
Chapter Syllabus
27.1 Typical Cluster Management Tasks
27.2 Adding a Node to the Cluster
27.3 Adding a Node to a Package
27.4 Adding a New Package to the Cluster Utilizing a Serviceguard Toolkit
27.5 Modifying an Existing Package to Use EMS Resources
27.6 Deleting a Package from the Cluster
27.7 Deleting a Node from the Cluster
27.8 Discussing the Process of Rolling Upgrades within a Cluster
27.9 If It Breaks, Fix It!
27.10 Installing and Using the Serviceguard Manager GUI
In this chapter, we look at key tasks when managing a cluster; we add and remove nodes from the cluster as well as add and remove packages from the cluster. An important aspect of these tasks is knowing when we can perform them without interrupting access to existing resources. After all, we are trying to provide a highly available computing resource to our user community; we are aiming to eliminate or at least minimize any unplanned downtime.
There are quite a few tasks we might want to perform when managing a cluster. Consequently, any form of “cookbook” is going to be based not around a single specific task but looking at how we can minimize downtime when managing the cluster. Here we summarize which cluster- and package-related tasks can and cannot be performed without interrupting service.
Change to Cluster Configuration | Required Cluster State |
|---|---|
Add a new node. | All cluster nodes must be running. |
Delete an existing node. | A node can be deleted even if it is down or unreachable. |
Change maximum configure packages. | Cluster must not be running. |
Change timing parameters. | Cluster must not be running. |
Change cluster lock configuration. | Cluster must not be running. |
Change serial heartbeat configuration. | Cluster must not be running. |
Change IP address for heartbeats. | Cluster must not be running. |
Change addresses of monitored subnets. | Cluster must not be running. |
Change to Package Configuration | Required Package State |
|---|---|
Add a new package. | Other packages can be running. |
Remove a package. | Package must be halted. Cluster can be running. |
Add a new node. | Package(s) may be running. |
Remove a node. | Package(s) may be running on different nodes. |
Add/remove a new service process. | Package must be halted. |
Add/remove a new subnet. | Package must be halted. Cluster may need halting if subnet is new to the cluster. |
Add/remove a new EMS resource. | Package must be halted. Cluster may need halting if EMS resource is new to the cluster. |
Changes to the run/halt script contents | Recommended that package be halted to avoid any timing problems while running the script. |
Script timeouts | Package may be running. |
Service timeouts | Package must be halted. |
Failfast parameters | Package must be halted. |
Auto_Run | Package may be running. |
Local LAN failover | Package may be running. |
Change node adoption order. | Package may be running. |
There are quite a lot of permutations to go though. I am not going to go through every one here. I will perform some of the more common tasks:
Adding a node to a cluster.
Adding a new node to a package.
Adding a new package to the cluster utilizing a Serviceguard Toolkit.
Modifying an existing package to use EMS resources.
Deleting a package from the cluster.
Deleting a node from the cluster.
Including deleting a node from a package.
Discussing the process of rolling upgrades within a cluster.
Installing and using the Serviceguard Manager GUI.
These individual tasks give you a template of the steps to perform in order to effect changes within your cluster. Let's start by adding a node to the cluster.
According to the list above, I can perform this task while the cluster and other packages are running. The process of adding a node is not too difficult. In essence, we need to update the binary cluster configuration file with the node specific details for the new node. Let's get some elementary tasks out of the way first:
Set up NTP between the new node and other cluster members.
Ensure that any shared LVM volume groups are not activated at boot time.
Install Serviceguard and any related patches on the new node.
Set up on all nodes the file
/etc/cmcluster/cmclnodelistto include the new node name.
The initial steps were covered in Chapter 25, “Setting up a Serviceguard Cluster.” To add a new node to our cluster, we need all nodes to be up and running. If we think about this process we could perform it in a number of ways; if we have the most up-to-date cluster ASCII configuration file we could simply append the relevant information to it in order to add new nodes. We would have to be certain of the information we added to that file and we would have to be certain we had the most up-to-date version of the ASCII configuration file. A safer way would be to go back to cmquerycl. We can perform a cmquerycl and produce a new ASCII cluster configuration file. With that we can compare it with our current ASCII configuration file and make any modifications necessary. In fact, to be super-safe we could actually extract from the cluster binary configuration file the ASCII configuration file that relates to it. In this way we are not relying on what might be an old ASCII configuration file. This also has the advantage of being able to perform this step from any node in the cluster. Here goes.
root@hpeos002[cmcluster] # cmgetconf -v -c McBond Current_cluster.ascii
Gathering configuration information .... Done
Warning: The disk at /dev/dsk/c1t2d0 on node hpeos001 does not have an ID, or a disk label.
Warning: Disks which do not have IDs cannot be included in the topology description.
Use pvcreate(1M) to initialize a disk for LVM or,
use vxdiskadm(1M) to initialize a disk for VxVM.
root@hpeos002[cmcluster] #
The warning above relates to a CD-ROM drive, no problem. We can now use cmquerycl to gather information relating to our current nodes and our new node (hpeos003).
root@hpeos002[cmcluster] # cmquerycl -v -c McBond -n hpeos001 -n hpeos002 -n hpeos003 -C New.cluster.ascii
Begin checking the nodes...
Looking for nodes in cluster McBond ... Done
Gathering configuration information ............ Done
Warning: The disk at /dev/dsk/c1t2d0 on node hpeos001 does not have an ID, or a disk label.
Warning: Disks which do not have IDs cannot be included in the topology description.
Use pvcreate(1M) to initialize a disk for LVM or,
use vxdiskadm(1M) to initialize a disk for VxVM.
Warning: Network interface lan2 on node hpeos003 couldn't talk to itself.
Warning: Network interface lan3 on node hpeos003 couldn't talk to itself.
Warning: Network interface lan4 on node hpeos003 couldn't talk to itself.
Node Names: hpeos001
hpeos002
hpeos003
I have abbreviated the output for succinctness. If there are any errors, we need to resolve them before proceeding.
Writing cluster data to New.cluster.ascii. root@hpeos002[cmcluster] #
We can now compare and contrast the file created from the cmgetconf process against the file created by cmquerycl. I have reviewed the content of the file New.cluster.ascii and it looks complete to me. It has included any modifications I made to the file Current_cluster.ascii file, e.g., MAX_CONFIGURED_PACKAGES 10 and any timing parameters. If I do not want to make any further changes I can simply proceed with the New.cluster.ascii file, as it stands. Be careful not to make any changes that require the cluster to be down; check the Cookbook above. Here are the lines that cmquerycl has effectively added to the configuration file for node hpeos003:
NODE_NAME hpeos003
NETWORK_INTERFACE lan0
HEARTBEAT_IP 192.168.0.203
NETWORK_INTERFACE lan1
FIRST_CLUSTER_LOCK_PV /dev/dsk/c4t8d0
# List of serial device file names
# For example:
# SERIAL_DEVICE_FILE /dev/tty0p0
# Possible standby Network Interfaces for lan0: lan1.
I will proceed with adding this new node into the cluster.
root@hpeos002[cmcluster] # cmcheckconf -v -C New.cluster.ascii Checking cluster file: New.cluster.ascii Checking nodes ... Done Checking existing configuration ... Done Gathering configuration information ... Done Gathering configuration information ... Done Gathering configuration information .............. Done Cluster McBond is an existing cluster Checking for inconsistencies .. Done Cluster McBond is an existing cluster Maximum configured packages parameter is 10. Configuring 1 package(s). 9 package(s) can be added to this cluster. Adding configuration to node hpeos003 Modifying configuration on node hpeos001 Modifying configuration on node hpeos002 Modifying the cluster configuration for cluster McBond. Adding node hpeos003 to cluster McBond. Verification completed with no errors found. Use the cmapplyconf command to apply the configuration. root@hpeos002[cmcluster] # root@hpeos002[cmcluster] # cmapplyconf -v -C New.cluster.ascii Checking cluster file: New.cluster.ascii Checking nodes ... Done Checking existing configuration ... Done Gathering configuration information ... Done Gathering configuration information ... Done Gathering configuration information .............. Done Cluster McBond is an existing cluster Checking for inconsistencies .. Done Cluster McBond is an existing cluster Maximum configured packages parameter is 10. Configuring 1 package(s). 9 package(s) can be added to this cluster. Adding configuration to node hpeos003 Modifying configuration on node hpeos001 Modifying configuration on node hpeos002 Modify the cluster configuration ([y]/n)? y Modifying the cluster configuration for cluster McBond. Adding node hpeos003 to cluster McBond. Completed the cluster creation. root@hpeos002[cmcluster] # root@hpeos002[cmcluster] # cmrunnode -v hpeos003 Successfully started $SGLBIN/cmcld on hpeos003. cmrunnode : Waiting for cluster to form..... cmrunnode : Cluster successfully formed. cmrunnode : Check the syslog files on all nodes in the cluster cmrunnode : to verify that no warnings occurred during startup. root@hpeos002[cmcluster] # cmviewcl CLUSTER STATUS McBond up NODE STATUS STATE hpeos001 up running PACKAGE STATUS STATE AUTO_RUN NODE clockwatch up running enabled hpeos001 NODE STATUS STATE hpeos002 up running hpeos003 up running root@hpeos002[cmcluster] #
I would carefully review syslog.log to ensure all is working as expected. To summarize the task of adding a node to a cluster, here's a template for adding/modifying a node in a cluster:
Install Serviceguard on the new node.
Install any related patches on the new node.
Set up on all nodes, the file
/etc/cmcluster/cmclnodelistto include the new node name.Get the most up-to-date ASCII configuration file (
cmgetconf).Query all nodes, including the new node, in the cluster (
cmquerycl).Compare the ASCII files obtained from
cmgetconfandcmquerycl.Update the ASCII configuration file obtained from
cmquerycl.Check the new ASCII configuration file (
cmcheckconf).Compile and distribute the new binary cluster configuration file (
cmapplyconf).Start cluster services on the new node (
cmrunnode).Check for any problems with
cmviewcland the logfile/var/adm/syslog/syslog.log.
Essentially, these are the same steps to modify cluster configuration parameters as well. The only step we need to leave out is the cmquerycl. Make sure that you check with the cookbook to see if the changes you are making require the cluster to be UP or DOWN.
My next task is not to remove a node from the cluster. In my mind, the reason I added node hpeos003 was to perform some useful function. In this case, it is to be a second adoptive node for the clockwatch application. According to the cookbook, I can add a node to a package while the package is running. That's my next task.
In the previous example, I added a node to the cluster to give me an additional adoptive node for the clockwatch application. I will now add that node into the configuration of the clockwatch application. As we see, this follows a similar pattern to the template for adding a node to the cluster:
Ensure that the application binaries are loaded onto the new node, if applicable.
Ensure that any shared disk drives are available to the new node, e.g.,
vgimport, and so on.Get the most up-to-date version of the ASCII configuration file (
cmgetconf).Update the ASCII configuration file.
Distribute the package control script to the new node.
Distribute any application monitoring script(s) to the new node.
Check the ASCII configuration file (
cmcheckconf).Compile and distribute the binary cluster configuration file (
cmapplyconf).Check that the changes have been distributed (
cmviewcl).
Because my application binaries are on the shared disk drives, I will proceed with this checklist with the cmgetconf command.
root@hpeos002[clockwatch] # cmgetconf -v -p clockwatch clockwatch.conf root@hpeos002[clockwatch] # root@hpeos002[clockwatch] # vi clockwatch.conf
The only change I made was to add the line
NODE_NAME hpeos003
to the list of adoptive nodes:
root@hpeos003[vg01] mkdir /etc/cmcluster/clockwatch
Remember to create the appropriate directory on the new node.
root@hpeos002[clockwatch] # rcp -p CLOCKWATCH.sh clockwatch.cntl hpeos003:/etc/cmcluster/clockwatch
Now that we have distributed (okay, so it's not the most secure method) the control script and application monitoring script(s), we can check the ASCII configuration file.
root@hpeos002[clockwatch] # cmcheckconf -v -P clockwatch.conf
Checking existing configuration ... Done
Gathering configuration information ... Done
Parsing package file: clockwatch.conf.
Package clockwatch already exists. It will be modified.
Maximum configured packages parameter is 10.
Configuring 1 package(s).
9 package(s) can be added to this cluster.
Modifying the package configuration for package clockwatch.
Adding node hpeos003 to package clockwatch.
Verification completed with no errors found.
Use the cmapplyconf command to apply the configuration.
root@hpeos002[clockwatch] #
And now to compile distribute the new binary cluster configuration file.
root@hpeos002[clockwatch] # cmapplyconf -v -P clockwatch.conf Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: clockwatch.conf. Package clockwatch already exists. It will be modified. Maximum configured packages parameter is 10. Configuring 1 package(s). 9 package(s) can be added to this cluster. Modify the package configuration ([y]/n)? y Modifying the package configuration for package clockwatch. Adding node hpeos003 to package clockwatch. Completed the cluster update. root@hpeos002[clockwatch] # root@hpeos002[clockwatch] # cmviewcl -v -p clockwatch PACKAGE STATUS STATE AUTO_RUN NODE clockwatch up running enabled hpeos001 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 clock_mon Subnet up 192.168.0.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos001 (current) Alternate up enabled hpeos002 Alternate up enabled hpeos003 root@hpeos002[clockwatch] #
If I were being super-efficient, I would test that node hpeos003 was able to run the application properly. I could disable node hpeos002 from running clockwatch; cmmodpkg –v –d –n hpeos002 clockwatch. And then I could fail the package over using one of the Standard or Stress Tests we saw in Chapter 26. I assume that you are being conscientious and have performed all such tests with the approval of your management and user community.
When we first added a package to our cluster, we used a cookbook approach. I am going to use the same cookbook to add a package to this cluster—a task I can do while the cluster and other packages are running. The package I am going to add uses one of the Serviceguard Toolkits. In this instance, it is for the Oracle Toolkit.
Before we get into actually configuring the new package, I want to point out some differences that I introduce with the configuration of this new package:
FAILOVER_POLICY MIN_PACKAGE_NODE
This failover policy introduces a level of intelligence into the choice of the next adoptive node. Instead of simply using the next node in the list, i.e.,
FAILOVER_POLICY CONFIGURED_NODE,Serviceguard will ascertain how many packages each node is currently running. The next node to run a failed package is the node that is enabled to accept the package and has the least number of packages currently running. Serviceguard makes no judgments other than the number of packages currently running on a node. This type of configuration allows us to implement a Rolling Standby cluster where any node can be the standby for any other node, and the standby is not necessarily the next node in the list. It is a good idea if every node in the cluster is of a similar type and configuration; you don't want a performance-hungry application running on a performance-deficient server, do you?FAILBACK_POLICY AUTOMATIC
This option means that an application will restart on the original node it came from when that node becomes re-enabled to run it, possibly after a critical failure. I would be very careful employing this configuration because it means that as soon as the original node becomes enabled (
cmmodpkg –e –n <nodename> -p <package>), Serviceguard will instigate the process of halting the package on its current node and starting the package back on its original node. I have seen this configuration used where the adoptive nodes were not as powerful as the primary nodes and it was thought right to have the application running back on the most powerful machine as quickly as possible. In the instance I am referring to, the slight interruption to service while this happened was not deemed relevant because the application would poll for anything up to 1 minute waiting for a connection to the application server.
With these two changes in mind, let us proceed by first discussing a Serviceguard Toolkit.
There are quite a number of Serviceguard Toolkits currently available, everything from NFS to Netscape to Oracle, Sybase Progress, Informix, and DB2 to name a few. The primary value of the toolkits is the inclusion of an application monitoring script for each application. This eliminates the need for you to code an application monitoring script from scratch. The monitoring scripts included with the toolkits require minor modifications to customize the script for your application.
I am going to look at the Oracle Toolkit. Once you have installed it, you will find the Enterprise Cluster Master Toolkit files under the directory /opt/cmcluster/toolkit. Here are the files for the current Oracle Toolkit:
root@hpeos001[] # cd /opt/cmcluster/toolkit root@hpeos001[toolkit] # ll total 6 dr-xr-xr-x 3 bin bin 1024 Aug 3 2002 SGOSB dr-xr-xr-x 2 bin bin 96 Aug 3 2002 db2 dr-xr-xr-x 2 bin bin 1024 Aug 3 2002 domain dr-xr-xr-x 2 bin bin 96 Aug 3 2002 fasttrack dr-xr-xr-x 2 bin bin 96 Feb 27 2002 foundation dr-xr-xr-x 2 bin bin 1024 Aug 3 2002 informix dr-xr-xr-x 2 bin bin 96 Aug 3 2002 oracle dr-xr-xr-x 2 bin bin 96 Aug 3 2002 progress dr-xr-xr-x 2 bin bin 96 Aug 3 2002 sybase root@hpeos001[toolkit] # ll oracle total 140 -r-xr-xr-x 1 bin bin 14069 Mar 21 2002 ORACLE.sh -r-xr-xr-x 1 bin bin 17118 Mar 21 2002 ORACLE_7_8.sh -r--r--r-- 1 bin bin 18886 Mar 21 2002 README -r--r--r-- 1 bin bin 19554 Mar 21 2002 README_7_8 root@hpeos001[toolkit] #
The files I am interested in are the ORACLE.sh script and the README file. I have just reviewed them and the ORACLE.sh file told me this:
# *************************************************************************** # * This script supports Oracle 9i only. * # * For Oracle 7 or 8, use the ORACLE_7_8.sh script. * # ***************************************************************************
This seems quite clear to me. I am not running Oracle 9i, so I need to concentrate on the ORACLE_7_8.sh and the README_7_8 file. Essentially, the process is exactly the same and is well documented in the associated README file; you should spend some time reviewing the README file. The ORACLE*.sh file is our application monitoring script. We update this script to reflect the particulars of our Oracle instance, i.e., ORACLE_HOME, SID_NAME, etc. Now, I am no Oracle expert; I worked on this with my Oracle DBA to fill in some of the configuration parameters in this application monitoring script. Once you have that information, you can proceed in much the same way as we did with adding the clockwatch application to the cluster. In fact, if you remember, I based the clockwatch application monitoring script on a Serviceguard Toolkit. Like CLOCKWATCH.sh, ORACLE*.sh has three functions: start, stop, and monitor. Each is triggered by the relevant command line argument. This means that we can use exactly the same procedure as we did to add clockwatch to the cluster:
Table 27-1. Cookbook for Setting Up a Package
✓ | 1. Set up and test a package-less cluster. |
✓ | 2. Understand how a Serviceguard package works. |
✓ | 3. Establish whether you can utilize a Serviceguard Toolkit. |
✓ | 4. Understand the workings of any in-house applications. |
5. Create package monitoring scripts, if necessary. | |
6. Distribute the application monitoring scripts to all relevant nodes in the cluster. | |
7. Create and update an ASCII package configuration file ( | |
8. Create and update an ASCII package control script ( | |
9. Distribute manually to all relevant nodes the ASCII package control script. | |
10. Check the ASCII package control file ( | |
11. Distribute the updated binary cluster configuration file ( | |
12. Ensure that any data files and programs that are to be shared are loaded onto shared disk drives. | |
13. Start the package ( | |
14. Ensure that package switching is enabled. | |
15. Test package failover functionality. |
We start with “Create if necessary a package monitoring script”, item 5 in the cookbook.
This is where we need to work with our Oracle DBA to check the application monitoring script supplied in the Toolkit and configure it according to our needs. Read the associated README file carefully; it details the steps involved in ensuring that the package is configured properly. The Oracle database was already installed, running, and tested; this is important, because we need to know the specifics of what the instance is called and where it is located. Here is what my DBA and I did to set up our application monitoring script:
root@hpeos001[toolkit] # pwd /opt/cmcluster/toolkit root@hpeos001[toolkit] # mkdir /etc/cmcluster/oracle1 root@hpeos001[toolkit] # cp oracle/ORACLE_7_8.sh /etc/cmcluster/oracle1/ORACLE1.sh root@hpeos001[toolkit] # cd /etc/cmcluster/oracle1 root@hpeos001[oracle1] # vi ORACLE1.sh
Here are the lines we updated to reflect the configuration of our Oracle database:
ORA_7_3_X=yes ORA_8_0_X= ORA_8_1_X= SID_NAME=oracle1 ORACLE_HOME=/u01/home/dba/oracle/product/8.1.6 SQLNET=no NET8= LISTENER_NAME= LISTENER_PASS= MONITOR_INTERVAL=10 PACKAGE_NAME=oracle1 TIME_OUT=20 set -A MONITOR_PROCESSES ora_smon_oracle1 ora_pmon_oracle1 ora_lgwr_oracle1
These configuration parameters started on line 130 of the application monitoring script. The application binaries have been installed on each node under the directory /u01. The database itself is stored on a filesystem accessible to all relevant nodes under the directory /ora1. We can now distribute the application monitoring script to all relevant nodes in the cluster.
As in the clockwatch package we need to manually distribute the application monitoring script to all relevant nodes in the cluster. When we say relevant nodes we mean all nodes that are required to run this package. In this case that means all nodes in the cluster.
This step follows the same pattern as in creating the package configuration file for the clockwatch package. It lists the commands executed and list the lines I updated in the configuration file:
root@hpeos001[oracle1] # cmmakepkg -v -p oracle1.conf
Begin generating package template... Done.
Package template is created.
This file must be edited before it can be used.
root@hpeos001[oracle1] # vi oracle1.conf
Here are the lines I updated in the configuration file oracle1.conf:
PACKAGE_NAME oracle1
This is just the package name:
FAILOVER_POLICY MIN_PACKAGE_NODE
The parameter FAILOVER_POLICY controls the level of intelligence we are allowing Serviceguard to use to decide which node to use to run the package should the original node fail. This can override the list of nodes we see below:
FAILBACK_POLICY AUTOMATIC
With AUTOMATIC set for FAILBACK_POLICY, when the original node comes back online, we should see the application move back to its original node:
NODE_NAME hpeos003 NODE_NAME hpeos001 NODE_NAME hpeos002
This is the list of the nodes the package is allowed to run on. Just to reiterate, with FAILBACK_POLICY set to AUTOMATIC, this is not the definitive order of the nodes on which the package will run:
RUN_SCRIPT /etc/cmcluster/oracle1/oracle1.cntl RUN_SCRIPT_TIMEOUT NO_TIMEOUT HALT_SCRIPT /etc/cmcluster/oracle1/oracle1.cntl HALT_SCRIPT_TIMEOUT NO_TIMEOUT
The package control script is created in the next step of this process:
SERVICE_NAME oracle1_mon SERVICE_FAIL_FAST_ENABLED YES SERVICE_HALT_TIMEOUT 300
I have chosen a SERVICE_NAME of oracle1_mon. This is equated to the actual application monitoring script in the package control script:
SUBNET 192.168.0.0
I use the same subnet address as in the clockwatch application and assign an IP address in the package control script. I can now proceed in creating the package control script.
The name I chose for the package control script was oracle1.cntl. This seems to follow the pattern for other applications. Obviously, you can name these files whatever you like. Let's look at my progress:
root@hpeos001[oracle1] # cmmakepkg -v -s oracle1.cntl Begin generating package control script... Done. Package control script is created. This file must be edited before it can be used. root@hpeos001[oracle1] # vi oracle1.cntl
As before, I will list only the configuration parameters that I have updated, not the entire file:
VG[0]="/dev/vgora"
This is the name of the volume group accessible by all nodes in the cluster that contains the data file for this application:
LV[0]="/dev/vgora/ora1"; FS[0]="/ora1"; FS_MOUNT_OPT[0]="-o rw"; FS_UMOUNT_OPT[0]=""; FS_FSCK_OPT[0]="" FS_TYPE[0]="vxfs"
This lists the names of all filesystems to be mounted and is a simplified configuration. I would suspect that in a real-life Oracle installation there would be significantly more filesystems involved:
IP[0]="192.168.0.230" SUBNET[0]="192.168.0.0"
I have allocated another IP address for this application. Remember, clients have to access this application by this new IP address, not the unique server's IP address:
SERVICE_NAME[0]="oracle1_mon" SERVICE_CMD[0]="/etc/cmcluster/oracle1/ORACLE1.sh monitor" SERVICE_RESTART[0]=""
Here, we equate the SERVICE_NAMEs from the package configuration file with SERVICE_CMDs. As you can see, we are running the application monitoring script with the monitor command line argument. It is crucial that we have listed all the application processes correctly within the monitoring script:
function customer_defined_run_cmds
{
# ADD customer defined run commands.
/etc/cmcluster/oracle1/ORACLE1.sh start
test_return 51
}
The customer_defined_run_cmds is where we actually start the application. Note again that it is the application monitoring script that starts the application:
function customer_defined_halt_cmds
{
# ADD customer defined halt commands.
/etc/cmcluster/oracle1/ORACLE1.sh stop
test_return 52
}
The customer_defined_halt_cmds is where we actually stop the application. If you need to be reminded of the order in which these functions are executed, I direct you to Chapter 26, “Configuring Packages in a Serviceguard Cluster.”
That's the only change I made. I can now distribute the package control script to all nodes.
I don't want you to think that I am just repeating myself all the time, but I do need to remind you that the ASCII control script is not distributed by the cmapplyconf command. You need to ensure that it exists on all relevant nodes when it is first created and in some ways more importantly whenever changes are made to it.
At this stage, we find out whether we have forgotten to distribute the package control script(s) to one particular node. We also determine whether our volume group as been configured on all nodes:
root@hpeos001[oracle1] # cmcheckconf -v -k -P oracle1.conf
Checking existing configuration ... Done
Gathering configuration information ... Done
Parsing package file: oracle1.conf.
Attempting to add package oracle1.
Maximum configured packages parameter is 10.
Configuring 2 package(s).
8 package(s) can be added to this cluster.
Adding the package configuration for package oracle1.
Verification completed with no errors found.
Use the cmapplyconf command to apply the configuration.
root@hpeos001[oracle1] #
All looks well, so let us continue.
Now we update and distribute the binary cluster configuration file. Remember, this is all happening with the cluster up and running and other packages running. Also remember that when we add a package, it does not start automatically the first time. We first check that everything is in place and then enable it to run:
root@hpeos001[oracle1] # cmapplyconf -v -k -P oracle1.conf Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: oracle1.conf. Attempting to add package oracle1. Maximum configured packages parameter is 10. Configuring 2 package(s). 8 package(s) can be added to this cluster. Modify the package configuration ([y]/n)? y Adding the package configuration for package oracle1. Completed the cluster update. root@hpeos001[oracle1] # root@hpeos001[oracle1] # cmviewcl -v -p oracle1 UNOWNED_PACKAGES PACKAGE STATUS STATE AUTO_RUN NODE oracle1 down halted disabled unowned Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback automatic Script_Parameters: ITEM STATUS NODE_NAME NAME Subnet up hpeos003 192.168.0.0 Subnet up hpeos001 192.168.0.0 Subnet up hpeos002 192.168.0.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 Alternate up enabled hpeos001 Alternate up enabled hpeos002 root@hpeos001[oracle1] #
Looking at the output from cmviewcl, we can see that the configuration choices we made are now evident; the FAILOVER and FAILBACK policies are in place. Before we start the package, we need to perform an important step. Let's move on and discuss that next step.
You may be saying, “I thought you said earlier the database files had already been loaded onto a volume group accessible by all nodes in the cluster?” This is perfectly true. What we need to ensure here is that the volume group is cluster-aware. In our first package, clockwatch, the volume group used (/dev/vg01) happened to be listed in the ASCII cluster configuration file as a cluster lock volume group. In that instance, cmapplyconf made sure that the volume group was cluster-aware. This is not necessarily the case in subsequent packages and subsequent volume groups. We need to ensure that the flag has been set in the VGDA that allows the Serviceguard daemon cmlvmd to monitor and track which node currently has the volume group active. To accomplish this, we need to execute the following command on one of the nodes attached to the volume group:
root@hpeos003[] vgchange -c y /dev/vgora
Performed Configuration change.
Volume group "/dev/vgora" has been successfully changed.
If we were to now try to activate the volume group in anything other than Exclusive Mode, we should receive an error.
root@hpeos003[] vgchange -a y /dev/vgora
vgchange: Activation mode requested for the volume group "/dev/vgora" conflicts with configured mode.
When performing maintenance on volume groups after a package has been accessed, e.g., adding logical volumes to a volume group, we must remember this. In those situations, we would need to do the following:
Halt the package.
Activate the volume group and then do either of the following:
In exclusive mode on one node (
vgchange –a e <VG>)Perform maintenance
Deactivate the volume group (
vgchange –a n <VG>)Or:
Temporarily activate the volume group in Non-Exclusive Mode:
Remove the cluster aware flag (
vgchange –c n <VG>).Activate the volume group (
vgchange –a y <VG>).Perform maintenance.
Deactivate the volume group (
vgchange –a n <VG>).Reapply the cluster-aware flag (
vgchange –c y <VG>).
Update and distribute the package control script.
Restart the package.
We have performed this task and can now consider starting the package.
Reviewing the output from cmviewcl, we can see that all nodes are enabled to receive the package. All we need to do is to enable AUTO_RUN, and the package will run on the most suitable node. In this instance, I expect it to run on node hpeos003 because it currently has no packages running on it and it is first on the list. Let's see what happens:
root@hpeos001[oracle1] # cmmodpkg -v -e oracle1 Enabling switching for package oracle1. cmmodpkg : Successfully enabled package oracle1. cmmodpkg : Completed successfully on all packages specified. root@hpeos001[oracle1] # root@hpeos001[oracle1] # cmviewcl -v -p oracle1 PACKAGE STATUS STATE AUTO_RUN NODE oracle1 up running enabled hpeos003 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback automatic Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 oracle1_mon Subnet up 192.168.0.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 (current) Alternate up enabled hpeos001 Alternate up enabled hpeos002 root@hpeos001[oracle1] #
As we can see, oracle1 is up and running on node hpeos003. If we look at the package logfile (/etc/cmcluster/oracle1/oracle1.cntl.log) from that node, we should see the package startup process in all its glory.
root@hpeos003[oracle1] more oracle1.cntl.log
########### Node "hpeos003": Starting package at Mon Aug 11 15:05:19 BST 2003 ###########
Aug 11 15:05:19 - "hpeos003": Activating volume group /dev/vgora with exclusive option.
Activated volume group in Exclusive Mode.
Volume group "/dev/vgora" has been successfully changed.
Aug 11 15:05:19 - Node "hpeos003": Checking filesystems:
/dev/vgora/ora1
/dev/vgora/rora1:file system is clean - log replay is not required
Aug 11 15:05:19 - Node "hpeos003": Mounting /dev/vgora/ora1 at /ora1
Aug 11 15:05:19 - Node "hpeos003": Adding IP address 192.168.0.230 to subnet 192.168.0.0
*** /etc/cmcluster/oracle1/ORACLE1.sh called with start argument. ***
"hpeos003": Starting Oracle SESSION oracle1 at Mon Aug 11 15:05:19 BST 2003
Oracle Server Manager Release 3.1.6.0.0 - Production
Copyright (c) 1997, 1999, Oracle Corporation. All Rights Reserved.
Oracle8i Release 8.1.6.0.0 - Production
JServer Release 8.1.6.0.0 - Production
SVRMGR> Connected.
SVRMGR> ORACLE instance started.
Total System Global Area 25004888 bytes
Fixed Size 72536 bytes
Variable Size 24649728 bytes
Database Buffers 204800 bytes
Redo Buffers 77824 bytes
Database mounted.
Database opened.
SVRMGR> Server Manager complete.
Oracle startup done.
Aug 11 15:05:24 - Node "hpeos003": Starting service oracle1_mon using
"/etc/cmcluster/oracle1/ORACLE1.sh monitor"
*** /etc/cmcluster/oracle1/ORACLE1.sh called with monitor argument. ***
########### Node "hpeos003": Package start completed at Mon Aug 11 15:05:25 BST 2003 ###########
Monitored process = ora_smon_oracle1, pid = 4786
Monitored process = ora_pmon_oracle1, pid = 4778
Monitored process = ora_lgwr_oracle1, pid = 4782
root@hpeos003[oracle1]
I am no Oracle expert, but this looks okay to me. The next stage before putting this package into a production environment would be to test package failover.
This should already have been accomplished because we started the package by enabling package switching (cmmodpkg –e oracle1). We can quickly check it with cmviewcl:
root@hpeos003[oracle1] cmviewcl -v -p oracle1
PACKAGE STATUS STATE AUTO_RUN NODE
oracle1 up running enabled hpeos003
Policy_Parameters:
POLICY_NAME CONFIGURED_VALUE
Failover min_package_node
Failback automatic
Script_Parameters:
ITEM STATUS MAX_RESTARTS RESTARTS NAME
Service up 0 0 oracle1_mon
Subnet up 192.168.0.0
Node_Switching_Parameters:
NODE_TYPE STATUS SWITCHING NAME
Primary up enabled hpeos003 (current)
Alternate up enabled hpeos001
Alternate up enabled hpeos002
root@hpeos003[oracle1]
We are now ready to move on to the final step in this cookbook, and that is to test package failover.
I am going to perform two tests:
Kill a critical application process.
This should fail the package over to the most suitable node in the cluster.
Re-enable the original node to receive the package.
The package should move it back to its original node automatically.
Let's take a quick review of the status of current packages:
root@hpeos003[oracle1] cmviewcl
CLUSTER STATUS
McBond up
NODE STATUS STATE
hpeos001 up running
PACKAGE STATUS STATE AUTO_RUN NODE
clockwatch up running enabled hpeos001
NODE STATUS STATE
hpeos002 up running
hpeos003 up running
PACKAGE STATUS STATE AUTO_RUN NODE
oracle1 up running enabled hpeos003
root@hpeos003[oracle1]
So oracle1 is running on node hpeos003 and clockwatch is running on node hpeos001. If oracle1 were to fail, which node would it move to?
root@hpeos003[oracle1] cmviewcl -v -p oracle1
PACKAGE STATUS STATE AUTO_RUN NODE
oracle1 up running enabled hpeos003
Policy_Parameters:
POLICY_NAME CONFIGURED_VALUE
Failover min_package_node
Failback automatic
Script_Parameters:
ITEM STATUS MAX_RESTARTS RESTARTS NAME
Service up 0 0 oracle1_mon
Subnet up 192.168.0.0
Node_Switching_Parameters:
NODE_TYPE STATUS SWITCHING NAME
Primary up enabled hpeos003 (current)
Alternate up enabled hpeos001
Alternate up enabled hpeos002
root@hpeos003[oracle1]
If I interoperate this output correctly, then oracle1 should fail over to node hpeos002 because it is the node with the least number of packages running on it, even though node hpeos001 is listed before it in the output from cmviewcl –v –p oracle1 above. Remember, that level of intelligence is coming from Serviceguard via the package configuration parameter FAILOVER_POLICY being set to MIN_PACKAGE_NODE. Let's put that theory to the test.
Kill a critical application process.
Let's kill one of the Oracle daemons. This will test the application monitoring script as well as test the working of the
FAILOVER_POLICY:root@hpeos003[oracle1] tail oracle1.cntl.log Aug 11 15:05:24 - Node "hpeos003": Starting service oracle1_mon using "/etc/cmcluster/oracle1/ORACLE1.sh monitor" *** /etc/cmcluster/oracle1/ORACLE1.sh called with monitor argument. *** ########### Node "hpeos003": Package start completed at Mon Aug 11 15:05:25 BST 2003 ########### Monitored process = ora_smon_oracle1, pid = 4786 Monitored process = ora_pmon_oracle1, pid = 4778 Monitored process = ora_lgwr_oracle1, pid = 4782 root@hpeos003[oracle1] root@hpeos003[oracle1] ps -fp 4786 UID PID PPID C STIME TTY TIME COMMAND oracle 4786 1 0 15:05:20 ? 0:00 ora_smon_oracle1 root@hpeos003[oracle1] root@hpeos003[oracle1] kill 4786
This fatal problem in the application should be picked up by the application monitoring script, and the package should move to node
hpeos002:root@hpeos003[oracle1] cmviewcl -v -p oracle1 PACKAGE STATUS STATE AUTO_RUN NODE oracle1 up running enabled hpeos002 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback automatic Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 oracle1_mon Subnet up 192.168.0.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up disabled hpeos003 Alternate up enabled hpeos001 Alternate up enabled hpeos002 (current) root@hpeos003[oracle1]As predicted, the
FAILOVER_POLICYhas meant that Serviceguard has moved the package to the most suitable node in the cluster. From a user's perspective, they will not care because they can still access the application using the application IP address:C:Work>ping 192.168.0.230 Pinging 192.168.0.230 with 32 bytes of data: Reply from 192.168.0.230: bytes=32 time<1ms TTL=255 Reply from 192.168.0.230: bytes=32 time<1ms TTL=255 Reply from 192.168.0.230: bytes=32 time<1ms TTL=255 Reply from 192.168.0.230: bytes=32 time<1ms TTL=255 Ping statistics for 192.168.0.230: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 0ms, Maximum = 0ms, Average = 0ms C:Work>arp -a Interface: 192.168.0.1 --- 0x2 Internet Address Physical Address Type 192.168.0.202 08-00-09-c2-69-c6 dynamic 192.168.0.230 08-00-09-c2-69-c6 dynamic C:Work>
As we can see, the MAC address associated with the application IP address (
192.168.0.230) is the same MAC Address as for nodehpeos002. This is of no consequence to the user; he or she is unaware of the slight delay in getting a connection from the application while the package moves to its adoptive node. In this case, the delay was only 10 seconds:########### Node "hpeos003": Package halt completed at Sat Aug 9 17:15:36 BST 2003 ########### ########### Node "hpeos002": Package start completed at Sat Aug 9 17:15:46 BST 2003 ###########
The next test we are going to undertake is seeing the impact of re-enabling the original node
hpeos003.Re-enable the original node to receive the package.
The package configuration parameter
FAILBACK_POLICYhas been set toAUTOMATIC. This should mean that when nodehpeos003becomes enabled to receive the package, Serviceguard should start the process of halting the package on its current node (hpeos002) and starting it on node (hpeos003). As mentioned previously, use of this option should take into consideration the fact that thisAUTOMATICmovement of a package will cause a slight interruption in the availability of the application. Let's conduct the test and see what happens:root@hpeos001[oracle1] # cmmodpkg -v -e -n hpeos003 oracle1 Enabling node hpeos003 for switching of package oracle1. cmmodpkg : Successfully enabled package oracle1 to run on node hpeos003. cmmodpkg : Completed successfully on all packages specified.
This will enable node hpeos003 to receive the package. Serviceguard should now move the package back to this node.
root@hpeos001[oracle1] # cmviewcl -v -p oracle1
PACKAGE STATUS STATE AUTO_RUN NODE
oracle1 up running enabled hpeos003
Policy_Parameters:
POLICY_NAME CONFIGURED_VALUE
Failover min_package_node
Failback automatic
Script_Parameters:
ITEM STATUS MAX_RESTARTS RESTARTS NAME
Service up 0 0 oracle1_mon
Subnet up 192.168.0.0
Node_Switching_Parameters:
NODE_TYPE STATUS SWITCHING NAME
Primary up enabled hpeos003 (current)
Alternate up enabled hpeos001
Alternate up enabled hpeos002
root@hpeos001[oracle1] #
As predicted the package is now back on node hpeos003.
I would not consider these tests to be sufficient in order to put this package into a production environment. I would thoroughly test the two-way failover and failback of the package from all nodes in the cluster. I would review both the Standard and Stress Tests undertaken for the package clockwatch. You need to be confident that your package will perform as expected in all situations within the cluster. I leave you to perform the remainder of those tests.
As we have seen, a Serviceguard Toolkit makes setting up packages much easier than having to write your own application monitoring scripts. It is important that you spend time reading the associated README file as well as fine-tuning the monitoring script itself. The only Toolkit that is slightly different is the Toolkit for Highly Available NFS. As the name implies, the package deals with exporting a number of NFS filesystems from a server. Being a Serviceguard package, this means that the exported filesystems will be filesystems accessible by all relevant nodes in the cluster. Serviceguard will mount and then export these filesystems as part of starting up the package. Users will access their NFS filesystems via the package name/IP address instead of the server name/IP address. Here are the files supplied with this Toolkit:
root@hpeos003[nfs] pwd /opt/cmcluster/nfs root@hpeos003[nfs] ll total 158 -rwxr-xr-x 1 bin bin 12740 Sep 20 2001 hanfs.sh -rwxr-xr-x 1 bin bin 36445 Sep 12 2001 nfs.cntl -rwxr-xr-x 1 bin bin 12469 Sep 12 2001 nfs.conf -rwxr-xr-x 1 bin bin 13345 Sep 12 2001 nfs.mon -rwxr-xr-x 1 bin bin 2111 Sep 12 2001 nfs_xmnt root@hpeos003[nfs]
As you can see, you are supplied with the package configuration and control scripts. This is because instead of specifying a SERVICE_NAME in the package control script, we specify an NFS_SERVICE_NAME. You see this later. This means that we don't perform the cmmakepkg –p or cmmakepkg –s steps. Essentially, the steps to configure such a package are the same as any other package. First, copy the entire contents of the directory /opt/cmcluster/nfs to /etc/cmcluster. Obviously, you would need to perform the preliminary steps for setting up a package as we did for all other packages, e.g., ensure that shared files are accessible to all relevant nodes, and so on. The modifications I would make to the supplied Toolkit files include:
Update the package configuration file. The updates listed below are for illustrative purposes only:
# vi nfs.conf PACKAGE_NAME nfs NODE_NAME node1 NODE_NAME node2 RUN_SCRIPT /etc/cmcluster/nfs/nfs.cntl HALT_SCRIPT /etc/cmcluster/nfs/nfs.cntl SERVICE_NAME nfs_service SUBNET 192.168.0.0 (or whatever is relevant)
Update the package control script. The updates listed below are for illustrative purposes only:
# vi nfs.cntl VG[0]=/dev/vg02 LV[0]=/dev/vg02/NFSvol1 LV[0]=/dev/vg02/NFSvol2 FS[0]=/manuals FS[1]=/docs IP[0]=192.168.0.240 (or whatever is relevant) SUBNET[0]=192.168.0.0
Prior to Serviceguard version 11.14, you would have to update the package control script with the following lines as well:
XFS[0]="/manuals" XFS[1]="/docs" NFS_SERVICE_NAME[0]="nfs_service" NFS_SERVICE_CMD[0]="/etc/cmcluster/nfs/nfs.mon" NFS_SERVICE_RESTART[0]="-r 0"
As of Serviceguard version 11.14, these last updates are handled by the additional script
hanfs.sh.Update the script
hanfs.sh, if appropriate. This script is new for Serviceguard version 11.14. This script lists the exported filesystems and theNFS_SERVICE_NAME. The updates listed below are for illustrative purposes only:XFS[0]="/manuals" XFS[1]="/docs" NFS_SERVICE_NAME[0]="nfs_service" NFS_SERVICE_CMD[0]="/etc/cmcluster/nfs/nfs.mon" NFS_SERVICE_RESTART[0]="-r 0"
The supplied script
nfs.monneeds no updating because it is simply monitoring all the relevant NFS daemons.We would continue with adding a package as before:
Distribute control and monitoring scripts to all nodes.
Check the package configuration file (
cmcheckconf).Update the cluster binary file (
cmapplyconf).Start the package (
cmmodpkgorcmrunpkg).Test that the package works as expected.
We now continue our discussions regarding managing a cluster by looking at updating an existing package by adding EMS resource monitoring.
A generalized template to update a package can be summarized as follows:
If necessary, shut down the package(s).
If necessary, shut down the cluster.
Get the most up-to-date version of the package ASCII configuration file (
cmgetconf).Update the package ASCII configuration file.
Update and distribute the package control script, if necessary.
Update and distribute the application monitoring script(s), if necessary.
Check the package ASCII configuration file (
cmcheckconf).Compile and distribute the binary cluster configuration file (
cmapplyconf).Start the cluster, if necessary.
Start the package(s), if necessary.
Check the status of the package(s) and the cluster (
cmviewcl).Test the changes made.
We are looking at adding EMS resource monitoring to one of our packages. The Event Monitoring Service (EMS) is a system that allows machines to monitor the state and status of a number of local resources. EMS utilizes the SNMP protocol (via the snmpd daemon) whereby each machine maintains a list of applications or resources that it is monitoring; this list is known as a MIB (Management Information Base) structure. This structure is populated with many resources, anything from the status of hardware components to the available space in a filesystem to system performance metrics. EMS has a number of daemons associated with these different resources. As of Serviceguard version 10.10, a package can be made dependent on an MIB variable, i.e., if the state of a hardware or software component falls below a critical threshold, the application will deemed to have failed, whereby Serviceguard will move the package to an adoptive node. The use of EMS resources is becoming more popular as more hardware suppliers are updating EMS monitors for their components. If we review our cookbook for managing a cluster, we will see that adding an EMS resource to a package requires the cluster to be down. The reason for this is that the cmcld daemon needs to register its intent to monitor a resource via the relevant EMS daemons during its initialization.
The MIB structure utilized by the snmpd daemon is a tree-like structure similar to a UNIX filesystem. It has a root (/), and to navigate this structure, we use the command resls. Here are a couple of examples of traversing this structure using resls:
root@hpeos001[] # resls / Contacting Registrar on hpeos001 NAME: / DESCRIPTION: This is the top level of the Resource Dictionary TYPE: / is a Resource Class. There are 7 resources configured below /: Resource Class /system /StorageAreaNetwork /adapters /connectivity /cluster /storage /net root@hpeos001[] # resls /system Contacting Registrar on hpeos001 NAME: /system DESCRIPTION: System Resources TYPE: /system is a Resource Class. There are 8 resources configured below /system: Resource Class /system/jobQueue1Min /system/kernel_resource /system/numUsers /system/jobQueue5Min /system/filesystem /system/events /system/jobQueue15Min /system/status root@hpeos001[] #
We look at configuring EMS in Chapter 10, “Monitoring System Resources.” In that chapter, we see that EMS can be configured to send EMS traps to entities such as OpenView Network Node Manager management stations. In this instance, the trap will be relayed to the cmcld daemon, which will detect that the resource has breached a threshold and fail the associated package. If you spend some time traversing the MIB structure, you might come across some interesting resources that you could monitor which may relate to your applications. For example, if your application uses disk space under the /var filesystem, you could monitor the resource /system/filesystem/availMb:
root@hpeos002[] # resls /system/filesystem/availMb
Contacting Registrar on hpeos002
NAME: /system/filesystem/availMb
DESCRIPTION: The amount of free space in the file system in megabytes.
TYPE: /system/filesystem/availMb is a Resource Class.
There are 7 resources configured below /system/filesystem/availMb:
Resource Class
/system/filesystem/availMb/home
/system/filesystem/availMb/opt
/system/filesystem/availMb/root
/system/filesystem/availMb/stand
/system/filesystem/availMb/tmp
/system/filesystem/availMb/usr
/system/filesystem/availMb/var
root@hpeos002[] #
Another valid resource could be the percentage of shared memory identifiers currently being used (kernel parameter = shmmni). Many RDBMS applications use shared memory segments, and if we run out of shared memory identifiers, the application will be returned an ENOMEM error by the kernel. How it deals with this is application-dependent; it may cause the application to fail. It may be more acceptable to move the application to an adoptive node before we reach the time when there are no shared memory identifiers left; we can set a threshold that will trigger Serviceguard to move our package to an adoptive node.
Here's the output from resls for this resource:
root@hpeos001[] resls /system/kernel_resource/system_v_ipc/shared_memory/shmmni
Contacting Registrar on hpeos001
NAME: /system/kernel_resource/system_v_ipc/shared_memory/shmmni
DESCRIPTION: Percentage of shared memory ID consumption.
TYPE: /system/kernel_resource/system_v_ipc/shared_memory/shmmni is a Resource Instance
whose values are 64-bit floating point values.
There are no active monitor requests reported for this resource.
root@hpeos001[]
We add this resource into one of our applications; it does not matter which one we choose, because we have to halt both of them in order to halt the cluster. I choose the clockwatch application to update. Looking at the template at the beginning of this section, I need to halt both the clockwatch and oracle1 packages before updating clockwatch to include my EMS resource. Here's the output from this process:
If necessary, shut down the package(s).
root@hpeos002[] # cmhaltpkg -v oracle1 Halting package oracle1. cmhaltpkg : Successfully halted package oracle1. cmhaltpkg : Completed successfully on all packages specified. root@hpeos002[] # cmhaltpkg -v clockwatch Halting package clockwatch. cmhaltpkg : Successfully halted package clockwatch. cmhaltpkg : Completed successfully on all packages specified.
If necessary, shut down the cluster.
root@hpeos002[] # cmhaltcl -v Disabling package switching to all nodes being halted. Disabling all packages from running on hpeos001. Disabling all packages from running on hpeos002. Disabling all packages from running on hpeos003. Warning: Do not modify or enable packages until the halt operation is completed. This operation may take some time. Halting cluster services on node hpeos001. Halting cluster services on node hpeos003. Halting cluster services on node hpeos002. .. Successfully halted all nodes specified. Halt operation complete. root@hpeos002[] #Get the most up-to-date version of the package ASCII configuration file (
cmgetconf).root@hpeos001[clockwatch] # cmgetconf -v -p clockwatch clockwatch.curr root@hpeos001[clockwatch] # ll total 244 -rwxr-x--- 1 root sys 1865 Aug 9 08:31 CLOCKWATCH.sh -rwxr-x--- 1 root sys 51467 Aug 9 08:32 clockwatch.cntl -rw-rw-rw- 1 root root 35649 Aug 9 20:51 clockwatch.cntl.log -rwxr-x--- 1 root sys 12733 Aug 9 01:03 clockwatch.conf -rw-rw-rw- 1 root sys 12701 Aug 9 20:56 clockwatch.curr root@hpeos001[clockwatch] # root@hpeos001[clockwatch] # vi clockwatch.curr
Update the package ASCII configuration file.
Here are the lines I added at the end of the package ASCII configuration file for the resource in question:
RESOURCE_NAME /system/kernel_resource/system_v_ipc/shared_memory/s hmmni
This is the full pathname to the resource in question.
RESOURCE_POLLING_INTERVAL 30
By default, EMS will monitor the resource every 60 seconds. Here, I am specifying a polling interval of every 30 seconds.
RESOURCE_START AUTOMATIC
If you are monitoring resources after the application is started up, e.g., filesystem space of shared filesystems, the
RESOURCE_STARTneeds to be set toDEFERRED. (This also requires a change to the application control script) In this case, we can start monitoring the resource before the application starts up.RESOURCE_UP_VALUE < 75
The
RESOURCE_UP_VALUEis setting the threshold for my resource. In this case, the resource is UP while its value is less than 75 percent. If 75 percent or more of the available shared memory identifiers get used up, this resource will be deemed DOWN, causing Serviceguard to move the package to an adoptive node. In this way, I am trying to preempt a failure by monitoring this critical system resource.Update and distribute the package control script, if necessary.
In this instance, this is not necessary.
Update and distribute the application monitoring script(s), if necessary.
In this instance, this is not necessary.
Check the package ASCII configuration file (cmcheckconf).
root@hpeos001[clockwatch] # cmcheckconf -v -k -P clockwatch.curr Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: clockwatch.curr. Package clockwatch already exists. It will be modified. Maximum configured packages parameter is 10. Configuring 2 package(s). 8 package(s) can be added to this cluster. Modifying the package configuration for package clockwatch. Adding resource ID 1 to package configuration. Verification completed with no errors found. Use the cmapplyconf command to apply the configuration. root@hpeos001[clockwatch] #Compile and distribute the binary cluster configuration file (cmapplyconf).
root@hpeos001[clockwatch] # cmapplyconf -v -k -P clockwatch.curr Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: clockwatch.curr. Package clockwatch already exists. It will be modified. Maximum configured packages parameter is 10. Configuring 2 package(s). 8 package(s) can be added to this cluster. Modify the package configuration ([y]/n)? y Modifying the package configuration for package clockwatch. Adding resource ID 1 to package configuration. Completed the cluster update. root@hpeos001[clockwatch] #
Start the cluster, if necessary.
This is necessary in this case.
root@hpeos001[clockwatch] # cmruncl -v Successfully started $SGLBIN/cmcld on hpeos003. Successfully started $SGLBIN/cmcld on hpeos001. Successfully started $SGLBIN/cmcld on hpeos002. cmruncl : Waiting for cluster to form...... cmruncl : Cluster successfully formed. cmruncl : Check the syslog files on all nodes in the cluster cmruncl : to verify that no warnings occurred during startup. root@hpeos001[clockwatch] #Start the package(s), if necessary.
In our case,
AUTO_RUNis enabled for theclockwatchpackage so it should start once the cluster is started.Check the status of the package(s) and the cluster (cmviewcl).
root@hpeos001[clockwatch] # cmviewcl -v -p clockwatch PACKAGE STATUS STATE AUTO_RUN NODE clockwatch up running enabled hpeos001 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 clock_mon Subnet up 192.168.0.0 Resource up /system/kernel_resource/system_v_ipc/shared_memory/shmmni Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos001 (current) Alternate up enabled hpeos002 Alternate up enabled hpeos003 root@hpeos001[clockwatch] #Test the changes made.
With the resource we are looking at, we would have to wait until our application opened more and more shared memory segments. To breach 75 percent, my application would have to create +150 shared memory segments, e.g., 75 percent of the kernel parameter
shmmni:root@hpeos001[clockwatch] # kmtune -q shmmni Parameter Current Dyn Planned Module Version ============================================================================= shmmni 200 - 200 root@hpeos001[clockwatch] #
As you can imagine, this may take some time. I decided to write a little program that spawns a child process that grabs and uses a 512KB shared memory segment (the program is called grabSHMEM and you can find the source code in Appendix B). This continues every 2 seconds until the resource is used up. Obviously, we wouldn't try this on a live production system, but it is of value to ensure that EMS is monitoring our resources properly. If you are going to try such a test, before you conduct the test please either:
Get the permission of a responsible adult.

Use a safety net.
The program grabSHMEM produces a line of output every time it is attached to a shared memory segment. If we kill the parent process (with signal INT, QUIT, or TERM), all the children will detach and remove their shared memory segment. If you use any other signal, e.g., kill –9 on the parent, you will leave lots of shared memory segments still in use on your system; see ipcrm for details. Because it can take a few minutes to use up all the shared memory identifiers, I list only a section of the output from grabSHMEM:
root@hpeos001[charlesk] # ll grabSHMEM.c -rw-rw-r-- 1 root sys 1547 Aug 9 23:05 grabSHMEM.c root@hpeos001[charlesk] # make grabSHMEM cc -O grabSHMEM.c -o grabSHMEM (Bundled) cc: warning 480: The -O option is available only with the C/ANSI C product; ignored. root@hpeos001[charlesk] # ./grabSHMEM & [1] 3506 root@hpeos001[charlesk] # Attached to SHMEM ID = 31206 Attached to SHMEM ID = 807 Attached to SHMEM ID = 408 Attached to SHMEM ID = 409 Attached to SHMEM ID = 410 Attached to SHMEM ID = 411
We can monitor the usage of shared memory segments with the command:
root@hpeos001[] # ipcs -mbop
IPC status from /dev/kmem as of Sun Aug 10 03:04:29 2003
T ID KEY MODE OWNER GROUP NATTCH SEGSZ CPID LPID
Shared Memory:
m 0 0x411c05c4 --rw-rw-rw- root root 0 348 420 420
m 1 0x4e0c0002 --rw-rw-rw- root root 1 61760 420 420
m 2 0x41200888 --rw-rw-rw- root root 1 8192 420 432
m 3 0x301c3e60 --rw-rw-rw- root root 3 1048576 957 971
m 4 0x501c7c07 --r--r--r-- root other 1 1075095 1023 1023
m 5 0x00000000 --rw------- root root 2 65536 1308 1308
m 31206 0x00000000 --rw-rw-rw- root sys 1 524288 3507 3507
m 807 0x00000000 --rw-rw-rw- root sys 1 524288 3513 3513
m 408 0x00000000 --rw-rw-rw- root sys 1 524288 3514 3514
m 409 0x00000000 --rw-rw-rw- root sys 1 524288 3515 3515
m 410 0x00000000 --rw-rw-rw- root sys 1 524288 3516 3516
m 411 0x00000000 --rw-rw-rw- root sys 1 524288 3517 3517
We can monitor the number of shared memory segments in use by using the command:
root@hpeos001[] # ipcs -mbop | tail +4 | wc -l
136
As you can see, we are nearly at a point where the EMS resource will reach its DOWN state (it took a few minutes to get to this point). We should then see the clockwatch package move to its adoptive node, in this case, hpeos002. We can monitor this via cmviewcl and also syslog.log. Here is some of the output I received in syslog.log:
Aug 10 03:15:55 hpeos001 cmcld: Resource /system/kernel_resource/system_v_ipc/shared_memory/shmmni in package clockwatch does not meet RESOURCE_UP_VALUE. Aug 10 03:15:55 hpeos001 cmcld: Executing '/etc/cmcluster/clockwatch/clockwatch.cntl stop' for package clockwatch, as service PKG*62977. Aug 10 03:16:00 hpeos001 CM-clockwatch[4198]: cmhaltserv clock_mon Aug 10 03:16:02 hpeos001 CM-clockwatch[4205]: cmmodnet -r -i 192.168.0.220 192.168.0.0 Aug 10 03:16:02 hpeos001 cmcld: Service PKG*62977 terminated due to an exit(0). Aug 10 03:16:02 hpeos001 cmcld: Halted package clockwatch on node hpeos001. Aug 10 03:16:02 hpeos001 cmcld: Resource /system/kernel_resource/system_v_ipc/sh ared_memory/shmmni does not meet package RESOURCE_UP_VALUE for package clockwatch. Aug 10 03:16:02 hpeos001 cmcld: Package clockwatch cannot run on this node. Aug 10 03:16:07 hpeos001 cmcld: (hpeos002) Started package clockwatch on node hpeos002.
As you can see, node hpeos001 did not have the resources to continue running this application. As a result clockwatch was moved to its adoptive node (hpeos002). Here's the output from cmviewcl:
root@hpeos001[charlesk] # cmviewcl -v -p clockwatch
PACKAGE STATUS STATE AUTO_RUN NODE
clockwatch up running enabled hpeos002
Policy_Parameters:
POLICY_NAME CONFIGURED_VALUE
Failover configured_node
Failback manual
Script_Parameters:
ITEM STATUS MAX_RESTARTS RESTARTS NAME
Service up 0 0 clock_mon
Subnet up 192.168.0.0
Resource up /system/kernel_resource/system_v_ipc/shared_memory/shmmni
Node_Switching_Parameters:
NODE_TYPE STATUS SWITCHING NAME
Primary up enabled hpeos001
Alternate up enabled hpeos002 (current)
Alternate up enabled hpeos003
root@hpeos001[charlesk] #
Notice that node hpeos001 is still enabled to run the application even though the EMS resource effectively failed the application. I would want to investigate this further and determine what has happened to all my shared memory segments. In this test scenario, my program grabSHMEM is still running and has consumed all the available shared memory segments:
root@hpeos001[clockwatch] # ipcs -mbop | tail +4 | wc -l
200
I am also getting errors from the program itself:
NO shmem left: No space left on device
When I killed the parent background process, I got lots of messages of the form:
Received signal 15 Letting go of shmseg = 448 Received signal 15 Letting go of shmseg = 61 Received signal 15 Letting go of shmseg = 62 Received signal 15 Letting go of shmseg = 627 Received signal 15 Letting go of shmseg = 231 Received signal 15 Letting go of shmseg = 233
This tells me that the shared memory segments have been released back to the system. I checked this with the following command:
root@hpeos001[clockwatch] # ipcs –mbop
IPC status from /dev/kmem as of Sun Aug 10 03:28:44 2003
T ID KEY MODE OWNER GROUP NATTCH SEGSZ CPID LPID
Shared Memory:
m 0 0x411c05c4 --rw-rw-rw- root root 0 348 420 420
m 1 0x4e0c0002 --rw-rw-rw- root root 1 61760 420 420
m 2 0x41200888 --rw-rw-rw- root root 1 8192 420 432
m 3 0x301c3e60 --rw-rw-rw- root root 3 1048576 957 971
m 4 0x501c7c07 --r--r--r-- root other 1 1075095 1023 1023
m 5 0x00000000 --rw------- root root 2 65536 1308 1308
root@hpeos001[clockwatch] #
This showed me that all was back to normal. If you are going to conduct such a test, please ensure that your system returns to a normal state before proceeding.
When we delete a package from the cluster, that application will no longer be under the control of Serviceguard. I think that is obvious. I hope it's obvious that to perform this task, the package must be DOWN. There is no need to shut down the entire cluster. The actual process is relatively straightforward so I will go through the process straight away:
root@hpeos002[] # cmhaltpkg -v oracle1
Halting package oracle1.
cmhaltpkg : Successfully halted package oracle1.
cmhaltpkg : Completed successfully on all packages specified.
root@hpeos002[] #
root@hpeos002[] # cmdeleteconf -v -p oracle1 Modify the package configuration ([y]/n)? y Completed the package deletion. root@hpeos002[] #
Here's an extract from my /var/adm/syslog/syslog.log file after deleting the oracle1 package:
Aug 10 07:36:27 hpeos002 CM-CMD[10468]: cmdeleteconf -v -p oracle1 Aug 10 07:36:30 hpeos002 cmclconfd[10470]: Updated file /etc/cmcluster/cmclconfig.tmp for node hpeos002 (length = 32960). Aug 10 07:36:31 hpeos002 cmclconfd[10470]: Updated file /etc/cmcluster/cmclconfig.tmp for node hpeos002 (length = 0). Aug 10 07:36:31 hpeos002 cmcld: Online Config - Successfully deleted package oracle1 with id 24322. Aug 10 07:36:31 hpeos002 cmclconfd[3618]: Updated file /etc/cmcluster/cmclconfig for node hpeos002 (length = 13704). Aug 10 07:36:32 hpeos002 cmclconfd[10470]: Deleted package configuration for package oracle1. (2-0-0-1-0-0-0-0-0-0-0-0)
The reason I am reviewing remaining cluster activity is to ensure that I didn't accidentally remove the wrong package. I want to ensure that all my other packages are intact and functioning as normal:
root@hpeos002[] # cmviewcl
CLUSTER STATUS
McBond up
NODE STATUS STATE
hpeos001 up running
PACKAGE STATUS STATE AUTO_RUN NODE
clockwatch up running enabled hpeos001
NODE STATUS STATE
hpeos002 up running
hpeos003 up running
root@hpeos002[] #
The package configuration files are still located in the directory /etc/cmcluster/oracle1, so if you wish to add the package back into the cluster at a later date, the old configuration files can make a basis for your new configuration. I suppose that if the application were to run outside of the control of Serviceguard, we would ensure that all application files were still intact and consider not sharing files between multiple nodes. Otherwise, that's it.
Although the process of deleting a node from a cluster is relatively straightforward, the consequences of changing the number of nodes in your cluster may have implications regarding the configuration of your cluster. For example, if you were to go from a three-node to a two-node cluster, you would have to realize one of the limitations of a two-node cluster: the necessity to have a cluster lock configured (either a cluster lock disk or a Quorum Server). If such changes are required as a consequence of removing a node from the cluster, we have to review the cookbook at the beginning of this chapter where we would realize that modifying the cluster lock configuration requires the cluster to be halted. As well as removing the node from the cluster configuration, we have to consider whether any packages need modifying; it doesn't make sense to have a node listed as an adoptive node when that node no longer exists in the cluster. Before updating the cluster configuration, we need to update the configuration of any affected packages. With no further ado, let's remove node hpeos003 from our cluster. The following sections detail the process I followed.
root@hpeos002[] # cmviewcl -v -n hpeos003
NODE STATUS STATE
hpeos003 up running
Network_Parameters:
INTERFACE STATUS PATH NAME
PRIMARY up 0/0/0/0 lan0
STANDBY up 0/2/0/0/4/0 lan1
root@hpeos002[] #
If any packages were running, it would be advisable to move the packages to another node.
This is a crucial step and it is one that is often forgotten. If we were to leave this step until later, we would come across errors when we try to remove the node from the binary cluster configuration file. If we look at our clockwatch package, we can see that node hpeos003 is an adoptive node for this package. We need to get rid of this dependency on node hpeos003 before we remove the node from the cluster. Let's remove this node from the clockwatch package.
Because there are no packages running on node hpeos003, this process is relatively straightforward.
root@hpeos002[clockwatch] # cmgetconf -v -p clockwatch clockwatch.curr
root@hpeos002[clockwatch] #
In my case, I simply removed the following line from the clockwatch.curr file:
NODE_NAME hpeos003
root@hpeos002[clockwatch] # cmcheckconf -v -P clockwatch.curr
Checking existing configuration ... Done
Gathering configuration information ... Done
Parsing package file: clockwatch.curr.
Package clockwatch already exists. It will be modified.
Maximum configured packages parameter is 10.
Configuring 1 package(s).
9 package(s) can be added to this cluster.
Modifying the package configuration for package clockwatch.
Warning: Deleting node hpeos003 from package clockwatch.
Verification completed with no errors found.
Use the cmapplyconf command to apply the configuration.
root@hpeos002[clockwatch] #
root@hpeos002[clockwatch] # cmapplyconf -v -P clockwatch.curr Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: clockwatch.curr. Package clockwatch already exists. It will be modified. Maximum configured packages parameter is 10. Configuring 1 package(s). 9 package(s) can be added to this cluster. Modify the package configuration ([y]/n)? y Modifying the package configuration for package clockwatch. Warning: Deleting node hpeos003 from package clockwatch. Completed the cluster update. root@hpeos002[clockwatch] #
root@hpeos002[clockwatch] # cmviewcl -v -p clockwatch
PACKAGE STATUS STATE AUTO_RUN NODE
clockwatch up running enabled hpeos001
Policy_Parameters:
POLICY_NAME CONFIGURED_VALUE
Failover configured_node
Failback manual
Script_Parameters:
ITEM STATUS MAX_RESTARTS RESTARTS NAME
Service up 0 0 clock_mon
Subnet up 192.168.0.0
Resource up /system/kernel_resource/system_v_ipc/shared_memory/shmmni
Node_Switching_Parameters:
NODE_TYPE STATUS SWITCHING NAME
Primary up enabled hpeos001 (current)
Alternate up enabled hpeos002
root@hpeos002[clockwatch] #
Now that the node has been removed from the package, we can continue removing it from the cluster.
root@hpeos002[] # cmhaltnode -v hpeos003 Disabling package switching to all nodes being halted. Disabling all packages from running on hpeos003. Warning: Do not modify or enable packages until the halt operation is completed. Halting cluster services on node hpeos003. .. Successfully halted all nodes specified. Halt operation complete. root@hpeos002[] # cmviewcl -v -n hpeos003 NODE STATUS STATE hpeos003 down halted Network_Parameters: INTERFACE STATUS PATH NAME PRIMARY unknown 0/0/0/0 lan0 STANDBY unknown 0/2/0/0/4/0 lan1 root@hpeos002[] #
root@hpeos002[] # cd /etc/cmcluster root@hpeos002[cmcluster] # cmgetconf -v -c McBond cluster.ascii.curr Gathering configuration information .... Done Warning: The disk at /dev/dsk/c1t2d0 on node hpeos001 does not have an ID, or a disk label. Warning: Disks which do not have IDs cannot be included in the topology description. Use pvcreate(1M) to initialize a disk for LVM or, use vxdiskadm(1M) to initialize a disk for VxVM. root@hpeos002[cmcluster] #
In my case, I removed the following lines from the file cluster.ascii.curr:
NODE_NAME hpeos003
NETWORK_INTERFACE lan0
HEARTBEAT_IP 192.168.0.203
NETWORK_INTERFACE lan1
# List of serial device file names
# For example:
# SERIAL_DEVICE_FILE /dev/tty0p0
# Primary Network Interfaces on Bridged Net 1: lan0.
# Possible standby Network Interfaces on Bridged Net 1: lan1.
root@hpeos002[cmcluster] # cmcheckconf -v -C cluster.ascii.curr
Checking cluster file: cluster.ascii.curr
Checking nodes ... Done
Checking existing configuration ... Done
Gathering configuration information ... Done
Gathering configuration information ... Done
Gathering configuration information .............. Done
Cluster McBond is an existing cluster
Checking for inconsistencies .. Done
Cluster McBond is an existing cluster
Maximum configured packages parameter is 10.
Configuring 1 package(s).
9 package(s) can be added to this cluster.
Modifying configuration on node hpeos001
Modifying configuration on node hpeos002
Removing configuration from node hpeos003
Modifying the cluster configuration for cluster McBond.
Modifying node hpeos001 in cluster McBond.
Modifying node hpeos002 in cluster McBond.
Deleting node hpeos003 from cluster McBond.
Verification completed with no errors found.
Use the cmapplyconf command to apply the configuration.
root@hpeos002[cmcluster] #
root@hpeos002[cmcluster] # cmapplyconf -v -C cluster.ascii.curr
Checking cluster file: cluster.ascii.curr
Checking nodes ... Done
Checking existing configuration ... Done
Gathering configuration information ... Done
Gathering configuration information ... Done
Gathering configuration information .............. Done
Cluster McBond is an existing cluster
Checking for inconsistencies .. Done
Cluster McBond is an existing cluster
Maximum configured packages parameter is 10.
Configuring 1 package(s).
9 package(s) can be added to this cluster.
Modifying configuration on node hpeos001
Modifying configuration on node hpeos002
Removing configuration from node hpeos003
Modify the cluster configuration ([y]/n)? y
Modifying the cluster configuration for cluster McBond.
Modifying node hpeos001 in cluster McBond.
Modifying node hpeos002 in cluster McBond.
Deleting node hpeos003 from cluster McBond.
Completed the cluster creation.
root@hpeos002[cmcluster] #
root@hpeos002[cmcluster] # cmviewcl
CLUSTER STATUS
McBond up
NODE STATUS STATE
hpeos001 up running
PACKAGE STATUS STATE AUTO_RUN NODE
clockwatch up running enabled hpeos001
NODE STATUS STATE
hpeos002 up running
root@hpeos002[cmcluster] #
As you will no doubt agree, removing a node from the cluster can be a more involved process than it first appears.
When we talk about rolling upgrades, we are talking about the process of upgrading hardware components, software components, applications, and loading patches, as well as upgrading the version of Serviceguard itself. The rolling part of the rolling upgrades statement relates to the fact that we are trying to minimize downtime for our applications and in order to do this, we roll the applications onto nodes around the cluster while the original node is being upgraded. There are no Serviceguard specific commands to perform upgrades. The process of upgrading software is normally controlled via swinstall. What we need to ensure is that we have adequate capacity within our cluster to run all current packages while the upgrade is in progress; some nodes may have to run multiple packages during this time. A simple checklist of processes to perform, in order to instigate an upgrade, would look something like this:
Move any package(s) off the node to be upgraded (
cmhaltpkg,cmrunpkg).Halt cluster services on the node to be upgraded (
cmhaltnode).Ensure that the node does not rejoin the cluster after a reboot (
AUTOSTART_CMCLD=0).Upgrade the node.
Apply any relevant patches.
Rejoin the cluster (
cmrunnode).Ensure that the node joins a cluster after a reboot (
AUTOSTART_CMCLD=1) if applicable.Repeat for all nodes in the cluster.
This last point is crucial because running a cluster with different versions of Serviceguard is not advisable. We must try to upgrade all nodes in the cluster as quickly as possible. While the cluster can run quite happily with different versions of Serviceguard, changes to the binary cluster configuration file are not allowed. If we understand this major limitation, we will realize the necessity to perform upgrades on all nodes in a timely fashion. Here is a list of limitations that apply to the cluster during an upgrade:
Cluster configuration files cannot be updated until all nodes are at the same version of the operating system.
This is an absolute. If you try to make any modifications, you will receive errors from commands such as
cmcheckconfandcmapplyconf.All Serviceguard commands must be issued from the node with latest version of Serviceguard.
You may be in a cluster where the binary file was created on an older version of Serviceguard. A new node brought into the cluster may be on a newer version. While commands from a newer version can understand an old version of the binary cluster configuration file, the reverse is not necessarily the case.
Only two versions of Serviceguard can be implemented during a rolling upgrade.
It is too much to ask Serviceguard to understand and interpolate between too many versions of the software.
Binary configuration files may be incompatible.
Software that uses the binary cluster configuration file should execute the command
/usr/sbin/convertafter being installed. This converts an older binary configuration file to the new format. You should check with the software's installation instructions whether this is performed automatically or whether you have to perform the step manually.Rolling upgrades can only be carried out on configurations that have not been modified since the last time cluster was started.
Serviceguard cannot be removed from a node while a cluster is being upgraded.
Any new features of Serviceguard cannot be utilized until all nodes are running that version of software.
Keep kernels consistent.
In some cases, it may be necessary to modify some kernel parameters in order for a node to run a particular application. This should be done only under the guidance of the operating system/application supplier.
Hardware configurations cannot be modified.
Most hardware changes would require a node to be rebooted, which is something we try to avoid during an upgrade. If we were to think of a specific example where this would be a real problem, it would be if we were to change one of our LAN cards. The MAC Address for a LAN card is compiled into the binary cluster configuration file. This is necessary because Serviceguard polls LAN cards at every
NETWORK_POLLING_INTERVAL. If we were to change a LAN card and hence the MAC Address, we would need to recompile and distribute the binary cluster configuration file, i.e.,cmgetconf,cmcheckconf, andcmapplyconf. As stated earlier, changes to the binary cluster configuration file are not allowed during a rolling upgrade.
Considering these limitations, we need to plan a rolling upgrade with great care. Most customers I know will upgrade one node first and perform significant testing on the cluster and applications on that one node. The plan you construct for performing the upgrade will be extensively tested as well. It is crucial in your planning to work out a drop-dead time for the upgrade. This is a time where you know that if the upgrade has not reached an important milestone, you must back out the upgrade and return the system to its original state before the upgrade started. At least if we can return the node to its original state, we can return the cluster to its original state and work out what went wrong during the upgrade process itself. If the important milestone has been reached by the drop-dead time, it is likely that you will have applications running on their original node in a timely fashion. If all goes well, you can schedule all the other nodes to be upgraded as soon as possible.
As part of an overall High Availability solution, Serviceguard ensures that our critical applications are running for the maximum amount of time. We have discussed many of the tasks involved in managing a cluster and its associated applications and should not lose site of the fact that the underlying principles of what constitutes a failure are still valid. We need to remember that Serviceguard is only part of the solution. While Serviceguard is good at monitoring many of the critical resources associated with an application, Serviceguard cannot fix the problems it finds. Throughout this book, we have stressed the need to maintain High Availability practices throughout our configuration tasks. Think back to our discussions regarding peripherals in Chapter 4, “Advanced Peripherals Configuration,” where we discussed OLA/R, the process of adding and replacing interface cards while the system is still running. All of these tasks go toward an entire ethos of high availability. We need to ensure that we monitor all of our system resources carefully and continuously. A failed disk drive can introduce a Single Point Of Failure into an otherwise highly available solution. If and when we detect these problems—be it a disk drive, the Quorum server, or a LAN card—we need to be in a position to effect a change in the shortest time possible with as little interruption as possible.
In the next section, we look at a tool that allows us to monitor and manager Serviceguard clusters via a GUI interface.
I installed Serviceguard Manager before I performed Step 5 (Delete a package from a cluster) and Step 6 (Delete a node from a cluster) in order to show you my cluster with the maximum amount of information.
Serviceguard Manager requires a server on the same subnet in the cluster to be have installed and possibly running a minimum of Serviceguard version 11.12. This version of Serviceguard comes with additional software known as Cluster Object Manager. The node running Serviceguard version 11.12 will discover other nodes and provide data back to the management station. The discovered nodes can be running versions of Serviceguard back to version 10.10 as well as the more esoteric versions of Serviceguard including Serviceguard OPS Edition, Metrocluster, and Continentalclusters. The discovered nodes can be members of multiple clusters on the same or different subnets, as long as the machine running Serviceguard Manager has the ability to reach those networks. As we see, not only can we view different clusters, but we can also manage packages and nodes with simple point-and-click technology.
The Serviceguard Manager GUI can run on an HP-UX system (preferably running HP-UX 11i because HP-UX 11.0 needs quite a few patches loading), a PC running Window NT4 (SP5 or later) or Windows 2000 (SP1 or later), or a machine running Linux. In my dealings with this tool, if it is going to be used, it is most commonly installed on a PC in order to give a convenient GUI interface. I leave you to read the installation requirements yourself; basically if you have a new(ish) PC, you should be fine because the minimum processor speed is 200 MHz. Here's the process I went through in order to get Serviceguard Manager up and running on my PC running Windows XP Home Edition.
Download the installation program (currently called
sgmgr_a030001.exe) from http://www.software.hp.com/HA_products_list.html. It's free to download the software. Beware that the download is 18.8MB in size. The software is available on CD as well:HP B8325BA –. software and license for HP-UX.
HP T1228BA –. software and license for Linux.
HP B8341BA –. software and license for Windows.
Install Serviceguard Manager. This was as simple as executing the downloaded binary. I took the default options supplied. It only took approximately 2 minutes to install.
If necessary, configure the file
/etc/cmcluster/cmclnodeliston all nodes in the cluster to include the name of the node running the Cluster Object Manager software. In my case, the Cluster Object Manager could be any of the nodes currently in the cluster. If you have multiple clusters, you need to update thecmclnodelistfile on all nodes in all clusters, to include the node acting as the Cluster Object Manager. Failure to do this means you will not be able to manage those nodes/clusters from within the GUI.Run the GUI. For Windows, this is accessible from the desktop icon created during the installation or via the Start Menu - Programs - Serviceguard Manager - SG Manager A.03.00.01. On HP-UX, the GUI is found under
/opt/sgmgr/bin/sgmgr. There are a number of command line arguments that you can use to specify particular clusters to view. I simply ran the GUI from the desktop icon. Figure 27-1 shows the first dialog box presented. I chose the default option to connect to a live cluster:
In Figure 27-2, you can see the information I entered to connect to a specific node, in this case hpeos002 (192.168.0.202). Obviously, you can use hostnames instead of IP addresses; it's just that my PC has no resolver configured. I need to be able to log in as the user root because root is the only user listed in the file cmclnodelist.

Once connected, the Cluster Object Manager node displays all the clusters it has discovered. In Figure 27-3, you can see the clusters discovered.
I can simply double-click to navigate through the icons. Right-clicking allows me to view Properties of particular entities. Figure 27-4 shows you the Property Sheet for the McBond cluster.
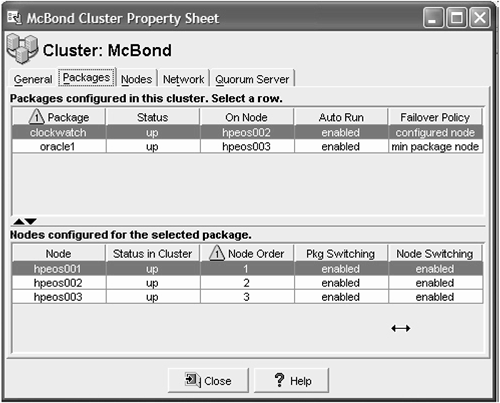
The different tabs at the top of a Property Sheet allow you to view Properties of different aspects of the cluster. This interface is fairly easy to navigate. In Figure 27-5, you can see the expanded cluster. I am in the process of dragging and dropping the clockwatch package from node hpeos002 to run on node hpeos001. This is how simple Serviceguard Manager can make managing a cluster.
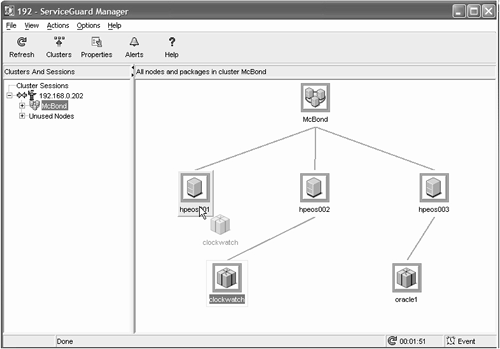
Once the move is complete, you receive a dialog box similar to the one you can see in Figure 27-6.
Finally, Figure 27-7 shows me right-clicking on a package. Here, I can perform various aspects of package management, all from the GUI.
As you can see, Serviceguard Manager is an extensive and well-constructed application. I am not going to go into its many features here; you can spend many happy hours finding that out for yourself. Happy GUI'ing!
We have looked at many aspects of managing a Serviceguard Cluster. I hope the hands-on approach gives you confidence to try these tasks for yourself. The only way we are going to gain that confidence is to plan, implement, and test the configuration that best suits our needs. We have looked at a number of configuration options to try to shed light on some of the myriad of options available to you. The questions below will allow you to recap what we discussed as well as get you thinking about some problem situations. Good luck in your endeavors, and see you in the next chapter.