
The intuitive mind is a sacred gift and the rational mind is a faithful servant. We have created a society that honors the servant and has forgotten the gift. | ||
| --Albert Einstein | ||
The nice thing about computers is that they never get tired of repeatedly doing the same task. This is probably the single most important quality that justifies letting them take part in our life. Searching through countless files or web pages, downloading emails every 10 minutes, looking up all values of a stock symbol for the last quarter to paint a nice graph—these are only a few examples where the computer needs to repeatedly process an item of a data collection. It is no wonder that a great deal of programming work is about collections.
Because collections are so prominent in programming, Groovy alleviates the tedium of using them by directly supporting datatypes of a collective nature: ranges, lists, and maps. In accordance with what you have seen of the simple datatypes, Groovy’s support for collective datatypes encompasses new lightweight means for literal declaration, specialized operators, and numerous GDK enhancements.
The notation that Groovy uses to set its collective datatypes into action will be new to Java programmers, but as you will see, it is easy to understand and remember. You will pick it up so quickly that you will hardly be able to imagine there was a time when you were new to the concept.
Despite the new notation possibilities, lists and maps have the exact same semantics as in Java. This situation is slightly different for ranges, because they don’t have a direct equivalent in Java. So let’s start our tour with that topic.
Think about how often you’ve written a loop like this:
for (int i=0; i<upperBound; i++){
// do something with i
}Most of us have done this thousands of times. It is so common that we hardly ever think about it. Take the opportunity to do it now. Does the code tell you what it does or how it does it?
After careful inspection of the variable, the conditional, and the incrementation, we see that it’s an iteration starting at zero and not reaching the upper bound, assuming there are no side effects on i in the loop body. We have to go through the description of how the code works to find out what it does.
Next, consider how often you’ve written a conditional such as this:
if (x >= 0 && x <= upperBound) {
// do something with x
}The same thing applies here: We have to inspect how the code works in order to understand what it does. Variable x must be between zero and an upper bound for further processing. It’s easy to overlook that the upper bound is now inclusive.
Now, we’re not saying that we make mistakes using this syntax on a regular basis. We’re not saying that we can’t get used to (or indeed haven’t gotten used to) the C-style for loop, as countless programmers have over the years. What we’re saying is that it’s harder than it needs to be; and, more important, it’s less expressive than it could be. Can you understand it? Absolutely. Then again, you could understand this chapter if it were written entirely in capital letters—that doesn’t make it a good idea, though.
Groovy allows you to reveal the meaning of such code pieces by providing the concept of a range. A range has a left bound and a right bound. You can do something for each element of a range, effectively iterating through it. You can determine whether a candidate element falls inside a range. In other words, a range is an interval plus a strategy for how to move through it.
By introducing the new concept of ranges, Groovy extends your means of expressing your intentions in the code.
We will show how to specify ranges, how the fact that they are objects makes them ubiquitously applicable, how to use custom objects as bounds, and how they’re typically used in the GDK.
Ranges are specified using the double dot .. range operator between the left and the right bound. This operator has a low precedence, so you often need to enclose the declaration in parentheses. Ranges can also be declared using their respective constructors.
The ..< range operator specifies a half-exclusive range—that is, the value on the right is not part of the range:
left..right (left..right) (left..<right)
Ranges usually have a lower left bound and a higher right bound. When this is switched, we call it a reverse range. Ranges can also be any combination of the types we’ve described. Listing 4.1 shows these combinations and how ranges can have bounds other than integers, such as dates and strings. Groovy supports ranges at the language level with the special for-in-range loop.

Note that we assign a range to a variable in ![]() . In other words, the variable holds a reference to an object of type
. In other words, the variable holds a reference to an object of type groovy.lang.Range. We will examine this feature further and see what consequences it implies.
Date objects can be used in ranges, as in ![]() , because the GDK adds the
, because the GDK adds the previous and next methods to date, which increase or decrease the date by one day.
By the Way
The GDK also adds minus and plus operators to java.util.Date, which increase or decrease the date by so many days.
The String methods previous and next are added by the GDK to make strings usable for ranges, as in ![]() . The last character in the string is incremented/decremented, and over-/underflow is handled by appending a new character or deleting the last character.
. The last character in the string is incremented/decremented, and over-/underflow is handled by appending a new character or deleting the last character.
We can walk through a range with the each method, which presents the current value to the given closure with each step, as shown in ![]() . If the range is reversed, we will walk through the range backward. If the range is half-exclusive, the walking stops before reaching the right bound.
. If the range is reversed, we will walk through the range backward. If the range is half-exclusive, the walking stops before reaching the right bound.
Because every range is an object, you can pass a range around and call its methods. The most prominent methods are each, which executes a specified closure for each element in the range, and contains, which specifies whether a value is within a range or not.
Being first-class objects, ranges can also participate in the game of operator overriding (see section 3.3) by providing an implementation of the isCase method, with the same meaning as contains. That way, you can use ranges as grep filters and as switch cases. This is shown in listing 4.2.
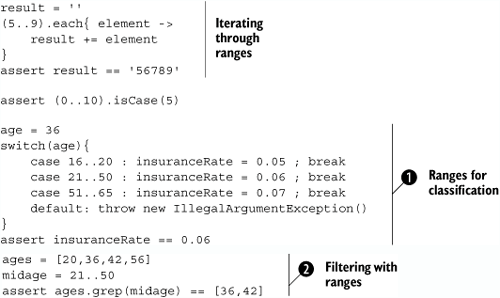
The use with the grep method ![]() is a good example for passing around range objects: The
is a good example for passing around range objects: The midage range gets passed as a parameter to the grep method.
Classification through ranges as shown at ![]() is what we often find in the business world: interest rates for different ranges of allocated assets, transaction fees based on volume ranges, and salary bonuses based on ranges of business done. Although technical people prefer using functions, business people tend to use ranges. When you’re modeling the business world in software, classification by ranges can be very handy.
is what we often find in the business world: interest rates for different ranges of allocated assets, transaction fees based on volume ranges, and salary bonuses based on ranges of business done. Although technical people prefer using functions, business people tend to use ranges. When you’re modeling the business world in software, classification by ranges can be very handy.
Listing 4.1 made use of date and string ranges. In fact, any datatype can be used with ranges, provided that both of the following are true:
The type implements
nextandprevious; that is, it overrides the++and--operators.The type implements
java.lang.Comparable; that is, it implementscompareTo, effectively overriding the<=>spaceship operator.
As an example, we implement a class Weekday in listing 4.3 that represents a day of the week. From the perspective of the code that uses our class, a Weekday has a value 'Sun' through 'Sat'. Internally, it’s just an index between 0 and 6. A little list maps indexes to weekday name abbreviations.
We implement next and previous to return the respective new Weekday object. compareTo simply compares the indexes.
With this preparation, we can construct a range of working days and work our way through it, reporting the work done until we finally reach the well-deserved weekend. Oh, and our boss wants to assess the weekly work report. A final assertion does this on his behalf.

This code can be placed inside one script file, even though it contains both a class declaration and script code. The Weekday class is like an inner class to the script.
The implementation of previous at ![]() is a bit unconventional. Although
is a bit unconventional. Although next uses the modulo operator in a conventional way to jump from Saturday (index 6) to Sunday (index 0), the opposite direction simply decreases the index. The index –1 is used for looking up the previous weekday name, and DAYS[-1] references the last entry of the days list, as you will see in the next section. We construct a new Weekday('Sat'), and the constructor normalizes the index to 6.
Compared to the Java alternatives, ranges have proven to be a flexible solution. For loops and conditionals are not objects, cannot be reused, and cannot be passed around, but ranges can. Ranges let you focus on what the code does, rather than how it does it. This is a pure declaration of your intent, as opposed to fiddling with indexes and boundary conditions.
Using custom ranges is the next step forward. Look actively through your code for possible applications. Ranges slumber everywhere, and bringing them to life can significantly improve the expressiveness of your code. With a bit of practice, you may find ranges where you never thought possible. This is a sure sign that new language concepts can change your perception of the world.
You will shortly refer to your newly acquired knowledge about ranges when exploring the subscript operator on lists, the built-in datatype that we are going to cover next.
In a recent Java project, we had to write a method that takes a Java array and adds an element to it. This seemed like a trivial task, but we forgot how awkward Java programming could be. (We’re spoiled from too much Groovy programming.) Java arrays cannot be changed in length, so you cannot add elements easily. One way is to convert the array to a java.util.List, add the element, and convert back. A second way is to construct a new array of size+1, copy the old values over, and set the new element to the last index position. Either takes some lines of code.
But Java arrays also have their benefits in terms of language support. They work with the subscript operator to easily retrieve elements of an array by index like myarray[index], or to store elements at an index position with myarray[index] = newElement.
We will demonstrate how Groovy lists give you the best of both approaches, extending the features for smart operator implementations, method overloading, and using lists as Booleans. With Groovy lists, you will also discover new ways of leveraging the power of the Java Collections API.
Listing 4.4 shows various ways of specifying lists. The primary way is with square brackets around a sequence of items, delimited with commas:
[item, item, item]
The sequence can be empty to declare an empty list. Lists are by default of type java.util.ArrayList and can also be declared explicitly by calling the respective constructor. The resulting list can still be used with the subscript operator. In fact, this works with any type of list, as we show here with type java.util.LinkedList.
Lists can be created and initialized at the same time by calling toList on ranges.

We use the addAll(Collection) method from java.util.List at ![]() to easily fill the lists. As an alternative, the collection to fill from can be passed right into the constructor, as we have done with
to easily fill the lists. As an alternative, the collection to fill from can be passed right into the constructor, as we have done with LinkedList.
For the sake of completeness, we need to add that lists can also be constructed by passing a Java array to Groovy. Such an array is subject to autoboxing—a list will be automatically generated from the array with its elements being autoboxed.
The GDK extends all arrays, collection objects, and strings with a toList method that returns a newly generated list of the contained elements. Strings are handled like lists of characters.
Lists implement some of the operators that you saw in section 3.3. Listing 4.4 contained two of them: the getAt and putAt methods to implement the subscript operator. But this was a simple use that works with a mere index argument. There’s much more to the list operators than that.
The GDK overloads the getAt method with range and collection arguments to access a range or a collection of indexes. This is demonstrated in Listing 4.5.
The same strategy is applied to putAt, which is overloaded with a Range argument, assigning a list of values to a whole sublist.
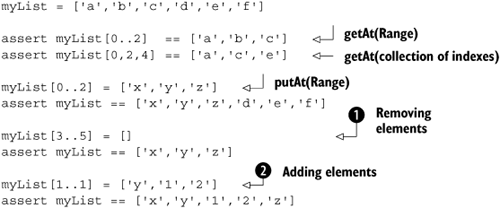
Subscript assignments with ranges do not need to be of identical size. When the assigned list of values is smaller than the range or even empty, the list shrinks, as shown at ![]() . When the assigned list of values is bigger, the list grows, as in
. When the assigned list of values is bigger, the list grows, as in ![]() .
.
Ranges as used within subscript assignments are a convenience feature to access Java’s excellent sublist support for lists. See also the Javadoc for java.util.List#sublist.
In addition to positive index values, lists can also be subscripted with negative indexes that count from the end of the list backward. Figure 4.1 show how positive and negative indexes map to an example list [0,1,2,3,4].
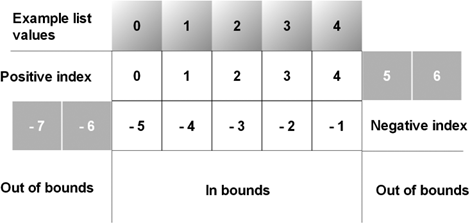
Figure 4.1. Positive and negative indexes of a list of length five, with “in bounds” and “out of bounds” classification for indexes
Consequently, you get the last entry of a non-empty list with list[-1] and the next-to-last with list[-2]. Negative indexes can also be used in ranges, so list[-3..-1] gives you the last three entries. When using a reversed range, the resulting list is reversed as well, so list[4..0] is [4,3,2,1,0]. In this case, the result is a new list object rather than a sublist in the sense of the JDK. Even mixtures of positive and negative indexes are possible, such as list[1..-2] to cut away the first entry and the last entry.
Tip
Ranges in List’s subscript operator are IntRanges. Exclusive IntRanges are mapped to inclusive ones at construction time, before the subscript operator comes into play and can map negative indexes to positive ones. This can lead to surprises when mixing positive left and negative right bounds with exclusiveness; for example, IntRange (0..<-2) gets mapped to (0..-1), such that list[0..<-2] is effectively list[0..-1].
Although this is stable and works predictably, it may be confusing for the readers of your code, who may expect it to work like list[0..-3]. For this reason, this situation should be avoided for the sake of clarity.
Although the subscript operator can be used to change any individual element of a list, there are also operators available to change the contents of the list in a more drastic way. They are plus(Object), plus(Collection),leftShift(Object), minus(Collection), and multiply. Listing 4.6 shows them in action. The plus method is overloaded to distinguish between adding an element and adding all elements of a collection. The minus method only works with collection parameters.

While we’re talking about operators, it’s worth noting that we have used the == operator on lists, happily assuming that it does what we expect. Now we see how it works: The equals method on lists tests that two collections have equal elements. See the Javadoc of java.util.List#equals for details.
Groovy lists are more than flexible storage places. They also play a major role in organizing the execution flow of Groovy programs. Listing 4.7 shows the use of lists in Groovy’s if, switch, and for control structures.

In ![]() and
and ![]() , you see the trick that you already know from patterns and ranges: implementing
, you see the trick that you already know from patterns and ranges: implementing isCase and getting a grep filter and a switch classification for free.
![]() is a little surprising. Inside a Boolean test, empty lists evaluate to
is a little surprising. Inside a Boolean test, empty lists evaluate to false.
![]() shows looping over lists or other collections and also demonstrates that lists can contain mixtures of types.
shows looping over lists or other collections and also demonstrates that lists can contain mixtures of types.
There are so many useful methods on the List type that we cannot provide an example for all of them in the language description. The large number of methods comes from the fact that the Java interface java.util.List is already fairly wide (25 methods in JDK 1.4).
Furthermore, the GDK adds methods to the List interface, to the Collection interface, and to Object. Therefore, many methods are available on the List type, including all methods of Collection and Object.
Appendix C has the complete overview of all methods added to List by the GDK. The Javadoc of java.util.List has the complete list of its JDK methods.
While working with lists in Groovy, there is no need to be aware of whether a method stems from the JDK or the GDK, or whether it is defined in the List or Collection interface. However, for the purpose of describing the Groovy List datatype, we fully cover the GDK methods on lists and collections, but not all combinations from overloaded methods and not what is already covered in the previous examples. We provide only partial examples of the JDK methods that we consider important.
A first set of methods is presented in Listing 4.8. It deals with changing the content of the list by adding and removing elements; combining lists in various ways; sorting, reversing, and flattening nested lists; and creating new lists from existing ones.
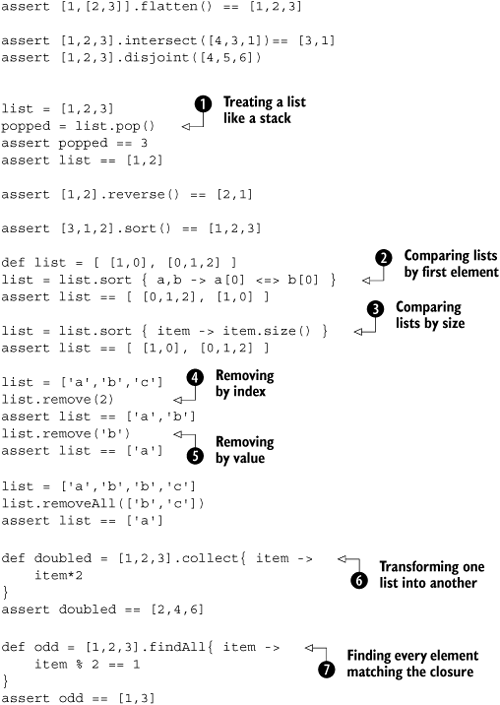
List elements can be of arbitrary type, including other nested lists. This can be used to implement lists of lists, the Groovy equivalent of multidimensional arrays in Java. For nested lists, the flatten method provides a flat view of all elements.
An intersection of lists contains all elements that appear in both lists. Collections can also be checked for being disjoint—that is, whether their intersection is empty.
Lists can be used like stacks, with usual stack behavior on push and pop, as in ![]() . The push operation is relayed to the list’s
. The push operation is relayed to the list’s << left-shift operator.
When list elements are Comparable, there is a natural sort. Alternatively, the comparison logic of the sort can be specified as a closure, as in ![]() and
and ![]() . In the first example, we sort lists of lists by comparing their entry at index zero. The second example shows that a single argument can be used inside the closure for comparison. In this case, the comparison is made between the results that the closure returns when fed each of the candidate elements.
. In the first example, we sort lists of lists by comparing their entry at index zero. The second example shows that a single argument can be used inside the closure for comparison. In this case, the comparison is made between the results that the closure returns when fed each of the candidate elements.
Elements can be removed by index, as in ![]() , or by value, as in
, or by value, as in ![]() . We can also remove all the elements that appear as values in the second list. These removal methods are the only ones in the listing that are available in the JDK.
. We can also remove all the elements that appear as values in the second list. These removal methods are the only ones in the listing that are available in the JDK.
The collect method, seen in ![]() , returns a new list that is constructed from what a closure returns when successively applied to all elements of the original list. In the example, we use it to retrieve a new list where each entry of the original list is multiplied by two. With
, returns a new list that is constructed from what a closure returns when successively applied to all elements of the original list. In the example, we use it to retrieve a new list where each entry of the original list is multiplied by two. With findAll, as in ![]() , we retrieve a list of all items for which the closure evaluates to
, we retrieve a list of all items for which the closure evaluates to true. In the example, we use the modulo operator to find all odd numbers.
Two issues related to changing an existing list are removing duplicates and removing null values. One way to remove duplicate entries is to convert the list to a datatype that is free of duplicates: a Set. This can be achieved by calling a Set’s constructor with that list as an argument.
def x = [1,1,1] assert [1] == new HashSet(x).toList() assert [1] == x.unique()
If you don’t want to create a new collection but do want to keep working on your cleaned list, you can use the unique method, which ensures that the sequence of entries is not changed by this operation.
Removing null from a list can be done by keeping all non-nulls—for example, with the findAll methods that you have seen previously:
def x = [1,null,1]
assert [1,1] == x.findAll{it != null}
assert [1,1] == x.grep{it}You can see there’s an even shorter version with grep, but in order to understand its mechanics, you need more knowledge about closures (chapter 5) and “The Groovy truth” (chapter 6). Just take it for granted until then.
Lists have methods to query their elements for certain properties, iterate through them, and retrieve accumulated results.
Query methods include a count of given elements in the list, min and max, a find method that finds the first element that satisfies a closure, and methods to determine whether every or any element in the list satisfies a closure.
Iteration can be achieved as usual, forward with each or backward with eachReverse.
Cumulative methods come in simple and sophisticated versions. The join method is simple: It returns all elements as a string, concatenated with a given string. The inject method is inspired by Smalltalk. It uses a closure to inject new functionality. That functionality operates on an intermediary result and the current element of the iteration. The first parameter of the inject method is the initial value of the intermediary result. In listing 4.9, we use this method to sum up all elements and then use it a second time to multiply them.

Understanding and using the inject method can be a bit challenging if you’re new to the concept. Note that it is exactly parallel to the iteration examples, with store playing the role of the intermediary result. The benefit is that you do not need to introduce that extra variable to the outer scope of your accumulation, and your closure has no side effects on that scope.
The GDK introduces two more convenience methods for lists: asImmutable and asSynchronized. These methods use Collections.unmodifiableList and Collections.synchronizedList to protect the list from unintended content changes and concurrent access. See these methods’ Javadocs for more details on the topic.
After all the artificial examples, you deserve to see a real one. Here it is: We will implement Tony Hoare’s Quicksort[1] algorithm in listing 4.10. To make things more interesting, we will do so in a generic way; we will not demand any particular datatype for sorting. We rely on duck typing—as long as something walks like a duck and talks like a duck, we happily treat it as a duck. For our use, this means that as long as we can use the <, =, and > operators with our list items, we treat them as if they were comparable.
The goal of Quicksort is to be sparse with comparisons. The strategy relies on finding a good pivot element in the list that serves to split the list into two sublists: one with all elements smaller than the pivot, the second with all elements bigger than the pivot. Quicksort is then called recursively on the sublists. The rationale behind this is that you never need to compare elements from one list with elements from the other list. If you always find the perfect pivot, which exactly splits your list in half, the algorithm runs with a complexity of n*log(n). In the worst case, you choose a border element every time, and you end up with a complexity of n2. In listing 4.10, we choose the middle element of the list, which is a good choice for the frequent case of preordered sublists.

In contrast to what we said earlier, we actually use not two but three lists in ![]() . Use this implementation when you don’t want to lose items that appear multiple times.
. Use this implementation when you don’t want to lose items that appear multiple times.
Our duck-typing approach is powerful when it comes to sorting different types. We can sort a list of mixed content types, as at ![]() , or even sort a string, as at
, or even sort a string, as at ![]() . This is possible because we did not demand any specific type to hold our items. As long as that type implements
. This is possible because we did not demand any specific type to hold our items. As long as that type implements size, getAt(index), and findAll, we are happy to treat it as a sortable. Actually, we used duck typing twice: for the items and for the structure.
By the Way
The sort method that comes with Groovy uses Java’s sorting implementation that beats our example in terms of worst-case performance. It guarantees a complexity of n*log(n). However, we win on a different front.
Of course, our implementation could be optimized in multiple dimensions. Our goal was to be tidy and flexible, not to be the fastest on the block.
If we had to explain the Quicksort algorithm without the help of Groovy, we would sketch it in pseudocode that looks exactly like listing 4.10. In other words, the Groovy code itself is the best description of what it does. Imagine what this can mean to your codebase, when all your code reads like it was a formal documentation of its purpose!
You have seen lists to be one of Groovy’s strongest workhorses. They are always at hand; they are easy to specify in-line, and using them is easy due to the operators supported. The plethora of available methods may be intimidating at first, but that is also the source of lists’ power.
You are now able to add them to your carriage and let them pull the weight of your code.
The next section about maps will follow the same principles that you have seen for lists: extending the Java collection’s capabilities while providing efficient shortcuts.
Suppose you were about to learn the vocabulary of a new language, and you set out to find the most efficient way of doing so. It would surely be beneficial to focus on those words that appear most often in your texts. So, you would take a collection of your texts and analyze the word frequencies in that text corpus.[2]
What Groovy means do you have to do this? For the time being, assume that you can work on a large string. You have numerous ways of splitting this string into words. But how do you count and store the word frequencies? You cannot have a distinct variable for each possible word you encounter. Finding a way of storing frequencies in a list is possible but inconvenient—more suitable for a brain teaser than for good code. Maps come to the rescue.
Some pseudocode to solve the problem could look like this:
for each word {
if (frequency of word is not known)
frequency[word] = 0
frequency[word] += 1
}This looks like the list syntax, but with strings as indexes rather than integers. In fact, Groovy maps appear like lists, allowing any arbitrary object to be used for indexing.
In order to describe the map datatype, we show how maps can be specified, what operations and methods are available for maps, some surprisingly convenient features of maps, and, of course, a map-based solution for the word-frequency exercise.
The specification of maps is analogous to the list specification that you saw in the previous section. Just like lists, maps make use of the subscript operator to retrieve and assign values. The difference is that maps can use any arbitrary type as an argument to the subscript operator, where lists are bound to integer indexes. Whereas lists are aware of the sequence of their entries, maps are generally not. Specialized maps like java.util.TreeMap may have a sequence to their keys, though.
Simple maps are specified with square brackets around a sequence of items, delimited with commas. The key feature of maps is that the items are key-value pairs that are delimited by colons:
[key:value, key:value, key:value]
In principle, any arbitrary type can be used for keys or values. When using exotic[3] types for keys, you need to obey the rules as outlined in the Javadoc for java.util.Map.
The character sequence [:] declares an empty map. Maps are by default of type java.util.HashMap and can also be declared explicitly by calling the respective constructor. The resulting map can still be used with the subscript operator. In fact, this works with any type of map, as you see in listing 4.11 with type java.util.TreeMap.
Example 4.11. Specifying maps
def myMap = [a:1, b:2, c:3] assert myMap instanceof HashMap assert myMap.size() == 3 assert myMap['a'] == 1 def emptyMap = [:] assert emptyMap.size() == 0 def explicitMap = new TreeMap() explicitMap.putAll(myMap) assert explicitMap['a'] == 1
In listing 4.11, we use the putAll(Map) method from java.util.Map to easily fill the example map. An alternative would have been to pass myMap as an argument to TreeMap’s constructor.
For the common case of having keys of type String, you can leave out the string markers (single or double quotes) in a map declaration:
assert ['a':1] == [a:1]
Such a convenience declaration is allowed only if the key contains no special characters (it needs to follow the rules for valid identifiers) and is not a Groovy keyword.
This notation can also get in the way when, for example, the content of a local variable is used as a key. Suppose you have local variable x with content 'a'. Because [x:1] is equal to ['x':1], how can you make it equal to ['a':1]? The trick is that you can force Groovy to recognize a symbol as an expression by putting it inside parentheses:
def x = 'a' assert ['x':1] == [x:1] assert ['a':1] == [(x):1]
It’s rare to require this functionality, but when you need keys that are derived from local symbols (local variables, fields, properties), forgetting the parentheses is a likely source of errors.
The simplest operations with maps are storing objects in the map with a key and retrieving them back using that key. Listing 4.12 demonstrates how to do that. One option for retrieving is using the subscript operator. As you have probably guessed, this is implemented with map’s getAt method. A second option is to use the key like a property with a simple dot-syntax. You will learn more about properties in chapter 7. A third option is the get method, which additionally allows you to pass a default value to be returned if the key is not yet in the map. If no default is given, null will be used as the default. If on a get(key,default) call the key is not found and the default is returned, the key:default pair is added to the map.
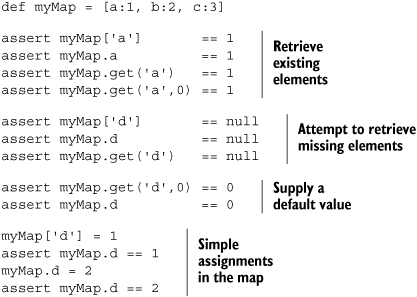
Assignments to maps can be done using the subscript operator or via the dot-key syntax. If the key in the dot-key syntax contains special characters, it can be put into string markers, like so:
myMap = ['a.b':1] assert myMap.'a.b' == 1
Just writing myMap.a.b would not work here—that would be the equivalent of calling myMap.getA().getB().
Listing 4.13 shows how information can easily be gleaned from maps, largely using core JDK methods from java.util.Map. Using equals, size, containsKey, and containsValue as in listing 4.13 is straightforward. The method keySet returns a set of keys, a collection that is flat like a list but has no duplicate entries and no inherent ordering. See the Javadoc of java.util.Set for details. In order to compare the keySet against our list of known keys, we need to convert this list to a set. This is done with a small service method toSet.
The value method returns the list of values. Because maps have no idea how their keys are ordered, there is no foreseeable ordering in the list of values. To make it comparable with our known list of values, we convert both to a set.
Maps can be converted into a collection by calling the entrySet method, which returns a set of entries where each entry can be asked for its key and value property.

The GDK adds two more informational methods to the JDK map type: any and every, as in ![]() . They work analogously to the identically named methods for lists: They return a Boolean value to tell whether any or every entry in the map satisfies a given closure.
. They work analogously to the identically named methods for lists: They return a Boolean value to tell whether any or every entry in the map satisfies a given closure.
With the information about the map, we can iterate over it in a number of ways: over the entries, or over keys and values separately. Because the sets that are returned from keySet and entrySet are collections, we can use them with the for-in-collection type loops. Listing 4.14 goes through some of the possible combinations.

Map’s each method uses closures in two ways: Passing one parameter into the closure means that it is an entry; passing two parameters means it is a key and a value. The latter is more convenient to work with for common cases.
Note
Listing 4.14 uses three assertions on the store string instead of a single one. This is because the sequence of entries is not guaranteed.
Finally, map content can be changed in various ways, as shown in listing 4.15. Removing elements works with the original JDK methods. New capabilities that the GDK introduces are as follows:
Creating a
subMapof all entries with keys from a given collectionfindAllentries in a map that satisfy a given closurefindone entry that satisfies a given closure, where unlike lists there is no notion of a first entry, because there is no ordering in mapscollectin a list whatever a closure returns for each entry, optionally adding to a given collection

The first two examples (clear and remove) are from the core JDK; the rest are all GDK methods. Only the subMap method, at ![]() , is particularly new here;
, is particularly new here; collect, find, and findAll act as they would with lists, operating on map entries instead of list elements. The subMap method is analogous to subList, but it specifies a collection of keys as a filter for the view onto the original map.
In order to assert that the collect method works as expected, we recall a trick that we learned about lists: We use the every method on the list to make sure that every entry is even. The collect method comes with a second version that takes an addition collection parameter. It adds all closure results directly to this collection, avoiding the need to create temporary lists.
From the list of available methods that you have seen for other datatypes, you may miss our dearly beloved isCase for use with grep and switch. Don’t we want to classify with maps? Well, we need to be more specific: Do we want to classify by the keys or by the values? Either way, an appropriate isCase is available when working on the map’s keySet or values.
The GDK introduces two more methods for the map datatype: asImmutable and asSynchronized. These methods use Collections.unmodifiableMap and Collections.synchronizedMap to protect the map from unintended content changes and concurrent access. See these methods’ Javadocs for more details on the topic.
In listing 4.16, we revisit our initial example of counting word frequencies in a text corpus. The strategy is to use a map with each distinct word serving as a key. The mapped value of that word is its frequency in the text corpus. We go through all words in the text and increase the frequency value of that respective word in the map. We need to make sure that we can increase the value when a word is hit the first time and there is no entry yet in the map. Luckily, the get(key,default) method does the job.
We then take all keys, put them in a list, and sort it such that it reflects the order of frequency. Finally, we play with the capabilities of lists, ranges, and strings to print a nice statistic.
The text corpus under analysis is Baloo the Bear’s anthem on his attitude toward life.

| The example nicely combines our knowledge of Groovy’s datatypes. Counting the word frequency is essentially a one-liner. It’s even shorter than the pseudocode that we used to start this section. |
| Having the |
Lists and maps make a powerful duo. There are whole languages that build on just these two datatypes (such as Perl, with list and hash) and implement all other datatypes and even objects upon them.
Their power comes from the complete and mindfully engineered Java Collections Framework. Thanks to Groovy, this power is now right at our fingertips.
Until now, we carelessly switched back and forth between Groovy and Java collection datatypes. We will throw more light on this interplay in the next section.
The Java Collections API is the basis for all the nice support that Groovy gives you through lists and maps. In fact, Groovy not only uses the same abstractions, it even works on the very same classes that make up the Java Collections API.
This is exceptionally convenient for those who come from Java and already have a good understanding of it. If you haven’t, and you are interested in more background information, have a look at your Javadoc starting at java.util.Collection.
Your JDK also ships with a guide and a tutorial about Java collections. It is located in your JDK’s doc folder under guide/collections.
One of the typical peculiarities of the Java collections is that you shouldn’t try to structurally change one while iterating through it. A structural change is one that adds an entry, removes an entry, or changes the sequence of entries when the collection is sequence-aware. This applies even when iterating through a view onto the collection, such as using list[range].
If you fail to meet this constraint, you will see a ConcurrentModificationException. For example, you cannot remove all elements from a list by iterating through it and removing the first element at each step:
def list = [1, 2, 3, 4]
list.each{ list.remove(0) }
// throws ConcurrentModificationException !!Note
Concurrent in this sense does not necessarily mean that a second thread changed the underlying collection. As shown in the example, even a single thread of control can break the “structural stability” constraint.
In this case, the correct solution is to use the clear method. The Collections API has lots of such specialized methods. When searching for alternatives, consider collect, addAll, removeAll, findAll, and grep.
This leads to a second issue: Some methods work on a copy of the collection and return it when finished; other methods work directly on the collection object they were called on (we call this the receiver[4] object).
Generally, there is no easy way to anticipate whether a method modifies the receiver or returns a copy. Some languages have naming conventions for this, but Groovy couldn’t do so because all Java methods are directly visible in Groovy and Java’s method names could not be made compliant to such a convention. But Groovy tries to adapt to Java and follow the heuristics that you can spot when looking through the Collections API:
Methods that modify the receiver typically don’t return a collection. Examples:
add,addAll,remove,removeAll, andretainAll. Counter-example:sort.Methods that return a collection typically don’t modify the receiver. Examples:
grep,findAll,collect. Counter-example:sort. Yes,sortis a countere-xample for both, because it returns a collection and modifies the receiver.Methods that modify the receiver have imperative names. They sound like there could be an exclamation mark behind them. (Indeed, this is Ruby’s naming convention for such methods.) Examples:
add,addAll,remove,removeAll,retainAll,sort. Counter-examples:collect,grep,findAll, which are imperative but do not modify the receiver and return a modified copy.The preceding rules can be mapped to operators, by applying them to the names of their method counterparts:
<< leftShiftis imperative and modifies the receiver (on lists, unfortunately not on strings—doing so would break Java’s invariant of strings being immutable);+ plusis not imperative and returns a copy.
These are not clear rules but only heuristics to give you some guidance. Whenever you’re in doubt and object identity is important, have a look at the documentation or write a few assertions.
This has been a long trip through the valley of Groovy’s datatypes. There were lots of different paths to explore that led to new interesting places.
We introduced ranges as objects that—as opposed to control structures—have their own time and place of creation, can be passed to methods as parameters, and can be returned from method calls. This makes them very flexible, and once the concept of a range is available, many uses beyond simple control structures suggest themselves. The most natural example you have seen is extracting a section of a list using a range as the operand to the list’s subscript operator.
Lists and maps are more familiar to Java programmers than ranges but have suffered from a lack of language support in Java itself. Groovy recognizes just how often these datatypes are used, gives them special treatment in terms of literal declarations, and of course provides operators and extra methods to make life even easier. The lists and maps used in Groovy are the same ones encountered in Java and come with the same rules and restrictions, although these become less onerous due to some of the additional methods available on the collections.
Throughout our coverage of Groovy’s datatypes, you have seen closures used ubiquitously for making functionality available in a simple and unobtrusive manner. In the next chapter, we will demystify the concept, explain the usual and the not-so-usual applications, and show how you can spice up your own code with closures.
[2] Analyzing word frequencies in a text corpus is a common task in computer linguistics and is used for optimizing computer-based learning, search engines, voice recognition, and machine translation programs.
[3] Exotic in this sense refers to types whose instances change their hashCode during their lifetime. There is also a corner case with GStrings if their values write themselves lazily.
[4] From the Smalltalk notion of describing method calls on an object as sending a message to the receiver.