
176 High Performance Visualization
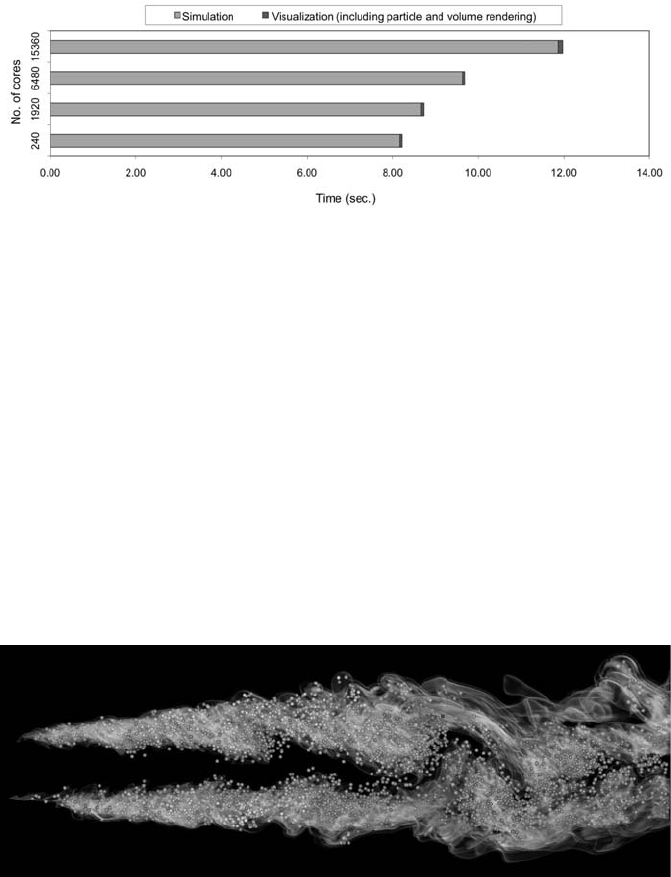
FIGURE 9.1: Timing results for both simulation and visualization using dif-
ferent numbers of cores. In this set of tests, the number of grid points on
each core is fixed so using more cores provides higher resolution calculations.
Visualization is computed every ten timesteps, which is at least 20–30 times
more frequent than usual. As shown, the visualization cost looks negligible.
The simulation time increases as more cores are used due to the communi-
cation required to exchange data after each iteration. The visualization time
also grows as more cores are used because of the communication required for
image compositing, but it grows at a much slower rate than the simulation
time.
FIGURE 9.2: Visualization of the particles and CH
2
O field.

In Situ Processing 177
simulation’s data is organized as an array of structures, and the visualization
system requires a structure of arrays, the simulation data must be reorga-
nized to match that of the visualization code, thus consuming more resources.
Conversely, adaptors for codes with very similar data structures may share
pointers to the simulation’s arrays with the visualization code, a “zero-copy”
scenario.
FIGURE 9.3: Diagram of the adaptor that connects fully featured visualiza-
tion systems with arbitrary simulation codes.
Tailored code and general co-processing share many of the same strengths
and weaknesses. Both approaches operate in the same address space as the
simulation, potentially operating on data directly without conversion. Both
approaches cause some extra code to be included in the simulation executable
and both may generate additional data, subtracting from the memory avail-
able to the simulation. This last property poses problems on many super-
computers, as the trend is to have less and less memory available per core.
Memory considerations are exacerbated for co-processing approaches since
adaptors may copy data and general visualization tools might have higher
memory usage requirements than tailored solutions. The two approaches may
also differ in their performance. Tailored code is optimized for the simulation
data structures, and so it may not match an optimal layout for already-written
general visualization algorithms. But it may be possible with tailored code to
optimize these algorithms for the simulation’s native data layout.
On the other hand, co-processing with general visualization tools can often
be easily enabled within a simulation through the addition of a few function
calls and by adding an adaptor layer. An adaptor code is far less complex
to create than the visualization routines themselves, often consisting of only
tens of lines of source code. Consequently, adaptor code is cheaper to develop
than tailored code and benefits from the use of existing well-exercised routines
from fully featured visualization systems. Furthermore, once the data are ex-
posed via the adaptor, they can be visualized in many ways using the general
178 High Performance Visualization
visualization system as opposed to a tailored approach, which might provide
highly optimized routines for creating limited types of visualizations.
9.3.1 Adaptor Design
A successful adaptor layer connecting computational simulations to general
purpose visualization tools will have several features inherent in its design:
• Maximize features and capabilities. There are numerous use cases for
visualization and analysis, particularly in situ.Focusinganin situ im-
plementation on a specific feature set, for example making movies, will
mean that important other use cases will be missing, like interactive
debugging. By adapting a general purpose, fully-featured visualization
and analysis tool, the in situ co-processing tasks gain the capability to
use many of these features, as long as the adaptor layer exposes the
simulation data properly to the tool.
• Minimize code modifications to simulations. The less effort it takes to
apply the adaptor to a new simulation, the more easily an in situ library
can be adopted by a wide range of codes in the HPC community. General
purpose tools are already capable of supporting the data model for a
wide range of simulation applications, so the barrier for translating data
structures should be minimal.
• Minimize impact to simulation codes when in use. Ideally, codes should
be able to run the same simulation with or without in situ analysis.
For example, the limited memory situation in distributed systems is
exacerbated by co-processing via shared computational nodes, and zero-
copy and similar features mitigate the negative impact.
• Zero impact to simulation codes when not active. Simulation codes
should be able to build a single executable, with in situ support built-in,
and suffer no detrimental side effects, such as reduced performance or
additional dependencies on libraries. Without this feature, users must
decide before running a simulation code—or worse, before compiling
it—whether or not they wish to pay a penalty for the possible use of in
situ capabilities, and may choose to forgo the option. Allowing users to
start an in situ session on demand enables many visualization and anal-
ysis tasks, like code debugging, that the user could not have predicted
beforehand.
9.3.2 High Level Implementation Issues
Co-processing is implemented successfully in the general visualization ap-
plications ParaView [9] and VisIt [35], two codes built on top of the Visual-
ization Toolkit (VTK) [23]. The codes are similar in many ways beyond their
In Situ Processing 179
mutual reliance on VTK, including their use of data flow networks to process
data. As described in Chapter 2, data flow networks are composed of various
interchangeable filters through which data flows from one end to the other
with transformations occurring in the filters. In an in situ context, the output
of the last filter in the data flow network is the product of the in situ oper-
ation. It may be a reduced data set, statistical results, or a rendered image.
For in situ use, both applications use adaptor layers to expose simulation data
to their visualization routines by ultimately creating VTK data sets that are
facades to the real simulation data. ParaView’s adaptor layer must be writ-
ten in C++ and it directly creates VTK objects that will be passed into its
data flow networks. VisIt adaptor layers may be written in C, Fortran, and
Python and also create VTK data sets that can pass through VisIt’s data flow
networks.
The co-processing strategies used by ParaView and VisIt are somewhat
different where the simulation interacts with the co-processing library. Para-
View’s co-processing library consists of a few top-level routines inserted into
the simulation’s main loop. The simulation data are transformed by the adap-
tor layer and passed into a co-processing routine, which constructs a data
flow network based on an XML specification from ParaView. The results of
the pipeline may be written to a disk or staged over the network to concurrent
resources, where ParaView may be used for further analysis. VisIt’s interaction
with the simulation emphasizes a more exploratory style of interaction where,
rather than executing fixed data flow networks, the VisIt client dynamically
connects to the simulation and directs it to create any number of data flow
networks. The end user can be involved with this process and decide which
analyses to perform on-the-fly. Since VisIt is able to send plotting commands
to the simulation, it integrates differently into the simulation’s main loop than
ParaView and its adaptor layer is executed only when necessary.
9.3.3 In Practice
This section explores Libsim,thein situ library in VisIt, in more detail.
Libsim wraps all of VisIt’s functionality in an interface that is accessible to
simulations. In effect, it transforms the simulation into the server in its client-
server design. Libsim has features consistent with the four design goals listed
in 9.3.1: it connects to VisIt, a fully-featured visualization and analysis tool
and can expose almost any type of data VisIt understands; it requires only a
handful of lines of code to instrument a simulation; it minimizes data copies
wherever possible; and it defers loading any heavyweight dependencies until
in situ analysis tasks begin.
There are two interfaces in Libsim: a control interface that drives the VisIt
server, and a data interface that hands data to the VisIt server upon request.
The control interface is contained in a small, lightweight static library that is
linked with the simulation code during compilation, and is literally a front-end
to a second, heavier-weight runtime library that is pulled in only when in situ
180 High Performance Visualization
analysis begins at runtime. The separation of Libsim into two pieces prevents
inflation of executable size, even after linking with Libsim, while still retaining
the ability to access the full VisIt feature set when it is needed.
The control interface is capable of advertising itself to authorized VisIt
clients, listening for incoming connections, initiating the connection back to
the VisIt client, handling VisIt requests like plot creation and data queries,
and letting the client know when the simulation has advanced and that new
data is available.
Several aspects of Libsim result in benefits for both interacting and inter-
facing with simulations. The separation between the front-end library and the
runtime library is one such aspect. In particular, modifications to simulation
codes to support Libsim can be minimal, as the front-end library contains
only approximately twenty simple control functions (most of which take no
arguments), and only as many data functions as the simulation code wishes
to expose. This separation also enables the front-end library to be written in
pure C. As such, despite VisIt being written in C++, no C++ dependencies
are introduced into the simulation by linking to the front-end library, which
is critical since many simulations are written in C and Fortran. Additionally,
by providing a C interface, the process of automatically generating bindings
to other programming languages, like Python, is greatly simplified. The sep-
aration into front-end and runtime library components also means that the
runtime library implementation is free to change as VisIt is upgraded, letting
the simulation benefit from these changes automatically, without relinking to
create a new executable. In addition, by deferring the heavyweight library
loading to runtime, there is effectively zero overhead and performance impact
on a simulation code linked with Libsim when the library is not in use.
Another beneficial aspect is the manner in which data are retrieved from
the simulations. First, as soon as an in situ connection is established, the sim-
ulation is queried for metadata containing a list of meshes and fields that the
simulation wishes to expose for analysis. The metadata comes from a function
in the adaptor layer. Just as in a normal VisIt operation, this list is trans-
mitted to the client, where users can generate plots and queries. Once the
user creates a plot and VisIt starts executing the plot’s data flow network, the
other functions in the simulation’s data adaptor layer are invoked to retrieve
only the data needed for the calculation. VisIt’s use of contracts (see 2.5.1)
ensures that the minimal set of variables will be exposed by the adaptor layer,
reducing any unnecessary data copying from converting variables that are not
involved in a calculation. Whenever possible, simulation array duplication is
avoided by including simulation arrays directly into the VTK objects, mini-
mizing the impact on the performance and scaling capabilities of simulation
codes.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.