
Let's show another example of capturing data to a file sink. This time we will use another Flume capability that allows it to receive data from a remote client.
- Create the following file as
agent3.confin the Flume working directory:agent3.sources = avrosource agent3.sinks = filesink agent3.channels = jdbcchannel agent3.sources.avrosource.type = avro agent3.sources.avrosource.bind = localhost agent3.sources.avrosource.port = 4000 agent3.sources.avrosource.threads = 5 agent3.sinks.filesink.type = FILE_ROLL agent3.sinks.filesink.sink.directory = /home/hadoop/flume/files agent3.sinks.filesink.sink.rollInterval = 0 agent3.channels.jdbcchannel.type = jdbc agent3.sources.avrosource.channels = jdbcchannel agent3.sinks.filesink.channel = jdbcchannel
- Create a new test file as
/home/hadoop/message2:Hello from Avro!
- Start the Flume agent:
$ flume-ng agent –conf conf –conf-file agent3.conf –name agent3 - In another window, use the Flume Avro client to send a file to the agent:
$ flume-ng avro-client -H localhost -p 4000 -F /home/hadoop/message - As before, check the file in the configured output directory:
$ cat files/*The output of the preceding command can be shown in following screenshot:
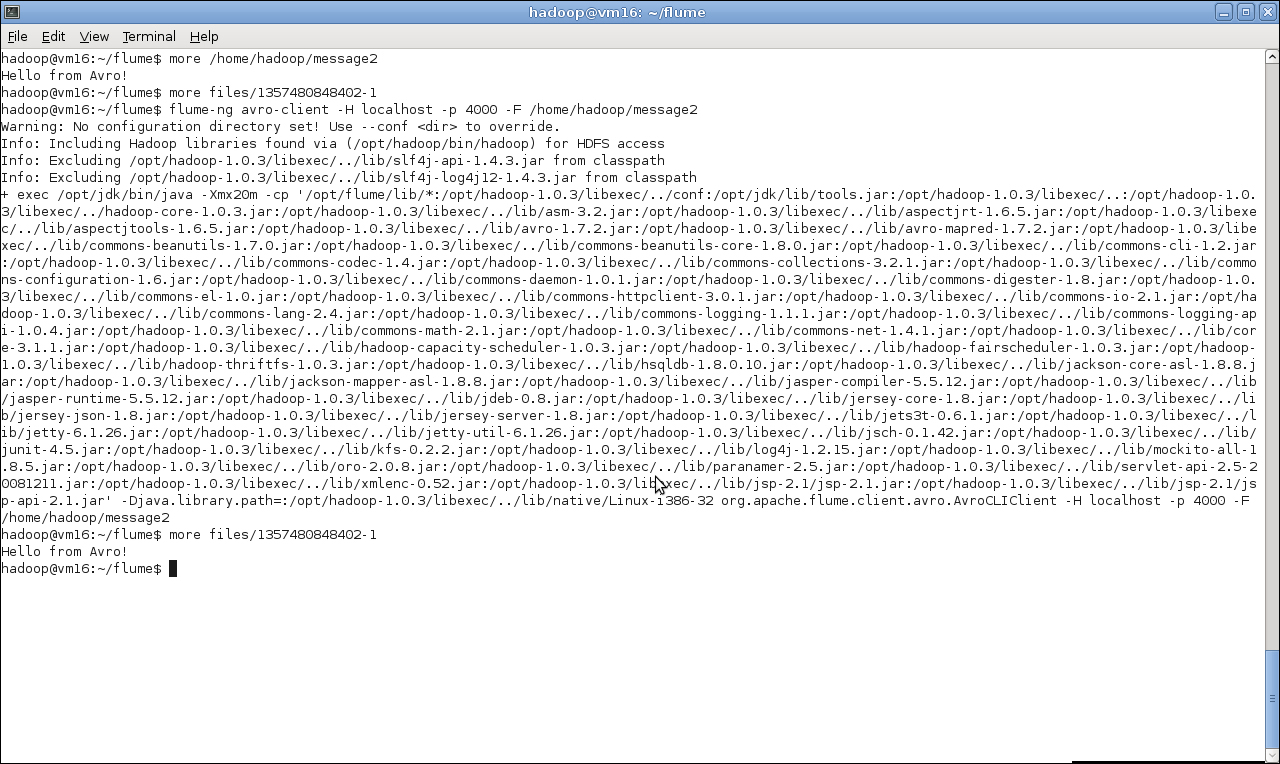
As before, we created a new configuration file and this time used an Avro source for the agent. Recall from Chapter 5, Advanced MapReduce Techniques, that Avro is a data serialization framework; that is, it manages the packaging and transport of data from one point to another across the network. Similarly to the Netcat source, the Avro source requires configuration parameters that specify its network settings. In this case, it will listen on port 4000 on the local machine. The agent is configured to use the file sink as before and we start it up as usual.
Flume comes with both an Avro source and a standalone Avro client. The latter can be used to read a file and send it to an Avro source anywhere on the network. In our example, we just use the local machine, but note that the Avro client requires the explicit hostname and port of the Avro source to which it should send the file. So this is not a constraint; an Avro client can send files to a listening Flume Avro source anywhere on the network.
The Avro client reads the file, sends it to the agent, and this gets written to the file sink. We check this behavior by confirming that the file contents are in the file sink location as expected.
We intentionally used a variety of sources, sinks, and channels in the previous examples just to show how they can be mixed and matched. However, we have not explored them—especially channels—in much detail. Let's dig a little deeper now.
We've looked at three sources: Netcat, exec, and Avro. Flume NG also supports a sequence generator source (mostly for testing) as well as both TCP and UDP variants of a source that reads syslogd data. Each source is configured within an agent and after receiving enough data to produce a Flume event, it sends this newly created event to the channel to which the source is connected. Though a source may have logic relating to how it reads data, translates events, and handles failure situations, the source has no knowledge of how the event is to be stored. The source has the responsibility of delivering the event to the configured channel, and all other aspects of the event processing are invisible to the source.
In addition to the logger and file roll sinks we used previously, Flume also supports sinks for HDFS, HBase (two types), Avro (for agent chaining), null (for testing), and IRC (for an Internet Relay Chat service). The sink is conceptually similar to the source but in reverse.
The sink waits for events to be received from the configured channel about whose inner workings it knows nothing. On receipt, the sink handles the output of the event to its particular destination, managing all issues around time outs, retries, and rotation.
So what are these mysterious channels that connect the source and sink? They are, as the name and configuration entries before suggest, the communication and retention mechanism that manages event delivery.
When we define a source and a sink, there may be significant differences in how they read and write data. An exec source may, for example, receive data much faster than a file roll sink can write it or the source may have times (such as when rolling to a new file or dealing with system I/O congestion) that writing needs be paused. The channel, therefore, needs buffer data between the source and sink to allow data to stream through the agent as efficiently as possible. This is why the channel configuration portions of our configuration files include elements such as capacity.
The memory channel is the easiest to understand as the events are read from the source into memory and passed to the sink as it is able to receive them. But if the agent process dies mid-way through the process (be it due to software or hardware failure), then all the events currently in the memory channel are lost forever.
The file and JDBC channels that we also used provide persistent storage of events to prevent such loss. After reading an event from a source, the file channel writes the contents to a file on the filesystem that is deleted only after successful delivery to the sink. Similarly, the JDBC channel uses an embedded Derby database to store events in a recoverable fashion.
This is a classic performance versus reliability trade-off. The memory channel is the fastest but has the risk of data loss. The file and JDBC channels are typically much slower but effectively provide guaranteed delivery to the sink. Which channel you choose depends on the nature of the application and the values of each event.
Don't feel limited by the existing collection of sources, sinks, and channels. Flume offers an interface to define your own implementation of each. In addition, there are a few components present in Flume OG that have not yet been incorporated into Flume NG but may appear in the future.
Now that we've talked through sources, sinks, and channels, let's take a look at one of the configuration files from earlier in a little more detail:
agent1.sources = netsource agent1.sinks = logsink agent1.channels = memorychannel
These first lines name the agent and define the sources, sinks, and channels associated with it. We can have multiple values on each line; the values are space separated:
agent1.sources.netsource.type = netcat agent1.sources.netsource.bind = localhost agent1.sources.netsource.port = 3000
These lines specify the configuration for the source. Since we are using the Netcat source, the configuration values specify how it should bind to the network. Each type of source has its own configuration variables.
agent1.sinks.logsink.type = logger
This specifies the sink to be used is the logger sink which is further configured via the command line or the log4j property file.
agent1.channels.memorychannel.type = memory agent1.channels.memorychannel.capacity = 1000 agent1.channels.memorychannel.transactionCapacity = 100 These lines specify the channel to be used and then add the type specific configuration values. In this case we are using the memory channel and we specify its capacity but – since it is non-persistent – no external storage mechanism. agent1.sources.netsource.channels = memorychannel agent1.sinks.logsink.channel = memorychannel
These last lines configure the channel to be used for the source and sink. Though we used different configuration files for our different agents, we could just as easily place all the elements in a single configuration file as the respective agent names provide the necessary separation. This can, however, produce a pretty verbose file which can be a little intimidating when you are just learning Flume. We can also have multiple flows within a given agent, we could, for example, combine the first two preceding examples into a single configuration file and agent.
Do just that! Create a configuration file that specifies the capabilities of both our previous agent1 and agent2 from the preceding example in a single composite agent that contains:
- A Netcat source and its associated logger sink
- An exec source and its associated file sink
- Two memory channels, one for each of the source/sink pairs mentioned before
To get you started, here's how the component definitions could look:
agentx.sources = netsource execsource agentx.sinks = logsink filesink agentx.channels = memorychannel1 memorychannel2
Let's discuss one more definition before we try another example. Just what is an event?
Remember that Flume is explicitly based around log files, so in most cases, an event equates to a line of text followed by a new line character. That is the behavior we've seen with the sources and sinks we've used.
This isn't always the case, however, the UDP syslogd source, for example, treats each packet of data received as a single event, which gets passed through the system. When using these sinks and sources, however, these definitions of events are unchangeable and when reading files, for example, we have no choice but to use line-based events.