Anomaly detection algorithms in the Shogun library are represented with the OCSVM algorithm. This algorithm is implemented in two classes: CSVMLightOneClass and CLibSVMOneClass. Note that they have different backends for SVM implementation: the former uses the SVMLight library (http://svmlight.joachims.org/), while the latter uses the LibSVM library (https://www.csie.ntu.edu.tw/~cjlin/libsvm/).
Let's start by looking at using the CLibSVMOneClass class for anomaly detection:
auto csv_file = some<CCSVFile>(dataset_name.string().c_str());
Matrix data;
data.load(csv_file);
Matrix train = data.submatrix(0, 50);
train = train.clone();
Matrix test = data.submatrix(50, data.num_cols);
test = test.clone();
// create a dataset
auto features = some<CDenseFeatures<DataType>>(train);
auto test_features = some<CDenseFeatures<DataType>>(test);
auto gauss_kernel = some<CGaussianKernel>(features, features, 0.5);
auto c = 0.5;
auto svm = some<CLibSVMOneClass>(c, gauss_kernel);
svm->train(features);
double dist_threshold = -3.15;
auto detect = [&](Some<CDenseFeatures<DataType>> data) {
auto labels = svm->apply(data);
for (int i = 0; i < labels->get_num_labels(); ++i) {
auto dist = labels->get_value(i);
if (dist > dist_threshold) {
// Do something with anomalies
} else {
// Do something with normal
}
}
};
detect(features);
detect(test_features);
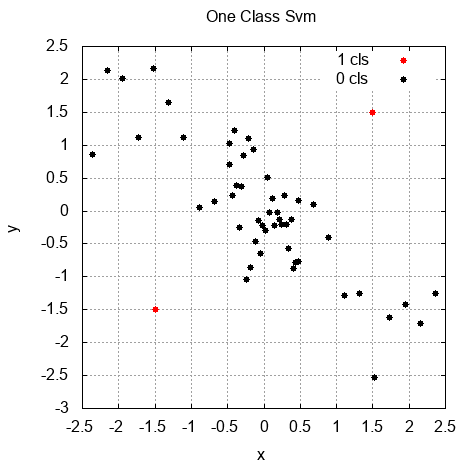
First, we loaded the dataset from the CSV file so that it's an object of the Matrix type and split it into two parts for training and testing. Then, we declared objects of the CDenseFeatures type in order to use loaded data in the Shogun algorithms. Next, we declared the kernel object of the CGaussianKernel type and used it to initialize the SVM algorithm object of the CLibSVMOneClass type. Note that the SVM object also takes a parameter that controls the smoothness of the solution. After we had the SVM object in place, we used the train() method with the training dataset to fit the algorithm to our data. Finally, we defined a distance threshold and used the apply() method on each of the datasets to detect anomalies. Notice that we used a different threshold value here than for the Dlib implementation. The following graph shows that the result of this algorithm is the same as our multivariate Gaussian distribution approach. The two samples from the dataset were detected as anomalies because they were artificially added to the dataset: