
The most important algorithmic innovations lower the cost of evaluating the loss function by using approximations that rely on second-order derivatives, resembling Newton's method to find stationary points. As a result, scoring potential splits during greedy tree expansion is faster relative to using the full loss function.
As mentioned previously, a gradient boosting model is trained in an incremental manner with the goal of minimizing the combination of the prediction error and the regularization penalty for the ensemble HM. Denoting the prediction of the outcome yi by the ensemble after step m as ŷi(m), l as a differentiable convex loss function that measures the difference between the outcome and the prediction, and Ω as a penalty that increases with the complexity of the ensemble HM, the incremental hypothesis hm aims to minimize the following objective:
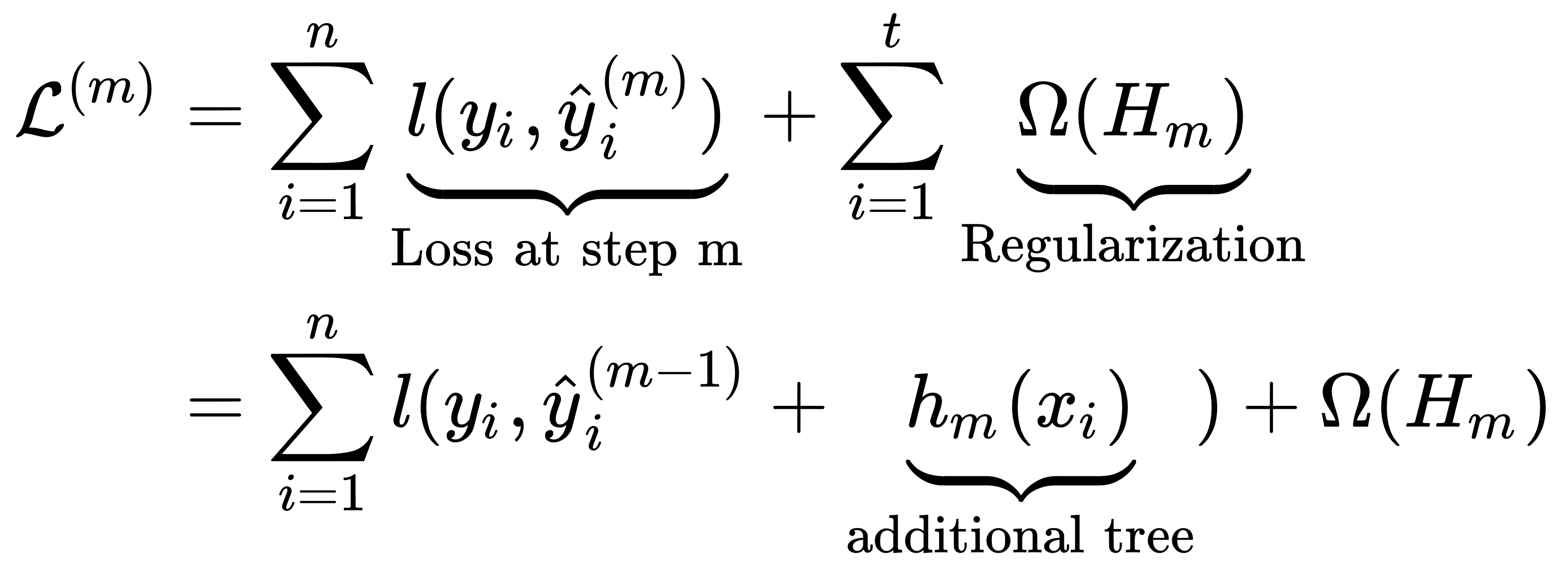
The regularization penalty helps to avoid overfitting by favoring the selection of a model that uses simple and predictive regression trees. In the case of XGBoost, for example, the penalty for a regression tree h depends on the number of leaves per tree T, the regression tree scores for each terminal node w, and the hyperparameters γ and λ. This is summarized in the following formula:
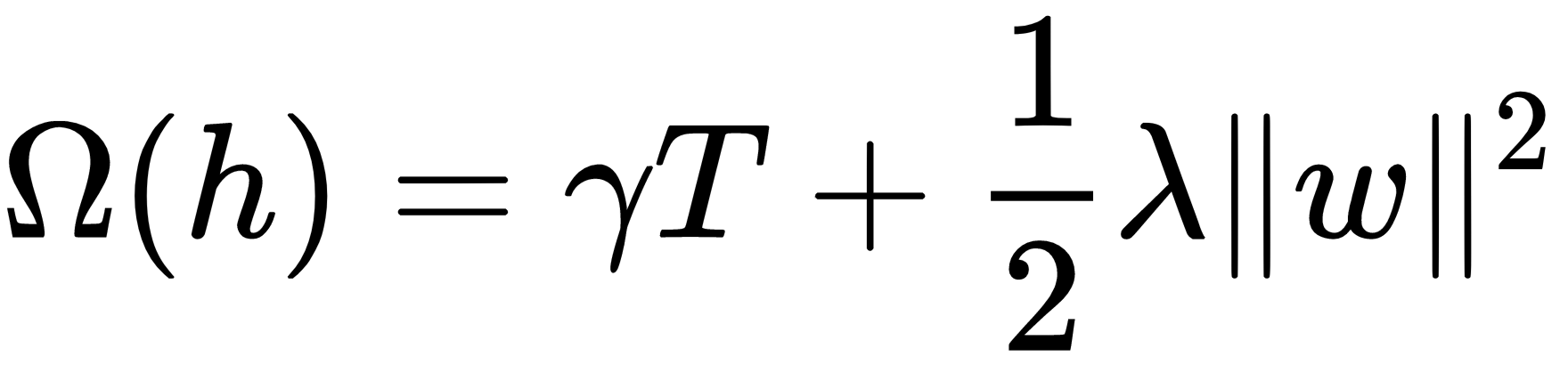
Therefore, at each step, the algorithm greedily adds the hypothesis hm that most improves the regularized objective. The second-order approximation of a loss function, based on a Taylor expansion, speeds up the evaluation of the objective, as summarized in the following formula:

Here, gi is the first-order gradient of the loss function before adding the new learner for a given feature value, and hi is the corresponding second-order gradient (or Hessian) value, as shown in the following formulas:
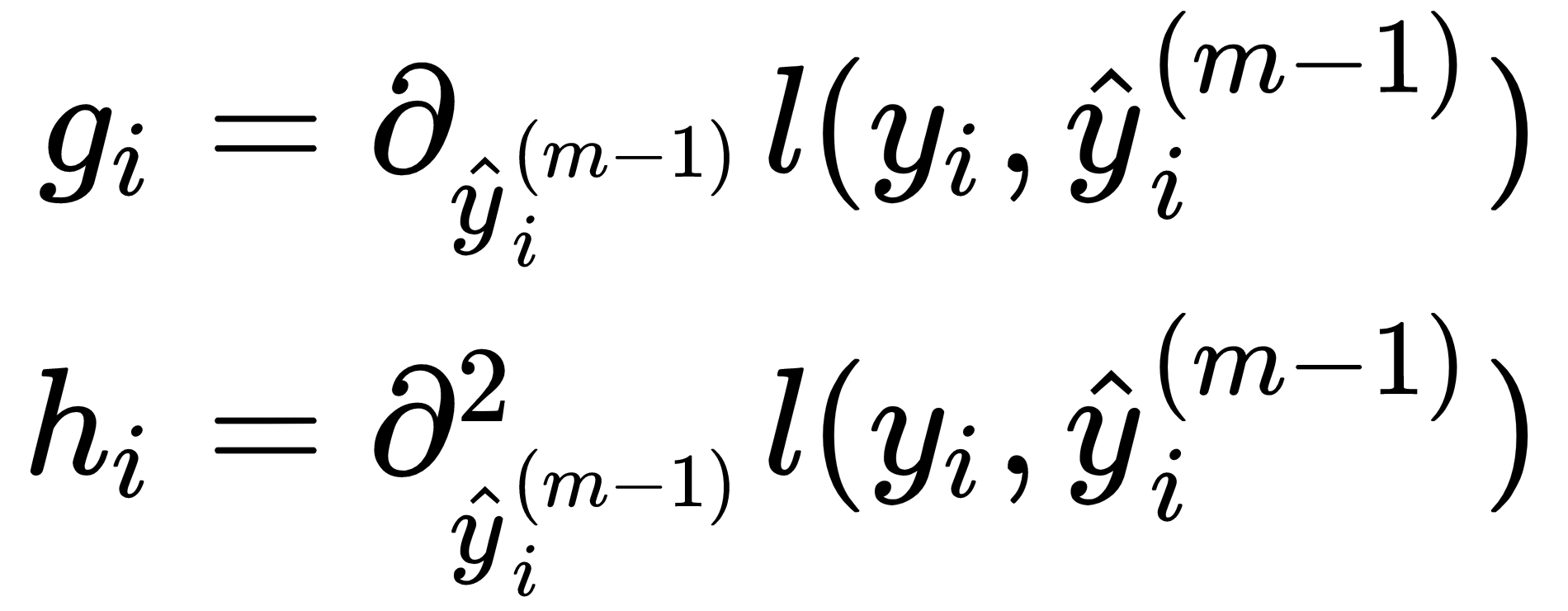
The XGBoost algorithm was the first open-source algorithm to leverage this approximation of the loss function to compute the optimal leave scores for a given tree structure and the corresponding value of the loss function. The score consists of the ratio of the sums of the gradient and Hessian for the samples in a terminal node. It uses this value to score the information gain that would result from a split, similar to the node impurity measures we saw in the previous chapter, but applicable to arbitrary loss functions (see the references on GitHub for the detailed derivation).