
In this section, we'll see how a 1 x 1 convolution will enable us to build a really interesting network architecture, that is, the inception network. Also, we'll go through the details of why a 1 x 1 convolution is so efficient, and see how GoogLeNet is built on top of this.
First, let's go through a 1 x 1 convolution. It looks really simple, but is very useful. For example, let's assume that we have a 4 x 4 x 1 input matrix and we want to convolve that with a 1 x 1 stride one filter, and, for the sake of argument, let's suppose that the cell value is 4, so it's just a constant:

Then, the convolution will be effected as follows:
- We start with the top-left position and just multiply the cell value by 4, that is 16 * 4, and the result is 64, as highlighted in the following screenshot:

Then as we move right, to the second cell, we multiply it by 4, and we get 88, as shown in the following screenshot:
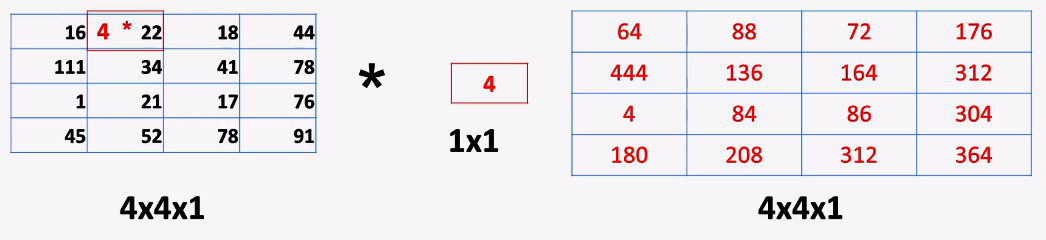
Then again, as we move to the right and multiple the third cell value by 4, we have 72:

Similarly, we get 176 in the fourth cell, as shown in the following screenshot:

Since we can't go any further to the right, we go 1 step down, and we have 4 multiplied by 111, which makes 444, as is highlighted in the following screenshot:

Then we go right, and then again down, until we end up in the bottom-right cell, which is the last one and makes 364.
The output matrix was just multiplying the input by 4. Even if we let the neural network figure out this value, it will still be multiplied by the constant, and it doesn't look very useful. Let's see another example; instead of having 1 channel, let's suppose that we have 64 channels, as shown in the following diagram. This means that we also need to have a 1 x 1 x 64 filter. The number of channels must match. And this filter will move on this input, for example, at this position. What it will do is multiply all the selected cells and then it will total them up, and all this will produce just one value:

Before producing the sum, we may apply a ReLU function. We saw that we just total this up, but usually, with a 1 x 1 convolution, you apply it to a ReLU function and then the output is sent to the output matrix. Then, we move to another position and do the same thing. We multiply, we sum, and we put this to a ReLU function, and then put it as the output. We will apply many of these 1 x 1 x 64 values, and together we should obtain 4 x 4 x 64, which is depicted in the following diagram:

For example, if we suppose the third dimension is 128, we will obtain an output of 4 x 4 x 128.
Now it's clear that a 1 x 1 convolution is really useful. It did a certain amount of multiplication summing, and even used ReLU to figure out more complex functions; at the same time, it increased the number of channels in order to capture more features. But one question still remains: we can do all this with 5 x 5 or 3 x 3 filters too, so what's so special about this 1 x 1 convolution? In order to see that, let's suppose that we have an input matrix with 4 x 4 x 128, and we want an output of 4 x 4 x 32:

One way to achieve that is by using a convolution same, 5 x 5 x 32. So, 4 x 4 x 128 is multiplied by the filter dimensions of 5 x 5 x 32, which gives us 1.64 million multiplication operations.
Now, let's try to do it a bit differently. Before applying this filter, let's suppose that we apply the convolution of 1 x 1 x 16, and that gives us a 4 x 4 x 16 output, as shown in the following diagram. Let's count the number of multiplications here:

Again, it will be these numbers multiplied together, and this gives us 33,000 multiplications. Now we apply the convolution same of 5 x 5 x 32. As shown in the preceding diagram it gives us exactly what we want, which is a 4 x 4 x 32 output. Let's count the number of multiplications, which makes 240,000 multiplications, as shown in the following screenshot:

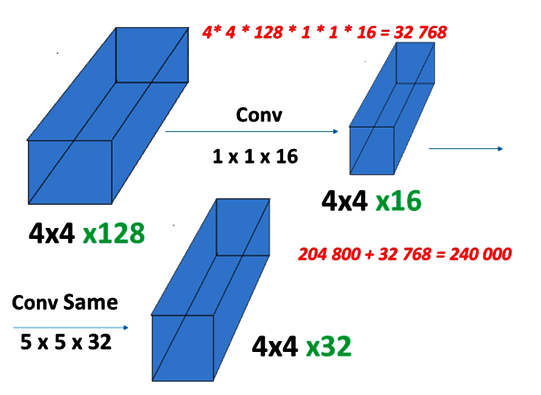
It's much less than the 1,640,000 shown in the preceding diagram, and it was approximately seven times smaller than the number of multiplications when we use a convolution same directly. In reality, the difference would be even more dramatic, because these two dimensions aren't that low. We saw that for RGB and the VGG-16, these were 224 x 224. Sometimes, the difference is 10 times and this could be like 10 millionths of 15 minutes and it's just 1,000,000. Now notice how this 1 x 1 x 16 convolution acted as a kind of bottleneck; somehow, it relaxed the dimensions a bit, when we apply the more expensive filter, it didn't blow up to millions of operations, it lowered down a bit, and then we applied an extensive filter. It's just a bottleneck to lower the computational cost.
Let's understand the inner workings of the inception network depicted in the following diagram:

The working is as follows:
- The first step is to apply a bottleneck, as we've learned to lower the computational cost. To supply the bottleneck, we apply a max pooling of 3 x 3.
- Apply more expensive filters, such as 3 x 3 and 5 x 5, but in this case, we're comfortable with a 1 x 1 convolution. Each of them separately will produce an output based on the filter used. The first two dimensions stay the same. After we concatenate all of these values, we should have an output of 28 x 28 x 256.
GoogLeNet uses several of these blocks together, and this output is just to measure the occurrence in the middle of the network, near the end, and maybe at the beginning. It's to see whether the progress from one layer to the deeper layers has been meaningful. Basically, you can just keep this block out and GoogLeNet just applies these blocks together. And merely a 1 x 1 convolution in 2015, enabled GoogLeNet to have a much deeper architecture and achieve outstanding results.