
We've abused HDFS and its DataNode enough; now let's see what damage we can do to MapReduce by killing some TaskTracker processes.
Though there is an mradmin command, it does not give the sort of status reports we are used to with HDFS. So we'll use the MapReduce web UI (located by default on port 50070 on the JobTracker host) to monitor the MapReduce cluster health.
Perform the following steps:
- Ensure everything is running via the
start-all.shscript then point your browser at the MapReduce web UI. The page should look like the following screenshot: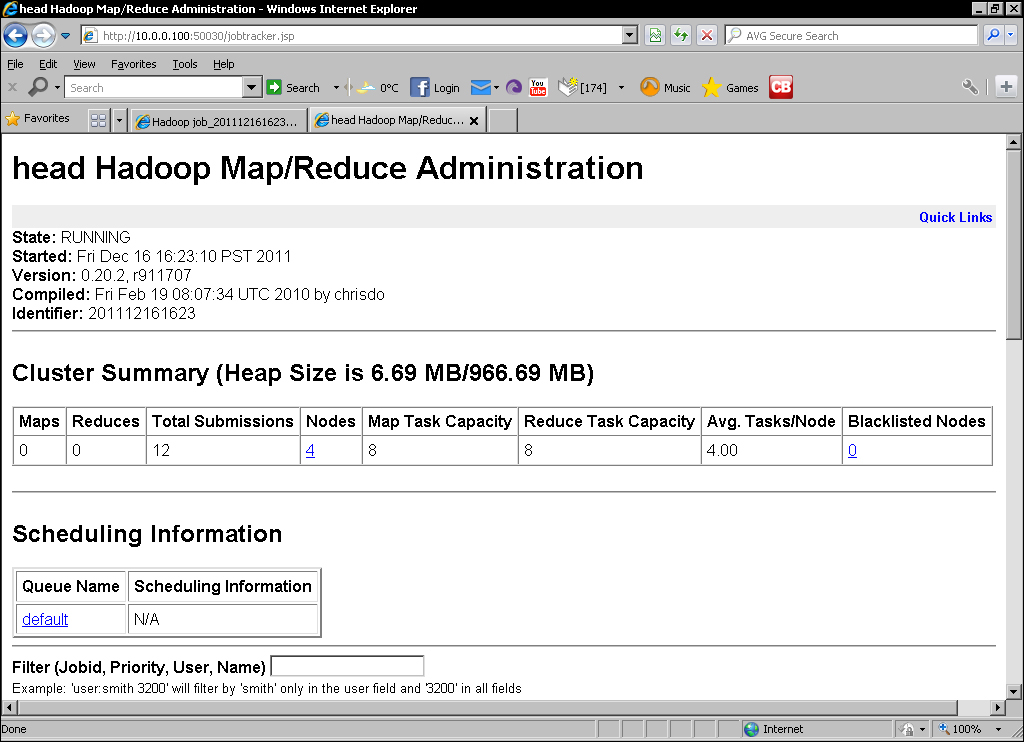
- Start a long-running MapReduce job; the example pi estimator with large values is great for this:
$ Hadoop jar Hadoop/Hadoop-examples-1.0.4.jar pi 2500 2500 - Now log onto a cluster node and use
jpsto identify the TaskTracker process:$ jps 21822 TaskTracker 3918 Jps 3891 DataNode
- Kill the TaskTracker process:
$ kill -9 21822 - Verify that the TaskTracker is no longer running:
$jps 3918 Jps 3891 DataNode
- Go back to the MapReduce web UI and after 10 minutes you should see that the number of nodes and available map/reduce slots change as shown in the following screenshot:
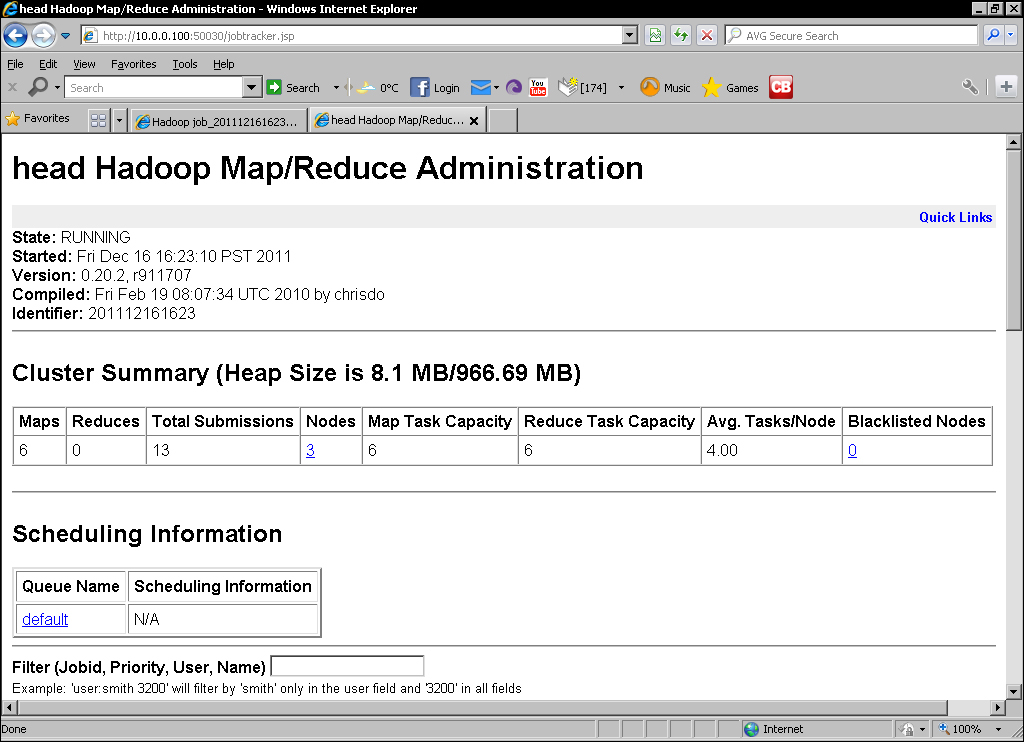
- Monitor the job progress in the original window; it should be proceeding, even if it is slow.
- Restart the dead TaskTracker process:
$ start-all.sh - Monitor the MapReduce web UI. After a little time the number of nodes should be back to its original number as shown in the following screenshot:
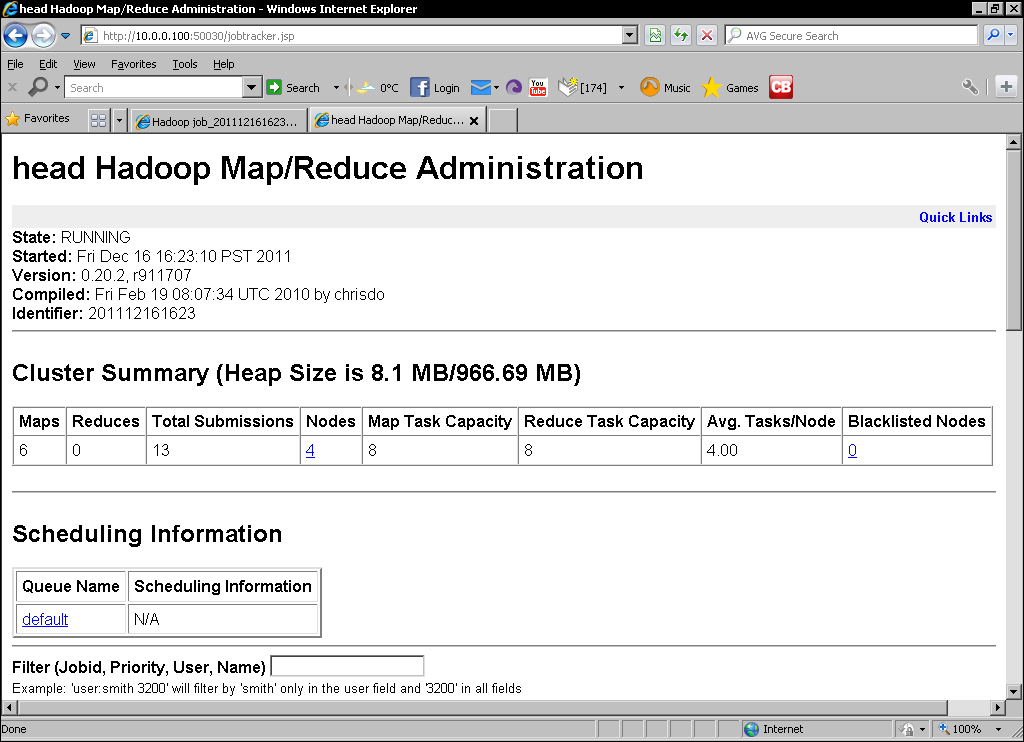
The MapReduce web interface provides a lot of information on both the cluster as well as the jobs it executes. For our interests here, the important data is the cluster summary that shows the currently executing number of map and reduce tasks, the total number of submitted jobs, the number of nodes and their map and reduce capacity, and finally, any blacklisted nodes.
The relationship of the JobTracker process to the TaskTracker process is quite different than that between NameNode and DataNode but a similar heartbeat/monitoring mechanism is used.
The TaskTracker process frequently sends heartbeats to the JobTracker, but instead of status reports of block health, they contain progress reports of the assigned task and available capacity. Each node has a configurable number of map and reduce task slots (the default for each is two), which is why we see four nodes and eight map and reduce slots in the first web UI screenshot.
When we kill the TaskTracker process, its lack of heartbeats is measured by the JobTracker process and after a configurable amount of time, the node is assumed to be dead and we see the reduced cluster capacity reflected in the web UI.
When a TaskTracker process is marked as dead, the JobTracker process also considers its in-progress tasks as failed and re-assigns them to the other nodes in the cluster. We see this implicitly by watching the job proceed successfully despite a node being killed.
After the TaskTracker process is restarted it sends a heartbeat to the JobTracker, which marks it as alive and reintegrates it into the MapReduce cluster. This we see through the cluster node and task slot capacity returning to their original values as can be seen in the final screenshot.
We'll not perform similar two or three node killing activities with TaskTrackers as the task execution architecture renders individual TaskTracker failures relatively unimportant. Because the TaskTracker processes are under the control and coordination of JobTracker, their individual failures have no direct effect other than to reduce the cluster execution capacity. If a TaskTracker instance fails, the JobTracker will simply schedule the failed tasks on a healthy TaskTracker process in the cluster. The JobTracker is free to reschedule tasks around the cluster because TaskTracker is conceptually stateless; a single failure does not affect other parts of the job.
In contrast, loss of a DataNode—which is intrinsically stateful—can affect the persistent data held on HDFS, potentially making it unavailable.
This highlights the nature of the various nodes and their relationship to the overall Hadoop framework. The DataNode manages data, and the TaskTracker reads and writes that data. Catastrophic failure of every TaskTracker would still leave us with a completely functional HDFS; a similar failure of the NameNode process would leave a live MapReduce cluster that is effectively useless (unless it was configured to use a different storage system).
Our recovery scenarios so far have assumed that the dead node can be restarted on the same physical host. But what if it can't due to the host having a critical failure? The answer is simple; you can remove the host from the slave's file and Hadoop will no longer try to start a DataNode or TaskTracker on that host. Conversely, if you get a replacement machine with a different hostname, add this new host to the same file and run start-all.sh.
Note
Note that the slave's file is only used by tools such as the start/stop and slaves.sh scripts. You don't need to keep it updated on every node, but only on the hosts where you generally run such commands. In practice, this is likely to be either a dedicated head node or the host where the NameNode or JobTracker processes run. We'll explore these setups in Chapter 7, Keeping Things Running.
Though the failure impact of DataNode and TaskTracker processes is different, each individual node is relatively unimportant. Failure of any single TaskTracker or DataNode is not a cause for concern and issues only occur if multiple others fail, particularly in quick succession. But we only have one JobTracker and NameNode; let's explore what happens when they fail.