
Chapter 8. Data Processing Tools
Google Cloud offers a variety of scalable, data processing tools. Dataflow and Dataproc are the most commonly used (outside of BigQuery, covered in another chapter). Both of these tools allow you to run open source Apache Spark and Apache Beam pipelines in a serverless or near-serverless environment. Cloud Dataflow, in particular, is an excellent environment for running large-scale, mission critical streaming pipelines for real-time analytics, data ingestion, and business logic. These recipes are examples of some of the most common tasks you’ll perform as you implement solutions on these tools.
Building a Streaming Pipeline in Dataflow SQL
- Problem
-
You want to build a streaming pipeline using various PubSub or BigQuery sources but don’t want to write a Python or Java Apache Beam pipeline to execute on Dataflow
- Solution
-
Dataflow SQL allows you to author pipelines purely in SQL and execute them from the Dataflow UI.
-
To demonstrate this, we will use a sample dataset of sales transactions, including the state where the transaction took place, and an enrichment table of sales regions. Each sales region covers several states, and we want to annotate each transaction with its sales region, in real time, for immediate analysis and avoiding future joins with the sales_region table. First, create the PubSub topic and BigQuery table:
PROJECT_ID=<my_project> gcloud pubsub topics create live_transactions bq mk --location=us sales_data # load data into the table bq load --autodetect $PROJECT_ID:sales_data.us_sales_regions ./bq_data.csv # examine the table bq head -n 10 $PROJECT_ID:sales_data.us_sales_regions -
Next, you’ll need to add a schema to your PubSub topic. This can be done after you switch the BigQuery UI to “Dataflow Engine” mode as indicated in Figure 9-1 and 9-2:

Figure 8-1. Query settings to enable “Dataflow SQL”
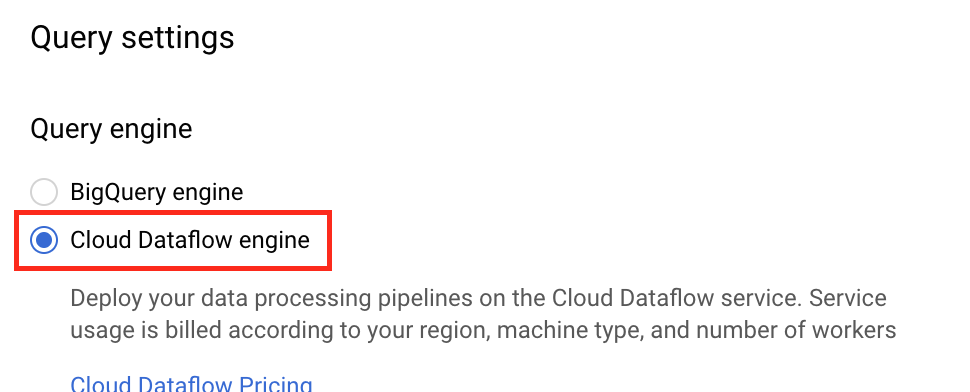
Figure 8-2. Enabling Dataflow Engine
-
Now you should be able to add “Cloud Dataflow sources” as shown in Figure 9-3.
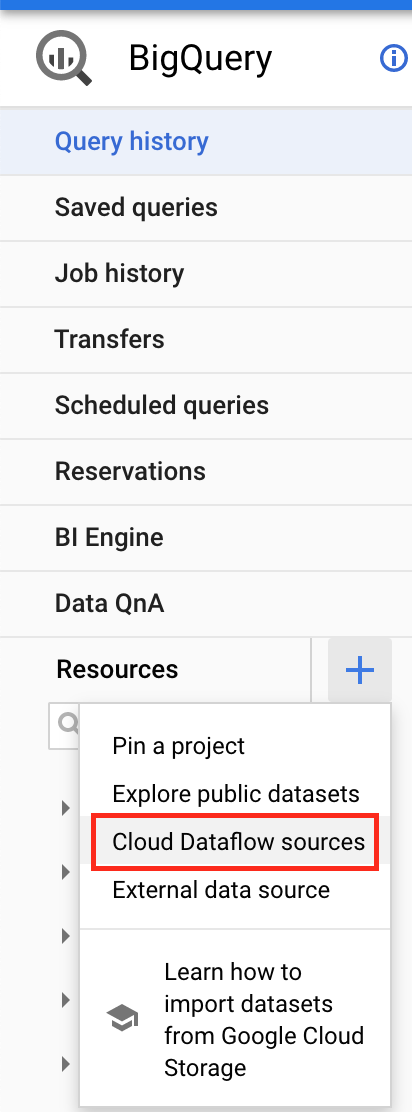
Figure 8-3. Adding Cloud Dataflow sources
-
Find and choose your topic as in Figure 9-4.
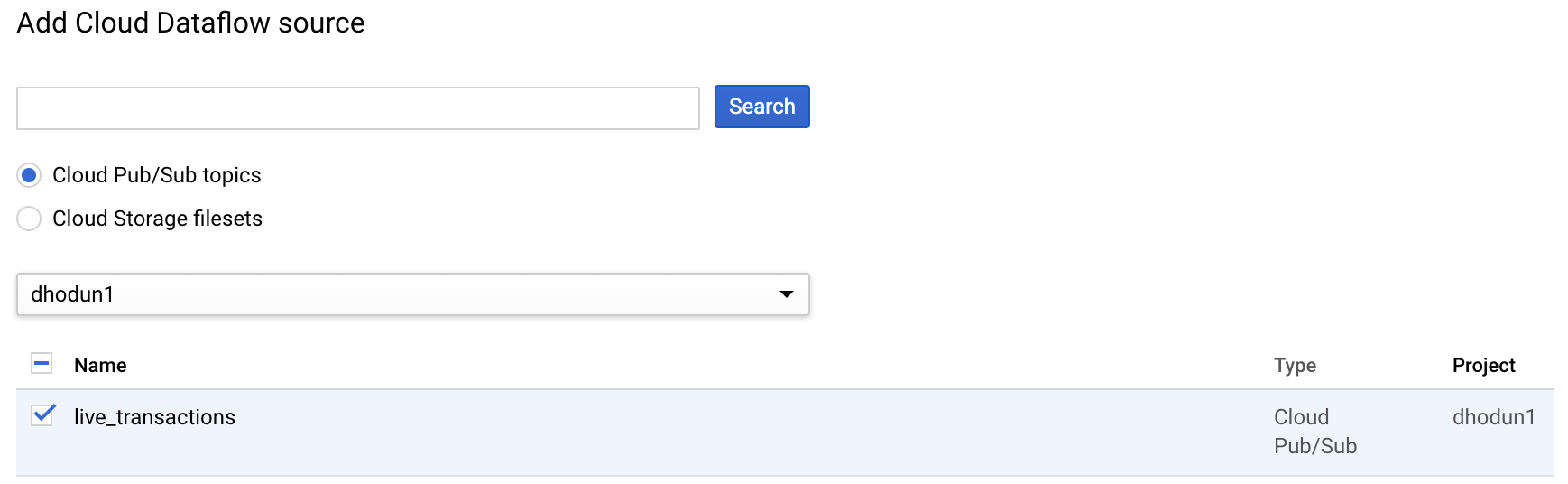
Figure 8-4. Adding your PubSub topic
-
Select your topic from the resource tree to add a schema as in Figures 9-5 and 9-6.
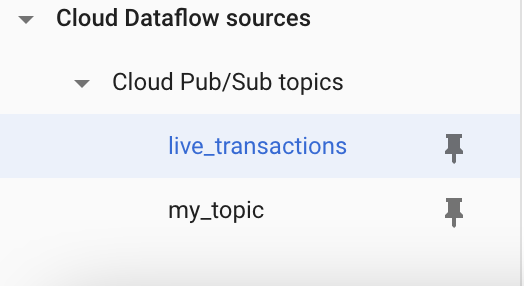
Figure 8-5. Selecting topic to which attach a schema

Figure 8-6. Adding a schema to your topic
-
Add the following schema and submit, shown in Figure 10-7. Now you can query on this pubsub topic as if it were a BigQuery table.
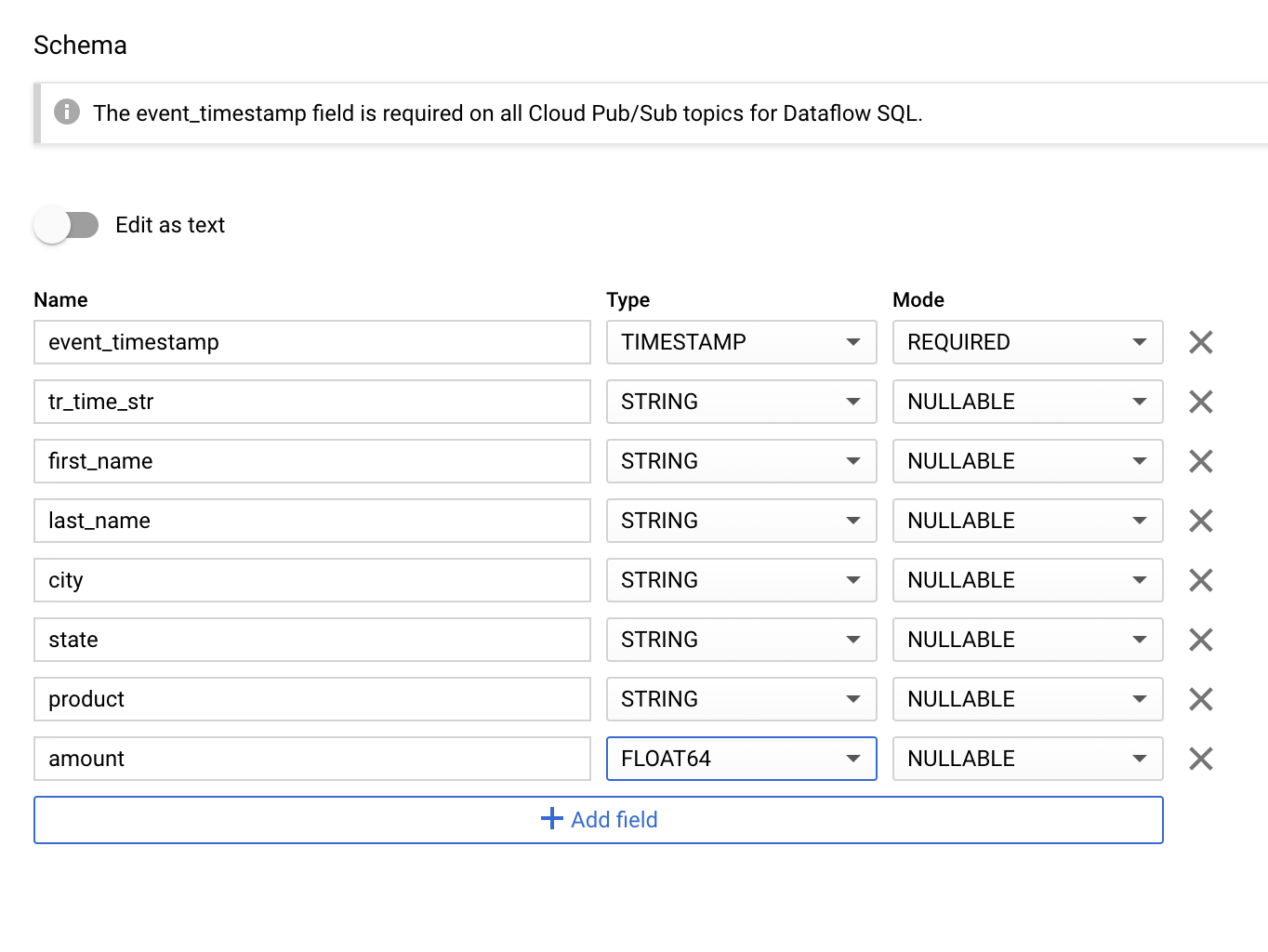
Figure 8-7. Adding a schema to your topic
-
Generate PubSub Data
export PROJECT_ID=$PROJECT_ID python publish_pubsub.py
-
Now you can author a fully streaming pipeline in the Dataflow SQL UI and execute the job. This query demonstrates joining a BigQuery table with a PubSub stream, as well as a windowed aggregation with TUMBLE(), the SQL implementation of “sliding windows”.
SELECT SUM(stream.amount) AS state_sales, stream.state AS state, stream.window_start AS minute FROM TUMBLE ( ( SELECT tr.tr_time_str, tr.state, tr.amount, tr.event_timestamp FROM pubsub.topic.dhodun1.live_transactions AS tr ), DESCRIPTOR(event_timestamp), "INTERVAL 1 MINUTE" ) AS stream GROUP BY stream.window_start, stream.state ) stream_aggregate INNER JOIN dhodun1.sales_data.us_sales_regions table ON stream_aggregate.state = table.state_name GROUP BY table.sales_region, stream_aggregate.minute
Discussion
Dataflow is a serverless, extremely scalable data processing service that executes both Batch and Streaming Apache Beam pipelines. Beam pipelines can be written in a variety of languages, including Java and Python, and then executed on a variety of runners, including Dataflow, Spark, and Flink. Dataflow SQL is an extension of Apache Beam SQL that allows users to write simple (or complex) streaming pipelines in SQL from the Google Cloud UI. This example shows how to join an unbounded PubSub dataset with a bounded BigQuery enrichment dataset, while performing windowed aggregations on the live dataset (essentially per-minute summarizations of the live transactional data)
Querying BigQuery from a Dataproc Job
- Problem
-
Your data warehousing solution of choice is BigQuery, and your processing logic is in Spark, so you need to configure access across the two.
- Solution
-
Using initialization actions when you create your Dataproc clusters, you can easily enable access to BigQuery, Google Cloud Storage, and other storage systems external to your Dataproc cluster.
-
First, create a Dataproc cluster with the necessary connectors and initialization actions
REGION=us-central1 CLUSTER_NAME=sample-cluster gcloud dataproc clusters create ${CLUSTER_NAME} --region ${REGION} --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/connectors/connectors.sh --metadata gcs-connector-version=2.2.0 --metadata bigquery-connector-version=1.2.0 --metadata spark-bigquery-connector-version=0.19.1 -
When the cluster is created, prepare a PySpark script to submit that will load an entire table into Spark for additional Querying
#!/usr/bin/python from pyspark.sql import SparkSession spark = SparkSession .builder .master('yarn') .appName('cookbook-query') .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "dhodun1" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. states = spark.read.format('bigquery') .option('table', 'dhodun1:sales_data.us_sales_regions') .load() states.createOrReplaceTempView('us_sales_regions') # Count how many states in each sales region regions_count = spark.sql( 'SELECT COUNT(*) AS num_states, sales_region FROM us_sales_regions GROUP BY sales_region') regions_count.show() regions_count.printSchema() # Saving the data to BigQuery regions_count.write.format('bigquery') .option('table', 'sales_data.sales_region_aggregate') .save() -
Lastly, submit the query using the Dataproc Jobs API. Notice that you are using a pre-built jar and providing the script.
#!/bin/bash REGION=us-central1 CLUSTER_NAME=sample-cluster gcloud dataproc jobs submit pyspark query_script.py --cluster=$CLUSTER_NAME --region=$REGION --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar -
You should see job completion, as well as a new table called “sales_region_aggregate” in your BigQuery dataset, as shown in the job output in Figure 9-8.
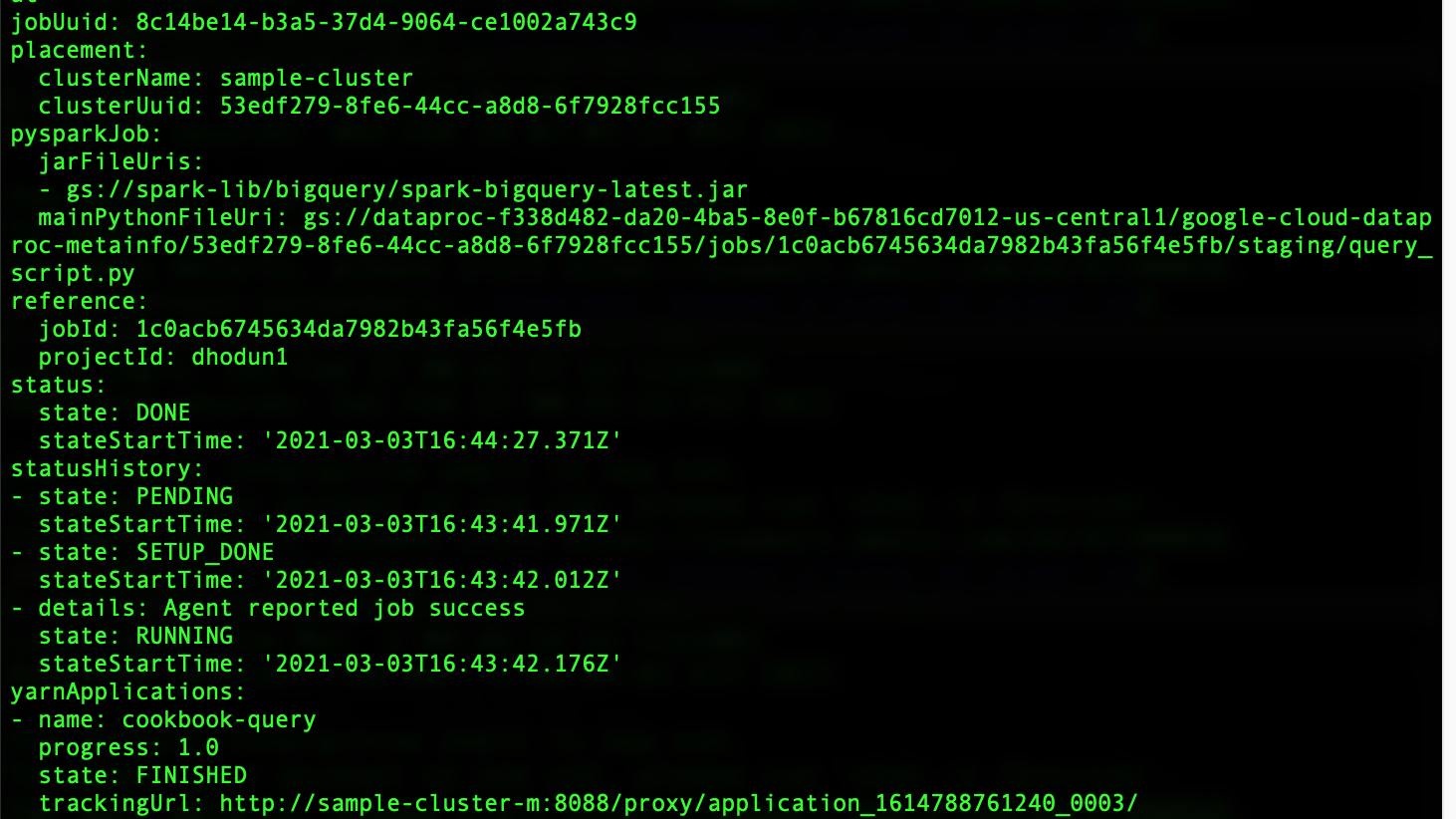
Figure 8-8. Dataproc job output
Discussion
Dataproc is Google Cloud’s managed Hadoop and Spark service, allowing for efficient, scalable execution of your Spark pipelines using just-in-time clusters provisioned in 90 seconds. Dataproc has a number of easy-to-use connectors for accessing your GCP data, primarily the BigQuery and Google Cloud Storage connectors. This allows you to write pipelines in OSS Spark code, but easily offload the storage (and sometimes in the case of BigQuery, significant compute) from the cluster into cloud native, cheaper and more efficient solutions. This allows for the paradigm of “per-job clusters” or “short lived clusters” vs. a long-lived monolithic cluster, adding operational burden.
Inferring and Using Schemas in Dataflow
- Problem
-
Your current Dataflow pipeline leverages custom coders, even though your data is well structured and defined in POJOs (plain old Java objects). Additionally, you are having to write out the schema of the objects for BigQueryIO.Write(). You want to write more concise, readable Dataflow pipelines and avoid custom coders to speed up development.
- Solution
-
Apache Beam gives you the ability to infer schemas from well-structured data, which automatically gives you high-performance encoding and automatically creates the BigQuery schema.
-
First, annotate any POJOs like this so that Beam will detect and register a schema for the object. Note that you can mark fields as nullable:
@DefaultSchema(JavaFieldSchema.class) public class LiveTransaction { String tr_time_str; @javax.annotation.Nullable String first_name; String last_name; String city; String state; String product; Double amount; } -
Now, you can use this schema in your pipeline to avoid using custom coders. You can also convert to and from <Row> objects, which are the generic schematized object in beam:
pipeline.apply("ReadFromPubSub", PubsubIO.readStrings().fromTopic(topic)) .apply("JsonToRow", JsonToRow.withSchema(LiveTransaction)) .apply("ConvertToObject", Convert.to(LiveTransaction.class)) -
Lastly, you can now add the “useBeamSchema()” object on your BigQueryIO.write() calls, whereas previously you had to create a TableSchema object and write out the structure of the data again to then pass to BigQueryIO.write():
.apply("WriteToBQ", BigQueryIO.<LiveTransaction>write().to(output).useBeamSchema() .withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)); -
To run the example pipeline, replace the static variables in the pipeline code, start the python generator, and run the pipeline with bash run.sh.
Discussion
More traditional Apache Beam pipelines, run on Dataflow, leveraged the <K,V> (or Key, Value) style of Beam execution. You would pass objects from step to step in the pipeline, extracting Key when it was needed for other aggregations, such as Summing on a GroupByKey. Pipeline authors often had to reason about how to encode these objects, since they needed to be serialized between each pipeline step. Newer Beam Schemas allows for a more natural way to encode and address well-structured data. The above recipe shows how to infer a schema from a POJO definition vs. writing a custom coder. It also shows how to easily write this data into BigQuery without having to supply another version of the schema that an author would usually have to provide.
Mini-batching and Streaming Dataflow Data to BigQuery - Filters
- Problem
-
Your current Dataflow pipeline leverages BigQuery streaming, but you want to control for cost and have a subset of event types or datasets that can handle a small mini-batch and load delay (>90s).
- Solution
-
Implement BigQuery batch loading in your Dataflow Pipeline, potentially on a subset of less time-sensitive data to the same table. You can split the data with a branching pipeline and Filter Functions.
-
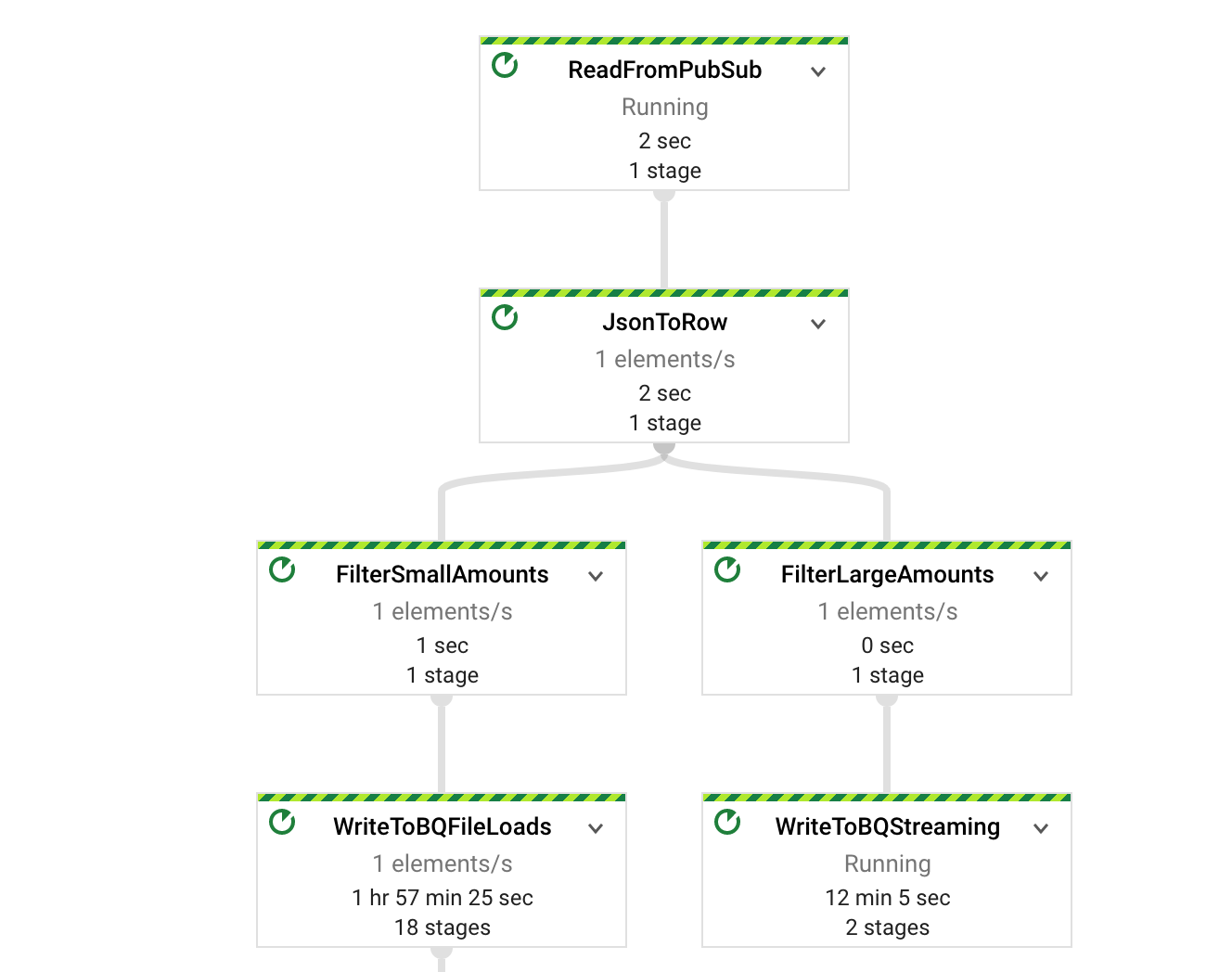
First, branch your pipeline the standard way and implement a Schema-aware filter function to determine which elements you want persisted in which method.
// Streaming Entries liveTransactions .apply("FilterLargeAmounts", Filter.<Row>create().whereFieldName("amount", (Double amount) -> amount > amountCutoff)) // Minibatch Entries liveTransactions .apply("FilterSmallAmounts", Filter.<Row>create().whereFieldName("amount", (Double amount) -> amount <= amountCutoff)) -
Next, implement your BigQuery write as before on the streaming branch
.apply("WriteToBQStreaming", BigQueryIO.<Row>write().to(output).useBeamSchema() .withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)); -
Lastly, implement a “BATCH_LOADS” BigQuery writer by setting .withMethod(), .withTriggeringFrequency(), and .withNumFileShards():
.apply("WriteToBQFileLoads", BigQueryIO.<Row>write().to(output).useBeamSchema() .withMethod(BigQueryIO.Write.Method.FILE_LOADS) .withTriggeringFrequency(Duration.standardSeconds(minibatchFrequency)) .withNumFileShards(1) .withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)); -
Run your pipeline with bash run.sh
Discussion
By default, Dataflow writes to BigQuery using streaming inserts in a streaming pipeline and a batch load job in a batch pipeline. Streaming inserts allow you to query the data immediately, allowing for realtime reporting and dashboards. However, there is an ingestion cost associated with streaming inserts, while batch load jobs are “free”. Generally best practice is to start with streaming inserts, but if this ingestion cost becomes an issue, you can usually identify some data to offload to “batch” loads with the method above. Currently this is only possible in the Java SDK, not the Python SDK.
Mini-batching and Streaming Dataflow Data to BigQuery - PCollectionTuples
- Problem
-
As before, your current Dataflow pipeline leverages BigQuery streaming, but you want to control for cost and have a subset of event types or datasets that can handle a small mini-batch and load delay (>90s).
- Solution
-
We will implement split batch loading as before, but this time with a singular Filter ParDo (vs. replicating the logic as before) and TupleTags to generate multiple PCollections from the single ParDo. We will also use @AccessField to write a ParDo using chema fields.
-
First, create TupleTags so you can generate two PCollections from a single ParDo.
static final TupleTag<Row> minibatchTransactions = new TupleTag<Row>() { }; static final TupleTag<Row> streamingTransactions = new TupleTag<Row>() { }; -
Next, implement the pipeline as before, but returning two PCollections and tagging them. Note that the item returned is a PCollectionTuple, not a PCollection, and that we were able to indicate which elements in the schema we wanted to address.
PCollectionTuple splitTransactions = pipeline.apply("ReadFromPubSub", PubsubIO.readStrings().fromTopic(topic)) .apply("JsonToRow", JsonToRow.withSchema(LiveTransaction)) .apply("FilterTransactions", ParDo.of(new DoFn<Row, Row>() { @ProcessElement public void process(ProcessContext context, @FieldAccess("amount") Double amount) { if (amount > amountCutoff) { context.output(streamingTransactions, context.element()); } else { context.output(minibatchTransactions, context.element()); } } }).withOutputTags(streamingTransactions, TupleTagList.of(minibatchTransactions))); -
Lastly, implement the batch loads and streaming loads as before, using the .get() method on the PCollectionTuple to index into the appropriate PCollection:
splitTransactions.get(streamingTransactions).setRowSchema(LiveTransaction) .apply("WriteToBQStreaming", BigQueryIO.<Row>write().to(output).useBeamSchema() .withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)); // Minibatch Entries splitTransactions.get(minibatchTransactions).setRowSchema(LiveTransaction) .apply("FilterSmallAmounts", Filter.<Row>create().whereFieldName("amount", (Double amount) -> amount <= amountCutoff)) .apply("WriteToBQFileLoads", BigQueryIO.<Row>write().to(output).useBeamSchema() .withMethod(BigQueryIO.Write.Method.FILE_LOADS) .withTriggeringFrequency(Duration.standardSeconds(minibatchFrequency)) .withNumFileShards(1) .withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)); -
Run your pipeline with bash run.sh

Discussion
This is a slightly more appropriate way to write the following pipeline, in particular because you aren’t replicating the filter logic in two different ParDos. It does require TupleTags and PColletionTuples, but this is a good design pattern to understand how to use.
8.1 Triggering a Dataflow job Automatically from a GCS Upload
- Problem
-
You want to automatically perform at ETL job on flat-file raw data staged into GCS. Another customer or team with which you work will periodically upload these files. You don’t want to rely just on time-based scheduling to automatically ingest the data. Rather you want to perform the ingest job right away.
- Solution
-
You can leverage Dataflow Templates and Google Cloud Function Triggers to automatically start a Dataflow job to process the file(s) immediately when they are landed.
-
Start with the same pipeline before, but parameterize it properly with an Options class.
public interface Options extends DataflowPipelineOptions { @Description("Path to events.json") String getInputPath(); void setInputPath(String inputPath); } public static void main(String[] args) { Options options = PipelineOptionsFactory.fromArgs(args).as(Options.class); run(options); } -
Now build an Uber jar with the entire pipeline. An Uber jar contains all the dependencies required for the pipeline, so it can be shipped and executed as a single unit.
mvn package ls -lh target/*.jar
-
Now that you have an Uber jar, we will build and stage a “Flex Template”. A Flex template will capture additional parameters as well as the full executable and package them further in a Docker image. This can then be called at any time, by anyone authorized, to start the pipeline with new parameters - in this case the file to ingest. First make sure you have a `metadata.json` file set for your parameters:
BUCKET=dhodun1 PROJECT=dhodun1 export TEMPLATE_PATH=gs://$BUCKET/tmp/templates export TEMPLATE_IMAGE="gcr.io/$PROJECT/cookbook/gcs-trigger-pipeline:latest" gcloud dataflow flex-template build $TEMPLATE_PATH --image-gcr-path "$TEMPLATE_IMAGE" --sdk-language "JAVA" --flex-template-base-image JAVA8 --metadata-file "metadata.json" --jar "target/cookbook-gcs-trigger-pipeline-1.0.jar" --env FLEX_TEMPLATE_JAVA_MAIN_CLASS="com.mypackage.pipeline.MyPipeline" -
Test Calling the Template from Command line:
BUCKET=dhodun1 PROJECT=dhodun1 export TEMPLATE_PATH=gs://$BUCKET/tmp/templates export TEMPLATE_IMAGE="gcr.io/$PROJECT/cookbook/gcs-trigger-pipeline:latest" INPUT_PATH="gs://dhodun1/tmp/data.json" export REGION="us-central1" gcloud dataflow flex-template run "cookbook-trigger-pipeline-`date +%Y%m%d-%H%M%S`" --template-file-gcs-location "$TEMPLATE_PATH" --parameters inputPath="$INPUT_PATH" --region "$REGION" -
Next we’ll deploy a GCS trigger using Cloud Functions to Trigger the pipeline. Take a look at the code in `main.py`.
BUCKET=dhodun1 gcloud functions deploy gcs_trigger --runtime python38 --trigger-resource $BUCKET --trigger-event google.storage.object.finalize
-
Lastly, trigger your new pipeline by re-creating the Json file. The pipeline is created automatically by the cloud function, the Flex Template kicks off, and eventually the pipeline complets and data is re-inserted into BigQuery
gsutil cp data.json gs://dhodun1/tmp/data.json
Discussion
There are several moving parts here. First is the notion of a fully parameterized, re-usable pipeline. You can build more generic pipelines directly in Java with ValueProvider classes, but it gets a little trickier to author, adds extra code to your pipeline, and make it less readable. Flex Templates come in handy here, and allow you to take more natural parameters on your pipeline. Flex templates also create a consistent deployment environment that any system can trigger. This is less of an issue with Java (since you can point Dataflow at an Uber Jar on GCS), but more important for Python where you need your triggering environment to have consistent PyPi dependencies. Lastly, we used a GCF trigger on GCS to interact with the Dataflow API and pass each new file in the bucket to the pipeline.