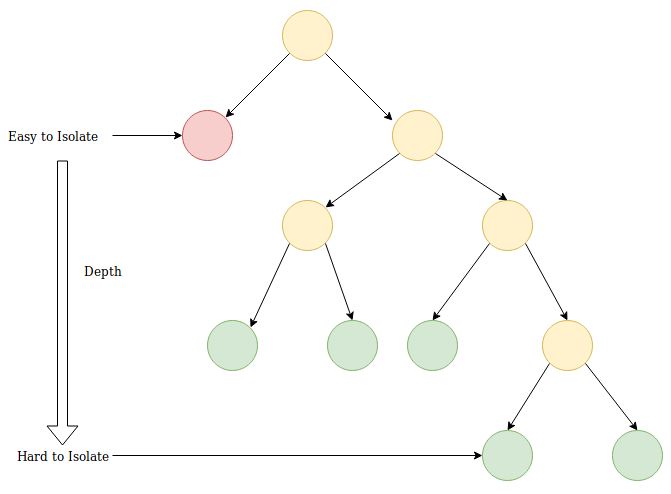
The idea of an isolation forest is based on the Monte Carlo principle: a random partitioning of the feature space is carried out so that, on average, isolated points are cut off from normal ones. The final result is averaged over several runs of the stochastic algorithm, and the result will form an isolation forest of corresponding trees. The isolation tree algorithm then builds a random binary decision tree. The root of the tree is the whole feature space. In the next node, a random feature and a random partitioning threshold are selected, and they are sampled from a uniform distribution on the range of the minimum and maximum values of the selected feature. The stopping criterion is the identical coincidence of all objects in the node, which means that the decision tree's construction has finished. The mark of the leaves is the anomaly_score value of the algorithm, which is the depth of the leaves in the constructed tree. The following formula shows how the anomaly score can be calculated:

Here, 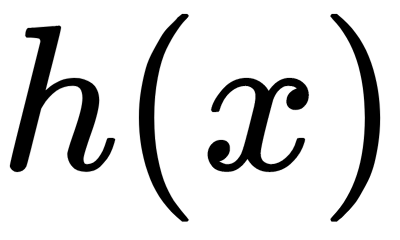 is the path length of the observation,
is the path length of the observation, 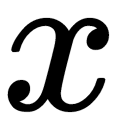 ,
, 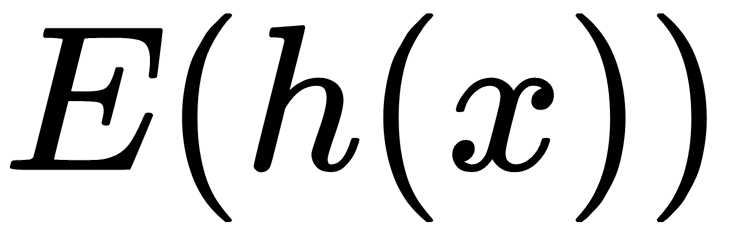 is an average of
is an average of 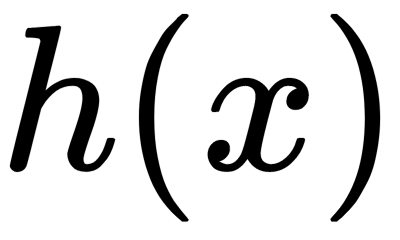 from a collection of isolation trees,
from a collection of isolation trees, 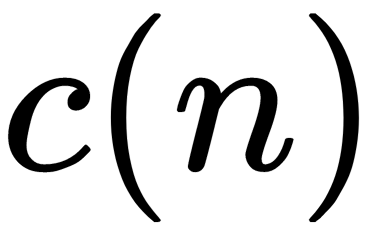 is the average path length of the unsuccessful search in a binary search tree, and
is the average path length of the unsuccessful search in a binary search tree, and 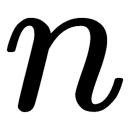 is the number of external nodes.
is the number of external nodes.
We're assuming that it is common for anomalies to appear in leaves with a low depth, which is close to the root, but for regular objects, the tree will build several more levels. The number of such levels is proportional to the size of the cluster. Consequently, anomaly_score is proportional to the points lying in it.
This assumption means that objects from clusters of small sizes (which are potentially anomalies) will have a lower anomaly_score than those from clusters of regular data: