
We mentioned earlier that there were mechanisms to have file data written in slightly more sophisticated ways. Let's do something very common and write our data into a directory with a dynamically-created timestamp.
- Create the following configuration file as
agent5.conf:agent5.sources = netsource agent5.sinks = hdfssink agent5.channels = memorychannel agent5.sources.netsource.type = netcat agent5.sources.netsource.bind = localhost agent5.sources.netsource.port = 3000 agent5.sources.netsource.interceptors = ts agent5.sources.netsource.interceptors.ts.type = org.apache.flume.interceptor.TimestampInterceptor$Builder agent5.sinks.hdfssink.type = hdfs agent5.sinks.hdfssink.hdfs.path = /flume-%Y-%m-%d agent5.sinks.hdfssink.hdfs.filePrefix = log- agent5.sinks.hdfssink.hdfs.rollInterval = 0 agent5.sinks.hdfssink.hdfs.rollCount = 3 agent5.sinks.hdfssink.hdfs.fileType = DataStream agent5.channels.memorychannel.type = memory agent5.channels.memorychannel.capacity = 1000 agent5.channels.memorychannel.transactionCapacity = 100 agent5.sources.netsource.channels = memorychannel agent5.sinks.hdfssink.channel = memorychannel
- Start the agent:
$ flume-ng agent –conf conf –conf-file agent5.conf –name agent5 - In another window, open up a telnet session and send seven events to Flume:
$ curl telnet://localhost:3000 - Check the directory name on HDFS and the files within it:
$ hadoop fs -ls /The output of the preceding code can be shown in the following screenshot:
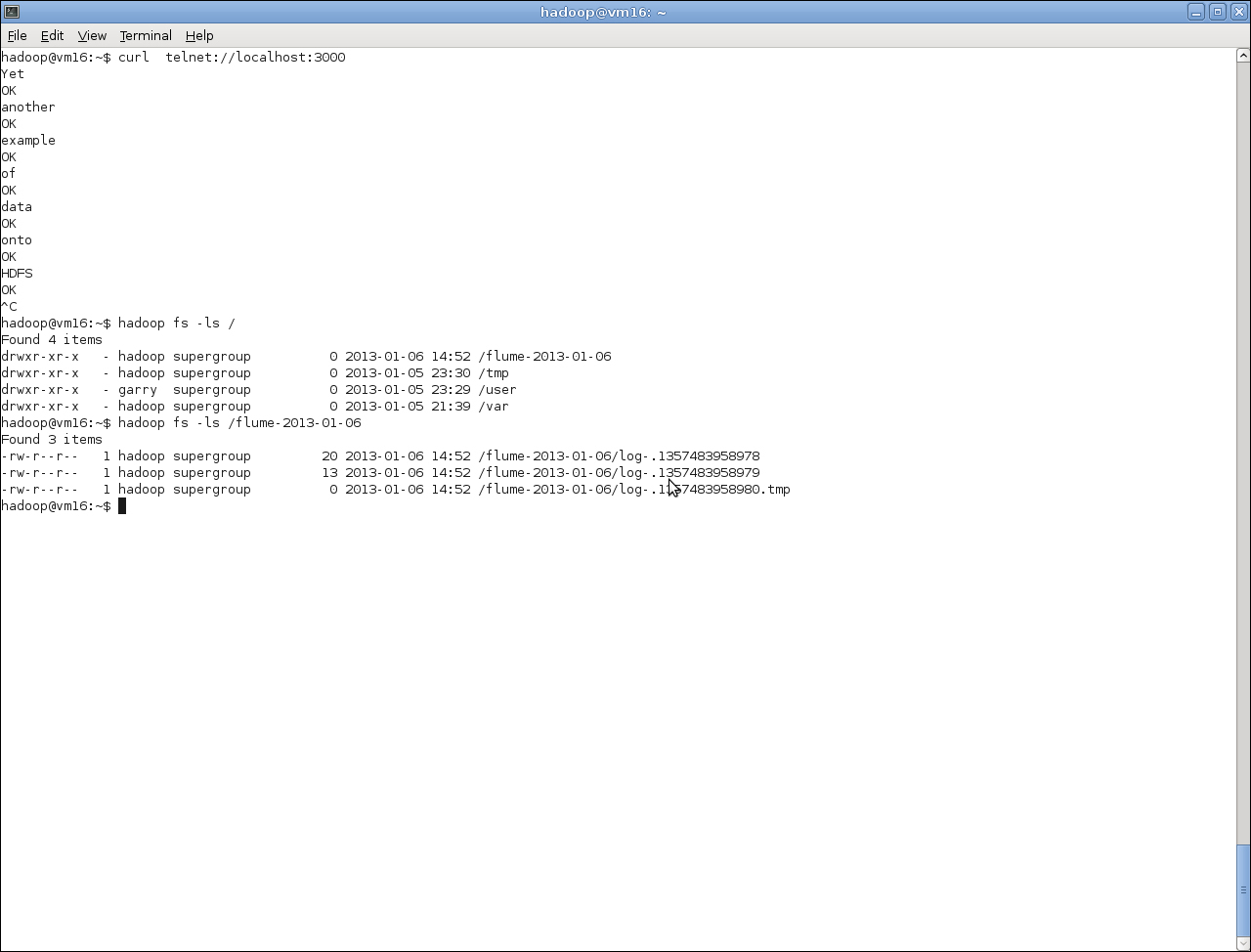
We made a few
changes to the previous configuration file. We added an interceptor specification to the Netcat source and gave its implementation class as TimestampInterceptor.
Flume interceptors are plugins that can manipulate and modify events before they pass from the source to the channel. Most interceptors either add metadata to the event (as in this case) or drop events based on certain criteria. In addition to several inbuilt interceptors, there is naturally a mechanism for user-defined interceptors.
We used the timestamp interceptor here which adds to the event metadata the Unix timestamp at the time the event is read. This allows us to extend the definition of the HDFS path into which events are to be written.
While previously we simply wrote all events to the /flume directory, we now specified the path as /flume-%Y-%m-%d. After running the agent and sending some data to Flume, we looked at HDFS and saw that these variables have been expanded to give the directory a year/month/date suffix.
The HDFS sink supports many other variables such as the hostname of the source and additional temporal variables that can allow precise partitioning to the level of seconds.
The utility here is plain; instead of having all events written into a single directory that becomes enormous over time, this simple mechanism can give automatic partitioning, making data management easier but also providing a simpler interface to the data for MapReduce jobs. If, for example, most of your MapReduce jobs process hourly data, then having Flume partition incoming events into hourly directories will make your life much easier.
To be precise, the event passing through Flume has had a complete Unix timestamp added, that is, accurate to the nearest second. In our example, we used only date-related variables in the directory specification, if hourly or finer-grained directory partitioning is required, then the time-related variables would be used.
Note
This assumes that the timestamp at the point of processing is sufficient for your needs. If files are being batched and then fed to Flume, then a file's contents may have timestamps from the previous hour than when they are being processed. In such a case, you could write a custom interceptor to set the timestamp header based on the contents of the file.
An obvious question is whether Sqoop or Flume is most appropriate if we have data in a relational database that we want to export onto HDFS. We've seen how Sqoop can perform such an export and we could do something similar using Flume, either with a custom source or even just by wrapping a call to the mysql command within an exec source.
A good rule of thumb is to look at the type of data and ask if it is log data or something more involved.
Flume was created in large part to handle log data and it excels in this area. But in most cases, Flume networks are responsible for delivering events from sources to sinks without any real transformation on the log data itself. If you have log data in multiple relational databases, then Flume is likely a great choice, though I would question the long-term scalability of using a database for storing log records.
Non-log data may require data manipulation that only Sqoop is capable of performing. Many of the transformations we performed in the previous chapter using Sqoop, such as specifying subsets of columns to be retrieved, are really not possible using Flume. It's also quite possible that if you are dealing with structured data that requires individual field processing, then Flume alone is not the ideal tool. If you want direct Hive integration then Sqoop is your only choice.
Remember, of course, that the tools can also work together in more complex workflows. Events could be gathered together onto HDFS by Flume, processed through MapReduce, and then exported into a relational database by Sqoop.