
In this chapter, we will explore transferrable skills that allow us to use schemaless data and distributed technologies to solve big data problems. The system we will build in this chapter will prepare us for a future where democratic elections all happen online—on Twitter of course. Our solution will collect and count votes by querying Twitter's streaming API for mentions of specific hashtags, and each component will be capable of horizontally scaling to meet demand. Our use case is a fun and interesting one, but the core concepts we'll learn and specific technology choices we'll make are the real focus of this chapter. The ideas discussed here are directly applicable to any system that needs true-scale capabilities.
Note
Horizontal scaling refers to adding nodes, such as physical machines, to a system in order to improve its availability, performance, and/or capacity. Big data companies such as Google can scale by adding affordable and easy-to-obtain hardware (commonly referred to as commodity hardware) due to the way they write their software and architect their solutions. Vertical scaling is synonymous with increasing the resource available to a single node, such as adding additional RAM to a box, or a processor with more cores.
In this chapter, you will:
- Learn about distributed NoSQL datastores; specifically how to interact with MongoDB
- Learn about distributed messaging queues; specifically Bit.ly's NSQ and how to use the
go-nsqpackage to easily publish and subscribe to events - Stream live tweet data through Twitter's streaming APIs and manage long running net connections
- Learn about how to properly stop programs with many internal goroutines
- Learn how to use low memory channels for signaling
Having a basic design sketched out is often useful, especially in distributed systems where many components will be communicating with each other in different ways. We don't want to spend too long on this stage because our design is likely to evolve as we get stuck into the details, but we will look at a high-level outline so we can discuss the constituents and how they fit together.
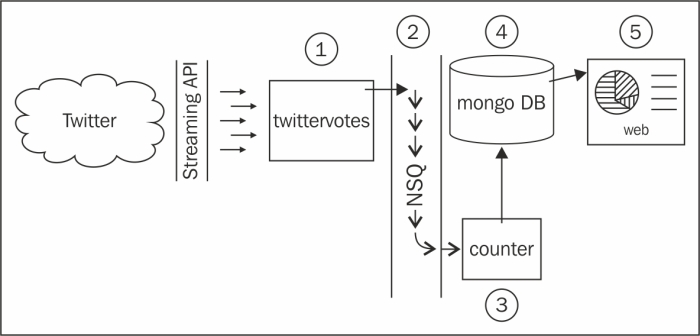
The preceding image shows the basic overview of the system we are going to build:
- Twitter is the social media network we all know and love.
- Twitter's streaming API allows long-running connections where tweet data is streamed as quickly as possible.
twittervotesis a program we will write that reads tweets and pushes the votes into the messaging queue.twittervotespulls the relevant tweet data, figures out what is being voted for (or rather, which options are mentioned), and pushes the vote into NSQ.- NSQ is an open source, real-time distributed messaging platform designed to operate at scale, built and maintained by Bit.ly. NSQ carries the message across its instances making it available to anyone who has expressed an interest in the vote data.
counteris a program we will write that listens out for votes on the messaging queue, and periodically saves the results in the MongoDB database.counterreceives the vote messages from NSQ and keeps an in-memory tally of the results, periodically pushing an update to persist the data.- MongoDB is an open source document database designed to operate at scale.
webis a web server program that will expose the live results that we will write in the next chapter.
It could be argued that a single Go program could be written that reads the tweets, counts the votes, and pushes them to a user interface but such a solution, while being a great proof of concept, would be very limited in scale. In our design, any one of the components can be horizontally scaled as the demand for that particular capability increases. If we have relatively few polls, but lots of people viewing the data, we can keep the twittervotes and counter instances down and add more web and MongoDB nodes, or vice versa if the situation is reversed.
Another key advantage to our design is redundancy; since we can have many instances of our components working at the same time, if one of our boxes disappears (due to a system crash or power cut, for example) the others can pick up the slack. Modern architectures often distribute such a system over the geographical expanse to protect from local natural disasters too. All of these options are available to use if we build our solution in this way.
We chose the specific technologies in this chapter because of their links to Go (NSQ, for example, is written entirely in Go), and the availability of well-tested drivers and packages. Conceptually, however, you can drop in a variety of alternatives as you see fit.
We will call our MongoDB database ballots. It will contain a single collection called polls which is where we will store the poll details, such as the title, the options, and the results (in a single JSON document). The code for a poll will look something like this:
{
"_id": "???",
"title": "Poll title",
"options": ["one", "two", "three"],
"results": {
"one": 100,
"two": 200,
"three": 300
}
}The _id field is automatically generated by MongoDB and will be how we identify each poll. The options field contains an array of string options; these are the hashtags we will look for on Twitter. The results field is a map where the key represents the option, and the value represents the total number of votes for each item.