
So far, we've examined all the building blocks needed to build a Convolutional Neural Network (CNN), and that's exactly what we are going to do in this section, where we explain why convolution is so efficient and widely used.
Here's the architecture of a CNN:
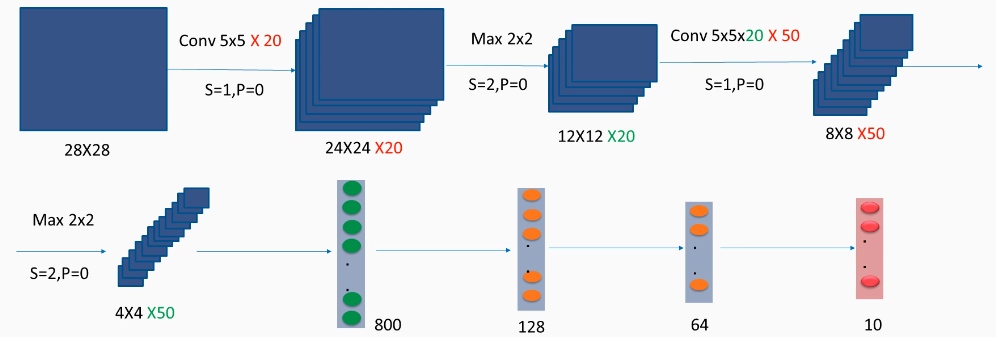
First, we start with a 28 x 28 grayscale image, so we have one channel that's just a black-and-white image. For now, it doesn't really matter, but these are handwritten digit images taken from the MNIST dataset that we saw in the previous chapter.
In the first layer, we'll apply a 5 x 5 filter, a convolution feed filter, with a stride of 1 and no padding, and, applying the formula we saw in the previous section will give us a 24 x 24 output matrix. But since we want a higher number of channels, in order to capture more features, we will apply 20 of these filters, and that gives us the final output of 24 x 24 x 20. So we have a 24 x 24 matrix. In the next layer, we'll apply a max pooling of 2 x 2, a stride of 2, and no padding. That basically shrinks the first two dimensions' widths by dividing by 2, so we'll have 12 x 12, and max pooling leaves the third dimension untouched, so we'll have 20 as the number of channels at the input.
In the next layer, we'll apply a convolution of 5 x 5, again with a stride of 1 and no padding. Since the input now has 20 channels, we have to have 20 of these 5 x 5 filters. So each of these filters will be convolved separately with each of these 20 channels and, in the end, the product will be totaled to give just one matrix: 8 x 8. But again, since we want a higher number of channels, in this case 50, we need to apply 50 structures of 5 x 5 x 20.
So, in a few words: convolving 5 x 5 x 20 with 12 x 12 x 20 will give us just one matrix, and having 50 such filters will give us 8 x 8 x 50.
In the fourth layer, and in the last convolution layer, we'll have max pooling again, 2 x 2, a stride of 2, and no padding. That divides the first dimensions by 2 and leaves the number of channels untouched. At the fourth layer, the convolution part is finished.
Now, we're going to use a simple neural network, full of connected hidden layers, that we've already seen. The output of the convolution will be transformed to a one-dimensional vector, with 800 inputs; there are 800 because that's simply the result of 4 x 4 x 50. Each of these 800 inputs will be fully connected with the first dense layer or the hidden layer, which will have 128 neurons, and then the activation's of these 128 neurons will be fully connected with the second hidden layer of 64 neurons. Then, through a softmax, we'll have 10 different classes, each representing digits, the prediction of digits from 0 to 9. And, as we'll see, this modified architecture will give us a much higher accuracy – more than 99%, instead of the 97% that we were stuck at.