
Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius—and a lot of courage—to move in the opposite direction. | ||
| --Albert Einstein | ||
There is a common misconception about scripting languages. Because a scripting language might support loose typing and provide some initially surprising syntax shorthands, it may be perceived as a nice new toy for hackers rather than a language suitable for serious object-oriented (OO) programming. This reputation stems from the time when scripting was done in terms of shell scripts or early versions of Perl, where the lack of encapsulation and other OO features sometimes led to poor code management, frequent code duplication, and obscure hidden bugs. It wasn’t helped by languages that combined notations from several existing sources as part of their heritage.
Over time, the scripting landscape has changed dramatically. Perl has added support for object orientation, Python has extended its object-oriented support, and more recently Ruby has made a name for itself as a full-fledged dynamic object-oriented scripting language with significant productivity benefits when compared to Java and C++.
Groovy follows the lead of Ruby by offering these dynamic object orientation features. Not only does it enhance Java by making it scriptable, but it also provides new OO features. You have already seen that Groovy provides reference types in cases where Java uses non-object primitive types, introduces ranges and closures as first-class objects, and has many shorthand notations for working with collections of objects. But these enhancements are just scratching the surface. If this were all that Groovy had to offer, it would be little more than syntactic sugar over normal Java. What makes Groovy stand apart is its set of dynamic features.
In this chapter, we will take you on a journey. We begin in familiar territory, with classes, objects, constructors, references, and so forth. Every so often, there’s something a bit different, a little tweak of Grooviness. By the end of the chapter, we’ll be in a whole new realm, changing the capabilities of objects and classes at runtime, intercepting method calls, and much, much more. Welcome to the Groovy world.
Class definition in Groovy is almost identical to Java; classes are declared using the class keyword and may contain fields, constructors, initializers, and methods.[1] Methods and constructors may themselves use local variables as part of their implementation code. Scripts are different—offering additional flexibility but with some restrictions too. They may contain code, variable definitions, and method definitions as well as class definitions. We will describe how all of these members are declared and cover a previously unseen operator on the way.
In its simplest terms, a variable is a name associated with a slot of memory that can hold a value. Just as in Java, Groovy has local variables, which are scoped within the method they are part of, and fields, which are associated with classes or instances of those classes. Fields and local variables are declared in much the same way, so we cover them together.
Fields and local variables must be declared before first use (except for a special case involving scripts, which we discuss later). This helps to enforce scoping rules and protects the programmer from accidental misspellings. The declaration always involves specifying a name, and may optionally include a type, modifiers, and assignment of an initial value. Once declared, variables are referenced by their name.
Scripts allow the use of undeclared variables, in which case these variables are assumed to come from the script’s binding and are added to the binding if not yet there. The binding is a data store that enables transfer of variables to and from the caller of a script. Section 11.3.2 has more details about this mechanism.
Groovy uses Java’s modifiers—the keywords private, protected, and public for modifying visibility;[2] final for disallowing reassignment; and static to denote class variables. A nonstatic field is also known as an instance variable. These modifiers all have the same meaning as in Java.
The default visibility for fields has a special meaning in Groovy. When no visibility modifier is attached to field declaration, a property is generated for the respective name. You will learn more about properties in section 7.4 when we present GroovyBeans.
Defining the type of a variable is optional. However, the identifier must not stand alone in the declaration. When no type and no modifier are given, the def keyword must be used as a replacement, effectively indicating that the field or variable is untyped (although under the covers it will be declared as type Object).
Listing 7.1 depicts the general appearance of field and variable declarations with optional assignment and using a comma-separated list of identifiers to declare multiple references at once.
Example 7.1. Variable declaration examples
class SomeClass {
public fieldWithModifier
String typedField
def untypedField
protected field1, field2, field3
private assignedField = new Date()
static classField
public static final String CONSTA = 'a', CONSTB = 'b'
def someMethod(){
def localUntypedMethodVar = 1
int localTypedMethodVar = 1
def localVarWithoutAssignment, andAnotherOne
}
}
def localvar = 1
boundvar1 = 1
def someMethod(){
localMethodVar = 1
boundvar2 = 1
}Assignments to typed references must conform to the type—that is, you cannot assign a number to a reference of type String or vice versa. You saw in chapter 3 that Groovy provides autoboxing and coercion when it makes sense. All other cases are type-breaking assignments and lead to a ClassCastException at runtime, as can be seen in listing 7.2.[3]
Example 7.2. Variable declaration examples
final static String PI = 3.14
assert PI.class.name == 'java.lang.String'
assert PI.length() == 4
new GroovyTestCase().shouldFail(ClassCastException.class){
Float areaOfCircleRadiousOne = PI
}As previously discussed, variables can be referred to by name in the same way as in Java—but Groovy provides a few more interesting possibilities.
In addition to referring to fields by name with the obj.fieldName[4] syntax, they can also be referenced with the subscript operator, as shown in listing 7.3. This allows you to access fields using a dynamically determined name.
Example 7.3. Referencing fields with the subscript operator
class Counter {
public count = 0
}
def counter = new Counter()
counter.count = 1
assert counter.count == 1
def fieldName = 'count'
counter[fieldName] = 2
assert counter['count'] == 2Accessing fields in such a dynamic way is part of the bigger picture of dynamic execution that we will analyze in the course of this chapter.
If you worked through the Groovy datatype descriptions, your next question will probably be, “can I override the subscript operator?” Sure you can, and you will extend but not override the general field-access mechanism that way. But you can do even better and extend the field access operator!
Listing 7.4 shows how to do that. To extend both set and get access, provide the methods
Object get (String name) void set (String name, Object value)
There is no restriction on what you do inside these methods; get can return artificial values, effectively pretending that your class has the requested field. In listing 7.4, the same value is always returned, regardless of which field value is requested. The set method is used for counting the write attempts.
Example 7.4. Extending the general field-access mechanism
class PretendFieldCounter {
public count = 0
Object get (String name) {
return 'pretend value'
}
void set (String name, Object value) {
count++
}
}
def pretender = new PretendFieldCounter()
assert pretender.isNoField == 'pretend value'
assert pretender.count == 0
pretender.isNoFieldEither = 'just to increase counter'
assert pretender.count == 1With the count field, you can see that it looks like the get/set methods are not used if the requested field is present. This is true for our special case. Later, in section 7.4, you will see the full set of rules that produces this effect.
Generally speaking, overriding the get method means to override the dot-fieldname operator. Overriding the set method overrides the field assignment operator.
For the Geeks
What about a statement of the form x.y.z=something?
This is equivalent to getX().getY().setZ (something).
Referencing fields is also connected to the topic of properties, which we will explore in section 7.4, where we will discuss the need for the additional obj.@fieldName syntax.
Method declarations follow the same concepts you have seen for variables: The usual Java modifiers can be used; declaring a return type is optional; and, if no modifiers or return type are supplied, the def keyword fills the hole. When the def keyword is used, the return type is deemed to be untyped (although it can still have no return type, the equivalent of a void method). In this case, under the covers, the return type will be java.lang.Object. The default visibility of methods is public.
Listing 7.5 shows the typical cases in a self-describing manner.

The main method ![]() has some interesting twists. First, the
has some interesting twists. First, the public modifier can be omitted because it is the default. Second, args usually has to be of type String[] in order to make the main method the one to start the class execution. Thanks to Groovy’s method dispatch, it works anyway, although args is now implicitly of static type java.lang.Object. Third, because return types are not used for the dispatch, we can further omit the void declaration.
So, this Java declaration
public static void main (String[] args)
static main (args)
Note
The Java compiler fails on missing return statements when a return type is declared for the method. In Groovy, return statements are optional, and therefore it’s impossible for the compiler to detect “accidentally” missing returns.
The main(args) example illustrates that declaring explicit parameter types is optional. When type declarations are omitted, Object is used. Multiple parameters can be used in sequence, delimited by commas. Listing 7.6 shows that explicit and omitted parameter types can also be mixed.
Example 7.6. Declaring parameter lists
class SomeClass {
static void main (args){
assert 'untyped' == method(1)
assert 'typed' == method('whatever')
assert 'two args'== method(1,2)
}
static method(arg) {
return 'untyped'
}
static method(String arg){
return 'typed'
}
static method(arg1, Number arg2){
return 'two args'
}
}In the examples so far, all method calls have involved positional parameters, where the meaning of each argument is determined from its position in the parameter list. This is easy to understand and convenient for the simple cases you have seen, but suffers from a number of drawbacks for more complex scenarios:
You must remember the exact sequence of the parameters, which gets increasingly difficult with the length of the parameter list.[5]
If it makes sense to call the method with different information for alternative usage scenarios, different methods must be constructed to handle these alternatives. This can quickly become cumbersome and lead to a proliferation of methods, especially where some parameters are optional. It is especially difficult if many of the optional parameters have the same type. Fortunately, Groovy comes to the rescue with using maps as named parameters.
Note
Whenever we talk about named parameters, we mean keys of a map that is used as an argument in method or constructor calls. From a programmer’s perspective, this looks pretty much like native support for named parameters, but it isn’t. This trick is needed because the JVM does not support storing parameter names in the bytecode.
Listing 7.7 illustrates Groovy method definitions and calls supporting positional and named parameters, parameter lists of variable length, and optional parameters with default values. The example provides four alternative summing mechanisms, each highlighting different approaches for defining the method call parameters.

All four alternatives have their pros and cons. In ![]() ,
, sumWithDefaults, we have the most obvious declaration of the arguments expected for the method call. It meets the needs of the sample script—being able to add two or three numbers together—but we are limited to as many arguments as we have declared parameters.
Using lists as shown in ![]() is easy in Groovy, because in the method call, the arguments only have to be placed in brackets. We can also support argument lists of arbitrary length. However, it is not as obvious what the individual list entries should mean. Therefore, this alternative is best suited when all arguments have the same meaning, as they do here where they are used for adding. Refer to section 4.2.3 for details about the
is easy in Groovy, because in the method call, the arguments only have to be placed in brackets. We can also support argument lists of arbitrary length. However, it is not as obvious what the individual list entries should mean. Therefore, this alternative is best suited when all arguments have the same meaning, as they do here where they are used for adding. Refer to section 4.2.3 for details about the List.inject method.
The sumWithOptionals method at ![]() can be called with two or more parameters. To declare such a method, define the last argument as an array. Groovy’s dynamic method dispatch bundles excessive arguments into that array.
can be called with two or more parameters. To declare such a method, define the last argument as an array. Groovy’s dynamic method dispatch bundles excessive arguments into that array.
Named arguments can be supported by using a map as in ![]() . It is good practice to reset any missing values to a default before working with them. This also better reveals what keys will be used in the method body, because this is not obvious from the method declaration.
. It is good practice to reset any missing values to a default before working with them. This also better reveals what keys will be used in the method body, because this is not obvious from the method declaration.
When designing your methods, you have to choose one of the alternatives. You may wish to formalize your choice within a project or incorporate the Groovy coding style.
Note
There is a second way of implementing parameter lists of variable length. You can hook into Groovy’s method dispatch by overriding the invokeMethod (name, params[]) that every GroovyObject provides. You will learn more about these hooks in section 7.6.2.
When calling a method on an object reference, we usually follow this format:
objectReference.methodName()
This format imposes the Java restrictions for method names; for example, they may not contain special characters such as minus (-) or dot (.). However, Groovy allows you to use these characters in method names if you put quotes around the name:
objectReference.'my.method-Name' ()The purpose of this feature is to support usages where the method name of a call becomes part of the functionality. You won’t normally use this feature directly, but it will be used under the covers by other parts of Groovy. You will see this in action in chapter 8 and chapter 10.
For the Geeks
Where there’s a string, you can generally also use a GString. So how about obj."${var}"()? Yes, this is also possible, and the GString will be resolved to determine the name of the method that is called on the object!
That’s it for the basics of class members. Before we leave this topic, though, there is one convenient operator we should introduce while we’re thinking about referring to members via references.
When a reference doesn’t point to any specific object, its value is null. When calling a method or accessing a field on a null reference, a NullPointerException (NPE) is thrown. This is useful to protect code from working on undefined preconditions, but it can easily get in the way of “best effort” code that should be executed for valid references and just be silent otherwise.
Listing 7.8 shows several alternative approaches to protect code from NPEs. As an example, we wish to access a deeply nested entry within a hierarchy of maps, which results in a path expression—a dotted concatenation of references that is typically cumbersome to protect from NPEs. We can use explicit if checks or use the try-catch mechanism. Groovy provides the additional ?. operator for safe dereferencing. When the reference before that operator is a null reference, the evaluation of the current expression stops, and null is returned.
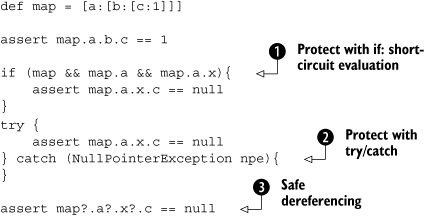
In comparison, using the safe dereferencing operator in ![]() is the most elegant and expressive solution.
is the most elegant and expressive solution.
Note that ![]() is more compact than its Java equivalent, which would need three additional nullity checks. It works because the expression is evaluated from left to right, and the
is more compact than its Java equivalent, which would need three additional nullity checks. It works because the expression is evaluated from left to right, and the && operator stops evaluation with the first operand that evaluates to false. This is known as shortcut evaluation.
Alternative ![]() is a bit verbose and doesn’t allow fine-grained control to protect only selective parts of the path expression. It also abuses the exception-handling mechanism. Exceptions weren’t designed for this kind of situation, which is easily avoided by verifying that the references are non-null before dereferencing them. Causing an exception and then catching it is the equivalent of steering a car by installing big bumpers and bouncing off buildings.
is a bit verbose and doesn’t allow fine-grained control to protect only selective parts of the path expression. It also abuses the exception-handling mechanism. Exceptions weren’t designed for this kind of situation, which is easily avoided by verifying that the references are non-null before dereferencing them. Causing an exception and then catching it is the equivalent of steering a car by installing big bumpers and bouncing off buildings.
Some software engineers like to think about code in terms of cyclomatic complexity, which in short describes code complexity by analyzing alternative pathways through the code. The safe dereferencing operator merges alternative pathways together and hence reduces complexity when compared to its alternatives; essentially, the metric indicates that the code will be easier to understand and simpler to verify as correct.
Objects are instantiated from their classes via constructors. If no constructor is given, an implicit constructor without arguments is supplied by the compiler. This appears to be exactly like in Java, but because this is Groovy, it should not be surprising that some additional features are available.
In section 7.1.2, we examined the merits of named parameters versus positional ones, as well as the need for optional parameters. The same arguments applicable to method calls are relevant for constructors, too, so Groovy provides the same convenience mechanisms. We’ll first look at constructors with positional parameters, and then we’ll examine named parameters.
Until now, we have only used implicit constructors. Listing 7.9 introduces the first explicit one. Notice that just like all other methods, the constructor is public by default. We can call the constructor in three different ways: the usual Java way, with enforced type coercion by using the as keyword, and with implicit type coercion.

The coercion in ![]() and
and ![]() may be surprising. When Groovy sees the need to coerce a list to some other type, it tries to call the type’s constructor with all arguments supplied by the list, in list order. This need for coercion can be enforced with the
may be surprising. When Groovy sees the need to coerce a list to some other type, it tries to call the type’s constructor with all arguments supplied by the list, in list order. This need for coercion can be enforced with the as keyword or can arise from assignments to statically typed references. The latter of these is called implicit construction, which we cover shortly.
Named parameters in constructors are handy. One use case that crops up frequently is creating immutable classes that have some parameters that are optional. Using positional parameters would quickly become cumbersome because you would need to have constructors allowing for all combinations of the optional parameters.
As an example, suppose in listing 7.9 that VendorWithCtor should be immutable and name and product can be optional. We would need four[6] constructors: an empty one, one to set name, one to set product, and one to set both attributes. To make things worse, we couldn’t have a constructor with only one argument, because we couldn’t distinguish whether to set the name or the product attribute (they are both strings). We would need an artificial extra argument for distinction, or we would need to strongly type the parameters.
But don’t panic: Groovy’s special way of supporting named parameters comes to the rescue again.
Listing 7.10 shows how to use named parameters with a simplified version of the Vendor class. It relies on the implicit default constructor. Could that be any easier?
Example 7.10. Calling constructors with named parameters
class Vendor {
String name, product
}
new Vendor()
new Vendor(name: 'Canoo')
new Vendor(product:'ULC')
new Vendor(name: 'Canoo', product:'ULC')
def vendor = new Vendor(name: 'Canoo')
assert 'Canoo' == vendor.nameThe example in listing 7.10 illustrates how flexible named parameters are for your constructors. In cases where you don’t want this flexibility and want to lock down all of your parameters, just define your desired constructor explicitly; the implicit constructor with named parameters will no longer be available.
Coming back to how we started this section, the empty default constructor call new Vendor appears in a new light. Although it looks exactly like its Java equivalent, it is a special case of the default constructor with named parameters that happens to be called without any being supplied.
Finally, there is a way to call a constructor implicitly by simply providing the constructor arguments as a list. That means that instead of calling the Dimension(width, height) constructor explicitly, for example, you can use
java.awt.Dimension area area = [200, 100] assert area.width == 200 assert area.height == 100
Of course, Groovy must know what constructor to call, and therefore implicit constructors are solely available for assignment to statically typed references where the type provides the respective constructor. They do not work for abstract classes or even interfaces.
Implicit constructors are often used with builders, as you’ll see in the SwingBuilder example in section 8.5.7.
That’s it for the usual class members. This is a solid basis we can build upon. But we are not yet in the penthouse; we have four more levels to go. We walk through the topic of how to organize classes and scripts to reach the level of advanced object-oriented features. The next floor is named GroovyBeans and deals with simple object-oriented information about objects. At this level, we can play with Groovy’s power features. Finally, we will visit the highest level, which is meta programming in Groovy—making the environment fully dynamic, and responding to ordinary-looking method calls and field references in an extraordinary way.
In section 2.4.1, you saw that Groovy classes are Java classes at the bytecode level, and consequently, Groovy objects are Java objects in memory. At the source-code level, Groovy class and object handling is almost a superset of the Java syntax, with the exception of nested classes that are currently not supported by the Groovy syntax and some slight changes to the way arrays are defined. We will examine the organization of classes and source files, and the relationships between the two. We will also consider Groovy’s use of packages and type aliasing, as well as demystify where Groovy can load classes from in its classpath.
The relationship between files and class declarations is not as fixed as in Java. Groovy files can contain any number of public class declarations according to the following rules:
If a Groovy file contains no class declaration, it is handled as a script; that is, it is transparently wrapped into a class of type
Script. This automatically generated class has the same name as the source script filename[7] (without the extension). The content of the file is wrapped into arunmethod, and an additionalmainmethod is constructed for easily starting the script.If a Groovy file contains exactly one class declaration with the same name as the file (without the extension), then there is the same one-to-one relationship as in Java.
A Groovy file may contain multiple class declarations of any visibility, and there is no enforced rule that any of them must match the filename. The
groovyccompiler happily creates *.class files for all declared classes in such a file. If you wish to invoke your script directly, for example usinggroovyon the command line or within an IDE, then the first class within your file should have amainmethod.[8]A Groovy file may mix class declarations and scripting code. In this case, the scripting code will become the main class to be executed, so don’t declare a class yourself having the same name as the source filename.
When not compiling explicitly, Groovy finds a class by matching its name to a corresponding *.groovy source file. At this point, naming becomes important. Groovy only finds classes where the class name matches the source filename. When such a file is found, all declared classes in that file are parsed and become known to Groovy.
Listing 7.11 shows a sample script with two simple classes, Vendor and Address. For the moment, they have no methods, only public fields.
Example 7.11. Multiple class declarations in one file
class Vendor {
public String name
public String product
public Address address = new Address()
}
class Address {
public String street, town, state
public int zip
}
def canoo = new Vendor()
canoo.name = 'Canoo Engineering AG'
canoo.product = 'UltraLightClient (ULC)'
canoo.address.street = 'Kirschgartenst. 7'
canoo.address.zip = 4051
canoo.address.town = 'Basel'
canoo.address.state = 'Switzerland'
assert canoo.dump() =~ /ULC/
assert canoo.address.dump() =~ /Basel/Vendor and Address are simple data storage classes. They are roughly equivalent to structs in C or Pascal records. We will soon explore more elegant ways of defining such classes.
Listing 7.11 illustrates a convenient convention supported by Groovy’s source file to class mapping rules, which we discussed earlier. This convention allows small helper classes that are used only with the current main class or current script to be declared within the same source file. Compare this with Java, which allows you to use nested classes to introduce locally used classes without cluttering up your public class namespace or making navigation of the codebase more difficult by requiring a proliferation of source code files. Although it isn’t exactly the same, this convention has similar benefits for Groovy developers.
Groovy follows Java’s approach of organizing files in packages of hierarchical structure. The package structure is used to find the corresponding class files in the filesystem’s directories.
Because *.groovy source files are not necessarily compiled to *.class files, there is also a need to look up *.groovy files. When doing so, the same strategy is used: The compiler looks for a Groovy class Vendor in the business package in the file business/Vendor.groovy.
In listing 7.12, we separate the Vendor and Address classes from the script code, as shown in listing 7.11, and move them to the business package.
The lookup has to start somewhere, and Java uses its classpath for this purpose. The classpath is a list of possible starting points for the lookup of *.class files. Groovy reuses the classpath for looking up *.groovy files.
When looking for a given class, if Groovy finds both a *.class and a *.groovy file, it uses whichever is newer; that is, it will recompile source files into *.class files if they have changed since the previous class file was compiled.[9]
Exactly like in Java, Groovy classes must specify their package before the class definition. When no package declaration is given, the default package is assumed.
Listing 7.12 shows the file business/Vendor.groovy, which has a package statement as its first line.
Example 7.12. Vendor and Address classes moved to the business package
package business
class Vendor {
public String name
public String product
public Address address = new Address()
}
class Address {
public String street, town, state
public int zip
}To reference Vendor in the business package, you can either use business.Vendor within the code or use imports for abbreviation.
Groovy follows Java’s notion of allowing import statements before any class declaration to abbreviate class references.
Note
Please keep in mind that unlike in some other scripting languages, import has nothing to do with literal inclusion of the imported class or file. It merely informs the compiler how to resolve references.
Listing 7.13 shows the use of the import statement, with the .* notation advising the compiler to try resolving all unknown class references against all classes in the business package.
Example 7.13. Using import to access Vendor in the business package
import business.* def canoo = new Vendor() canoo.name = 'Canoo Engineering AG' canoo.product = 'UltraLightClient (ULC)' assert canoo.dump() =~ /ULC/
Note
By default, Groovy imports six packages and two classes, making it seem like every groovy code program contains the following initial statements:
import java.lang.* import java.util.* import java.io.* import java.net.* import groovy.lang.* import groovy.util.* import java.math.BigInteger import java.math.BigDecimal
The import statement has another nice twist: together with the as keyword, it can be used for type aliasing. Whereas a normal import allows a fully qualified class to be referred to by its base name, a type alias allows a fully qualified class to be referred to by a name of your choosing. This feature resolves naming conflicts and supports local changes or bug fixes to a third-party library.
Consider the following library class:
package thirdparty
class MathLib {
Integer twice(Integer value) {
return value * 3 // intentionally wrong!
}
Integer half(Integer value) {
return value / 2
}
}Note its obvious error[10] (although in general it might not be an error but just a locally desired modification). Suppose now that we have some existing code that uses that library:
assert 10 == new MathLib().twice(5)
We can use a type alias to rename the old library and then use inheritance to make a fix. No change is required to the original code that was using the library, as you can see in listing 7.14.

Now, suppose that we have the following additional math library that we need to use:
package thirdparty2
class MathLib {
Integer increment(Integer value) {
return value + 1
}
}Although it has a different package, it has the same name as the previous library. Without aliasing, we have to fully qualify one or both of the libraries within our code. With aliasing, we can avoid this in an elegant way and also improve communication by better indicating intent within our program about the role of the third-party library’s code, as shown in listing 7.15.
Example 7.15. Using import as for avoiding name clashes
import thirdparty.MathLib as TwiceHalfMathLib import thirdparty2.MathLib as IncMathLib def math1 = new TwiceHalfMathLib() def math2 = new IncMathLib() assert 3 == math1.half(math2.increment(5))
For example, if we later find a math package with both increment and twice/half functionality, we can refer to that new library twice and keep our more meaningful names.
You should consider using aliases within your own program, even when using simple built-in types. For example, if you are developing an adventure game, you might alias Map[11] to SatchelContents. This doesn’t provide the strong typing that defining a separate SatchelContents class would give, but it does greatly improve the human understandability of the code.
Finding classes in *.class and *.groovy files is an important part of working with Groovy, and unfortunately a likely source of problems.
If you installed the J2SDK including the documentation, you will find the classpath explanation under %JAVA_HOME%/docs/tooldocs/windows/classpath.html under Windows, or under a similar directory for Linux and Solaris. Everything the documentation says equally applies to Groovy.
A number of contributors can influence the effective classpath in use. The overview in table 7.1 may serve as a reference when you’re looking for a possible bad guy that’s messing up your classpath.
Table 7.1. Forming the classpath
Origin | Definition | Purpose and use |
|---|---|---|
JDK/JRE | %JAVA_HOME%/lib %JAVA_HOME%/lib/ext | Bootclasspath for the Java Runtime Environment and its extensions |
OS setting |
| Provides general default settings |
Command shell |
| Provides more specialized settings |
Java |
| Settings per runtime invocation |
Groovy | %GROOVY_HOME%/lib | The Groovy Runtime Environment |
Groovy |
| Settings per |
Groovy | . | Groovy classpath defaults to the current directory |
Groovy defines its classpath in a special configuration file under %GROOVY_ HOME%/conf. Looking at the file groovy-starter.conf reveals the following lines (beside others):
# Load required libraries
load ${groovy.home}/lib/*.jar
# load user specific libraries
# load ${user.home}/.groovy/lib/*Uncommenting the last line by removing the leading hash sign enables a cool feature. In your personal home directory user.home, you can use a subdirectory .groovy/lib (note the leading dot!), where you can store any *.class or *.jar files that you want to have accessible whenever you work with Groovy.
If you have problems finding your user.home, open a command shell and execute
groovy -e "println System.properties.'user.home'"
Chances are, you are in this directory by default anyway.
Chapter 11 goes through more advanced classpath issues that need to be respected when embedding Groovy in environments that manage their own classloading infrastructure—for example an application server.
You are now able to use constructors in a number of different ways to make new instances of a class. Classes may reside in packages, and you have seen how to make them known via imports. This wraps up our exploration of object basics. The next step is to explore more advanced OO features, which we discuss in the following section.
Before beginning to embrace further parts of the Groovy libraries that make fundamental use of the OO features we have been discussing, we first stop to briefly explore other OO concepts that change once you enter the Groovy world. We will cover inheritance and interfaces, which will be familiar from Java, and multimethods, which will give you a taste of the dynamic object orientation coming later.
You have seen how to explicitly add your own fields, methods, and constructors into your class definitions. Inheritance allows you to implicitly add fields and methods from a base class. The mechanism is useful in a range of use cases. We leave it up to others[12] to describe its benefits and warn you about the potential overuse of this feature. We simply let you know that all the inheritance features of Java (including abstract classes) are available in Groovy and also work (almost seamlessly[13]) between Groovy and Java.
Groovy classes can extend Groovy and Java classes and interfaces alike. Java classes can also extend Groovy classes and interfaces. You need to compile your Java and Groovy classes in a particular order for this to work. See section 11.4.2 for more details. The only other thing you need to be aware of is that Groovy is more dynamic than Java when it selects which methods to invoke for you. This feature is known as multimethods and is discussed further in section 7.3.3.
A frequently advocated style of Java programming involves using Java’s interface mechanism. Code written using this style refers to the dependent classes that it uses solely by interface. The dependent classes can be safely changed later without requiring changes to the original program. If a developer accidentally tries to change one of the classes for another that doesn’t comply with the interface, this discrepancy is detected at compile time. Groovy fully supports the Java interface mechanism.
Some[14] argue that interfaces alone are not strong enough, and design-by-contract is more important for achieving safe object substitution and allowing nonbreaking changes to your libraries. Judicious use of abstract methods and inheritance becomes just as important as using interfaces. Groovy’s support for Java’s abstract methods, its automatically enabled assert statement, and its built-in ready access to test methods mean that it is ideally suited to also support this stricter approach.
Still others[15] argue that dynamic typing is the best approach, leading to much less typing and less scaffolding code without much reduced safety—which should be covered by tests in any case. The good news is that Groovy supports this style as well. To give you a flavor of how this would impact you in everyday coding, consider how you would build a plug-in mechanism in Java and Groovy.
In Java, you would normally write an interface for the plug-in mechanism and then an implementation class for each plug-in that implements that interface. In Groovy, dynamic typing allows you to more easily create and use implementations that meet a certain need. You are likely to be able to create just two classes as part of developing two plug-in implementations. In general, you have a lot less scaffolding code and a lot less typing.
For the Geeks
If you decide to make heavy use of interfaces, Groovy provides ways to make them more dynamic. If you have an interface MyInterface with a single method and a closure myClosure, you can use the as keyword to coerce the closure to be of type MyInterface. Similarly, if you have an interface with several methods, you can create a map of closures keyed on the method names and coerce the map to your interface type. See the Groovy wiki for more details.
In summary, if you’ve come from the Java world, you may be used to following a strict style of coding that strongly encourages interfaces. When using Groovy, you are not compelled to stick with any one style. In many situations, you can minimize the amount of typing by making use of dynamic typing; and if you really need it, the full use of interfaces is available.
Remember that Groovy’s mechanics of method lookup take the dynamic type of method arguments into account, whereas Java relies on the static type. This Groovy feature is called multimethods.
Listing 7.16 shows two methods, both called oracle, that are distinguishable only by their argument types. They are called two times with arguments of the same static type but different dynamic types.

The x argument is of static type Object and of dynamic type Integer. The y argument is of static type Object but of dynamic type String.
Both arguments are of the same static type, which would make the equivalent Java program dispatch both to oracle(Object). Because Groovy dispatches by the dynamic type, the specialized implementation of oracle(String) is used in the second case.
With this capability in place, you can better avoid duplicated code by being able to override behavior more selectively. Consider the equals implementation in listing 7.17 that overrides Object’s default equals method only for the argument type Equalizer.
Example 7.17. Multimethods to selectively override equals
class Equalizer {
boolean equals(Equalizer e){
return true
}
}
Object same = new Equalizer()
Object other = new Object()
assert new Equalizer().equals( same )
assert ! new Equalizer().equals( other )When an object of type Equalizer is passed to the equals method, the specialized implementation is chosen. When an arbitrary object is passed, the default implementation of its superclass Object.equals is called, which implements the equality check as a reference identity check.
The net effect is that the caller of the equals method can be fully unaware of the difference. From a caller’s perspective, it looks like equals(Equalizer) would override equals(Object), which would be impossible to do in Java. Instead, a Java programmer has to write it like this:
public class Equalizer { // Java
public boolean equals(Object obj)
{
if (obj == null) return false;
if (!(obj instanceof Equalizer)) return false;
Equalizer w = (Equalizer) obj;
return true; // custom logic here
}
}This is unfortunate, because the logic of how to correctly override equals needs to be duplicated for every custom type in Java. This is another example where Java uses the static type Object and leaves the work of dynamic type resolution to the programmer.
Note
Wherever there’s a Java API that uses the static type Object, this code effectively loses the strength of static typing. You will inevitably find it used with typecasts, compromising compile-time type safety. This is why the Java type concept is called weak static typing: You lose the merits of static typing without getting the benefits of a dynamically typed language such as multimethods.
Groovy, in contrast, comes with a single and consistent implementation of dispatching methods by the dynamic types of their arguments.
The JavaBeans specification[16] was introduced with Java 1.1 to define a lightweight and generic software component model for Java. The component model builds on naming conventions and APIs that allow Java classes to expose their properties to other classes and tools. This greatly enhanced the ability to define and use reusable components and opened up the possibility of developing component-aware tools.
The first tools were mainly visually oriented, such as visual builders that retrieved and manipulated properties of visual components. Over time, the Java-Beans concept has been widely used and extended to a range of use cases including server-side components (in Java Server Pages [JSP]), transactional behavior and persistence (Enterprise JavaBeans [EJB]), object-relational mapping (ORM) frameworks, and countless other frameworks and tools.
Groovy makes using JavaBeans (and hence most of these other JavaBean-related frameworks) easier with special language support. This support covers three aspects: special Groovy syntax for creating JavaBean classes; mechanisms for easily accessing beans, regardless of whether they were declared in Groovy or Java; and support for JavaBean event handling. This section will examine each part of this language-level support as well as cover the library support provided by the Expando class.
JavaBeans are normal classes that follow certain naming conventions. For example, to make a String property myProp available in a JavaBean, the bean’s class must have public methods declared as String getMyProp and void setMyProp (String value). The JavaBean specification also strongly recommends that beans should be serializable so they can be persistent and provide a parameterless constructor to allow easy construction of objects from within tools. A typical Java implementation is as follows:
// Java
public class MyBean implements java.io.Serializable {
private String myprop;
public String getMyprop(){
return myprop;
}
public void setMyprop(String value){
myprop = value;
}
}The Groovy equivalent is
class MyBean implements Serializable {
String myprop
}The most obvious difference is size. One line of Groovy replaces seven lines of Java. But it’s not only about less typing, it is also about self-documentation. In Groovy, it is easier to assess what fields are considered exposed properties: all fields that are declared with default visibility. The three related pieces of information—the field and the two accessor methods—are kept together in one declaration. Changing the type or the name of the property requires changing the code in only a single place.
Note
Older versions of Groovy used an @Property syntax for denoting properties. This was considered ugly and was removed in favor of handling properties as a “default visibility.”
Underneath the covers, Groovy provides public accessor methods similar to this Java code equivalent, but you don’t have to type them. Moreover, they are generated only if they don’t already exist in the class. This allows you to override the standard accessors with either customized logic or constrained visibility. Groovy also provides a private backing field (again similar to the Java equivalent code). Note that the JavaBean specification cares only about the available accessor methods and doesn’t even require a backing field; but having one is an intuitive and simple way to implement the methods—so that is what Groovy does.
Note
It is important that Groovy constructs the accessor methods and adds them to the bytecode. This ensures that when using a MyBean in the Java world, the Groovy MyBean class is recognized as a proper JavaBean.
Listing 7.18 shows the declaration options for properties with optional typing and assignment. The rules are equivalent to those for fields (see section 7.2.1).
Example 7.18. Declaring properties in GroovyBeans
class MyBean implements Serializable {
def untyped
String typed
def item1, item2
def assigned = 'default value'
}
def bean = new MyBean()
assert 'default value' == bean.getAssigned()
bean.setUntyped('some value')
assert 'some value' == bean.getUntyped()
bean = new MyBean(typed:'another value')
assert 'another value' == bean.getTyped()Properties are sometimes called readable or writeable depending on whether the corresponding getter or setter method is available. Groovy properties are both readable and writeable, but you can always roll your own if you have special requirements. When the final keyword is used with a property declaration, the property will only be readable (no setter method is created and the backing field is final).
Writing GroovyBeans is a simple and elegant solution for fully compliant Java-Bean support, with the option of specifying types as required.
The wide adoption of the JavaBeans concept in the world of Java has led to a common programming style where bean-style accessor methods are limited to simple access (costly operations are strictly avoided in these methods). These are the types of accessors generated for you by Groovy. If you have complex additional logic related to a property, you can always override the relevant getter or setter, but you are usually better off writing a separate business method for your advanced logic.
Even for classes that do not fully comply with the JavaBeans standard, you can usually assume that such an accessor method can be called without a big performance penalty or other harmful side-effects. The characteristics of an accessor method are much like those of a direct field access (without breaking the uniform access principle[17]).
Groovy supports this style at the language level according to the mapping of method calls shown in table 7.2.
This mapping works regardless of whether it’s applied to a Groovy or plain old Java object (POJO), and it works for beans as well as for all other classes. Listing 7.19 shows this in a combination of bean-style and derived properties.

Note how much the Groovy-style property access in ![]() and
and ![]() looks like direct field access, whereas
looks like direct field access, whereas ![]() makes clear that there is no field but only some derived value. From a caller’s point of view, the access is truly uniform.
makes clear that there is no field but only some derived value. From a caller’s point of view, the access is truly uniform.
Because field access and the accessor method shortcut have an identical syntax, it takes rules to choose one or the other.
Rules
When both a field and the corresponding accessor method are accessible to the caller, the property reference is resolved as an accessor method call. If only one is accessible, that option is chosen.
That looks straightforward, and it is in the majority of cases. However, there are some points to consider, as you will see next.
Before we leave the topic of properties, we have one more example to explore: listing 7.20. The listing illustrates how you can provide your own accessor methods and also how to bypass the accessor mechanism. You can get directly to the field using the .@ dot-at operator when the need arises.

Let’s start with what’s familiar: bean.value at ![]() calls
calls getValue and thus returns the doubled value. But wait—getValue calculates the result at ![]() as
as value * 2. If value was at this point interpreted as a bean shortcut for getValue, we would have an endless recursion.
A similar situation arises at ![]() , where the assignment
, where the assignment this.value = would in bean terms be interpreted as this.setValue, which would also let us fall into endless looping. Therefore the following rules have been set up.
Rules
Inside the lexical scope of a field, references to fieldname or this.fieldname are resolved as field access, not as property access. The same effect can be achieved from outside the scope using the reference.@fieldname syntax.
It needs to be mentioned that these rules can produce pathological corner cases with logical but surprising behavior, such as when using @ from a static context or with def x=this; x.@fieldname, and so on. We will not go into more details here, because such a design is discouraged. Decide whether to expose state as a field, as a property, or via explicit accessor methods, but do not mix these approaches. Keep the access uniform.
Besides properties, JavaBeans can also be event sources that feed event listeners.[18] An event listener is an object with a callback method that gets called to notify the listener that an event was fired. An event object that further qualifies the event is passed as a parameter to the callback method.
The JDK is full of different types of event listeners. A simple event listener is the ActionListener on a button, which calls an actionPerformed(ActionEvent) method whenever the button is clicked. A more complex example is the VetoableChangeListener that allows listeners to throw a PropertyVetoException inside their vetoableChange(PropertyChangeEvent) method to roll back a change to a bean’s property. Other usages are multifold, and it’s impossible to provide an exhaustive list.
Groovy supports event listeners in a simple but powerful way. Suppose you need to create a Swing JButton with the label “Push me!” that prints the label to the console when it is clicked. A Java implementation can use an anonymous inner class in the following way:
// Java
final JButton button = new JButton("Push me!");
button.addActionListener(new IActionListener(){
public void actionPerformed(ActionEvent event){
System.out.println(button.getText());
}
});The developer needs to know about the respective listener and event types (or interfaces) as well as about the registration and callback methods.
A Groovy programmer only has to attach a closure to the button as if it were a field named by the respective callback method:
button = new JButton('Push me!')
button.actionPerformed = { event ->
println button.text
}The event parameter is added only to show how we could get it when needed. In this example, it could have been omitted, because it is not used inside the closure.
Note
Groovy uses bean introspection to determine whether a field setter refers to a callback method of a listener that is supported by the bean. If so, a ClosureListener is transparently added that calls the closure when notified. A ClosureListener is a proxy implementation of the required listener interface.
Event handling is conceived as a JavaBeans standard. However, you don’t need to somehow declare your object to be a bean before you can do any event handling. The dependency is the other way around: As soon as your object supports this style of event handling, it is called a bean.
Although Groovy adds the ability to register event listeners easily as closures, the Java style of bean event handling remains fully intact. That means you can still use all available Java methods to get a list of all registered listeners, adding more of them, or removing them when they are no longer needed.
Groovy doesn’t distinguish between beans and other kinds of object. It solely relies on the accessibility of the respective getter and setter methods.
Listing 7.21 shows how to use the getProperties method and thus the properties property (sorry for the tricky wording) to get a map of a bean’s properties. You can do so with any object you fancy.
Example 7.21. GDK methods for bean properties
class SomeClass {
def someProperty
public someField
private somePrivateField
}
def obj = new SomeClass()
def store = []
obj.properties.each { property ->
store += property.key
store += property.value
}
assert store.contains('someProperty')
assert store.contains('someField') == false
assert store.contains('somePrivateField') == false
assert store.contains('class')
assert store.contains('metaClass')
assert obj.properties.size() == 3In addition to the property that is explicitly declared, you also see class and meta-Class references. These are artifacts of the Groovy class generation.[19]
This was a taste of what will be explained in more detail in section 9.1.
In Groovy code, you will often find expressions such as object.name. Here is what happens when Groovy resolves this reference:
If
objectrefers to a map,object.namerefers to the value corresponding to thenamekey that is stored in the map.Otherwise, if
nameis a is a property ofobject, the property is referenced (with precedence of accessor methods over fields, as you saw in section 7.4.2).Every Groovy object has the opportunity to implement its own
getProperty (name)andsetProperty(name,value)methods. When it does, these implementations are used to control the property access. Maps, for example, use this mechanism to expose keys as properties.As shown in section 7.1.1, field access can be intercepted by providing the
object.get(name) method. This is a last resort as far as the Groovy runtime is concerned: It’s used only when there is no appropriate JavaBeans property available and whengetPropertyisn’t implemented.
It is worth noting that when name contains special characters that would not be valid for an identifier, it can be supplied in string delimiters: for example, object.'my-name'. You can also use a GString: def name = 'my-name'; object. "$name". As you saw in section 7.1.1 and we will further explore in section 9.1.1, there is also a getAt implementation on Object that delegates to the property access such that you can access a property via object[name].
The rationale behind the admittedly nontrivial reference resolution is to allow dynamic state and behavior for Groovy objects. Groovy comes with an example of how useful this feature is: Expando. An Expando can be thought of as an expandable alternative to a bean, albeit one that can be used only within Groovy and not directly in Java. It supports the Groovy style of property access with a few extensions. Listing 7.22 shows how an Expando object can be expanded with properties by assignment, analogous to maps. The difference comes with assigning closures to a property. Those are executed when accessing the property, optionally taking parameters. In the example, the boxer fights back by returning multiple times what he has taken before.
Example 7.22. Expando
def boxer = new Expando()
assert null == boxer.takeThis
boxer.takeThis = 'ouch!'
assert 'ouch!' == boxer.takeThis
boxer.fightBack = {times -> return this.takeThis * times }
assert 'ouch!ouch!ouch!' == boxer.fightBack(3)In a way, Expando’s ability to assign closures to properties and have property access calling the stored closures is like dynamically attaching methods to an object.
Maps and Expandos are extreme solutions when it comes to avoiding writing dump data structures as classes, because they do not require any extra class to be written. In Groovy, accessing the keys of a map or the properties of an Expando doesn’t look different from accessing the properties of a full-blown JavaBean. This comes at at a price: Expandos cannot be used as beans in the Java world and do not support any kind of typing.
This section presents three power features that Groovy supports at the language level: GPath, the Spread operator, and the use keyword.
We start by looking at GPaths. A GPath is a construction in Groovy code that powers object navigation. The name is chosen as an analogy to XPath, which is a standard for describing traversal of XML (and equivalent) documents. Just like XPath, a GPath is aimed at expressiveness: realizing short, compact expressions that are still easy to read.
GPaths are almost entirely built on concepts that you have already seen: field access, shortened method calls, and the GDK methods added to Collection. They introduce only one new operator: the *. spread-dot operator. Let’s start working with it right away.
We’ll explore Groovy by paving a path through the Reflection API. The goal is to get a sorted list of all getter methods for the current object. We will do so step-by-step, so please open a groovyConsole and follow along. You will try to get information about your current object, so type
this
and run the script (by pressing Ctrl-Enter). In the output pane, you will see something like
Script1@e7e8eb
which is the string representation of the current object. To get information about the class of this object, you could use this.getClass, but in Groovy you can type
this.class
which displays (after you run the script again)
class Script2
The class object reveals available methods with getMethods, so type
this.class.methods
which prints a long list of method object descriptions. This is too much information for the moment. You are only interested in the method names. Each method object has a getName method, so call
this.class.methods.name
and get a list of method names, returned as a list of string objects. You can easily work on it applying what you learned about strings, regular expressions, and lists. Because you are only interested in getter methods and want to have them sorted, type
this.class.methods.name.grep(~/get.*/).sort()
and voilà, you will get the result
["getBinding", "getClass", "getMetaClass", "getProperty"]
Such an expression is called a GPath. One special thing about it is that you can call the name property on a list of method objects and receive a list of string objects—that is, the names.
The rule behind this is that
list.property
is equal to
list.collect{ item -> item?.property}
This is an abbreviation of the special case when properties are accessed on lists. The general case reads like
list*.member
where *. is called the spread-dot operator and member can be a field access, a property access, or a method call. The spread-dot operator is needed whenever a method should be applied to all elements of the list rather than to the list itself. It is equivalent to
list.collect{ item -> item?. member}
To see GPath in action, we step into an example that is reasonably close to reality. Suppose you are processing invoices that consist of line items, where each line refers to the sold product and a multiplicity. A product has a price in dollars and a name.
An invoice could look like table 7.3.
Figure 7.1 depicts the corresponding software model in a UML class diagram. The Invoice class aggregates multiple LineItems that in turn refer to a Product.

Figure 7.1. UML class diagram of an Invoice class that aggregates multiple instances of a LineItem class, which in turn aggregates exactly one instance of a Product class
Listing 7.23 is the Groovy implementation of this design. It defines the classes as GroovyBeans, constructs sample invoices with this structure, and finally uses GPath expressions to query the object graph in multiple ways.
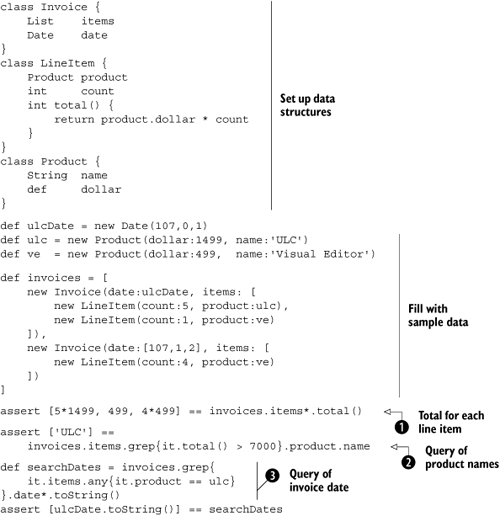
The queries in listing 7.23 are fairly involved. The first, at ![]() , finds the total for each invoice, adding up all the line items. We then run a query, at
, finds the total for each invoice, adding up all the line items. We then run a query, at ![]() , which finds all the names of products that have a line item with a total of over 7,000 dollars. Finally, query
, which finds all the names of products that have a line item with a total of over 7,000 dollars. Finally, query ![]() finds the date of each invoice containing a purchase of the ULC product and turns it into a string.
finds the date of each invoice containing a purchase of the ULC product and turns it into a string.
Printing the full Java equivalent here would cover four pages and would be boring to read. If you want to read it, you can find it in the book’s online resources.
The interesting part is the comparison of GPath and the corresponding Java code. The GPath
invoices.items.grep{ it.total() > 7000 }.product.nameleads to the Java equivalent
// Java
private static List getProductNamesWithItemTotal(Invoice[] invoices) {
List result = new LinkedList();
for (int i = 0; i < invoices.length; i++) {
List items = invoices[i].getItems();
for (Iterator iter = items.iterator(); iter.hasNext();) {
LineItem lineItem = (LineItem) iter.next();
if (lineItem.total() > 7000){
result.add(lineItem.getProduct().getName());
}
}
}
return result;
}Table 7.4 gives you some metrics about both full versions, comparing lines of code (LOC), number of statements, and complexity in the sense of nesting depth
There may be ways to slim down the Java version, but the order of magnitude remains: Groovy needs less than 25% of the Java code lines and fewer than 10% of the statements!
Writing less code is not just an exercise for its own sake. It also means lower chances of making errors and thus less testing effort. Whereas some new developers think of a good day as one in which they’ve added lots of lines to the codebase, we consider a really good day as one in which we’ve added functionality but removed lines from the codebase.
In a lot of languages, less code comes at the expense of clarity. Not so in Groovy. The GPath example is the best proof. It is much easier to read and understand than its Java counterpart. Even the complexity metrics are superior.
As a final observation, consider maintainability. Suppose your customer refines their requirements, and you need to change the lookup logic. How much effort does that take in Groovy as opposed to Java?
Groovy provides a * spread operator that is connected to the spread-dot operator in that it deals with tearing a list apart. It can be seen as the reverse counterpart of the subscript operator that creates a list from a sequence of comma-separated objects. The spread operator distributes all items of a list to a receiver that can take this sequence. Such a receiver can be a method that takes a sequence of arguments or a list constructor.
What is this good for? Suppose you have a method that returns multiple results in a list, and your code needs to pass these results to a second method. The spread operator distributes the result values over the second method’s parameters:
def getList(){
return [1,2,3]
}
def sum(a,b,c){
return a + b + c
}
assert 6 == sum(*list)This allows clever meshing of methods that return and receive multiple values while allowing the receiving method to declare each parameter separately.
The distribution with the spread operator also works on ranges and when distributing all items of a list into a second list:
def range = (1..3) assert [0,1,2,3] == [0,*range]
The same trick can be applied to maps:
def map = [a:1,b:2] assert [a:1, b:2, c:3] == [c:3, *:map]
The spread operator eliminates the need for boilerplate code that would otherwise be necessary to merge lists, ranges, and maps into the expected format. You will see this in action in section 10.3, where this operator helps implement a user command language for database access.
As shown in the previous assertions, the spread operator is conveniently used inside expressions, supporting a functional style of programming as opposed to a procedural style. In a procedural style, you would introduce statements like list.addAll(otherlist).
Now comes Groovy’s ultimate power feature, which you can use to assign new methods to any Groovy or Java class.
Consider a program that reads two integer values from an external device, adds them together, and writes the result back. Reading and writing are in terms of strings; adding is in terms of integer math. You can’t write
write( read() + read() )
because this would result in calling the plus method on strings and would concatenate the arguments rather than adding them.
Groovy provides the use method,[20] which allows you to augment a class’s available instance methods using a so-called category. In our example, we can augment the plus method on strings to get the required Perl-like behavior:
use(StringCalculationCategory) {
write( read() + read() )
}A category is a class that contains a set of static methods (called category methods). The use keyword makes each of these methods available on the class of that method’s first argument, as an instance method:
class StringCalculationCategory {
static String plus(String self, String operand) {
// implementation
}
}Because self is the first argument, the plus(operand) method is now available (or overridden) on the String class.
Listing 7.24 shows the full example. It implements these requirements with a fallback in case the strings aren’t really integers and a usual concatenation should apply.
Example 7.24. The use keyword for calculation on strings
class StringCalculationCategory {
static def plus(String self, String operand) {
try {
return self.toInteger() + operand.toInteger()
}
catch (NumberFormatException fallback){
return (self << operand).toString()
}
}
}
use (StringCalculationCategory) {
assert 1 == '1' + '0'
assert 2 == '1' + '1'
assert 'x1' == 'x' + '1'
}The use of a category is limited to the duration of the attached closure and the current thread. The rationale is that such a change should not be globally visible to protect from unintended side effects.
Throughout the language basics part of this book, you have seen that Groovy adds new methods to existing classes. The whole GDK is implemented by adding new methods to existing JDK classes. The use method allows any Groovy programmer to use the same strategy in their own code.
A category can be used for multiple purposes:
To provide special-purpose methods, as you have seen with
StringCalculationCategory, where the calculation methods have the same receiver class and may override existing behavior. Overriding operator methods is special.To provide additional methods on library classes, effectively solving the incomplete library class smell.[21]
To provide a collection of methods on different receivers that work in combination—for example, a new
encryptedWritemethod onjava.io.OutputStreamanddecryptedReadonjava.io.InputStream.Where Java uses the Decorator[22] pattern, but without the hassle of writing lots of relay methods.
To split an overly large class into a core class and multiple aspect categories that are used with the core class as needed. Note that
usecan take any number of category classes.
When a category method is assigned to Object, it is available in all objects—that is, everywhere. This makes for nice all-purpose methods like logging, printing, persistence, and so on. For example, you already know everything to make that happen for persistence:
class PersistenceCategory {
static void save(Object self) {
// whatever you do to store 'self' goes here
}
}
use (PersistenceCategory) {
save()
}Instead of Object, a smaller area of applicability may be of interest, such as all Collection classes or all your business objects if they share a common interface.
Note that you can supply as many category classes as you wish as arguments to the use method by comma-separating the classes or supplying them as a list.
use (ACategory, BCategory, CCategory) {}By now, you should have some idea of Groovy’s power features. They are impressive even at first read, but the real appreciation will come when you apply them in your own code. It is worth consciously bearing them in mind early on in your travels with Groovy so that you don’t miss out on some elegant code just because the features and patterns are unfamiliar. Before long, they will become so familiar that you will miss them a lot when you are forced to go back to Java. The good news is that Groovy can easily be used from Java, as we will explore in chapter 11.
The use of category classes in closures is a feature that Groovy can provide because of its Meta concept, which is presented in the next section.
In order to fully leverage the power of Groovy, it’s beneficial to have a general understanding of how it works inside. It is not necessary to know all the details, but familiarity with the overall concepts will allow you to work more confidently in Groovy and find more elegant solutions.
This section provides you with a peek inside how Groovy performs its magic. The intent is to explain some of the general concepts used under the covers, so that you can write solutions that integrate more closely with Groovy’s inner runtime workings. Groovy has numerous interception points, and choosing between them lets you leverage or override different amounts of the built-in Groovy capabilities. This gives you many options to write powerful yet elegant solutions outside the bounds of what Groovy can give you out of the box. We will describe these interception points and then provide an example of how they work in action.
The capabilities described in this section collectively form Groovy’s implementation of the Meta-Object Protocol (MOP). This is a term used for a system’s ability to change the behavior of objects and classes at runtime—to mess around with the guts of the system, to put it crudely.
At the time of writing, a redesign of the MOP is ongoing and is called the new MOP. It is mainly concerned with improving the internals with respect to consistency of the implementation and runtime performance. We highlight where changes are expected for the programmer.
In Groovy, everything starts with the GroovyObject interface, which, like all the other classes we’ve mentioned, is declared in the package groovy.lang. It looks like this:
public interface GroovyObject {
public Object invokeMethod(String name, Object args);
public Object getProperty(String property);
public void[23] setProperty(String property, Object newValue);
public MetaClass getMetaClass();
public void setMetaClass(MetaClass metaClass);
}All classes you program in Groovy are constructed by the GroovyClassGenerator such that they implement this interface and have a default implementation for each of these methods—unless you choose to implement it yourself.
Note
If you want a usual Java class to be recognized as a Groovy class, you only have to implement the GroovyObject interface. For convenience, you can also subclass the abstract class GroovyObjectSupport, which provides default implementations.
GroovyObject has an association with MetaClass, which is the navel of the Groovy meta concept. It provides all the meta-information about a Groovy class, such as the list of available methods, fields, and properties. It also implements the following methods:
Object invokeMethod(Object obj, String methodName, Object args) Object invokeMethod(Object obj, String methodName, Object[] args) Object invokeStaticMethod(Object obj, String methodName, Object[] args) Object invokeConstructor(Object[] args)
These methods do the real work of method invocation,[24] either through the Java Reflection API or (by default and with better performance) through a transparently created reflector class. The default implementation of GroovyObject. invokeMethod relays any calls to its MetaClass.
The MetaClass is stored in and retrieved from a central store, the MetaClassRegistry.
Figure 7.2 shows the overall picture (keep this picture in mind when thinking through Groovy’s process of invoking a method).
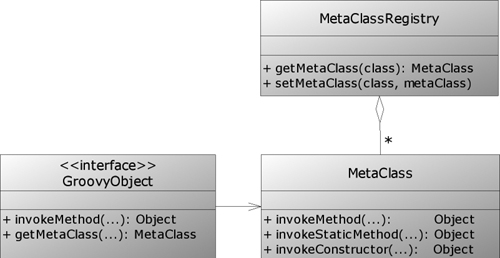
Figure 7.2. UML class diagram of the GroovyObject interface that refers to an instance of class MetaClass, where MetaClass objects are also aggregated by the MetaClassRegistry to allow class-based retrieval of MetaClasses in addition to GroovyObject’s potentially object-based retrieval
Note
The MetaClassRegistry class is intended to be a Singleton but it is not used as such, yet. Anyway, throughout the code, a factory method on InvokerHelper is used to refer to a single instance of this registry.
The structure as depicted in figure 7.2 is able to deal with having one MetaClass per object, but this capability is not used in the default implementations. Current default implementations use one MetaClass per class in the MetaClassRegistry. This difference becomes important when you’re trying to define methods that are accessible only on certain instances of a class (like singleton methods in Ruby).
Note
The MetaClass that a GroovyObject refers to and the MetaClass that is registered for the type of this GroovyObject in the MetaClassRegistry do not need to be identical. For instance, a certain object can have a special MetaClass assigned that differs from the MetaClass of all other objects of this class.
Groovy generates its Java bytecode such that each method call (after some redirections) is handled by one of the following mechanisms:
The class’s own
invokeMethodimplementation (which may further choose to relay it to someMetaClass)Its own
MetaClass, by callinggetMetaClass().invokeMethod(...)The
MetaClassthat is registered for its type in theMetaClassRegistry
The decision is taken by an Invoker singleton that applies the logic as shown in figure 7.3.[25] Each number in the diagram refers to the corresponding mechanism in the previous numbered list.
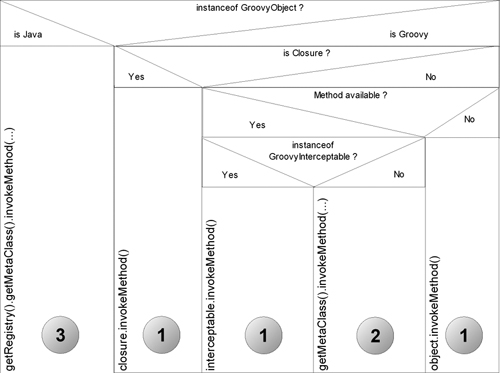
Figure 7.3. Nassi-Shneidermann diagram of Groovy’s decision logic for three distinct kinds of method invocation based on the method’s receiver type and method availability. Follow the conditions like a flow diagram to discover which course of action is taken.
This is a relatively complex decision to make for every method call, and of course most of the time you don’t need to think about it. You certainly shouldn’t be mentally tracing your way through the diagram for every method call you make—after all, Groovy is meant to make things easier, not harder! However, it’s worth having the details available so that you can always work out exactly what will happen in a complicated situation. It also opens your mind to a wide range of possibilities for adding dynamic behavior to your own classes. The possibilities include the following:
You can intercept method calls with cross-cutting concerns (aspects) such as logging/tracing all invocations, applying security restrictions, enforcing transaction control, and so on.
You can relay method calls to other objects. For example, a wrapper can relay to a wrapped object all method calls that it cannot handle itself.
You can pretend to execute a method while some other logic is applied. For example, an
Htmlclass could pretend to have a methodbody, while the call was executed asprint('body').By the Way
This is what builders do. They pretend to have methods that are used to define nested product structures. This will be explained in detail in chapter 8.
The invocation logic suggests that there are multiple ways to implement intercepted, relayed, or pretended methods:
Implementing/overriding
invokeMethodin aGroovyObjectto pretend or relay method calls (all your defined methods are still called as usual).Implementing/overriding
invokeMethodin aGroovyObject, and also implementing theGroovyInterceptableinterface to additionally intercept calls to your defined methods.Providing an implementation of
MetaClass, and callingsetMetaClasson the targetGroovyObjects.Providing an implementation of
MetaClass, and registering it in theMetaClassRegistryfor all target classes (Groovy and Java classes). This scenario is supported by theProxyMetaClass.
Generally speaking, overriding/implementing invokeMethod means to override the dot-methodname operator.
The next section will teach you how to leverage this knowledge.
Suppose we have a Groovy class Whatever with methods outer and inner that call each other, and we have lost track of the intended calling sequence. We would like to get a runtime trace of method calls like
before method 'outer' before method 'inner' after method 'inner' after method 'outer'
to confirm that the outer method calls the inner method.
Because this is a GroovyObject, we can override invokeMethod. To make sure we can intercept calls to our defined methods, we need to implement the GroovyInterceptable interface, which is only a marker interface and has no methods.
Inside invokeMethod, we write into a trace log before and after executing the method call. We keep an indentation level for tidy output. Trace output should go to System.out by default or to a given Writer, which allows easy testing. We achieve this by providing a writer property.
To make our code more coherent, we put all the tracing functionality in a superclass Traceable. Listing 7.25 shows the final solution.

It’s crucial not to step into an endless loop when relaying the method call, which would be unavoidable when calling the method in the same way the interception method was called (thus falling into the same column in figure 7.3). Instead, we enforce falling into the leftmost column with the invokeMethod call at ![]() .
.
We use Groovy’s convenient StringBufferWriter to access the output at ![]() . To see the output on
. To see the output on System.out, use new Whatever without parameters.
The whole execution starts at ![]() . We also assert that we still get the proper result.
. We also assert that we still get the proper result.
Unfortunately, this solution is limited. First, it works only on GroovyObjects, not on arbitrary Java classes. Second, it doesn’t work if the class under inspection already extends some other superclass.
Recalling figure 7.3, we need a solution that replaces our MetaClass in the MetaClassRegistry with an implementation that allows tracing. There is such a class in the Groovy codebase: ProxyMetaClass.
This class serves as a decorator over an existing MetaClass and adds intercept-ablility to it by using an Interceptor (see groovy.lang.Interceptor in the Groovy Javadocs). Luckily, there is a TracingInterceptor that serves our purposes. Listing 7.26 shows how we can use it with the Whatever class.

Note that this solution also works with all Java classes when called from Groovy.
For GroovyObjects that are not invoked via the MetaClassRegistry, you can pass the object under analysis to the use method to make it work:
proxy.use(traceMe){
// call methods on traceMe
}Interceptor and ProxyMetaClass can be useful for debugging purposes but also for simple profiling tasks. They open the door for all the cross-cutting concerns that we mentioned earlier.
Note
Take care when applying wide-ranging changes to the MetaClassRegistry. This can potentially have unintended effects on parts of the codebase that seem unrelated. Be careful with your cross-cutting concerns, and avoid cutting too much or too deeply!
That’s it for our tour through Groovy’s Meta capabilities. The magician has revealed all his tricks (well, at least most of them), and you can now be a magician yourself.
MOP makes Groovy a dynamic language. It is the basis for numerous inventions that Groovy brings to the Java platform. The remainder of this book will show the most important ones: builders, markup, persistency, distributed programming, transparent mocks and stubs for testing purposes, and all kinds of dynamic APIs over existing frameworks, such as for Windows scripting with Scriptom or object-relational mapping through Hibernate.
This dynamic nature makes a framework such as Grails (see chapter 16) possible on the Java platform.
Groovy is often perceived as a scripting language for the JVM, and it is. But making Java scriptable is not the most distinctive feature. The Meta-Object Protocol and the resulting dynamic nature elevate Groovy over other languages.
Congratulations on making it to the end of this chapter and the end of part 1 of this book. If you are new to dynamic languages, your head may be spinning right now—it’s been quite a journey!
The chapter started without too many surprises, showing the similarities between Java and Groovy in terms of defining and organizing classes. As we introduced named parameters for constructors and methods, optional parameters for methods, and dynamic field lookup with the subscript operator, as well as Groovy’s “load at runtime” abilities, it became obvious that Groovy has more spring in its step than Java.
Groovy’s handling of the JavaBeans conventions reinforced this, as we showed Groovy classes with JavaBean-style properties that were simpler and more expressive to both create and use than their Java equivalents. By the time you saw Groovy’s power features such as GPath and categories, the level of departure was becoming more apparent, and Groovy’s dynamic nature was beginning to show at the seams.
Finally, with a discussion of Groovy’s implementation of the Meta-Object Protocol, this dynamic nature came out in the open. What began as a “drip, drip, drip” of features with a mixture of dynamic aspects and syntactic sugar ended as a torrent of options for changing almost every aspect of Groovy’s behavior dynamically at runtime.
In retrospect, the dependencies and mutual support between these different aspects of the language become obvious: using the map datatype with default constructors, using the range datatype with the subscript operator, using operator overriding with the switch control structure, using closures for grepping through a list, using the list datatype in generic constructors, using bean properties with a field-like syntax, and so on. This seamless interplay not only gives Groovy its power but also makes it fun to use.
What is perhaps most striking is the compactness of the Groovy code while the readability is preserved if not enhanced. It has been reported[26] that developer productivity hasn’t improved much since the ’70s in terms of lines of code written per day. The boost in productivity comes from the fact that a single line of code nowadays expresses much more than in previous eras. Now, if a single line of Groovy can replace multiple lines of Java, we could start to see the next major boost in developer productivity.
[1] Interfaces are also like their Java counterparts, but we will hold off discussing those further until section 7.3.2.
[2] Java’s default package-wide visibility is not supported.
[3] The shouldFail method as used in this example checks that a ClassCastException occurs. More details can be found in section 14.3.
[4] This notation can also appear in the form of obj.@fieldname, as you will see in section 7.4.2.
[5] We recommend a coding style that encourages small numbers of parameters, but this is not always possible
[6] In general, 2n constructors are needed, where n is the number of optional attributes.
[7] Because the class has no package name, it is implicitly placed in the default package.
[8] Strictly speaking, you can alternatively extend GroovyTestCase or implement the Runnable interface.
[9] Whether classes are checked for runtime updates can be controlled by the CompilerConfiguration, which obeys the system property groovy.recompile by default. See the API documentation for details.
[10] Where are the library author’s unit tests?
[11] Here we mean java.util.Map and not TreasureMap, which our adventure game might allow us to place within the satchel!
[12] Designing Object-Oriented Software, Rebecca Wirfs-Brock et al (Prentice-Hall, 1990).
[13] The only limitation that we are aware of has to do with Map-based constructors, which Groovy provides by default. These are not available directly in Java if you extend a Groovy class. They are provided by Groovy as a runtime trick.
[14] See Object-oriented Software Construction, 2nd ed., by Bertrand Meyer (Prentice-Hall, 1997) and http://cafe.elharo.com/java/the-three-reasons-for-data-encapsulation/.
[18] See the JavaBeans Specification.
[19] The class property stems from Java. However, tools that use Java’s bean introspection often hide this property.
[20] Like most Groovy programmers, we prefer to call use a keyword, but strictly speaking it is a method that Groovy adds to java.lang.Object.
[21] See chapter 3 (written by Kent Beck and Martin Fowler) of Refactoring (Addison-Wesley, 2000).
[22] See page 195 of Design Patterns: Elements of Reusable Object-Oriented Software by Gamma et al (Addison Wesley, 1994).
[23] New MOP: return boolean to indicate success of the operation. No more exceptions are thrown.
[24] New MOP: These methods no longer throw an exception in case of errors but return an error token. The same is true for getProperty. The internals of the implementation may also change; for example, more specialized methods may be used for faster dispatch.
[25] New MOP: Closures will no longer be handled as a special case in the default MetaClass. Instead, a custom MetaClass for closures will produce the same effect.
[26] The Journal of Defense Software Engineering, 08/2000, http://www.stsc.hill.af.mil/crosstalk/2000/08/jensen.html, based on the work of Gerald M. Weinberg.