(in the first column) and of the ‘explanatory’ variables ![]() (in column
i + 1, with the convention ε
t
= 0 for
t ≤ 0), and
(in column
i + 1, with the convention ε
t
= 0 for
t ≤ 0), and ![]() . Estimating
J(θ
0) by
n
−1
X
′
X
, and
κ
η
− 1 by
n
−1
Y
′
Y
, we obtain
. Estimating
J(θ
0) by
n
−1
X
′
X
, and
κ
η
− 1 by
n
−1
Y
′
Y
, we obtain
and one recognizes
n
times the coefficient of determination in the linear regression of
Y
on the columns of
X
. Since this coefficient is not changed by linear transformation of the variables (see Exercise 5.11), we simply have
R
n
= nR
2
, where
R
2
is the coefficient of determination in the regression of ![]() on a constant and
q
lagged values
on a constant and
q
lagged values ![]() . Under the null hypothesis of conditional homoscedasticity,
R
n
asymptotically follows the
. Under the null hypothesis of conditional homoscedasticity,
R
n
asymptotically follows the ![]() law.
law.
The previous simple forms of the Wald and score tests are obtained with estimators of J which exploit the particular form of the matrix under the null. Note that there exist other versions of these tests, obtained with other consistent estimators of J . The different versions are equivalent under the null, but can have different asymptotic behaviours under the alternative.
8.3.5 Asymptotic Comparison of the Tests
The Wald and score tests that we have just defined are in general consistent, that is, their powers converge to 1 when they are applied to a wide class of conditionally heteroscedastic processes. An asymptotic study will be conducted via two different approaches: Bahadur's approach compares the rates of convergence to zero of the p ‐values under fixed alternatives, whereas Pitman's approach compares the asymptotic powers under a sequence of local alternatives, that is, a sequence of alternatives tending to the null as the sample size increases.
Bahadur's Approach
Let S W (t) = ℙ(W > t) and S R (t) = ℙ(R > t) be the asymptotic survival functions of the two test statistics, under the null hypothesis H 0 defined by ( 8.26). Consider, for instance, the Wald test. Under the alternative of an ARCH(q) which does not satisfy H 0 , the p ‐value of the Wald test S W (W n ) converges almost surely to zero as n → ∞ because

The p‐value of a test is typically equivalent to exp{−nc/2}, where c is a positive constant called the Bahadur slope. Using the fact that
and that ![]() , the (approximate
1
) Bahadur slope of the Wald test is thus
, the (approximate
1
) Bahadur slope of the Wald test is thus

To compute the Bahadur slope of the score test, note that we have the linear regression model ![]() is the linear innovation of
is the linear innovation of ![]() . We then have
. We then have

The previous limit is thus equal to the Bahadur slope of the score test. The comparison of the two slopes favours the score test over the Wald test.
Bahadur's approach is sometimes criticised for not taking account of the critical value of test, and thus for not really comparing the powers. This approach only takes into account the (asymptotic) distribution of the statistic under the null and the rate of divergence of the statistic under the alternative. It is unable to distinguish a two‐sided test from its one‐sided counterpart (see Exercise 8.8). In this sense, the result of Proposition 8.4 must be put into perspective.
Pitman's Approach
In the ARCH(1) case, consider a sequence of local alternatives ![]() . We can show that under this sequence of alternatives,
. We can show that under this sequence of alternatives,
Consequently, the local asymptotic power of the Wald test is
The score test has the local asymptotic power
Note that the probability in (8.32) is the power of the test of the assumption
H
0 : θ = 0 against the assumption
H
1 : θ = τ > 0, based on the rejection region of {X > c
1} with only one observation ![]() . The power (8.33) is that of the two‐sided test {∣X ∣ > c
2}. The tests {X > c
1} and {∣X ∣ > c
2} have the same level, but the first test is uniformly more powerful than the second (by the Neyman–Pearson lemma, {X > c
1} is even uniformly more powerful than any test of level less than or equal to
α
, for any one‐sided alternative of the form
H
1
). The local asymptotic power of the Wald test is thus uniformly strictly greater than that of Rao's test for testing for conditional homoscedasticity in an ARCH(1) model.
. The power (8.33) is that of the two‐sided test {∣X ∣ > c
2}. The tests {X > c
1} and {∣X ∣ > c
2} have the same level, but the first test is uniformly more powerful than the second (by the Neyman–Pearson lemma, {X > c
1} is even uniformly more powerful than any test of level less than or equal to
α
, for any one‐sided alternative of the form
H
1
). The local asymptotic power of the Wald test is thus uniformly strictly greater than that of Rao's test for testing for conditional homoscedasticity in an ARCH(1) model.
Consider the ARCH(2) case, and a sequence of local alternatives ![]() . Under this sequence of alternatives
. Under this sequence of alternatives
with ![]() Let
c
1
be the critical value of the Wald test of level
α
. The local asymptotic power of the Wald test is
Let
c
1
be the critical value of the Wald test of level
α
. The local asymptotic power of the Wald test is

Let c 2 be the critical value of the Rao test of level α . The local asymptotic power of the Rao test is
where (U
1 + τ
1)2 + (U
2 + τ
2)2
follows a non‐central
χ
2
distribution, with two degrees of freedom and non‐centrality parameter ![]() . Figure 8.5 compares the powers of the two tests when
τ
1 = τ
2
.
. Figure 8.5 compares the powers of the two tests when
τ
1 = τ
2
.

Figure 8.5 Local asymptotic power of the Wald test (solid line) and of the Rao test (dotted line) for testing for conditional homoscedasticity in an ARCH(2) model.
Thus, the comparison of the local asymptotic powers clearly favours the Wald test over the score test, counter‐balancing the result of Proposition 8.4.
8.4 Diagnostic Checking with Portmanteau Tests
To check the adequacy of a given time series model, for instance an ARMA(p, q) model, it is common practice to test the significance of the residual autocorrelations. In the GARCH framework this approach is not relevant because the process ![]() is always a white noise (more precisely a martingale difference) even when the volatility is misspecified, that is, when
is always a white noise (more precisely a martingale difference) even when the volatility is misspecified, that is, when ![]() with
with ![]() . To check the adequacy of a volatility model, for instance a GARCH(
p, q) of the form (7.1), it is much more fruitful to look at the squared residual autocovariances
. To check the adequacy of a volatility model, for instance a GARCH(
p, q) of the form (7.1), it is much more fruitful to look at the squared residual autocovariances

where ∣h ∣ < n
, ![]() ,
, ![]() is defined by Eq. (7.4) and
is defined by Eq. (7.4) and ![]() is the QMLE given by Eq. (7.9).
is the QMLE given by Eq. (7.9).
For any fixed integer
m
, 1 ≤ m < n
, consider the statistic ![]() . Let
. Let ![]() and
and ![]() be weakly consistent estimators of
κ
η
and
J
. For instance, one can take
be weakly consistent estimators of
κ
η
and
J
. For instance, one can take

Define also the
m × (p + q + 1) matrix ![]() whose (h, k)th element, for 1 ≤ h ≤ m
and 1 ≤ k ≤ p + q + 1, is given by
whose (h, k)th element, for 1 ≤ h ≤ m
and 1 ≤ k ≤ p + q + 1, is given by

8.5 Application: Is the GARCH(1,1) Model Overrepresented?
The GARCH(1,1) model is by far the most widely used by practitioners who wish to estimate the volatility of daily returns. In general, this model is chosen a priori, without implementing any statistical identification procedure. This practice is motivated by the common belief that the GARCH(1,1) (or its simplest asymmetric extensions) is sufficient to capture the properties of financial series and that higher‐order models may be unnecessarily complicated.
We will show that, for a large number of series, this practice is not always statistically justified. We consider daily and weekly series of 11 returns (CAC, DAX, DJA, DJI, DJT, DJU, FTSE, Nasdaq, Nikkei, SMI and S&P 500) and five exchange rates. The observations cover the period from 2 January 1990 to 22 January 2009 for the daily returns and exchange rates, and from 2 January 1990 to 20 January 2009 for the weekly returns (except for the indices for which the first observations are after 1990). We begin with the portmanteau tests defined in Section 8.4 . Table 8.4 shows that the ARCH models (even with large order q) are generally rejected, whereas the GARCH(1,1) is only occasionally rejected. This table only concerns the daily returns, but similar conclusions hold for the weekly returns and exchange rates. The portmanteau tests are known to be omnibus tests, powerful for a broad spectrum of alternatives. As we will now see, for the specific alternatives for which they are built, the tests defined in Section 8.3 (Wald, score, and likelihood ratio) may be much more powerful.
Portmanteau test p‐values for adequacy of the ARCH(5) and GARCH(1,1) models for daily returns of stock market indices, based on m squared residual autocovariances.
| M | ||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| Portmanteau tests for adequacy of the ARCH(5) | ||||||||||||
| CAC | 0.194 | 0.010 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| DAX | 0.506 | 0.157 | 0.140 | 0.049 | 0.044 | 0.061 | 0.080 | 0.119 | 0.140 | 0.196 | 0.185 | 0.237 |
| DJA | 0.441 | 0.34 | 0.139 | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| DJI | 0.451 | 0.374 | 0.015 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| DJT | 0.255 | 0.514 | 0.356 | 0.044 | 0.025 | 0.013 | 0.020 | 0.023 | 0.000 | 0.000 | 0.000 | 0.000 |
| DJU | 0.477 | 0.341 | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| FTSE | 0.139 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Nasdaq | 0.025 | 0.031 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Nikkei | 0.004 | 0.000 | 0.001 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| SMI | 0.502 | 0.692 | 0.407 | 0.370 | 0.211 | 0.264 | 0.351 | 0.374 | 0.463 | 0.533 | 0.623 | 0.700 |
| S&P 500 | 0.647 | 0.540 | 0.012 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Portmanteau tests for adequacy of the GARCH(1,1) | ||||||||||||
| CAC | 0.312 | 0.379 | 0.523 | 0.229 | 0.301 | 0.396 | 0.495 | 0.578 | 0.672 | 0.660 | 0.704 | 0.743 |
| DAX | 0.302 | 0.583 | 0.574 | 0.704 | 0.823 | 0.901 | 0.938 | 0.968 | 0.983 | 0.989 | 0.994 | 0.995 |
| DJA | 0.376 | 0.424 | 0.634 | 0.740 | 0.837 | 0.908 | 0.838 | 0.886 | 0.909 | 0.916 | 0.938 | 0.959 |
| DJI | 0.202 | 0.208 | 0.363 | 0.505 | 0.632 | 0.742 | 0.770 | 0.812 | 0.871 | 0.729 | 0.748 | 0.811 |
| DJT | 0.750 | 0.100 | 0.203 | 0.276 | 0.398 | 0.518 | 0.635 | 0.721 | 0.804 | 0.834 | 0.885 | 0.925 |
| DJU | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| FTSE | 0.733 | 0.940 | 0.934 | 0.980 | 0.919 | 0.964 | 0.328 | 0.424 | 0.465 | 0.448 | 0.083 | 0.108 |
| Nasdaq | 0.523 | 0.024 | 0.061 | 0.019 | 0.001 | 0.001 | 0.002 | 0.001 | 0.002 | 0.001 | 0.001 | 0.002 |
| Nikkei | 0.049 | 0.146 | 0.246 | 0.386 | 0.356 | 0.475 | 0.567 | 0.624 | 0.703 | 0.775 | 0.718 | 0.764 |
| SMI | 0.586 | 0.758 | 0.908 | 0.959 | 0.986 | 0.995 | 0.996 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 |
| S&P 500 | 0.598 | 0.364 | 0.528 | 0.643 | 0.673 | 0.394 | 0.512 | 0.535 | 0.639 | 0.432 | 0.496 | 0.594 |
p‐values less than 5% are in bold, those less than 1% are underlined.
The GARCH(1,1) model is chosen as the benchmark model and is successively tested against the GARCH(1,2), GARCH(1,3), GARCH(1,4), and GARCH(2,1) models. In each case, the three tests (Wald, score, and likelihood ratio) are applied. The empirical p‐values are displayed in Table 8.5. This table shows that (i) the results of the tests strongly depend on the alternative; (ii) the p‐values of the three tests can be quite different; (iii) for most of the series, the GARCH(1,1) model is clearly rejected. Point (ii) is not surprising because the asymptotic equivalence between the three tests is only shown under the null hypothesis or under local alternatives. Moreover, because of the positivity constraints, it is possible (see, for instance, the DJU) that the estimated GARCH(1,2) model satisfies ![]() with
with ![]() . In this case, when the estimators lie at the boundary of the parameter space and the score is strongly positive, the Wald and LR tests do not reject the GARCH(1,1) model, whereas the score does reject it. In other situations, the Wald or LR test rejects the GARCH(1,1), whereas the score does not (see, for instance the DAX for the GARCH(1,4) alternative). This study shows that it is often relevant to employ several tests and several alternatives. The conservative approach of Bonferroni (rejecting if the minimal p‐value multiplied by the number of tests is less than a given level
α
), leads to rejection of the GARCH(1,1) model for 16 out of the 24 series in Table 8.5. Other procedures, less conservative than that of Bonferroni, could also be applied (see Wright 1992) without changing the general conclusion.
. In this case, when the estimators lie at the boundary of the parameter space and the score is strongly positive, the Wald and LR tests do not reject the GARCH(1,1) model, whereas the score does reject it. In other situations, the Wald or LR test rejects the GARCH(1,1), whereas the score does not (see, for instance the DAX for the GARCH(1,4) alternative). This study shows that it is often relevant to employ several tests and several alternatives. The conservative approach of Bonferroni (rejecting if the minimal p‐value multiplied by the number of tests is less than a given level
α
), leads to rejection of the GARCH(1,1) model for 16 out of the 24 series in Table 8.5. Other procedures, less conservative than that of Bonferroni, could also be applied (see Wright 1992) without changing the general conclusion.
p‐values for tests of the null of a GARCH(1,1) model against the GARCH(1,2), GARCH(1,3), GARCH(1,4), and GARCH(2,1) alternatives, for returns of stock market indices and exchange rates.
| Alternative | ||||||||||||
| GARCH(1,2) | GARCH(1,3) | GARCH(1,4) | GARCH(2,1) | |||||||||
| W n | R n | L n | W n | R n | L n | W n | R n | L n | W n | R n | L n | |
| Daily returns of indices | ||||||||||||
| CAC | 0.007 | 0.033 | 0.013 | 0.005 | 0.000 | 0.001 | 0.024 | 0.188 | 0.040 | 0.500 | 0.280 | 0.500 |
| DAX | 0.002 | 0.001 | 0.003 | 0.001 | 0.000 | 0.000 | 0.001 | 0.162 | 0.014 | 0.350 | 0.031 | 0.143 |
| DJA | 0.158 | 0.337 | 0.166 | 0.259 | 0.285 | 0.269 | 0.081 | 0.134 | 0.064 | 0.500 | 0.189 | 0.500 |
| DJI | 0.044 | 0.100 | 0.049 | 0.088 | 0.071 | 0.094 | 0.107 | 0.143 | 0.114 | 0.500 | 0.012 | 0.500 |
| DJT | 0.469 | 0.942 | 0.470 | 0.648 | 0.009 | 0.648 | 0.519 | 0.116 | 0.517 | 0.369 | 0.261 | 0.262 |
| DJU | 0.500 | 0.000 | 0.500 | 0.643 | 0.000 | 0.643 | 0.725 | 0.001 | 0.725 | 0.017 | 0.000 | 0.005 |
| FTSE | 0.080 | 0.122 | 0.071 | 0.093 | 0.223 | 0.083 | 0.213 | 0.423 | 0.205 | 0.458 | 0.843 | 0.442 |
| Nasdaq | 0.469 | 0.922 | 0.468 | 0.579 | 0.983 | 0.578 | 0.683 | 0.995 | 0.702 | 0.500 | 0.928 | 0.500 |
| Nikkei | 0.004 | 0.002 | 0.004 | 0.042 | 0.332 | 0.081 | 0.052 | 0.526 | 0.108 | 0.238 | 0.000 | 0.027 |
| SMI | 0.224 | 0.530 | 0.245 | 0.058 | 0.202 | 0.063 | 0.086 | 0.431 | 0.108 | 0.500 | 0.932 | 0.500 |
| SP 500 | 0.053 | 0.079 | 0.047 | 0.089 | 0.035 | 0.078 | 0.055 | 0.052 | 0.043 | 0.500 | 0.045 | 0.500 |
| Weekly returns of indices | ||||||||||||
| CAC | 0.017 | 0.143 | 0.049 | 0.028 | 0.272 | 0.068 | 0.061 | 0.478 | 0.142 | 0.500 | 0.575 | 0.500 |
| DAX | 0.154 | 0.000 | 0.004 | 0.674 | 0.798 | 0.674 | 0.667 | 0.892 | 0.661 | 0.043 | 0.000 | 0.000 |
| DJA | 0.194 | 0.001 | 0.052 | 0.692 | 0.607 | 0.692 | 0.679 | 0.899 | 0.597 | 0.003 | 0.000 | 0.000 |
| DJI | 0.173 | 0.000 | 0.030 | 0.682 | 0.482 | 0.682 | 0.788 | 0.358 | 0.788 | 0.000 | 0.000 | 0.000 |
| DJT | 0.428 | 0.623 | 0.385 | 0.628 | 0.456 | 0.628 | 0.693 | 0.552 | 0.693 | 0.002 | 0.000 | 0.004 |
| DJU | 0.500 | 0.747 | 0.500 | 0.646 | 0.011 | 0.646 | 0.747 | 0.038 | 0.747 | 0.071 | 0.003 | 0.017 |
| FTSE | 0.188 | 0.484 | 0.222 | 0.183 | 0.534 | 0.214 | 0.242 | 0.472 | 0.272 | 0.500 | 0.532 | 0.500 |
| Nasdaq | 0.441 | 0.905 | 0.448 | 0.387 | 0.868 | 0.412 | 0.199 | 0.927 | 0.266 | 0.069 | 0.961 | 0.344 |
| Nikkei | 0.500 | 0.140 | 0.500 | 0.310 | 0.154 | 0.260 | 0.330 | 0.316 | 0.462 | 0.030 | 0.138 | 0.053 |
| SMI | 0.500 | 0.720 | 0.500 | 0.217 | 0.144 | 0.150 | 0.796 | 0.754 | 0.796 | 0.314 | 0.769 | 0.360 |
| SP 500 | 0.117 | 0.000 | 0.001 | 0.659 | 0.114 | 0.659 | 0.724 | 0.051 | 0.724 | 0.000 | 0.000 | 0.000 |
| Daily exchange rates | ||||||||||||
| $/€ | 0.452 | 0.904 | 0.452 | 0.194 | 0.423 | 0.181 | 0.066 | 0.000 | 0.015 | 0.500 | 0.002 | 0.500 |
| ¥/€ | 0.037 | 0.000 | 0.002 | 0.616 | 0.090 | 0.618 | 0.304 | 0.000 | 0.227 | 0.136 | 0.000 | 0.000 |
| £/€ | 0.439 | 0.879 | 0.440 | 0.471 | 0.905 | 0.464 | 0.677 | 0.981 | 0.677 | 0.258 | 0.493 | 0.248 |
| CHF/€ | 0.141 | 0.000 | 0.012 | 0.641 | 0.152 | 0.641 | 0.520 | 0.154 | 0.562 | 0.012 | 0.000 | 0.000 |
| C$/€ | 0.500 | 0.268 | 0.500 | 0.631 | 0.714 | 0.631 | 0.032 | 0.000 | 0.002 | 0.045 | 0.045 | 0.029 |
p‐values less than 5% are in bold, those less than 1% are underlined.
In conclusion, this study shows that the GARCH(1,1) model is certainly overrepresented in empirical studies. The tests presented in this chapter are easily implemented and lead to selection of GARCH models that are more elaborate than the GARCH(1,1).
8.6 Proofs of the Main Results*
8.7 Bibliographical Notes
It is well known that when the parameter is at the boundary of the parameter space, the maximum likelihood estimator does not necessarily satisfy the first‐order conditions and, in general, does not admit a limiting normal distribution. The technique, employed in particular by Chernoff (1954) and Andrews (1997) in a general framework, involves approximating the quasi‐likelihood by a quadratic function, and defining the asymptotic distribution of the QML as that of the projection of a Gaussian vector on a convex cone. Particular GARCH models are considered by Andrews (1997, 1999) and Jordan (2003). The general GARCH(p, q) case is considered by Francq and Zakoïan (2007). A proof of Theorem 8.1, when the moment assumption B7 is replaced by assumption B7 ′ of Remark 8.2, can be found in the latter reference. When the nullity of GARCH coefficients is tested, the parameter is at the boundary of the parameter space under the null, and the alternative is one‐sided. Numerous works deal with testing problems where, under the null hypothesis, the parameter is at the boundary of the parameter space. Such problems have been considered by Chernoff (1954), Bartholomew (1959), Perlman (1969), and Gouriéroux, Holly, and Monfort (1982), among many others. General one‐sided tests have been studied by, for instance Rogers (1986), Wolak (1989), Silvapulle and Silvapulle (1995), and King and Wu (1997). Papers dealing more specifically with ARCH and GARCH models are Lee and King (1993), Hong (1997), Demos and Sentana (1998), Andrews (2001), Hong and Lee (2001), Dufour et al. (2004), Francq and Zakoïan (2009b) and Pedersen and Rahbek (2018).
The portmanteau tests based on the squared residual autocovariances were proposed by McLeod and Li (1983), Li and Mak (1994), and Ling and Li (1997). The results presented here closely follow Berkes, Horváth, and Kokoszka (2003a). Problems of interest that are not studied in this book are the tests on the distribution of the iid process (see Horváth, Kokoszka, and Teyssiére 2004; Horváth and Zitikis 2006).
Concerning the overrepresentation of the GARCH(1, 1) model in financial studies, we mention Stărică (2006). This paper highlights, on a very long S&P 500 series, the poor performance of the GARCH(1, 1) in terms of prediction and modelling, and suggests a non‐stationary dynamics of the returns.
8.8 Exercises
8.1 (Minimisation of a distance under a linear constraint)
Let J be an n × n invertible matrix, let x 0 be a vector of ℝ n , and let K be a full‐rank p × n matrix, p ≤ n . Solve the problem of the minimisation of Q(x) = (x − x 0)′ J(x − x 0) under the constraint Kx = 0.
-
8.2 (Minimisation of a distance when some components are equal to zero) Let
J
be an
n × n
invertible matrix,
x
0
a vector of ℝ
n
, and
p < n
. Minimise
Q(x) = (x − x
0)′
J(x − x
0) under the constraints
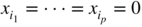 (
x
i
denoting the
i
th component of
x
, and assuming that 1 ≤ i
1 < ⋯ < i
p
≤ n
).
(
x
i
denoting the
i
th component of
x
, and assuming that 1 ≤ i
1 < ⋯ < i
p
≤ n
). -
8.3 (Lagrangian or method of substitution for optimisation with constraints) Compare the solutions of the optimisation problem of Exercise 8.2, with

and the constraints
- x 3 = 0,
- x 2 = x 3 = 0.
-
8.4 (Minimisation of a distance under inequality constraints) Find the minimum of the function

under the constraints λ 2 ≥ 0 and λ 3 ≥ 0, when
- Z = (−2, 1, 2)′ ,
- Z = (−2, − 1, 2)′ ,
- Z = (−2, 1, − 2)′ ,
- Z = (−2, − 1, − 2)′ .
- 8.5 (Influence of the positivity constraints on the moments of the QMLE) Compute the mean and variance of the vector λ Λ defined by equality (8.16). Compare these moments with the corresponding moments of Z = (Z 1, Z 2, Z 3)′ .
- 8.6 (Asymptotic distribution of the QMLE of an ARCH in the conditionally homoscedastic case) For an ARCH( q ) model, compute the matrix Σ involved in the asymptotic distribution of the QMLE in the case where all the α 0i are equal to zero.
-
8.7 (Asymptotic distribution of the QMLE when an ARCH(1) is fitted to a strong white noise) Let
 be the QMLE in the ARCH(1) model
be the QMLE in the ARCH(1) model  when the true parameter is equal to (ω
0, α
0) = (ω
0, 0) and when
when the true parameter is equal to (ω
0, α
0) = (ω
0, 0) and when  . Give an expression for the asymptotic distribution of
. Give an expression for the asymptotic distribution of  with the aid of
with the aid of
Compute the mean vector and the variance matrix of this asymptotic distribution. Determine the density of the asymptotic distribution of
 . Give an expression for the kurtosis coefficient of this distribution as function of
κ
η
.
. Give an expression for the kurtosis coefficient of this distribution as function of
κ
η
. -
8.8 (One‐sided and two‐sided tests have the same Bahadur slopes) Let
X
1, …, X
n
be a sample from the
풩(θ, 1) distribution. Consider the null hypothesis
H
0 : θ = 0. Denote by Φ the
풩(0, 1) cumulative distribution function. By the Neyman–Pearson lemma, we know that, for alternatives of the form
H
1 : θ > 0, the one‐sided test of rejection region

is uniformly more powerful than the two‐sided test of rejection region

(moreover, C is uniformly more powerful than any other test of level α or less). Although the previous argument shows that the test C is superior to the test C * in finite samples, we will conduct an asymptotic comparison of the two tests, using the Bahadur and Pitman approaches.
- The asymptotic Bahadur slope c(θ) is defined as the almost sure limit of −2/n times the logarithm of the p ‐value under P θ , when the limit exists. Compare the Bahadur slopes of the two tests.
- In the Pitman approach, we define a local power around
θ = 0 as being the power at
 . Compare the local powers of
C
and
C
*
. Compare also the local asymptotic powers of the two tests for non‐Gaussian samples.
. Compare the local powers of
C
and
C
*
. Compare also the local asymptotic powers of the two tests for non‐Gaussian samples.
-
8.9 (The local asymptotic approach cannot distinguish the Wald, score and likelihood ratio tests) Let
X
1,…, X
n
be a sample of the
 distribution, where
θ
and
σ
2
are unknown. Consider the null hypothesis
H
0 : θ = 0 against the alternative
H
1 : θ > 0. Consider the following three tests:
distribution, where
θ
and
σ
2
are unknown. Consider the null hypothesis
H
0 : θ = 0 against the alternative
H
1 : θ > 0. Consider the following three tests:-
 , whereis the Wald statistic;
, whereis the Wald statistic;
-
 , where
, where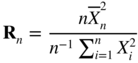
is the Rao score statistic;
-
 , where
, where
is the likelihood ratio statistic.
Give a justification for these three tests. Compare their local asymptotic powers and their Bahadur slopes.
-
-
8.10 (The Wald and likelihood ratio statistics have the same asymptotic distribution) Consider the case
d
2 = 1, that is, the framework of Section 8.3.3 where only one coefficient is equal to zero. Without using Remark 8.3, show that the asymptotic laws
W
and
L
defined by (8.22) and (8.24) are such that

- 8.11 (For testing conditional homoscedasticity, the Wald and likelihood ratio statistics have the same asymptotic distribution) Repeat Exercise 8.10 for the conditional homoscedasticity test ( 8.26) in the ARCH( q ) case.
- 8.12 (The product of two independent random variables is null if and only if one of the two variables is null) Let X and Y be two independent random variables such that XY = 0 almost surely. Show that either X = 0 almost surely or Y = 0 almost surely.