
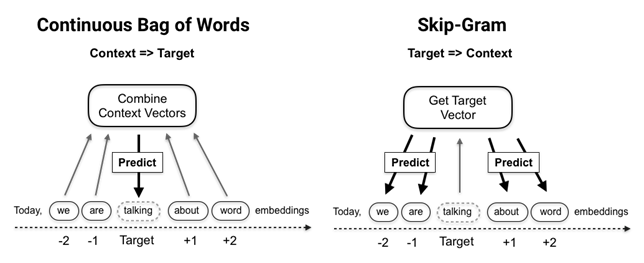
A Word2vec model is a two-layer neural net that takes a text corpus as input and outputs a set of embedding vectors for words in that corpus. There are two different architectures to learn word vectors efficiently using shallow neural networks depicted in the following figure:
- The Continuous-Bag-Of-Words (CBOW) model predicts the target word using the average of the context word vectors as input so that their order does not matter. A CBOW model trains faster and tends to be slightly more accurate for frequent terms, but pays less attention to infrequent words.
- The Skip-Gram (SG) model, by contrast, uses the target word to predict words sampled from the context. It works well with small datasets and finds good representations even for rare words or phrases:
Hence, the Word2vec model receives an embedding vector as input and computes the dot product with another embedding vector. Note that, assuming normed vectors, the dot product is maximized (in absolute terms) when vectors are equal, and minimized when they are orthogonal.
It then uses backpropagation to adjust the embedding weights in response to the loss computed by an objective function due to any classification errors. We will see in the next section how Word2vec computes the loss.
Training proceeds by sliding the context window over the documents, typically segmented into sentences. Each complete iteration over the corpus is called an epoch. Depending on the data, several dozen epochs may be necessary for vector quality to converge.
Technically, the SG model has been shown to factorize a word-context matrix that contains the pointwise mutual information of the respective word and context pairs implicitly (see references on GitHub).