
Since we've discussed Q-learning, I want to spend the rest of this chapter highlighting some fantastic work done by Kenan Deen. His Tower of Hanoi solution is a great example of how you can use reinforcement learning to solve real-world problems.
This form of reinforcement learning is more formally known as a Markov Decision Process (MDP). An MDP is a discrete-time stochastic control process, which means that at each time step, the process is in state x. The decision maker may choose any available action for that state, and the process will respond at the next time step by randomly moving into a new state and giving the decision maker a reward. The probability that the process moves into its new state is determined by the chosen action. So, the next state depends on the current state and the decision maker's action. Given the state and the action, the next move is completely independent of all previous states and actions.
The Tower of Hanoi consists of three rods and several sequentially sized disks in the leftmost rod. The objective is to move all the disks from the leftmost rod to the rightmost one with the fewest possible number of moves.
Two important rules you have to follow are that you can move only one disk at a time, and you can't put a bigger disk on top of a smaller one; that is, in any rod, the order of disks must always be from the largest disk at the bottom to the smallest disk at the top, depicted as follows:

Let's say we are using three disks, as pictured just now. In this scenario, there are 33 possible states, shown as follows:
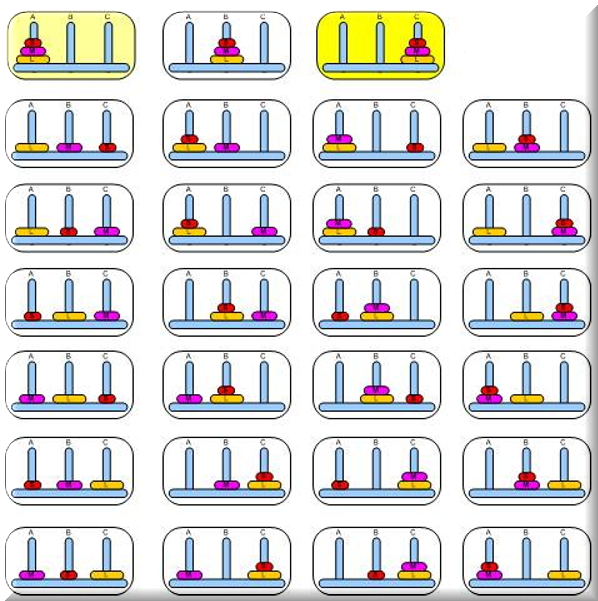
The total number of all possible states in a Tower of Hanoi puzzle is 3 raised to the number of disks.
Where ||S|| is the number of elements in the set states, and n is the number of disks.
So, in our example, we have 3 x 3 x 3 = 27 unique possible states of the distribution of disks over the three rods, including empty rods; but two empty rods can be in a state at max.
With the total number of states being defined, here are all the possible actions our algorithm has available to move from one state to another:

The least possible number of moves for this puzzle is:
LeastPossibleMoves = 2n - 1
Where n is the number of disks.
The Q-learning algorithm can be formally defined as follows:

In this Q-learning algorithm, we have the following variables being used:
- Q matrix: A 2D array that, at first, is populated with a fixed value for all elements (usually 0). It is used to hold the calculated policy over all states; that is, for every state, it holds the rewards for the respective possible actions.
- R matrix: A 2D array that holds the initial rewards and allows the program to determine the list of possible actions for a specific state.
- Discount factor: Determines the policy of the agent in how it deals with rewards. A discount factor closer to 0 will make the agent greedy by only considering current rewards, while a discount factor approaching 1 will make it more strategic and farsighted for better rewards in the long run.
We should briefly highlight some of the methods of our Q-learning class:
- Init: Called for generation of all possible states as well as for the start of the learning process.
- Learn: Has sequential steps for the learning process.
- InitRMatrix: This initializes the reward matrix with one of these values:
- 0: We do not have information about the reward when taking this action in this state
- X: There is no way to take this action in this state
- 100: This is our big reward in the final state, where we want to go
- TrainQMatrix: Contains the actual iterative value update rule of the Q matrix. When completed, we expect to have a trained agent.
- NormalizeQMatrix: This normalizes the values of the Q matrix making them percentages.
- Test: Provides textual input from the user and displays the optimal shortest path to solve the puzzle.
Let's look deeper into our TrainQMatrix code:
private void TrainQMatrix(int _StatesMaxCount)
{
pickedActions = new Dictionary<int, int>();
// list of available actions (will be based on R matrix which
// contains the allowed next actions starting from some state as 0 values in the array
List<int> nextActions = new List<int>();
int counter = 0;
int rIndex = 0;
// _StatesMaxCount is the number of all possible states of a puzzle
// from my experience with this application, 4 times the number
// of all possible moves has enough episodes to train Q matrix
while (counter < 3 * _StatesMaxCount)
{
var init = Utility.GetRandomNumber(0, _StatesMaxCount);
do
{
// get available actions
nextActions = GetNextActions(_StatesMaxCount, init);
// Choose any action out of the available actions randomly
if (nextActions != null)
{
var nextStep = Utility.GetRandomNumber(0, nextActions.Count);
nextStep = nextActions[nextStep];
// get available actions
nextActions = GetNextActions(_StatesMaxCount, nextStep);
// set the index of the action to take from this state
for (int i = 0; i < 3; i++)
{
if (R != null && R[init, i, 1] == nextStep)
rIndex = i;
}
// this is the value iteration update rule, discount factor is 0.8
Q[init, nextStep] = R[init, rIndex, 0] + 0.8 * Utility.GetMax(Q, nextStep, nextActions);
// set the next step as the current step
init = nextStep;
}
}
while (init != FinalStateIndex);
counter++;
}
}
Running the application with three disks:

Running the application with four disks:

And here's running with seven disks. The optimal number of moves is 127, so you can see how fast the solution can multiply the possible combinations:
