
AdaBoost can also be interpreted as a stagewise forward approach to minimizing an exponential loss function for a binary y ∈ [-1, 1] at each iteration m to identify a new base learner hm with the corresponding weight αm to be added to the ensemble, as shown in the following formula:

This interpretation of the AdaBoost algorithm was only discovered several years after its publication. It views AdaBoost as a coordinate-based gradient descent algorithm that minimizes a particular loss function, namely exponential loss.
Gradient boosting leverages this insight and applies the boosting method to a much wider range of loss functions. The method enables the design of machine learning algorithms to solve any regression, classification, or ranking problem as long as it can be formulated using a loss function that is differentiable and thus has a gradient. The flexibility to customize this general method to many specific prediction tasks is essential to boosting's popularity.
The main idea behind the resulting Gradient Boosting Machines (GBM) algorithm is the training of the base learners to learn the negative gradient of the current loss function of the ensemble. As a result, each addition to the ensemble directly contributes to reducing the overall training error given the errors made by prior ensemble members. Since each new member represents a new function of the data, gradient boosting is also said to optimize over the functions hm in an additive fashion.
In short, the algorithm successively fits weak learners hm, such as decision trees, to the negative gradient of the loss function that is evaluated for the current ensemble, as shown in the following formula:

In other words, at a given iteration m, the algorithm computes the gradient of the current loss for each observation and then fits a regression tree to these pseudo-residuals. In a second step, it identifies an optimal constant prediction for each terminal node that minimizes the incremental loss that results from adding this new learner to the ensemble.
This differs from standalone decision trees and random forests, where the prediction depends on the outcome values of the training samples present in the relevant terminal or leaf node: their average, in the case of regression, or the frequency of the positive class for binary classification. The focus on the gradient of the loss function also implies that gradient boosting uses regression trees to learn both regression and classification rules since the gradient is always a continuous function.
The final ensemble model makes predictions based on the weighted sum of the predictions of the individual decision trees, each of which has been trained to minimize the ensemble loss given the prior prediction for a given set of feature values, as shown in the following diagram:
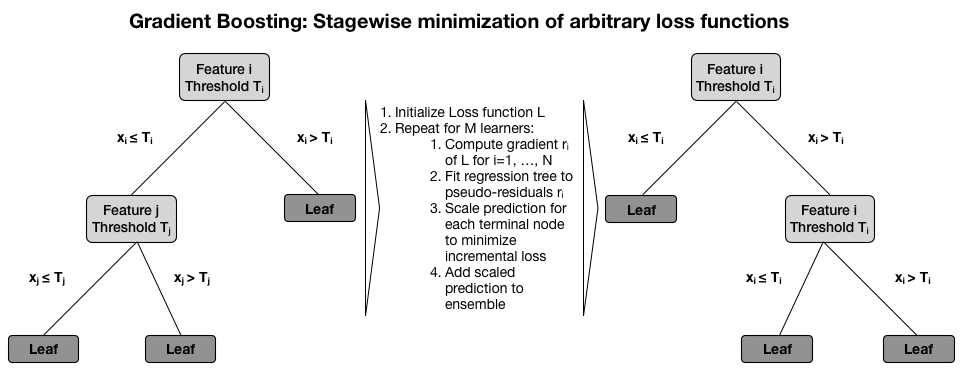
Gradient boosting trees have demonstrated state-of-the-art performance on many classification, regression, and ranking benchmarks. They are probably the most popular ensemble learning algorithm both as a standalone predictor in a diverse set of machine learning competitions, as well as in real-world production pipelines, for example, to predict click-through rates for online ads.
The success of gradient boosting is based on its ability to learn complex functional relationships in an incremental fashion. The flexibility of this algorithm requires the careful management of the risk of overfitting by tuning hyperparameters that constrain the model's inherent tendency to learn noise as opposed to the signal in the training data.
We will introduce the key mechanisms to control the complexity of a gradient boosting tree model, and then illustrate model tuning using the sklearn implementation.