

96 High Performance Visualization
FIGURE 6.3: Data sets used for IC tests. Integral curves through the mag-
netic field of a GenASiS supernova simulation (left). Image courtesy of David
Pugmire (ORNL), data courtesy of Anthony Mezzacappa (ORNL). Integral
curves through the magnetic field of a NIMROD fusion simulation (right).
Image courtesy of David Pugmire (ORNL), data courtesy of Scott Kruger
(Tech-X Corporation).
a number of spatially disjoint data blocks. Each block may or may not have
ghost cells for connectivity purposes. Each block has a timestep associated
with it. Thus, two blocks that occupy the same space at different times are
considered independent.
6.3.1 Test Data
To cover a wide range of potential problem characteristics, different seeding
scenarios and different data sets were used in the performance experiments
that follow. Although the techniques here are readily applicable to any mesh
type and decomposition scheme, the data sets discussed here are multi-block
and rectilinear. The simplest type of data representation was intentionally
chosen, in order to exclude additional performance complexities that arise
with more complex mesh types.
Astrophysics. The astrophysics test data is the magnetic field from a
GenASiS code simulation of a core-collapse supernova. The search for the ex-
plosion mechanism of core-collapse supernovae and the computation of the
nucleosynthesis in these stellar explosions is one of the most important and
challenging problems in computational nuclear astrophysics. Understanding
the magnetic field around the core is a fundamental component of this re-
search, and IC analysis has proven to be an effective technique. The test
data was computed by GenASiS, a multiphysics code being developed for the
simulation of astrophysical systems involving nuclear matter [2, 3]. GenASiS
Parallel Integral Curves 97
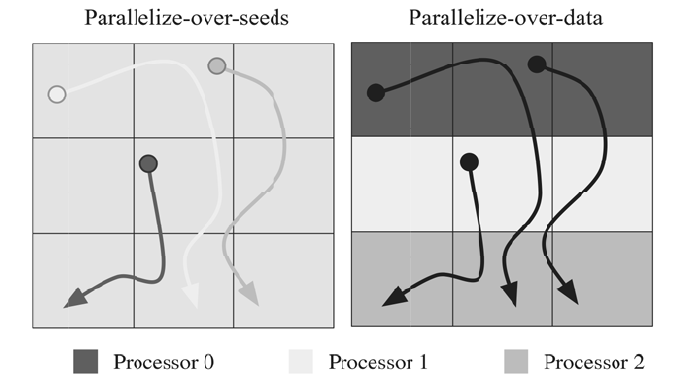
FIGURE 6.4: Parallelization over seeds versus parallelization over data algo-
rithms.
computes the magnetic field at each cell face. For the purposes of this study,
a cell-centered vector was computed by differencing the values at the faces in
the X, Y, and Z directions. Node-centered vectors are computed by averaging
adjacent cells to each node. To see how this algorithm would perform on very
large data sets, the magnetic field was upsampled onto a total 512 blocks with
1 million cells per block. The dense seed set corresponds to seed points placed
randomly in a small box around the collapsing core, whereas the sparse seed
test places streamline seed points randomly throughout the entire data set
domain.
Fusion. The second data set is from a simulation of magnetically con-
fined fusion in a tokamak device. The development of magnetic confinement
fusion, which may be a future source for low-cost power, is an important area
of research. Physicists are particularly interested in using magnetic fields to
confine the burning plasma in a toroidal-shaped device, known as a tokamak.
To achieve stable plasma equilibrium, the field lines of these magnetic fields
need to travel around the torus in a helical fashion. By using streamlines, the
scientist can see and better understand the magnetic fields. The simulation
was performed using the NIMROD code [12]. This data set has the unusual
property that most streamlines are approximately closed and they repeatedly
traverse the torus-shaped vector field domain. This behavior stresses the data
cache.

98 High Performance Visualization
6.3.2 Parallelization Over Seed Points
The first of the traditional algorithms is one that parallelizes over the
axis of particles. In this algorithm, shown in Figure 6.4, the seed points, or
particles, are uniformly assigned across the set of processors. Thus, given n
processors, 1/n of the seed points are assigned to each processor. To enhance
spatial locality, the seed points are sorted spatially before they are assigned
to the processors. As outlined in Algorithm 1, each processor integrates the
particles assigned to it until termination, or until the point exits the spatial
data block. As particles move between blocks, each processor loads the appro-
priate block into memory. In order to minimize I/O, each processor integrates
all particles to the edge of the loaded blocks, loading a block from a disk only
when there is no more work to be done on the in-memory blocks. Each par-
ticle is only ever owned by one processor; however, blocks may be loaded by
multiple processors. Each processor terminates independently when all of its
streamlines have terminated.
In order to manage the handling of blocks, this algorithm makes use of
the data block caching in a least-recently used (LRU) fashion. If there is in-
sufficient memory for additional blocks when a new block must be loaded,
the block that is purged is that which was least recently used. Clearly, hav-
ing more main memory available decreases the need for I/O operations and
increases the performance of this algorithm.
Another method for the handling of data blocks was introduced by Camp
et al. 2011 [1], where an extended hierarchy of memory layers is used for data
block management. When using a local disk, either SSD or hard drive, careful
management of data block movement shows an increase in overall performance
by about 2×.
Algorithm 1 Parallelization Over Seed Points Algorithm
while not done do
activeParticles = particles that reside in a loaded data block
inactiveParticles = particles that do not reside in a loaded data block
while activeParicles not empty do
advect particle
end while
if inactiveParticles then
Load a dataset from inactiveParticles
else
done = true
end if
end while
Advantages: This algorithm is straightforward to implement; it requires no
communication and is ideal if I/O requirements are known to be minimal.
Parallel Integral Curves 99
For example, if the entire mesh will fit into the main memory of a single
process, or if the flow is known to be spatially local, the I/O will be minimal.
In such cases, parallelization is trivial, and parallel scaling is expected to be
nearly ideal. Also, the risk of processor imbalance is minimized because of the
uniform assignment of seeds to processors.
Disadvantages: Because data blocks are loaded on demand, it is possible for
I/O to dominate this algorithm. For example, in a vector field with circular
flow and a data block cache that does not have large enough blocks, data will
be continuously loaded and purged in the LRU cache. Additionally, workload
imbalance is possible if the computational requirements for particles differ
significantly. For example, if some particles are advected significantly farther
than others, the processors assigned to these particles will be doing all the
work, while the others sit idle.
6.3.3 Parallelization Over Data
The second of the traditional algorithms is one that parallelizes over the
axis of data blocks. In this algorithm, shown in Figure 6.4, the data blocks
are statically assigned to the processors. Thus, given n processors, 1/n of the
data blocks are assigned to each processor. Each particle is integrated until it
terminates or leaves the blocks owned by the processor. As a particle crosses
block boundaries, it is communicated to the processor that owns the data
block. A globally maintained active particle count is maintained so that all
processors may monitor how many particles have yet to terminate. Once the
count goes to zero, all processors terminate.
Advantages: This algorithm performs the minimal amount of I/O, where
each data block is loaded once, and only once into memory. As I/O operations
are orders of magnitude more expensive than computation, this is a significant
advantage. This algorithm is well-suited to situations where the vector field is
known to be uniform and the seed points are known to be sparse.
Disadvantages: Because of the spatial parallelization, this algorithm is very
sensitive to seeding and vector field complexity. If the seeding is dense, only the
processors where the seeds lie spatially will do any work. All other processors
will be idle. Finally, in cases where the vector field contains critical points, or
invariant manifolds, points will be drawn to these spatial regions, increasing
the workload of some processors, while decreasing the work of the rest.
6.3.4 A Hybrid Approach to Parallelization
As outlined previously, parallelization over seeds or data blocks are subject
to workload imbalance. Because of the complex nature of vector field analy-
sis, it is often very difficult or impossible to know a priori which strategy

100 High Performance Visualization
Algorithm 2 Parallelization Over Data Algorithm
activeP articleCount = N
while activeP articleCount > 0 do
activeParticles = particles that reside in a loaded data block
inactiveParticles = particles that do not reside in a loaded data block
while activeParicles not empty do
advect particle
if particle terminates then
activeParticleCount = activeParticleCount - 1
Communicate activeParticleCount update to all
end if
if particle moves to another data block then
Send particle to process that owns data block
end if
end while
Receive incoming particles
Receive incoming particle count updates
end while
would be most efficient. In general, where smooth flow and complex flow exist
within the same data set, it is impossible to achieve perfectly scalable parallel
performance using the traditional algorithms.
Research has shown that the most effective solution is a hybrid approach,
where parallelization is performed over both seed points, and data blocks. In
hybrid approaches, the resource requirements are monitored and the realloca-
tion of resources can be done dynamically, based on the nature of a particular
vector field and a seeding scenario. By reallocating as needed, resources can
be dynamically used in the most efficient manner possible.
The algorithm introduced in Pugmire et al. [11] is a hybrid between paral-
lelization across particles and data blocks. This hybrid approach dynamically
partitions the workload of both particles and data blocks to processors in an
attempt to load balance on-the-fly, based on the processor workloads and the
nature of the vector field. It attempts to keep all processors busy while also
minimizing I/O by choosing either to communicate particles to other proces-
sors or to have processors load duplicate data blocks based on heuristics.
Since detailed knowledge of flow is often unpredictable or unknown, the
hybrid algorithm was designed to adapt during the computation to concen-
trate resources where they are needed, distributing particles where needed,
and/or duplicating blocks when needed. Workload monitoring and balancing
achieves parallelization across data blocks and particles simultaneously, and
the algorithm is able to adapt to the challenges posed by the varying the
characteristics of integration-based problems.
In the hybrid algorithm, the processors are divided up into sets of work
groups. Each work group consists of a single master process, and a group
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.