
Let's see skip mode in action by writing a MapReduce job that receives the data that causes it to fail:
- Save the following Ruby script as
gendata.rb:File.open("skipdata.txt", "w") do |file| 3.times do 500000.times{file.write("A valid record ")} 5.times{file.write("skiptext ")} end 500000.times{file.write("A valid record ")} End - Run the script:
$ ruby gendata.rb - Check the size of the generated file and its number of lines:
$ ls -lh skipdata.txt -rw-rw-r-- 1 hadoop hadoop 29M 2011-12-17 01:53 skipdata.txt ~$ cat skipdata.txt | wc -l 2000015
- Copy the file onto HDFS:
$ hadoop fs -put skipdata.txt skipdata.txt - Add the following property definition to
mapred-site.xml:<property> <name>mapred.skip.map.max.skip.records</name> <value5</value> </property>
- Check the value set for
mapred.max.map.task.failuresand set it to20if it is lower. - Save the following Java file as
SkipData.java:import java.io.IOException; import org.apache.hadoop.conf.* ; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.* ; import org.apache.hadoop.mapred.* ; import org.apache.hadoop.mapred.lib.* ; public class SkipData { public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, LongWritable> { private final static LongWritable one = new LongWritable(1); private Text word = new Text("totalcount"); public void map(LongWritable key, Text value, OutputCollector<Text, LongWritable> output, Reporter reporter) throws IOException { String line = value.toString(); if (line.equals("skiptext")) throw new RuntimeException("Found skiptext") ; output.collect(word, one); } } public static void main(String[] args) throws Exception { Configuration config = new Configuration() ; JobConf conf = new JobConf(config, SkipData.class); conf.setJobName("SkipData"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(LongWritable.class); conf.setMapperClass(MapClass.class); conf.setCombinerClass(LongSumReducer.class); conf.setReducerClass(LongSumReducer.class); FileInputFormat.setInputPaths(conf,args[0]) ; FileOutputFormat.setOutputPath(conf, new Path(args[1])) ; JobClient.runJob(conf); } } - Compile this file and jar it into
skipdata.jar. - Run the job:
$ hadoop jar skip.jar SkipData skipdata.txt output … 11/12/16 17:59:07 INFO mapred.JobClient: map 45% reduce 8% 11/12/16 17:59:08 INFO mapred.JobClient: Task Id : attempt_201112161623_0014_m_000003_0, Status : FAILED java.lang.RuntimeException: Found skiptext at SkipData$MapClass.map(SkipData.java:26) at SkipData$MapClass.map(SkipData.java:12) at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:50) at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:358) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:307) at org.apache.hadoop.mapred.Child.main(Child.java:170) 11/12/16 17:59:11 INFO mapred.JobClient: map 42% reduce 8% ... 11/12/16 18:01:26 INFO mapred.JobClient: map 70% reduce 16% 11/12/16 18:01:35 INFO mapred.JobClient: map 71% reduce 16% 11/12/16 18:01:43 INFO mapred.JobClient: Task Id : attempt_201111161623_0014_m_000003_2, Status : FAILED java.lang.RuntimeException: Found skiptext ... 11/12/16 18:12:44 INFO mapred.JobClient: map 99% reduce 29% 11/12/16 18:12:50 INFO mapred.JobClient: map 100% reduce 29% 11/12/16 18:13:00 INFO mapred.JobClient: map 100% reduce 100% 11/12/16 18:13:02 INFO mapred.JobClient: Job complete: job_201112161623_0014 ...
- Examine the contents of the job output file:
$ hadoop fs -cat output/part-00000 totalcount 2000000
- Look in the output directory for skipped records:
$ hadoop fs -ls output/_logs/skip Found 15 items -rw-r--r-- 3 hadoop supergroup 203 2011-12-16 18:05 /user/hadoop/output/_logs/skip/attempt_201112161623_0014_m_000001_3 -rw-r--r-- 3 hadoop supergroup 211 2011-12-16 18:06 /user/hadoop/output/_logs/skip/attempt_201112161623_0014_m_000001_4 …
- Check the job details from the MapReduce UI to observe the recorded statistics as shown in the following screenshot:
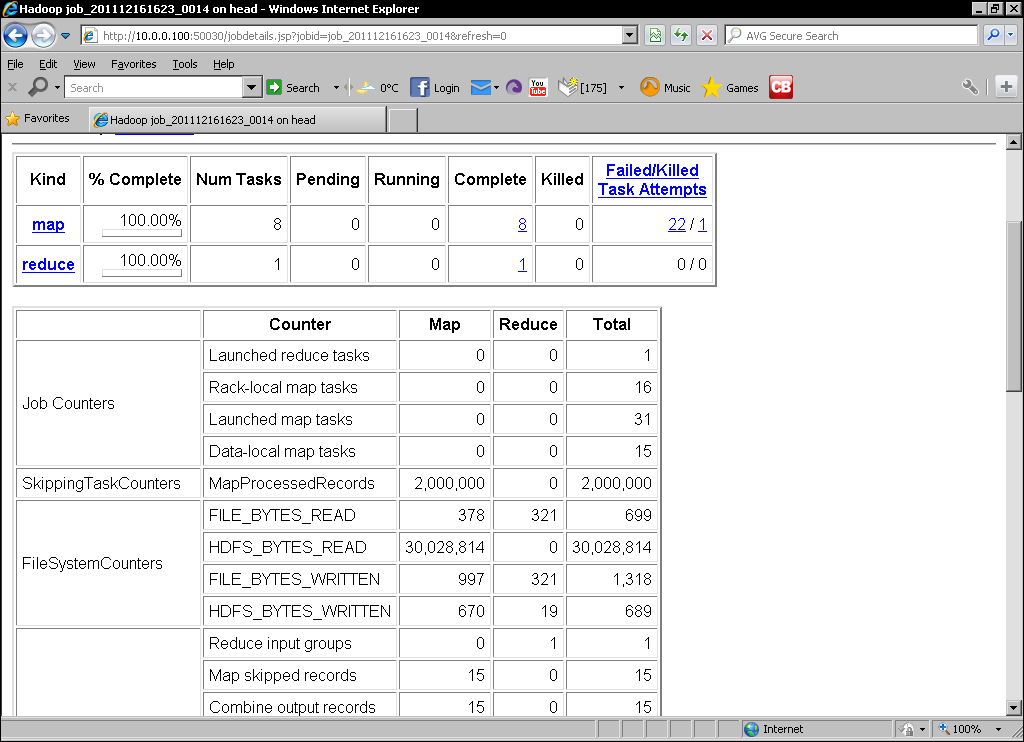
We had to do a lot of setup here so let's walk through it a step at a time.
Firstly, we needed to configure Hadoop to use skip mode; it is disabled by default. The key configuration property was set to 5, meaning that we didn't want the framework to skip any set of records greater than this number. Note that this includes the invalid records, and by setting this property to 0 (the default) Hadoop will not enter skip mode.
We also check to ensure that Hadoop is configured with a sufficiently high threshold for repeated task attempt failures, which we will explain shortly.
Next we needed a test file that we could use to simulate dirty data. We wrote a simple Ruby script that generated a file with 2 million lines that we would treat as valid with three sets of five bad records interspersed through the file. We ran this script and confirmed that the generated file did indeed have 2,000,015 lines. This file was then put on HDFS where it would be the job input.
We then wrote a simple MapReduce job that effectively counts the number of valid records. Every time the line reads from the input as the valid text we emit an additional count of 1 to what will be aggregated as a final total. When the invalid lines are encountered, the mapper fails by throwing an exception.
We then compile this file, jar it up, and run the job. The job takes a while to run and as seen from the extracts of the job status, it follows a pattern that we have not seen before. The map progress counter will increase but when a task fails, the progress will drop back then start increasing again. This is skip mode in action.
Every time a key/value pair is passed to the mapper, Hadoop by default increments a counter that allows it to keep track of which record caused a failure.
When a task fails, Hadoop retries it on the same block but attempts to work around the invalid records. Through a binary search approach, the framework performs retries across the data until the number of skipped records is no greater than the maximum value we configured earlier, that is 5. This process does require multiple task retries and failures as the framework seeks the optimal batch to skip, which is why we had to ensure the framework was configured to be tolerant of a higher-than-usual number of repeated task failures.
We watched the job continue following this back and forth process and on completion checked the contents of the output file. This showed 2,000,000 processed records, that is the correct number of valid records in our input file. Hadoop successfully managed to skip only the three sets of five invalid records.
We then looked within the _logs directory in the job output directory and saw that there is a skip directory containing the sequence files of the skipped records.
Finally, we looked at the MapReduce web UI to see the overall job status, which included both the number of records processed while in skip mode as well as the number of records skipped. Note that the total number of failed tasks was 22, which is greater than our threshold for failed map attempts, but this number is aggregate failures across multiple tasks.
Skip mode can be very effective but as we have seen previously, there is a performance penalty caused by Hadoop having to determine which record range to skip. Our test file was actually quite helpful to Hadoop; the bad records were nicely grouped in three groups and only accounted for a tiny fraction of the overall data set. If there were many more invalid records in the input data and they were spread much more widely across the file, a more effective approach may have been to use a precursor MapReduce job to filter out all the invalid records.
This is why we have presented the topics of writing code to handle bad data and using skip mode consecutively. Both are valid techniques that you should have in your tool belt. There is no single answer to when one or the other is the best approach, you need to consider the input data, performance requirements, and opportunities for hardcoding before making a decision.