
- Hadoop Beginner's Guide
- Table of Contents
- Hadoop Beginner's Guide
- Credits
- About the Author
- About the Reviewers
- www.PacktPub.com
- Preface
- 1. What It's All About
- 2. Getting Hadoop Up and Running
- Hadoop on a local Ubuntu host
- Time for action – checking the prerequisites
- Time for action – downloading Hadoop
- Time for action – setting up SSH
- Time for action – using Hadoop to calculate Pi
- Time for action – configuring the pseudo-distributed mode
- Time for action – changing the base HDFS directory
- Time for action – formatting the NameNode
- Time for action – starting Hadoop
- Time for action – using HDFS
- Time for action – WordCount, the Hello World of MapReduce
- Using Elastic MapReduce
- Time for action – WordCount on EMR using the management console
- Comparison of local versus EMR Hadoop
- Summary
- 3. Understanding MapReduce
- Key/value pairs
- The Hadoop Java API for MapReduce
- Writing MapReduce programs
- Time for action – setting up the classpath
- Time for action – implementing WordCount
- Time for action – building a JAR file
- Time for action – running WordCount on a local Hadoop cluster
- Time for action – running WordCount on EMR
- Time for action – WordCount the easy way
- Walking through a run of WordCount
- Startup
- Splitting the input
- Task assignment
- Task startup
- Ongoing JobTracker monitoring
- Mapper input
- Mapper execution
- Mapper output and reduce input
- Partitioning
- The optional partition function
- Reducer input
- Reducer execution
- Reducer output
- Shutdown
- That's all there is to it!
- Apart from the combiner…maybe
- Time for action – WordCount with a combiner
- Time for action – fixing WordCount to work with a combiner
- Hadoop-specific data types
- Time for action – using the Writable wrapper classes
- Input/output
- Summary
- 4. Developing MapReduce Programs
- Using languages other than Java with Hadoop
- Time for action – implementing WordCount using Streaming
- Analyzing a large dataset
- Time for action – summarizing the UFO data
- Time for action – summarizing the shape data
- Time for action – correlating of sighting duration to UFO shape
- Time for action – performing the shape/time analysis from the command line
- Time for action – using ChainMapper for field validation/analysis
- Time for action – using the Distributed Cache to improve location output
- Counters, status, and other output
- Time for action – creating counters, task states, and writing log output
- Summary
- 5. Advanced MapReduce Techniques
- Simple, advanced, and in-between
- Joins
- Time for action – reduce-side join using MultipleInputs
- Graph algorithms
- Time for action – representing the graph
- Time for action – creating the source code
- Time for action – the first run
- Time for action – the second run
- Time for action – the third run
- Time for action – the fourth and last run
- Using language-independent data structures
- Time for action – getting and installing Avro
- Time for action – defining the schema
- Time for action – creating the source Avro data with Ruby
- Time for action – consuming the Avro data with Java
- Time for action – generating shape summaries in MapReduce
- Time for action – examining the output data with Ruby
- Time for action – examining the output data with Java
- Summary
- 6. When Things Break
- Failure
- Time for action – killing a DataNode process
- Time for action – the replication factor in action
- Time for action – intentionally causing missing blocks
- Time for action – killing a TaskTracker process
- Time for action – killing the JobTracker
- Time for action – killing the NameNode process
- What just happened?
- Starting a replacement NameNode
- The role of the NameNode in more detail
- File systems, files, blocks, and nodes
- The single most important piece of data in the cluster – fsimage
- DataNode startup
- Safe mode
- SecondaryNameNode
- So what to do when the NameNode process has a critical failure?
- BackupNode/CheckpointNode and NameNode HA
- Hardware failure
- Host failure
- Host corruption
- The risk of correlated failures
- Task failure due to software
- What just happened?
- Time for action – causing task failure
- Time for action – handling dirty data by using skip mode
- Summary
- 7. Keeping Things Running
- A note on EMR
- Hadoop configuration properties
- Time for action – browsing default properties
- Setting up a cluster
- Time for action – examining the default rack configuration
- Time for action – adding a rack awareness script
- Cluster access control
- Time for action – demonstrating the default security
- Managing the NameNode
- Time for action – adding an additional fsimage location
- Time for action – swapping to a new NameNode host
- Managing HDFS
- MapReduce management
- Time for action – changing job priorities and killing a job
- Scaling
- Summary
- 8. A Relational View on Data with Hive
- Overview of Hive
- Setting up Hive
- Time for action – installing Hive
- Using Hive
- Time for action – creating a table for the UFO data
- Time for action – inserting the UFO data
- Time for action – validating the table
- Time for action – redefining the table with the correct column separator
- Time for action – creating a table from an existing file
- Time for action – performing a join
- Time for action – using views
- Time for action – exporting query output
- Time for action – making a partitioned UFO sighting table
- Time for action – adding a new User Defined Function (UDF)
- Hive on Amazon Web Services
- Time for action – running UFO analysis on EMR
- Summary
- 9. Working with Relational Databases
- Common data paths
- Setting up MySQL
- Time for action – installing and setting up MySQL
- Time for action – configuring MySQL to allow remote connections
- Time for action – setting up the employee database
- Getting data into Hadoop
- Time for action – downloading and configuring Sqoop
- Time for action – exporting data from MySQL to HDFS
- Time for action – exporting data from MySQL into Hive
- Time for action – a more selective import
- Time for action – using a type mapping
- Time for action – importing data from a raw query
- Getting data out of Hadoop
- Time for action – importing data from Hadoop into MySQL
- Time for action – importing Hive data into MySQL
- Time for action – fixing the mapping and re-running the export
- AWS considerations
- Summary
- 10. Data Collection with Flume
- A note about AWS
- Data data everywhere...
- Time for action – getting web server data into Hadoop
- Introducing Apache Flume
- Time for action – installing and configuring Flume
- Time for action – capturing network traffic in a log file
- Time for action – logging to the console
- Time for action – capturing the output of a command to a flat file
- Time for action – capturing a remote file in a local flat file
- Time for action – writing network traffic onto HDFS
- Time for action – adding timestamps
- Time for action – multi level Flume networks
- Time for action – writing to multiple sinks
- The bigger picture
- Summary
- 11. Where to Go Next
- A. Pop Quiz Answers
- Index
Let's now perform the initial execution of this algorithm on our starting representation of the graph:
- Put the previously created
graph.txtfile onto HDFS:$ hadoop fs -mkdirgraphin $ hadoop fs -put graph.txtgraphin/graph.txt
- Compile the job and create the JAR file:
$ javac GraphPath.java $ jar -cvf graph.jar *.class
- Execute the MapReduce job:
$ hadoop jar graph.jarGraphPathgraphingraphout1 - Examine the output file:
$ hadoop fs –cat /home/user/hadoop/graphout1/part-r00000 12,3,40D 21,41C 31,5,61C 41,21C 53,6-1P 63,5-1P 76-1P
After putting the source file onto HDFS and creating the job JAR file, we executed the job in Hadoop. The output representation of the graph shows a few changes, as follows:
- Node 1 is now marked as Done; its distance from itself is obviously 0
- Nodes 2, 3, and 4 – the neighbors of node 1 — are marked as Currently processing
- All other nodes are Pending
Our graph now looks like the following figure:
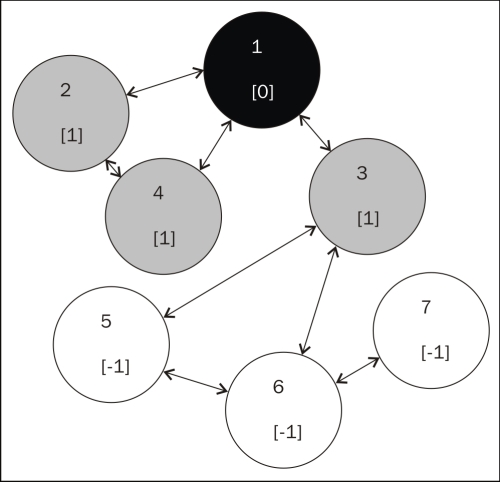
Given the algorithm, this is to be expected; the first node is complete and its neighboring nodes, extracted through the mapper, are in progress. All other nodes are yet to begin processing.
-
No Comment
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.